概要
ビデオでチャットできたらどんなに良いだろうかと考えたことはありますか? 私自身もブログをやっているので、関連情報を見つけるために 3.5 時間のビデオを見るのは退屈なことがよくあります。 ビデオを見て有益な情報を得るのが仕事のように感じることがあります。 そこで、YouTube ビデオやその他のビデオとチャットできるチャットボットを構築しました。 これは、GPT-XNUMX-turbo、Langchain、ChromaDB、Whisper、および Gradio によって可能になりました。 そこで、この記事では、Langchain を使用して YouTube 動画用の機能的なチャットボットを構築するコードウォークスルーを行います。
学習目標
- Gradio を使用して Web インターフェイスを構築する
- Whisper を使用して YouTube 動画を処理し、そこからテキスト データを抽出します。
- テキストを適切に処理して書式設定する
- テキストデータの埋め込みを作成する
- データを保存するために Chroma DB を構成する
- OpenAI chatGPT、ChromaDB、埋め込み関数を使用して Langchain 会話チェーンを初期化する
- 最後に、Gradio チャットボットへのクエリと回答のストリーミング
コーディング部分に入る前に、使用するツールとテクノロジーについて理解しましょう。
この記事は、の一部として公開されました データサイエンスブログ。
目次
ラングチェーン
Langchain は、Python で書かれたオープンソース ツールで、大規模言語モデルをデータ認識およびエージェント化します。 それで、それは一体何を意味するのでしょうか? GPT-3.5 や GPT-4 などの市販の LLM のほとんどには、トレーニング対象のデータに制限があります。 たとえば、ChatGPT は、すでに見た質問にのみ答えることができます。 2021 年 XNUMX 月以降のことは不明です。 これは、Langchain が解決する中心的な問題です。 Word ドキュメントであれ、個人的な PDF であれ、データを LLM にフィードすると、人間のような応答を得ることができます。 Vector DB、チャット モデル、埋め込み関数などのツールのラッパーがあり、Langchain だけを使用して AI アプリケーションを簡単に構築できます。
Langchain を使用すると、エージェント (LLM ボット) を構築することもできます。 これらの自律エージェントは、データ分析、SQL クエリ、さらには基本的なコードの作成など、複数のタスク用に構成できます。 これらのエージェントを使用して自動化できることはたくさんあります。 これは、低レベルの知識作業を LLM にアウトソーシングできるため、時間とエネルギーを節約できて便利です。
このプロジェクトでは、Langchain ツールを使用してビデオ用のチャット アプリを構築します。 Langchain の詳細については、次のサイトを参照してください。 公式サイト.
ウィスパー
ウィスパー OpenAI のもう XNUMX つの子孫です。 これは、音声またはビデオをテキストに変換できる汎用の音声テキスト変換モデルです。 多言語翻訳、音声認識、分類を実行するために、大量の多様な音声でトレーニングされています。
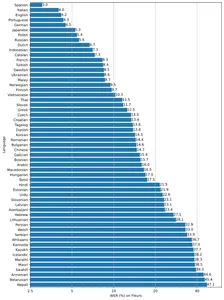
このモデルには、速度と精度のトレードオフを考慮して、小型、基本、中型、小型、大型の 2 つの異なるサイズが用意されています。 モデルのパフォーマンスは言語にも依存します。 以下の図は、ラージ vXNUMX モデルを使用した Fleur のデータセットの言語別の WER (Word Error Rate) の内訳を示しています。
ベクトルデータベース
ほとんどの機械学習アルゴリズムは、画像、音声、ビデオ、テキストなどの生の非構造化データを処理できません。 これらはベクトル埋め込みの行列に変換する必要があります。 これらのベクトル埋め込みは、多次元平面内のデータを表します。 エンベディングを取得するには、データの意味論的な意味を捕捉できる高効率の深層学習モデルが必要です。 これは AI アプリを作成する場合に非常に重要です。 このデータを保存してクエリするには、それらを効果的に処理できるデータベースが必要です。 その結果、ベクトル データベースと呼ばれる特殊なデータベースが作成されました。 複数のオープンソース データベースが存在します。 Chroma、Milvus、Weaviate、FAISS などが最も人気があります。
ベクター ストアのもう XNUMX つの USP は、非構造化データに対して高速な検索操作を実行できることです。 埋め込みを取得したら、それをクラスタリング、検索、並べ替え、分類に使用できます。 データ点はベクトル空間内にあるため、それらの間の距離を計算して、それらがどの程度密接に関連しているかを知ることができます。 類似したデータ ポイントを見つけるには、コサイン類似度、ユークリッド距離、KNN、ANN (近似最近傍) などの複数のアルゴリズムが使用されます。
我々は使用するだろう クロマ Vector Store – オープンソースのベクトル データベース。 Chroma には Langchain も統合されており、非常に便利です。
グラディオ
私たちのアプリ Gradio の XNUMX 番目の騎士は、機械学習モデルを簡単に共有するためのオープンソース ライブラリです。 また、Python を使用してコンポーネントやイベントを含むデモ Web アプリを構築するのにも役立ちます。
Gradio と Langchain に慣れていない場合は、先に進む前に次の記事を読んでください。
それでは構築を始めましょう。
開発環境のセットアップ
開発環境をセットアップするには、Python を作成します 仮想環境 または、Docker を使用してローカル開発環境を作成します。
これらの依存関係をすべてインストールします
pytube==15.0.0
gradio == 3.27.0
openai == 0.27.4
langchain == 0.0.148
chromadb == 0.3.21
tiktoken == 0.3.3
openai-whisper==20230314 ライブラリのインポート
import os
import tempfile
import whisper
import datetime as dt
import gradio as gr
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
from pytube import YouTube
from typing import TYPE_CHECKING, Any, Generator, List
Webインターフェースの作成
Gradio Block とコンポーネントを使用して、アプリケーションのフロントエンドを構築します。 そこで、インターフェイスを作成する方法を次に示します。 必要に応じて自由にカスタマイズしてください。
with gr.Blocks() as demo: with gr.Row(): # with gr.Group(): with gr.Column(scale=0.70): api_key = gr.Textbox(placeholder='Enter OpenAI API key', show_label=False, interactive=True).style(container=False) with gr.Column(scale=0.15): change_api_key = gr.Button('Change Key') with gr.Column(scale=0.15): remove_key = gr.Button('Remove Key') with gr.Row(): with gr.Column(): chatbot = gr.Chatbot(value=[]).style(height=650) query = gr.Textbox(placeholder='Enter query here', show_label=False).style(container=False) with gr.Column(): video = gr.Video(interactive=True,) start_video = gr.Button('Initiate Transcription') gr.HTML('OR') yt_link = gr.Textbox(placeholder='Paste a YouTube link here', show_label=False).style(container=False) yt_video = gr.HTML(label=True) start_ytvideo = gr.Button('Initiate Transcription') gr.HTML('Please reset the app after being done with the app to remove resources') reset = gr.Button('Reset App') if __name__ == "__main__": demo.launch() インターフェイスは次のように表示されます

ここには、OpenAI キーを入力として受け取るテキストボックスがあります。 また、API キーの変更とキーの削除のための XNUMX つのキーもあります。 左側にはチャット UI、右側にはローカル ビデオをレンダリングするためのボックスもあります。 ビデオ ボックスのすぐ下には、YouTube リンクを求めるボックスと、「文字起こしを開始する」というボタンがあります。
グラディオイベント
次に、アプリをインタラクティブにするイベントを定義します。 gr.Blocks() の最後に以下のコードを追加します。
start_video.click(fn=lambda :(pause, update_yt), outputs=[start2, yt_video]).then( fn=embed_video, inputs=, outputs=).success( fn=lambda:resume, outputs=[start2]) start_ytvideo.click(fn=lambda :(pause, update_video), outputs=[start1,video]).then( fn=embed_yt, inputs=[yt_link], outputs = [yt_video, chatbot]).success( fn=lambda:resume, outputs=[start1]) query.submit(fn=add_text, inputs=[chatbot, query], outputs=[chatbot]).success( fn=QuestionAnswer, inputs=[chatbot,query,yt_link,video], outputs=[chatbot,query]) api_key.submit(fn=set_apikey, inputs=api_key, outputs=api_key)
change_api_key.click(fn=enable_api_box, outputs=api_key) remove_key.click(fn = remove_key_box, outputs=api_key)
reset.click(fn = reset_vars, outputs=[chatbot,query, video, yt_video, ])- start_video: クリックすると、ビデオからテキストを取得するプロセスがトリガーされ、会話チェーンが作成されます。
- start_ytvideo: クリックすると同じことが行われますが、今度は YouTube ビデオから実行され、完了するとそのすぐ下に YouTube ビデオがレンダリングされます。
- クエリ: LLM からチャット UI へのストリーミング応答を担当します。
残りのイベントは、API キーの処理とアプリのリセット用です。
イベントは定義しましたが、イベントをトリガーする関数は定義していません。
バックエンド
複雑で煩雑にならないように、バックエンドで処理するプロセスの概要を説明します。
- API キーを処理します。
- アップロードされたビデオを処理します。
- ビデオを文字に起こしてテキストを取得します。
- ビデオテキストからチャンクを作成します。
- テキストから埋め込みを作成します。
- ベクター エンベディングを ChromaDB ベクター ストアに保存します。
- Langchain を使用して会話型検索チェーンを作成します。
- 関連するドキュメントを OpenAI チャット モデル (gpt-3.5-turbo) に送信します。
- 回答を取得し、チャット UI にストリーミングします。
これらすべてのことを、いくつかの例外処理とともに実行します。
いくつかの環境変数を定義します。
chat_history = []
result = None
chain = None
run_once_flag = False
call_to_load_video = 0 enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set', interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) pause = gr.Button.update(interactive=False)
resume = gr.Button.update(interactive=True)
update_video = gr.Video.update(value = None) update_yt = gr.HTML.update(value=None) API キーの処理
ユーザーがキーを送信すると、そのキーが環境変数として設定され、テキストボックスへのさらなる入力も無効になります。 変更キーを押すと再びミュータブルになります。 キーの削除をクリックするとキーが削除されます。
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)
remove_box = gr.Textbox.update(value = 'Your API key successfully removed', interactive=False) def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box
def enable_api_box(): return enable_box
def remove_key_box(): os.environ['OPENAI_API_KEY'] = '' return remove_boxビデオの処理
次に、アップロードされたビデオと YouTube リンクを扱います。 それぞれのケースに対処する XNUMX つの異なる関数があります。 YouTube リンクの場合は、iframe 埋め込みリンクを作成します。 それぞれのケースで、別の関数を呼び出します make_chain() チェーンを作成する責任があります。
これらの機能は、誰かがビデオをアップロードするか、YouTube リンクを提供して文字起こしボタンを押すとトリガーされます。
def embed_yt(yt_link: str): # This function embeds a YouTube video into the page. # Check if the YouTube link is valid. if not yt_link: raise gr.Error('Paste a YouTube link') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Set the global variable `call_to_load_video` to 0. # This is used to keep track of how many times the function has been called. call_to_load_video = 0 # Create a chain using the YouTube link. make_chain(url=yt_link) # Get the URL of the YouTube video. url = yt_link.replace('watch?v=', '/embed/') # Create the HTML code for the embedded YouTube video. embed_html = f"""<iframe width="750" height="315" src="{url}" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>""" # Return the HTML code and an empty list. return embed_html, [] def embed_video(video=str | None): # This function embeds a video into the page. # Check if the video is valid. if not video: raise gr.Error('Upload a Video') # Set the global variable `run_once_flag` to False. # This is used to prevent the function from being called more than once. run_once_flag = False # Create a chain using the video. make_chain(video=video) # Return the video and an empty list. return video, []チェーンの作成
これはすべての手順の中で最も重要な手順の XNUMX つです。 これには、Chroma ベクター ストアと Langchain チェーンの作成が含まれます。 このユースケースでは、会話型検索チェーンを使用します。 OpenAI 埋め込みを使用しますが、実際のデプロイメントでは、Huggingface センテンス エンコーダーなどの無料の埋め込みモデルを使用します。
def make_chain(url=None, video=None) -> (ConversationalRetrievalChain | Any | None): global chain, run_once_flag # Check if a YouTube link or video is provided if not url and not video: raise gr.Error('Please provide a YouTube link or Upload a video') if not run_once_flag: run_once_flag = True # Get the title from the YouTube link or video title = get_title(url, video).replace(' ','-') # Process the text from the video grouped_texts, time_list = process_text(url=url) if url else process_text(video=video) # Convert time_list to metadata format time_list = [{'source': str(t.time())} for t in time_list] # Create vector stores from the processed texts with metadata vector_stores = Chroma.from_texts(texts=grouped_texts, collection_name='test', embedding=OpenAIEmbeddings(), metadatas=time_list) # Create a ConversationalRetrievalChain from the vector stores chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.0), retriever= vector_stores.as_retriever( search_kwargs={"k": 5}), return_source_documents=True) return chain
- YouTube URL またはビデオ ファイルからテキストとメタデータを取得します。
- テキストとメタデータから Chroma ベクター ストアを作成します。
- OpenAI gpt-3.5-turbo とクロマ ベクター ストアを使用してチェーンを構築します。
- チェーンを戻します。
プロセステキスト
このステップでは、ビデオからテキストを適切にスライスし、上記のチェーン構築プロセスで使用したメタデータ オブジェクトも作成します。
def process_text(video=None, url=None) -> tuple[list, list[dt.datetime]]: global call_to_load_video if call_to_load_video == 0: print('yes') # Call the process_video function based on the given video or URL result = process_video(url=url) if url else process_video(video=video) call_to_load_video += 1 texts, start_time_list = [], [] # Extract text and start time from each segment in the result for res in result['segments']: start = res['start'] text = res['text'] start_time = dt.datetime.fromtimestamp(start) start_time_formatted = start_time.strftime("%H:%M:%S") texts.append(''.join(text)) start_time_list.append(start_time_formatted) texts_with_timestamps = dict(zip(texts, start_time_list)) # Convert the timestamp strings to datetime objects formatted_texts = { text: dt.datetime.strptime(str(timestamp), '%H:%M:%S') for text, timestamp in texts_with_timestamps.items() } grouped_texts = [] current_group = '' time_list = [list(formatted_texts.values())[0]] previous_time = None time_difference = dt.timedelta(seconds=30) # Group texts based on time difference for text, timestamp in formatted_texts.items(): if previous_time is None or timestamp - previous_time <= time_difference: current_group += text else: grouped_texts.append(current_group) time_list.append(timestamp) current_group = text previous_time = time_list[-1] # Append the last group of texts if current_group: grouped_texts.append(current_group) return grouped_texts, time_list
- process_text 関数は、URL またはビデオ パスのいずれかを受け取ります。 このビデオは process_video 関数で転写され、最終的なテキストが得られます。
- 次に、各文の開始時間を (Whisper から) 取得し、30 秒にグループ化します。
- 最後に、グループ化されたテキストと各グループの開始時間を返します。
ビデオの処理
このステップでは、ビデオまたはオーディオ ファイルを文字に起こし、テキストを取得します。 転写には Whisper ベース モデルを使用します。
def process_video(video=None, url=None) -> dict[str, str | list]: if url: file_dir = load_video(url) else: file_dir = video print('Transcribing Video with whisper base model') model = whisper.load_model("base") result = model.transcribe(file_dir) return resultYouTube 動画の場合は、直接処理できないため、別途処理する必要があります。 Pytube というライブラリを使用して、YouTube 動画の音声またはビデオをダウンロードします。 そこで、その方法を紹介します。
def load_video(url: str) -> str: # This function downloads a YouTube video and returns the path to the downloaded file. # Create a YouTube object for the given URL. yt = YouTube(url) # Get the target directory. target_dir = os.path.join('/tmp', 'Youtube') # If the target directory does not exist, create it. if not os.path.exists(target_dir): os.mkdir(target_dir) # Get the audio stream of the video. stream = yt.streams.get_audio_only() # Download the audio stream to the target directory. print('----DOWNLOADING AUDIO FILE----') stream.download(output_path=target_dir) # Get the path of the downloaded file. path = target_dir + '/' + yt.title + '.mp4' # Return the path of the downloaded file. return path
- 指定された URL の YouTube オブジェクトを作成します。
- 一時的なターゲット ディレクトリ パスを作成する
- パスが存在するかどうかを確認し、存在しない場合はディレクトリを作成します
- ファイルの音声をダウンロードします。
- ビデオのパス ディレクトリを取得する
これは、ビデオからテキストを取得してチェーンを作成するまでのボトムアップ プロセスでした。 あとはチャットボットを設定するだけです。
チャットボットを構成する
ここで必要なのは、クエリと chat_history を送信して回答を取得することだけです。 そこで、クエリが送信されたときにのみトリガーされる関数を定義します。
def add_text(history, text): if not text: raise gr.Error('enter text') history = history + [(text,'')] return history def QuestionAnswer(history, query=None, url=None, video=None) -> Generator[Any | None, Any, None]: # This function answers a question using a chain of models. # Check if a YouTube link or a local video file is provided. if video and url: # Raise an error if both a YouTube link and a local video file are provided. raise gr.Error('Upload a video or a YouTube link, not both') elif not url and not video: # Raise an error if no input is provided. raise gr.Error('Provide a YouTube link or Upload a video') # Get the result of processing the video. result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) # Add the question and answer to the chat history. chat_history += [(query, result["answer"])] # For each character in the answer, append it to the last element of the history. for char in result['answer']: history[-1][-1] += char yield history, ''
会話のコンテキストを保持するために、クエリとともにチャット履歴を提供します。 最後に、回答をチャットボットにストリーミングして返します。 すべての値をリセットするリセット機能を定義することを忘れないでください。
以上でした。 次に、アプリケーションを起動してビデオでのチャットを開始します。
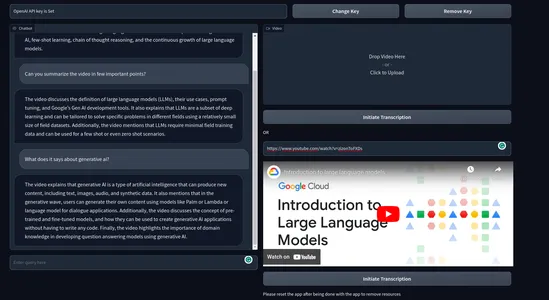
最終製品はこんな感じです
ビデオデモ:
[埋め込まれたコンテンツ]
実際の使用例
エンドユーザーがビデオやオーディオでチャットできるアプリケーションには、幅広い使用例があります。 このチャットボットの実際の使用例をいくつか紹介します。
- 教育: 学生は何時間ものビデオ講義を受講することがよくあります。 このチャットボットは、学生が講義ビデオから学習するのを支援し、有用な情報を迅速に抽出して、時間とエネルギーを節約します。 これにより、学習体験が大幅に向上します。
- リーガル: 法律専門家は、事件の分析、文書の作成、調査、コンプライアンスの監視などを行うために、多くの場合、長期にわたる法的手続きや証言録取を行っています。 このようなチャットボットは、そのようなタスクを整理するのに大いに役立ちます。
- 内容の要約: このアプリはビデオコンテンツを分析し、要約されたテキストバージョンを生成できます。 これにより、ユーザーはビデオを完全に視聴しなくても、ビデオのハイライトを把握できます。
- 顧客とのやり取り: ブランドは、自社の製品やサービスにビデオ チャットボット機能を組み込むことができます。 これは、高額な商品やサービス、または多くの説明を必要とする商品やサービスを販売する企業に役立ちます。
- ビデオ翻訳: テキスト コーパスを他の言語に翻訳できます。 これにより、言語を超えたコミュニケーション、言語学習、または非母語話者のアクセシビリティが促進されます。
これらは、私が思いつく可能性のある使用例の一部です。 動画用のチャットボットには、さらに便利なアプリケーションがたくさんあります。
まとめ
以上、ビデオ用チャットボットの機能デモ Web アプリの構築についてでした。 この記事では多くの概念を取り上げました。 この記事の主な要点を以下に示します。
- AI アプリケーションを簡単に作成するための人気ツールである Langchain について学びました。
- Whisper は、OpenAI による強力な音声テキスト変換モデルです。 音声や動画をテキストに変換できるオープンソースモデル。
- 私たちは、ベクトル データベースがどのようにしてベクトル埋め込みの効果的な保存とクエリを容易にするかを学びました。
- 私たちは、Langchain、Chroma、OpenAI モデルを使用して、完全に機能する Web アプリを最初から構築しました。
- また、チャットボットの潜在的な実際の使用例についても説明しました。
以上がすべてでした。気に入っていただければ幸いです。ぜひフォローを検討してください Twitter 開発に関連するその他の事項については、
GitHubリポジトリ: sunilkumardash9/chatgpt-for-videos。 これが役に立ったと思われる場合は、リポジトリを ⭐ 実行してください。
よくある質問
A. LangChain は、大規模な言語モデルを使用してアプリケーションの作成を簡素化するオープンソース フレームワークです。 チャットボット、ドキュメント分析、コード分析、質問応答、生成タスクなど、さまざまなタスクに使用できます。
A. チェーンは、順番に実行される一連のステップです。 これらは、特定のタスクまたはプロセスを定義するために使用されます。 たとえば、チェーンを使用して文書を要約したり、質問に答えたり、クリエイティブなテキストを生成したりできます。
エージェントはチェーンよりも複雑です。 彼らはどのステップを実行するかを決定することができ、また自分の経験から学ぶこともできます。 エージェントは、データ分析やコード生成など、多くの創造性や推論を必要とするタスクによく使用されます。
A. 1. アクション: アクション エージェントは、実行するアクションを決定し、そのアクションを一度に XNUMX ステップずつ実行します。 これらはより従来型であり、小規模なタスクに適しています。
2. 計画と実行のエージェントは、まず実行するアクションの計画を決定し、次にそれらのアクションを一度に XNUMX つずつ実行します。 これらはより複雑で、より高い計画と柔軟性が必要なタスクに適しています。
A. Langchain は LLM とチャット モデルを統合できます。 LLM は、文字列入力を受け取り、文字列応答を返すモデルです。 チャット モデルは、チャット メッセージのリストを入力として受け取り、チャット メッセージを出力します。
A. はい、Lagchain はオープンソースの無料で使用できるツールですが、ほとんどの操作には料金が発生する OpenAI API キーが必要です。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 自動車/EV、 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- ブロックオフセット。 環境オフセット所有権の近代化。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/06/build-a-chatgpt-for-youtube-videos-with-langchain/

