15 年 2024 月 XNUMX 日 (Nanowerkニュース) 声帯に病的な状態がある人や喉頭がんの手術から回復中の人など、音声障害のある人は、話すことが困難または不可能であることがよくあります。それはすぐに変わるかもしれません。 UCLAのエンジニアのチームは、声帯の機能不全を持つ人々が声の機能を取り戻すのを助けるために、喉の外側の皮膚に取り付けることができる、1平方インチ強の柔らかくて薄く伸縮性のある装置を発明した。彼らの進歩はジャーナルで詳しく説明されています ネイチャー·コミュニケーションズ (「機械学習支援のウェアラブルセンシング作動システムを使用して、声帯を使わずに話す」)。 UCLA サムエリ工学部の生物工学助教授であるジュン チェン氏とその同僚によって開発された新しい生体電気システムは、人間の喉頭の筋肉の動きを検出し、機械の助けを借りてそれらの信号を可聴音声に変換することができます。学習テクノロジー — ほぼ 95% の精度。この画期的な成果は、障害を持つ人々を支援するチェン氏の取り組みの最新のものである。彼のチームは以前、ASL ユーザーが手話の仕方を知らないユーザーとコミュニケーションできるように、アメリカ手話をリアルタイムで英語音声に翻訳できるウェアラブル グローブを開発しました。この小さな新しいパッチのようなデバイスは XNUMX つのコンポーネントで構成されています。 XNUMX つは自己電源式のセンシング コンポーネントで、筋肉の動きによって生成された信号を検出し、忠実度の高い分析可能な電気信号に変換します。これらの電気信号は、機械学習アルゴリズムを使用して音声信号に変換されます。もう XNUMX つは作動コンポーネントであり、これらの音声信号を目的の音声表現に変換します。 XNUMX つのコンポーネントにはそれぞれ XNUMX つの層が含まれています。弾性特性を持つ生体適合性シリコーン化合物ポリジメチルシロキサン (PDMS) の層と、銅誘導コイルで作られた磁気誘導層です。 XNUMX つのコンポーネントの間には、磁場を生成するマイクロ磁石と混合された PDMS を含む XNUMX 番目の層が挟まれています。
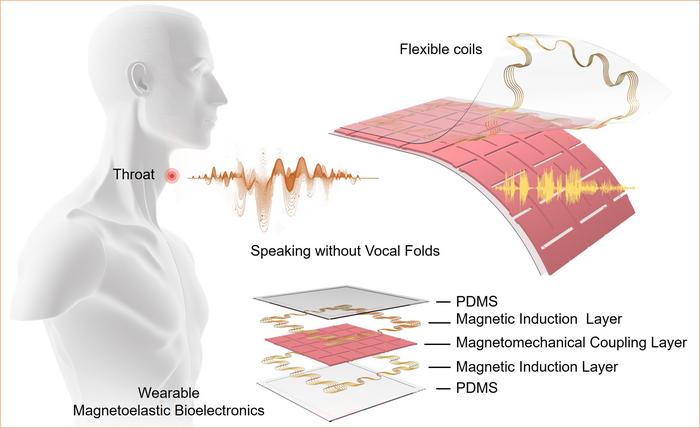 このデバイスの 2021 つのコンポーネントと XNUMX つの層により、筋肉の動きを電気信号に変換でき、機械学習の助けを借りて、最終的に音声信号と可聴音声表現に変換されます。 (画像: Jun Chen Lab/UCLA) XNUMX 年に Chen のチームが開発した軟磁気弾性センシング機構を利用 (ネイチャーマテリアルズ, 「バイオエレクトロニクス用ソフトシステムにおける巨大磁気弾性効果」)、この装置は、機械的な力、この場合は喉頭筋の動きの結果として磁場が変化したときに、その変化を検出することができます。磁気弾性層に埋め込まれた蛇行誘導コイルは、センシング目的で高忠実度の電気信号を生成するのに役立ちます。各辺の寸法が 1.2 インチのこのデバイスの重さは約 7 グラム、厚さはわずか 0.06 インチです。生体適合性のある両面テープを使用すると、声帯付近の喉に簡単に貼り付けることができ、必要に応じてテープを貼り直すことで再利用できます。音声障害は、あらゆる年齢および人口統計グループに蔓延しています。研究によると、ほぼ 30% の人が生涯に少なくとも XNUMX 回はそのような障害を経験することがわかっています。しかし、外科的介入や音声療法などの治療アプローチでは、音声の回復に XNUMX か月から XNUMX 年かかる場合があり、一部の侵襲的技術では術後にかなりの期間の強制的な音声休息が必要となります。 「携帯型電気喉頭装置や気管食道穿刺処置などの既存のソリューションは、不便、侵襲的、または不快な場合があります」と、UCLA のウェアラブル バイオエレクトロニクス研究グループを率い、XNUMX 年から XNUMX 年間で世界で最も引用数の高い研究者の XNUMX 人に選ばれているチェン氏は述べています。行。 「この新しいデバイスは、音声障害の治療前および治療後の回復期間中の患者のコミュニケーションを支援できる、ウェアラブルで非侵襲的なオプションを提供します。」
このデバイスの 2021 つのコンポーネントと XNUMX つの層により、筋肉の動きを電気信号に変換でき、機械学習の助けを借りて、最終的に音声信号と可聴音声表現に変換されます。 (画像: Jun Chen Lab/UCLA) XNUMX 年に Chen のチームが開発した軟磁気弾性センシング機構を利用 (ネイチャーマテリアルズ, 「バイオエレクトロニクス用ソフトシステムにおける巨大磁気弾性効果」)、この装置は、機械的な力、この場合は喉頭筋の動きの結果として磁場が変化したときに、その変化を検出することができます。磁気弾性層に埋め込まれた蛇行誘導コイルは、センシング目的で高忠実度の電気信号を生成するのに役立ちます。各辺の寸法が 1.2 インチのこのデバイスの重さは約 7 グラム、厚さはわずか 0.06 インチです。生体適合性のある両面テープを使用すると、声帯付近の喉に簡単に貼り付けることができ、必要に応じてテープを貼り直すことで再利用できます。音声障害は、あらゆる年齢および人口統計グループに蔓延しています。研究によると、ほぼ 30% の人が生涯に少なくとも XNUMX 回はそのような障害を経験することがわかっています。しかし、外科的介入や音声療法などの治療アプローチでは、音声の回復に XNUMX か月から XNUMX 年かかる場合があり、一部の侵襲的技術では術後にかなりの期間の強制的な音声休息が必要となります。 「携帯型電気喉頭装置や気管食道穿刺処置などの既存のソリューションは、不便、侵襲的、または不快な場合があります」と、UCLA のウェアラブル バイオエレクトロニクス研究グループを率い、XNUMX 年から XNUMX 年間で世界で最も引用数の高い研究者の XNUMX 人に選ばれているチェン氏は述べています。行。 「この新しいデバイスは、音声障害の治療前および治療後の回復期間中の患者のコミュニケーションを支援できる、ウェアラブルで非侵襲的なオプションを提供します。」
 このウェアラブル技術は、皮膚の下にある喉頭筋の動きに合わせて動き、その活動を捉えるのに十分な柔軟性を備えているように設計されています。 (画像: ジュン・チェン研究室/UCLA)
機械学習がウェアラブル技術をどのように実現するか
研究者らは実験で、94.68人の健康な成人を対象にウェアラブル技術をテストした。彼らは喉頭の筋肉の動きに関するデータを収集し、機械学習アルゴリズムを使用して、得られた信号を特定の単語に関連付けました。次に、デバイスの作動コンポーネントを通じて、対応する出力音声信号を選択しました。研究チームは、参加者に「こんにちは、レイチェル、今日の調子はどうですか?」などの XNUMX つの文を声に出して、無声で発音してもらい、システムの精度を実証しました。そして愛しています!"モデルの全体的な予測精度は XNUMX% で、参加者の音声信号が作動コンポーネントによって増幅されました。これは、センシング機構が喉頭の動きの信号を認識し、参加者が言いたかった対応する文と一致していることを示しています。研究チームは今後も機械学習を通じてデバイスの語彙を拡大し、言語障害を持つ人々を対象にテストする予定だ。
このウェアラブル技術は、皮膚の下にある喉頭筋の動きに合わせて動き、その活動を捉えるのに十分な柔軟性を備えているように設計されています。 (画像: ジュン・チェン研究室/UCLA)
機械学習がウェアラブル技術をどのように実現するか
研究者らは実験で、94.68人の健康な成人を対象にウェアラブル技術をテストした。彼らは喉頭の筋肉の動きに関するデータを収集し、機械学習アルゴリズムを使用して、得られた信号を特定の単語に関連付けました。次に、デバイスの作動コンポーネントを通じて、対応する出力音声信号を選択しました。研究チームは、参加者に「こんにちは、レイチェル、今日の調子はどうですか?」などの XNUMX つの文を声に出して、無声で発音してもらい、システムの精度を実証しました。そして愛しています!"モデルの全体的な予測精度は XNUMX% で、参加者の音声信号が作動コンポーネントによって増幅されました。これは、センシング機構が喉頭の動きの信号を認識し、参加者が言いたかった対応する文と一致していることを示しています。研究チームは今後も機械学習を通じてデバイスの語彙を拡大し、言語障害を持つ人々を対象にテストする予定だ。
このデバイスの 2021 つのコンポーネントと XNUMX つの層により、筋肉の動きを電気信号に変換でき、機械学習の助けを借りて、最終的に音声信号と可聴音声表現に変換されます。 (画像: Jun Chen Lab/UCLA) XNUMX 年に Chen のチームが開発した軟磁気弾性センシング機構を利用 (ネイチャーマテリアルズ, 「バイオエレクトロニクス用ソフトシステムにおける巨大磁気弾性効果」)、この装置は、機械的な力、この場合は喉頭筋の動きの結果として磁場が変化したときに、その変化を検出することができます。磁気弾性層に埋め込まれた蛇行誘導コイルは、センシング目的で高忠実度の電気信号を生成するのに役立ちます。各辺の寸法が 1.2 インチのこのデバイスの重さは約 7 グラム、厚さはわずか 0.06 インチです。生体適合性のある両面テープを使用すると、声帯付近の喉に簡単に貼り付けることができ、必要に応じてテープを貼り直すことで再利用できます。音声障害は、あらゆる年齢および人口統計グループに蔓延しています。研究によると、ほぼ 30% の人が生涯に少なくとも XNUMX 回はそのような障害を経験することがわかっています。しかし、外科的介入や音声療法などの治療アプローチでは、音声の回復に XNUMX か月から XNUMX 年かかる場合があり、一部の侵襲的技術では術後にかなりの期間の強制的な音声休息が必要となります。 「携帯型電気喉頭装置や気管食道穿刺処置などの既存のソリューションは、不便、侵襲的、または不快な場合があります」と、UCLA のウェアラブル バイオエレクトロニクス研究グループを率い、XNUMX 年から XNUMX 年間で世界で最も引用数の高い研究者の XNUMX 人に選ばれているチェン氏は述べています。行。 「この新しいデバイスは、音声障害の治療前および治療後の回復期間中の患者のコミュニケーションを支援できる、ウェアラブルで非侵襲的なオプションを提供します。」
このウェアラブル技術は、皮膚の下にある喉頭筋の動きに合わせて動き、その活動を捉えるのに十分な柔軟性を備えているように設計されています。 (画像: ジュン・チェン研究室/UCLA)
機械学習がウェアラブル技術をどのように実現するか
研究者らは実験で、94.68人の健康な成人を対象にウェアラブル技術をテストした。彼らは喉頭の筋肉の動きに関するデータを収集し、機械学習アルゴリズムを使用して、得られた信号を特定の単語に関連付けました。次に、デバイスの作動コンポーネントを通じて、対応する出力音声信号を選択しました。研究チームは、参加者に「こんにちは、レイチェル、今日の調子はどうですか?」などの XNUMX つの文を声に出して、無声で発音してもらい、システムの精度を実証しました。そして愛しています!"モデルの全体的な予測精度は XNUMX% で、参加者の音声信号が作動コンポーネントによって増幅されました。これは、センシング機構が喉頭の動きの信号を認識し、参加者が言いたかった対応する文と一致していることを示しています。研究チームは今後も機械学習を通じてデバイスの語彙を拡大し、言語障害を持つ人々を対象にテストする予定だ。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.nanowerk.com/news2/robotics/newsid=64863.php

