
著者による画像
大規模言語モデル (LLM) に関するニュースを十分に消化したと思ったちょうどその時、Microsoft Research Asia チームが Visual ChatGPT を発表しました。 Visual ChatGPT は、単一の言語モダリティでトレーニングされているため、視覚情報を処理できないという ChatGPT の現在の制限を克服します。
Visual ChatGPT は Visual Foundation Models (VFM) を組み込んだシステムで、ChatGPT が視覚情報をよりよく理解し、生成し、編集できるようにします。 VFM には、入出力形式を指定し、視覚情報を言語形式に変換し、VFM の履歴、優先順位、競合を処理する機能があります。
したがって、Visual ChatGPT は、ChatGPT の制限と、ユーザーがチャットを介して通信し、ビジュアルを生成できるようにする間の橋渡しとして機能する AI モデルです。
ChatGPT の制限事項
ChatGPT は、過去数週間から数か月の間、人々の会話の大部分を占めてきました。 ただし、その言語トレーニング機能により、画像の処理と生成はできません。
Visual Transformers や Steady Diffusion など、驚くべきビジュアル機能を備えたビジュアル基盤モデルがあります。 これは、言語モデルと画像モデルの組み合わせによって Visual ChatGPT が作成された場所です。
ビジュアル ファンデーション モデルとは
Visual Foundation Models は、コンピューター ビジョンで使用される基本的なアルゴリズムをグループ化するために使用されます。 彼らは、標準的なコンピューター ビジョン スキルを AI アプリケーションに移して、より複雑なタスクを処理します。
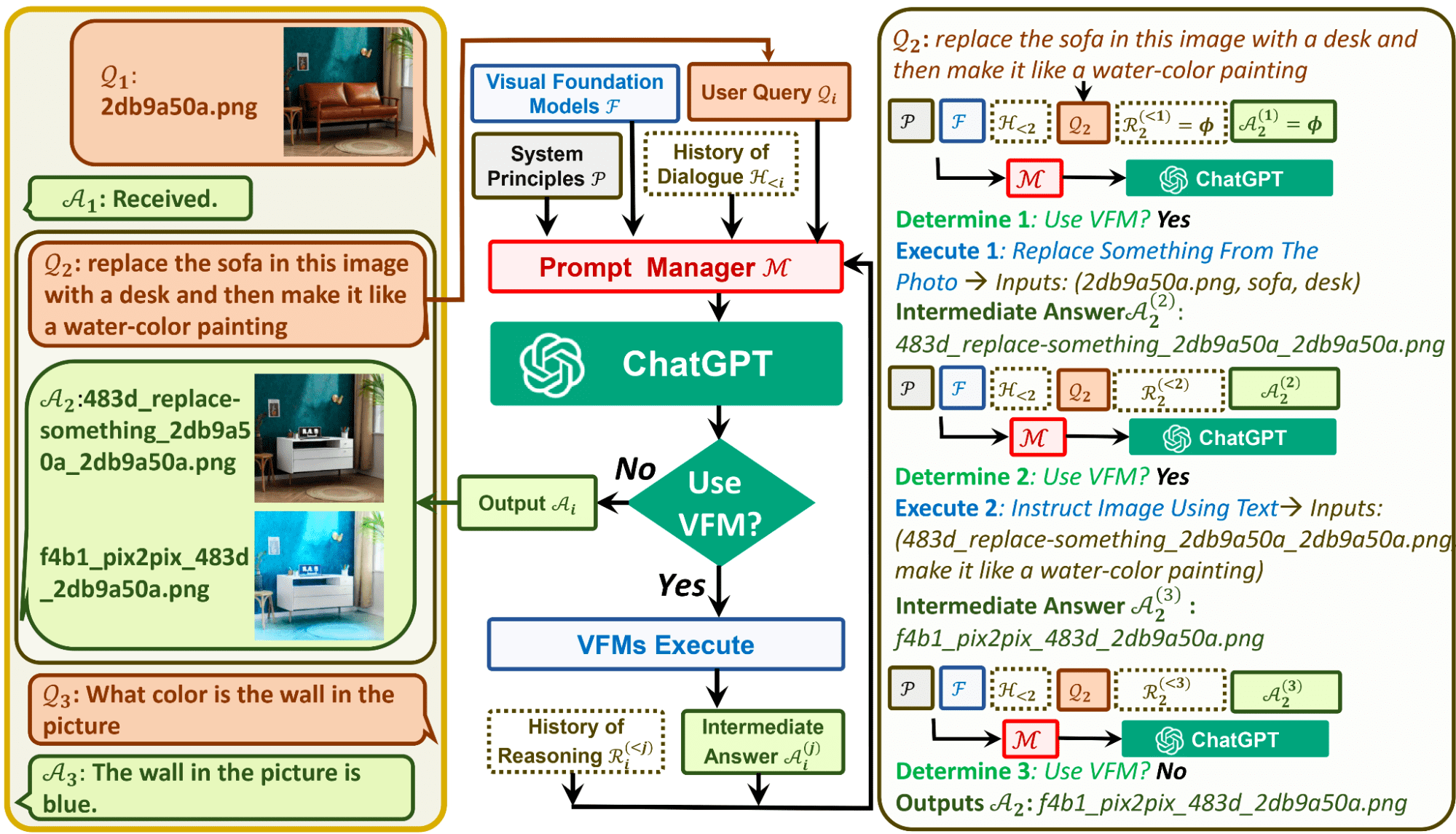
Visual ChatGPT の Prompt Manager は、Text-to-Image、ControlNet、Edge-To-Image などを含む 22 の VFM で構成されています。 これは、ChatGPT が画像のすべての視覚信号を ChatGPT がよりよく理解できるように言語に変換するのに役立ちます。 では、Visual ChatGPT はどのように機能するのでしょうか?
Visual ChatGPT は、Large Language Model ChatGPT がビジュアルを理解するのに役立つさまざまなコンポーネントで構成されています。
Visual ChatGPT のアーキテクチャ コンポーネント
- ユーザークエリ: ユーザーがクエリを送信する場所
- プロンプトマネージャー: これにより、ユーザーのビジュアル クエリが言語形式に変換され、ChatGPT モデルが理解できるようになります。
- ビジュアル ファンデーション モデル: これは、BLIP (Bootstrapping Language-Image Pre-training)、Stable Diffusion、ControlNet、Pix2Pix などのさまざまな VFM を組み合わせたものです。
- システム原理: Visual ChatGPT の基本的なルールと要件を示します。
- 対話の歴史: これは、システムがユーザーとやり取りする最初のポイントです。
- 推論の歴史: これは、複雑なクエリを解決するために、さまざまな VFM が過去に持っていた以前の推論を使用します。
- 中間回答: VFM を使用すると、モデルは論理的に控えめないくつかの中間回答を出力しようとします。
による画像 マイクロソフト GitHub
プロンプト マネージャーの詳細
ChatGPT は画像のすべての視覚信号を言語に変換するため、これは視覚を処理するための強制的な回避策であると考える人もいるかもしれません。 画像をアップロードするとき、Prompt Manager はファイル名などの情報を含む内部チャット履歴を合成して、ChatGPT がクエリが参照しているものをよりよく理解できるようにします。
たとえば、ユーザーが入力した画像の名前は操作履歴として機能し、プロンプト マネージャーは、モデルが「推論形式」を使用して、画像に対して何を行う必要があるかを判断するのを支援します。 これは、ChatGPT が正しい VFM 操作を選択する前のモデルの内部的な考えと見なすことができます。
下の画像では、Prompt Manager が Visual ChatGPT のルールを開始する方法を確認できます。
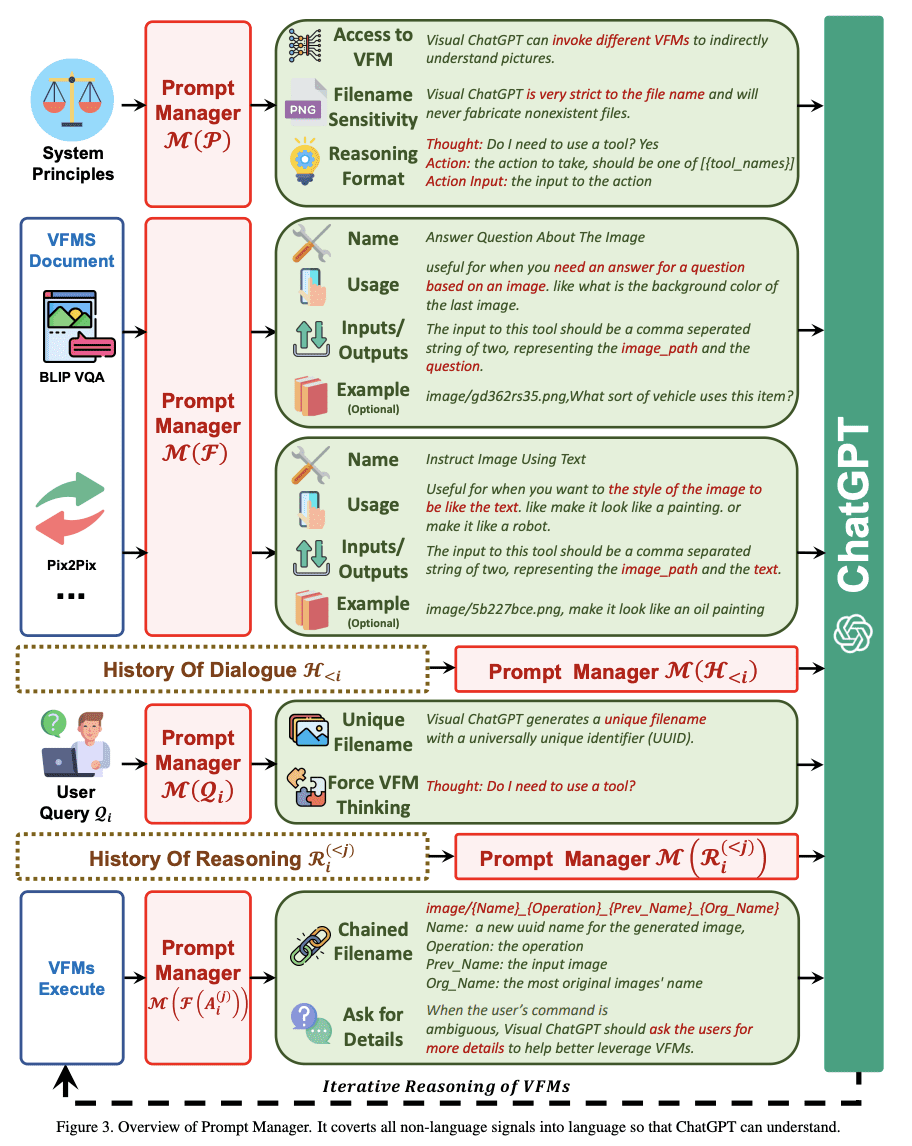
による画像 Visual ChatGPT: Visual Foundation モデルを使用した会話、描画、および編集
Visual ChatGPT ジャーニーを開始するには、最初に Visual ChatGPT デモを実行する必要があります。
# create a new environment
conda create -n visgpt python=3.8 # activate the new environment
conda activate visgpt # prepare the basic environments
pip install -r requirement.txt # download the visual foundation models
bash download.sh # prepare your private openAI private key
export OPENAI_API_KEY={Your_Private_Openai_Key} # create a folder to save images
mkdir ./image # Start Visual ChatGPT !
python visual_chatgpt.py
また、詳細については、 Microsoft の Visual ChatGPT GitHub. Visual Foundation モデルごとに GPU メモリの使用状況を確認してください。
Visual ChatGPT でできること
画像生成
説明を入力して、Visual ChatGPT にイメージをゼロから作成するよう依頼できます。 利用可能な計算能力にもよりますが、画像は数秒で生成されます。 テキストデータを使用した合成画像の生成は、Stable Diffusion に基づいています。
画像の背景を変更する
ここでも、安定した拡散を使用して、Visual ChatGPT は入力画像の背景を変更できます。 ユーザーは、背景を何に変更したいかについての説明をアシスタントに提供することができ、安定した拡散モデルが画像の背景を修復します。
カラー画像とその他の効果の変更
アプリケーションに説明を提供することに基づいて、画像の色を変更し、効果を適用することもできます。 Visual ChatGPT は、さまざまな事前トレーニング済みモデルを使用し、 OpenCV、画像の色の変更、画像のエッジの強調表示などを行います。
画像に変更を加える
Visual ChatGPT を使用すると、画像内のオブジェクトをアプリケーションに指示されたテキスト説明で編集および変更することにより、画像の側面を削除または置換できます。 ただし、この機能にはより多くの計算能力が必要であることに注意してください。
私たちが知っているように、組織がサービスを改善するために取り組む必要がある何らかの形の欠陥が常に存在します.
コンピュータ ビジョンと大規模言語モデルの組み合わせ
Visual ChatGPT は ChatGPT と VFM に大きく依存しているため、これらの個々の側面の精度と信頼性が Visual ChatGPT のパフォーマンスに影響します。 大規模言語モデルとコンピューター ビジョンを組み合わせて使用するには、大量の迅速なエンジニアリングが必要であり、熟練したパフォーマンスを達成するのが難しい場合があります。
プライバシーとセキュリティ
Visual ChatGPT には、VFM を簡単に抜き差しできる機能があります。これは、セキュリティとプライバシーの問題について一部のユーザーにとって懸念事項となる可能性があります。 Microsoft は、機密データが危険にさらされていない方法をさらに調査する必要があります。
自己修正モジュール
Visual ChatGPT の研究者が遭遇した制限の XNUMX つは、VFM の失敗とプロンプトの多様性により生成される結果に一貫性がないことでした。 したがって、彼らは、生成された出力がユーザーが要求したものと一致していることを保証し、必要な修正を行うことができる自己修正モジュールに取り組む必要があると結論付けました.
大量の GPU が必要
Visual ChatGPT を利用して 22 個の VFM を利用するには、大量の GPU RAM (A100 など) が必要です。 目の前のタスクに応じて、タスクを効果的に完了するために必要な GPU の量を把握してください。
Visual ChatGPT にはまだ制限がありますが、これは大規模言語モデルとコンピューター ビジョンの同時使用における大きなブレークスルーです。 Visual ChatGPT について詳しく知りたい場合は、次の論文をお読みください。 Visual ChatGPT: Visual Foundation モデルを使用した会話、描画、および編集
Visual ChatGPT は ChatGPT4 と似ていますか? XNUMXつを試した場合、あなたの意見はどうですか? 以下にコメントをドロップしてください!
ニシャ・アリア KDnuggets のデータ サイエンティスト、フリーランス テクニカル ライター、およびコミュニティ マネージャーです。 彼女は特に、データ サイエンスに関するキャリア アドバイスやチュートリアル、およびデータ サイエンスに関する理論に基づく知識を提供することに関心を持っています。 彼女はまた、人工知能が人間の寿命を延ばすためのさまざまな方法を探求したいと考えています。 熱心な学習者であり、他の人を導く手助けをしながら、技術知識とライティング スキルを広げようとしています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- Platoblockchain。 Web3メタバースインテリジェンス。 知識の増幅。 こちらからアクセスしてください。
- 情報源: https://www.kdnuggets.com/2023/03/visual-chatgpt-microsoft-combine-chatgpt-vfms.html?utm_source=rss&utm_medium=rss&utm_campaign=visual-chatgpt-microsoft-combine-chatgpt-and-vfms

