この記事は、の一部として公開されました データサイエンスブログソン.
概要
ソーシャル メディアの文化とトレンドの拡大に伴い、毎日生成されるデータの量は劇的に増加しています。 この大量のデータを効率的に処理するために、Teradata は企業の資産になりつつあります。 Teradata は、高速処理が必要な大量のデータを扱う支配者です。
Teradata は、強力な OLAP (Online Analytical Programming) 機能を実行し、データを並行して処理できます。 Teradata は、Oracle やその他の DBMS データ構造よりも優れたパフォーマンスとリニアなデータベース スケーラビリティを提供します。
テラデータとは?
アメリカの IT 企業である Teradata Corporation は、Teradata ソフトウェアと呼ばれる大規模なデータ ウェアハウス アプリケーションを開発できるソフトウェアを開発しました。 これは、オープンソースのリレーショナル データベース管理システム (RDBMS) であり、並列処理 (超並列サービス) の概念を使用し、複数のデータ ウェアハウス操作をサポートします。
Teradata は、Unix/Linux/Windows などのさまざまなプラットフォーム サーバーをサポートすると同時に、さまざまなクライアント環境のサポートを保証します。 非常に効率的で安価な RDBMS です。
Teradata アーキテクチャ
Teradata アーキテクチャは、大量のデータを非常に簡単に処理できるように設計された超並列処理 (MPP) アーキテクチャです。 パーシング エンジン(PE)、BYNET、およびアクセス モジュール プロセッサ(AMP)の XNUMX つの重要なコンポーネントで構成されます。 Teradata アーキテクチャの各コンポーネントについて詳しく説明し、その機能を理解しましょう!
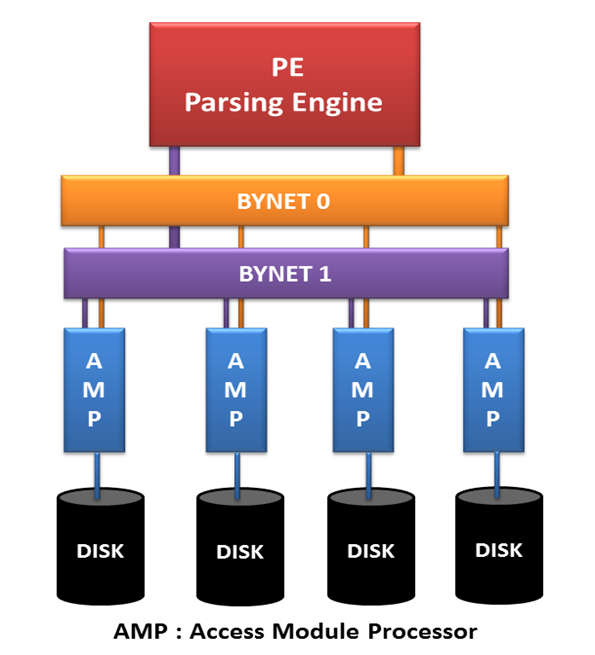
画像:- https://tdexperts.wordpress.com/2016/04/14/teradata-architecture/
A. 解析エンジン: 解析エンジンは Teradata の基本コンポーネントと見なされ、クライアントから受け取ったクエリを解析し、実行計画を準備します。 リクエストを最適化してユーザーに送信し、セッションを管理します。 解析エンジンの重要な責任の一部を以下に示します。
-
クライアントから送信された SQL クエリを受け取り、解析を実行して構文エラーをチェックします。
-
クエリで使用可能なオブジェクトが関連しているかどうかをチェックします。
-
ユーザーがクエリに存在するオブジェクトに対して認証されているかどうかを確認する責任があります。
-
クエリの効率的な実行計画を作成し、それを BYNET (メッセージ パッシング レイヤー) に送信します。
-
最後に、アクセス モジュール プロセッサからの出力を受け取り、クライアントに送り返します。
B. バイネット: BYNET は、解析エンジンと AMP 間の通信チャネルとして機能する Teradata のネットワーク レイヤーです。 以下の手順は、BYNET の機能を定義します。
-
メッセージ パッシング レイヤーは、解析エンジン (PE) から実行計画を受け取り、それを AMP に配信します。
-
次に、AMP によって生成された処理済みの出力を取得し、それを解析エンジンに転送します。
-
適切な可用性を維持するために、BYNET 0 と BYNET 1 という XNUMX つの BYNET が利用可能です。プライマリ BYNET に障害が発生した場合、セカンダリ BYNET は遅延なく適切に機能することを保証します。
C. アクセス モジュール プロセッサ (AMP): AMP は、レコードをディスクに格納する Teradata の仮想プロセッサです。 以下の手順では、AMP の機能を定義します。
-
解析エンジンからデータと実行計画を受け取り、並べ替え、集計、フィルタリングなどの結果の生成に関連する必要な変換を実行します。
-
AMP はデータベースの一部を管理し、データ ストレージ用にテーブル レコードを均等に分散します。
-
また、ロックおよびスペース管理も実行します。
主な機能に応じて、Teradata のアーキテクチャは次の XNUMX つの形式で認識されます。
-
ストレージアーキテクチャ
-
検索アーキテクチャ
Teradata ストレージ アーキテクチャ
クライアントがレコードを挿入するクエリを発行するたびに、解析エンジンがレコードを BYNET に送信します。 BYNET はレコードを受信するとすぐに、必要な行を取得し、挿入のためにターゲット AMP に送信します。 現在、AMP はレコード ストレージに使用できるディスクを持っているため、それらの行をディスクに保持し、ストレージ ユニットとして機能します。
Teradata 検索アーキテクチャ
Teradata システムがデータ取得のクライアント リクエストを受け取るたびに、解析エンジンはリクエストを BYNET に転送します。 次に、BYNET の仕事は、検索要求を適切な AMP に転送することです。 現在、AMP の仕事は、すべてのディスクからレコード検索を並行して実行し、見つかったレコードを BYNET に転送することです。BYNET は、解析エンジンの助けを借りてそれらをクライアントに送信します。
Teradata と Hadoop の違い
アーキテクチャ
Hadoopの:- Hadoop に続くアーキテクチャ タイプは、マスター スレーブ アーキテクチャであり、クラスタは単一のマスター ノードと複数のスレーブ ノードで構成されます。 Hadoop のアーキテクチャは、次のコンポーネントで構成されています。
-
HDFS: HDFS は、Hadoop アーキテクチャのストレージ ユニットである Hadoop Distributed File System の略です。
-
YARN: YARN は、Yet Another Resource Negotiator の略です。 リソース マネージャーとして機能し、システムで使用可能なリソースを割り当てます。
-
MapReduce: MapReduce は、作業を分割して出力を収集するエージェントとして機能します。
Teradata:- Teradata は、超並列処理 (MPP) システムに基づくシェアード ナッシング アーキテクチャに従います。 Teradata は、さまざまなクライアント アプリケーションから複数の同時または並列の要求を受け取ることができる単一のデータ ストアです。 Teradata は、BYNET、解析エンジン (PE)、AMP (アクセス モジュール プロセッサ)、および複数のノードなどのさまざまな要素で構成されています。
テクノロジー
ハドゥープ:- これは、Apache Software Foundation によって開発および維持されているオープン ソースのビッグ データ テクノロジ プラットフォームであり、比較的安価なコモディティ ハードウェアのスケーラブルなクラスター上で大量のデータとそのアプリケーションを保存および処理するために使用されます。 もともと Java で書かれたフレームワークで、Google の MapReduce や GFS(Google File System) の概念を利用しています。 これは、従来の技術ではあまりにも多様で急速に変化するデータを含むビッグデータの課題を解決するための最適化された方法です。
テラデータ:- Teradata は、さまざまなクライアント プラットフォームからの複数の同時ユーザーをサポートするアクティブなエンタープライズ データ ウェアハウスです。 Unix または Windows で実行できるオープン ソースのリレーショナル データベース管理システム (RDBMS) です。 効率的なパフォーマンスのための並列アーキテクトを提供し、優れたデータ ウェアハウジング ソリューションとして機能します。
データの種類
ハドゥープ:- Hadoop は、多くのデータ駆動型企業にとってよく知られているソリューションです。その理由は非常に単純です。さまざまなデータ タイプを処理および処理できるからです。 利用可能なすべてのデータから全体の値を簡単に抽出できます。 データの種類に関係なく、数百テラバイトのデータを安価に処理できます。 複数のオープンソース ツールを使用して、構造化データ、半構造化データ、さらには非構造化データを処理できます。 Teradata は予期しない非構造化データを処理するように設計されていないため、Hadoop は Teradata よりもさまざまなデータの処理に適しています。
テラデータ:- Teradata は単純なリレーショナル データ ウェアハウス ソリューションであり、「リレーショナル」という言葉だけで、構造化データに最適です。 その機能は、表形式のデータで利用可能な大量の構造化データを処理する機能であるため、半構造化データまたは非構造化データを保存および処理することはできません。 優れたパフォーマンスでスケーラビリティを提供し、100 つのシステムで 100 ギガバイトから XNUMX プラス ペタバイトを超えるデータまで拡張できます。
Teradata でのデータ操作
Teradata はデータ操作をサポートしており、簡単な SQL クエリを使用してレコードを挿入、削除、および更新できます。
A. レコードの挿入
RDBMS テーブルを作成するときはいつでも、最初のタスクは常にテーブル内にデータを配置することです。これを行うには、「INSERT INTO」ステートメントを使用できます。
構文:-
INSERT INTO
(coln1、coln2、coln3、…) 値 (v1、v2、v3…);
例:-
INSERT INTO Empl ( Eid, FName, LName, DOB, DOJ,Dept) VALUES ( 'E111', 'John', 'Kelvin', '10-11-1986', '25-12-2001',04);
B. 更新記録
テーブル内の既存のレコードを更新するには、「UPDATE…SET」ステートメントを使用できます。
構文:-
UPDATE
SET = [WHERE 条件];
例:-
UPDATE Empl SET Dept = 01 WHERE Eid = 'E111';
C. レコードの削除
テーブル内の既存のレコードを削除するには、「DELETE…FROM」ステートメントを使用できます。
構文:-
から削除
[WHERE 条件];
例:-
DELETE FROM Empl WHERE Eid = 'E111';
まとめ
Teradata は、表形式で保存された非常に重要な構造化データを処理するために多くの大手企業によって使用されている、非常に信頼性の高いテクノロジです。 絶えず変化する複雑なビジネス ニーズに対応できるリアルタイム データ ウェアハウス エンジンを使用します。 Teradata は、スケーラビリティ、高性能、および分析機能を提供することで有名です。 このブログから引き出された重要なポイントは次のとおりです。
1. Teradata は何を意味しますか?
2. ストレージと検索アーキテクチャを含む、Teradata の XNUMX 種類のアーキテクチャについて説明しました。
3. BYNET、AMP、および解析エンジンを含む Teradata コンポーネントも垣間見ました。
4. また、アーキテクチャ、テクノロジ、およびデータの種類に基づく Teradata と Hadoop の正確な違いについても説明しました。 ここでは、Teradata が多国籍企業の長期的な構造化データにどのように役立つかについて説明しました。
この記事に示されているメディアは Analytics Vidhya が所有するものではなく、著者の裁量で使用されています。
関連記事
- コインスマート。 ヨーロッパで最高のビットコインと暗号通貨取引所。ここをクリック
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.analyticsvidhya.com/blog/2022/11/understanding-the-concepts-of-teradata/

