
著者による画像
データは、情報に基づいた意思決定を促進し、人工知能ベースのアプリケーションを実現する上で重要な役割を果たします。その結果、さまざまな業界にわたって、熟練したデータ専門家の需要が高まっています。データ サイエンスの初心者向けに、この広範なガイドのコレクションは、膨大な量のデータから洞察を引き出すために必要な必須スキルの開発に役立つように設計されています。
リンク: データサイエンスのためのSQLをマスターするための7つのステップ

SQL をマスターするための段階的なアプローチであり、SQL コマンド、集計、グループ化、並べ替え、結合、サブクエリ、ウィンドウ関数の基本をカバーしています。
このガイドでは、要件を技術分析に変換することで現実のビジネス上の問題を解決するために SQL を使用することの重要性も強調しています。データ サイエンスの面接の練習と準備には、HackerRank や PGExercises などのオンライン プラットフォームを通じて SQL を練習することをお勧めします。
リンク: データサイエンスのためにPythonをマスターするための7つのステップ

このガイドでは、Python プログラミングを学習し、データ サイエンスと分析のキャリアに必要なスキルを開発するための段階的なロードマップを提供します。オンライン コースやコーディングの課題を通じて Python の基礎を学ぶことから始まります。次に、データ分析、機械学習、Web スクレイピングのための Python ライブラリについて説明します。
キャリア ガイドでは、プロジェクトを通じてコーディングを練習し、スキルを披露するオンライン ポートフォリオを構築することの重要性を強調しています。また、ステップごとに無料および有料のリソースの推奨事項も提供されます。
リンク: データのクリーニングと前処理のテクニックをマスターするための 7 つのステップ
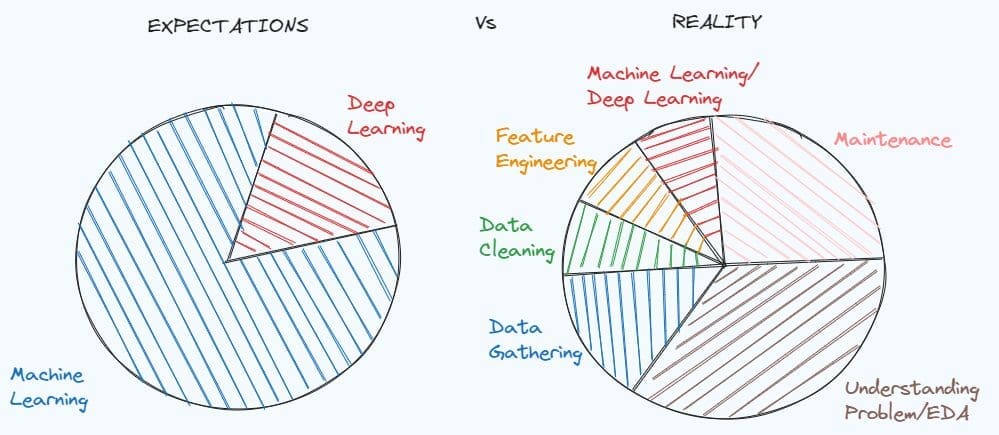
データ サイエンス プロジェクトに不可欠なデータ クリーニングと前処理のテクニックを習得するためのステップバイステップ ガイド。このガイドでは、探索的データ分析、欠損値の処理、重複と外れ値の処理、カテゴリ特徴のエンコード、データのトレーニング セットとテスト セットへの分割、特徴のスケーリング、分類問題における不均衡なデータの対処など、さまざまなトピックを取り上げています。
Pandas や scikit-learn などの Python ライブラリを使用したさまざまな前処理タスクのサンプル コードを利用して、問題ステートメントとデータを理解することの重要性を学びます。
リンク: Pandas と Python を使用したデータ ラングリングをマスターする 7 つのステップ

これは、パンダを使用したデータ ラングリングをマスターするための包括的な学習パスです。このガイドでは、Python の基礎、SQL、Web スクレイピングの学習などの前提条件について説明し、その後、さまざまなソースからのデータの読み込み、データフレームの選択とフィルター、データセットの探索とクリーンアップ、変換と集計の実行、データフレームの結合、ピボット テーブルの作成の手順が説明されています。最後に、Streamlit を使用してインタラクティブなデータ ダッシュボードを構築し、データ分析スキルを披露し、仕事の機会を求める意欲的なデータ アナリストにとって不可欠なプロジェクトのポートフォリオを作成することを提案しています。
リンク: 探索的データ分析をマスターするための 7 つのステップ
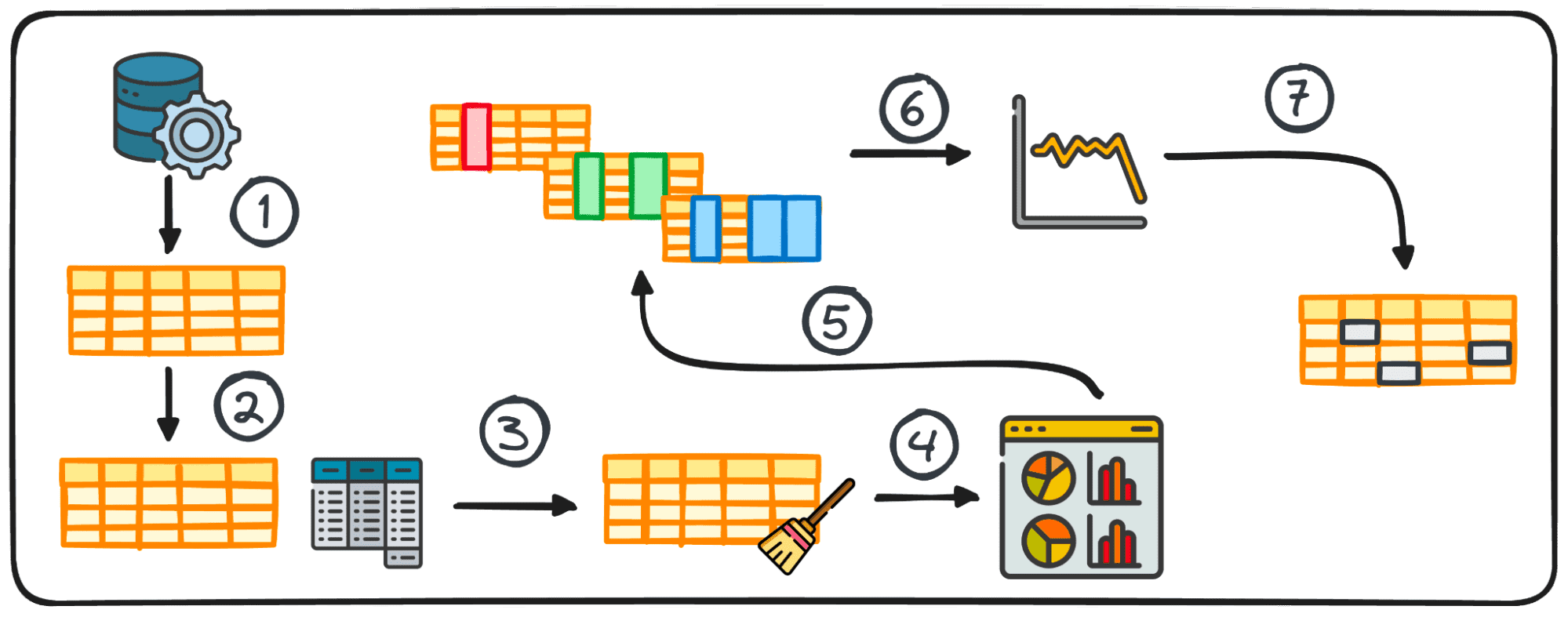
このガイドでは、Python を使用して効果的な探索的データ分析 (EDA) を実行するための 7 つの重要な手順について概説します。これらの手順には、データ収集、統計概要の生成、クリーニングと変換によるデータの準備、パターンと外れ値を特定するためのデータの視覚化、変数の一変量、二変量、および多変量分析の実行、時系列データの分析、欠損値と外れ値の処理が含まれます。 EDA はデータ分析における重要なフェーズであり、専門家がデータの品質、構造、関係を理解し、後続の段階での正確で洞察に満ちた分析を保証できるようにします。
データ サイエンスへの取り組みを始めるには、SQL をマスターすることから始めることをお勧めします。これにより、データベースを効率的に操作できるようになります。 SQL に慣れたら、データ分析用の強力なライブラリが付属する Python プログラミングに取り組むことができます。データ クリーニングなどの基本的なテクニックを学ぶことは、高品質のデータセットを維持するのに役立つため重要です。
次に、パンダを使用したデータ ラングリングの専門知識を取得して、データを再形成して準備します。最も重要なのは、探索的データ分析をマスターして、データセットを徹底的に理解し、洞察を明らかにすることです。
これらのガイドラインに従った後の次のステップは、プロジェクトに取り組んで経験を積むことです。単純なプロジェクトから始めて、より複雑なプロジェクトに進むことができます。 Medium にそれについて書いて、スキルを向上させるための最新のテクニックについて学びましょう。
アビッド・アリ・アワン (@ 1abidaliawan) は、機械学習モデルの構築を愛する認定データ サイエンティストのプロフェッショナルです。現在はコンテンツ制作に注力し、機械学習やデータサイエンス技術に関する技術ブログを執筆している。アビッドは、テクノロジー管理の修士号と電気通信工学の学士号を取得しています。彼のビジョンは、精神疾患に苦しむ学生のためにグラフ ニューラル ネットワークを使用して AI 製品を構築することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis?utm_source=rss&utm_medium=rss&utm_campaign=collection-of-guides-on-mastering-sql-python-data-cleaning-data-wrangling-and-exploratory-data-analysis

