2 月、OpenAI は、 ソラのお披露目は、テキスト プロンプトを魅力的なビデオに変換できる優れた AI ツールです。 Sora を使用すると、ユーザーは AI が短いテキストの合図からダイナミックな 60 秒のビデオを作成するのを見て、自分のアイデアに命を吹き込むことができます。しかし、市内の別のプレーヤーがインターネット上で話題を呼んでいます。それは、XNUMX か月前に登場した Google のビデオ生成ツール、VideoPoet です。
VideoPoet は Google Research の 31 人の研究者チームの発案であり、マルチメディア作成の世界に大きな変革をもたらします。 Sora はテキストを視覚的なストーリーに変えることに重点を置いていますが、VideoPoet は異なるアプローチを採用しています。自己回帰言語モデリングや MAGVIT V2 や SoundStream などのトークナイザーなどの高度な技術のおかげで、テキスト、画像、さらには既存のビデオ映像を使用してリアルなビデオを作成することに優れています。この多用途性により、デジタル アート、映画制作、インタラクティブ メディアの可能性の世界が開かれます。

出典: Google リサーチ
VideoPoet を際立たせているのは、そのユニークなアーキテクチャです。多くのビデオ生成モデルは、この分野で最も優れたパフォーマンスを発揮すると考えられている拡散ベースの手法に依存していますが、Google Research は別のルートを採用しました。 Google 研究者らは、一般的な安定拡散モデルを使用する代わりに、トランスフォーマー アーキテクチャに基づく大規模言語モデル (LLM) を選択しました。通常、テキストやコードの生成に使用されるこのタイプの AI モデルは、ビデオの生成に再利用されています。これは、VideoPoet を他と区別する大胆な動きです。
「既存のモデルのほとんどは拡散ベースの手法を採用しており、これがビデオ生成において現在のトップパフォーマンスであると考えられています。これらのビデオ モデルは通常、個々のフレームに対して忠実度の高い画像を生成する安定拡散などの事前トレーニング済みの画像モデルから始まり、その後、ビデオ フレーム間の時間的一貫性を向上させるためにモデルを微調整します」と Google Research チームは事前報告書で書いています。レビュー 研究論文.
VideoPoet とは何ですか?またどのように機能しますか?
VideoPoet はその中核として、自己回帰言語モデルを使用して、ビデオ、画像、オーディオ、テキストなどのさまざまなモダリティから学習します。これは、複数のトークナイザーを採用することで可能になります。マグビット V2 ビデオと画像の場合はSoundStream、オーディオの場合はSoundStreamです。
モデルが特定のコンテキストに基づいてトークンを生成すると、これらのトークンは後でそれぞれのトークナイザーのデコーダーを使用して目に見える表現に変換されます。これにより、さまざまな形式のメディア間のシームレスな翻訳が可能になり、すべてのモダリティにわたる一貫性のある包括的な理解を保証します。以下は VideoPoet のコンポーネントです。
- 事前トレーニングされた MAGVIT V2 および SoundStream トークナイザー。画像、ビデオ、オーディオ クリップをモデルが理解できる一連のコードに変換します。
- 自己回帰言語モデル。ビデオ、画像、オーディオ、テキストなどのさまざまなモダリティから学習して、シーケンス内の次のトークンを予測します。
- テキストからビデオ、テキストから画像、画像からビデオなどを含む幅広い生成学習目標により、VideoPoet は多様で高品質のビデオを作成できます。
革新的な機能と機能
Sora や Stable Diffusion と同様、VideoPoet にはビデオ作成に新たな視点をもたらす革新的な機能がいくつかあります。
ハイモーション可変長ビデオ: 従来のモデルとは異なり、VideoPoet は動きの多い可変長ビデオを簡単に作成し、ビデオ生成の可能性の限界を押し広げます。
クロスモダリティ学習: VideoPoet の強みの 1 つは、さまざまなモダリティを横断して学習できることです。 VideoPoet は、テキスト、画像、ビデオ、オーディオの間のギャップを埋めることで、創造的なプロセスを豊かにする総合的な理解を提供します。
インタラクティブな編集機能: VideoPoet はビデオを生成するだけではなく、ユーザーにインタラクティブな編集機能を提供します。入力ビデオの拡張からモーションの制御、テキスト プロンプトに基づく様式化された効果の適用まで、創造的な制御をユーザーの手に委ねます。
Google の VideoPoet は単なるビデオ生成ツールではなく、AI の世界における変革をもたらします。複数の機能を単一の大規模言語モデル (LLM) にシームレスに統合することで、ビデオ生成の状況を再定義します。テキスト、画像、オーディオの処理における多用途性により、コンテンツ作成者や AI 愛好家にとって不可欠なものとなり、創造性と革新性の新たな標準を確立します。
以下の図を使用して、VideoPoet の機能を詳しく説明します。
まず、入力画像にアニメーションを適用して、ビデオ内にダイナミックな動きを作成できます。さらに、ユーザーは特定の領域をトリミングまたはマスクしてビデオを編集するオプションがあり、シームレスなインペイントまたはアウトペイント効果が可能になります。
様式化に関しては、モデルは奥行きとオプティカル フロー、つまりシーン内の動きをキャプチャするビデオを分析することで魔法を発揮します。この情報を使用して、テキスト プロンプトに従ってスタイル要素を適用し、ビデオ全体の視覚的な魅力を高めます。
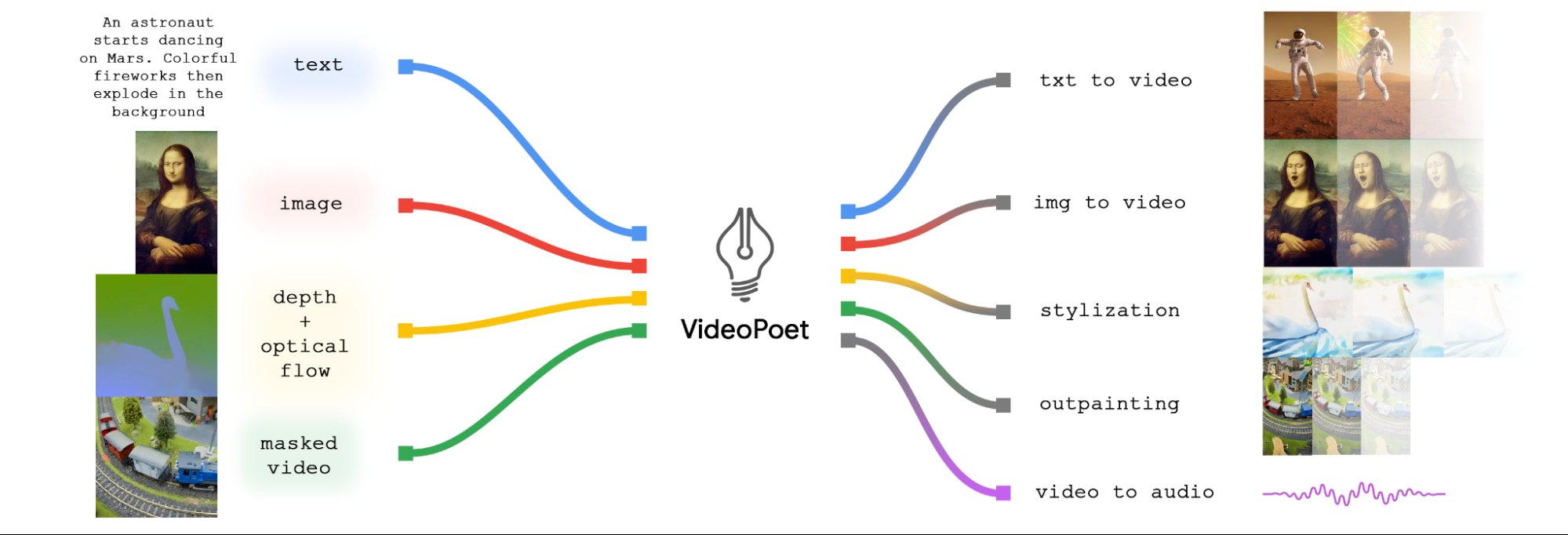
クリックして展開
専門用語はこれくらいにして、結果について話しましょう。 VideoPoet の機能を紹介するために、Google Research チームは、ストーリーテリング AI である Bard からのプロンプトに基づいて短編映画を制作しました。結果?旅をするアライグマの魅力的な物語が、一連の魅惑的なビデオ クリップによって命を吹き込まれます。これはストーリーテリングにおける AI の力の証であり、マルチメディア作成の未来を垣間見ることができます。
[埋め込まれたコンテンツ]
コンテンツが王様の世界では、Sora や VideoPoet のようなツールが状況を変え、クリエイターがこれまで不可能だった方法でアイデアを実現できるようにしています。これらの AI 駆動ツールは、高度な機能とユーザーフレンドリーなインターフェイスを備えており、ビデオを通じてストーリーを伝え、自分自身を表現する方法に革命を起こす準備ができています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://techstartups.com/2024/04/12/videopoet-google-looks-to-challenge-openai-sora-and-stable-diffusion-for-dominance-in-ai-video-creation/

