Pelanggan 360 (C360) memberikan pandangan yang lengkap dan terpadu tentang interaksi dan perilaku pelanggan di seluruh titik kontak dan saluran. Tampilan ini digunakan untuk mengidentifikasi pola dan tren perilaku pelanggan, yang dapat menginformasikan keputusan berdasarkan data untuk meningkatkan hasil bisnis. Misalnya, Anda dapat menggunakan C360 untuk melakukan segmentasi dan membuat kampanye pemasaran yang lebih mungkin diterima oleh kelompok pelanggan tertentu.
Pada tahun 2022, AWS menugaskan penelitian yang dilakukan oleh American Productivity and Quality Center (APQC) untuk mengukur Nilai Bisnis Pelanggan 360. Gambar berikut menunjukkan beberapa metrik yang diperoleh dari penelitian ini. Organisasi yang menggunakan C360 mencapai pengurangan durasi siklus penjualan sebesar 43.9%, peningkatan nilai seumur hidup pelanggan sebesar 22.8%, waktu pemasaran yang lebih cepat sebesar 25.3%, dan peningkatan peringkat skor promotor bersih (NPS) sebesar 19.1%.

Tanpa C360, bisnis akan kehilangan peluang, laporan yang tidak akurat, dan pengalaman pelanggan yang terputus-putus, sehingga menyebabkan churn pelanggan. Namun, membuat solusi C360 bisa jadi rumit. A Survei Pemasaran Gartner menemukan hanya 14% organisasi yang berhasil menerapkan solusi C360, karena kurangnya konsensus mengenai arti pandangan 360 derajat, tantangan terhadap kualitas data, dan kurangnya struktur tata kelola lintas fungsi untuk data pelanggan.
Dalam postingan ini, kami membahas bagaimana Anda dapat menggunakan layanan AWS yang dibuat khusus untuk membuat strategi data end-to-end bagi C360 guna menyatukan dan mengatur data pelanggan untuk mengatasi tantangan ini. Kami menyusunnya dalam lima pilar yang mendukung C360: pengumpulan data, penyatuan, analitik, aktivasi, dan tata kelola data, serta arsitektur solusi yang dapat Anda gunakan untuk implementasi Anda.
Lima pilar C360 yang matang
Saat Anda mulai membuat C360, Anda bekerja dengan beberapa kasus penggunaan, jenis data pelanggan, serta pengguna dan aplikasi yang memerlukan alat berbeda. Membangun C360 pada kumpulan data yang tepat, menambahkan kumpulan data baru dari waktu ke waktu dengan tetap menjaga kualitas data, dan menjaganya tetap aman memerlukan strategi data menyeluruh untuk data pelanggan Anda. Anda juga perlu menyediakan alat yang memudahkan tim Anda membuat produk yang menyempurnakan C360 Anda.
Kami merekomendasikan untuk membangun strategi data Anda berdasarkan lima pilar C360, seperti yang ditunjukkan pada gambar berikut. Hal ini dimulai dengan pengumpulan data dasar, menyatukan dan menghubungkan data dari berbagai saluran yang terkait dengan pelanggan unik, dan berlanjut ke analisis dasar hingga lanjutan untuk pengambilan keputusan, dan keterlibatan yang dipersonalisasi melalui berbagai saluran. Saat Anda semakin matang dalam masing-masing pilar ini, Anda mengalami kemajuan dalam merespons sinyal pelanggan secara real-time.
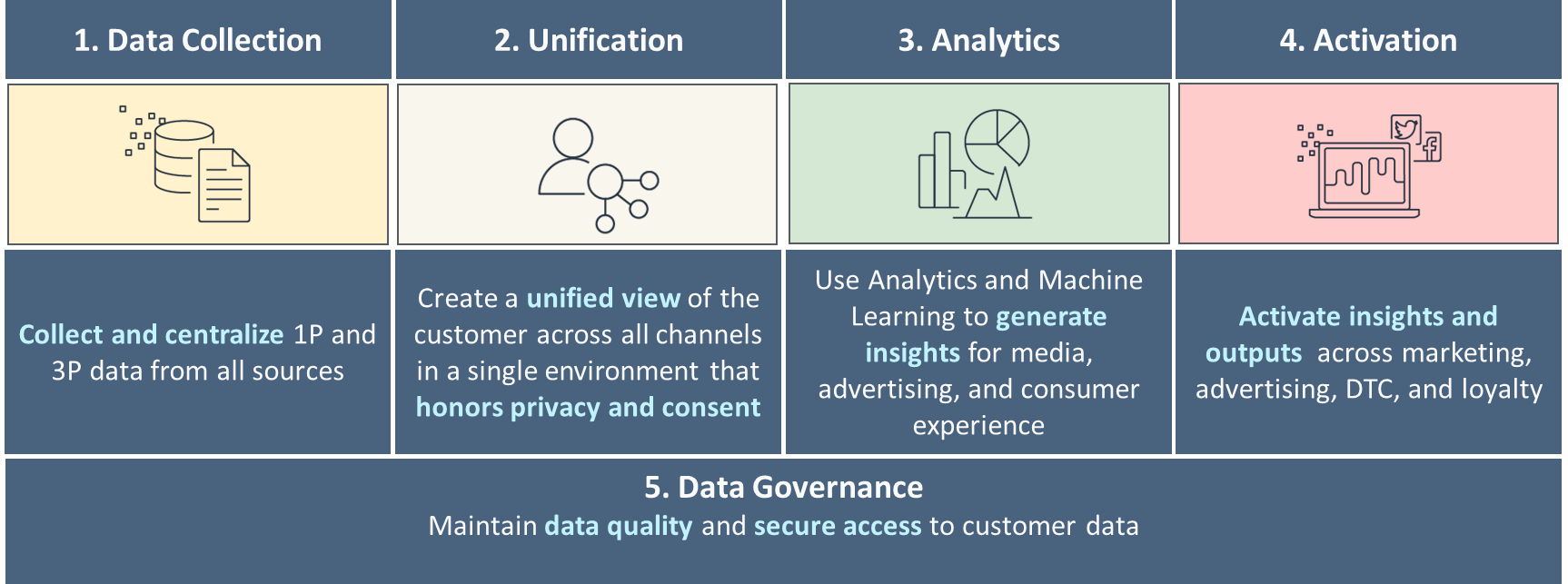
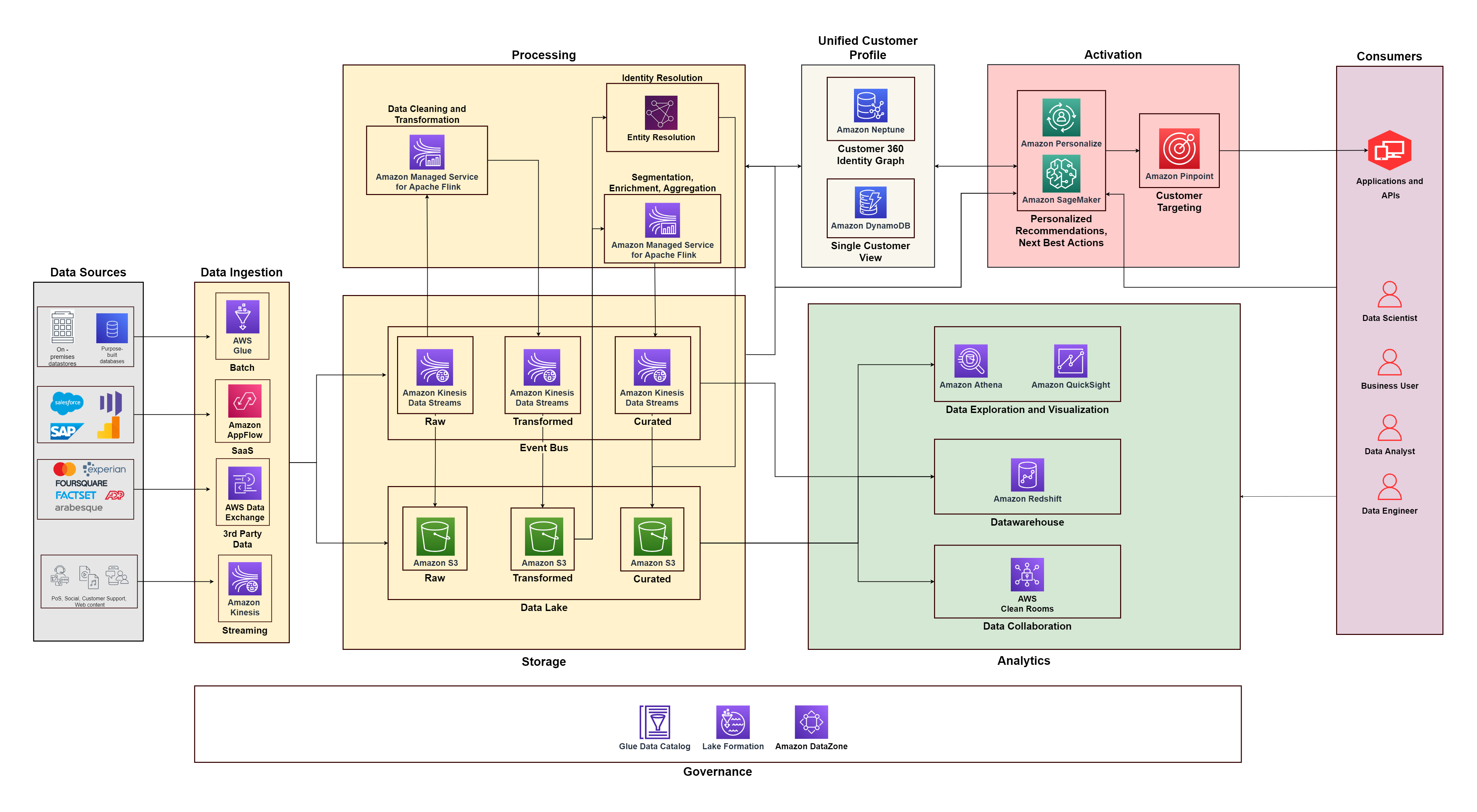
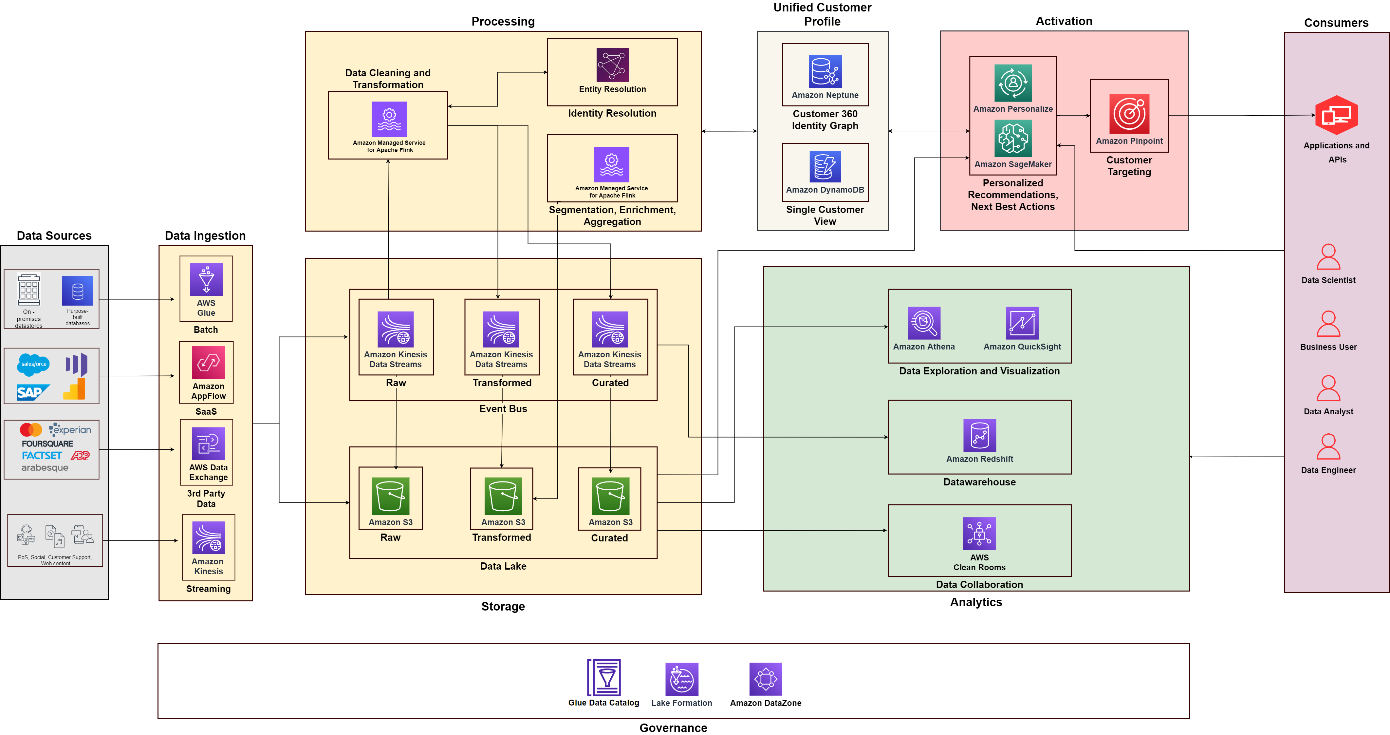
Diagram berikut mengilustrasikan arsitektur fungsional yang menggabungkan blok bangunan a Platform Data Pelanggan di AWS dengan komponen tambahan yang digunakan untuk merancang solusi C360 end-to-end. Hal ini selaras dengan lima pilar yang kita bahas pada postingan kali ini.
Pilar 1: Pengumpulan data
Saat Anda mulai membangun platform data pelanggan, Anda harus mengumpulkan data dari berbagai sistem dan titik kontak, seperti sistem penjualan, dukungan pelanggan, web dan media sosial, serta pasar data. Bayangkan pilar pengumpulan data sebagai kombinasi kemampuan penyerapan, penyimpanan, dan pemrosesan.
Penyerapan data
Anda harus membangun jalur penyerapan berdasarkan faktor-faktor seperti jenis sumber data (penyimpanan data lokal, file, aplikasi SaaS, data pihak ketiga), dan aliran data (aliran tidak terbatas atau data batch). AWS menyediakan layanan berbeda untuk membangun jalur penyerapan data:
- Lem AWS adalah layanan integrasi data tanpa server yang menyerap data dalam batch dari database lokal dan penyimpanan data di cloud. Ini terhubung ke lebih dari 70 sumber data dan membantu Anda membangun pipeline ekstrak, transformasi, dan muat (ETL) tanpa harus mengelola infrastruktur pipeline. Kualitas Data AWS Glue memeriksa dan memperingatkan data yang buruk, sehingga memudahkan untuk menemukan dan memperbaiki masalah sebelum membahayakan bisnis Anda.
- Alur Aplikasi Amazon menyerap data dari aplikasi perangkat lunak sebagai layanan (SaaS) seperti Google Analytics, Salesforce, SAP, dan Marketo, memberi Anda fleksibilitas untuk menyerap data dari lebih dari 50 aplikasi SaaS.
- Pertukaran Data AWS memudahkan untuk menemukan, berlangganan, dan menggunakan data pihak ketiga untuk analisis. Anda dapat berlangganan produk data yang membantu memperkaya profil pelanggan, misalnya data demografi, data periklanan, dan data pasar keuangan.
- Amazon Kinesis menyerap acara streaming secara real-time dari sistem point-of-sales, data clickstream dari aplikasi seluler dan situs web, dan data media sosial. Anda juga dapat mempertimbangkan untuk menggunakan Amazon Managed Streaming untuk Apache Kafka (Amazon MSK) untuk streaming acara secara real-time.
Diagram berikut mengilustrasikan alur berbeda untuk menyerap data dari berbagai sistem sumber menggunakan layanan AWS.
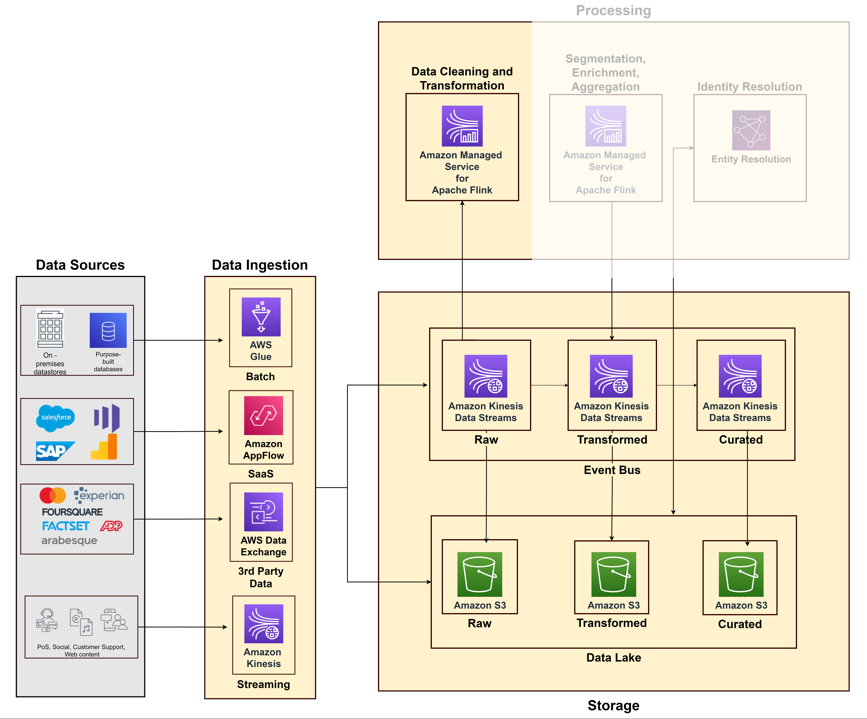
Penyimpanan data
Data batch terstruktur, semi-terstruktur, atau tidak terstruktur disimpan dalam penyimpanan objek karena hemat biaya dan tahan lama. Layanan Penyimpanan Sederhana Amazon (Amazon S3) adalah layanan penyimpanan terkelola dengan fitur pengarsipan yang dapat menyimpan data berukuran petabyte sebelas 9 daya tahan. Data streaming dengan kebutuhan latensi rendah disimpan di Aliran Data Amazon Kinesis untuk konsumsi waktu nyata. Hal ini memungkinkan analisis dan tindakan langsung untuk berbagai konsumen hilir—seperti yang terlihat pada pusat Riot Games Bus Acara Kerusuhan.
Pengolahan data
Data mentah sering kali berantakan dengan duplikat dan format yang tidak teratur. Anda perlu memprosesnya agar siap untuk dianalisis. Jika Anda menggunakan data batch dan data streaming, pertimbangkan untuk menggunakan kerangka kerja yang bisa menangani keduanya. Pola seperti Arsitektur Kappa memandang semuanya sebagai aliran, menyederhanakan jalur pipa pemrosesan. Pertimbangkan untuk menggunakan Layanan Terkelola Amazon untuk Apache Flink untuk menangani pekerjaan pemrosesan. Dengan Layanan Terkelola untuk Apache Flink, Anda dapat membersihkan dan mengubah data streaming dan mengarahkannya ke tujuan yang sesuai berdasarkan persyaratan latensi. Anda juga dapat menerapkan pemrosesan data batch menggunakan Amazon ESDM pada kerangka kerja sumber terbuka seperti Apache Spark dengan kinerja 3.5 kali lebih baik daripada versi yang dikelola sendiri. Keputusan arsitektur dalam menggunakan sistem pemrosesan batch atau streaming akan bergantung pada berbagai faktor; namun, jika Anda ingin mengaktifkan analisis real-time pada data pelanggan Anda, sebaiknya gunakan pola arsitektur Kappa.
Pilar 2: Unifikasi
Untuk menghubungkan beragam data yang datang dari berbagai titik kontak ke pelanggan unik, Anda perlu membangun solusi pemrosesan identitas yang mengidentifikasi login anonim, menyimpan informasi pelanggan yang berguna, menautkannya ke data eksternal untuk mendapatkan wawasan yang lebih baik, dan mengelompokkan pelanggan berdasarkan domain yang diminati. Meskipun solusi pemrosesan identitas membantu membangun profil pelanggan terpadu, sebaiknya pertimbangkan ini sebagai bagian dari kemampuan pemrosesan data Anda. Diagram berikut mengilustrasikan komponen solusi tersebut.
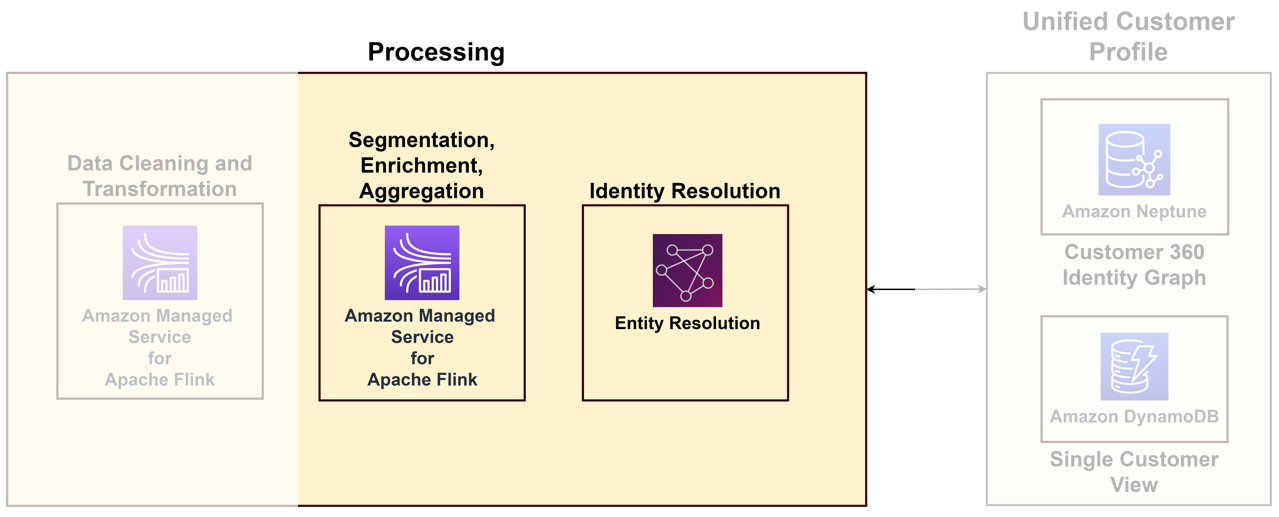
Komponen utamanya adalah sebagai berikut:
- Resolusi identitas – Resolusi identitas adalah solusi deduplikasi, di mana catatan dicocokkan untuk mengidentifikasi pelanggan dan prospek unik dengan menghubungkan beberapa pengidentifikasi seperti cookie, pengidentifikasi perangkat, alamat IP, ID email, dan ID perusahaan internal ke orang yang dikenal atau profil anonim menggunakan privasi- metode yang sesuai. Ini dapat dicapai dengan menggunakan Resolusi Entitas AWS, yang memungkinkan penggunaan aturan dan teknik pembelajaran mesin (ML) untuk mencocokkan catatan dan menyelesaikan identitas. Atau, Anda bisa membuat grafik identitas menggunakan Amazon Neptunus untuk satu tampilan terpadu tentang pelanggan Anda.
- Agregasi profil – Jika Anda telah mengidentifikasi pelanggan secara unik, Anda bisa membangun aplikasi di Layanan Terkelola untuk Apache Flink untuk mengkonsolidasikan semua metadatanya, mulai dari nama hingga riwayat interaksi. Kemudian, Anda mengubah data ini menjadi format yang ringkas. Daripada menampilkan setiap detail transaksi, Anda dapat menawarkan nilai pembelanjaan gabungan dan link ke data Manajemen Hubungan Pelanggan (CRM) mereka. Untuk interaksi layanan pelanggan, berikan skor CSAT rata-rata dan tautan ke sistem pusat panggilan untuk mengetahui lebih dalam riwayat komunikasi mereka.
- Pengayaan profil – Setelah Anda menetapkan pelanggan ke satu identitas, tingkatkan profil mereka menggunakan berbagai sumber data. Pengayaan biasanya melibatkan penambahan data demografi, perilaku, dan geolokasi. Anda dapat gunakan produk data pihak ketiga dari AWS Marketplace dikirimkan melalui AWS Data Exchange untuk mendapatkan wawasan tentang pendapatan, pola konsumsi, skor risiko kredit, dan banyak dimensi lainnya untuk lebih menyempurnakan pengalaman pelanggan.
- Segmentasi pelanggan – Setelah mengidentifikasi dan memperkaya profil pelanggan secara unik, Anda dapat mengelompokkannya berdasarkan demografi seperti usia, pembelanjaan, pendapatan, dan lokasi menggunakan aplikasi di Layanan Terkelola untuk Apache Flink. Saat Anda maju, Anda dapat menggabungkannya Layanan AI untuk teknik penargetan yang lebih tepat.
Setelah Anda melakukan pemrosesan identitas dan segmentasi, Anda memerlukan kemampuan penyimpanan untuk menyimpan profil pelanggan unik dan menyediakan kemampuan pencarian dan kueri di atasnya agar konsumen hilir dapat menggunakan data pelanggan yang diperkaya.
Diagram berikut mengilustrasikan pilar penyatuan untuk profil pelanggan terpadu dan tampilan tunggal pelanggan untuk aplikasi hilir.
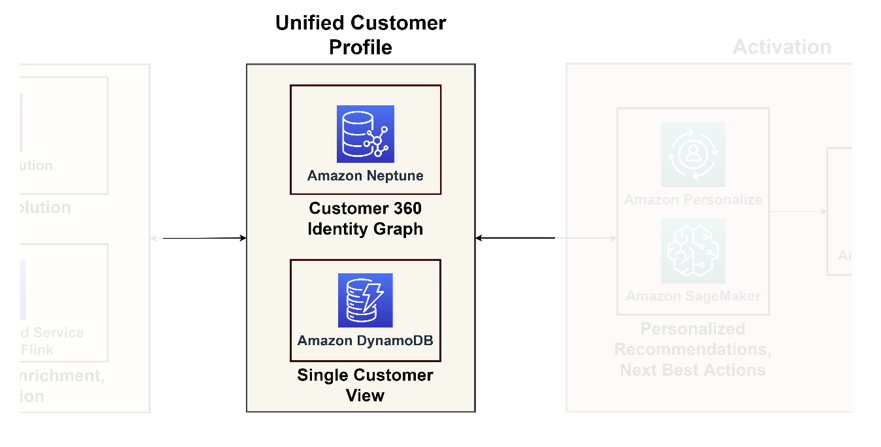
Profil pelanggan terpadu
Basis data grafik unggul dalam memodelkan interaksi dan hubungan pelanggan, menawarkan pandangan komprehensif tentang perjalanan pelanggan. Jika Anda berurusan dengan miliaran profil dan interaksi, Anda dapat mempertimbangkan untuk menggunakan Neptune, layanan database grafik terkelola di AWS. Organisasi seperti Zeta dan Activision telah berhasil menggunakan Neptune untuk menyimpan dan menanyakan miliaran pengidentifikasi unik per bulan dan jutaan kueri per detik pada waktu respons milidetik.
Tampilan pelanggan tunggal
Meskipun database grafik memberikan wawasan yang mendalam, namun database grafik bisa jadi rumit untuk aplikasi biasa. Sebaiknya data ini dikonsolidasikan ke dalam satu tampilan pelanggan, yang berfungsi sebagai referensi utama untuk aplikasi hilir, mulai dari platform e-niaga hingga sistem CRM. Pandangan terkonsolidasi ini bertindak sebagai penghubung antara platform data dan aplikasi yang berpusat pada pelanggan. Untuk tujuan tersebut, kami merekomendasikan penggunaan Amazon DynamoDB karena kemampuan beradaptasi, skalabilitas, dan kinerjanya, sehingga menghasilkan basis data pelanggan yang terkini dan efisien. Basis data ini akan menerima banyak permintaan tulis kembali dari sistem aktivasi yang mempelajari informasi baru tentang pelanggan dan memberikan umpan balik kepada mereka.
Pilar 3: Analisis
Pilar analitik mendefinisikan kemampuan yang membantu Anda menghasilkan wawasan selain data pelanggan Anda. Strategi analitik Anda berlaku untuk kebutuhan organisasi yang lebih luas, bukan hanya C360. Anda dapat menggunakan kemampuan yang sama untuk menyajikan pelaporan keuangan, mengukur kinerja operasional, atau bahkan memonetisasi aset data. Buat strategi berdasarkan cara tim Anda menjelajahi data, menjalankan analisis, mengatur data untuk kebutuhan hilir, dan memvisualisasikan data di berbagai tingkat. Rencanakan bagaimana Anda dapat memungkinkan tim Anda menggunakan ML untuk beralih dari analisis deskriptif ke analisis preskriptif.
Grafik Arsitektur data modern AWS menunjukkan cara untuk membangun platform data yang dibuat khusus, aman, dan dapat diskalakan di cloud. Belajar dari hal ini untuk membangun kemampuan kueri di seluruh data lake dan gudang data Anda.
Diagram berikut mengelompokkan kemampuan analitik menjadi eksplorasi data, visualisasi, pergudangan data, dan kolaborasi data. Mari kita cari tahu peran masing-masing komponen ini dalam konteks C360.

Eksplorasi data
Eksplorasi data membantu menemukan inkonsistensi, outlier, atau kesalahan. Dengan mengenali hal ini sejak dini, tim Anda dapat memiliki integrasi data yang lebih baik untuk C360, yang pada gilirannya menghasilkan analisis dan prediksi yang lebih akurat. Pertimbangkan persona yang mengeksplorasi data, keterampilan teknis mereka, dan waktu untuk mendapatkan wawasan. Misalnya, analis data yang tahu cara menulis SQL dapat langsung menanyakan data yang berada di Amazon S3 menggunakan Amazon Athena. Pengguna yang tertarik dengan eksplorasi visual dapat melakukannya menggunakan DataBrew Lem AWS. Data yang dapat digunakan oleh ilmuwan atau insinyur Studio Amazon EMR or Studio Amazon SageMaker untuk menjelajahi data dari notebook, dan untuk pengalaman kode rendah, Anda dapat menggunakannya Pengatur Data Amazon SageMaker. Karena layanan ini secara langsung menanyakan bucket S3, Anda dapat menjelajahi data saat data tersebut masuk ke data lake, sehingga mengurangi waktu untuk mendapatkan wawasan.
Visualisasi
Mengubah kumpulan data yang kompleks menjadi visual yang intuitif akan mengungkap pola tersembunyi dalam data, dan hal ini sangat penting untuk kasus penggunaan C360. Dengan kemampuan ini, Anda dapat merancang laporan untuk berbagai tingkat yang memenuhi berbagai kebutuhan: laporan eksekutif yang menawarkan ikhtisar strategis, laporan manajemen yang menyoroti metrik operasional, dan laporan terperinci yang membahas secara spesifik. Kejelasan visual seperti itu membantu organisasi Anda mengambil keputusan yang tepat di semua tingkatan, sehingga memusatkan perspektif pelanggan.
Diagram berikut menunjukkan contoh dasbor C360 yang dibuat Amazon QuickSight. QuickSight menawarkan kemampuan visualisasi tanpa server yang skalabel. Anda bisa memanfaatkan integrasi ML-nya untuk wawasan otomatis seperti perkiraan dan deteksi anomali atau kueri bahasa alami Amazon Q di QuickSight, konektivitas data langsung dari berbagai sumber, dan harga bayar per sesi. Dengan QuickSight, Anda bisa menyematkan dasbor ke situs web dan aplikasi eksternal, Dan SPICE mesin memungkinkan visualisasi data yang cepat dan interaktif dalam skala besar. Tangkapan layar berikut menunjukkan contoh dasbor C360 yang dibangun di QuickSight.
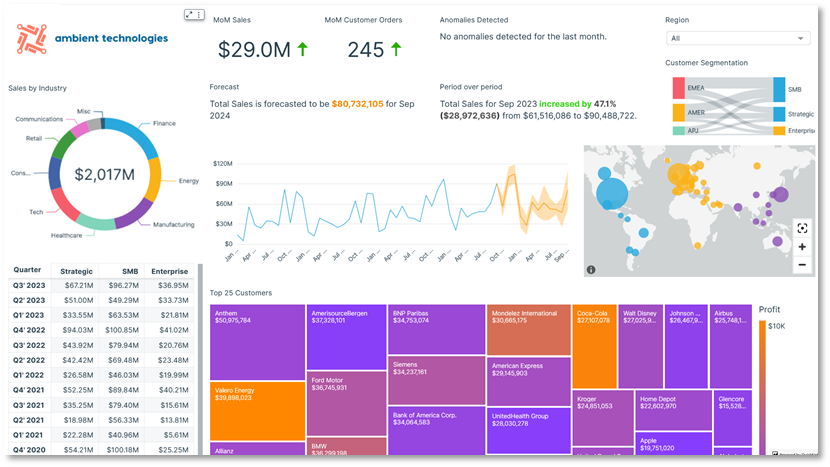
Gudang data
Gudang data efisien dalam menggabungkan data terstruktur dari berbagai sumber dan melayani kueri analitik dari sejumlah besar pengguna secara bersamaan. Gudang data dapat memberikan tampilan yang terpadu dan konsisten terhadap sejumlah besar data pelanggan untuk kasus penggunaan C360. Pergeseran Merah Amazon menjawab kebutuhan ini dengan secara mahir menangani data dalam jumlah besar dan beban kerja yang beragam. Hal ini memberikan konsistensi yang kuat di seluruh kumpulan data, memungkinkan organisasi memperoleh wawasan yang andal dan komprehensif tentang pelanggan mereka, yang penting untuk pengambilan keputusan yang tepat. Amazon Redshift menawarkan wawasan waktu nyata dan kemampuan analisis prediktif untuk menganalisis data dari terabyte hingga petabyte. Dengan Amazon Redshift ML, Anda dapat menyematkan ML di atas data yang disimpan di gudang data dengan overhead pengembangan minimum. Amazon Redshift Tanpa Server menyederhanakan pembuatan aplikasi dan memudahkan perusahaan untuk menanamkan kemampuan analisis data yang kaya.
Kolaborasi data
Anda bisa dengan aman berkolaborasi dan menganalisis kumpulan data kolektif dari mitra Anda tanpa berbagi atau menyalin data dasar satu sama lain Kamar Bersih AWS. Anda dapat menyatukan data yang berbeda dari seluruh saluran keterlibatan dan kumpulan data mitra untuk membentuk gambaran 360 derajat tentang pelanggan Anda. AWS Clean Rooms dapat menyempurnakan C360 dengan mengaktifkan kasus penggunaan seperti pengoptimalan pemasaran lintas saluran, segmentasi pelanggan tingkat lanjut, dan personalisasi yang sesuai dengan privasi. Dengan menggabungkan kumpulan data secara aman, teknologi ini menawarkan wawasan yang lebih kaya dan privasi data yang kuat, memenuhi kebutuhan bisnis dan standar peraturan.
Pilar 4: Aktivasi
Nilai data semakin berkurang seiring bertambahnya usia, sehingga menyebabkan biaya peluang yang lebih tinggi seiring berjalannya waktu. Dalam sebuah survei dilakukan oleh Intersystems, 75% organisasi yang disurvei percaya bahwa data yang tidak tepat waktu menghambat peluang bisnis. Dalam survei lain, 58% dari organisasi (dari 560 responden dewan Penasihat HBR dan pembaca) menyatakan bahwa mereka melihat peningkatan retensi dan loyalitas pelanggan menggunakan analisis pelanggan waktu nyata.
Anda dapat mencapai kedewasaan di C360 ketika Anda membangun kemampuan untuk bertindak berdasarkan semua wawasan yang diperoleh dari pilar-pilar sebelumnya yang telah kita diskusikan secara real-time. Misalnya, pada tingkat kedewasaan ini, Anda dapat bertindak berdasarkan sentimen pelanggan berdasarkan konteks yang Anda peroleh secara otomatis dengan profil pelanggan yang diperkaya dan saluran terintegrasi. Untuk melakukan hal ini, Anda perlu menerapkan pengambilan keputusan preskriptif tentang cara mengatasi sentimen pelanggan. Untuk melakukan hal ini dalam skala besar, Anda harus menggunakan layanan AI/ML untuk pengambilan keputusan. Diagram berikut mengilustrasikan arsitektur untuk mengaktifkan wawasan menggunakan ML untuk analisis preskriptif dan layanan AI untuk penargetan dan segmentasi.
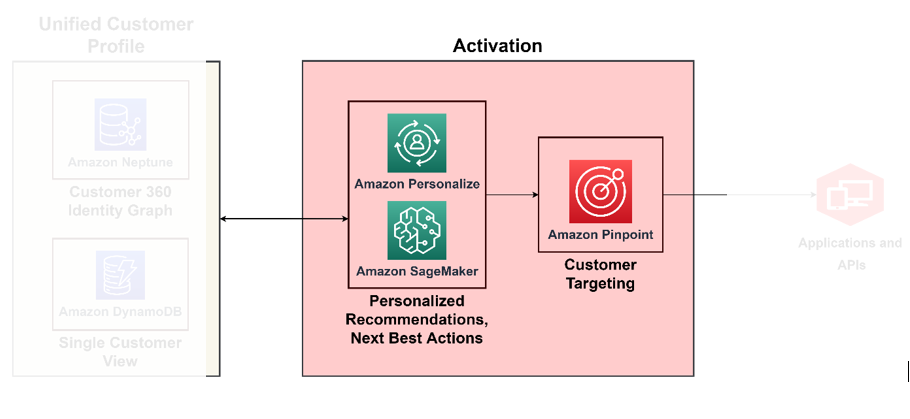
Gunakan ML untuk mesin pengambilan keputusan
Dengan ML, Anda dapat meningkatkan pengalaman pelanggan secara keseluruhan—Anda dapat membuat model perilaku pelanggan yang prediktif, merancang penawaran yang sangat dipersonalisasi, dan menargetkan pelanggan yang tepat dengan insentif yang tepat. Anda dapat membuatnya menggunakan Amazon SageMaker, yang menampilkan serangkaian layanan terkelola yang dipetakan ke siklus hidup ilmu data, termasuk perselisihan data, pelatihan model, hosting model, inferensi model, deteksi penyimpangan model, dan penyimpanan fitur. SageMaker memungkinkan Anda melakukannya membangun dan mengoperasionalkan model ML Anda, memasukkannya kembali ke dalam aplikasi Anda untuk menghasilkan wawasan yang tepat kepada orang yang tepat pada waktu yang tepat.
Amazon Personalisasi mendukung rekomendasi kontekstual, yang melaluinya Anda dapat meningkatkan relevansi rekomendasi dengan menghasilkannya dalam konteks—misalnya, jenis perangkat, lokasi, atau waktu. Tim Anda dapat memulai tanpa pengalaman ML sebelumnya menggunakan API untuk membangun kemampuan personalisasi canggih dalam beberapa klik. Untuk informasi lebih lanjut, lihat Sesuaikan rekomendasi Anda dengan mempromosikan item tertentu menggunakan aturan bisnis dengan Amazon Personalize.
Aktifkan saluran di seluruh pemasaran, periklanan, langsung ke konsumen, dan loyalitas
Kini setelah Anda mengetahui siapa pelanggan Anda dan siapa yang harus dijangkau, Anda dapat membangun solusi untuk menjalankan kampanye penargetan dalam skala besar. Dengan Amazon tepat, Anda dapat mempersonalisasi dan mengelompokkan komunikasi untuk melibatkan pelanggan di berbagai saluran. Misalnya, Anda dapat menggunakan Amazon Pinpoint untuk membangun pengalaman pelanggan yang menarik melalui berbagai saluran komunikasi seperti email, SMS, notifikasi push, dan notifikasi dalam aplikasi.
Pilar 5: Tata Kelola Data
Membangun tata kelola yang tepat yang menyeimbangkan kontrol dan akses akan memberikan kepercayaan dan keyakinan kepada pengguna terhadap data. Bayangkan menawarkan promosi produk yang tidak dibutuhkan pelanggan, atau membombardir pelanggan yang salah dengan notifikasi. Kualitas data yang buruk dapat menyebabkan situasi seperti itu, dan pada akhirnya mengakibatkan perpindahan pelanggan. Anda harus membangun proses yang memvalidasi kualitas data dan mengambil tindakan perbaikan. Kualitas Data AWS Glue dapat membantu Anda membangun solusi yang memvalidasi kualitas data saat disimpan dan dalam transit, berdasarkan aturan yang telah ditentukan sebelumnya.
Untuk menyiapkan struktur tata kelola lintas fungsi untuk data pelanggan, Anda memerlukan kemampuan untuk mengatur dan berbagi data di seluruh organisasi Anda. Dengan Zona Data Amazon, admin dan pengelola data dapat mengelola dan mengatur akses ke data, dan konsumen seperti teknisi data, ilmuwan data, manajer produk, analis, dan pengguna bisnis lainnya dapat menemukan, menggunakan, dan berkolaborasi dengan data tersebut untuk mendorong wawasan. Ini menyederhanakan akses data, memungkinkan Anda menemukan dan menggunakan data pelanggan, mendorong kolaborasi tim dengan aset data bersama, dan menyediakan analisis yang dipersonalisasi baik melalui aplikasi web atau API di portal. Formasi Danau AWS memastikan data diakses dengan aman, menjamin orang yang tepat melihat data yang tepat untuk alasan yang tepat, yang sangat penting untuk tata kelola lintas fungsi yang efektif di organisasi mana pun. Metadata bisnis disimpan dan dikelola oleh Amazon DataZone, yang didukung oleh metadata teknis dan informasi skema, yang terdaftar di Katalog Data AWS Glue. Metadata teknis ini juga digunakan oleh layanan tata kelola lainnya seperti Lake Formation dan Amazon DataZone, serta layanan analitik seperti Amazon Redshift, Athena, dan AWS Glue.

Memadukan semua
Dengan menggunakan diagram berikut sebagai referensi, Anda dapat membuat proyek dan tim untuk membangun dan mengoperasikan berbagai kemampuan. Misalnya, Anda dapat membuat tim integrasi data fokus pada pilar pengumpulan data—Anda kemudian dapat menyelaraskan peran fungsional, seperti arsitek data dan insinyur data. Anda dapat membangun praktik analitik dan ilmu data untuk masing-masing fokus pada pilar analitik dan aktivasi. Kemudian Anda dapat membuat tim khusus untuk pemrosesan identitas pelanggan dan untuk membangun tampilan terpadu tentang pelanggan. Anda dapat membentuk tim tata kelola data dengan pengelola data dari berbagai fungsi, admin keamanan, dan pembuat kebijakan tata kelola data untuk merancang dan mengotomatisasi kebijakan.
Kesimpulan
Membangun kemampuan C360 yang kuat merupakan hal mendasar bagi organisasi Anda untuk mendapatkan wawasan tentang basis pelanggan Anda. Layanan Database, Analytics, dan AI/ML AWS dapat membantu menyederhanakan proses ini, memberikan skalabilitas dan efisiensi. Dengan mengikuti lima pilar untuk memandu pemikiran Anda, Anda dapat membangun strategi data menyeluruh yang mendefinisikan tampilan C360 di seluruh organisasi, memastikan keakuratan data, dan menetapkan tata kelola lintas fungsi untuk data pelanggan. Anda dapat mengategorikan dan memprioritaskan produk dan fitur yang harus Anda bangun dalam setiap pilar, memilih alat yang tepat untuk pekerjaan tersebut, dan membangun keterampilan yang Anda perlukan dalam tim Anda.
Mengunjungi Kisah Pelanggan AWS for Data untuk mempelajari bagaimana AWS mentransformasikan perjalanan pelanggan, dari perusahaan terbesar di dunia hingga perusahaan rintisan yang sedang berkembang.
Tentang Penulis
 Ismail Makhlouf adalah Arsitek Solusi Spesialis Senior untuk Analisis Data di AWS. Ismail berfokus pada merancang solusi untuk organisasi di seluruh bidang analisis data end-to-end mereka, termasuk streaming batch dan real-time, big data, data warehousing, dan beban kerja data lake. Dia terutama bekerja dengan organisasi di bidang ritel, ecommerce, FinTech, HealthTech, dan perjalanan untuk mencapai tujuan bisnis mereka dengan platform data yang dirancang dengan baik.
Ismail Makhlouf adalah Arsitek Solusi Spesialis Senior untuk Analisis Data di AWS. Ismail berfokus pada merancang solusi untuk organisasi di seluruh bidang analisis data end-to-end mereka, termasuk streaming batch dan real-time, big data, data warehousing, dan beban kerja data lake. Dia terutama bekerja dengan organisasi di bidang ritel, ecommerce, FinTech, HealthTech, dan perjalanan untuk mencapai tujuan bisnis mereka dengan platform data yang dirancang dengan baik.
 Sandipan Bhaumik (Sandi) adalah Arsitek Solusi Spesialis Analisis Senior di AWS. Dia membantu pelanggan memodernisasi platform data mereka di cloud untuk melakukan analisis secara aman dalam skala besar, mengurangi overhead operasional, dan mengoptimalkan penggunaan untuk efektivitas biaya dan keberlanjutan.
Sandipan Bhaumik (Sandi) adalah Arsitek Solusi Spesialis Analisis Senior di AWS. Dia membantu pelanggan memodernisasi platform data mereka di cloud untuk melakukan analisis secara aman dalam skala besar, mengurangi overhead operasional, dan mengoptimalkan penggunaan untuk efektivitas biaya dan keberlanjutan.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/create-an-end-to-end-data-strategy-for-customer-360-on-aws/

