ZOO digitale fornisce servizi multimediali e di localizzazione end-to-end per adattare i contenuti televisivi e cinematografici originali a lingue, regioni e culture diverse. Rende la globalizzazione più semplice per i migliori creatori di contenuti del mondo. Scelto dai più grandi nomi dell'intrattenimento, ZOO Digital offre servizi multimediali e di localizzazione di alta qualità su larga scala, inclusi doppiaggio, sottotitoli, scripting e conformità.
I tipici flussi di lavoro di localizzazione richiedono la diarizzazione manuale dell'oratore, in cui un flusso audio viene segmentato in base all'identità dell'oratore. Questo lungo processo deve essere completato prima che il contenuto possa essere doppiato in un'altra lingua. Con i metodi manuali, la localizzazione di un episodio di 30 minuti può richiedere da 1 a 3 ore. Attraverso l'automazione, ZOO Digital mira a raggiungere la localizzazione in meno di 30 minuti.
In questo post, discutiamo dell'implementazione di modelli scalabili di machine learning (ML) per la diarizzazione dei contenuti multimediali Amazon Sage Maker, con un focus su WhisperX modello.
sfondo
La visione di ZOO Digital è fornire una consegna più rapida dei contenuti localizzati. Questo obiettivo è ostacolato dalla natura intensiva dell'esercizio manuale, aggravata dalla piccola forza lavoro di persone qualificate in grado di localizzare manualmente i contenuti. ZOO Digital lavora con oltre 11,000 freelance e ha localizzato oltre 600 milioni di parole solo nel 2022. Tuttavia, l’offerta di personale qualificato viene superata dalla crescente domanda di contenuti, che richiede l’automazione per assistere nei flussi di lavoro di localizzazione.
Con l'obiettivo di accelerare la localizzazione dei flussi di lavoro dei contenuti attraverso l'apprendimento automatico, ZOO Digital ha coinvolto AWS Prototyping, un programma di investimento di AWS per co-creare carichi di lavoro con i clienti. L'impegno si è concentrato sulla fornitura di una soluzione funzionale per il processo di localizzazione, fornendo al contempo formazione pratica agli sviluppatori ZOO Digital su SageMaker, Amazon Transcribee Amazon Traduttore.
Sfida del cliente
Dopo aver trascritto un titolo (un film o un episodio di una serie TV), è necessario assegnare i relatori a ciascun segmento del discorso in modo che possano essere correttamente assegnati ai doppiatori scelti per interpretare i personaggi. Questo processo è chiamato diarizzazione degli oratori. ZOO Digital affronta la sfida di diarizzare i contenuti su larga scala pur essendo economicamente fattibile.
Panoramica della soluzione
In questo prototipo, abbiamo archiviato i file multimediali originali in un formato specificato Servizio di archiviazione semplice Amazon (Amazon S3) secchio. Questo bucket S3 è stato configurato per emettere un evento quando vengono rilevati nuovi file al suo interno, attivando un file AWS Lambda funzione. Per istruzioni sulla configurazione di questo trigger, fare riferimento al tutorial Utilizzo di un trigger Amazon S3 per richiamare una funzione Lambda. Successivamente, la funzione Lambda ha richiamato l'endpoint SageMaker per l'inferenza utilizzando il file Client Boto3 SageMaker Runtime.
I WhisperX modello, basato su Il sussurro di OpenAI, esegue trascrizioni e diarizzazione per risorse multimediali. È costruito su Sussurro più veloce reimplementazione, offrendo una trascrizione fino a quattro volte più veloce con un migliore allineamento del timestamp a livello di parola rispetto a Whisper. Inoltre, introduce la diarizzazione degli altoparlanti, non presente nel modello Whisper originale. WhisperX utilizza il modello Whisper per le trascrizioni, il Wav2Vec2 modello per migliorare l'allineamento del timestamp (garantendo la sincronizzazione del testo trascritto con i timestamp audio) e il pyannote modello di diarizzazione. FFmpeg viene utilizzato per caricare l'audio dal supporto sorgente, supportando vari formati multimediali. L'architettura del modello trasparente e modulare consente flessibilità, poiché ogni componente del modello può essere sostituito in base alle esigenze future. Tuttavia, è essenziale notare che WhisperX non dispone di funzionalità di gestione complete e non è un prodotto di livello aziendale. Senza manutenzione e supporto, potrebbe non essere adatto alla distribuzione in produzione.
In questa collaborazione, abbiamo distribuito e valutato WhisperX su SageMaker, utilizzando un endpoint di inferenza asincrona per ospitare il modello. Gli endpoint asincroni SageMaker supportano dimensioni di caricamento fino a 1 GB e incorporano funzionalità di scalabilità automatica che mitigano in modo efficiente i picchi di traffico e riducono i costi durante le ore non di punta. Gli endpoint asincroni sono particolarmente adatti per l'elaborazione di file di grandi dimensioni, come film e serie TV nel nostro caso d'uso.
Il diagramma seguente illustra gli elementi principali degli esperimenti che abbiamo condotto in questa collaborazione.

Nelle sezioni seguenti, approfondiamo i dettagli della distribuzione del modello WhisperX su SageMaker e valutiamo le prestazioni di diarizzazione.
Scarica il modello e i suoi componenti
WhisperX è un sistema che include più modelli per la trascrizione, l'allineamento forzato e la diarizzazione. Per un funzionamento regolare di SageMaker senza la necessità di recuperare gli artefatti del modello durante l'inferenza, è essenziale pre-scaricare tutti gli artefatti del modello. Questi artefatti vengono quindi caricati nel contenitore di servizio SageMaker durante l'avvio. Poiché questi modelli non sono direttamente accessibili, offriamo descrizioni e codice di esempio dal sorgente WhisperX, fornendo istruzioni su come scaricare il modello e i suoi componenti.
WhisperX utilizza sei modelli:
La maggior parte di questi modelli può essere ottenuta da Abbracciare il viso utilizzando la libreria Huggingface_hub. Usiamo quanto segue download_hf_model() funzione per recuperare questi artefatti del modello. È richiesto un token di accesso di Hugging Face, generato dopo aver accettato i contratti d'uso per i seguenti modelli pyannote:
import huggingface_hub
import yaml
import torchaudio
import urllib.request
import os
CONTAINER_MODEL_DIR = "/opt/ml/model"
WHISPERX_MODEL = "guillaumekln/faster-whisper-large-v2"
VAD_MODEL_URL = "https://whisperx.s3.eu-west-2.amazonaws.com/model_weights/segmentation/0b5b3216d60a2d32fc086b47ea8c67589aaeb26b7e07fcbe620d6d0b83e209ea/pytorch_model.bin"
WAV2VEC2_MODEL = "WAV2VEC2_ASR_BASE_960H"
DIARIZATION_MODEL = "pyannote/speaker-diarization"
def download_hf_model(model_name: str, hf_token: str, local_model_dir: str) -> str:
"""
Fetches the provided model from HuggingFace and returns the subdirectory it is downloaded to
:param model_name: HuggingFace model name (and an optional version, appended with @[version])
:param hf_token: HuggingFace access token authorized to access the requested model
:param local_model_dir: The local directory to download the model to
:return: The subdirectory within local_modeL_dir that the model is downloaded to
"""
model_subdir = model_name.split('@')[0]
huggingface_hub.snapshot_download(model_subdir, token=hf_token, local_dir=f"{local_model_dir}/{model_subdir}", local_dir_use_symlinks=False)
return model_subdir
Il modello VAD viene recuperato da Amazon S3 e il modello Wav2Vec2 viene recuperato dal modulo torchaudio.pipelines. In base al codice seguente, possiamo recuperare tutti gli artefatti dei modelli, inclusi quelli di Hugging Face, e salvarli nella directory del modello locale specificata:
def fetch_models(hf_token: str, local_model_dir="./models"):
"""
Fetches all required models to run WhisperX locally without downloading models every time
:param hf_token: A huggingface access token to download the models
:param local_model_dir: The directory to download the models to
"""
# Fetch Faster Whisper's Large V2 model from HuggingFace
download_hf_model(model_name=WHISPERX_MODEL, hf_token=hf_token, local_model_dir=local_model_dir)
# Fetch WhisperX's VAD Segmentation model from S3
vad_model_dir = "whisperx/vad"
if not os.path.exists(f"{local_model_dir}/{vad_model_dir}"):
os.makedirs(f"{local_model_dir}/{vad_model_dir}")
urllib.request.urlretrieve(VAD_MODEL_URL, f"{local_model_dir}/{vad_model_dir}/pytorch_model.bin")
# Fetch the Wav2Vec2 alignment model
torchaudio.pipelines.__dict__[WAV2VEC2_MODEL].get_model(dl_kwargs={"model_dir": f"{local_model_dir}/wav2vec2/"})
# Fetch pyannote's Speaker Diarization model from HuggingFace
download_hf_model(model_name=DIARIZATION_MODEL,
hf_token=hf_token,
local_model_dir=local_model_dir)
# Read in the Speaker Diarization model config to fetch models and update with their local paths
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'r') as file:
diarization_config = yaml.safe_load(file)
embedding_model = diarization_config['pipeline']['params']['embedding']
embedding_model_dir = download_hf_model(model_name=embedding_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['embedding'] = f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}"
segmentation_model = diarization_config['pipeline']['params']['segmentation']
segmentation_model_dir = download_hf_model(model_name=segmentation_model,
hf_token=hf_token,
local_model_dir=local_model_dir)
diarization_config['pipeline']['params']['segmentation'] = f"{CONTAINER_MODEL_DIR}/{segmentation_model_dir}/pytorch_model.bin"
with open(f"{local_model_dir}/{DIARIZATION_MODEL}/config.yaml", 'w') as file:
yaml.safe_dump(diarization_config, file)
# Read in the Speaker Embedding model config to update it with its local path
speechbrain_hyperparams_path = f"{local_model_dir}/{embedding_model_dir}/hyperparams.yaml"
with open(speechbrain_hyperparams_path, 'r') as file:
speechbrain_hyperparams = file.read()
speechbrain_hyperparams = speechbrain_hyperparams.replace(embedding_model_dir, f"{CONTAINER_MODEL_DIR}/{embedding_model_dir}")
with open(speechbrain_hyperparams_path, 'w') as file:
file.write(speechbrain_hyperparams)
Seleziona il contenitore AWS Deep Learning appropriato per servire il modello
Dopo aver salvato gli artefatti del modello utilizzando il codice di esempio precedente, è possibile scegliere quelli precostruiti Contenitori per l'apprendimento profondo AWS (DLC) dai seguenti Repository GitHub. Quando selezioni l'immagine Docker, considera le seguenti impostazioni: framework (Hugging Face), attività (inferenza), versione Python e hardware (ad esempio, GPU). Ti consigliamo di utilizzare la seguente immagine: 763104351884.dkr.ecr.[REGION].amazonaws.com/huggingface-pytorch-inference:2.0.0-transformers4.28.1-gpu-py310-cu118-ubuntu20.04 Questa immagine ha tutti i pacchetti di sistema necessari preinstallati, come ffmpeg. Ricordati di sostituire [REGION] con la regione AWS che stai utilizzando.
Per altri pacchetti Python richiesti, creare un file requirements.txt file con un elenco di pacchetti e le loro versioni. Questi pacchetti verranno installati quando verrà creato il DLC AWS. Di seguito sono riportati i pacchetti aggiuntivi necessari per ospitare il modello WhisperX su SageMaker:
Creare uno script di inferenza per caricare i modelli ed eseguire l'inferenza
Successivamente, creiamo un file personalizzato inference.py script per delineare come il modello WhisperX e i suoi componenti vengono caricati nel contenitore e come dovrebbe essere eseguito il processo di inferenza. Lo script contiene due funzioni: model_fn ed transform_fn. model_fn viene richiamata la funzione per caricare i modelli dalle rispettive posizioni. Successivamente, questi modelli vengono passati al transform_fn funzione durante l'inferenza, dove vengono eseguiti i processi di trascrizione, allineamento e diarizzazione. Di seguito è riportato un esempio di codice per inference.py:
import io
import json
import logging
import tempfile
import time
import torch
import whisperx
DEVICE = 'cuda' if torch.cuda.is_available() else 'cpu'
def model_fn(model_dir: str) -> dict:
"""
Deserialize and return the models
"""
logging.info("Loading WhisperX model")
model = whisperx.load_model(whisper_arch=f"{model_dir}/guillaumekln/faster-whisper-large-v2",
device=DEVICE,
language="en",
compute_type="float16",
vad_options={'model_fp': f"{model_dir}/whisperx/vad/pytorch_model.bin"})
logging.info("Loading alignment model")
align_model, metadata = whisperx.load_align_model(language_code="en",
device=DEVICE,
model_name="WAV2VEC2_ASR_BASE_960H",
model_dir=f"{model_dir}/wav2vec2")
logging.info("Loading diarization model")
diarization_model = whisperx.DiarizationPipeline(model_name=f"{model_dir}/pyannote/speaker-diarization/config.yaml",
device=DEVICE)
return {
'model': model,
'align_model': align_model,
'metadata': metadata,
'diarization_model': diarization_model
}
def transform_fn(model: dict, request_body: bytes, request_content_type: str, response_content_type="application/json") -> (str, str):
"""
Load in audio from the request, transcribe and diarize, and return JSON output
"""
# Start a timer so that we can log how long inference takes
start_time = time.time()
# Unpack the models
whisperx_model = model['model']
align_model = model['align_model']
metadata = model['metadata']
diarization_model = model['diarization_model']
# Load the media file (the request_body as bytes) into a temporary file, then use WhisperX to load the audio from it
logging.info("Loading audio")
with io.BytesIO(request_body) as file:
tfile = tempfile.NamedTemporaryFile(delete=False)
tfile.write(file.read())
audio = whisperx.load_audio(tfile.name)
# Run transcription
logging.info("Transcribing audio")
result = whisperx_model.transcribe(audio, batch_size=16)
# Align the outputs for better timings
logging.info("Aligning outputs")
result = whisperx.align(result["segments"], align_model, metadata, audio, DEVICE, return_char_alignments=False)
# Run diarization
logging.info("Running diarization")
diarize_segments = diarization_model(audio)
result = whisperx.assign_word_speakers(diarize_segments, result)
# Calculate the time it took to perform the transcription and diarization
end_time = time.time()
elapsed_time = end_time - start_time
logging.info(f"Transcription and Diarization took {int(elapsed_time)} seconds")
# Return the results to be stored in S3
return json.dumps(result), response_content_type
All'interno della directory del modello, accanto a requirements.txt file, assicurarsi della presenza di inference.py in una sottodirectory del codice. IL models la directory dovrebbe essere simile alla seguente:
Crea un tarball dei modelli
Dopo aver creato i modelli e le directory del codice, puoi utilizzare le seguenti righe di comando per comprimere il modello in un file tar (file .tar.gz) e caricarlo su Amazon S3. Al momento in cui scriviamo, utilizzando il modello Large V2 più veloce, il tarball risultante che rappresenta il modello SageMaker ha una dimensione di 3 GB. Per ulteriori informazioni, fare riferimento a Modelli di hosting dei modelli in Amazon SageMaker, Parte 2: Introduzione alla distribuzione di modelli in tempo reale su SageMaker.
Crea un modello SageMaker e distribuisci un endpoint con un predittore asincrono
Ora puoi creare il modello SageMaker, la configurazione dell'endpoint e l'endpoint asincrono con AsyncPredictor utilizzando il tarball del modello creato nel passaggio precedente. Per istruzioni, fare riferimento a Creare un endpoint di inferenza asincrono.
Valutare le prestazioni di diarizzazione
Per valutare le prestazioni di diarizzazione del modello WhisperX in vari scenari, abbiamo selezionato tre episodi ciascuno da due titoli inglesi: un titolo drammatico composto da episodi di 30 minuti e un titolo documentario composto da episodi di 45 minuti. Abbiamo utilizzato il toolkit di metriche di Pyannote, pyannote.metrics, per calcolare il tasso di errore di diarizzazione (DER). Nella valutazione, le trascrizioni trascritte e diarizzate manualmente fornite da ZOO sono servite come verità fondamentale.
Abbiamo definito il DER come segue:
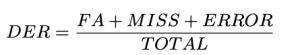
Totale è la durata del video della verità sul terreno. FA (Falso allarme) è la lunghezza dei segmenti considerati come parlato nelle previsioni, ma non nella realtà. Perdere è la lunghezza dei segmenti considerati come discorso nella verità fondamentale, ma non nella previsione. Errore, Anche chiamato Confusione, è la lunghezza dei segmenti assegnati a diversi parlanti nella previsione e nella verità fondamentale. Tutte le unità sono misurate in secondi. I valori tipici per DER possono variare a seconda dell'applicazione specifica, del set di dati e della qualità del sistema di diarizzazione. Tieni presente che DER può essere maggiore di 1.0. Un DER più basso è migliore.
Per poter calcolare il DER per un elemento multimediale, è necessaria una diarizzazione della realtà così come gli output trascritti e diarizzati WhisperX. Questi devono essere analizzati e produrre elenchi di tuple contenenti un'etichetta dell'oratore, l'ora di inizio del segmento del discorso e l'ora di fine del segmento del discorso per ciascun segmento del discorso nei media. Non è necessario che le etichette degli oratori corrispondano tra WhisperX e le diarizzazioni di verità sul campo. I risultati si basano principalmente sul tempo dei segmenti. pyannote.metrics prende queste tuple di diarizzazione di verità e di diarizzazione di output (indicate nella documentazione di pyannote.metrics come riferimento ed ipotesi) per calcolare il DER. La tabella seguente riassume i nostri risultati.
| Tipo di video | IL | Corretta | Perdere | Errore | Falso allarme |
| Dramma | 0.738 | 44.80% | 21.80% | 33.30% | 18.70% |
| Documentario | 1.29 | 94.50% | 5.30% | 0.20% | 123.40% |
| Media | 0.901 | 71.40% | 13.50% | 15.10% | 61.50% |
Questi risultati rivelano una differenza significativa nelle prestazioni tra i titoli drammatici e quelli documentari, con il modello che ottiene risultati notevolmente migliori (utilizzando DER come metrica aggregata) per gli episodi drammatici rispetto al titolo documentario. Un’analisi più approfondita dei titoli fornisce informazioni sui potenziali fattori che contribuiscono a questo divario di prestazioni. Un fattore chiave potrebbe essere la frequente presenza di musica di sottofondo sovrapposta al parlato nel titolo del documentario. Sebbene la preelaborazione dei media per migliorare la precisione della diarizzazione, come la rimozione del rumore di fondo per isolare il parlato, andasse oltre lo scopo di questo prototipo, apre strade per lavori futuri che potrebbero potenzialmente migliorare le prestazioni di WhisperX.
Conclusione
In questo post, abbiamo esplorato la partnership di collaborazione tra AWS e ZOO Digital, utilizzando tecniche di machine learning con SageMaker e il modello WhisperX per migliorare il flusso di lavoro di diarizzazione. Il team AWS ha svolto un ruolo fondamentale nell'assistere ZOO nella prototipazione, valutazione e comprensione dell'implementazione efficace di modelli ML personalizzati, progettati specificamente per la diarizzazione. Ciò includeva l'integrazione del ridimensionamento automatico per la scalabilità utilizzando SageMaker.
Sfruttare l'intelligenza artificiale per la diarizzazione porterà a notevoli risparmi sia in termini di costi che di tempo durante la generazione di contenuti localizzati per ZOO. Aiutando i trascrittori a creare e identificare i relatori in modo rapido e preciso, questa tecnologia risolve la natura tradizionalmente lunga e soggetta a errori del compito. Il processo convenzionale spesso prevede più passaggi attraverso il video e ulteriori passaggi di controllo qualità per ridurre al minimo gli errori. L’adozione dell’intelligenza artificiale per la diarizzazione consente un approccio più mirato ed efficiente, aumentando così la produttività in un arco di tempo più breve.
Abbiamo delineato i passaggi chiave per distribuire il modello WhisperX sull'endpoint asincrono SageMaker e ti invitiamo a provarlo tu stesso utilizzando il codice fornito. Per ulteriori approfondimenti sui servizi e sulla tecnologia di ZOO Digital, visita Sito ufficiale di ZOO Digital. Per dettagli sulla distribuzione del modello OpenAI Whisper su SageMaker e varie opzioni di inferenza, fare riferimento a Ospita il modello Whisper su Amazon SageMaker: esplora le opzioni di inferenza. Sentiti libero di condividere i tuoi pensieri nei commenti.
Informazioni sugli autori
 Ying Hou, dottorato di ricerca, è un architetto di prototipazione di machine learning presso AWS. Le sue principali aree di interesse comprendono il deep learning, con particolare attenzione alla GenAI, alla visione artificiale, alla PNL e alla previsione dei dati delle serie temporali. Nel tempo libero ama trascorrere momenti di qualità con la sua famiglia, immergersi nei romanzi e fare escursioni nei parchi nazionali del Regno Unito.
Ying Hou, dottorato di ricerca, è un architetto di prototipazione di machine learning presso AWS. Le sue principali aree di interesse comprendono il deep learning, con particolare attenzione alla GenAI, alla visione artificiale, alla PNL e alla previsione dei dati delle serie temporali. Nel tempo libero ama trascorrere momenti di qualità con la sua famiglia, immergersi nei romanzi e fare escursioni nei parchi nazionali del Regno Unito.
 Ethan Cumberland è un ingegnere di ricerca sull'intelligenza artificiale presso ZOO Digital, dove lavora sull'utilizzo dell'intelligenza artificiale e dell'apprendimento automatico come tecnologie assistive per migliorare i flussi di lavoro nel parlato, nel linguaggio e nella localizzazione. Ha un background in ingegneria del software e ricerca nel settore della sicurezza e della polizia, concentrandosi sull'estrazione di informazioni strutturate dal Web e sullo sfruttamento di modelli ML open source per analizzare e arricchire i dati raccolti.
Ethan Cumberland è un ingegnere di ricerca sull'intelligenza artificiale presso ZOO Digital, dove lavora sull'utilizzo dell'intelligenza artificiale e dell'apprendimento automatico come tecnologie assistive per migliorare i flussi di lavoro nel parlato, nel linguaggio e nella localizzazione. Ha un background in ingegneria del software e ricerca nel settore della sicurezza e della polizia, concentrandosi sull'estrazione di informazioni strutturate dal Web e sullo sfruttamento di modelli ML open source per analizzare e arricchire i dati raccolti.
 Gaurav Kaila guida il team di prototipazione AWS per il Regno Unito e l'Irlanda. Il suo team lavora con clienti di diversi settori per ideare e co-sviluppare carichi di lavoro aziendali critici con il mandato di accelerare l'adozione dei servizi AWS.
Gaurav Kaila guida il team di prototipazione AWS per il Regno Unito e l'Irlanda. Il suo team lavora con clienti di diversi settori per ideare e co-sviluppare carichi di lavoro aziendali critici con il mandato di accelerare l'adozione dei servizi AWS.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/streamline-diarization-using-ai-as-an-assistive-technology-zoo-digitals-story/

