概要
わずか XNUMX か月で、OpenAI の ChatGPT は私たちの生活に不可欠な部分になりました。 それはもはやテクノロジーだけに限定されません。 学生からライターまで、年齢や職業を問わず幅広く利用されています。 これらのチャット モデルは、正確さ、スピード、そして人間らしい会話に優れています。 テクノロジーだけでなく、さまざまな分野で重要な役割を果たすことが期待されています。
AutoGPT、BabyAGI、Langchain などのオープンソース ツールが登場し、言語モデルの力を活用しています。 プロンプトを使用してプログラミング タスクを自動化し、言語モデルをデータ ソースに接続し、これまでよりも迅速に AI アプリケーションを作成します。 Langchain は、PDF 用の ChatGPT 対応 Q&A ツールであり、AI アプリケーションを構築するためのワンストップ ショップになります。
学習目標
- Gradio を使用してチャットボット インターフェイスを構築する
- PDF からテキストを抽出し、埋め込みを作成する
- Chroma ベクトル データベースにエンベディングを保存する
- クエリをバックエンド (Langchain チェーン) に送信します。
- テキストに対してセマンティック検索を実行して、関連するデータ ソースを見つける
- LLM (ChatGPT) にデータを送信し、チャットボットで回答を受け取ります
Langchain を使用すると、これらすべての手順を数行のコードで簡単に実行できます。 埋め込みモデル、チャット モデル、ベクトル データベースなど、複数のサービスのラッパーが含まれています。
この記事は、の一部として公開されました データサイエンスブログ。
目次
ラングチェーンとは何ですか?
Langchain は、Python で書かれたオープンソース ツールで、外部データを大規模言語モデルに接続するのに役立ちます。 これにより、GPT-4 や GPT-3.5 などのチャット モデルがよりエージェント的でデータ認識型になります。 したがって、ある意味、Langchain は、トレーニングされていない新しいデータを LLM に供給する方法を提供します。 Langchain は、言語モデルと対話する際の複雑さを抽象化する多くのチェーンを提供します。 また、ベクトル埋め込みを作成するためのモデルや、ベクトルを保存するためのベクトル データベースなど、他のいくつかのツールも必要です。 先に進む前に、テキストの埋め込みについて簡単に見てみましょう。 これらは何ですか?なぜ重要ですか?
テキストの埋め込み
テキストの埋め込みは、大規模な言語操作の核心です。 技術的には、自然言語を使用した言語モデルを操作できますが、自然言語の保存と取得は非常に非効率的です。 たとえば、このプロジェクトでは、大量のデータに対して高速検索操作を実行する必要があります。 自然言語データに対してそのような操作を実行することは不可能です。
より効率的にするには、テキスト データをベクター形式に変換する必要があります。 テキストから埋め込みを作成するための専用の ML モデルがあります。 テキストは多次元ベクトルに変換されます。 埋め込むと、これらのデータのグループ化、並べ替え、検索などを行うことができます。 XNUMX つの文の間の距離を計算して、それらがどの程度密接に関連しているかを知ることができます。 そして、その最も優れた点は、これらの操作が従来のデータベース検索のようにキーワードに限定されるのではなく、むしろ XNUMX つの文の意味上の近さを捉えることです。 これにより、機械学習のおかげでさらに強力になります。
ラングチェーンツール
Langchain には、Chroma、Redis、Pinecone、Alpine db などのすべての主要なベクター データベースのラッパーがあります。 同じことが LLM にも当てはまり、OpeanAI モデルとともに、Cohere のモデルである GPT4ALL (GPT モデルのオープンソース代替品) もサポートされます。 埋め込みに関しては、OpeanAI、Cohere、および HuggingFace 埋め込み用のラッパーを提供します。 カスタム埋め込みモデルも使用できます。
つまり、Langchain は、基盤となるテクノロジーとのやり取りに伴う多くの複雑さを抽象化し、誰でも簡単に AI アプリケーションを迅速に構築できるようにするメタツールです。
この記事では、 OpenAI 埋め込み 埋め込みを作成するためのモデル。 エンド ユーザー向けに AI アプリを展開したい場合は、Huggingface モデルや Google の Universal Sentence Encoder などのオープンソース モデルの使用を検討してください。
ベクトルを保存するには、次を使用します。 クロマDB、オープンソースのベクター ストア データベース。 Alpine、Pinecone、Redis などの他のデータベースもお気軽に探索してください。 Langchain には、これらすべてのベクター ストアのラッパーがあります。
Langchain チェーンを作成するには、次を使用します。 会話型検索チェーン()、履歴のあるチャット モデルとの会話に最適です (会話のコンテキストを維持するため)。 ぜひチェックしてみてください 公式ドキュメント さまざまな LLM チェーンについて。
開発環境のセットアップ
使用するライブラリはかなり多くあります。 したがって、事前にインストールしてください。 シームレスですっきりとした開発環境を作成するには、次を使用します。 仮想環境 or デッカー.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"次に、これらのライブラリをインポートします
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Imageチャットインターフェイスの構築
アプリケーションのインターフェイスには XNUMX つの主要な機能があります。XNUMX つはチャット インターフェイスで、もう XNUMX つは PDF の関連ページを画像としてレンダリングします。 これとは別に、エンド ユーザーから OpenAI API キーを受け入れるためのテキスト ボックス。 この記事を最後まで読むことを強くお勧めします Gradio を使用して GPT チャットボットを構築する ゼロから。 この記事では、Gradio の基本的な側面について説明します。 この記事から多くのことを借用します。
Gradio Blocks クラスを使用すると、Web アプリを構築できます。 Row クラスと Columns クラスを使用すると、Web アプリ上で複数のコンポーネントを整列させることができます。 これらを使用して Web インターフェイスをカスタマイズします。
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
インターフェイスはシンプルで、いくつかのコンポーネントが含まれています。
それは持っています:
- PDF と通信するためのチャット インターフェイス。
- 関連する PDF ページをレンダリングするためのコンポーネント。
- API キーを受け入れるためのテキスト ボックスとキーの変更ボタン。
- 質問するためのテキスト ボックスと送信ボタン。
- ファイルをアップロードするためのボタン。
これは Web UI のスナップショットです。
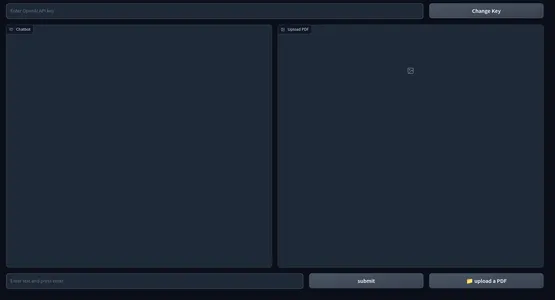
アプリケーションのフロントエンド部分が完了しました。 バックエンドに飛び乗りましょう。
バックエンド
まず、これから扱うプロセスの概要を説明します。
- アップロードされた PDF と OpenAI API キーを処理する
- PDF からテキストを抽出し、OpenAI 埋め込みを使用して PDF からテキスト埋め込みを作成します。
- ベクター エンベディングを ChromaDB ベクター ストアに保存します。
- Langchain を使用して会話型検索チェーンを作成します。
- クエリされたテキストの埋め込みを作成し、埋め込まれたドキュメントに対して類似性検索を実行します。
- 関連するドキュメントを OpenAI チャット モデル (gpt-3.5-turbo) に送信します。
- 回答を取得し、チャット UI にストリーミングします。
- 関連する PDF ページを Web UI にレンダリングします。
以上がアプリケーションの概要です。 構築を始めましょう。
グラディオイベント
Web UI で特定のアクションが実行されると、これらのイベントがトリガーされます。 したがって、イベントによって Web アプリがインタラクティブかつ動的になります。 Gradio を使用すると、Python コードでイベントを定義できます。
Gradio イベントは、前に定義したコンポーネント変数を使用してバックエンドと通信します。 アプリケーションに必要ないくつかのイベントを定義します。 これらは
- APIキーイベントの送信: API キーを貼り付けた後に Enter キーを押すと、このイベントがトリガーされます。
- キーの変更: これにより、新しい API キーを提供できるようになります
- クエリの入力: テキスト クエリをチャットボットに送信します
- ファイルをアップロード: これにより、エンドユーザーは PDF ファイルをアップロードできるようになります
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )これまでのところ、上記のイベント ハンドラー内で呼び出される関数は定義されていません。 次に、これらすべての関数を定義して、機能する Web アプリを作成します。
API キーの処理
全体が BYOK (Bring Your Own Key) 原則に基づいて実行されるため、ユーザーの API キーの処理は重要です。 ユーザーがキーを送信するたびに、キーが設定されていることを示唆するプロンプトが表示され、テキスト ボックスが不変になる必要があります。 そして、「Change Key」イベントがトリガーされると、ボックスは入力を受け取ることができる必要があります。
これを行うには、XNUMX つのグローバル変数を定義します。
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)関数を定義する
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxset_apikey 関数は文字列入力を受け取り、実行後にテキストボックスを不変にする disable_box 変数を返します。 Gradio Events セクションでは、set_apikey 関数を呼び出す api_key Submit イベントを定義しました。 OSライブラリを使用してAPIキーを環境変数として設定します。
「API キーの変更」ボタンをクリックすると、enable_box 変数が返され、テキストボックスの変更可能性が再び有効になります。
チェーンの作成
これが最も重要なステップです。 このステップには、テキストの抽出、埋め込みの作成、およびそれらのベクトル ストアへの保存が含まれます。 複数のサービスのラッパーを提供する Langchain のおかげで、作業が簡単になります。 それでは、関数を定義しましょう。
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- APIキーが設定されているかどうかのチェックを作成しました。 キーが設定されていない場合、フロントエンドでエラーが発生します。
- PyPDFLoaderを使用してPDFファイルをロードする
- OpenAIEmbeddings を使用した定義済みエンベディング機能。
- 埋め込み機能を使用して、PDF のテキストのリストからベクトル ストアを作成しました。
- chatOpenAI (デフォルトでは、ChatOpenAI は gpt-3.5-turbo を使用します)、ベース レトリーバー (類似性検索を使用します) を使用してチェーンを定義しました。
応答の生成
チェーンが作成されたら、チェーンを呼び出してクエリを送信します。 クエリとともにチャット履歴を送信して、会話のコンテキストを保持し、応答をチャット インターフェイスにストリーミングします。 関数を定義しましょう。
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- PDF がアップロードされていない場合はエラーが発生します。
- process_file 関数を XNUMX 回だけ呼び出します。
- クエリとチャット履歴をチェーンに送信します
- 最も関連性の高い回答のページ番号を取得します。
- 応答をフロントエンドに渡します。
PDF ファイルのイメージをレンダリングする
最後のステップでは、最も関連性の高い回答を含む PDF ファイルの画像をレンダリングします。 PyMuPdf ライブラリと PIL ライブラリを使用して、ドキュメントの画像をレンダリングできます。
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- PyMuPdf の Fitz でファイルを開きます。
- 該当するページを取得します。
- ページのピクスマップを取得します。
- PIL の Image クラスからイメージを作成します。
PDF とチャットするための機能的な Web アプリを作成するために必要な作業はこれですべてです。
すべてをまとめる
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()すべての設定が完了したので、アプリケーションを起動しましょう。
次のコマンドを使用して、アプリケーションをデバッグ モードで起動できます。
グラデーションapp.py
それ以外の場合は、Python コマンドを使用してアプリケーションを単純に実行することもできます。 以下は最終製品のスナップショットです。 の GitHub リポジトリ コード.
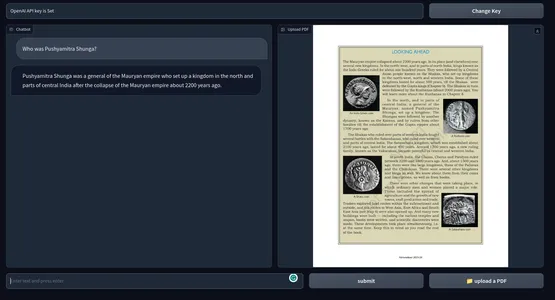
[埋め込まれたコンテンツ]
可能な改善
現在のアプリケーションは非常にうまく機能します。 しかし、それを改善するためにできることがいくつかあります。
- これは OpenAI 埋め込みを使用しますが、長期的にはコストが高くなる可能性があります。 本番環境に対応したアプリの場合は、オフライン埋め込みモデルの方が適している可能性があります。
- プロトタイピング用の Gradio は問題ありませんが、現実の世界では、Next Js や Svelte などの最新の JavaScript フレームワークを備えたアプリの方が、パフォーマンスと見た目の点ではるかに優れています。
- 関連するテキストを見つけるためにコサイン類似度を使用しました。 状況によっては、KNN アプローチの方が優れている場合があります。
- 高密度のテキストコンテンツを含む PDF の場合は、より小さいテキストの塊を作成する方が良い場合があります。
- モデルが優れていればいるほど、パフォーマンスも向上します。 他の LLM を試して結果を比較してください。
実用的なユースケース
教育から法律、学界に至るまでの複数の分野、または膨大なテキストを読み進める必要があると考えられるあらゆる分野にわたってツールを使用できます。 PDF に対する ChatGPT の実際の使用例の一部を以下に示します。
- 教育機関: 学生は教科書、教材、課題をアップロードでき、ツールは質問に答えたり、特定のセクションを説明したりできます。 これにより、生徒にとって学習プロセス全体の負担が軽減されます。
- リーガルポリシー: 法律事務所は、PDF 形式で大量の法的文書を処理する必要があります。 このツールを使用すると、訴訟文書、法的契約書、法令から関連情報を簡単に抽出できます。 これにより、弁護士は条項、判例、その他の情報をより迅速に見つけることができます。
- アカデミー: 研究者は研究論文や技術文書を扱うことがよくあります。 文献を要約し、分析し、文書から回答を提供できるツールは、全体的な時間を節約し、生産性を向上させるのに大いに役立ちます。
- 管理: 政府オフィスやその他の管理部門は、毎日大量のフォーム、申請書、レポートを処理します。 文書に回答するチャットボットを採用すると、管理プロセスが合理化され、全員の時間とお金が節約されます。
- ファイナンス:財務報告書を分析して何度も見直すのは面倒です。 これはチャットボットを使用することで簡単に行うことができます。 本質的にはインターンです。
- メディア: ジャーナリストとアナリストは、chatGPT 対応の PDF 質問回答ツールを使用して、大規模なテキスト コーパスをクエリし、回答をすばやく見つけることができます。
chatGPT 対応の PDF Q&A ツールを使用すると、大量の PDF テキストから情報を迅速に収集できます。 テキストデータの検索エンジンのようなものです。 PDF だけでなく、少しコードを操作するだけで、このツールをテキスト データを含むあらゆるものに拡張することもできます。
まとめ
以上、ChatGPT を使用して PDF ファイルと会話するためのチャットボットを構築することについてでした。 Langchain のおかげで、AI アプリケーションの構築がはるかに簡単になりました。 この記事の重要なポイントは次のとおりです。
- Gradio は、AI アプリケーションのプロトタイピング用のオープンソース ツールです。 Gradio を使用してアプリケーションのフロントエンドを作成しました。
- Langchain は、AI アプリケーションの構築を可能にするもう XNUMX つのオープンソース ツールです。 一般的な LLM とベクター データ ストアのラッパーがあり、基盤となるサービスと簡単にやり取りできるようになります。
- アプリケーションのバックエンド システムの構築には Langchain を使用しました。
- OpenAI モデルは、私たちのアプリにとって全体的に非常に重要でした。 PDF とのチャットには OpenAI 埋め込みと GPT 3.5 エンジンを使用しました。
- PDF やその他のテキスト データ用の ChatGPT 対応 Q&A ツールは、ナレッジ タスクの合理化に大いに役立ちます。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- プラトアイストリーム。 Web3 データ インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- 未来を鋳造する w エイドリエン・アシュリー。 こちらからアクセスしてください。
- PREIPO® を使用して PRE-IPO 企業の株式を売買します。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

