デジタルはニューノーマルであり、後戻りはできません。 毎年、消費者はユーザー名とパスワードを必要とする平均 191 の Web サイトまたはサービスにアクセスしており、デジタル フットプリントは指数関数的に増加すると予想されます。 露出が多すぎると、当然、アカウントの乗っ取り (ATO) などの追加のリスクが生じます。
毎年、悪意のある人物が、盗まれた認証情報、フィッシング、ソーシャル エンジニアリング、および複数の形式の ATO を通じて、何十億ものアカウントを侵害しています。 概観すると、アカウント乗っ取り詐欺は 90 年と比較して 11.4 年に 2021% 増加し、推定 2020 億ドルに達しました。ATO は、財務上の影響を超えて、顧客体験を損ない、ブランドの忠誠心と評判を脅かし、チャージバックを管理する詐欺チームに負担をかけます。顧客の主張。
多くの企業は、洗練された詐欺チームを擁する企業であっても、侵害されたアカウントを検出するためにルールベースのソリューションを使用しています。これは、作成が簡単であるためです。 防御を強化し、正当なユーザーの摩擦を軽減するために、企業は AI と機械学習 (ML) への投資を増やして、アカウントの乗っ取りを検出しています。
AWS は、次のようなソリューションを使用して不正行為の軽減を改善するのに役立ちます アマゾン詐欺検出器. この完全に管理された AI サービスを使用すると、ML の専門知識がなくてもカスタム ML 不正検出モデルをトレーニングできるため、潜在的に不正なオンライン アクティビティを特定できます。
この投稿では、Amazon Fraud Detector の新しい Account Takeover Insights (ATI) モデルを使用してリアルタイム検出器エンドポイントを作成する方法について説明します。
ソリューションの概要
Amazon Fraud Detector は、調整されたアルゴリズム、エンリッチメント、機能変換を備えた特定のモデルに依存して、複数のユースケースで不正なイベントを検出します。 新たに開始された ATI モデルは、侵害された可能性のあるアカウントと ATO 詐欺を検出するように設計された、低レイテンシーの詐欺検出 ML モデルです。 ATI モデルは、従来のルールベースのアカウント乗っ取りソリューションよりも最大 XNUMX 倍多くの ATO 詐欺を検出し、正当なユーザーの摩擦のレベルを最小限に抑えます。
ATI モデルは、ビジネスの過去のログイン イベントを含むデータセットを使用してトレーニングされます。 ATI モデルは教師なし学習に革新的なアプローチを使用しているため、モデル トレーニングのイベント ラベルはオプションです。 このモデルは、実際のアカウント所有者によって生成されたイベント (正当なイベント) と悪意のある人物によって生成されたイベント (異常なイベント) を区別します。
Amazon Fraud Detector は、提供されたデータを継続的に集計することにより、ユーザーの過去の行動を導き出します。 ユーザーの行動の例には、ユーザーが特定の IP アドレスからサインインした回数が含まれます。 これらの追加のエンリッチメントと集計により、Amazon Fraud Detector は、ログイン イベントからの小さな入力セットから強力なモデル パフォーマンスを生成できます。
リアルタイム予測の場合は、 GetEventPrediction ATO のリスクを定量化するために、ユーザーが有効なログイン資格情報を提示した後の API。 応答として、0 ~ 1000 のモデル スコア (0 は不正リスクが低いことを示し、1000 は不正リスクが高いことを示します) と、定義した一連のビジネス ルールに基づく結果を受け取ります。 次に、ログインを承認する、ログインを拒否する、または追加の身元確認を強制してユーザーにチャレンジするなど、適切なアクションを実行できます。
また、ATI モデルを使用して、アカウント ログインを非同期に評価し、その結果に基づいてアクションを実行することもできます。たとえば、アカウントを調査キューに追加して、人間のレビュー担当者がさらにアクションを実行する必要があるかどうかを判断できるようにします。
次の手順は、ATI モデルをトレーニングし、検出器エンドポイントを公開して不正予測を生成するプロセスの概要を示しています。
- データを準備して検証します。
- エンティティ、イベント、イベント変数、およびイベント ラベルを定義します (オプション)。
- イベントデータをアップロードします。
- モデルのトレーニングを開始します。
- モデルを評価します。
- 検出エンドポイントを作成し、ビジネス ルールを定義します。
- リアルタイムの予測を取得します。
前提条件
開始する前に、次の前提条件の手順を完了します。
データの準備と検証
Amazon Fraud Detector では、UTF-8 形式でエンコードされた CSV ファイルでユーザー アカウントのログイン データを提供する必要があります。 ATI の場合、CSV ファイルのヘッダー行に特定のイベント メタデータとイベント変数を指定する必要があります。
必要なイベント メタデータは次のとおりです。
- イベント_ID – ログイン イベントの一意の識別子。
- ENTITY_TYPE – マーチャントや顧客など、ログイン イベントを実行するエンティティ。
- ENTITY_ID – ログイン イベントを実行するエンティティの識別子。
- EVENT_TIMESTAMP – ログイン イベントが発生したときのタイムスタンプ。 タイムスタンプの形式は、UTC の ISO 8601 標準である必要があります。
- EVENT_LABEL (オプション) – イベントを不正または合法として分類するラベル。 不正、合法、1、0 など、任意のラベルを使用できます。
イベント メタデータは大文字にする必要があります。 ログイン イベントにはラベルは必要ありません。 ただし、含めることをお勧めします。 EVENT_LABEL メタデータと、利用可能な場合はログイン イベントのラベルを提供します。 ラベルを提供すると、Amazon Fraud Detector はそれらを使用してアカウント乗っ取り検出率を自動的に計算し、モデルのパフォーマンスメトリクスに表示します。
ATI モデルには、必須変数とオプション変数の両方があります。 イベント変数名は小文字にする必要があります。
次の表は、必須の変数をまとめたものです。
| カテゴリー | 可変型 | 説明 |
|---|---|---|
| IPアドレス | IP_ADDRESS |
ログイン イベントで使用される IP アドレス |
| ブラウザとデバイス | USERAGENT |
ログイン イベントで使用されたブラウザ、デバイス、および OS |
| 有効な資格情報 | VALIDCRED |
ログインに使用された資格証明が有効かどうかを示します |
次の表は、オプションの変数をまとめたものです。
| カテゴリー | タイプ | 説明 |
|---|---|---|
| ブラウザとデバイス | FINGERPRINT |
ブラウザまたはデバイスのフィンガープリントの一意の識別子 |
| セッションID | SESSION_ID |
認証セッションの識別子 |
| ラベル | EVENT_LABEL |
イベントを不正または合法として分類するラベル ( fraud, legit, 1または 0) |
| スタンプ | LABEL_TIMESTAMP |
ラベルが最後に更新されたときのタイムスタンプ。 これは必要です EVENT_LABEL 供給される |
追加の変数を指定できます。 ただし、Amazon Fraud Detector には、ATI モデルをトレーニングするためのこれらの変数は含まれません。
データセットの準備
ログイン データの準備を開始するときは、次の要件を満たす必要があります。
- 少なくとも 1,500 のエンティティ (個々のユーザー アカウント) を提供し、それぞれに少なくとも XNUMX つのログイン イベントが関連付けられている
- データセットは少なくとも 30 日間のログイン イベントをカバーする必要があります
次の構成はオプションです。
- データセットには、失敗したログイン イベントの例を含めることができます
- オプションで、これらの失敗したログインに次のラベルを付けることができます。
fraudulentorlegitimate - 6 か月以上にわたるログイン イベントの履歴データを準備し、100,000 エンティティを含めることができます
我々は サンプルデータセット 開始するために使用できるテスト目的で。
データ検証
ATI モデルを作成する前に、Amazon Fraud Detector は、モデルをトレーニングするためにデータセットに含めたメタデータと変数がサイズと形式の要件を満たしているかどうかを確認します。 詳細については、次を参照してください。 データセットの検証. データセットが検証に合格しない場合、モデルは作成されません。 一般的なデータセット エラーの詳細については、次を参照してください。 一般的なイベント データセット エラー.
エンティティ、イベント タイプ、およびイベント変数を定義する
このセクションでは、エンティティ、イベント タイプ、およびイベント変数を作成する手順について説明します。 オプションで、イベント ラベルを定義することもできます。
エンティティを定義する
エンティティ 誰がイベントを実行しているかを定義します。 エンティティを作成するには、次の手順を実行します。
- Amazon Fraud Detectorコンソールのナビゲーションペインで、[ エンティティ.
- 選択する 創造する.
- エンティティ名とオプションの説明を入力します。
- 選択する エンティティを作成する.
イベントとイベント変数を定義する
イベントとは、不正リスクについて評価されるビジネス活動です。 このイベントは、作成したばかりのエンティティによって実行されます。 イベントタイプは、Amazon Fraud Detector に送信されるイベントの構造を定義します。これには、イベントの変数、イベントを実行するエンティティ、および可能な場合はイベントを分類するラベルが含まれます。
イベントを作成するには、次の手順を実行します。
- Amazon Fraud Detectorコンソールのナビゲーションペインで、[ イベント .
- 選択する 創造する.
- 名前 で、イベント タイプの名前を入力します。
- エンティティで、前の手順で作成したエンティティを選択します。
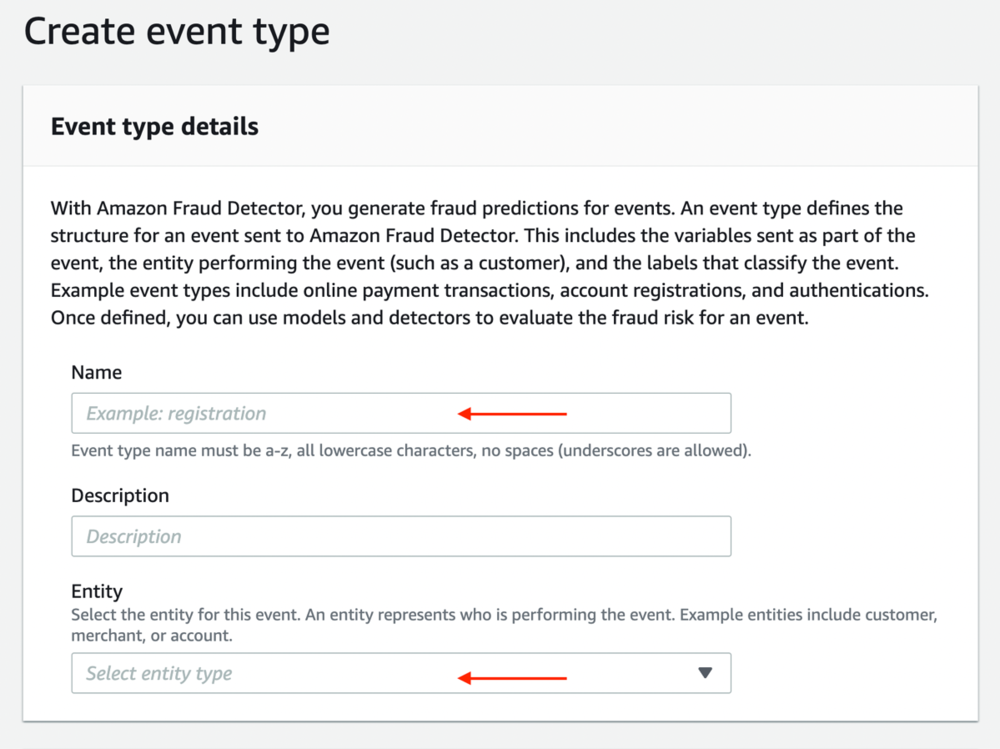
イベント変数を定義する
イベント変数の場合、次の手順を完了します。
- IAM ロール セクションを作成するで、トレーニング データをアップロードした特定のバケット名を入力します。
S3 バケットの名前は、データセットをアップロードした名前にする必要があります。 そうしないと、アクセス拒否の例外エラーが発生します。 - 選択する 役割を作成する.

- データの場所、トレーニング データへのパスを入力します。パスは、前提条件の手順でコピーした S3 URI です。 アップロード.
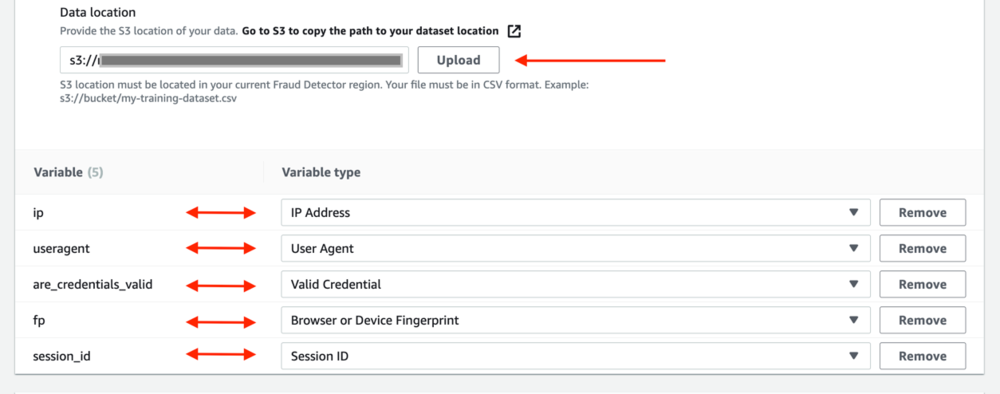
Amazon Fraud Detector は、トレーニング データセットからヘッダーを抽出し、各ヘッダーの変数を作成します。 変数が正しい変数タイプに割り当てられていることを確認してください。 モデルトレーニングプロセスの一環として、Amazon Fraud Detector は変数に関連付けられた変数タイプを使用して、変数の強化と機能エンジニアリングを実行します。 変数の型の詳細については、を参照してください。 変数の種類.
イベント ラベルの定義 (オプション)
ラベルは、個々のイベントを不正または正当として分類するために使用されます。 ATI モデルは教師なし学習に革新的なアプローチを使用しているため、モデル トレーニングのイベント ラベルはオプションです。 このモデルは、実際のアカウント所有者によって生成されたイベント (正当なイベント) と、攻撃者によって生成されたイベント (異常なイベント) を区別します。 含めることをお勧めします EVENT_LABEL メタデータを取得し、利用可能な場合はログイン イベントのラベルを提供します。 ラベルを提供すると、Amazon Fraud Detector はそれらを使用してアカウント乗っ取り検出率を自動的に計算し、モデルのパフォーマンスメトリクスに表示します。
イベントを作成するには、次の手順を実行します。
- 1 つのラベルを定義します (この投稿では、0 と XNUMX)。
- 選択する イベントタイプを作成する.

イベントデータをアップロードする
このセッションでは、モデル トレーニングのためにイベント データをサービスにアップロードする手順について説明します。
ATI モデルは、Amazon Fraud Detector に内部的に保存されたデータセットでトレーニングされます。 イベントデータを Amazon Fraud Detector に保存することで、自動計算された変数を使用してパフォーマンスを向上させ、モデルの再トレーニングを簡素化し、不正ラベルを更新して機械学習のフィードバックループを閉じるモデルをトレーニングできます。 見る 保存されたイベント Amazon Fraud Detector を使用してイベント データセットを保存する方法の詳細については、こちらをご覧ください。
イベントを定義したら、に移動します 保存されたイベント タブ。 に 保存されたイベント タブでは、保存されているイベントの数やデータセットの合計サイズ (MB) など、データセットに関する情報を確認できます。 このイベント タイプを作成したばかりなので、保存されたイベントはまだありません。 このページでは、イベントの取り込みをオンまたはオフにすることができます。 イベントの取り込みがオンになっている場合、履歴イベント データを Amazon Fraud Detector にアップロードし、予測からのイベント データをリアルタイムで自動的に保存できます。
履歴データを保存する最も簡単な方法は、CSV ファイルをアップロードしてイベントをインポートすることです。 または、データを Amazon Fraud Detector にストリーミングすることもできます。 SendEvent API( GitHubリポジトリ サンプル ノート用)。 イベントを CSV ファイルからインポートするには、次の手順を実行します。
- イベントデータのインポート、選択する 新規インポート.
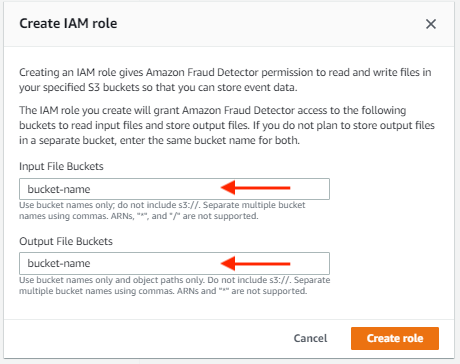
新しい IAM ロールを作成する必要がある可能性があります。 イベントのインポート機能には、Amazon S3 への読み取りアクセスと書き込みアクセスの両方が必要です。

- 新しい IAM ロールを作成し、入力ファイルと出力ファイル用の S3 バケットを提供します。
作成した IAM ロールは、Amazon Fraud Detector にこれらのバケットへのアクセスを許可し、入力ファイルを読み取り、出力ファイルを保存します。 出力ファイルを別のバケットに保存する予定がない場合は、両方に同じバケット名を入力してください。 - 選択する 役割を作成する.
- イベント データを含む CSV ファイルの場所を入力します。 これは、前にコピーした S3 URI である必要があります。
- 選んだ 開始 イベントのインポートを開始します。
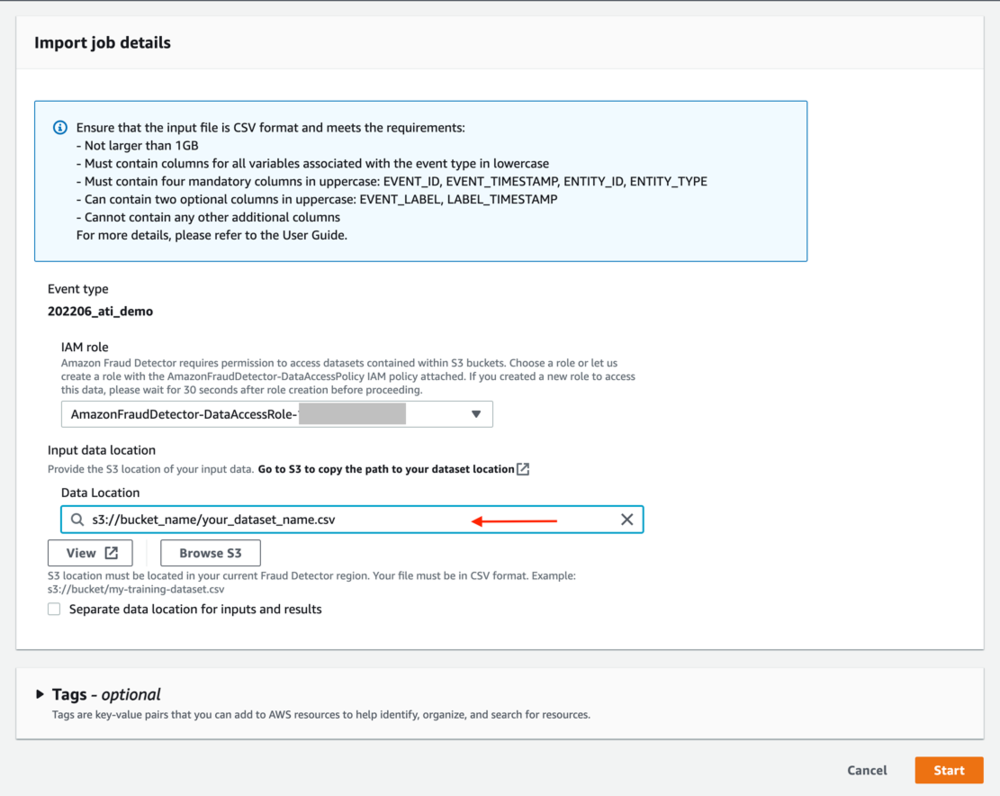
インポート時間は、インポートするイベントの数によって異なります。 20,000 件のイベントを含むデータセットの場合、このプロセスには約 12 分かかります。ページを更新すると、ステータスが次のように変わります。 Completed. ステータスが Errorで、インポートが失敗した理由を示すジョブ名を選択します。
モデルトレーニングを開始する
イベントを正常にインポートすると、モデルのトレーニングを開始するためのすべての要素が揃います。 モデルをトレーニングするには、次の手順を実行します。
- Amazon Fraud Detectorコンソールのナビゲーションペインで、[ Models.
- 選択する モデルを追加 をクリックして モデルを作成する.
- モデル名、モデルの希望の名前を入力します
- モデルタイプ選択 テイクオーバー アカウント インサイト.
- イベントタイプで、前に作成したイベント タイプを選択します。
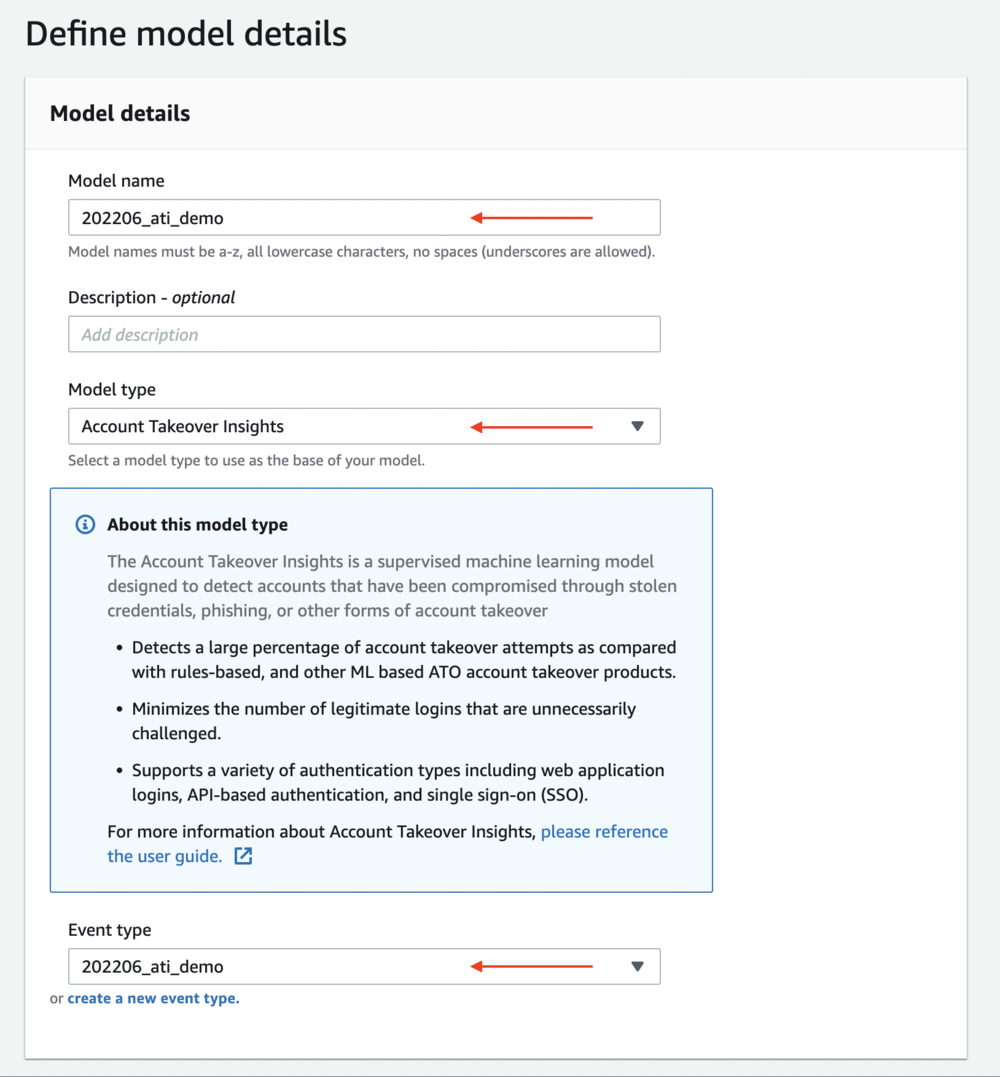
- 過去のイベントデータ、必要に応じてモデルをトレーニングするイベントの日付範囲を指定できます。
- 選択する Next.

- この記事では、モデルへの入力として使用される変数を特定してトレーニングを構成します。
- 変数を評価した後、 Next.
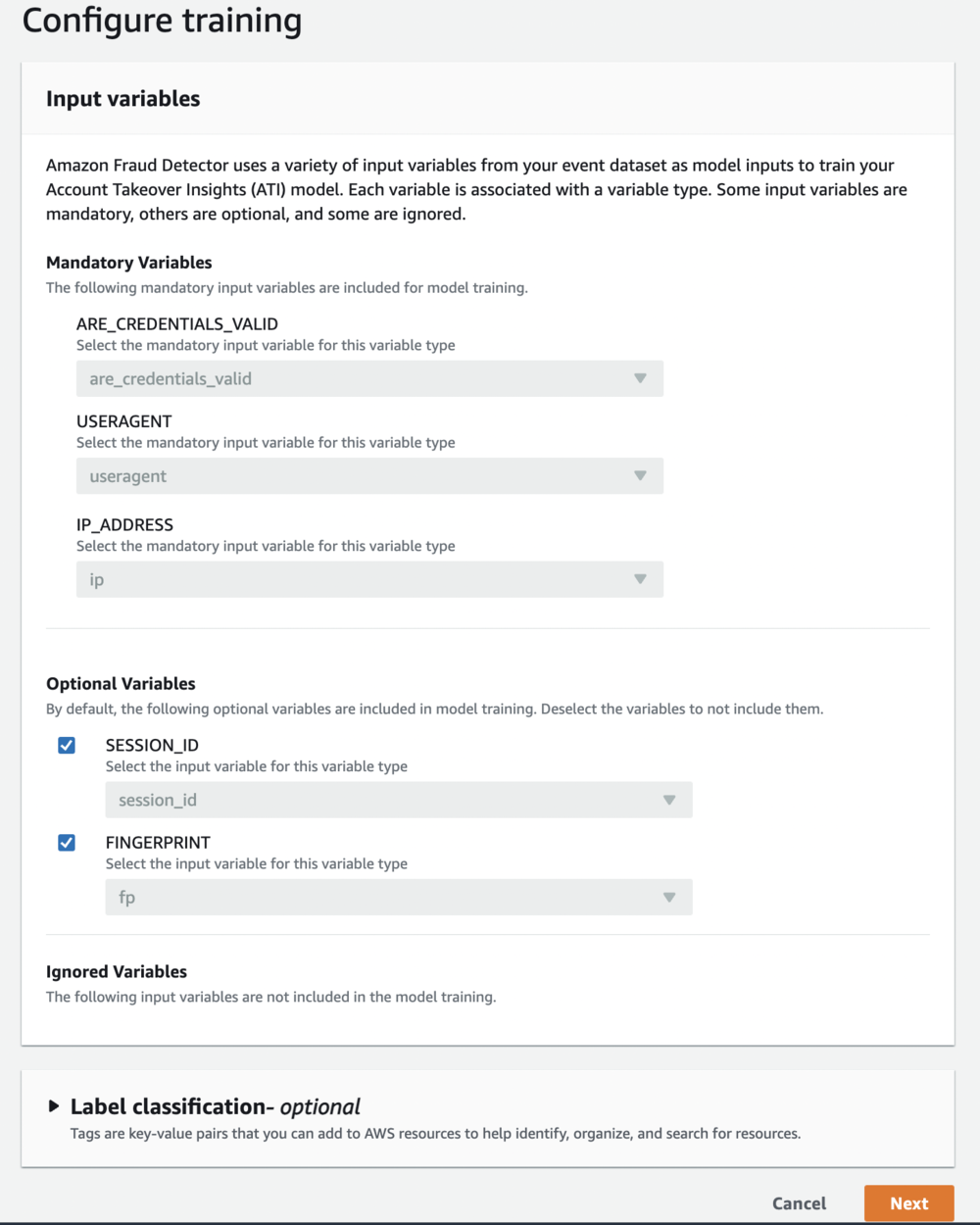
モデルに対する変数の値が不明な場合でも、使用可能なすべての変数を含めることをお勧めします。 モデルがトレーニングされると、Amazon Fraud Detector はモデルのパフォーマンスに対する各変数の影響のランク付けされたリストを提供するため、将来のモデル トレーニングにその変数を含めるかどうかを知ることができます。 ラベルが提供されている場合、Amazon Fraud Detector はそれらを使用して、モデルの検出率に関してモデルのパフォーマンスを評価および表示します。
ラベルが提供されていない場合、Amazon Fraud Detector はネガティブ サンプリングを使用して、モデルが正当な活動と不正な活動を区別するのに役立つ例または類似のログイン試行を提供します。 これにより、正確なリスク スコアが生成され、誤ってフラグが立てられた正当なアクティビティをキャプチャするモデルの能力が向上します。
最初のXNUMXつの手順で構成されたモデルを確認した後、次を選択します。 創造する そしてモデルをトレーニングします。
コンソール ページでモデルのトレーニング ステータスを確認できます。 モデルの作成とトレーニングは、完了するまでに約 45 分かかります。 モデルのトレーニングが停止したら、モデルのバージョンを選択してモデルのパフォーマンスを確認できます。

モデルのパフォーマンスを評価してモデルをデプロイする
このセッションでは、モデルのパフォーマンスを確認して評価する手順について説明します。
Amazon Fraud Detector は、モデルのトレーニングに使用されなかったデータの 15% を使用してモデルのパフォーマンスを検証し、パフォーマンスメトリクスを提供します。 これらの指標とビジネス目標を考慮して、ビジネス モデルに合わせたしきい値を定義する必要があります。 メトリックの詳細としきい値の決定方法については、次を参照してください。 モデルのパフォーマンスメトリック.
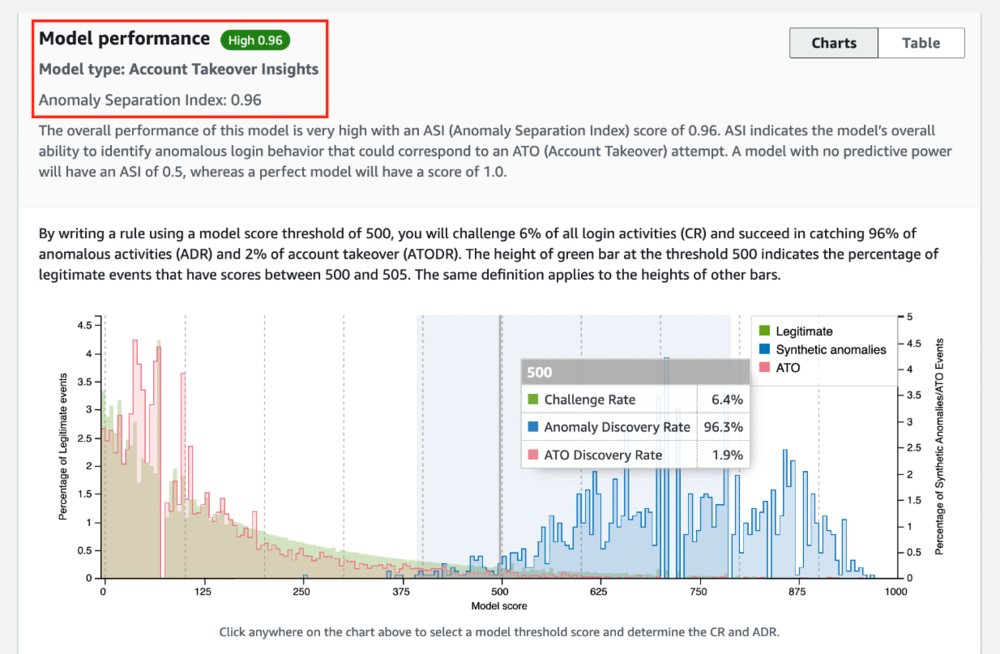
ATI は分類モデルではなく、異常検出モデルです。 したがって、評価指標は分類モデルとは異なります。 ATI モデルのトレーニングが完了すると、異常分離指数 (ASI) を確認できます。これは、リスクの高い異常なログインを識別するモデルの能力の総合的な尺度です。 75% 以上の ASI は良好、90% 以上は高い、75% 未満は不良と見なされます。
適切なバランスの選択を支援するために、Amazon Fraud Detector は、ATI モデルのパフォーマンスを評価するための次のメトリクスを提供します。
- 異常分離指数 (ASI) – 異常なアクティビティをユーザーの予期される動作から分離するモデルの全体的な機能を要約します。 分離能のないモデルの ASI スコアは、可能な限り最低の 0.5 になります。 対照的に、分離能が高いモデルの ASI スコアは、可能な限り最高の 1.0 になります。
- チャレンジ率 (CR) – スコアしきい値は、モデルがワンタイム パスワード、多要素認証、身元確認、調査などの形式でチャレンジすることを推奨するログイン イベントの割合を示します。
- 異常発見率 (ADR) – 選択したスコアしきい値でモデルが検出できる異常の割合を定量化します。 スコアしきい値が低いほど、モデルによってキャプチャされる異常の割合が増加します。 それでも、ログイン イベントのより多くの割合に異議を申し立てる必要があり、顧客の摩擦が大きくなります。
- ATO 発見率 (ATODR) – 選択したスコアしきい値でモデルが検出できるアカウント侵害イベントの割合を定量化します。 このメトリクスは、少なくとも 50 つのラベル付き ATO イベントを持つ XNUMX 以上のエンティティが、取り込まれたデータセットに存在する場合にのみ使用できます。
次の例では、ASI が 0.96 (高) であり、異常なアクティビティをユーザーの通常の行動から分離する能力が高いことを示しています。 モデル スコアのしきい値 500 を使用してルールを作成すると、すべてのログイン アクティビティの 6% に異議を唱えたり摩擦を引き起こしたりして、異常なアクティビティの 96% をキャッチします。
もう XNUMX つの重要なメトリックは、モデル変数の重要度です。 変数の重要度は、さまざまな変数がモデルのパフォーマンスにどのように関連しているかを理解するのに役立ちます。 生変数と集計変数の XNUMX 種類の変数を使用できます。 生の変数は、データセットに基づいて定義された変数ですが、集計変数は、強化され、集計された重要度値を持つ複数の変数の組み合わせです。
変数の重要度の詳細については、次を参照してください。 モデル変数の重要性.

変数 (未処理または集計) が残りの変数よりもはるかに大きい場合、モデルが過剰適合している可能性があることを示している可能性があります。 対照的に、比較的低い数値を持つ変数は単なるノイズである可能性があります。
モデルのパフォーマンスを確認し、ビジネス モデルに適合するモデル スコアのしきい値を決定したら、モデル バージョンをデプロイできます。 そのために、 メニュー、選択 モデルバージョンをデプロイする. モデルをデプロイしたら、検出エンドポイントを作成し、リアルタイム予測を実行します。

検出エンドポイントを作成し、ビジネス ルールを定義する
Amazon Fraud Detector は、検出エンドポイントを使用して不正予測を生成します。 検出器には、不正を評価する特定のイベントの、トレーニング済みモデルやビジネス ルールなどの検出ロジックが含まれています。 検出ロジックはルールを使用して、モデルに関連付けられたデータを解釈する方法を Amazon Fraud Detector に指示します。
検出器を作成するには、次の手順を実行します。
- Amazon Fraud Detectorコンソールのナビゲーションペインで、[ 検出器.
- 選択する 検出器を作成する.
- 検出器名、名前を入力します。
- 必要に応じて、検出器について説明します。
- イベントタイプで、前に作成したモデルと同じイベント タイプを選択します。
- 選択する Next.

- ソフトウェア設定ページで、下図のように モデルの追加(オプション) ページ、選択 モデルを追加.
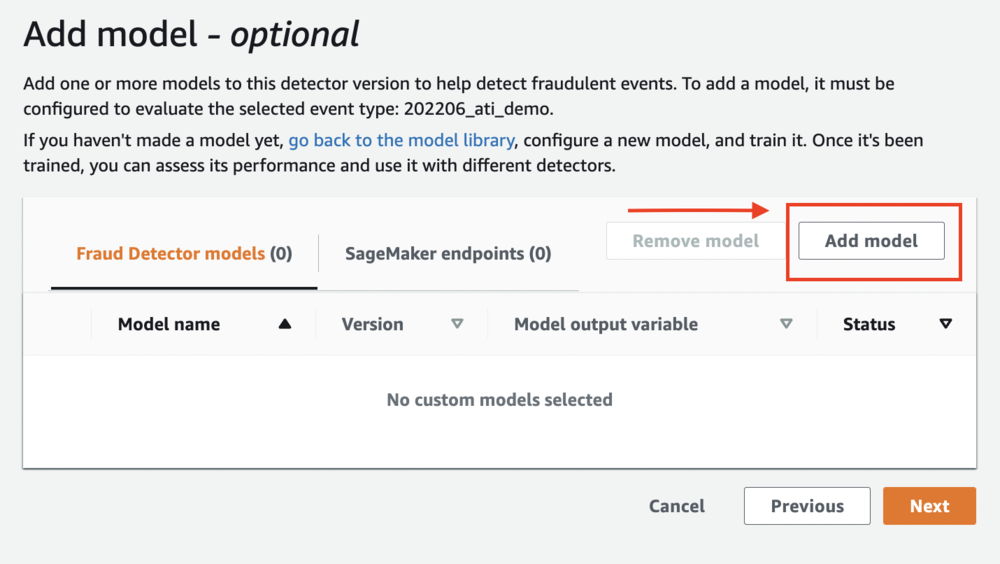
- モデルを追加するには、モデルのトレーニング手順でトレーニングして公開したモデルを選択し、アクティブなバージョンを選択します。
- 選択する モデルを追加.
次のステップの一部として、結果を定義するビジネス ルールを作成します。 ルールは、不正予測中に変数値を解釈する方法を Amazon Fraud Detector に指示する条件です。 ルールは、XNUMX つ以上の変数、論理式、および XNUMX つ以上の結果で構成されます。 結果は不正予測の結果であり、評価中にルールが一致した場合に返されます。
- 定義する
decline_ruleas$= 950結果を伴うdeny_login. - 定義する
friction_ruleas$ your_model_name _insightscore >= 855&$ your_model_name_insightscore >= 950結果を伴うchallenge_login. - 定義する
approve_ruleas$account_takeover_model_insightscore < 855結果を伴うapprove_login.
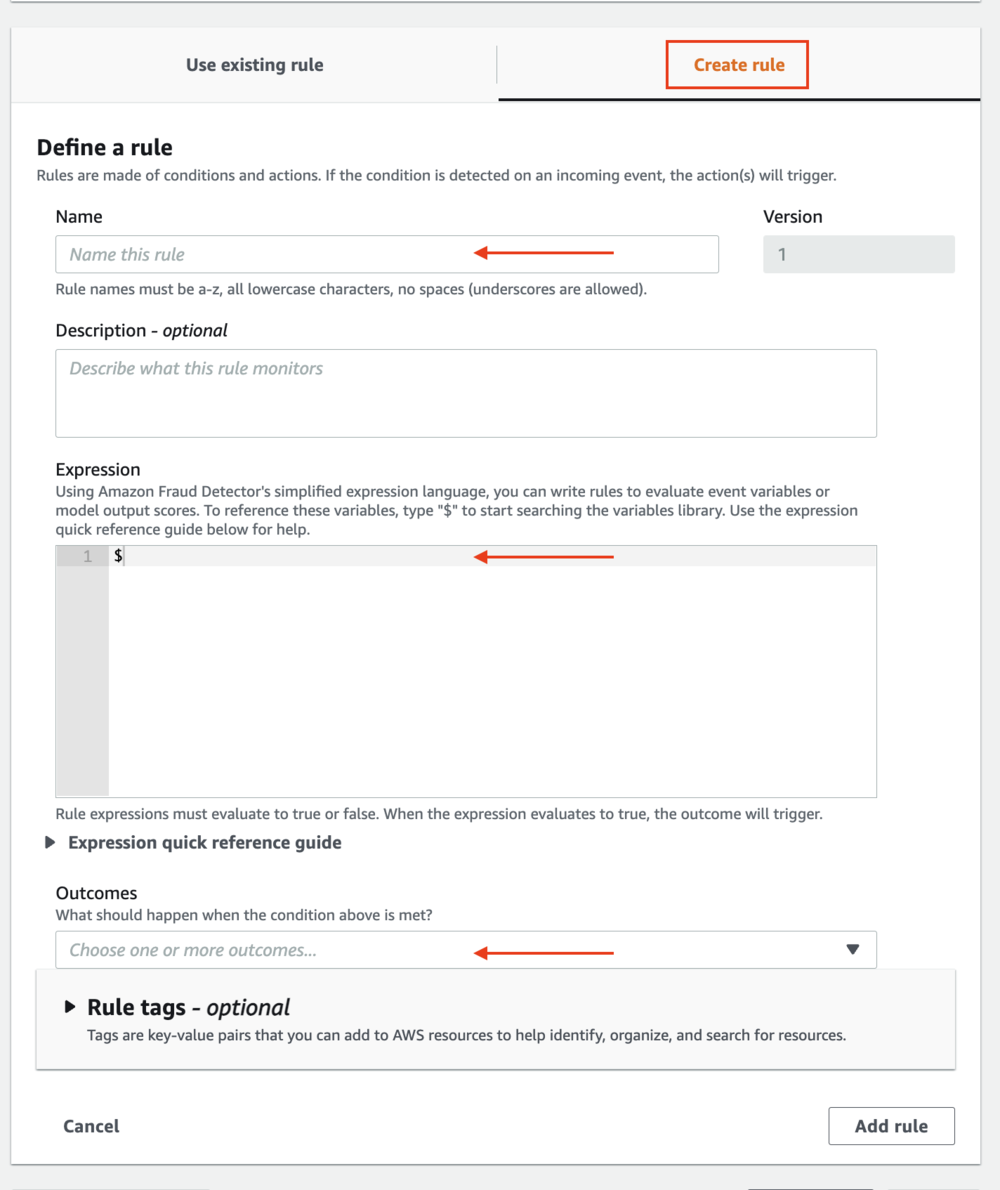
結果は、で返される文字列です。 GetEventPrediction API 応答。 結果を使用して、アプリケーションやダウンストリーム システムを呼び出してイベントをトリガーしたり、不正または正当である可能性が高い人物を簡単に特定したりできます。
- ソフトウェア設定ページで、下図のように ルールを追加する ページ、選択 Next すべてのルールの追加が完了した後。

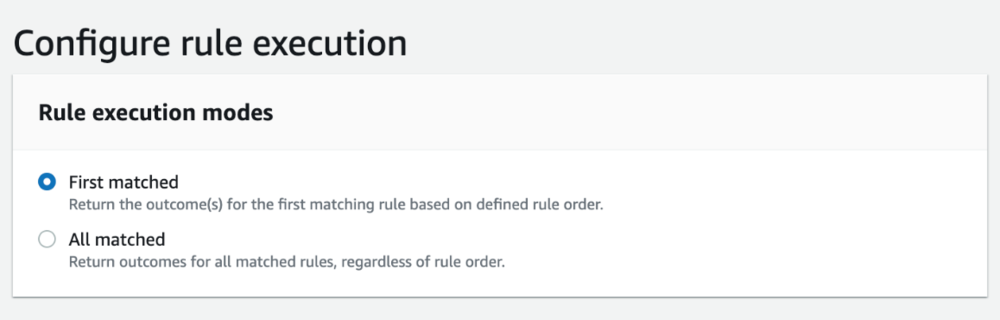
- ルールの実行を構成する セクションで、ルール エンジンのモードを選択します。
Amazon Fraud Detector ルール エンジンには、最初に一致するモードとすべて一致するモードの XNUMX つのモードがあります。 最初に一致したモードは、順次ルールを実行するためのもので、最初に満たされた条件の結果を返します。 もう XNUMX つのモードはすべて一致で、すべてのルールを評価し、一致するすべてのルールから結果を返します。 この例では、検出器に最初に一致したモードを使用します。
 このプロセスの後、検出器を作成し、いくつかのテストを実行する準備が整います。
このプロセスの後、検出器を作成し、いくつかのテストを実行する準備が整います。
- テストを実行するには、新しく作成した検出器に移動し、使用する検出器のバージョンを選択します。
- 要求に応じて変数値を指定し、 テストを実行する.
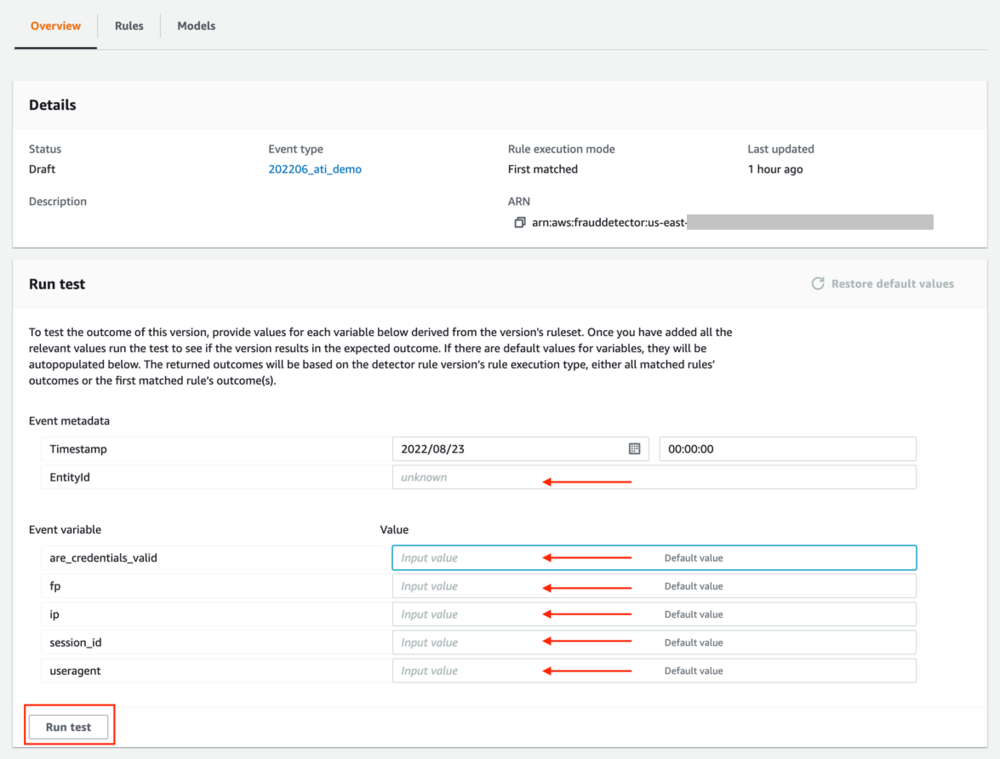
テストの結果として、ビジネス ルールに基づくリスク スコアと結果を受け取ります。
左側のパネルに移動して選択することで、過去の予測を検索することもできます。 過去の予測を検索します。 予測は、不正イベントの全体的な可能性に対する各変数の寄与度に基づいています。 次のスクリーンショットは、入力変数と、それらが不正予測スコアにどのように影響したかを示す過去の予測の例です。

リアルタイムの予測を取得する
リアルタイムの予測を取得し、Amazon Fraud Detector をワークフローに統合するには、検出エンドポイントを公開する必要があります。 次の手順を完了します。
- 新しく作成された検出器に移動し、バージョン 1 になる検出器のバージョンを選択します。
- ソフトウェア設定ページで、下図のように メニュー、選択 パブリッシュ.
を呼び出して、公開された検出器でリアルタイム予測を実行できます。 GetEventPrediction API。 以下は、 GetEventPrediction API:
まとめ
Amazon Fraud Detector は、調整されたアルゴリズム、エンリッチメント、機能変換を備えた特定のモデルに依存して、複数のユースケースで不正なイベントを検出します。 この投稿では、データの取り込み、モデルのトレーニングとデプロイ、ビジネス ルールの記述、検出器の公開を行って、侵害された可能性のあるアカウントでリアルタイムの不正予測を生成する方法を学習しました。
訪問 アマゾン詐欺検出器 Amazon Fraud Detector または当社の詳細については、 GitHubレポ コード サンプル、ノートブック、および合成データセット用。
著者について
 マルセル・ピビダル ワールド ワイド スペシャリスト オーガニゼーションのシニア AI サービス ソリューション アーキテクトです。 マルセルは、フィンテック、決済プロバイダー、製薬会社、および政府機関のテクノロジーを通じてビジネス上の問題を解決してきた 20 年以上の経験を持っています。 彼が現在注力している分野は、リスク管理、不正防止、本人確認です。
マルセル・ピビダル ワールド ワイド スペシャリスト オーガニゼーションのシニア AI サービス ソリューション アーキテクトです。 マルセルは、フィンテック、決済プロバイダー、製薬会社、および政府機関のテクノロジーを通じてビジネス上の問題を解決してきた 20 年以上の経験を持っています。 彼が現在注力している分野は、リスク管理、不正防止、本人確認です。
 マイクエイムス データ サイエンティストから ID 検証ソリューションのスペシャリストに転向した彼は、組織を詐欺、浪費、悪用から保護するための機械学習および AI ソリューションの開発に豊富な経験を持っています。 余暇には、ハイキング、マウンテン バイク、犬のマックスとフリービーで遊んでいるのを見つけることができます。
マイクエイムス データ サイエンティストから ID 検証ソリューションのスペシャリストに転向した彼は、組織を詐欺、浪費、悪用から保護するための機械学習および AI ソリューションの開発に豊富な経験を持っています。 余暇には、ハイキング、マウンテン バイク、犬のマックスとフリービーで遊んでいるのを見つけることができます。

