Sono stati compiuti enormi progressi nel campo del deep learning distribuito per modelli linguistici di grandi dimensioni (LLM), soprattutto dopo il rilascio di ChatGPT nel dicembre 2022. I LLM continuano a crescere di dimensioni con miliardi o addirittura trilioni di parametri, e spesso non lo faranno adattarsi a un singolo dispositivo di accelerazione come GPU o anche a un singolo nodo come ml.p5.32xlarge a causa delle limitazioni di memoria. I clienti che formano LLM spesso devono distribuire il proprio carico di lavoro su centinaia o addirittura migliaia di GPU. Consentire una formazione su tale scala rimane una sfida nella formazione distribuita, e la formazione efficiente in un sistema così ampio è un altro problema altrettanto importante. Negli ultimi anni, la comunità di formazione distribuita ha introdotto il parallelismo 3D (parallelismo dei dati, parallelismo delle pipeline e parallelismo dei tensori) e altre tecniche (come il parallelismo delle sequenze e il parallelismo degli esperti) per affrontare tali sfide.
Nel dicembre 2023, Amazon ha annunciato il rilascio del Libreria parallela del modello SageMaker 2.0 (SMP), che raggiunge un'efficienza all'avanguardia nell'addestramento di modelli di grandi dimensioni, insieme a Libreria per il parallelismo dei dati distribuiti SageMaker (SMDDP). Questa versione è un aggiornamento significativo rispetto alla versione 1.x: SMP è ora integrato con PyTorch open source Parallelo dei dati completamente condivisi (FSDP), che consente di utilizzare un'interfaccia familiare durante l'addestramento di modelli di grandi dimensioni ed è compatibile con Motore del trasformatore (TE), sbloccando per la prima volta le tecniche di parallelismo tensoriale insieme a FSDP. Per ulteriori informazioni sulla versione, fare riferimento a La libreria parallela del modello Amazon SageMaker ora accelera i carichi di lavoro FSDP PyTorch fino al 20%.
In questo post esploriamo i vantaggi prestazionali di Amazon Sage Maker (inclusi SMP e SMDDP) e come utilizzare la libreria per addestrare modelli di grandi dimensioni in modo efficiente su SageMaker. Dimostriamo le prestazioni di SageMaker con benchmark su cluster ml.p4d.24xlarge fino a 128 istanze e precisione mista FSDP con bfloat16 per il modello Llama 2. Inizieremo con una dimostrazione delle efficienze di scalabilità quasi lineare per SageMaker, seguita dall'analisi dei contributi di ciascuna funzionalità per un throughput ottimale e terminiamo con un addestramento efficiente con varie lunghezze di sequenza fino a 32,768 attraverso il parallelismo del tensore.
Scalabilità quasi lineare con SageMaker
Per ridurre il tempo di addestramento complessivo per i modelli LLM, preservare un throughput elevato durante la scalabilità su cluster di grandi dimensioni (migliaia di GPU) è fondamentale dato il sovraccarico di comunicazione tra nodi. In questo post, dimostriamo l'efficienza di un ridimensionamento robusto e quasi lineare (variando il numero di GPU per una dimensione totale fissa del problema) sulle istanze p4d che invocano sia SMP che SMDDP.
In questa sezione, dimostriamo le prestazioni di scaling quasi lineare di SMP. Qui addestriamo modelli Llama 2 di varie dimensioni (parametri 7B, 13B e 70B) utilizzando una lunghezza di sequenza fissa di 4,096, il backend SMDDP per la comunicazione collettiva, abilitato TE, una dimensione batch globale di 4 milioni, con da 16 a 128 nodi p4d . La tabella seguente riassume la nostra configurazione ottimale e le prestazioni di addestramento (modello TFLOP al secondo).
| Taglia del modello | Numero di nodi | TFLOP* | sdp* | tp* | scaricare* | Efficienza in scala |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13B | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70B | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Alla data dimensione del modello, lunghezza della sequenza e numero di nodi, mostriamo il throughput e le configurazioni ottimali a livello globale dopo aver esplorato varie combinazioni di sdp, tp e offload di attivazione.
La tabella precedente riassume i numeri di throughput ottimali soggetti al grado di parallelo dei dati condivisi (sdp) (in genere utilizzando lo sharding ibrido FSDP invece dello sharding completo, con maggiori dettagli nella sezione successiva), al grado di tensore parallelo (tp) e alle modifiche del valore di offload dell'attivazione, dimostrando un ridimensionamento quasi lineare per SMP insieme a SMDDP. Ad esempio, considerando la dimensione del modello Llama 2 7B e la lunghezza della sequenza 4,096, nel complesso raggiunge efficienze di scalabilità del 97.0%, 91.6% e 84.1% (rispetto a 16 nodi) rispettivamente a 32, 64 e 128 nodi. Le efficienze di ridimensionamento sono stabili tra le diverse dimensioni del modello e aumentano leggermente man mano che le dimensioni del modello aumentano.
SMP e SMDDP dimostrano efficienze di ridimensionamento simili anche per altre lunghezze di sequenza come 2,048 e 8,192.
Prestazioni della libreria parallela del modello SageMaker 2.0: Llama 2 70B
Le dimensioni dei modelli hanno continuato a crescere negli ultimi anni, insieme a frequenti aggiornamenti delle prestazioni all'avanguardia nella comunità LLM. In questa sezione, illustriamo le prestazioni in SageMaker per il modello Llama 2 utilizzando una dimensione fissa del modello 70B, una lunghezza della sequenza di 4,096 e una dimensione batch globale di 4 milioni. Per confrontare la configurazione e il throughput ottimali a livello globale della tabella precedente (con backend SMDDP, in genere sharding ibrido FSDP e TE), la tabella seguente si estende ad altri throughput ottimali (potenzialmente con parallelismo tensore) con specifiche aggiuntive sul backend distribuito (NCCL e SMDDP) , strategie di partizionamento orizzontale FSDP (sharding completo e ibrido) e abilitazione o meno di TE (impostazione predefinita).
| Taglia del modello | Numero di nodi | TFLOPS | Configurazione TFLOP n. 3 | Miglioramento dei TFLOP rispetto al basale | ||||||||
| . | . | Sharding completo NCCL: #0 | Sharding completo SMDDP: n. 1 | Sharding ibrido SMDDP: n. 2 | Sharding ibrido SMDDP con TE: #3 | sdp* | tp* | scaricare* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70B | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Alla data dimensione del modello, lunghezza della sequenza e numero di nodi, mostriamo il throughput e la configurazione ottimali a livello globale dopo aver esplorato varie combinazioni di sdp, tp e offload di attivazione.
L'ultima versione di SMP e SMDDP supporta molteplici funzionalità tra cui FSDP PyTorch nativo, sharding ibrido esteso e più flessibile, integrazione del motore del trasformatore, parallelismo del tensore e funzionamento collettivo ottimizzato di tutte le raccolte. Per comprendere meglio come SageMaker ottiene una formazione distribuita efficiente per i LLM, esploriamo i contributi incrementali di SMDDP e del seguente SMP caratteristiche principali:
- Miglioramento SMDDP rispetto a NCCL con sharding completo FSDP
- Sostituzione dello sharding completo FSDP con lo sharding ibrido, che riduce i costi di comunicazione per migliorare la velocità effettiva
- Un ulteriore incremento della produttività con TE, anche quando il parallelismo del tensore è disabilitato
- Con impostazioni di risorse inferiori, l'offload dell'attivazione potrebbe essere in grado di abilitare l'addestramento che altrimenti sarebbe irrealizzabile o molto lento a causa dell'elevata pressione della memoria
Sharding completo FSDP: miglioramento SMDDP rispetto a NCCL
Come mostrato nella tabella precedente, quando i modelli sono completamente partizionati con FSDP, sebbene i throughput NCCL (TFLOPs #0) e SMDDP (TFLOPs #1) siano paragonabili a 32 o 64 nodi, si verifica un enorme miglioramento del 50.4% da NCCL a SMDDP a 128 nodi.
Con modelli di dimensioni più piccole, osserviamo miglioramenti consistenti e significativi con SMDDP rispetto a NCCL, a partire da dimensioni di cluster più piccole, perché SMDDP è in grado di mitigare efficacemente il collo di bottiglia della comunicazione.
Sharding ibrido FSDP per ridurre i costi di comunicazione
In SMP 1.0 abbiamo lanciato parallelismo dei dati frammentati, una tecnica di formazione distribuita sviluppata internamente da Amazon MiCS tecnologia. In SMP 2.0, introduciamo lo sharding ibrido SMP, una tecnica di sharding ibrido estensibile e più flessibile che consente di eseguire lo sharding dei modelli tra un sottoinsieme di GPU, invece che tra tutte le GPU di addestramento, come nel caso dello sharding completo FSDP. È utile per i modelli di medie dimensioni che non necessitano di essere suddivisi in partizioni nell'intero cluster per soddisfare i vincoli di memoria per GPU. Ciò porta i cluster ad avere più di una replica del modello e ciascuna GPU a comunicare con meno peer in fase di runtime.
Lo sharding ibrido di SMP consente uno sharding efficiente del modello su una gamma più ampia, dal grado di sharding più piccolo senza problemi di memoria insufficiente fino alla dimensione dell'intero cluster (che equivale allo sharding completo).
La figura seguente illustra per semplicità la dipendenza del throughput da sdp a tp = 1. Sebbene non sia necessariamente uguale al valore tp ottimale per lo sharding completo NCCL o SMDDP nella tabella precedente, i numeri sono abbastanza vicini. Convalida chiaramente il valore del passaggio dallo sharding completo allo sharding ibrido con cluster di grandi dimensioni di 128 nodi, applicabile sia a NCCL che a SMDDP. Per modelli di dimensioni più piccole, miglioramenti significativi con lo sharding ibrido iniziano con dimensioni di cluster più piccole e la differenza continua ad aumentare con la dimensione del cluster.
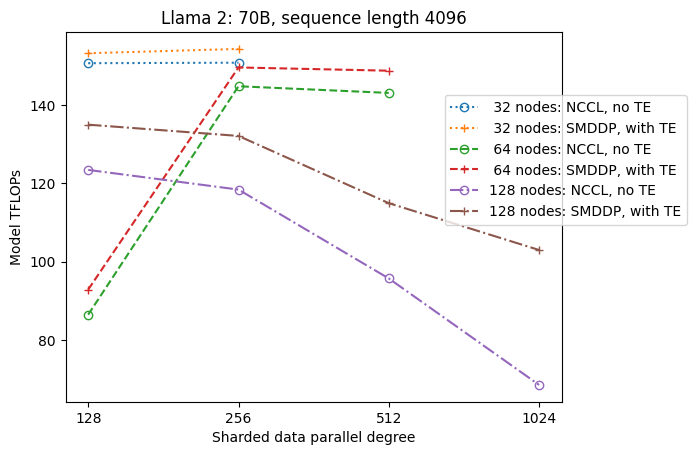
Miglioramenti con TE
TE è progettato per accelerare la formazione LLM sulle GPU NVIDIA. Nonostante non utilizziamo FP8 perché non è supportato sulle istanze p4d, vediamo comunque un aumento significativo della velocità con TE su p4d.
Oltre a MiCS addestrato con il backend SMDDP, TE introduce un aumento coerente del throughput su tutte le dimensioni dei cluster (l'unica eccezione è lo sharding completo a 128 nodi), anche quando il parallelismo del tensore è disabilitato (il grado di parallelo del tensore è 1).
Per modelli di dimensioni più piccole o lunghezze di sequenza diverse, l'incremento TE è stabile e non banale, nell'intervallo di circa il 3–7.6%.
Offload dell'attivazione con impostazioni di risorse basse
Con impostazioni di risorse basse (dato un numero limitato di nodi), FSDP potrebbe riscontrare un utilizzo elevato della memoria (o addirittura memoria insufficiente nel peggiore dei casi) quando il checkpoint di attivazione è abilitato. Per tali scenari con colli di bottiglia dovuti alla memoria, l'attivazione dell'offload dell'attivazione è potenzialmente un'opzione per migliorare le prestazioni.
Ad esempio, come abbiamo visto in precedenza, sebbene Llama 2 con dimensione del modello 13B e lunghezza della sequenza 4,096 sia in grado di addestrarsi in modo ottimale con almeno 32 nodi con checkpoint di attivazione e senza offload di attivazione, raggiunge il miglior throughput con offload di attivazione quando limitato a 16 nodi.
Abilita l'addestramento con sequenze lunghe: parallelismo del tensore SMP
Lunghezze di sequenze più lunghe sono desiderate per conversazioni e contesti lunghi e stanno ricevendo maggiore attenzione nella comunità LLM. Pertanto, riportiamo vari throughput a sequenza lunga nella tabella seguente. La tabella mostra i throughput ottimali per l'addestramento di Llama 2 su SageMaker, con varie lunghezze di sequenza da 2,048 a 32,768. Alla lunghezza della sequenza 32,768, l'addestramento FSDP nativo non è fattibile con 32 nodi con una dimensione batch globale di 4 milioni.
| . | . | . | TFLOPS | ||
| Taglia del modello | Lunghezza della sequenza | Numero di nodi | FSDP e NCCL nativi | SMP e SMDDP | Miglioramento dell'SMP |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13B | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: massimo | . | . | . | . | 8.3% |
| *: mediana | . | . | . | . | 5.8% |
Quando la dimensione del cluster è grande e viene data una dimensione batch globale fissa, alcuni addestramenti del modello potrebbero non essere fattibili con PyTorch FSDP nativo, in mancanza di una pipeline integrata o del supporto per il parallelismo del tensore. Nella tabella precedente, data una dimensione batch globale di 4 milioni, 32 nodi e una lunghezza di sequenza di 32,768, la dimensione batch effettiva per GPU è 0.5 (ad esempio, tp = 2 con dimensione batch 1), che altrimenti sarebbe irrealizzabile senza introdurre parallelismo tensoriale.
Conclusione
In questo post, abbiamo dimostrato un'efficiente formazione LLM con SMP e SMDDP su istanze p4d, attribuendo contributi a molteplici funzionalità chiave, come il miglioramento SMDDP rispetto a NCCL, lo sharding ibrido FSDP flessibile anziché lo sharding completo, l'integrazione TE e l'abilitazione del parallelismo tensore a favore di sequenze di lunga durata. Dopo essere stato testato su un'ampia gamma di impostazioni con vari modelli, dimensioni di modello e lunghezze di sequenza, mostra robuste efficienze di ridimensionamento quasi lineare, fino a 128 istanze p4d su SageMaker. In sintesi, SageMaker continua a essere un potente strumento per ricercatori e professionisti LLM.
Per saperne di più, fare riferimento a Libreria di parallelismo dei modelli SageMaker v2oppure contatta il team SMP all'indirizzo sm-model-parallel-feedback@amazon.com.
Ringraziamenti
Vorremmo ringraziare Robert Van Dusen, Ben Snyder, Gautam Kumar e Luis Quintela per il loro feedback e le loro discussioni costruttive.
Informazioni sugli autori

Xinle Sheila Liu è un SDE in Amazon SageMaker. Nel tempo libero le piace leggere e fare sport all'aria aperta.
 Suhit Kodgule è un ingegnere di sviluppo software del gruppo Intelligenza Artificiale di AWS che lavora su framework di deep learning. Nel tempo libero gli piace fare escursioni, viaggiare e cucinare.
Suhit Kodgule è un ingegnere di sviluppo software del gruppo Intelligenza Artificiale di AWS che lavora su framework di deep learning. Nel tempo libero gli piace fare escursioni, viaggiare e cucinare.
 Vittorio Zhu è un ingegnere software in Distributed Deep Learning presso Amazon Web Services. Può essere trovato mentre si diverte con escursioni e giochi da tavolo nella zona della baia di San Francisco.
Vittorio Zhu è un ingegnere software in Distributed Deep Learning presso Amazon Web Services. Può essere trovato mentre si diverte con escursioni e giochi da tavolo nella zona della baia di San Francisco.
 Derya Cavdar lavora come ingegnere del software presso AWS. I suoi interessi includono il deep learning e l'ottimizzazione della formazione distribuita.
Derya Cavdar lavora come ingegnere del software presso AWS. I suoi interessi includono il deep learning e l'ottimizzazione della formazione distribuita.
 Teng Xu è un ingegnere di sviluppo software nel gruppo di formazione distribuita in AWS AI. Gli piace leggere.
Teng Xu è un ingegnere di sviluppo software nel gruppo di formazione distribuita in AWS AI. Gli piace leggere.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

