概要
一部のデータ構造は汎用性があり、幅広いアプリケーションで使用できますが、その他のデータ構造は特殊化され、特定の問題を処理するように設計されています。 そのような特殊な構造の XNUMX つは、シンプルでありながら驚くべき実用性で知られています。 スタック.
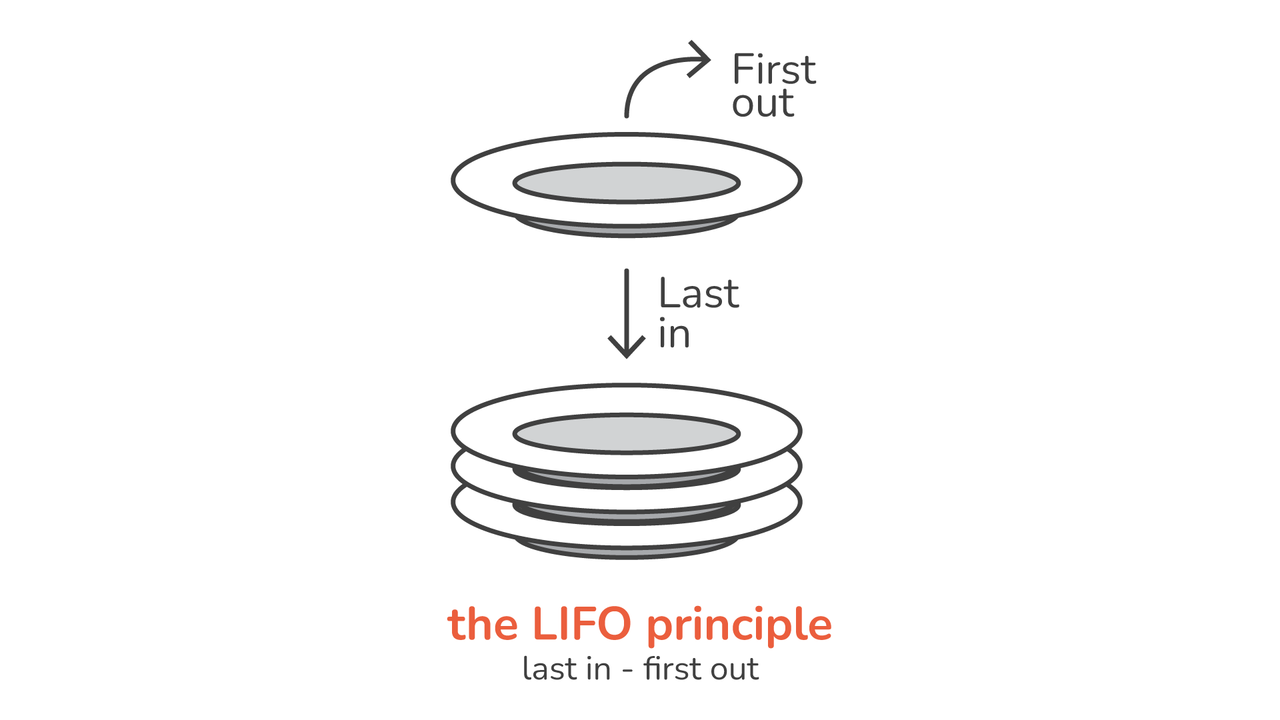
では、スタックとは何でしょうか? スタックの核心は、次の線形データ構造です。 LIFO (後入れ先出し) 原則。 これをカフェテリアにある皿の山と考えてください。 一番上にあるプレートのみを取得し、新しいプレートを配置するときは、それがスタックの一番上に移動します。
最後に追加された要素が最初に削除される要素になります
しかし、なぜスタックを理解することが重要なのでしょうか? 長年にわたり、スタックは、お気に入りのプログラミング言語でのメモリ管理から Web ブラウザの「戻る」ボタン機能に至るまで、さまざまな分野で応用されてきました。 この本質的なシンプルさとその広範な応用性により、スタックは開発者の武器庫に不可欠なツールとなっています。
このガイドでは、スタックの背後にある概念、その実装、ユースケースなどについて詳しく説明します。 スタックとは何か、スタックがどのように機能するかを定義し、Python でスタック データ構造を実装する最も一般的な XNUMX つの方法を見ていきます。
スタックデータ構造の基本概念
本質的に、スタックは一見単純ですが、計算領域で多用途のアプリケーションを可能にする微妙なニュアンスを持っています。 その実装と実際の使用法に入る前に、スタックを取り巻く中心となる概念をしっかりと理解しておきましょう。
LIFO (後入れ先出し) の原則
LIFO がスタックの背後にある基本原則です。 これは、スタックに最後に入る項目が最初にスタックから出る項目であることを意味します。 この特性により、スタックはキューなどの他の線形データ構造と区別されます。
注: スタックがどのように機能するのかという概念を理解するのに役立つもう XNUMX つの例は、人々がスタックに出入りするところを想像することです。 エレベーター – エレベーターに最後に乗った人が最初に降りるのです。
基本操作
すべてのデータ構造は、それがサポートする操作によって定義されます。 スタックの場合、次の操作は簡単ですが重要です。
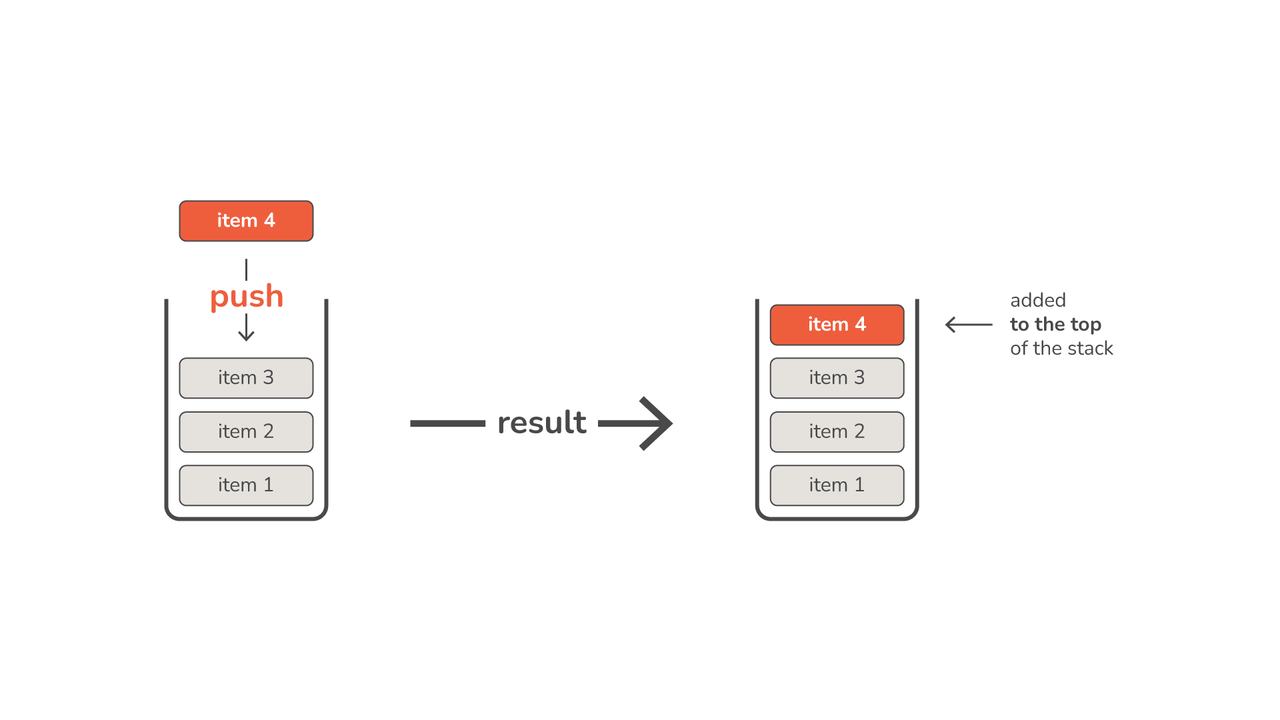
- プッシュ – 要素をスタックの先頭に追加します。 スタックがいっぱいの場合、この操作によりスタック オーバーフローが発生する可能性があります。
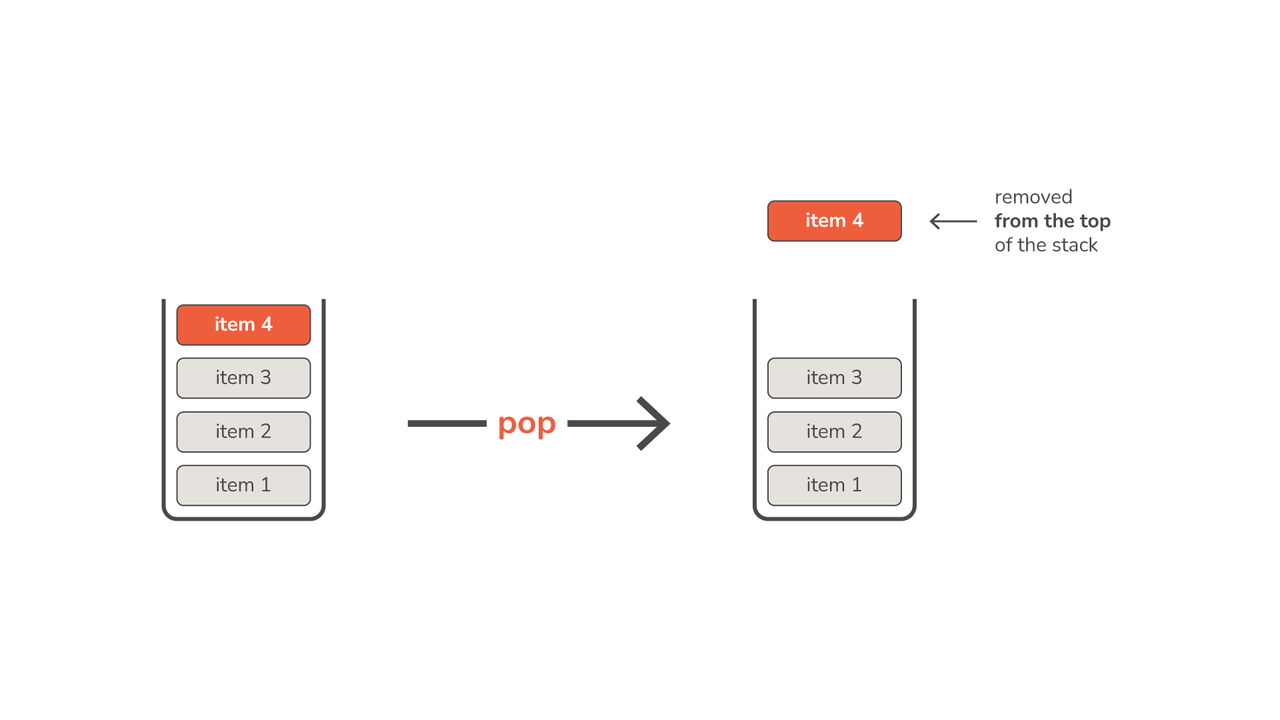
- ポップ – スタックの最上位の要素を削除して返します。 スタックが空の場合、ポップを試みるとスタックのアンダーフローが発生する可能性があります。
- ピーク (またはトップ) – 最上位の要素を削除せずに観察します。 この操作は、スタックの状態を変更せずに現在の最上位要素を検査したい場合に便利です。
ここまでで、スタック データ構造の重要性とその基本概念が明らかになったはずです。 先に進むにつれて、その実装を詳しく見ていき、これらの基本原則が実際のコードにどのように変換されるかを明らかにしていきます。
Python でスタックを最初から実装する方法
スタックの背後にある基本原則を理解したら、今度は袖をまくって、物事の実践的な側面を詳しく掘り下げてみましょう。 スタックの実装は簡単ですが、複数の方法でアプローチできます。 このセクションでは、スタックを実装する XNUMX つの主な方法、つまり配列とリンク リストを使用する方法について説明します。
配列を使用したスタックの実装
配列 連続したメモリ位置は、スタックを表す直感的な手段を提供します。 これらにより、インデックスによる要素へのアクセスの複雑さが O(1) に抑えられ、迅速なプッシュ、ポップ、ピーク操作が保証されます。 また、配列ではリンク リストのようなポインターのオーバーヘッドがないため、メモリ効率が向上します。
一方、従来の配列のサイズは固定されており、一度初期化されるとサイズを変更できません。 これにより、次のような問題が発生する可能性があります。 スタックオーバーフロー 監視されていない場合。 これは動的配列 (Python のような) によって克服できます。 list)、サイズを変更できますが、この操作にはかなりのコストがかかります。
以上で、Python で配列を使用してスタック クラスの実装を開始しましょう。 まず、スタックのサイズをパラメーターとして受け取るコンストラクターを使用して、クラス自体を作成しましょう。
class Stack: def __init__(self, size): self.size = size self.stack = [None] * size self.top = -1
ご覧のとおり、クラスに XNUMX つの値を保存しました。 の size はスタックの希望のサイズです。 stack はスタック データ構造を表すために使用される実際の配列です。 top の最後の要素のインデックスです。 stack 配列 (スタックの最上位)。
ここからは、基本的なスタック操作ごとに XNUMX つのメソッドを作成して説明します。 これらの各メソッドは、 Stack 作成したばかりのクラス。
まずは push() 方法。 前に説明したように、プッシュ操作ではスタックの先頭に要素が追加されます。 まず最初に、追加したい要素を配置できるスペースがスタックに残っているかどうかを確認します。 スタックがいっぱいの場合は、 Stack Overflow 例外。 それ以外の場合は、要素を追加して調整します。 top & stack それに応じて:
def push(self, item): if self.top == self.size - 1: raise Exception("Stack Overflow") self.top += 1 self.stack[self.top] = item
これで、スタックの最上位から要素を削除するメソッドを定義できます。 pop() 方法。 空のスタックから要素をポップしようとしても意味がないため、要素を削除する前に、スタックに要素があるかどうかを確認する必要があります。
def pop(self): if self.top == -1: raise Exception("Stack Underflow") item = self.stack[self.top] self.top -= 1 return item
最後に、次のように定義できます。 peek() 現在スタックの一番上にある要素の値を返すだけのメソッド:
def peek(self): if self.top == -1: raise Exception("Stack is empty") return self.stack[self.top]
以上です! これで、Python のリストを使用してスタックの動作を実装するクラスができました。
リンクされたリストを使用したスタックの実装
リンクされたリスト 動的データ構造、簡単に拡大および縮小できるため、スタックの実装には有益です。 リンク リストは必要に応じてメモリを割り当てるため、明示的なサイズ変更を必要とせずにスタックを動的に拡大および縮小できます。 リンク リストを使用してスタックを実装することのもう XNUMX つの利点は、プッシュ操作とポップ操作に必要なのは単純なポインターの変更だけであることです。 その欠点は、リンクされたリストのすべての要素に追加のポインターがあり、配列と比較してより多くのメモリを消費することです。
すでに説明したように、 「Python リンクリスト」 この記事を参照すると、実際のリンク リストを作成する前に最初に実装する必要があるのは、単一ノードのクラスです。
class Node: def __init__(self, data): self.data = data self.next = None
ベストプラクティス、業界で認められた標準、および含まれているチートシートを含む、Gitを学習するための実践的で実用的なガイドを確認してください。 グーグルGitコマンドを停止し、実際に 学ぶ それ!
この実装では、ノードに格納される値 (data) と次のノードへの参照 (next).
Python のリンク リストに関する 3 部構成のシリーズ:
これで、実際のスタック クラス自体にジャンプできるようになりました。 コンストラクターは以前のものとは少し異なります。 これには変数が XNUMX つだけ含まれます。これは、スタックの最上位にあるノードへの参照です。
class Stack: def __init__(self): self.top = None
予想通り、 push() メソッドは、新しい要素 (この場合はノード) をスタックの先頭に追加します。
def push(self, item): node = Node(item) if self.top: node.next = self.top self.top = node
pop() このメソッドはスタック内に要素があるかどうかを確認し、スタックが空でない場合は最上位の要素を削除します。
def pop(self): if not self.top: raise Exception("Stack Underflow") item = self.top.data self.top = self.top.next return item
最後に、 peek() このメソッドは、スタックの最上位 (存在する場合) から要素の値を読み取るだけです。
def peek(self): if not self.top: raise Exception("Stack is empty") return self.top.data
注: 両方のインターフェイス Stack クラスは同じです。唯一の違いは、クラス メソッドの内部実装です。 つまり、クラスの内部を心配することなく、異なる実装を簡単に切り替えることができます。
配列とリンク リストのどちらを選択するかは、アプリケーションの特定の要件と制約によって異なります。
Python の組み込み構造を使用してスタックを実装する方法
多くの開発者にとって、スタックを最初から構築することは、教育的ではありますが、実際のアプリケーションでスタックを使用する最も効率的な方法ではない可能性があります。 幸いなことに、一般的なプログラミング言語の多くには、スタック操作を自然にサポートする組み込みのデータ構造とクラスが備わっています。 このセクションでは、この点に関する Python の機能について説明します。
Python は多用途かつ動的言語であるため、専用のスタック クラスがありません。 ただし、その組み込みデータ構造、特にリストと deque クラスは、 collections モジュールはスタックとして簡単に機能します。
Python リストをスタックとして使用する
Python リストは、その動的な性質と次のようなメソッドの存在により、スタックを非常に効果的にエミュレートできます。 append() & pop().
-
押し込み操作 – スタックの先頭に要素を追加するのは、
append()方法:stack = [] stack.append('A') stack.append('B') -
ポップ操作 – 最上位の要素を削除するには、
pop()引数のないメソッド:top_element = stack.pop() -
ピーク操作 ポップせずに先頭にアクセスするには、負のインデックスを使用します。
top_element = stack[-1]
使い方 両端キュー からのクラス コレクション モジュール
deque (double-ended queue の略) クラスは、スタック実装のためのもう XNUMX つの多用途ツールです。 両端からの高速な追加とポップのために最適化されており、リストよりもスタック操作の方がわずかに効率的です。
-
初期化:
from collections import deque stack = deque() -
押し込み操作 – リストと同様に、
append()メソッドが使用されます:stack.append('A') stack.append('B') -
ポップ操作 – リストのように、
pop()メソッドは次の仕事をします。top_element = stack.pop() -
ピーク操作 – アプローチはリストの場合と同じです。
top_element = stack[-1]
いつどちらを使用するか?
リストと両端キューの両方をスタックとして使用できますが、主に構造体をスタックとして使用している場合 (一方の端から追加とポップを行う)、 deque 最適化により若干高速になる可能性があります。 ただし、ほとんどの実用的な目的では、パフォーマンスが重要なアプリケーションを扱う場合を除き、Python のリストで十分です。
注: このセクションでは、スタックのような動作を実現する Python の組み込み機能について詳しく説明します。 このような強力なツールをすぐに使える場合、必ずしも車輪の再発明 (スタックを最初から実装すること) を行う必要はありません。
スタック関連の潜在的な問題とその解決方法
スタックは他のデータ構造と同様に非常に多用途で効率的ですが、潜在的な落とし穴の影響を受けないわけではありません。 スタックを扱う際にはこれらの課題を認識し、それに対処するための戦略を立てることが重要です。 このセクションでは、スタック関連の一般的な問題をいくつか取り上げ、それらを克服する方法を検討します。
スタックオーバーフロー
これは、最大容量に達したスタックに要素をプッシュしようとしたときに発生します。 これは、特定の低レベル プログラミング シナリオや再帰関数呼び出しなど、スタック サイズが固定されている環境で特に問題になります。
配列ベースのスタックを使用している場合は、サイズが自動的に変更される動的配列またはリンク リストの実装に切り替えることを検討してください。 スタック オーバーフローを防ぐもう XNUMX つの手順は、特にプッシュ操作の前にスタックのサイズを継続的に監視し、スタック オーバーフローに関する明確なエラー メッセージまたはプロンプトを提供することです。
過剰な再帰呼び出しによってスタック オーバーフローが発生した場合は、反復的な解決策を検討するか、環境が許せば再帰制限を増やしてください。
スタックアンダーフロー
これは、空のスタックから要素をポップしようとしたときに発生します。 これを防ぐには、ポップまたはピーク操作を実行する前にスタックが空かどうかを必ず確認してください。 明確なエラー メッセージを返すか、プログラムをクラッシュさせることなくアンダーフローを適切に処理します。
それが許容される環境では、空のスタックからポップするときに、操作が無効であることを示す特別な値を返すことを検討してください。
メモリの制約
メモリに制約のある環境では、スタック (リンク リストに基づくスタックなど) のサイズを動的に変更しても、スタックが大きくなりすぎるとメモリが枯渇する可能性があります。 したがって、アプリケーションの全体的なメモリ使用量とスタックの増加に注意してください。 おそらくスタックのサイズにソフトキャップを導入するでしょう。
スレッドの安全性に関する懸念
マルチスレッド環境では、異なるスレッドによる共有スタック上での同時操作により、データの不整合や予期しない動作が発生する可能性があります。 この問題に対する考えられる解決策は次のとおりです。
- ミューテックスとロック – ミューテックス (相互排他オブジェクト) またはロックを使用して、特定の時点で XNUMX つのスレッドのみがスタック上で操作を実行できるようにします。
- 不可分操作 – 環境でサポートされている場合は、アトミック操作を活用して、プッシュおよびポップ操作中のデータの一貫性を確保します。
- スレッドローカルスタック – 各スレッドがスタックを必要とするシナリオでは、スレッドローカル ストレージを使用して各スレッドに個別のスタック インスタンスを与えることを検討してください。
スタックは確かに強力ですが、その潜在的な問題を認識し、ソリューションを積極的に実装することで、堅牢でエラーのないアプリケーションが保証されます。 これらの落とし穴を認識することが戦いの半分であり、残りの半分はそれらに効果的に対処するためのベスト プラクティスを採用することです。
まとめ
スタックは、一見単純な性質のように見えますが、コンピューティングの世界における多くの基本的な操作を支えています。 複雑な数式の解析から関数呼び出しの管理まで、その有用性は幅広く、不可欠です。 このデータ構造を隅々まで調べてみると、その強みは効率性だけでなく、汎用性にもあることが明らかです。
ただし、他のツールと同様に、その有効性は使用方法によって異なります。 スタックの真の力を確実に活用できるように、その原則、潜在的な落とし穴、ベスト プラクティスを十分に理解してください。 ゼロから実装する場合でも、Python などの言語の組み込み機能を利用する場合でも、ソリューションを際立たせるのは、これらのデータ構造を注意深く適用することです。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://stackabuse.com/guide-to-stacks-in-python/

