Il lancio di ChatGPT e l'aumento della popolarità dell'intelligenza artificiale generativa hanno catturato l'immaginazione dei clienti che sono curiosi di sapere come utilizzare questa tecnologia per creare nuovi prodotti e servizi su AWS, come i chatbot aziendali, che sono più conversazionali. Questo post mostra come creare un'interfaccia utente Web, che chiamiamo Chat Studio, per avviare una conversazione e interagire con i modelli di base disponibili in JumpStart di Amazon SageMaker come Llama 2, Stable Diffusion e altri modelli disponibili su Amazon Sage Maker. Dopo aver distribuito questa soluzione, gli utenti possono iniziare rapidamente e sperimentare le funzionalità di più modelli di base nell'intelligenza artificiale conversazionale tramite un'interfaccia web.
Chat Studio può anche facoltativamente richiamare l'endpoint del modello Diffusione stabile per restituire un collage di immagini e video pertinenti se l'utente richiede la visualizzazione di contenuti multimediali. Questa funzionalità può aiutare a migliorare l'esperienza dell'utente con l'uso dei media come risorse di accompagnamento alla risposta. Questo è solo un esempio di come puoi arricchire Chat Studio con integrazioni aggiuntive per raggiungere i tuoi obiettivi.
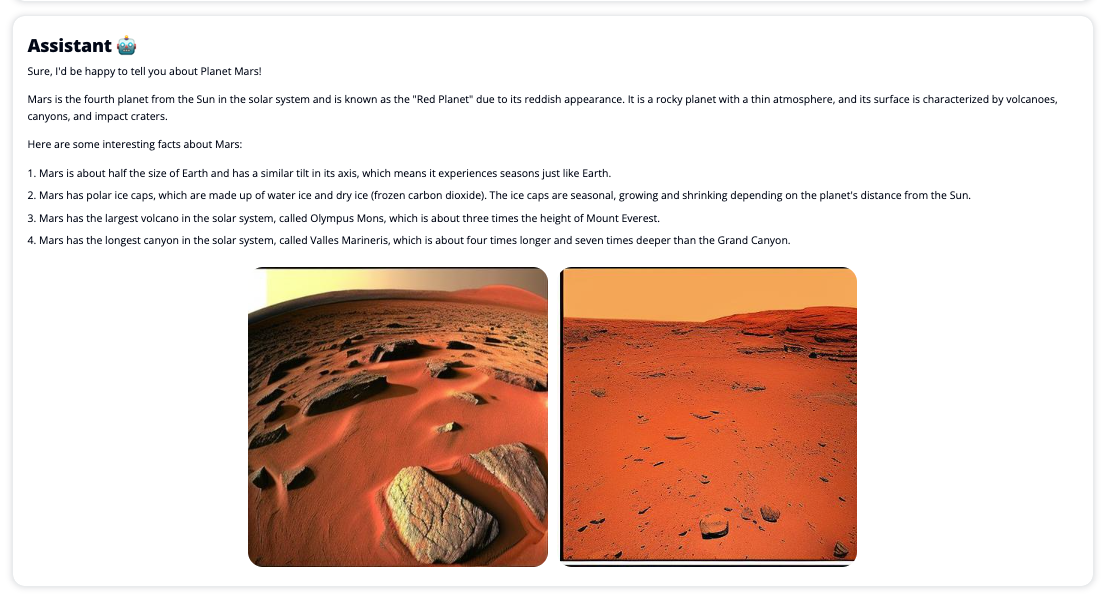
Gli screenshot seguenti mostrano esempi di come appaiono una query e una risposta dell'utente.

Grandi modelli linguistici
I chatbot con intelligenza artificiale generativa come ChatGPT sono alimentati da modelli linguistici di grandi dimensioni (LLM), basati su una rete neurale di deep learning che può essere addestrata su grandi quantità di testo senza etichetta. L'uso di LLM consente una migliore esperienza di conversazione che ricorda da vicino le interazioni con esseri umani reali, favorendo un senso di connessione e una migliore soddisfazione dell'utente.
Modelli di fondazione SageMaker
Nel 2021, lo Stanford Institute for Human-Centered Artificial Intelligence ha definito alcuni LLM come modelli di fondazione. I modelli di base sono pre-addestrati su un insieme ampio e ampio di dati generali e sono pensati per fungere da base per ulteriori ottimizzazioni in un'ampia gamma di casi d'uso, dalla generazione di arte digitale alla classificazione di testi multilingue. Questi modelli di base sono apprezzati dai clienti perché la formazione di un nuovo modello da zero richiede tempo e può essere costosa. SageMaker JumpStart fornisce l'accesso a centinaia di modelli di base gestiti da fornitori proprietari e open source di terze parti.
Panoramica della soluzione
Questo post illustra un flusso di lavoro low-code per la distribuzione di LLM pre-addestrati e personalizzati tramite SageMaker e la creazione di un'interfaccia utente Web per interfacciarsi con i modelli distribuiti. Copriamo i seguenti passaggi:
- Distribuisci i modelli di base SageMaker.
- Schierare AWS Lambda ed Gestione dell'identità e dell'accesso di AWS (IAM) utilizzando le autorizzazioni AWS CloudFormazione.
- Configurare ed eseguire l'interfaccia utente.
- Facoltativamente, aggiungi altri modelli di fondazione SageMaker. Questo passaggio estende la capacità di Chat Studio di interagire con ulteriori modelli di base.
- Facoltativamente, distribuire l'applicazione utilizzando AWS Amplifica. Questo passaggio distribuisce Chat Studio sul Web.
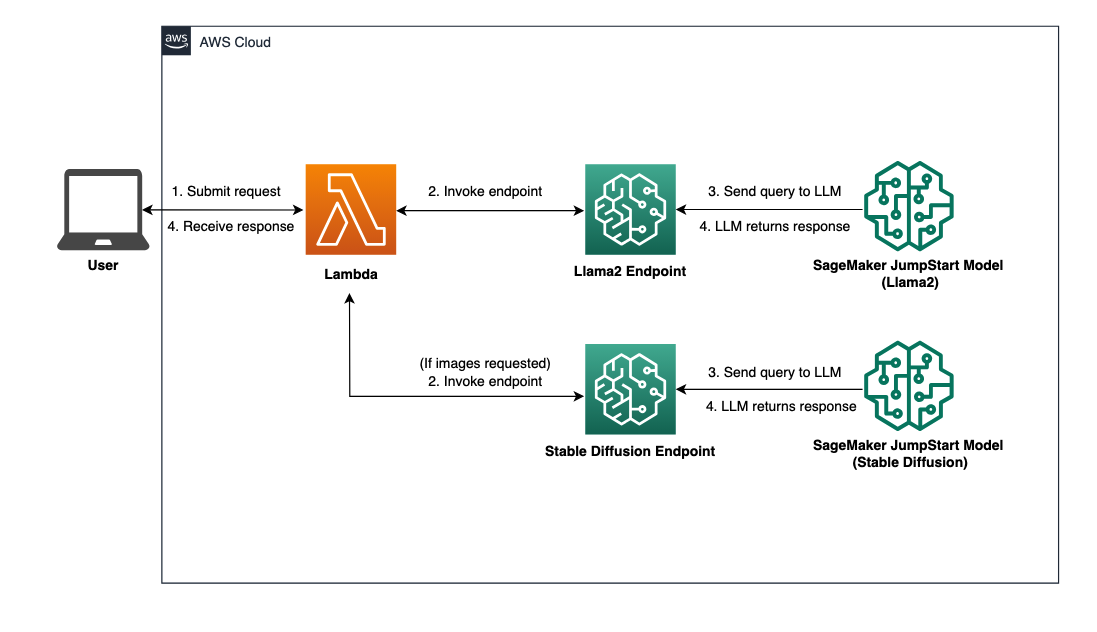
Fare riferimento al diagramma seguente per una panoramica dell'architettura della soluzione.
Prerequisiti
Per esaminare la soluzione, è necessario disporre dei seguenti prerequisiti:
- An Account AWS con sufficienti privilegi utente IAM.
npminstallato nel tuo ambiente locale. Per istruzioni su come installarenpm, fare riferimento a Download e installazione di Node.js e npm.- Una quota di servizio pari a 1 per gli endpoint SageMaker corrispondenti. Per Llama 2 13b Chat, utilizziamo un'istanza ml.g5.48xlarge e per Stable Diffusion 2.1, utilizziamo un'istanza ml.p3.2xlarge.
Per richiedere un aumento della quota del servizio, sul Console Quote di servizio AWS, navigare verso Servizi AWS, SageMakere la richiesta di aumento della quota di servizio al valore 1 per ml.g5.48xlarge per l'utilizzo dell'endpoint e ml.p3.2xlarge per l'utilizzo dell'endpoint.
L'approvazione della richiesta di quota di servizio potrebbe richiedere alcune ore, a seconda della disponibilità del tipo di istanza.
Distribuisci i modelli di base SageMaker
SageMaker è un servizio di machine learning (ML) completamente gestito che consente agli sviluppatori di creare e addestrare rapidamente e con facilità modelli ML. Completare i seguenti passaggi per distribuire i modelli base Llama 2 13b Chat e Stable Diffusion 2.1 utilizzando Amazon Sage Maker Studio:
- Crea un dominio SageMaker. Per istruzioni, fare riferimento a Onboarding nel dominio Amazon SageMaker utilizzando la configurazione rapida.
Un dominio configura tutto lo spazio di archiviazione e ti consente di aggiungere utenti per accedere a SageMaker.
- Sulla console di SageMaker, scegli Studio nel riquadro di navigazione, quindi scegli Apri Studio.
- All'avvio di Studio, sotto SageMaker JumpStart nel pannello di navigazione, scegli Modelli, taccuini, soluzioni.
- Nella barra di ricerca, cerca Llama 2 13b Chat.
- Sotto Configurazione di distribuzione, Per Istanza di hosting SageMakerscegli ml.g5.48xgrande e per Nome dell'endpoint, accedere
meta-textgeneration-llama-2-13b-f. - Scegli Distribuire.
Una volta completata la distribuzione, dovresti essere in grado di vedere il file In Service stato.
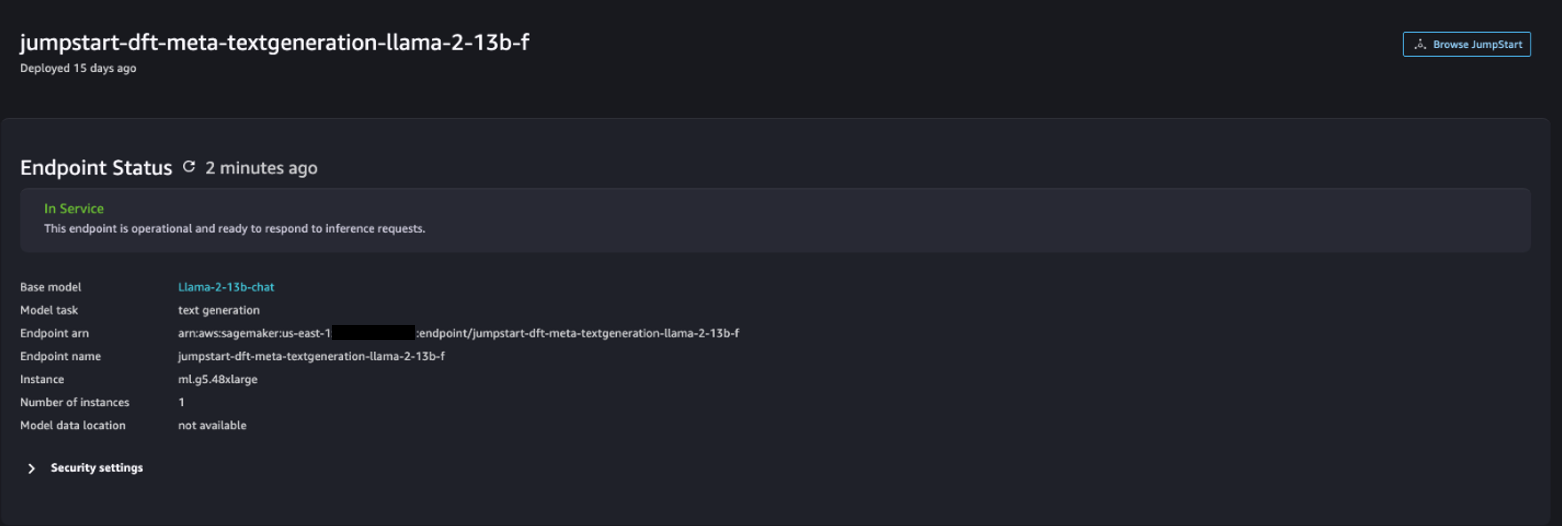
- Sulla Modelli, taccuini, soluzioni pagina, cercare Stable Diffusion 2.1.
- Sotto Configurazione di distribuzione, Per Istanza di hosting SageMakerscegli ml.p3.2xgrande e per Nome dell'endpoint, accedere
jumpstart-dft-stable-diffusion-v2-1-base. - Scegli Schierare.
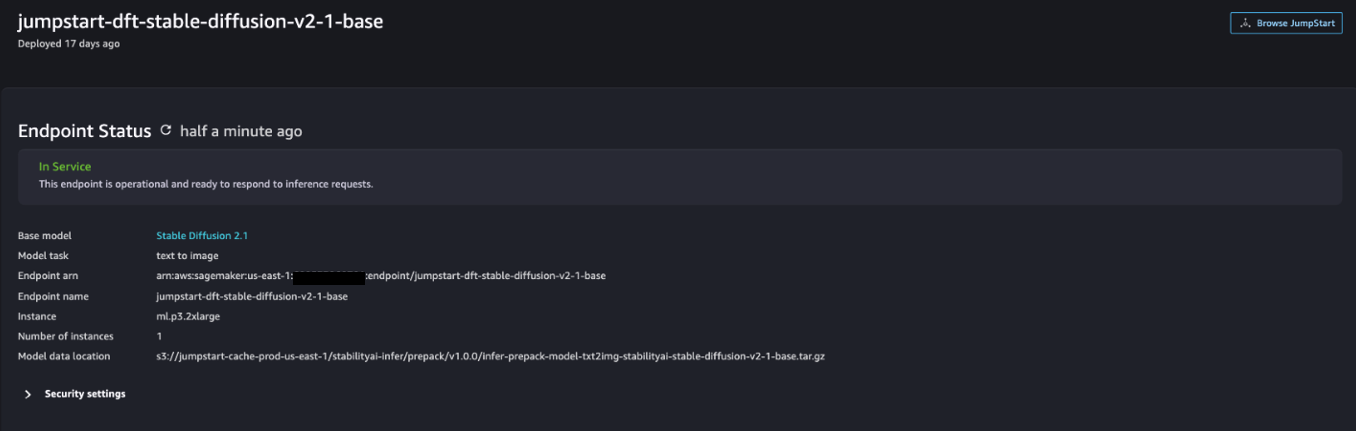
Una volta completata la distribuzione, dovresti essere in grado di vedere il file In Service stato.
Distribuisci le autorizzazioni Lambda e IAM utilizzando AWS CloudFormation
Questa sezione descrive come avviare uno stack CloudFormation che distribuisce una funzione Lambda che elabora la richiesta dell'utente e chiama l'endpoint SageMaker che hai distribuito e distribuisce tutte le autorizzazioni IAM necessarie. Completa i seguenti passaggi:
- Passare alla Repository GitHub e scarica il modello CloudFormation (
lambda.cfn.yaml) sul computer locale. - Nella console CloudFormation, scegli il file Crea stack menu a discesa e scegliere Con nuove risorse (standard).
- Sulla Specifica il modello pagina, selezionare Carica un file modello ed Scegli il file.
- Scegliere il
lambda.cfn.yamlfile scaricato, quindi scegli Avanti. - Sulla Specifica i dettagli dello stack pagina, inserisci un nome di stack e la chiave API ottenuta nei prerequisiti, quindi scegli Avanti.
- Sulla Configura le opzioni di stack pagina, scegli Avanti.
- Rivedi e riconosci le modifiche e scegli Invio.
Configura l'interfaccia utente Web
Questa sezione descrive i passaggi per eseguire l'interfaccia utente Web (creata utilizzando Sistema di progettazione Cloudscape) sul tuo computer locale:
- Nella console IAM, vai all'utente
functionUrl. - Sulla Credenziali di sicurezza scheda, scegliere Crea chiave di accesso.
- Sulla Accedi alle migliori pratiche e alternative chiave pagina, selezionare Command Line Interface (CLI) e scegli Avanti.
- Sulla Imposta il tag di descrizione pagina, scegli Crea chiave di accesso.
- Copia la chiave di accesso e la chiave di accesso segreta.
- Scegli Fatto.
- Passare alla Repository GitHub e scaricare il
react-llm-chat-studiocodice. - Avvia la cartella nel tuo IDE preferito e apri un terminale.
- Spostarsi
src/configs/aws.jsone inserisci la chiave di accesso e la chiave di accesso segreta che hai ottenuto. - Immettere i seguenti comandi nel terminale:
- Apri http://localhost:3000 nel tuo browser e inizia a interagire con i tuoi modelli!
Per utilizzare Chat Studio, scegli un modello fondamentale nel menu a discesa e inserisci la tua query nella casella di testo. Per ottenere immagini generate dall'intelligenza artificiale insieme alla risposta, aggiungi la frase "con immagini" alla fine della query.
Aggiungi altri modelli di fondazione SageMaker
È possibile estendere ulteriormente la capacità di questa soluzione per includere ulteriori modelli di base SageMaker. Poiché ogni modello prevede formati di input e output diversi quando richiama il proprio endpoint SageMaker, dovrai scrivere del codice di trasformazione nella funzione Lambda callSageMakerEndpoints per interfacciarsi con il modello.
Questa sezione descrive i passaggi generali e le modifiche al codice necessarie per implementare un modello aggiuntivo di tua scelta. Tieni presente che per i passaggi 6–8 è richiesta una conoscenza di base del linguaggio Python.
- In SageMaker Studio, distribuisci il modello di base SageMaker di tua scelta.
- Scegli SageMaker JumpStart ed Avvia le risorse JumpStart.
- Scegli l'endpoint del modello appena distribuito e scegli Apri taccuino.
- Sulla console del notebook, trova i parametri del carico utile.
Questi sono i campi che il nuovo modello si aspetta quando richiama il suo endpoint SageMaker. La schermata seguente mostra un esempio.

- Nella console Lambda, vai a
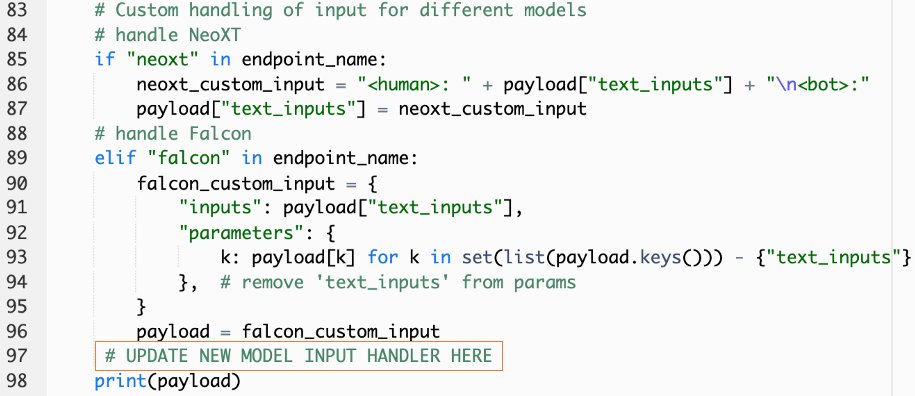
callSageMakerEndpoints. - Aggiungi un gestore di input personalizzato per il tuo nuovo modello.
Nello screenshot seguente, abbiamo trasformato l'input per Falcon 40B Instruct BF16 e GPT NeoXT Chat Base 20B FP16. Puoi inserire la logica dei parametri personalizzati come indicato per aggiungere la logica di trasformazione dell'input con riferimento ai parametri del payload che hai copiato.
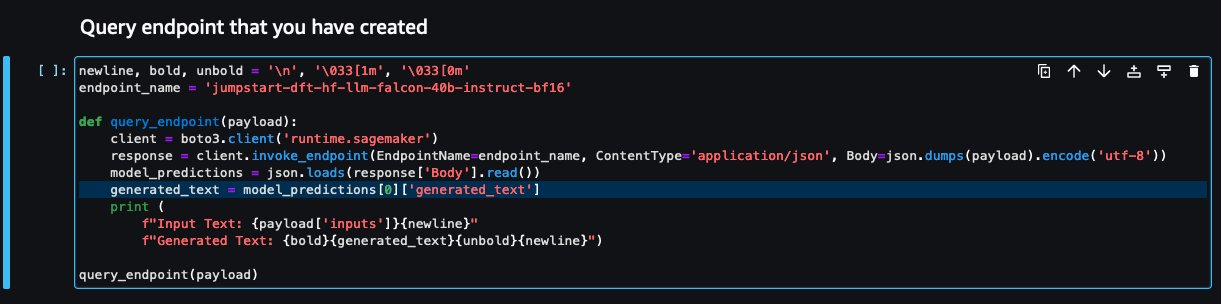
- Ritorna alla console del notebook e individua
query_endpoint.
Questa funzione ti dà un'idea di come trasformare l'output dei modelli per estrarre la risposta testuale finale.
- Con riferimento al codice in
query_endpoint, aggiungi un gestore di output personalizzato per il tuo nuovo modello.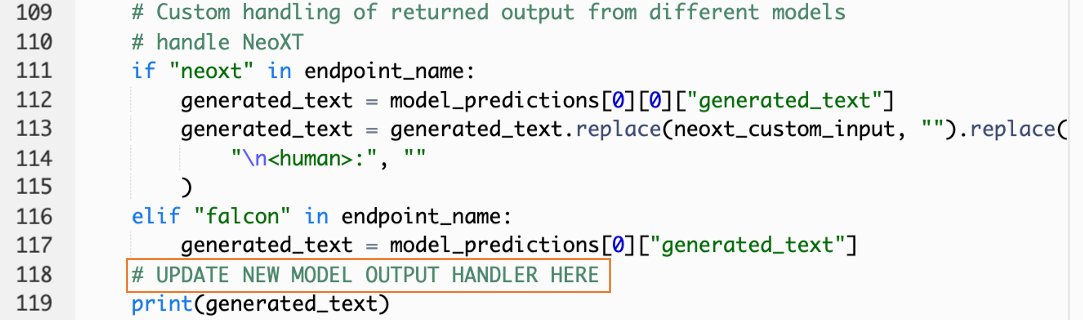
- Scegli Distribuire.
- Apri il tuo IDE, avvia il file
react-llm-chat-studiocodice e accedere asrc/configs/models.json. - Aggiungi il nome del modello e l'endpoint del modello e inserisci i parametri del carico utile dal passaggio 4 di seguito
payloadutilizzando il seguente formato: - Aggiorna il tuo browser per iniziare a interagire con il tuo nuovo modello!
Distribuire l'applicazione utilizzando Amplify
Amplify è una soluzione completa che ti consente di distribuire la tua applicazione in modo rapido ed efficiente. Questa sezione descrive i passaggi per distribuire Chat Studio su un file Amazon CloudFront distribuzione utilizzando Amplify se desideri condividere la tua applicazione con altri utenti.
- Passare alla
react-llm-chat-studiocartella del codice creata in precedenza. - Immettere i seguenti comandi nel terminale e seguire le istruzioni di configurazione:
- Inizializza un nuovo progetto Amplify utilizzando il comando seguente. Fornire un nome di progetto, accettare le configurazioni predefinite e scegliere Chiavi di accesso AWS quando viene richiesto di selezionare il metodo di autenticazione.
- Ospita il progetto Amplify utilizzando il comando seguente. Scegliere Amazon CloudFront e S3 quando viene richiesto di selezionare la modalità plug-in.
- Infine, crea e distribuisci il progetto con il seguente comando:
- Una volta completata la distribuzione, apri l'URL fornito nel tuo browser e inizia a interagire con i tuoi modelli!
ripulire
Per evitare di incorrere in addebiti futuri, completare i seguenti passaggi:
- Elimina lo stack CloudFormation. Per le istruzioni, fare riferimento a Eliminazione di uno stack nella console AWS CloudFormation.
- Elimina l'endpoint SageMaker JumpStart. Per istruzioni, fare riferimento a Elimina endpoint e risorse.
- Elimina il dominio SageMaker. Per istruzioni, fare riferimento a Elimina un dominio Amazon SageMaker.
Conclusione
In questo post, abbiamo spiegato come creare un'interfaccia utente Web per l'interfacciamento con gli LLM distribuiti su AWS.
Con questa soluzione, puoi interagire con il tuo LLM e tenere una conversazione in modo intuitivo per testare o porre domande LLM e ottenere un collage di immagini e video, se necessario.
È possibile estendere questa soluzione in vari modi, ad esempio integrando ulteriori modelli di fondazione, integrarsi con Amazon Kendra per abilitare la ricerca intelligente basata sul machine learning per comprendere i contenuti aziendali e altro ancora!
Ti invitiamo a sperimentare diversi LLM pre-addestrati disponibili su AWSoppure costruisci o addirittura crea i tuoi LLM in SageMaker. Fateci sapere le vostre domande e scoperte nei commenti e buon divertimento!
Circa gli autori
 Jarrett Yeo Shan Wei è un Associate Cloud Architect in AWS Professional Services che copre il settore pubblico in tutta l'ASEAN ed è un sostenitore dell'aiuto ai clienti nella modernizzazione e nella migrazione nel cloud. Ha ottenuto cinque certificazioni AWS e ha anche pubblicato un documento di ricerca sugli insiemi di macchine per il potenziamento del gradiente nell'ottava conferenza internazionale sull'intelligenza artificiale. Nel tempo libero, Jarrett si concentra e contribuisce alla scena dell'intelligenza artificiale generativa in AWS.
Jarrett Yeo Shan Wei è un Associate Cloud Architect in AWS Professional Services che copre il settore pubblico in tutta l'ASEAN ed è un sostenitore dell'aiuto ai clienti nella modernizzazione e nella migrazione nel cloud. Ha ottenuto cinque certificazioni AWS e ha anche pubblicato un documento di ricerca sugli insiemi di macchine per il potenziamento del gradiente nell'ottava conferenza internazionale sull'intelligenza artificiale. Nel tempo libero, Jarrett si concentra e contribuisce alla scena dell'intelligenza artificiale generativa in AWS.
 Tammy Lim Lee Xin è un Associate Cloud Architect presso AWS. Utilizza la tecnologia per aiutare i clienti a ottenere i risultati desiderati nel loro percorso di adozione del cloud ed è appassionata di AI/ML. Fuori dal lavoro ama viaggiare, fare escursioni e passare il tempo con la famiglia e gli amici.
Tammy Lim Lee Xin è un Associate Cloud Architect presso AWS. Utilizza la tecnologia per aiutare i clienti a ottenere i risultati desiderati nel loro percorso di adozione del cloud ed è appassionata di AI/ML. Fuori dal lavoro ama viaggiare, fare escursioni e passare il tempo con la famiglia e gli amici.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/create-a-web-ui-to-interact-with-llms-using-amazon-sagemaker-jumpstart/

