
Image par auteur
Supervisé est une sous-catégorie d'apprentissage automatique dans laquelle l'ordinateur apprend à partir de l'ensemble de données étiqueté contenant à la fois l'entrée et la sortie correcte. Il essaie de trouver la fonction de mappage qui relie l'entrée (x) à la sortie (y). Vous pouvez imaginer que cela revient à apprendre à votre jeune frère ou sœur comment reconnaître différents animaux. Vous leur montrerez quelques images (x) et leur direz comment s'appelle chaque animal (y). Après un certain temps, ils apprendront les différences et seront capables de reconnaître correctement la nouvelle image. C’est l’intuition de base derrière l’apprentissage supervisé. Avant d’aller plus loin, examinons de plus près son fonctionnement.
Comment fonctionne l’apprentissage supervisé ?
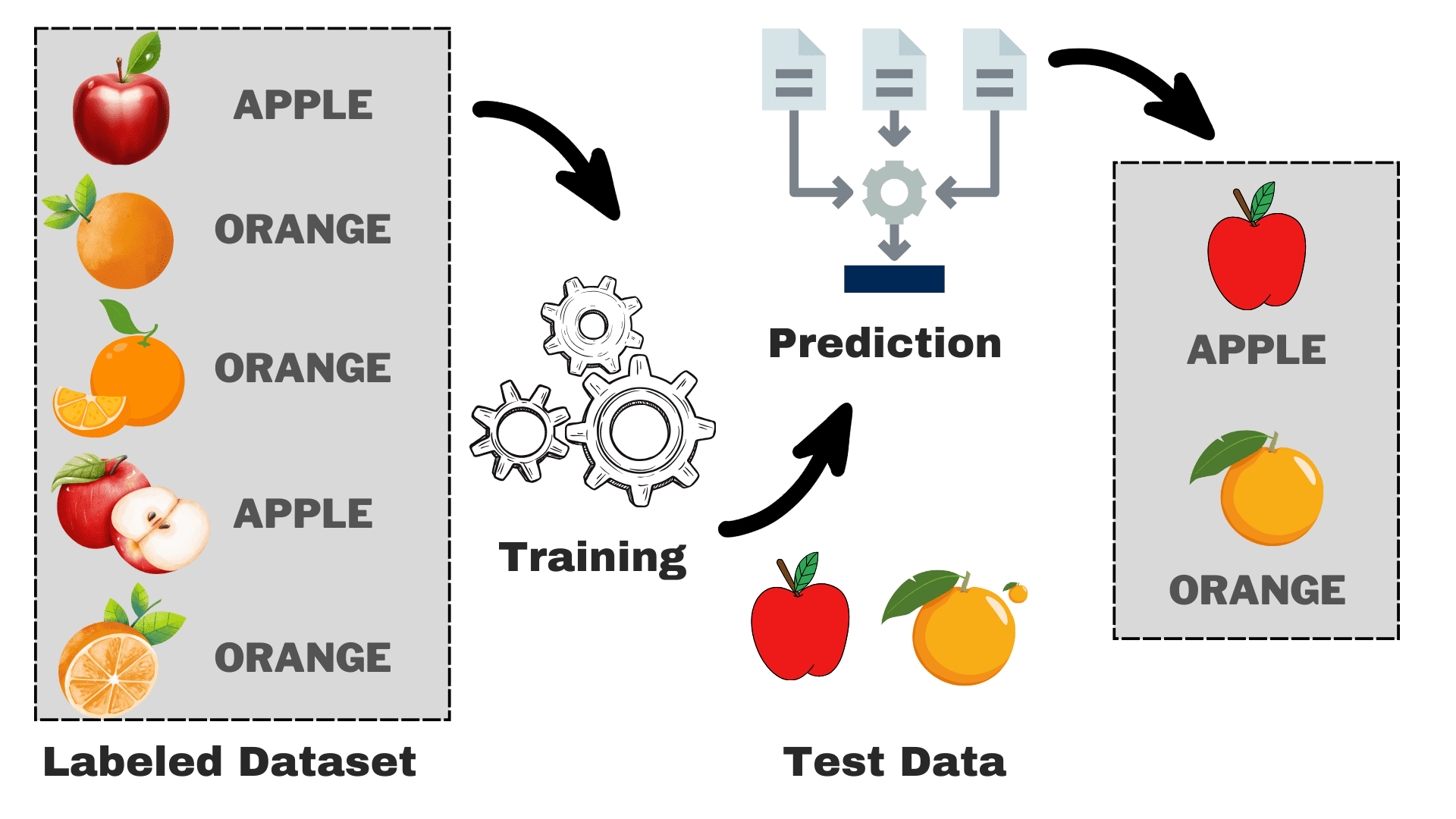
Image par auteur
Supposons que vous souhaitiez créer un modèle capable de différencier les pommes et les oranges en fonction de certaines caractéristiques. Nous pouvons décomposer le processus en tâches suivantes :
- Collecte des données : Rassemblez un ensemble de données avec des images de pommes et d'oranges, et chaque image est étiquetée « pomme » ou « orange ».
- Sélection de modèle: Nous devons choisir ici le bon classificateur, souvent appelé le bon algorithme d'apprentissage automatique supervisé pour votre tâche. C'est comme choisir les bonnes lunettes qui vous aideront à mieux voir
- Entraînement du modèle : Maintenant, vous alimentez l’algorithme avec les images étiquetées de pommes et d’oranges. L’algorithme examine ces images et apprend à reconnaître les différences, telles que la couleur, la forme et la taille des pommes et des oranges.
- Évaluation et tests : Pour vérifier si votre modèle fonctionne correctement, nous lui fournirons des images inédites et comparerons les prédictions avec la réalité.
L’apprentissage supervisé peut être divisé en deux types principaux :
Classification
Dans les tâches de classification, l'objectif principal est d'attribuer des points de données à des catégories spécifiques à partir d'un ensemble de classes discrètes. Lorsqu’il n’y a que deux résultats possibles, tels que « oui » ou « non », « spam » ou « pas spam », « accepté » ou « rejeté », on parle de classification binaire. Cependant, lorsqu'il y a plus de deux catégories ou classes impliquées, comme la notation des étudiants en fonction de leurs notes (par exemple, A, B, C, D, F), cela devient un exemple de problème de multi-classification.
Régression
Pour les problèmes de régression, vous essayez de prédire une valeur numérique continue. Par exemple, vous pourriez être intéressé à prédire vos résultats à l’examen final en fonction de vos performances passées en classe. Les scores prédits peuvent couvrir n’importe quelle valeur dans une plage spécifique, généralement de 0 à 100 dans notre cas.
Nous avons désormais une compréhension de base du processus global. Nous explorerons les algorithmes populaires d’apprentissage automatique supervisé, leur utilisation et leur fonctionnement :
1. Régression linéaire
Comme son nom l'indique, il est utilisé pour des tâches de régression telles que la prévision des cours boursiers, la prévision de la température, l'estimation de la probabilité de progression de la maladie, etc. Nous essayons de prédire la cible (variable dépendante) en utilisant l'ensemble d'étiquettes (variables indépendantes). Cela suppose que nous avons une relation linéaire entre nos fonctionnalités d'entrée et l'étiquette. L'idée centrale consiste à prédire la ligne la mieux ajustée pour nos points de données en minimisant l'erreur entre nos valeurs réelles et prédites. Cette droite est représentée par l'équation :
Où,
- Y Sortie prévue.
- X = Caractéristique d'entrée ou matrice de caractéristiques dans la régression linéaire multiple
- b0 = Interception (là où la ligne croise l'axe Y).
- b1 = Pente ou coefficient qui détermine l'inclinaison de la ligne.
Il estime la pente de la ligne (poids) et son origine (biais). Cette ligne peut être utilisée davantage pour faire des prédictions. Bien qu’il s’agisse du modèle le plus simple et le plus utile pour développer les lignes de base, il est très sensible aux valeurs aberrantes qui peuvent influencer la position de la ligne.
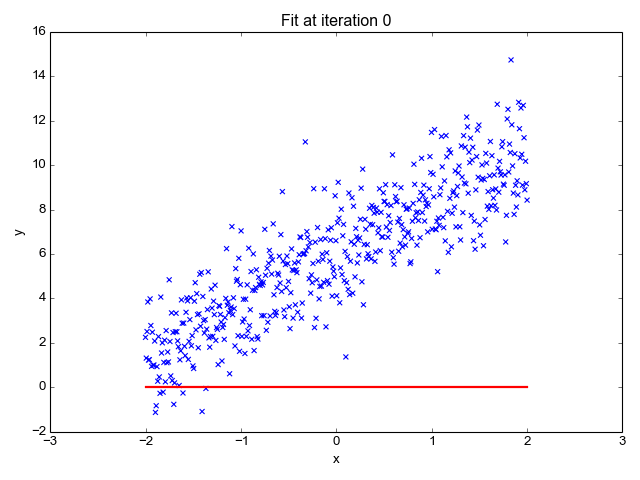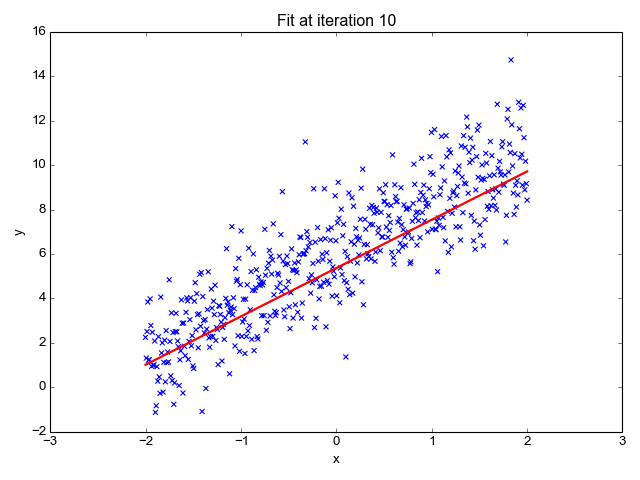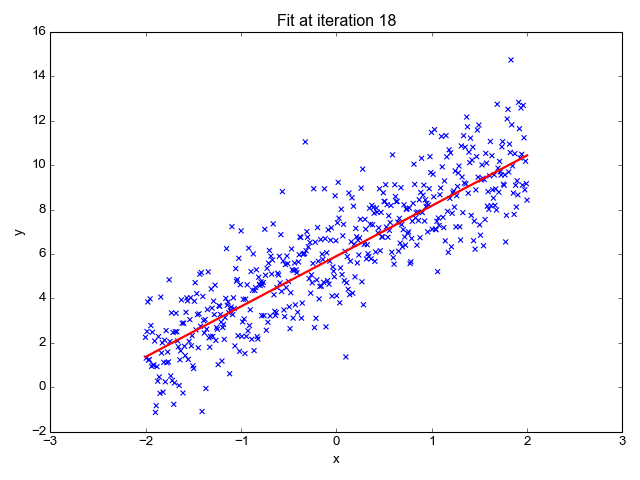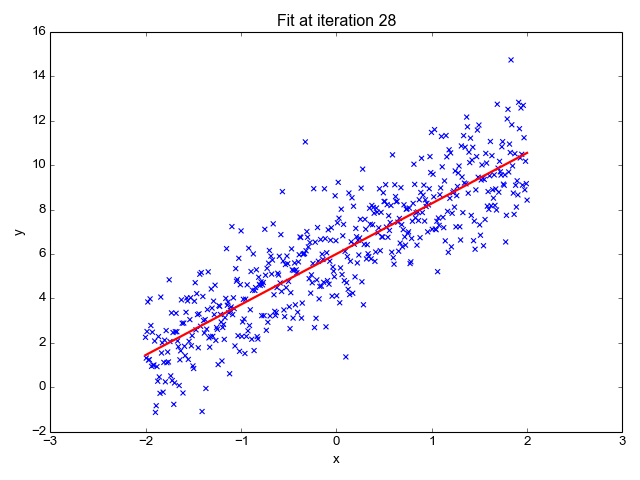
Gif sur Primo.ai
2. Régression logistique
Bien qu'il ait une régression dans son nom, il est fondamentalement utilisé pour les problèmes de classification binaire. Il prédit la probabilité d'un résultat positif (variable dépendante) qui se situe entre 0 et 1. En fixant un seuil (généralement 0.5), nous classons les points de données : ceux avec une probabilité supérieure au seuil appartiennent à la classe positive, et vice versa. La régression logistique calcule cette probabilité à l'aide de la fonction sigmoïde appliquée à la combinaison linéaire des entités en entrée qui est spécifiée comme :
Où,
- P(Y=1) = Probabilité du point de données appartenant à la classe positive
- X1 ,… ,Xn = Caractéristiques d'entrée
- b0,….,bn = Poids d'entrée que l'algorithme apprend pendant l'entraînement
Cette fonction sigmoïde se présente sous la forme d'une courbe en forme de S qui transforme n'importe quel point de données en un score de probabilité compris entre 0 et 1. Vous pouvez voir le graphique ci-dessous pour une meilleure compréhension.
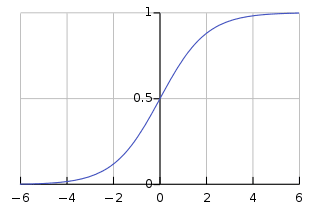
Image sur Wikipédia
Une valeur plus proche de 1 indique une plus grande confiance dans le modèle dans sa prédiction. Tout comme la régression linéaire, elle est connue pour sa simplicité mais on ne peut pas effectuer la classification multi-classes sans modifier l'algorithme d'origine.
3. Arbres de décision
Contrairement aux deux algorithmes ci-dessus, les arbres de décision peuvent être utilisés à la fois pour des tâches de classification et de régression. Il a une structure hiérarchique, tout comme les organigrammes. À chaque nœud, une décision concernant le chemin est prise en fonction de certaines valeurs de caractéristiques. Le processus continue jusqu'à ce que nous atteignions le dernier nœud qui représente la décision finale. Voici quelques termes de base que vous devez connaître :
- Noeud principal: Le nœud supérieur contenant l’intégralité de l’ensemble de données est appelé nœud racine. Nous sélectionnons ensuite la meilleure fonctionnalité à l'aide d'un algorithme pour diviser l'ensemble de données en 2 sous-arbres ou plus.
- Nœuds internes : Chaque nœud interne représente une fonctionnalité spécifique et une règle de décision pour décider de la prochaine direction possible pour un point de données.
- Nœuds feuilles : Les nœuds de fin qui représentent une étiquette de classe sont appelés nœuds feuilles.
Il prédit les valeurs numériques continues pour les tâches de régression. À mesure que la taille de l’ensemble de données augmente, il capture le bruit conduisant au surapprentissage. Cela peut être géré en élaguant l’arbre de décision. Nous supprimons les branches qui n'améliorent pas significativement la précision de nos décisions. Cela permet à notre arbre de se concentrer sur les facteurs les plus importants et d’éviter de se perdre dans les détails.
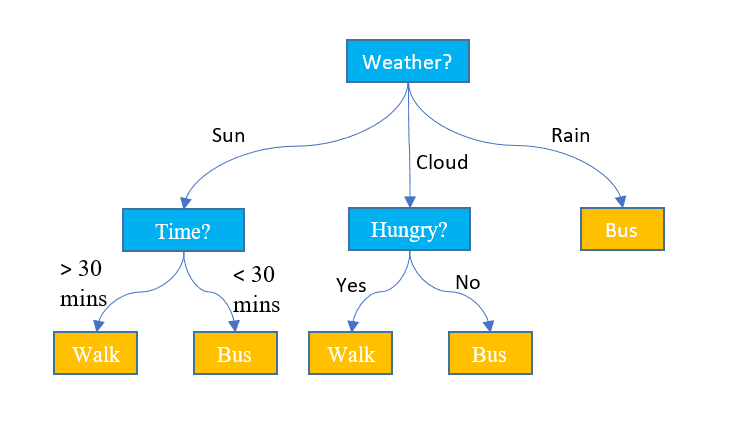
Image Jake Hoare sur Displayr
4. Forêt aléatoire
La forêt aléatoire peut également être utilisée à la fois pour les tâches de classification et de régression. Il s'agit d'un groupe d'arbres de décision travaillant ensemble pour faire la prédiction finale. Vous pouvez le considérer comme un comité d’experts prenant une décision collective. Voici comment cela fonctionne :
- Échantillonnage des données : Au lieu de prendre l’ensemble des données en une seule fois, il prélève des échantillons aléatoires via un processus appelé bootstrapping ou bagging.
- Sélection de fonctionnalité: Pour chaque arbre de décision dans une forêt aléatoire, seul le sous-ensemble aléatoire de fonctionnalités est pris en compte pour la prise de décision au lieu de l'ensemble complet des fonctionnalités.
- Vote: Pour la classification, chaque arbre de décision de la forêt aléatoire vote et la classe ayant obtenu le plus de votes est sélectionnée. Pour la régression, nous faisons la moyenne des valeurs obtenues de tous les arbres.
Bien que cela réduise l'effet du surajustement causé par les arbres de décision individuels, cela coûte cher en termes de calcul. Un mot que vous lirez fréquemment dans la littérature est que la forêt aléatoire est une méthode d’apprentissage d’ensemble, ce qui signifie qu’elle combine plusieurs modèles pour améliorer les performances globales.
5. Machines vectorielles de soutien (SVM)
Il est principalement utilisé pour les problèmes de classification, mais peut également gérer des tâches de régression. Il tente de trouver le meilleur hyperplan séparant les classes distinctes en utilisant l’approche statistique, contrairement à l’approche probabiliste de la régression logistique. Nous pouvons utiliser le SVM linéaire pour les données linéairement séparables. Cependant, la plupart des données du monde réel sont non linéaires et nous utilisons les astuces du noyau pour séparer les classes. Voyons en profondeur comment cela fonctionne :
- Sélection d'hyperplan : En classification binaire, SVM trouve le meilleur hyperplan (ligne 2D) pour séparer les classes tout en maximisant la marge. La marge est la distance entre l'hyperplan et les points de données les plus proches de l'hyperplan.
- Astuce du noyau : Pour les données linéairement inséparables, nous utilisons une astuce du noyau qui mappe l'espace de données d'origine dans un espace de grande dimension où elles peuvent être séparées linéairement. Les noyaux courants comprennent les noyaux linéaires, polynomiaux, à fonction de base radiale (RBF) et sigmoïde.
- Maximisation de la marge : SVM tente également d'améliorer la généralisation du modèle en augmentant la marge de maximisation.
- Classification: Une fois le modèle entraîné, les prédictions peuvent être faites en fonction de sa position par rapport à l'hyperplan.
SVM dispose également d'un paramètre appelé C qui contrôle le compromis entre maximiser la marge et maintenir l'erreur de classification au minimum. Bien qu’ils puissent bien gérer des données de grande dimension et non linéaires, choisir le bon noyau et l’hyperparamètre n’est pas aussi simple qu’il y paraît.
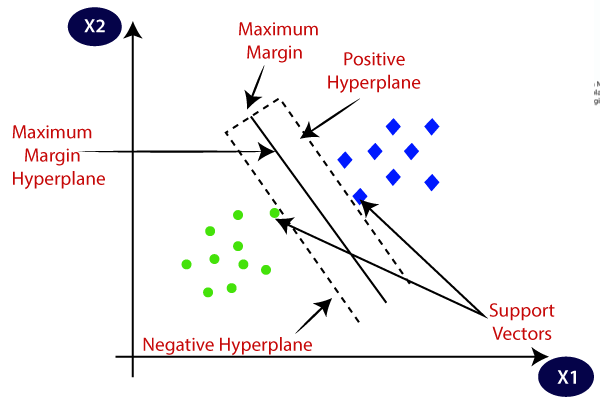
Image sur Point Java
6. k-Voisins les plus proches (k-NN)
K-NN est l'algorithme d'apprentissage supervisé le plus simple, principalement utilisé pour les tâches de classification. Il ne fait aucune hypothèse sur les données et attribue au nouveau point de données une catégorie en fonction de sa similitude avec les points existants. Pendant la phase de formation, il conserve l’intégralité de l’ensemble de données comme point de référence. Il calcule ensuite la distance entre le nouveau point de données et tous les points existants en utilisant une métrique de distance (distance Eucilinedain par exemple). Sur la base de ces distances, il identifie les K voisins les plus proches de ces points de données. Nous comptons ensuite l’occurrence de chaque classe parmi les K voisins les plus proches et attribuons la classe apparaissant le plus fréquemment comme prédiction finale.
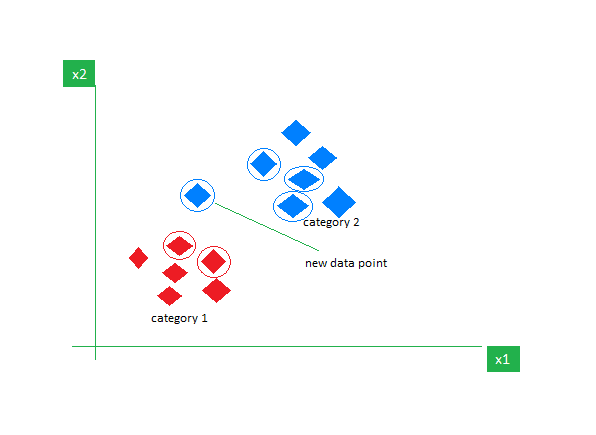
Image sur GeekspourGeeks
Choisir la bonne valeur de K nécessite de l’expérimentation. Bien qu'il soit robuste aux données bruitées, il ne convient pas aux ensembles de données de grande dimension et entraîne un coût élevé en raison du calcul de la distance de tous les points de données.
En concluant cet article, j'encourage les lecteurs à explorer davantage d'algorithmes et à essayer de les implémenter à partir de zéro. Cela renforcera votre compréhension de la façon dont les choses fonctionnent sous le capot. Voici quelques ressources supplémentaires pour vous aider à démarrer :
Kanwal Mehren est un développeur de logiciels en herbe avec un vif intérêt pour la science des données et les applications de l'IA en médecine. Kanwal a été sélectionné comme Google Generation Scholar 2022 pour la région APAC. Kanwal aime partager ses connaissances techniques en écrivant des articles sur des sujets d'actualité et se passionne pour l'amélioration de la représentation des femmes dans l'industrie technologique.
- Contenu propulsé par le référencement et distribution de relations publiques. Soyez amplifié aujourd'hui.
- PlatoData.Network Ai générative verticale. Autonomisez-vous. Accéder ici.
- PlatoAiStream. Intelligence Web3. Connaissance Amplifiée. Accéder ici.
- PlatonESG. Automobile / VE, Carbone, Technologie propre, Énergie, Environnement, Solaire, La gestion des déchets. Accéder ici.
- PlatoHealth. Veille biotechnologique et essais cliniques. Accéder ici.
- GraphiquePrime. Élevez votre jeu de trading avec ChartPrime. Accéder ici.
- Décalages de bloc. Modernisation de la propriété des compensations environnementales. Accéder ici.
- La source: https://www.kdnuggets.com/understanding-supervised-learning-theory-and-overview?utm_source=rss&utm_medium=rss&utm_campaign=understanding-supervised-learning-theory-and-overview

