Cet article a été rédigé en collaboration avec Bhajandeep Singh et Ajay Vishwakarma de AWS AI/ML Practice de Wipro.
De nombreuses organisations utilisent une combinaison de solutions de science des données sur site et open source pour créer et gérer des modèles d'apprentissage automatique (ML).
Les équipes de science des données et DevOps peuvent être confrontées à des difficultés pour gérer ces piles d'outils et ces systèmes isolés. L'intégration de plusieurs piles d'outils pour créer une solution compacte peut impliquer la création de connecteurs ou de flux de travail personnalisés. La gestion de différentes dépendances en fonction de la version actuelle de chaque pile et la maintenance de ces dépendances avec la publication de nouvelles mises à jour de chaque pile complique la solution. Cela augmente le coût de maintenance des infrastructures et nuit à la productivité.
Offres d'intelligence artificielle (IA) et d'apprentissage automatique (ML) de Amazon Web Services (AWS), ainsi que des services intégrés de surveillance et de notification, aident les organisations à atteindre le niveau requis d'automatisation, d'évolutivité et de qualité de modèle à un coût optimal. AWS aide également les équipes de science des données et DevOps à collaborer et rationalise le processus global du cycle de vie des modèles.
Le portefeuille AWS de services ML comprend un ensemble robuste de services que vous pouvez utiliser pour accélérer le développement, la formation et le déploiement d'applications d'apprentissage automatique. La suite de services peut être utilisée pour prendre en charge le cycle de vie complet du modèle, y compris la surveillance et le recyclage des modèles ML.
Dans cet article, nous discutons du développement de modèles et de la mise en œuvre du framework MLOps pour l'un des clients de Wipro qui utilise Amazon Sage Maker et d'autres services AWS.
Wipro est un Partenaire de services AWS Premier Tier et fournisseur de services gérés (MSP). C'est Solutions IA/ML améliorer l'efficacité opérationnelle, la productivité et l'expérience client pour bon nombre de leurs entreprises clientes.
Défis actuels
Commençons par comprendre quelques-uns des défis auxquels les équipes de science des données et DevOps du client sont confrontées avec leur configuration actuelle. Nous pouvons ensuite examiner comment les offres intégrées SageMaker AI/ML ont contribué à résoudre ces défis.
- Collaboration – Les data scientists ont chacun travaillé sur leurs propres notebooks Jupyter locaux pour créer et entraîner des modèles ML. Il leur manquait une méthode efficace pour partager et collaborer avec d’autres data scientists.
- Évolutivité – La formation et le recyclage des modèles ML prenaient de plus en plus de temps à mesure que les modèles devenaient plus complexes tandis que la capacité de l'infrastructure allouée restait statique.
- MLOps – La surveillance des modèles et la gouvernance continue n'étaient pas étroitement intégrées et automatisées avec les modèles ML. Il existe des dépendances et des complexités liées à l'intégration d'outils tiers dans le pipeline MLOps.
- Réutilisabilité – Sans cadres MLOps réutilisables, chaque modèle doit être développé et gouverné séparément, ce qui ajoute à l'effort global et retarde l'opérationnalisation du modèle.
Ce diagramme résume les défis et comment la mise en œuvre de Wipro sur SageMaker les a résolus avec les services et offres SageMaker intégrés.
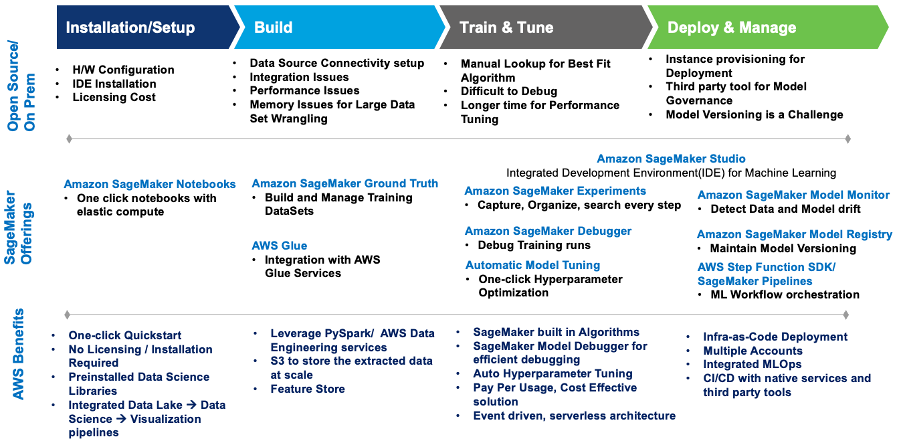
Figure 1 – Offres SageMaker pour la migration des charges de travail ML
Wipro a défini une architecture qui répond aux défis de manière rentable et entièrement automatisée.
Voici le cas d'utilisation et le modèle utilisés pour créer la solution :
- Cas d'utilisation: Prédiction de prix basée sur l'ensemble de données sur les voitures d'occasion
- Type de problème : Régression
- Modèles utilisés : XGBoost et Linear Learner (algorithmes intégrés à SageMaker)
Architecture de la solution
Les consultants Wipro ont organisé un atelier de découverte approfondi avec les équipes de science des données, DevOps et d'ingénierie des données du client pour comprendre l'environnement actuel ainsi que leurs exigences et attentes pour une solution moderne sur AWS. À la fin de la mission de conseil, l'équipe avait mis en œuvre l'architecture suivante qui répondait efficacement aux principales exigences de l'équipe client, notamment :
Partage de Code – Les notebooks SageMaker permettent aux data scientists d'expérimenter et de partager du code avec d'autres membres de l'équipe. Wipro a encore accéléré son parcours de modèle ML en mettant en œuvre les accélérateurs et les extraits de code de Wipro pour accélérer l'ingénierie des fonctionnalités, la formation des modèles, le déploiement de modèles et la création de pipelines.
Pipeline d’intégration continue et de livraison continue (CI/CD) – L'utilisation du référentiel GitHub du client a permis la gestion des versions du code et des scripts automatisés pour lancer le déploiement du pipeline chaque fois que de nouvelles versions du code sont validées.
MLOps – L'architecture implémente un pipeline de surveillance des modèles SageMaker pour une gouvernance continue de la qualité des modèles en validant les données et la dérive du modèle comme l'exige le calendrier défini. Chaque fois qu'une dérive est détectée, un événement est lancé pour avertir les équipes respectives d'agir ou de lancer le recyclage du modèle.
Architecture événementielle – Les pipelines pour la formation des modèles, le déploiement des modèles et la surveillance des modèles sont bien intégrés par utilisation Amazon Event Bridge, un bus d'événements sans serveur. Lorsque des événements définis se produisent, EventBridge peut appeler un pipeline à exécuter en réponse. Cela fournit un ensemble de pipelines faiblement couplés qui peuvent fonctionner selon les besoins en réponse à l'environnement.
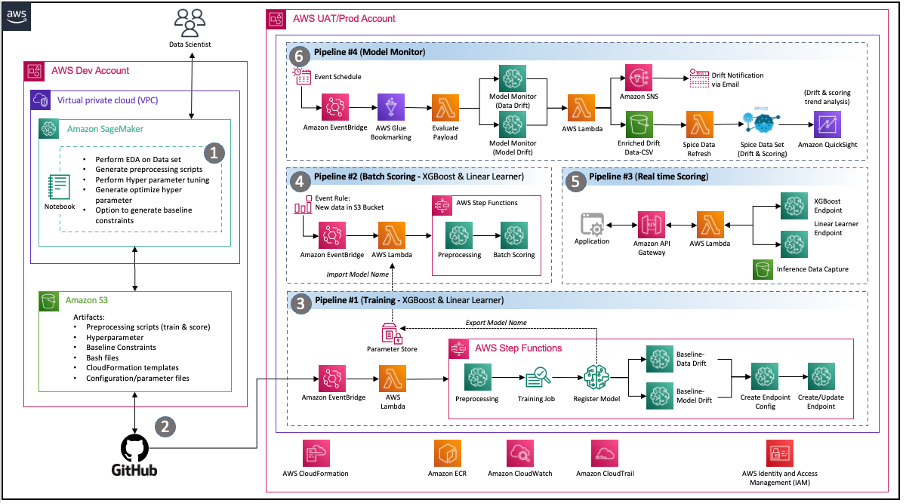
Figure 2 – Architecture MLOps basée sur les événements avec SageMaker
Composants de la solution
Cette section décrit les différents composants de la solution de l'architecture.
Carnets d'expérimentation
- Objectif: L'équipe de science des données du client souhaitait expérimenter divers ensembles de données et plusieurs modèles pour proposer les fonctionnalités optimales, en les utilisant comme entrées supplémentaires dans le pipeline automatisé.
- Solution: Wipro a créé des cahiers d'expérimentation SageMaker avec des extraits de code pour chaque étape réutilisable, telle que la lecture et l'écriture de données, l'ingénierie des fonctionnalités du modèle, la formation du modèle et le réglage des hyperparamètres. Les tâches d'ingénierie des fonctionnalités peuvent également être préparées dans Data Wrangler, mais le client a spécifiquement demandé des tâches de traitement SageMaker et Fonctions d'étape AWS parce qu'ils étaient plus à l'aise avec ces technologies. Nous avons utilisé le SDK de science des données de fonction étape AWS pour créer une fonction étape (pour les tests de flux) directement à partir de l'instance de notebook afin de permettre des entrées bien définies pour les pipelines. Cela a aidé l’équipe de data scientists à créer et tester des pipelines à un rythme beaucoup plus rapide.
Pipeline de formation automatisé
- Objectif : Pour activer un pipeline de formation et de recyclage automatisé avec des paramètres configurables tels que le type d'instance, les hyperparamètres et un Service de stockage simple Amazon (Amazon S3) emplacement du seau. Le pipeline devrait également être lancé par l’événement data push vers S3.
- Solution: Wipro a mis en œuvre un pipeline de formation réutilisable à l'aide du SDK Step Functions, du traitement SageMaker, des tâches de formation, d'un conteneur de surveillance de modèle SageMaker pour la génération de référence, AWS Lambdaet les services EventBridge. Grâce à l'architecture basée sur les événements AWS, le pipeline est configuré pour se lancer automatiquement en fonction d'un nouvel événement de données transmis au compartiment S3 mappé. Les notifications sont configurées pour être envoyées aux adresses e-mail définies. À un niveau élevé, le flux de formation ressemble au diagramme suivant :
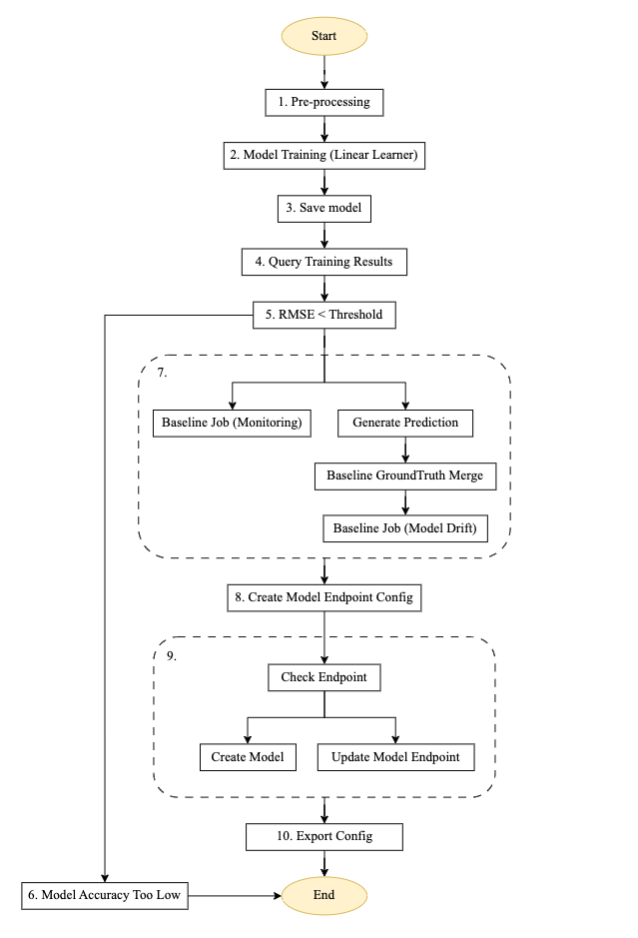
Figure 3 – Machine à étapes du pipeline de formation.
Description du flux pour le pipeline de formation automatisé
Le diagramme ci-dessus est un pipeline de formation automatisé construit à l'aide de Step Functions, Lambda et SageMaker. Il s'agit d'un pipeline réutilisable permettant de configurer une formation automatisée de modèles, de générer des prédictions, de créer une base de référence pour la surveillance du modèle et la surveillance des données, ainsi que de créer et de mettre à jour un point de terminaison basé sur la valeur de seuil précédente du modèle.
- Pré-traitement: Cette étape prend les données d'un emplacement Amazon S3 en entrée et utilise le conteneur SageMaker SKLearn pour effectuer les tâches nécessaires d'ingénierie des fonctionnalités et de prétraitement des données, telles que l'entraînement, le test et la validation de la répartition.
- Formation modèle : À l'aide du SDK SageMaker, cette étape exécute le code de formation avec l'image de modèle respective et entraîne les ensembles de données à partir de scripts de prétraitement tout en générant les artefacts de modèle entraînés.
- Enregistrer le modèle : Cette étape crée un modèle à partir des artefacts du modèle entraîné. Le nom du modèle est stocké pour référence dans un autre pipeline à l'aide du Magasin de paramètres AWS Systems Manager.
- Résultats de la formation des requêtes : Cette étape appelle la fonction Lambda pour récupérer les métriques de la tâche de formation terminée à partir de l'étape de formation du modèle précédente.
- Seuil RMSE : Cette étape vérifie la métrique du modèle entraîné (RMSE) par rapport à un seuil défini pour décider s'il faut procéder au déploiement du point de terminaison ou rejeter ce modèle.
- Précision du modèle trop faible : À cette étape, la précision du modèle est vérifiée par rapport au meilleur modèle précédent. Si le modèle échoue lors de la validation des métriques, la notification est envoyée par une fonction Lambda au sujet cible enregistré dans Service de notification simple Amazon (Amazon SNS). Si cette vérification échoue, le flux se termine car le nouveau modèle entraîné n’a pas atteint le seuil défini.
- Dérive des données de travail de référence : Si le modèle entraîné réussit les étapes de validation, des statistiques de base sont générées pour cette version du modèle entraîné afin de permettre la surveillance et les étapes de branchement parallèles sont exécutées pour générer la référence pour le contrôle de qualité du modèle.
- Créez une configuration de point de terminaison de modèle : Cette étape crée une configuration de point de terminaison pour le modèle évalué à l'étape précédente avec un activer la capture de données configuration.
- Vérifiez le point de terminaison : Cette étape vérifie si le point de terminaison existe ou doit être créé. En fonction du résultat, l'étape suivante consiste à créer ou à mettre à jour le point de terminaison.
- Configuration d'exportation : Cette étape exporte le nom du modèle, le nom du point de terminaison et la configuration du point de terminaison vers le Gestionnaire de systèmes AWS Magasin de paramètres.
Des alertes et des notifications sont configurées pour être envoyées à l'e-mail de sujet SNS configuré en cas d'échec ou de réussite d'un changement d'état de machine d'état. La même configuration de pipeline est réutilisée pour le modèle XGBoost.
Pipeline de notation par lots automatisé
- Objectif : Lancez la notation par lots dès que les données du lot d'entrée de notation sont disponibles dans l'emplacement Amazon S3 respectif. La notation par lots doit utiliser le dernier modèle enregistré pour effectuer la notation.
- Solution: Wipro a mis en œuvre un pipeline de notation réutilisable à l'aide du SDK Step Functions, des tâches de transformation par lots SageMaker, Lambda et EventBridge. Le pipeline est déclenché automatiquement en fonction de la nouvelle disponibilité des données du lot de notation sur l'emplacement S3 respectif.
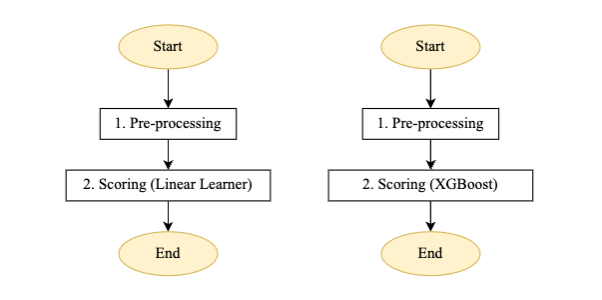
Figure 4 – Machine pas à pas de pipeline de notation pour l'apprenant linéaire et le modèle XGBoost
Description du flux pour le pipeline de notation par lots automatisé :
- Pré-traitement: L'entrée de cette étape est un fichier de données provenant de l'emplacement S3 respectif et effectue le prétraitement requis avant d'appeler la tâche de transformation par lots SageMaker.
- Notation: Cette étape exécute la tâche de transformation par lots pour générer des inférences, en appelant la dernière version du modèle enregistré et en stockant la sortie de notation dans un compartiment S3. Wipro a utilisé le filtre d'entrée et la fonctionnalité de jointure de l'API de transformation par lots SageMaker. Cela a permis d'enrichir les données de notation pour une meilleure prise de décision.
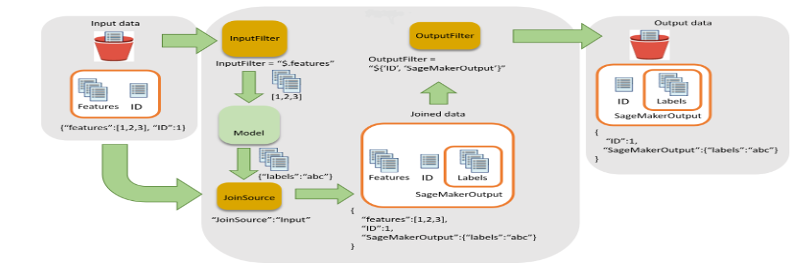
Figure 5 – Filtre d'entrée et flux de jointure pour la transformation par lots
- Au cours de cette étape, le pipeline de machine d'état est lancé par un nouveau fichier de données dans le compartiment S3.
La notification est configurée pour être envoyée à l'e-mail de sujet SNS configuré en cas d'échec/réussite du changement d'état de la machine d'état.
Pipeline d'inférence en temps réel
- Objectif : Pour activer les inférences en temps réel à partir des points de terminaison des deux modèles (Linear Learner et XGBoost) et obtenir la valeur maximale prédite (ou en utilisant toute autre logique personnalisée pouvant être écrite en tant que fonction Lambda) à renvoyer à l'application.
- Solution: L'équipe Wipro a implémenté une architecture réutilisable en utilisant Passerelle d'API Amazon, Lambda et le point de terminaison SageMaker, comme illustré dans la figure 6 :

Figure 6 – Pipeline d'inférence en temps réel
Description du flux pour le pipeline d'inférence en temps réel illustré à la figure 6 :
- La charge utile est envoyée depuis l'application vers Amazon API Gateway, qui l'achemine vers la fonction Lambda correspondante.
- Une fonction Lambda (avec une couche personnalisée SageMaker intégrée) effectue le prétraitement requis, le formatage de la charge utile JSON ou CSV et appelle les points de terminaison respectifs.
- La réponse est renvoyée à Lambda et renvoyée à l'application via API Gateway.
Le client a utilisé ce pipeline pour des modèles à petite et moyenne échelle, qui incluaient l'utilisation de divers types d'algorithmes open source. L'un des principaux avantages de SageMaker est que différents types d'algorithmes peuvent être introduits dans SageMaker et déployés à l'aide d'une technique BYOC (Bring Your Own Container). BYOC implique de conteneuriser l'algorithme et d'enregistrer l'image dans Registre de conteneurs élastiques Amazon (Amazon ECR), puis en utilisant la même image pour créer un conteneur pour effectuer la formation et l'inférence.
La mise à l’échelle est l’un des problèmes les plus importants du cycle d’apprentissage automatique. SageMaker est livré avec les outils nécessaires pour mettre à l'échelle un modèle lors de l'inférence. Dans l'architecture précédente, les utilisateurs doivent activer la mise à l'échelle automatique de SageMaker, qui gère finalement la charge de travail. Pour activer la mise à l'échelle automatique, les utilisateurs doivent fournir une stratégie de mise à l'échelle automatique qui demande le débit par instance ainsi que les instances maximales et minimales. Dans le cadre de la politique en place, SageMaker gère automatiquement la charge de travail des points de terminaison en temps réel et bascule entre les instances si nécessaire.
Pipeline de surveillance de modèle personnalisé
- Objectif : L'équipe client souhaitait disposer d'une surveillance automatisée des modèles pour capturer à la fois la dérive des données et la dérive du modèle. L'équipe Wipro a utilisé la surveillance du modèle SageMaker pour permettre à la fois la dérive des données et la dérive du modèle avec un pipeline réutilisable pour les inférences en temps réel et la transformation par lots. Notez que lors du développement de cette solution, la surveillance du modèle SageMaker n'a pas prévu de détection de données ou dérive du modèle pour la transformation par lots. Nous avons implémenté des personnalisations pour utiliser le conteneur de moniteur de modèle pour la charge utile des transformations par lots.
- Solution: L'équipe Wipro a mis en œuvre un pipeline de surveillance de modèles réutilisable pour les charges utiles d'inférence en temps réel et par lots en utilisant Colle AWS pour capturer la charge utile incrémentielle et appeler la tâche de surveillance du modèle selon le calendrier défini.

Figure 7 – Modèle de machine pas à pas de moniteur
Description du flux pour le pipeline de surveillance de modèle personnalisé :
Le pipeline s'exécute selon le calendrier défini configuré via EventBridge.
- Consolidation CSV – Il utilise la fonctionnalité de signet AWS Glue pour détecter la présence de charge utile incrémentielle dans le compartiment S3 défini de capture et de réponse de données en temps réel et de réponse de données par lots. Il regroupe ensuite ces données pour un traitement ultérieur.
- Évaluer la charge utile – Si des données incrémentielles ou une charge utile sont présentes pour l'exécution en cours, la branche de surveillance est appelée. Sinon, il contourne sans traitement et quitte le travail.
- Post-traitement – La branche de surveillance est conçue pour avoir deux sous-branches parallèles : une pour la dérive des données et une autre pour la dérive du modèle.
- Surveillance (dérive des données) – La branche de dérive des données s’exécute chaque fois qu’une charge utile est présente. Il utilise les dernières contraintes de base du modèle formé et les fichiers de statistiques générés via le pipeline de formation pour les fonctionnalités de données et exécute la tâche de surveillance du modèle.
- Surveillance (dérive du modèle) – La branche de dérive du modèle s'exécute uniquement lorsque les données de vérité terrain sont fournies, ainsi que la charge utile d'inférence. Il utilise les contraintes de base du modèle entraîné et les fichiers de statistiques générés via le pipeline de formation pour les fonctionnalités de qualité du modèle et exécute la tâche de surveillance du modèle.
- Évaluer la dérive – Le résultat de la dérive des données et du modèle est un fichier de violation de contrainte qui est évalué par la fonction Lambda d'évaluation de la dérive qui envoie une notification aux sujets Amazon SNS respectifs avec les détails de la dérive. Les données de dérive sont encore enrichies avec l'ajout d'attributs à des fins de reporting. Les e-mails de notification de dérive ressembleront aux exemples de la figure 8.

Figure 8 – Message de notification de dérive des données et du modèle

Figure 9 – Message de notification de dérive des données et du modèle
Informations avec la visualisation Amazon QuickSight :
- Objectif : Le client souhaitait avoir des informations sur la dérive des données et du modèle, relier les données de dérive aux tâches de surveillance du modèle respectives et découvrir les tendances des données d'inférence pour comprendre la nature des tendances des données d'interférence.
- Solution: L'équipe Wipro a enrichi les données de dérive en connectant les données d'entrée au résultat de dérive, ce qui permet le tri de la dérive à la surveillance et aux données de notation respectives. Les visualisations et les tableaux de bord ont été créés à l'aide Amazon QuickSight avec Amazone Athéna comme source de données (en utilisant les données de notation et de dérive Amazon S3 CSV).
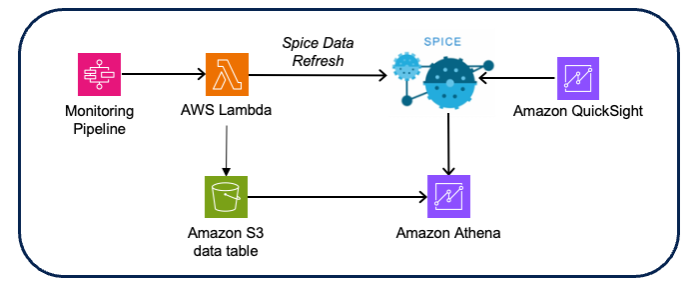
Figure 10 – Architecture de visualisation de surveillance du modèle
Considérations sur la conception:
- Utilisez l’ensemble de données Spice QuickSight pour de meilleures performances en mémoire.
- Utilisez les API d’actualisation de l’ensemble de données QuickSight pour automatiser l’actualisation des données Spice.
- Implémentez une sécurité basée sur les groupes pour le contrôle d’accès aux tableaux de bord et aux analyses.
- Sur l’ensemble des comptes, automatisez le déploiement à l’aide des appels d’API d’exportation et d’importation d’ensembles de données, de sources de données et d’analyse fournis par QuickSight.
Tableau de bord de surveillance du modèle :
Pour permettre un résultat efficace et des informations significatives sur les tâches de surveillance du modèle, des tableaux de bord personnalisés ont été créés pour les données de surveillance du modèle. Les points de données d'entrée sont combinés en parallèle avec les données de demande d'inférence, les données de tâches et les sorties de surveillance pour créer une visualisation des tendances révélées par la surveillance du modèle.
Cela a vraiment aidé l'équipe client à visualiser les aspects des différentes fonctionnalités de données ainsi que le résultat prévu de chaque lot de demandes d'inférence.
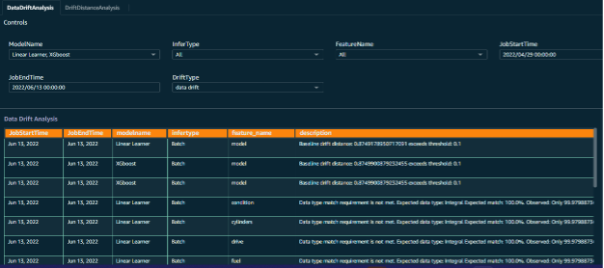
Figure 11 – Tableau de bord du moniteur de modèle avec invites de sélection

Figure 12 – Analyse de la dérive du moniteur de modèle
Conclusion
La mise en œuvre expliquée dans cet article a permis à Wipro de migrer efficacement ses modèles sur site vers AWS et de créer un cadre de développement de modèles évolutif et automatisé.
L'utilisation de composants de structure réutilisables permet à l'équipe de science des données de conditionner efficacement son travail en tant que composants JSON AWS Step Functions déployables. Simultanément, les équipes DevOps ont utilisé et amélioré le pipeline CI/CD automatisé pour faciliter la promotion et le recyclage transparents des modèles dans des environnements supérieurs.
Le composant de surveillance du modèle a permis une surveillance continue des performances du modèle, et les utilisateurs reçoivent des alertes et des notifications chaque fois que des données ou une dérive du modèle sont détectées.
L'équipe du client utilise ce framework MLOps pour migrer ou développer davantage de modèles et accroître son adoption de SageMaker.
En exploitant la suite complète de services SageMaker en conjonction avec notre architecture méticuleusement conçue, les clients peuvent intégrer de manière transparente plusieurs modèles, réduisant ainsi considérablement le temps de déploiement et atténuant les complexités associées au partage de code. De plus, notre architecture simplifie la maintenance du versioning du code, garantissant un processus de développement rationalisé.
Cette architecture gère l'intégralité du cycle d'apprentissage automatique, englobant la formation automatisée des modèles, l'inférence en temps réel et par lots, la surveillance proactive des modèles et l'analyse des dérives. Cette solution de bout en bout permet aux clients d'obtenir des performances de modèle optimales tout en conservant des capacités de surveillance et d'analyse rigoureuses pour garantir une précision et une fiabilité continues.
Pour créer cette architecture, commencez par créer des ressources essentielles comme Cloud privé virtuel Amazon (Amazon VPC), les blocs-notes SageMaker et les fonctions Lambda. Assurez-vous de configurer correctement Gestion des identités et des accès AWS (IAM) politiques pour ces ressources.
Ensuite, concentrez-vous sur la création des composants de l'architecture, tels que les scripts de formation et de prétraitement, dans SageMaker Studio ou Jupyter Notebook. Cette étape consiste à développer le code et les configurations nécessaires pour activer les fonctionnalités souhaitées.
Une fois les composants de l'architecture définis, vous pouvez procéder à la création des fonctions Lambda pour générer des inférences ou effectuer des étapes de post-traitement sur les données.
À la fin, utilisez Step Functions pour connecter les composants et établir un flux de travail fluide qui coordonne le déroulement de chaque étape.
À propos des auteurs
 Stephen Randolph est architecte de solutions partenaire senior chez Amazon Web Services (AWS). Il aide et soutient les partenaires Global Systems Integrator (GSI) sur la dernière technologie AWS alors qu'ils développent des solutions industrielles pour résoudre les défis commerciaux. Stephen est particulièrement passionné par la sécurité et l'IA générative, et il aide les clients et partenaires à concevoir des solutions sécurisées, efficaces et innovantes sur AWS.
Stephen Randolph est architecte de solutions partenaire senior chez Amazon Web Services (AWS). Il aide et soutient les partenaires Global Systems Integrator (GSI) sur la dernière technologie AWS alors qu'ils développent des solutions industrielles pour résoudre les défis commerciaux. Stephen est particulièrement passionné par la sécurité et l'IA générative, et il aide les clients et partenaires à concevoir des solutions sécurisées, efficaces et innovantes sur AWS.
 Bhajandeep Singh a occupé le poste de responsable du centre d'excellence AWS AI/ML chez Wipro Technologies, dirigeant les engagements clients pour fournir des solutions d'analyse de données et d'IA. Il est titulaire de la certification AWS AI/ML Specialty et écrit des blogs techniques sur les services et solutions AI/ML. Fort de son expérience dans les solutions AWS AI/ML de premier plan dans tous les secteurs, Bhajandeep a permis aux clients de maximiser la valeur des services AWS AI/ML grâce à son expertise et son leadership.
Bhajandeep Singh a occupé le poste de responsable du centre d'excellence AWS AI/ML chez Wipro Technologies, dirigeant les engagements clients pour fournir des solutions d'analyse de données et d'IA. Il est titulaire de la certification AWS AI/ML Specialty et écrit des blogs techniques sur les services et solutions AI/ML. Fort de son expérience dans les solutions AWS AI/ML de premier plan dans tous les secteurs, Bhajandeep a permis aux clients de maximiser la valeur des services AWS AI/ML grâce à son expertise et son leadership.
 Ajay Vishwakarma est un ingénieur ML pour l'aile AWS de la pratique des solutions d'IA de Wipro. Il possède une bonne expérience dans la création de solutions BYOM pour des algorithmes personnalisés dans SageMaker, le déploiement de pipelines ETL de bout en bout, la création de chatbots à l'aide de Lex, le partage de ressources QuickSight entre comptes et la création de modèles CloudFormation pour les déploiements. Il aime explorer AWS en prenant chaque problème de ses clients comme un défi pour en explorer davantage et leur proposer des solutions.
Ajay Vishwakarma est un ingénieur ML pour l'aile AWS de la pratique des solutions d'IA de Wipro. Il possède une bonne expérience dans la création de solutions BYOM pour des algorithmes personnalisés dans SageMaker, le déploiement de pipelines ETL de bout en bout, la création de chatbots à l'aide de Lex, le partage de ressources QuickSight entre comptes et la création de modèles CloudFormation pour les déploiements. Il aime explorer AWS en prenant chaque problème de ses clients comme un défi pour en explorer davantage et leur proposer des solutions.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- La source: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

