概要
この記事では、データ変換が発生するときの ETL (抽出、変換、読み込み) と ELT (抽出、読み込み、変換) の違いについて説明します。 ETL では、ターゲット データ ファイルの要件を満たすためにデータが複数の場所から抽出され、ファイルに配置されます。 変換プロセスは、ターゲットの外部、別の処理ツールまたはシステムで発生します。
ELT では、データは複数のソースから抽出され、ターゲットに配置されます。 変換プロセスは、ファイルの処理能力を使用してデータ ファイルを取得します。 変換は、データがファイルに配置された後に実行されます。
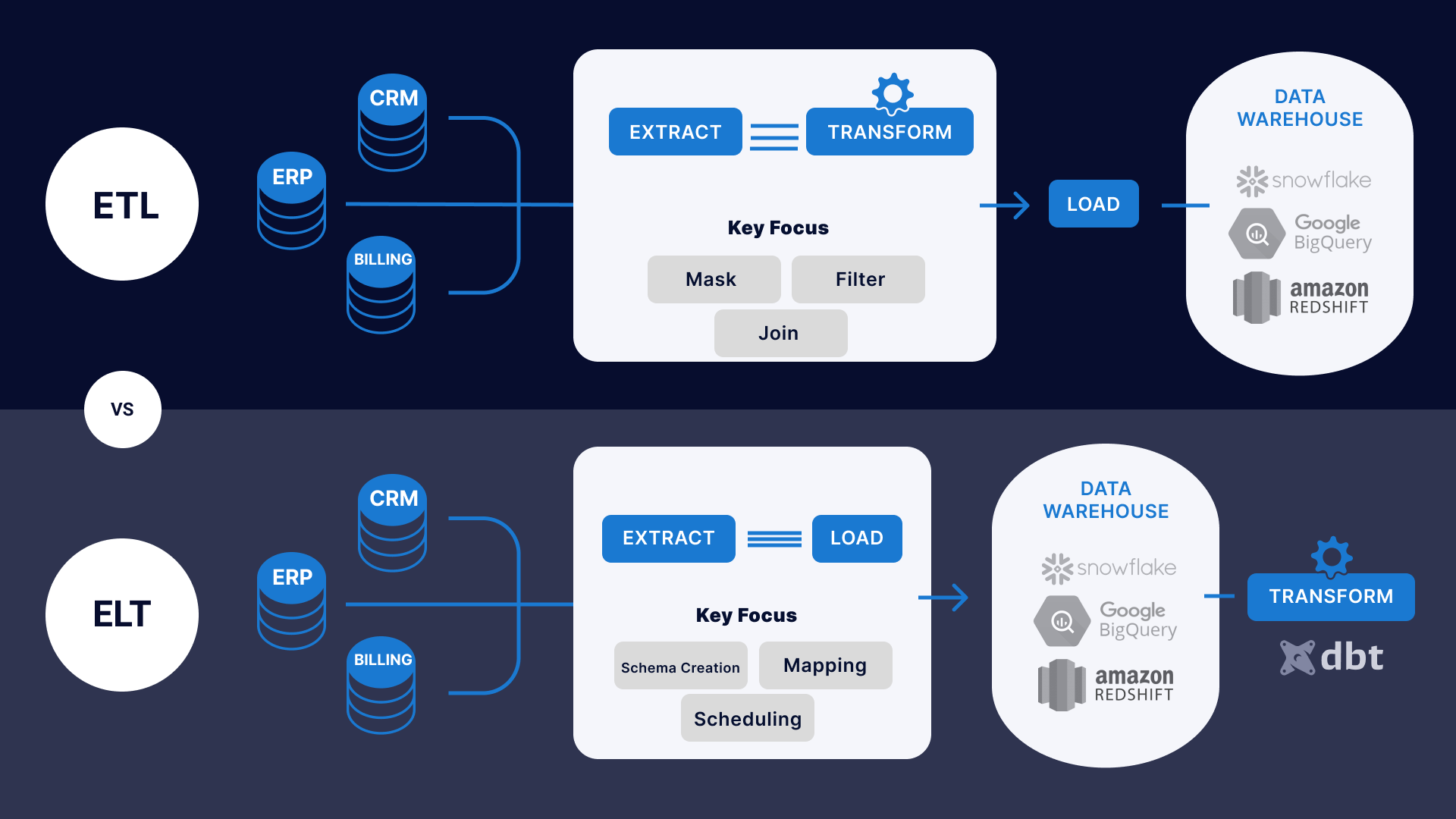
要約すると、ETL と ELT の主な違いは、データ変換の操作の順序と、変換が行われる場所です。 ETL はデータをターゲット ファイルにロードする前に変換を実行しますが、ELT はデータをファイルにロードした後に変換を実行します。
学習目標:
ETL と ELT パイプラインに関する記事の可能性を次に示します。
1. ETL パイプラインと ELT パイプラインの違いを理解する。これには、各アプローチでいつ、どこでデータ変換が行われるかなども含まれます。
2. 速度やデータ品質など、ETL パイプラインと ELT パイプラインの長所と短所の比較。
3. ETL または ELT パイプラインを実装した企業の実例に精通し、アプローチの選択に影響を与えた要因を理解する。
4. クラウド コンピューティングやリアルタイム データ処理の重要性の高まりなど、データ統合の将来の傾向と進歩を理解する。
データをロードする際の重要なステップを含む、データ統合プロセスの包括的な概要を取得します。 さまざまなタイプのデータ統合シナリオに対する ETL および ELT パイプラインの適合性を評価し、これらのアプローチから選択する必要がある要因。
この記事は、の一部として公開されました データサイエンスブログソン.
目次
- ELT が ETL を上回っているのはなぜですか?
- 最善のアプローチを決定する方法 – ETL または ELT?
- ETL および ELT パイプラインの例
- セキュリティとデータ ガバナンス
- データ統合の分野における今後の動向と進歩
- ETL または ELT パイプラインを使用している企業の実例
- まとめ
ELT が ETL より優れているのはなぜですか?
ETL および ELT パイプラインの長所と短所の一部を次に示します。
ETL パイプラインの利点:
- ETL パイプラインは広く採用されており、実績のある十分に理解されたデータ統合ソリューションを提供します。
- ETL パイプラインは大量のデータを処理できるため、バッチ処理とウェアハウジング アプリケーションを作成できます。
- ETL パイプラインはデータを提供し、データの管理とアクセスを容易にします。
- ETL パイプラインはクリーニングと検証を行うことができ、データ品質を向上させ、分析と意思決定を容易にします。
ETL パイプラインの欠点:
- ETL パイプラインは遅く、リソースを大量に消費する可能性があるため、リアルタイムのデータ処理には適していません。
- ETL パイプラインは複雑で管理が難しく、専門的な技術スキルが必要になる場合があります。
- ETL パイプラインは柔軟性に欠ける場合があり、変化するビジネス要件への対応が難しくなります。
- ETL パイプラインは、データ統合プロセスに遅延をもたらす可能性があり、リアルタイムの洞察を得ることを困難にします。
ELT パイプラインの利点:
- ELT パイプラインは、リアルタイムのデータ処理用に設計されており、アプリケーションの洞察とアクションを実現します。
- ELT パイプラインは、クラウド コンピューティングの力を活用して、リアルタイムでデータを処理できるようにします。
- ELT パイプラインは、複数のソースと IoT デバイスからのデータを統合できるため、データの完全なビューを取得できます。
- ELT パイプラインはより柔軟で、ビジネス要件が変化します。
ELT パイプラインの欠点:
- ELT パイプラインは比較的新しいソリューションです。
- ELT パイプラインは、セットアップと管理がより複雑になる可能性があり、専門的な技術スキルが必要になります。
- ELT パイプラインは、異なるレベルのデータ検証とパイプラインを提供する可能性があり、データ品質の低下につながる可能性があります。
- ELT パイプラインはバッチ処理には適していない可能性があり、データ ウェアハウスはリアルタイム データ処理用に最適化されています。
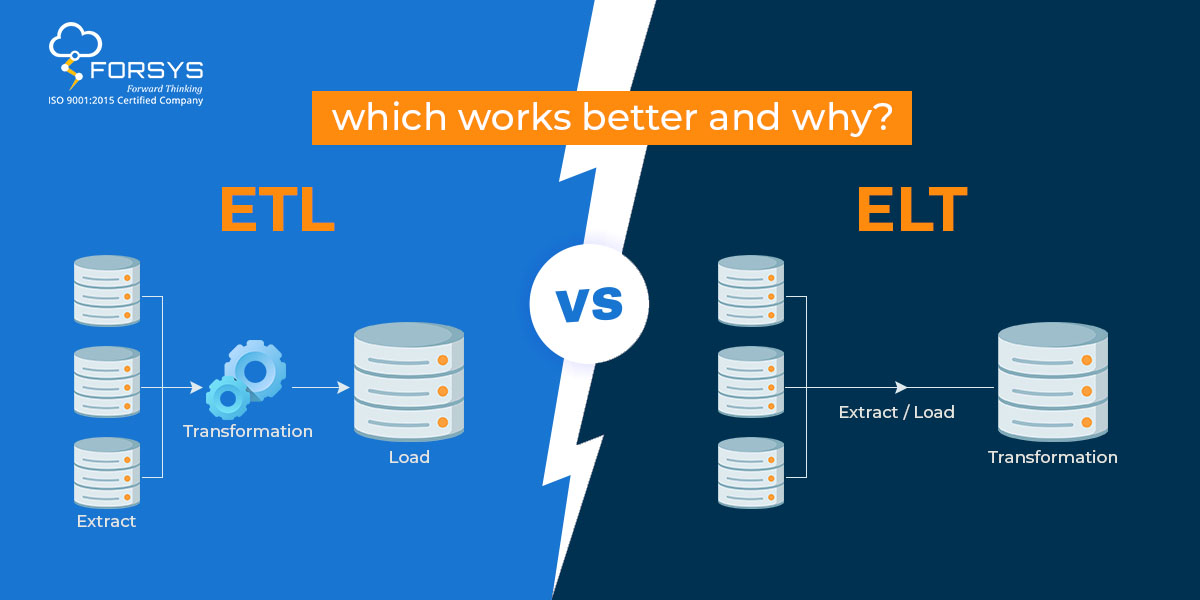
最善のアプローチを決定する方法 – ETL または ELT?
ETL と ELT のどちらを選択するかは、特定の要件です。 たとえば、複数のソースからのデータを統合し、複雑な変換を実行する必要がある場合は、ETL の方が適している場合があります。 ETL 変換機能を備えており、複雑なデータ統合シナリオを処理できます。
XNUMX つを区別するためのいくつかのポインター:
- ETL はターゲット システムにデータをロードする前のデータ変換に重点を置いていますが、ELT はデータのロードとターゲット システムの実行に重点を置いています。
- ETL は、複数のソースからのデータ変換と統合に適しています。
- 変換ステップは大量のデータを処理するように設計されたターゲット システムであるため、ELT はパフォーマンスの点でより効率的です。
- ELT はデータ統合により適している可能性があり、ターゲット システムのリソースと並列処理機能を活用する必要があります。
- データ変換ステップが別の ETL ツールを使用して行われるため、ETL はよりスケーラブルになり、ターゲット システムとは独立してスケーリングできます。
ETL および ELT パイプラインの例
Python と一般的な ETL ツール Apache NiFi を使用した ETL プロセスの例を次に示します。 次のコードは、CSV ファイルからデータを抽出して実行し、データを MySQL データベースにロードします。
from nifi import ProcessGroup, ExtractText, ReplaceText, PutSQL # CSV ファイルからデータを抽出する extract = ExtractText(path="path="path/to/input.csv") replace = ReplaceText(search="old_value", replace="new_value") #データを MySQL データベースにロード load = PutSQL(connection_url="jdbc:mysql://host:port/database", username="username", password="password", sql_select_query="INSERT INTO table (column1, column2) VALUES (?, ?)") # プロセッサをリンクする ProcessGroup を作成します pg = ProcessGroup(processors=[extract, replace, load]) # ETL プロセスを実行します pg.run()
以下は、Python と SQLAlchemy ライブラリを使用した ELT プロセスの例です。 次のコードは、CSV ファイルからデータを抽出し、それを PostgreSQL データベースにロードして、SQL クエリを使用して実行します。
from sqlalchemy import create_engine import pandas # PostgreSQL データベース エンジンに接続 = create_engine("postgresql://username:[メール保護]:port/database") # データを CSV ファイルから Pandas DataFrame にロードします df = pd.read_csv("path/to/input.csv") # データを PostgreSQL データベースにロードします df.to_sql("table_name", engine, if_exists="replace") # engine.connect() を使用した SQL クエリ con: con: con.execute("UPDATE table_name SET column1 = column1 + 1") con.execute("DELETE FROM table_name WHERE column2 = 'value'" )
これらの例は単なる ETL および ELT プロセスであり、実際のシナリオではプロセスがはるかに複雑であることに注意することが重要です。 さまざまなライブラリとツールが含まれる場合があります。
セキュリティとデータ ガバナンス
ETL と ELT のどちらを選択するかを選択する場合、セキュリティとデータ ガバナンスは重要な要素です。 ETL では、ETL ツールによるデータ ガバナンスにより、データをより細かく制御できます。 ETL ツールは、セキュリティ対策、暗号化、データ マスキング、およびアクセス制御を実装するように構成できます。 これにより、機密データのセキュリティ層を追加できます。
一方、ELT はデータ ガバナンスをターゲット システムに依存します。 同時に、ターゲット システムは堅牢なセキュリティ対策を提供する可能性がありますが、ETL ツールとは異なるレベルの制御を備えています。 また、ELT がターゲット システムにデータをロードすると、データに機密情報が含まれている場合、セキュリティ リスクが生じる可能性があります。
データ ガバナンスの品質、系列、カタログ化、およびコンプライアンスの規制。 ETL は、より優れたデータを提供し、データの品質と系列をより適切に制御できるため、データの変更を追跡しやすくなり、データをよりよく理解できるようになります。 一方、ELT はデータではより困難になる可能性があります。 データの変更を追跡し、データを明確に理解するには、より多くの作業が必要です。

出典:Analytics Vidhya
データ統合分野の今後の動向と進歩
以下は、データ統合の分野における将来の傾向と進歩です。
- 自動化と AI 主導のデータ統合: 自動化と人工知能は、データ統合の将来において大きな役割を果たし、プロセスをより迅速かつ効率的にし、エラーを起こしにくくします。 AIアルゴリズム リアルタイムのデータ主導の意思決定で、パターンと異常を自動的に識別できます。
- マルチクラウドと EdgeComputing: クラウドの台頭に伴い、ますます複数のクラウド プロバイダーに依存するようになっています。 データ統合ソリューションは、複数のクラウドからのデータをシームレスに統合し、 IoTデバイス.
- データ ガバナンスに焦点を当てる: データガバナンスはますます重要になります。 データ統合ソリューションは、プライバシー、セキュリティ、系統など、堅牢なデータ ガバナンス機能を提供する必要があります。
- リアルタイムのデータ処理をさらに重視: リアルタイムの洞察とアクションに対する需要が高まる中、IoT デバイスを含むデータ統合ソリューションはリアルタイムでデータを処理する必要があります。
- ローコードおよびノーコード プラットフォームの拡張: ローコードおよびノーコード プラットフォームの人気が高まり続け、専門的な技術スキルを必要とせずにデータ統合パイプラインを簡単に作成および管理できるようになります。
- ブロックチェーン技術の使用の増加: ブロックチェーン テクノロジーは、データの統合、共有、コラボレーションに革命をもたらします。
- データ仮想化の出現: データ仮想化はますます重要になり、データを物理的に移動することなく、複数のソースからのデータにアクセスして統合します。
これらのトレンドと進歩は、 データ統合、より良いデータ駆動型の意思決定を行い、ビジネス環境における全体的な効率を向上させます。

ETL または ELT パイプラインの実際の例
ETL または ELT パイプラインの実際の例を次に示します。
- ウォルマート: Walmart ETL パイプラインを使用して、POS システムやサプライヤーなどのデータを抽出し、データをクリーンアップして、中央のデータ ウェアハウスにロードします。 これにより、会社は販売データと意思決定を分析できます。
- Netflix: Netflix ELT パイプラインを使用して生データを抽出し、それをクラウドベースのデータ レイクにロードしてから、クラウドベースの分析ツールを使用してデータを分析します。 大量のデータをリアルタイムで処理し、パーソナライズされたレコメンデーションをユーザーに提供できるようにします。
- アマゾン: Amazon 特定に応じて、ETL および ELT パイプラインを使用します。 たとえば、ETL パイプラインは、複数のソースからの大量のデータを処理し、分析のためにデータ ウェアハウスにロードするために使用されます。 一方、ELT パイプラインは、リアルタイムのデータ処理と顧客の行動に使用され、ショッピング エクスペリエンスを向上させます。
- グーグル社: でログイン ELT パイプラインを使用して、検索クエリ、広告、その他のソースからのデータなど、リアルタイムでデータを抽出します。 これにより、企業はユーザーの行動に関する洞察を得て、ユーザー エクスペリエンスを向上させるためのリアルタイムの意思決定を行うことができます。
- Spotifyは: Spotifyは ELT パイプラインを使用して、ユーザーが生成したデータ (リスニング習慣やソーシャル ロケーション データなど) を抽出、読み込みます。 これにより、企業はユーザー エクスペリエンスをパーソナライズし、データ主導の意思決定を行って全体的なユーザー エクスペリエンスを向上させることができます。
まとめ
結論として、ETL と ELT は、あるシステムから別のシステムに移行するために使用される一般的なデータ統合アプローチです。 ETL は、データがターゲット システムである従来のアプローチです。 ELT は新しいアプローチであり、データは最初にターゲット システムにロードされてから変更されます。 ELT には、パフォーマンス、リソースのより効率的な使用、よりリアルタイムのデータ統合、およびガバナンスなど、ETL よりも優れた利点があります。
ETL と ELT は相互に排他的ではなく、リアルタイムのデータ統合のために ETL の読み込みと ELT に応じて組み合わせることができます。 ETL と ELT のどちらを選択するかは、特定の要件に基づいて決定する必要があります。
この記事の要点:
1. ETL (抽出、変換、ロード) および ELT (抽出、ロード、変換) は、あるシステムから別のシステムに移動するために使用される統合アプローチです。
2. ETL および ELT パイプラインの利点について説明しました。 前述したように、ELT は ETL よりも強力で便利です。
3. ETL と ELT のどちらを選択するかについて説明しました。 どのパイプラインが最も効果的かを話し合い、決定する必要があります。
4. Python を使用して ETL および ELT パイプラインの例をいくつかコーディングしました。この例では、CSV ファイルからデータを読み取り、それを MySQLデータベース 実行後。 その後、記事を締めくくりました。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2023/02/unlock-the-true-potential-of-your-data-with-etl-and-elt-pipeline/

