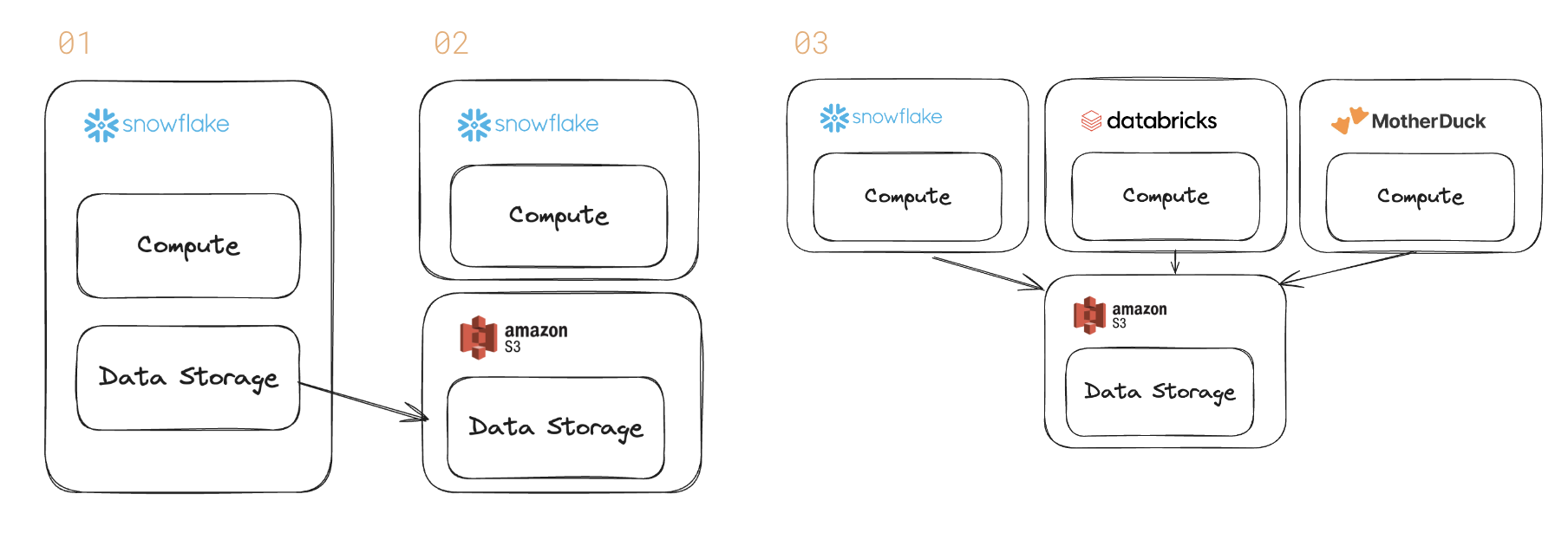
データベースはバンドル解除されています。歴史的に、Snowflake のようなデータベースは、データ ストレージとクエリ エンジン (およびクエリを実行するコンピューティング能力) の両方を販売していました。それが上記のステップ 1 です。
しかし、顧客はコンピューティングとストレージのより深い分離を求めています。最近の Snowflake の決算発表では、この傾向が浮き彫りになりました。大規模な顧客は、相互運用性のためにオープン フォーマットを好みます (ステップ 2 と 3)。
多くの大企業顧客は、オプションを提供するオープン ファイル形式を望んでいます。そのため、データの相互運用性は非常に重要であり、当社の AI 製品は通常、クラウド ストレージにあるデータに対しても動作します。
当社の大規模顧客の多くが Iceberg 形式を採用し、データを Snowflake から移動することになると予想しています。その場合、当社はストレージ収益を失い、そのデータを Snowflake に移動することに関連するコンピューティング収益も失います。
顧客はデータを 1 つのデータベースにロックするのではなく、Apache Arrow、Apache Parquet、Apache Iceberg などのオープン形式で保存することを好みます。
企業内でのデータ使用が拡大するにつれて、そのデータに対する要求も多様化しています。
探索的分析、ビジネス インテリジェンス、AI ワークロードなど、異なる目的で毎回データをコピーするのではなく、データを一元管理して、さまざまなシステムからデータにアクセスできるようにしてはいかがでしょうか。
これによりコストが節約されます。Snowflake の場合、ストレージは全体で約 280 億 300 万ドルから XNUMX 億ドルかかります。
なお、当社の総収益の約 10% ~ 11% はストレージに関連しています。
しかし、それはアーキテクチャを簡素化するものでもあります。
また、クエリ エンジンが価格とパフォーマンスでさまざまなワークロードを競う時代の到来も告げます。大規模な BI には Snowflake の方が適している可能性があります。 Databricks の AI データ パイプライン用 Spark ; マザーダック インタラクティブ分析用。
データ ウェアハウス ベンダーは、 ストレージとコンピューティングの分離 過去に。しかし、そのメッセージは、自社製品内でより大きなデータを処理できるようにシステムを拡張することに関するものでした。
顧客は、より深い分離、つまりデータベースのストレージ料金がかからない世界を求めています。
- SEO を活用したコンテンツと PR 配信。 今日増幅されます。
- PlatoData.Network 垂直生成 Ai。 自分自身に力を与えましょう。 こちらからアクセスしてください。
- プラトアイストリーム。 Web3 インテリジェンス。 知識増幅。 こちらからアクセスしてください。
- プラトンESG。 カーボン、 クリーンテック、 エネルギー、 環境、 太陽、 廃棄物管理。 こちらからアクセスしてください。
- プラトンヘルス。 バイオテクノロジーと臨床試験のインテリジェンス。 こちらからアクセスしてください。
- 情報源: https://www.tomtunguz.com/why-databases-wont-charge-storage/

