Wussten Sie, dass der Ahrefs-Blog zwar auf WordPress basiert, der Rest der Website jedoch auf JavaScript wie React basiert?
Die Realität im aktuellen Web ist, dass JavaScript überall ist. Die meisten Websites verwenden eine Art JavaScript, um Interaktivität hinzuzufügen und die Benutzererfahrung zu verbessern.
Doch das meiste JavaScript, das auf so vielen Websites verwendet wird, hat keinerlei Auswirkungen auf die Suchmaschinenoptimierung. Wenn Sie eine normale WordPress-Installation ohne viele Anpassungen haben, wird wahrscheinlich keines der Probleme auf Sie zutreffen.
Probleme treten dann auf, wenn JavaScript zum Erstellen einer gesamten Seite, zum Hinzufügen oder Entfernen von Elementen oder zum Ändern bereits vorhandener Elemente auf der Seite verwendet wird. Einige Websites verwenden es für Menüs, zum Eingeben von Produkten oder Preisen, zum Abrufen von Inhalten aus mehreren Quellen oder in einigen Fällen für alles auf der Website. Wenn das nach Ihrer Website klingt, lesen Sie weiter.
Wir sehen ganze Systeme und Apps, die mit JavaScript-Frameworks erstellt wurden, und sogar einige traditionelle CMS mit JavaScript-Flair, bei denen sie Headless oder entkoppelt sind. Das CMS wird als Backend-Datenquelle verwendet, die Frontend-Präsentation erfolgt jedoch über JavaScript.
Ich sage nicht, dass SEOs losgehen und lernen müssen, wie man JavaScript programmiert. Ich empfehle es eigentlich nicht, da es unwahrscheinlich ist, dass Sie den Code jemals berühren werden. Was SEOs wissen müssen, ist, wie Google mit JavaScript umgeht und wie man Probleme behebt.
JavaScript SEO ist ein Teil davon technische SEO (Suchmaschinenoptimierung), die JavaScript-intensive Websites einfach zu crawlen und zu indexieren sowie suchfreundlich macht. Ziel ist es, dass diese Websites gefunden werden und in Suchmaschinen höher ranken.
JavaScript ist nicht schlecht für SEO, und es ist nicht böse. Es unterscheidet sich einfach von dem, was viele SEOs gewohnt sind, und es gibt eine gewisse Lernkurve.
Viele der Prozesse ähneln den Dingen, die SEOs bereits gewohnt sind, es kann jedoch geringfügige Unterschiede geben. Sie werden sich immer noch hauptsächlich mit HTML-Code befassen, nicht mit JavaScript.
Alle normalen Best Practices für On-Page-SEO gelten weiterhin. Sehen Unser Leitfaden zum Thema On-Page-SEO.
Sie finden sogar bekannte Plugin-Optionen zur Handhabung vieler grundlegender SEO-Elemente, sofern diese nicht bereits in das von Ihnen verwendete Framework integriert sind. Bei JavaScript-Frameworks werden diese Module genannt, und Sie finden viele Paketoptionen, um sie zu installieren.
Es gibt Versionen für viele der gängigen Frameworks wie Reagieren, Vue, Angular und Svelte, die Sie finden können, indem Sie nach dem Framework + Modulnamen wie „React Helmet“ suchen. Meta-Tags, Helmet und Head sind beliebte Module mit ähnlicher Funktionalität und ermöglichen das Setzen vieler beliebter Tags, die für SEO benötigt werden.
In mancher Hinsicht ist JavaScript besser als herkömmliches HTML, beispielsweise hinsichtlich der einfachen Erstellung und der Leistung. In mancher Hinsicht ist JavaScript schlechter, da es beispielsweise nicht progressiv analysiert werden kann (wie es bei HTML und CSS der Fall sein kann) und die Seitenlast und -leistung stark beeinträchtigen kann. Oft tauschen Sie Leistung gegen Funktionalität ein.
JavaScript ist nicht perfekt und nicht immer das richtige Werkzeug für den Job. Entwickler verwenden es häufig für Dinge, für die es wahrscheinlich eine bessere Lösung gibt. Aber manchmal muss man mit dem arbeiten, was einem gegeben wird.
Dies sind viele der häufigsten SEO-Probleme, auf die Sie bei der Arbeit mit JavaScript-Websites stoßen können.
Verfügen Sie über eindeutige Titel-Tags und Meta-Beschreibungen
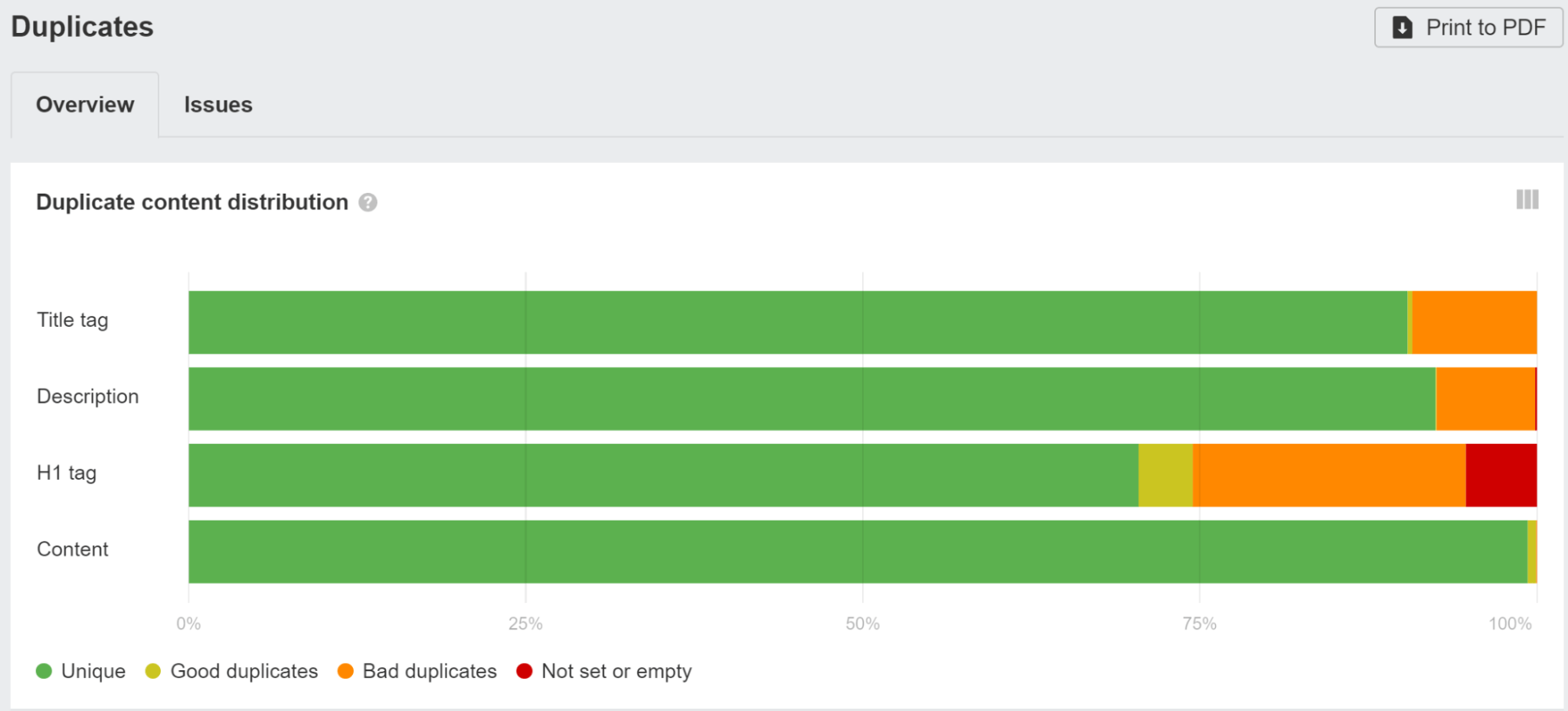
Sie möchten immer noch etwas Einzigartiges haben Titel-Tags und Metabeschreibung auf Ihren Seiten. Da viele JavaScript-Frameworks auf Vorlagen basieren, kann es leicht passieren, dass für alle Seiten oder eine Gruppe von Seiten derselbe Titel oder dieselbe Metabeschreibung verwendet wird.
Prüfen Sie die Duplikate Bericht in Ahrefs' Standortüberwachung Klicken Sie auf eine der Gruppierungen, um weitere Daten zu den von uns gefundenen Problemen anzuzeigen.
Sie können eines der SEO-Module wie Helmet verwenden, um benutzerdefinierte Tags für jede Seite festzulegen.
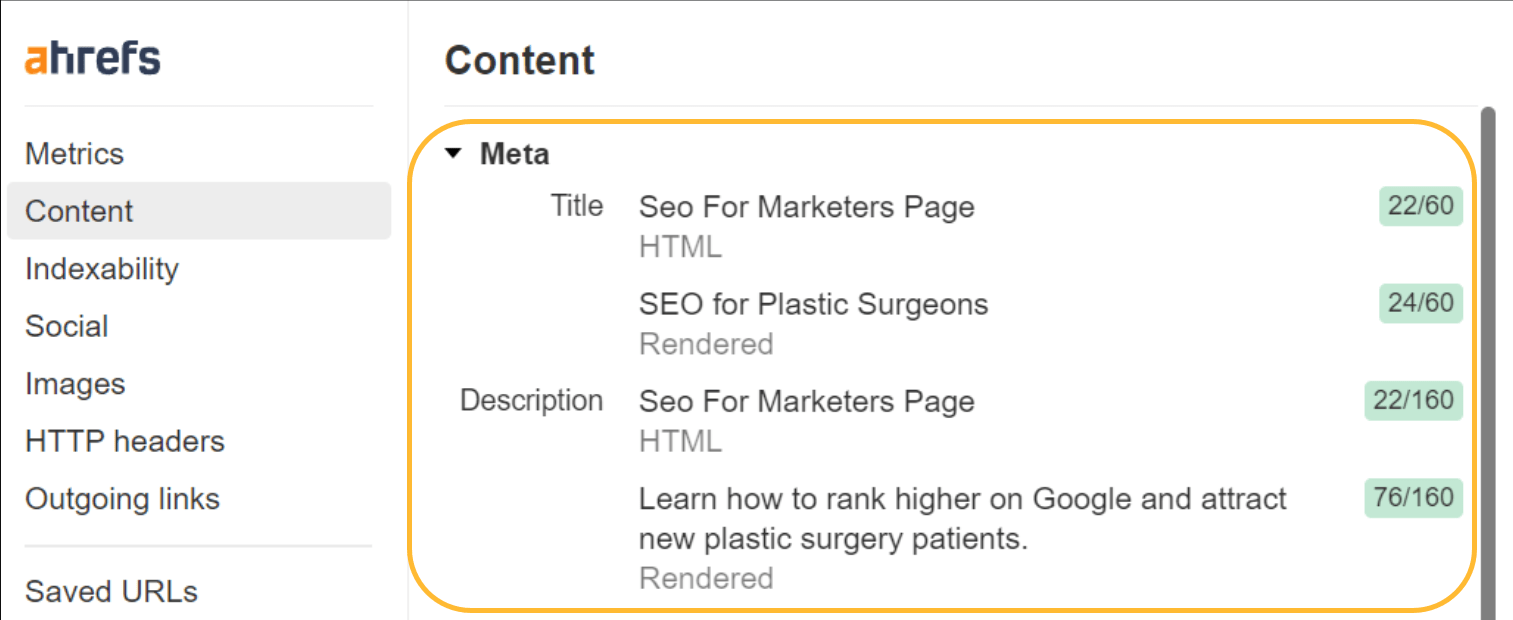
JavaScript kann auch verwendet werden, um von Ihnen möglicherweise festgelegte Standardwerte zu überschreiben. Google wird dies verarbeiten und den überschriebenen Titel oder die überschriebene Beschreibung verwenden. Für Benutzer können Titel jedoch problematisch sein, da ein Titel möglicherweise im Browser angezeigt wird und sie beim Überschreiben ein Blinken bemerken.
Wenn der Titel blinkt, können Sie Ahrefs verwenden. SEO-Toolbar um sowohl die Roh-HTML- als auch die gerenderte Version anzuzeigen.
Google darf Ihre Titel oder Meta-Beschreibungen ohnehin nicht verwenden. Wie bereits erwähnt, lohnt es sich für Benutzer, die Titel aufzuräumen. Die Behebung dieses Problems für Meta-Beschreibungen wird jedoch keinen wirklichen Unterschied machen.
Als wir die Umschreibung von Google untersuchten, stellten wir das fest Google überschreibt Titel in 33.4 % der Fälle und Meta-Beschreibungen in 62.78 % der Fälle. Im Site Audit zeigen wir Ihnen sogar, welche Ihrer Titel-Tags Google geändert hat.
Probleme mit kanonischen Tags
Jahrelang behauptete Google, es respektiere dies nicht kanonische Tags mit JavaScript eingefügt. Schließlich wurde der Dokumentation eine Ausnahme für Fälle hinzugefügt, in denen noch kein Tag vorhanden war. Ich habe diese Veränderung verursacht. Ich habe Tests durchgeführt, um zu zeigen, dass dies funktionierte, während Google allen mitteilte, dass dies nicht der Fall sei.
Wenn bereits ein kanonisches Tag vorhanden war und Sie ein weiteres hinzufügen oder das vorhandene mit JavaScript überschreiben, geben Sie ihnen zwei kanonische Tags. In diesem Fall muss Google herausfinden, welches davon verwendet werden soll, oder die kanonischen Tags zugunsten eines anderen ignorieren Kanonisierungssignale.
Der standardmäßige SEO-Ratschlag „Jede Seite sollte ein selbstreferenzierendes Canonical-Tag haben“ bringt viele SEOs in Schwierigkeiten. Ein Entwickler erfüllt diese Anforderung und macht Seiten mit und ohne abschließenden Schrägstrich selbstkanonisch.
example.com/page mit einer Kanonik von example.com/page und example.com/page/ mit einer Kanonik von example.com/page/. Ups, das ist falsch! Sie möchten wahrscheinlich eine dieser Versionen auf die andere umleiten.
Das Gleiche kann mit parametrisierten Versionen passieren, die Sie möglicherweise kombinieren möchten, aber jede ist selbstreferenzierend.
Google verwendet das restriktivste Meta-Robots-Tag
Mit der Meta-Robots-TagsGoogle wird immer die restriktivste Option wählen, die es sieht – unabhängig vom Standort.
Wenn Sie ein Index-Tag im Roh-HTML und ein Noindex-Tag im gerenderten HTML haben, behandelt Google es als Noindex. Wenn Sie im Roh-HTML ein Noindex-Tag haben, es aber mithilfe von JavaScript mit einem Index-Tag überschreiben, wird die Seite trotzdem als Noindex behandelt.
Für Nofollow-Tags funktioniert es genauso. Google wird die restriktivste Option wählen.
Legen Sie Alt-Attribute für Bilder fest
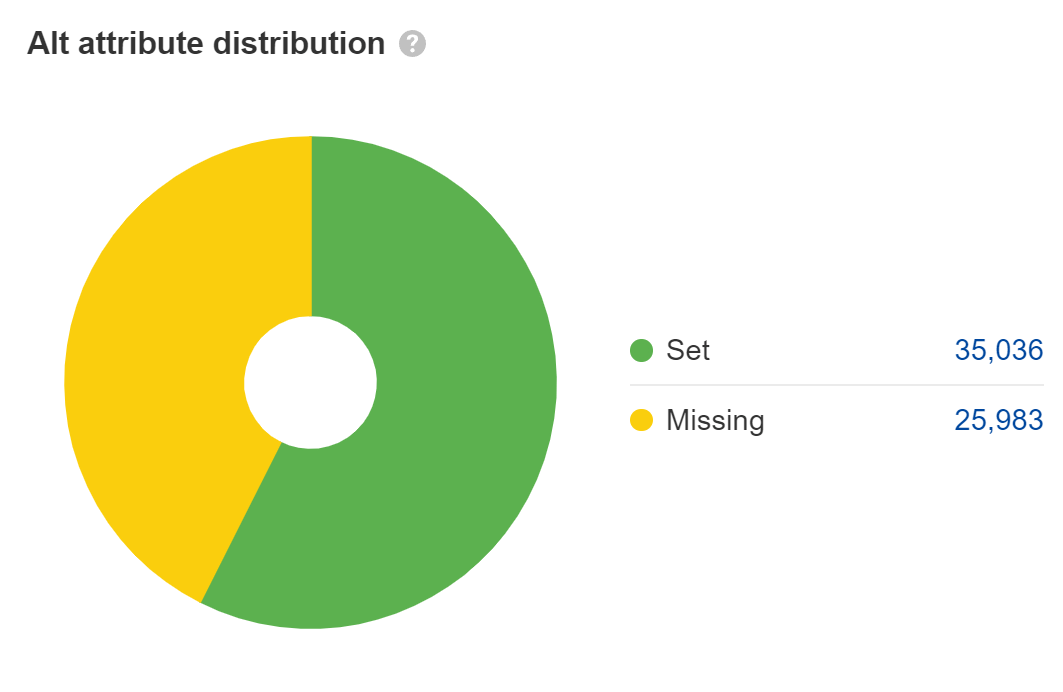
Vermisst Alt-Attribute stellen ein Problem der Barrierefreiheit dar, das zu einem rechtlichen Problem werden kann. Die meisten großen Unternehmen wurden wegen ADA-Compliance-Problemen auf ihren Websites verklagt, und einige werden mehrmals im Jahr verklagt. Ich würde das für die Hauptinhaltsbilder beheben, aber nicht für Dinge wie Platzhalter oder dekorative Bilder, bei denen Sie die Alt-Attribute leer lassen können.
Bei der Websuche zählt der Text in Alt-Attributen als Text auf der Seite, aber das ist eigentlich die einzige Rolle, die er spielt. Meiner Meinung nach wird seine Bedeutung für SEO oft überbewertet. Es hilft jedoch bei der Bildsuche und dem Bildranking.
Viele JavaScript-Entwickler lassen Alt-Attribute leer, also überprüfen Sie noch einmal, ob Ihres vorhanden ist. Schaue auf die Bilder Bericht einreichen Standortüberwachung um diese zu finden.
Erlauben Sie das Crawlen von JavaScript-Dateien
Blockieren Sie nicht den Zugriff auf Ressourcen, wenn diese zum Erstellen eines Teils der Seite oder zum Ergänzen des Inhalts benötigt werden. Google muss auf Ressourcen zugreifen und diese herunterladen, damit die Seiten ordnungsgemäß gerendert werden können. In deinem robots.txt, der einfachste Weg, das Crawlen der benötigten Ressourcen zu ermöglichen, besteht darin, Folgendes hinzuzufügen:
User-Agent: GooglebotAllow: .jsAllow: .css
Überprüfen Sie außerdem die robots.txt-Dateien auf Subdomains oder zusätzliche Domains, von denen Sie möglicherweise Anfragen stellen, beispielsweise solche für Ihre API-Aufrufe.
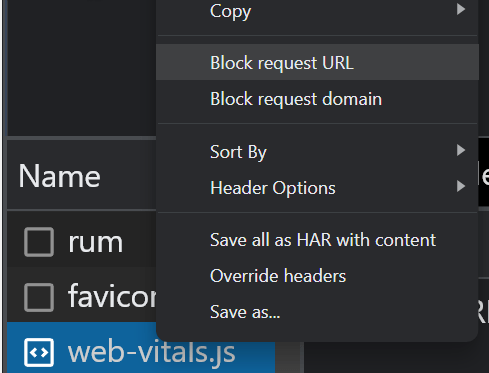
Wenn Sie Ressourcen mit robots.txt blockiert haben, können Sie mithilfe der Blockierungsoptionen auf der Registerkarte „Netzwerk“ in den Chrome Dev Tools überprüfen, ob sich dies auf den Seiteninhalt auswirkt. Wählen Sie die Datei aus und blockieren Sie sie. Laden Sie dann die Seite neu, um zu sehen, ob Änderungen vorgenommen wurden.
Überprüfen Sie, ob Google Ihre Inhalte sieht
Viele Seiten mit JavaScript-Funktionalität zeigen Google möglicherweise nicht standardmäßig den gesamten Inhalt an. Wenn Sie mit Ihren Entwicklern sprechen, verweisen diese möglicherweise darauf, dass das Document Object Model (DOM) nicht geladen ist. Dies bedeutet, dass der Inhalt nicht standardmäßig geladen wurde und später möglicherweise durch eine Aktion wie einen Klick geladen wird.
Eine schnelle Überprüfung besteht darin, einfach in Google nach einem Ausschnitt Ihres Inhalts in Anführungszeichen zu suchen. Suchen Sie nach „einen Ausdruck aus Ihrem Inhalt“ und prüfen Sie, ob die Seite in den Suchergebnissen angezeigt wird. Wenn ja, wurde Ihr Inhalt wahrscheinlich gesehen.
Randnotiz.
Inhalte, die standardmäßig ausgeblendet sind, werden möglicherweise nicht in Ihrem Snippet angezeigt SERPs. Es ist besonders wichtig, Ihre mobile Version zu überprüfen, da diese oft aus Gründen der Benutzerfreundlichkeit abgespeckt ist.
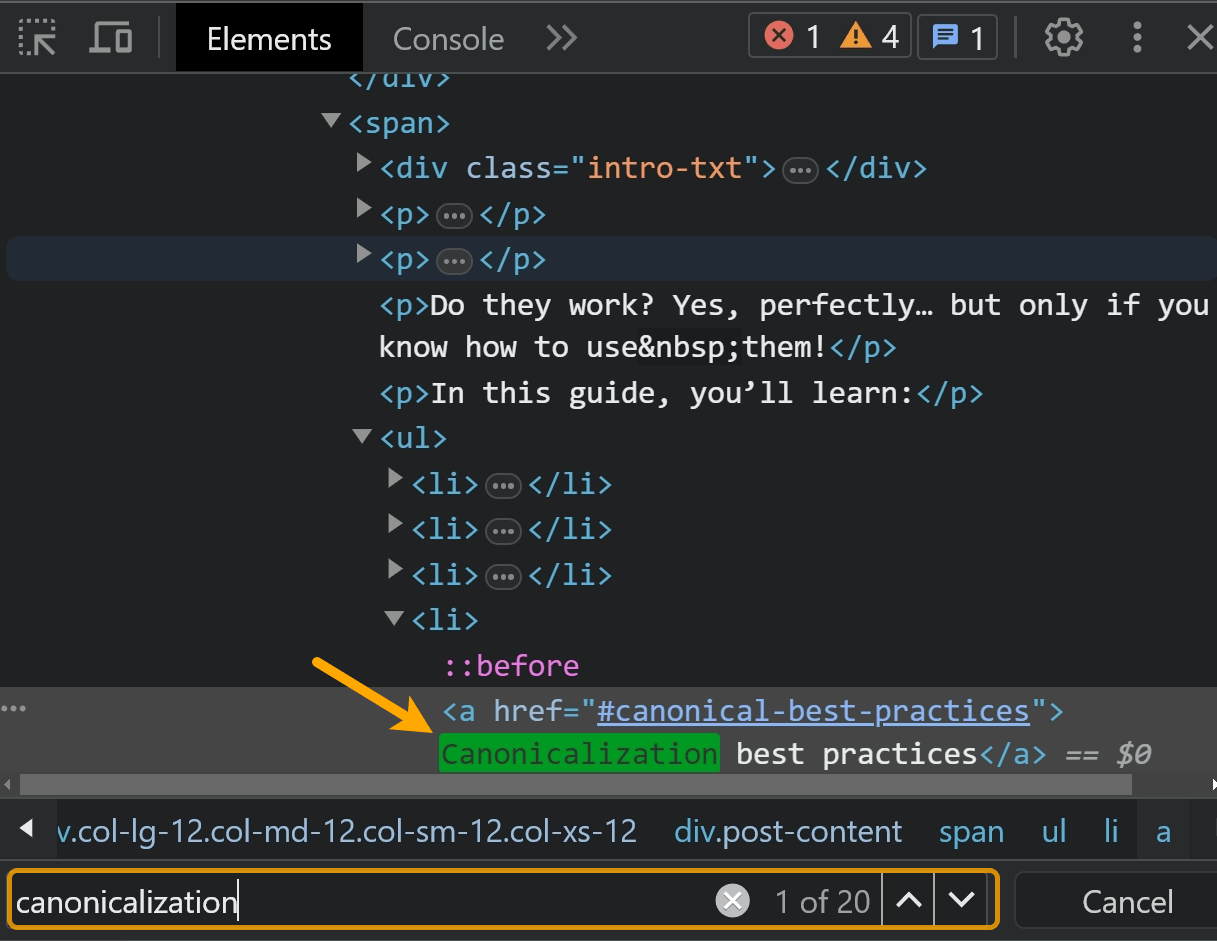
Sie können auch mit der rechten Maustaste klicken und die Option „Inspizieren“ verwenden. Suchen Sie auf der Registerkarte „Elemente“ nach dem Text.
Die beste Überprüfung besteht darin, den Inhalt eines der Testtools von Google zu durchsuchen, beispielsweise das URL-Inspektionstool in der Google Search Console. Ich werde später mehr darüber sprechen.
Ich würde auf jeden Fall alles überprüfen, was sich hinter einem Akkordeon oder einem Dropdown befindet. Oft stellen diese Elemente Anfragen, die beim Anklicken Inhalte in die Seite laden. Google klickt nicht und sieht daher den Inhalt nicht.
Wenn Sie die Prüfmethode zum Durchsuchen von Inhalten verwenden, achten Sie darauf, den Inhalt zu kopieren und dann die Seite neu zu laden oder sie in einem Inkognito-Fenster zu öffnen, bevor Sie mit der Suche beginnen.
Wenn Sie auf das Element geklickt und den Inhalt geladen haben, als diese Aktion ausgeführt wurde, finden Sie den Inhalt. Beim erneuten Laden der Seite wird möglicherweise nicht das gleiche Ergebnis angezeigt.
Probleme mit doppelten Inhalten
Bei JavaScript kann es mehrere URLs für denselben Inhalt geben, was dazu führt Duplicate Content Probleme. Dies kann durch Groß- und Kleinschreibung, abschließende Schrägstriche, IDs, Parameter mit IDs usw. verursacht werden. Es kann also alles davon vorliegen:
domain.com/Abcdomain.com/abcdomain.com/123domain.com/?id=123
Wenn Sie nur eine Version indizieren möchten, sollten Sie einen selbstreferenzierenden Canonical und entweder Canonical-Tags von anderen Versionen festlegen, die auf die Hauptversion verweisen oder idealerweise die anderen Versionen auf die Hauptversion umleiten.
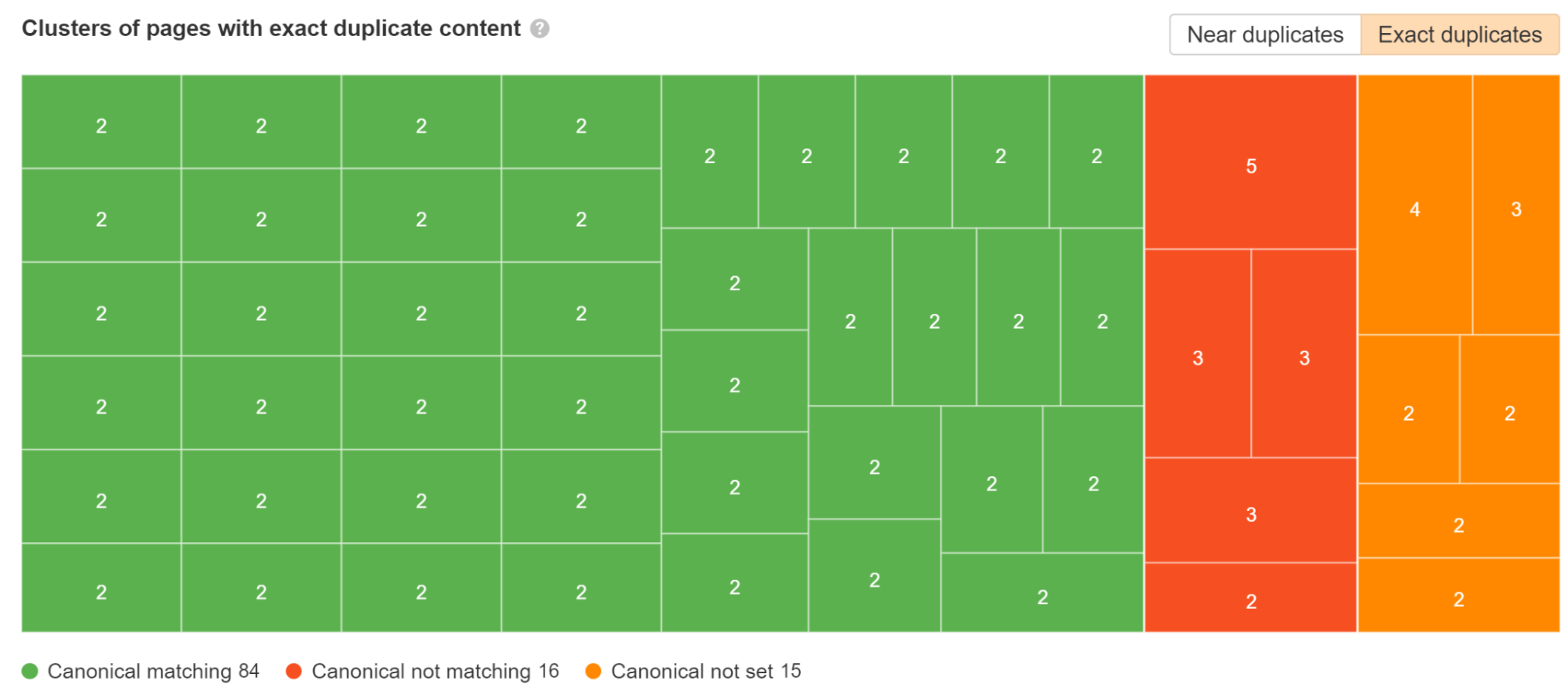
Prüfen Sie die Duplikate Bericht einreichen Standortüberwachung. Wir schlüsseln auf, bei welchen doppelten Clustern kanonische Tags festgelegt sind und bei welchen es Probleme gibt.
Ein häufiges Problem bei JavaScript-Frameworks besteht darin, dass Seiten mit und ohne abschließenden Schrägstrich existieren können. Idealerweise wählen Sie die von Ihnen bevorzugte Version aus und stellen sicher, dass diese Version über ein selbstreferenzierendes Canonical-Tag verfügt, und leiten dann die andere Version auf Ihre bevorzugte Version um.
Bei App-Shell-Modellen werden in der ersten HTML-Antwort möglicherweise nur sehr wenige Inhalte und Code angezeigt. Tatsächlich kann auf jeder Seite der Website derselbe Code angezeigt werden, und dieser Code kann genau mit dem Code auf einigen anderen Websites identisch sein.
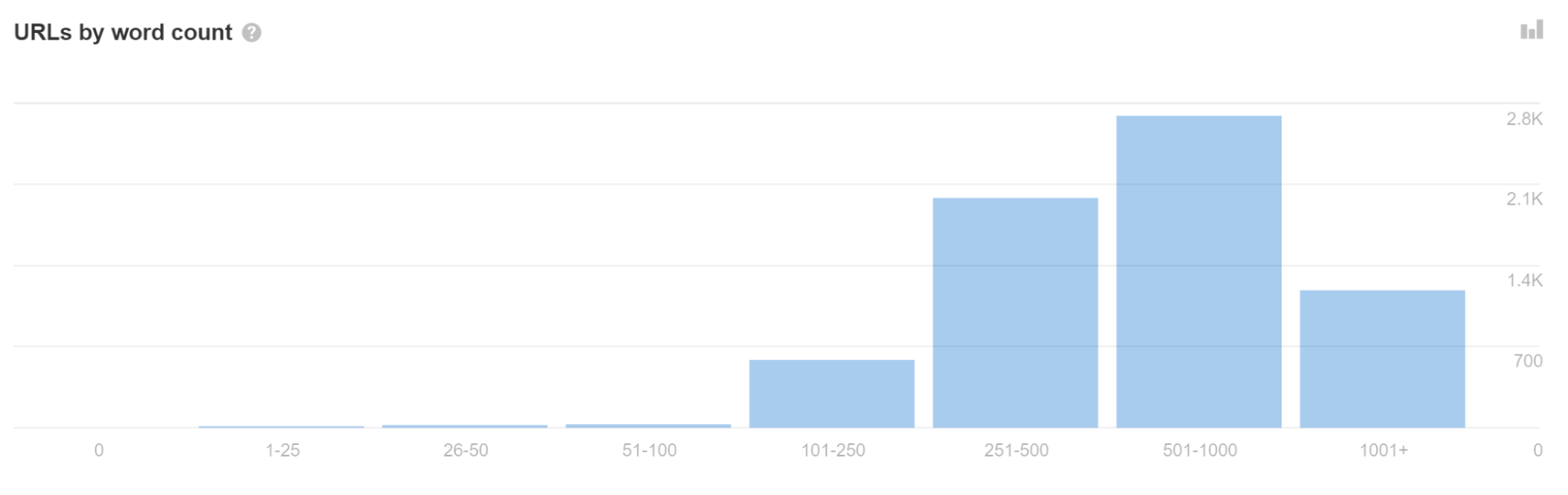
Wenn Sie in Site Audit viele URLs mit einer geringen Wortzahl sehen, kann dies ein Hinweis darauf sein, dass bei Ihnen dieses Problem vorliegt.
Dies kann manchmal dazu führen, dass Seiten als Duplikate behandelt werden und nicht sofort gerendert werden. Schlimmer noch: In den Suchergebnissen wird möglicherweise die falsche Seite oder sogar die falsche Website angezeigt. Dies sollte sich mit der Zeit von selbst beheben, kann jedoch insbesondere bei neueren Websites problematisch sein.
Verwenden Sie in URLs keine Fragmente (#).
# verfügt bereits über eine definierte Funktionalität für Browser. Wenn Sie darauf klicken, verlinkt es auf einen anderen Teil einer Seite – wie zum Beispiel unsere „Inhaltsverzeichnis“-Funktion im Blog. Server verarbeiten im Allgemeinen nichts nach einem #. Also für eine URL wie abc.com/#something, alles nach einem # wird normalerweise ignoriert.
JavaScript-Entwickler haben beschlossen, # als Auslöser für verschiedene Zwecke zu verwenden, was zu Verwirrung führt. Am häufigsten werden sie für die Weiterleitung und für Zwecke missbraucht URL-Parameter. Ja, sie funktionieren. Nein, das solltest du nicht tun.
JavaScript-Frameworks verfügen normalerweise über Router, die sogenannte Routen (Pfade) zuordnen saubere URLs. Viele JavaScript-Entwickler verwenden Hashes (#) für das Routing. Dies ist insbesondere bei Vue und einigen früheren Versionen von Angular ein Problem.
Um dieses Problem für Vue zu beheben, können Sie mit Ihrem Entwickler zusammenarbeiten, um Folgendes zu ändern:
Vue router: Use ‘History’ Mode instead of the traditional ‘Hash’ Mode.
const router = new VueRouter ({mode: ‘history’,router: [] //the array of router links)}
Es gibt einen wachsenden Trend, dass Menschen # anstelle von ? verwenden. als Fragment-Identifikator, insbesondere für passive URL-Parameter, wie sie zum Tracking verwendet werden. Wegen all der Verwirrung und Probleme rate ich eher davon ab. Situationsbedingt könnte es für mich in Ordnung sein, viele unnötige Parameter zu entfernen.
Erstellen Sie eine Sitemap
Die Router-Optionen, die saubere URLs ermöglichen, verfügen in der Regel über ein zusätzliches Modul, das auch Sitemaps erstellen kann. Sie finden sie, indem Sie nach der Sitemap Ihres Systems und Ihres Routers suchen, z. B. „Vue-Router-Sitemap“.
Viele der Rendering-Lösungen verfügen möglicherweise auch über Sitemap-Optionen. Suchen Sie auch hier einfach nach dem System, das Sie verwenden, und googeln Sie das System + die Sitemap, z. B. „Gatsby-Sitemap“, und Sie werden sicher eine Lösung finden, die bereits existiert.
Statuscodes und Soft 404s
Da JavaScript-Frameworks nicht serverseitig sind, können sie nicht wirklich einen Serverfehler wie einen 404 auslösen. Sie haben verschiedene Optionen für Fehlerseiten, wie zum Beispiel:
- Verwenden einer JavaScript-Weiterleitung zu einer Seite, die mit einem 404-Statuscode antwortet.
- Hinzufügen eines Noindex-Tags zu der Seite, die fehlschlägt, zusammen mit einer Fehlermeldung wie „404-Seite nicht gefunden“. Dies wird als Soft 404 behandelt, da der tatsächlich zurückgegebene Statuscode 200 okay ist.
JavaScript-Weiterleitungen sind in Ordnung, werden aber nicht bevorzugt
SEOs sind es gewohnt 301/302-Weiterleitungen, die serverseitig sind. JavaScript wird normalerweise clientseitig ausgeführt. Serverseitige Weiterleitungen und sogar Meta-Refresh-Weiterleitungen sind für Google einfacher zu verarbeiten als JavaScript-Weiterleitungen, da die Seite nicht gerendert werden muss, um sie anzuzeigen.
JavaScript-Weiterleitungen werden beim Rendern weiterhin angezeigt und verarbeitet und sollten in den meisten Fällen in Ordnung sein – sie sind jedoch nicht so ideal wie andere Weiterleitungstypen. Sie werden als permanente Weiterleitungen behandelt und leiten weiterhin alle Signale weiter PageRank.
Sie können diese Weiterleitungen häufig im Code finden, indem Sie nach „window.location.href“ suchen. Die Weiterleitungen könnten möglicherweise auch in der Konfigurationsdatei enthalten sein. In der Next.js-Konfiguration gibt es eine Weiterleitungsfunktion, mit der Sie Weiterleitungen festlegen können. In anderen Systemen finden Sie sie möglicherweise im Router.
Fragen der Internationalisierung
Normalerweise gibt es einige Moduloptionen für verschiedene Frameworks, die einige für die Internationalisierung erforderliche Funktionen unterstützen, z hreflang. Sie wurden üblicherweise auf die verschiedenen Systeme portiert und umfassen i18n, intl oder oft können dieselben Module, die für Header-Tags verwendet werden, wie z. B. Helmet, zum Hinzufügen der benötigten Tags verwendet werden.
Wir weisen auf Hreflang-Probleme im hin Lokalisierung Bericht einreichen Standortüberwachung. Wir haben auch eine Studie durchgeführt und das herausgefunden 67 % der Domains, die hreflang verwenden, haben Probleme.
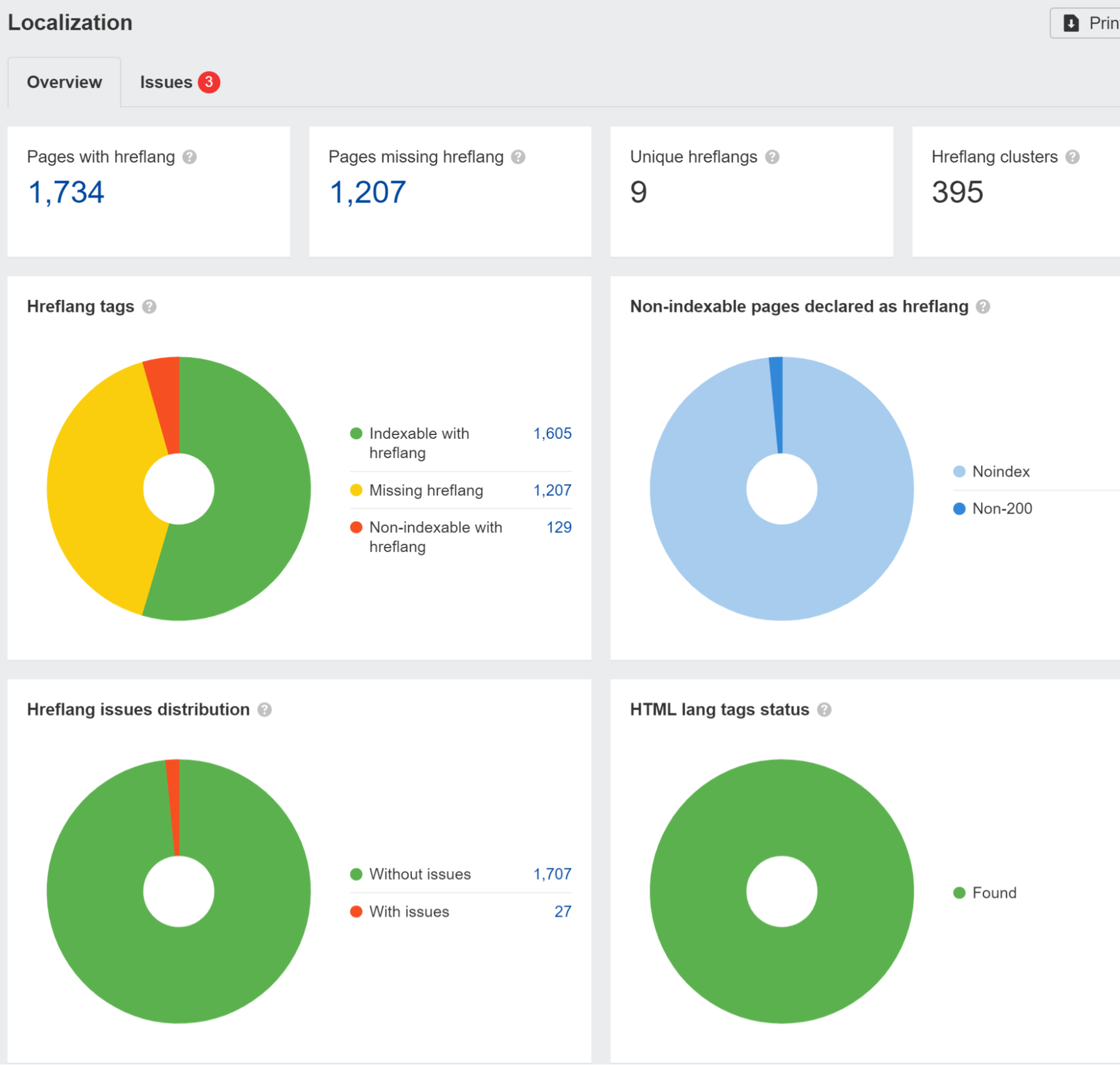
Sie müssen auch vorsichtig sein, wenn Ihre Website Besucher aus einem bestimmten Land blockiert oder behandelt oder eine bestimmte IP auf unterschiedliche Weise verwendet. Dies kann dazu führen, dass Ihre Inhalte nicht gesehen werden Googlebot. Wenn Sie über eine Logik verfügen, die Benutzer umleitet, möchten Sie möglicherweise Bots von dieser Logik ausschließen.
Wir informieren Sie, wenn dies beim Einrichten eines Projekts in Site Audit geschieht.

Verwenden Sie strukturierte Daten
JavaScript kann verwendet werden, um strukturierte Daten auf Ihren Seiten zu generieren oder einzufügen. Es ist ziemlich üblich, dies mit JSON-LD zu tun und wahrscheinlich keine Probleme zu verursachen, aber führen Sie einige Tests durch, um sicherzustellen, dass alles so aussieht, wie Sie es erwarten.
Wir kennzeichnen alle strukturierten Daten, die wir im sehen Fragen Bericht einreichen Standortüberwachung. Suchen Sie nach dem Fehler „Strukturierte Daten verfügen über eine schema.org-Validierung“. Wir sagen Ihnen für jede Seite genau, was falsch ist.
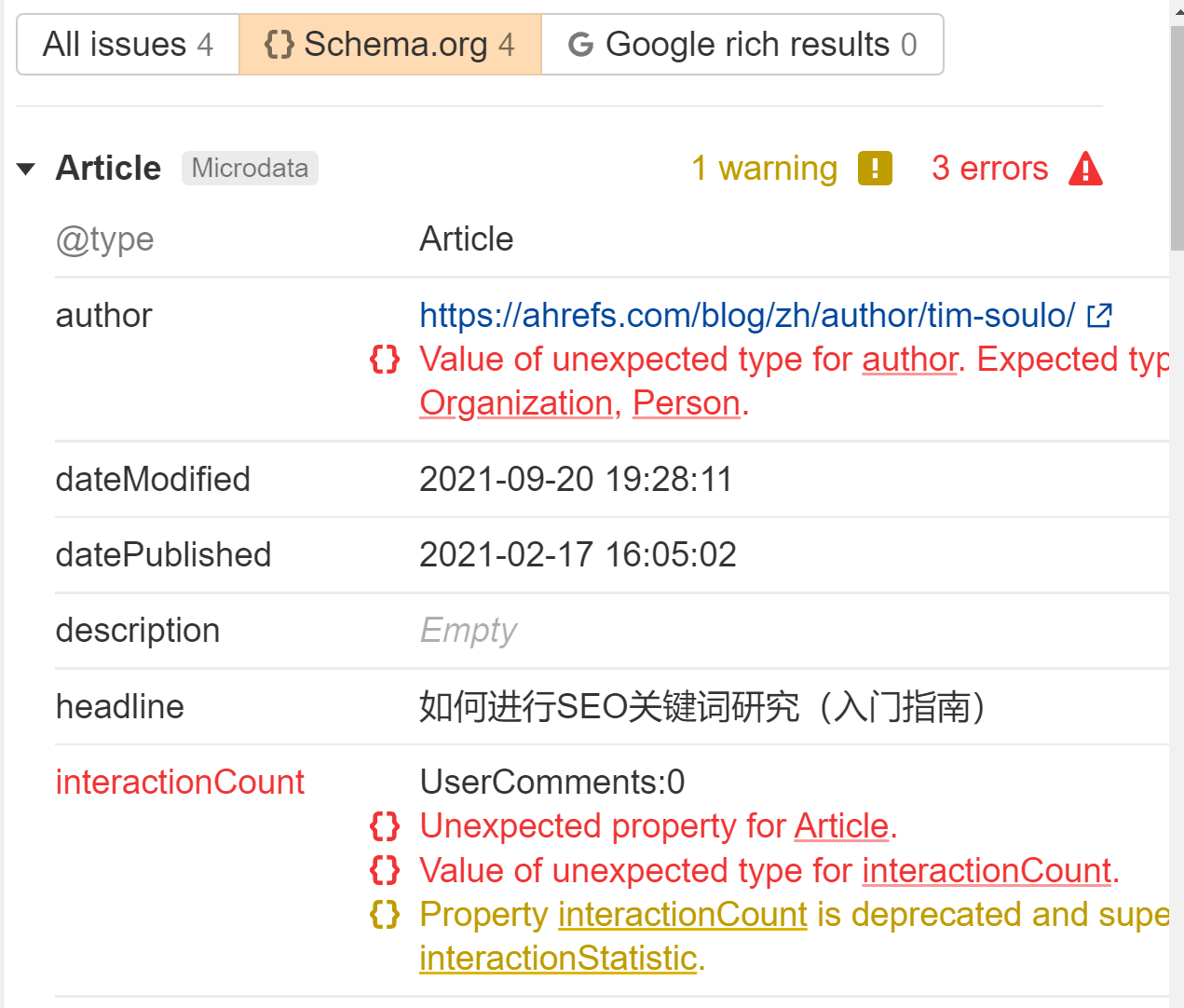
Verwenden Sie Links im Standardformat
Links zu anderen Seiten sollten im Webstandardformat vorliegen. Interne und externe Links müssen ein sein <a> Tag mit einem href Attribut. Es gibt viele Möglichkeiten, Links für Benutzer mit JavaScript bereitzustellen, die nicht suchfreundlich sind.
Gut:
<a href=”/page”>simple is good</a>
<a href=”/page” onclick=”goTo(‘page’)”>still okay</a>
schlecht:
<a onclick=”goTo(‘page’)”>nope, no href</a>
<a href=”javascript:goTo(‘page’)”>nope, missing link</a>
<a href=”javascript:void(0)”>nope, missing link</a>
<span onclick=”goTo(‘page’)”>not the right HTML element</span>
<option value="page">nope, wrong HTML element</option>
<a href=”#”>no link</a>
Knopf, ng-klick, es gibt noch viele weitere Möglichkeiten, wie das falsch gemacht werden kann.
Meiner Erfahrung nach verarbeitet Google immer noch viele der schlechten Links und crawlt sie, aber ich bin mir nicht sicher, wie es sie als Weitergabesignale wie PageRank behandelt. Das Web ist ein chaotischer Ort und die Parser von Google sind oft ziemlich nachsichtig.
Es ist auch erwähnenswert, dass interne Links Mit JavaScript hinzugefügte Elemente werden erst nach dem Rendern übernommen. Das sollte relativ schnell gehen und in den meisten Fällen kein Grund zur Sorge sein.
Verwenden Sie die Dateiversionierung, um unmögliche Zustände bei der Indizierung zu ermitteln
Google speichert alle Ressourcen stark im Cache. Ich werde später etwas ausführlicher darauf eingehen, aber Sie sollten wissen, dass sein System dazu führen kann, dass einige unmögliche Zustände indiziert werden. Das ist eine Eigenart seiner Systeme. In diesen Fällen werden im Renderprozess frühere Dateiversionen verwendet und die indizierte Version einer Seite kann Teile älterer Dateien enthalten.
Sie können Dateiversionierung oder Fingerabdruck (file.12345.js) verwenden, um neue Dateinamen zu generieren, wenn wesentliche Änderungen vorgenommen werden, sodass Google die aktualisierte Version der Ressource zum Rendern herunterladen muss.
Möglicherweise sehen Sie nicht, was dem Googlebot angezeigt wird
Möglicherweise müssen Sie Ihren Benutzeragenten ändern, um einige Probleme richtig diagnostizieren zu können. Inhalte können für verschiedene Benutzeragenten oder sogar IPs unterschiedlich gerendert werden. Sie sollten überprüfen, was Google mit seinen Testtools tatsächlich sieht, und darauf werde ich gleich eingehen.
Sie können mit Chrome DevTools einen benutzerdefinierten Benutzeragenten einrichten, um Fehler bei Websites zu beheben, die auf der Grundlage bestimmter Benutzeragenten vorab gerendert werden, oder Sie können dies ganz einfach mit tun unsere Symbolleiste auch.
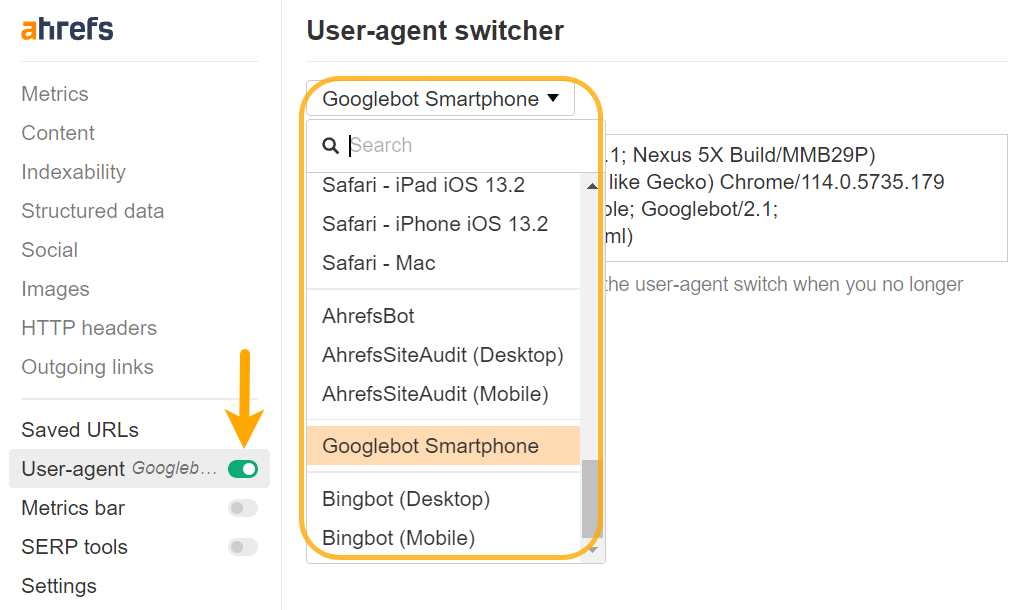
Verwenden Sie Polyfills für nicht unterstützte Features
Möglicherweise werden von Entwicklern Funktionen verwendet, die der Googlebot nicht unterstützt. Ihre Entwickler können es verwenden Funktionserkennung. Und wenn eine Funktion fehlt, können sie diese Funktionalität entweder überspringen oder eine Fallback-Methode mit einer verwenden Polyfüllung um zu sehen, ob sie es zum Laufen bringen können.
Dies ist hauptsächlich eine Informationsquelle für SEOs. Wenn Sie etwas sehen, von dem Sie denken, dass Google es sehen sollte, es aber nicht sieht, könnte das an der Implementierung liegen.
Verwenden Sie Lazy Loading
Seit ich dies ursprünglich geschrieben habe, hat sich Lazy Loading größtenteils von JavaScript-gesteuert zu einer Verarbeitung durch Browser entwickelt.
Möglicherweise stoßen Sie immer noch auf einige JavaScript-gesteuerte Lazy-Load-Setups. Meistens sind sie wahrscheinlich in Ordnung, wenn das verzögerte Laden für Bilder gilt. Ich würde vor allem prüfen, ob Inhalte verzögert geladen werden. Sehen Sie sich oben den Abschnitt „Überprüfen Sie, ob Google Ihre Inhalte sieht“ an. Solche Setups haben zu Problemen bei der korrekten Erfassung der Inhalte geführt.
Unendliche Scroll-Probleme
Wenn Sie ein Infinite-Scroll-Setup haben, empfehle ich dennoch eine paginierte Seitenversion, damit Google weiterhin ordnungsgemäß crawlen kann.
Ein weiteres Problem, das mir bei diesem Setup aufgefallen ist, besteht darin, dass gelegentlich zwei Seiten als eine indiziert werden. Ich habe das ein paar Mal gesehen, als Leute sagten, sie könnten ihre Seite nicht indizieren lassen. Aber ich habe festgestellt, dass ihr Inhalt als Teil einer anderen Seite indiziert ist, bei der es sich normalerweise um den vorherigen Beitrag von ihnen handelt.
Meine Theorie ist, dass Google, als Google die Größe des Ansichtsfensters änderte, um es länger zu machen (dazu später mehr), das unendliche Scrollen auslöste und beim Rendern einen weiteren Artikel lud. In diesem Fall empfehle ich, die JavaScript-Datei zu blockieren, die das unendliche Scrollen verarbeitet, damit die Funktionalität nicht ausgelöst werden kann.
Performance-Probleme
Viele JavaScript-Frameworks übernehmen eine Menge moderner Leistungsoptimierung für Sie.
Alle traditionellen Best Practices für die Leistung gelten weiterhin, aber Sie erhalten einige ausgefallene neue Optionen. Durch die Codeaufteilung werden die Dateien in kleinere Dateien aufgeteilt. Durch das Baumschütteln werden benötigte Teile herausgebrochen, sodass Sie nicht alles für jede Seite laden, wie Sie es bei herkömmlichen monolithischen Setups sehen würden.
Gut gemachte JavaScript-Setups sind etwas Schönes. Nicht gut durchgeführte JavaScript-Setups können überladen sein und lange Ladezeiten verursachen.
Verpasse nicht unseren Leitfaden zu Core Web Vitals Weitere Informationen zur Website-Leistung finden Sie hier.
JavaScript-Sites verbrauchen mehr Crawling-Budget
JavaScript-XHR-Anfragen fressen Budget crawlen, und ich meine, sie verschlingen es. Im Gegensatz zu den meisten anderen zwischengespeicherten Ressourcen werden diese während des Rendervorgangs live abgerufen.
Ein weiteres interessantes Detail ist, dass der Rendering-Dienst versucht, keine Ressourcen abzurufen, die nicht zum Inhalt der Seite beitragen. Wenn dies falsch ist, fehlen Ihnen möglicherweise einige Inhalte.
Arbeitnehmer werden nicht unterstützt, oder doch?
Während Google traditionell sagt, dass es Service-Worker ablehnt und Service-Worker das DOM nicht bearbeiten können, deutete Google-Mitarbeiter Martin Splitt an, dass man mit der Verwendung von Web-Workern manchmal durchkommt.
Verwenden Sie HTTP-Verbindungen
Googlebot unterstützt HTTP-Anfragen, unterstützt jedoch keine anderen Verbindungstypen wie WebSockets or WebRTC. Wenn Sie diese verwenden, stellen Sie einen Fallback bereit, der HTTP-Verbindungen verwendet.
Ein Problem bei JavaScript-Sites besteht darin, dass sie Teilaktualisierungen des DOM durchführen können. Beim Navigieren zu einer anderen Seite als Benutzer werden möglicherweise einige Aspekte wie Titel-Tags oder kanonische Tags im DOM nicht aktualisiert, für Suchmaschinen stellt dies jedoch möglicherweise kein Problem dar.
Google lädt jede Seite zustandslos, als wäre sie neu geladen. Bisherige Informationen werden nicht gespeichert und es wird nicht zwischen den Seiten navigiert.
Ich habe gesehen, dass SEOs ins Stolpern geraten sind und denken, es gäbe ein Problem aufgrund dessen, was sie sehen, nachdem sie von einer Seite zur anderen navigiert haben, etwa ein kanonisches Tag, das nicht aktualisiert wird. Aber Google wird diesen Zustand möglicherweise nie sehen.
Entwickler können dies beheben, indem sie den Status mit dem sogenannten aktualisieren Verlaufs-API. Aber auch hier ist es möglicherweise kein Problem. Oft sind es nur SEOs, die den Entwicklern Ärger bereiten, weil es für sie komisch aussieht. Aktualisieren Sie die Seite und sehen Sie, was Sie sehen. Oder noch besser: Führen Sie eines der Testtools von Google durch, um zu sehen, was es sieht.
Apropos Testtools: Lassen Sie uns darüber reden.
Google-Testtools
Google verfügt über mehrere Testtools, die für JavaScript nützlich sind.
URL-Inspektionstool in der Google Search Console
Dies sollte Ihre Quelle der Wahrheit sein. Wenn Sie eine URL überprüfen, erhalten Sie viele Informationen darüber, was Google gesehen hat, und über den tatsächlich von seinem System gerenderten HTML-Code.
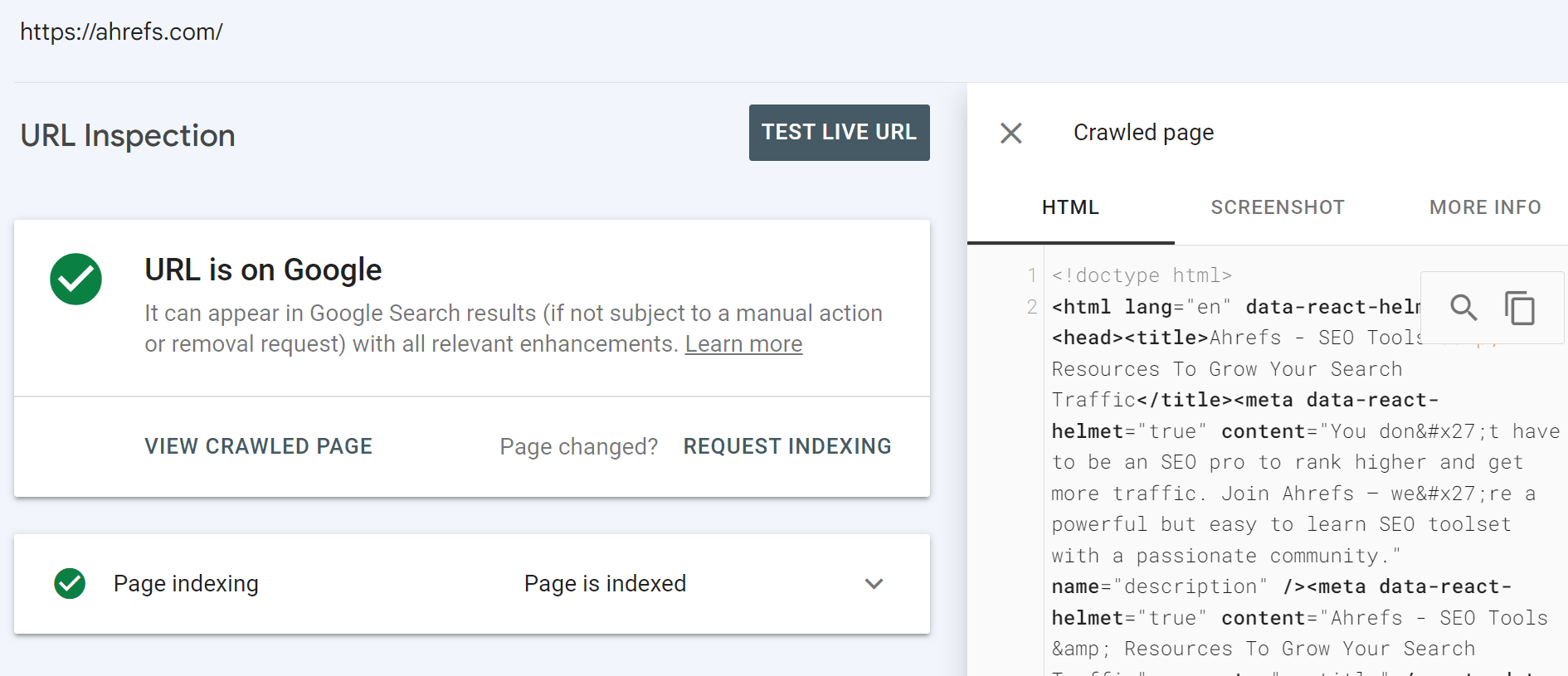
Sie haben auch die Möglichkeit, einen Live-Test durchzuführen.

Es gibt einige Unterschiede zwischen dem Hauptrenderer und dem Live-Test. Der Renderer verwendet zwischengespeicherte Ressourcen und ist ziemlich geduldig. Der Live-Test und andere Testtools nutzen Live-Ressourcen und unterbrechen das Rendern frühzeitig, da Sie auf ein Ergebnis warten. Ich werde später im Abschnitt „Rendering“ näher darauf eingehen.
Die Screenshots in diesen Tools zeigen auch Seiten mit bemalten Pixeln, was Google beim Rendern einer Seite eigentlich nicht tut.
Die Tools sind nützlich, um festzustellen, ob Inhalte DOM-geladen sind. Der in diesen Tools angezeigte HTML-Code ist das gerenderte DOM. Sie können nach einem Textausschnitt suchen, um zu sehen, ob er standardmäßig geladen wurde.
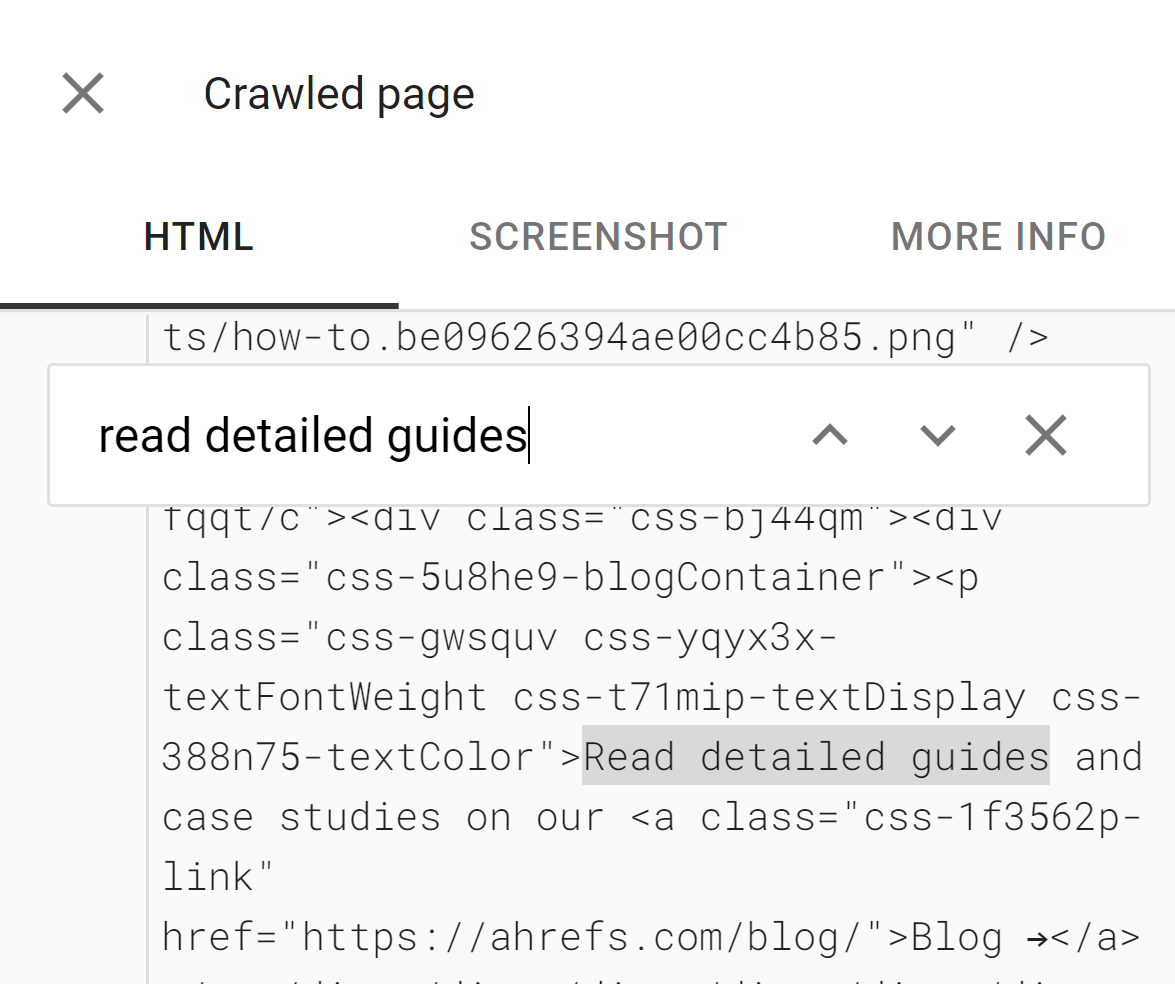
Die Tools zeigen Ihnen außerdem möglicherweise blockierte Ressourcen und Konsolenfehlermeldungen an, die beim Debuggen nützlich sind.
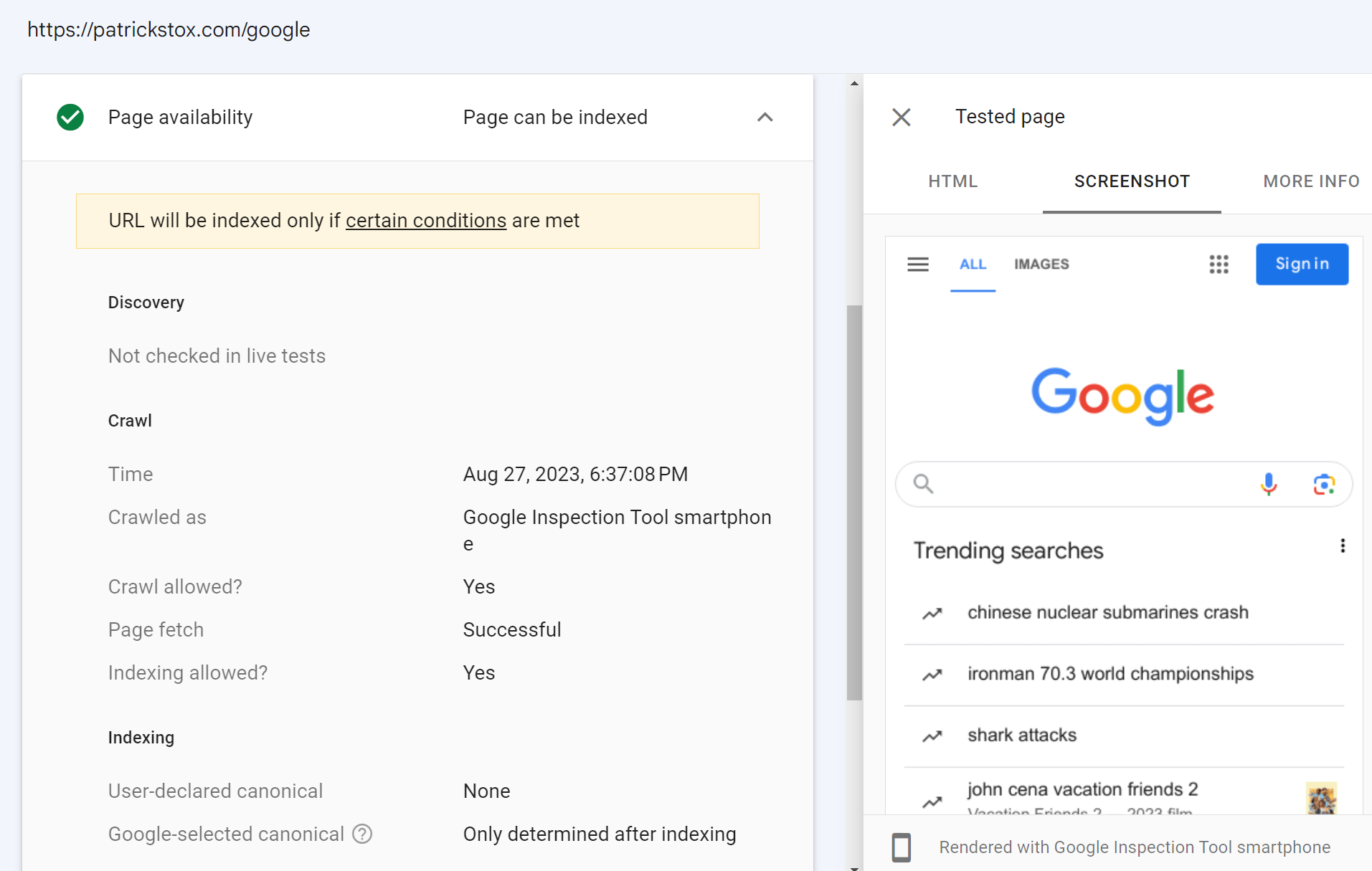
Wenn Sie keinen Zugriff auf die Google Search Console-Property für eine Website haben, können Sie trotzdem einen Live-Test darauf durchführen. Wenn Sie auf Ihrer eigenen Website eine Weiterleitung auf einer Property hinzufügen, auf die Sie Zugriff auf die Google Search Console haben, können Sie diese URL überprüfen. Das Inspektionstool folgt dann der Weiterleitung und zeigt Ihnen das Live-Testergebnis für die Seite auf der anderen Domain an.
Im Screenshot unten habe ich eine Weiterleitung von meiner Website zur Google-Startseite hinzugefügt. Der Live-Test hierfür folgt der Weiterleitung und zeigt mir die Startseite von Google. Ich habe eigentlich keinen Zugriff auf das Google Search Console-Konto von Google, obwohl ich es gerne hätte.
Testtool für Rich-Suchergebnisse
Das Testtool für Rich-Suchergebnisse ermöglicht es Ihnen, Ihre gerenderte Seite so zu überprüfen, wie der Googlebot sie auf Mobilgeräten oder Desktops sehen würde.
Mobilfreundliches Testtool
Sie können die . weiterhin verwenden Mobile-Friendly-Test-Tool vorerst, aber Google hat angekündigt, dass es im Dezember 2023 abgeschaltet wird.
Es hat die gleichen Macken wie die anderen Testtools von Google.
Ahrefs
Ahrefs ist das einzige große SEO-Tool, das Rendert Webseiten beim Crawlen des WebsDaher verfügen wir über Daten von JavaScript-Websites, die kein anderes Tool liefert. Wir rendern etwa 200 Millionen Seiten pro Tag, aber das ist nur ein Bruchteil dessen, was wir crawlen.
Es ermöglicht uns, nach JavaScript-Weiterleitungen zu suchen. Wir können auch mit JavaScript eingefügte Links anzeigen, die wir mit einem JS-Tag in den Linkberichten anzeigen:

Im Dropdown-Menü für Seiten in Site Explorer, wir haben auch eine Inspektionsoption, mit der Sie den Verlauf einer Seite sehen und ihn mit anderen Crawls vergleichen können. Wir haben dort eine JS-Markierung für Seiten, die mit aktiviertem JavaScript gerendert wurden.

Sie können JavaScript in aktivieren Standortüberwachung Crawlt, um mehr Daten in Ihren Audits freizuschalten.
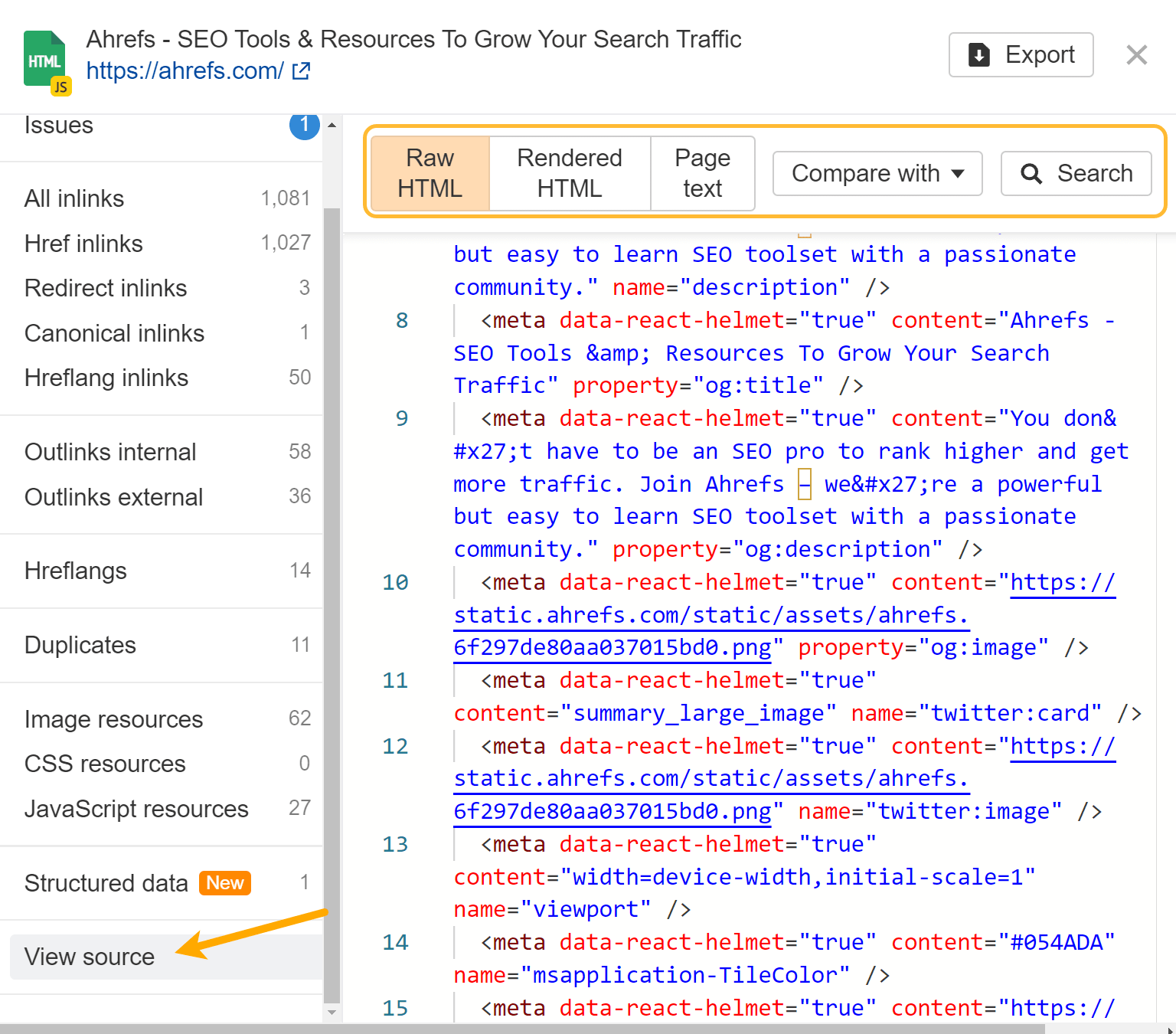
Wenn Sie JavaScript-Rendering aktiviert haben, stellen wir den rohen und gerenderten HTML-Code für jede Seite bereit. Verwenden Sie die Option „Lupe“ neben einer Seite im Seiten-Explorer und gehen Sie im Menü auf „Quelle anzeigen“. Sie können auch mit früheren Crawls vergleichen und im rohen oder gerenderten HTML auf allen Seiten der Website suchen.
Wenn Sie einen Crawl ohne JavaScript und anschließend einen weiteren mit JavaScript durchführen, können Sie unsere Crawl-Vergleichsfunktionen nutzen, um Unterschiede zwischen den Versionen zu erkennen.
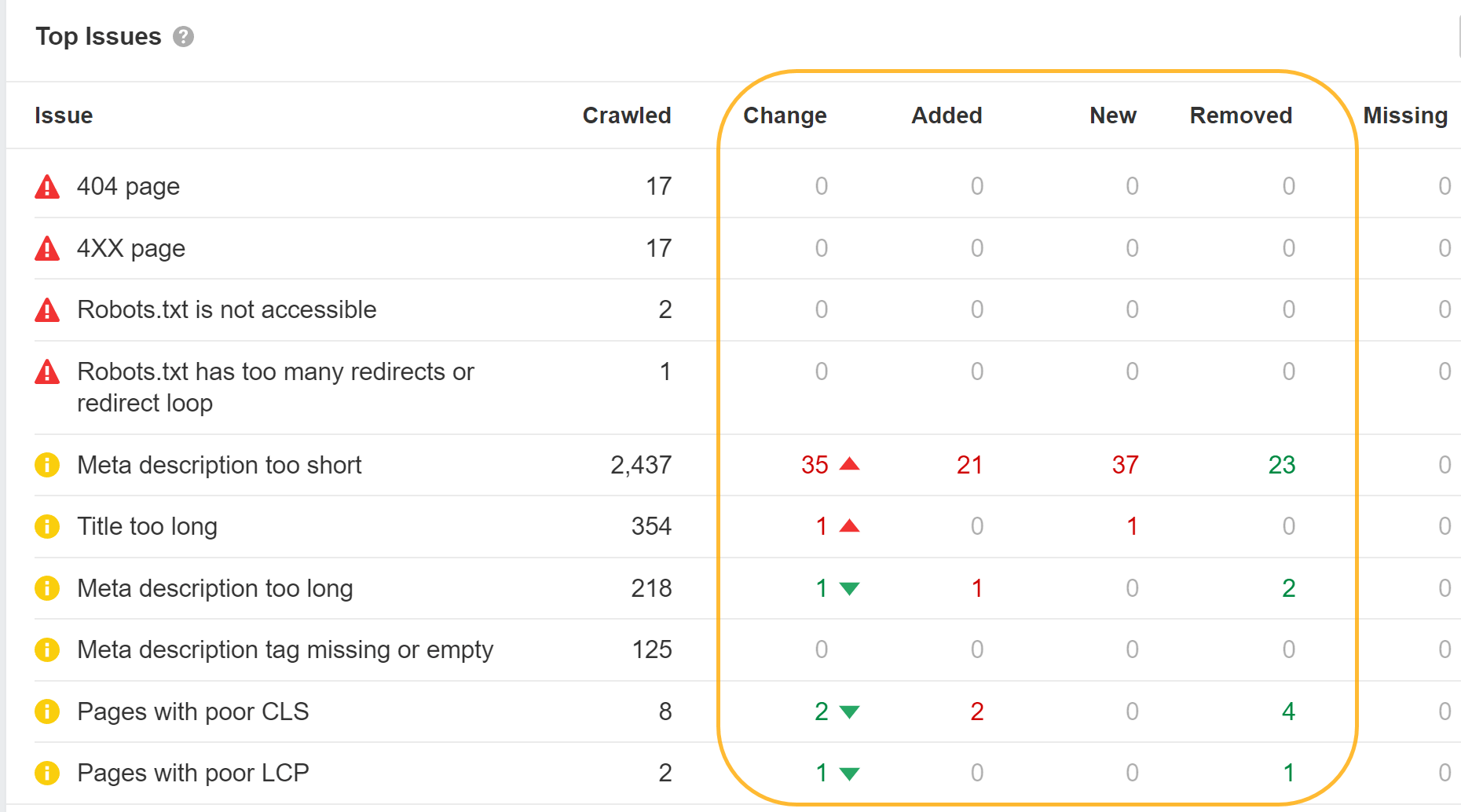
Ahrefs SEO-Toolbar unterstützt auch JavaScript und ermöglicht Ihnen den Vergleich von HTML mit gerenderten Versionen von Tags.
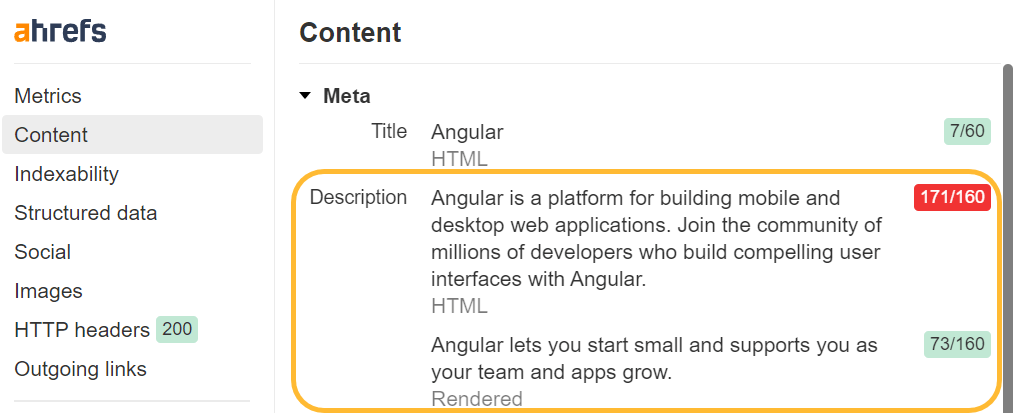
Quelle anzeigen vs. prüfen
Wenn Sie mit der rechten Maustaste in ein Browserfenster klicken, werden einige Optionen zum Anzeigen des Quellcodes der Seite und zum Überprüfen der Seite angezeigt. Die Ansichtsquelle zeigt Ihnen dasselbe wie eine GET-Anfrage. Dies ist der Roh-HTML-Code der Seite.

Inspect zeigt Ihnen das verarbeitete DOM an, nachdem Änderungen vorgenommen wurden, und ist näher am Inhalt, den Googlebot sieht. Dies ist die Seite, nachdem JavaScript ausgeführt und Änderungen daran vorgenommen wurde.
Wenn Sie mit JavaScript arbeiten, sollten Sie hauptsächlich „Inspect“ anstelle der „View Source“-Funktion verwenden.
Manchmal müssen Sie die Ansichtsquelle überprüfen
Da Google bei manchen Problemen sowohl rohes als auch gerendertes HTML untersucht, müssen Sie möglicherweise trotzdem gelegentlich die Quellquelle überprüfen. Wenn Ihnen die Tools von Google beispielsweise mitteilen, dass die Seite als „noindex“ gekennzeichnet ist, Sie aber im gerenderten HTML-Code kein „noindex“-Tag sehen, war es möglicherweise im Roh-HTML vorhanden und wurde überschrieben.
Für Dinge wie Noindex, Nofollow und Canonical-Tags müssen Sie möglicherweise den Roh-HTML überprüfen, da sich Probleme übertragen können. Denken Sie daran, dass Google die restriktivsten Anweisungen, die es für die Meta-Robots-Tags gesehen hat, annimmt und kanonische Tags ignoriert, wenn Sie ihm mehrere kanonische Tags anzeigen.
Surfen Sie nicht, wenn JavaScript deaktiviert ist
Ich habe diese Empfehlung viel zu oft gesehen. Google rendert JavaScript, sodass das, was Sie ohne JavaScript sehen, überhaupt nicht mit dem übereinstimmt, was Google sieht. Das ist einfach albern.
Verwenden Sie nicht Google Cache
Der Cache von Google ist keine zuverlässige Methode, um zu überprüfen, was der Googlebot sieht. Was Sie normalerweise im Cache sehen, ist der rohe HTML-Snapshot. Ihr Browser löst dann das JavaScript aus, auf das im HTML verwiesen wird. Es ist nicht das, was Google beim Rendern der Seite gesehen hat.
Um dies noch weiter zu verkomplizieren, können Websites ihre eigenen haben Cross-Origin-Ressourcenfreigabe (CORS) Richtlinie so eingerichtet, dass die erforderlichen Ressourcen nicht von einer anderen Domäne geladen werden können.
Der Cache wird auf webcache.googleusercontent.com gehostet. Wenn diese Domäne versucht, die Ressourcen von der tatsächlichen Domäne anzufordern, sagt die CORS-Richtlinie: „Nein, Sie können nicht auf meine Dateien zugreifen.“ Dann werden die Dateien nicht geladen und die Seite sieht im Cache kaputt aus.
Das Cache-System wurde entwickelt, um den Inhalt anzuzeigen, wenn eine Website nicht verfügbar ist. Als Debug-Tool ist es nicht besonders nützlich.
In den Anfängen der Suchmaschinen reichte eine heruntergeladene HTML-Antwort aus, um den Inhalt der meisten Seiten zu sehen. Dank des Aufstiegs von JavaScript müssen Suchmaschinen heute viele Seiten wie ein Browser rendern, damit sie Inhalte so sehen können, wie ein Benutzer sie sieht.
Das System, das den Rendering-Prozess bei Google abwickelt, heißt Web Rendering Service (WRS). Google hat ein vereinfachtes Diagramm bereitgestellt, um die Funktionsweise dieses Prozesses zu veranschaulichen.
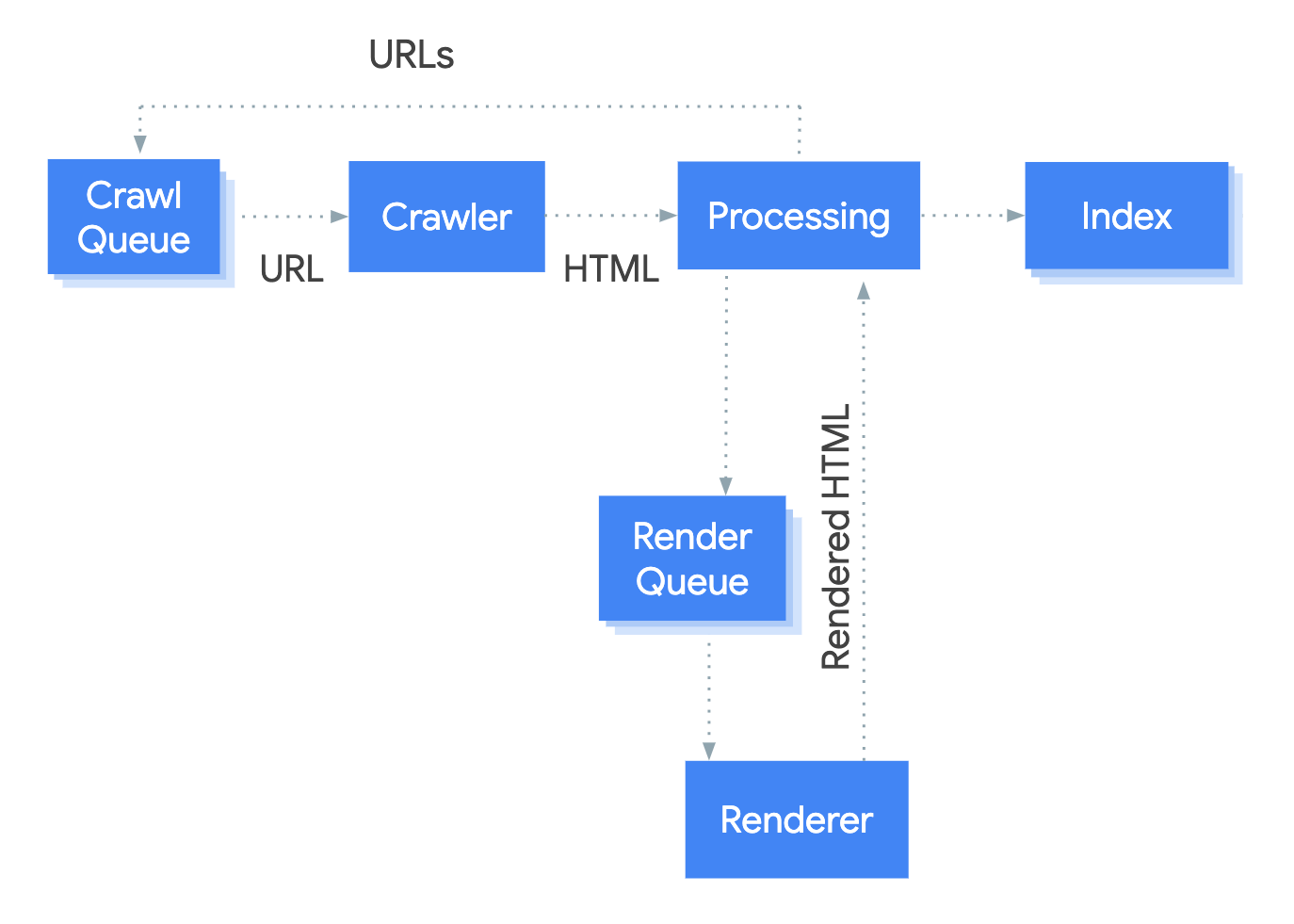
Nehmen wir an, wir starten den Prozess unter der URL.
1. Raupe
Der Crawler sendet GET-Anfragen an den Server. Der Server antwortet mit Headern und dem Inhalt der Datei, die dann gespeichert wird. Die Header und der Inhalt kommen normalerweise in derselben Anfrage.
Die Anfrage kommt wahrscheinlich von einem mobilen User-Agent, da Google ison Mobile-erste Indexierung jetzt, aber es crawlt auch weiterhin mit dem Desktop-Benutzeragenten.
Die Anfragen kommen hauptsächlich aus Mountain View (CA, USA), aber das kommt auch etwas Crawling für gebietsschemaadaptive Seiten außerhalb der USA Wie ich bereits erwähnt habe, kann dies zu Problemen führen, wenn Websites Besucher in einem bestimmten Land blockieren oder unterschiedlich behandeln.
Es ist auch wichtig zu beachten, dass Google im obigen Bild zwar die Ausgabe des Crawling-Prozesses als „HTML“ angibt, in Wirklichkeit aber die zum Erstellen der Seite erforderlichen Ressourcen wie HTML-, JavaScript- und CSS-Dateien crawlt und speichert. Es gibt außerdem eine maximale Größenbeschränkung von 15 MB für HTML-Dateien.
2. wird bearbeitet
Es gibt viele Systeme, die durch den Begriff „Verarbeitung“ im Bild verschleiert werden. Ich werde einige davon behandeln, die für JavaScript relevant sind.
Ressourcen und Links
Google navigiert nicht wie ein Nutzer von Seite zu Seite. Ein Teil der „Verarbeitung“ besteht darin, die Seite auf Links zu anderen Seiten und Dateien zu überprüfen, die zum Erstellen der Seite erforderlich sind. Diese Links werden herausgezogen und der Crawling-Warteschlange hinzugefügt, die Google zum Priorisieren und Planen des Crawlings verwendet.

Google ruft Ressourcenlinks (CSS, JS usw.) ab, die zum Erstellen einer Seite aus Dingen wie erforderlich sind <link> Stichworte.
Wie ich schon erwähnt habe, interne Links Mit JavaScript hinzugefügte Elemente werden erst nach dem Rendern übernommen. Das sollte relativ schnell gehen und in den meisten Fällen kein Grund zur Sorge sein. Dinge wie Nachrichtenseiten können die Ausnahme sein, wo jede Sekunde zählt.
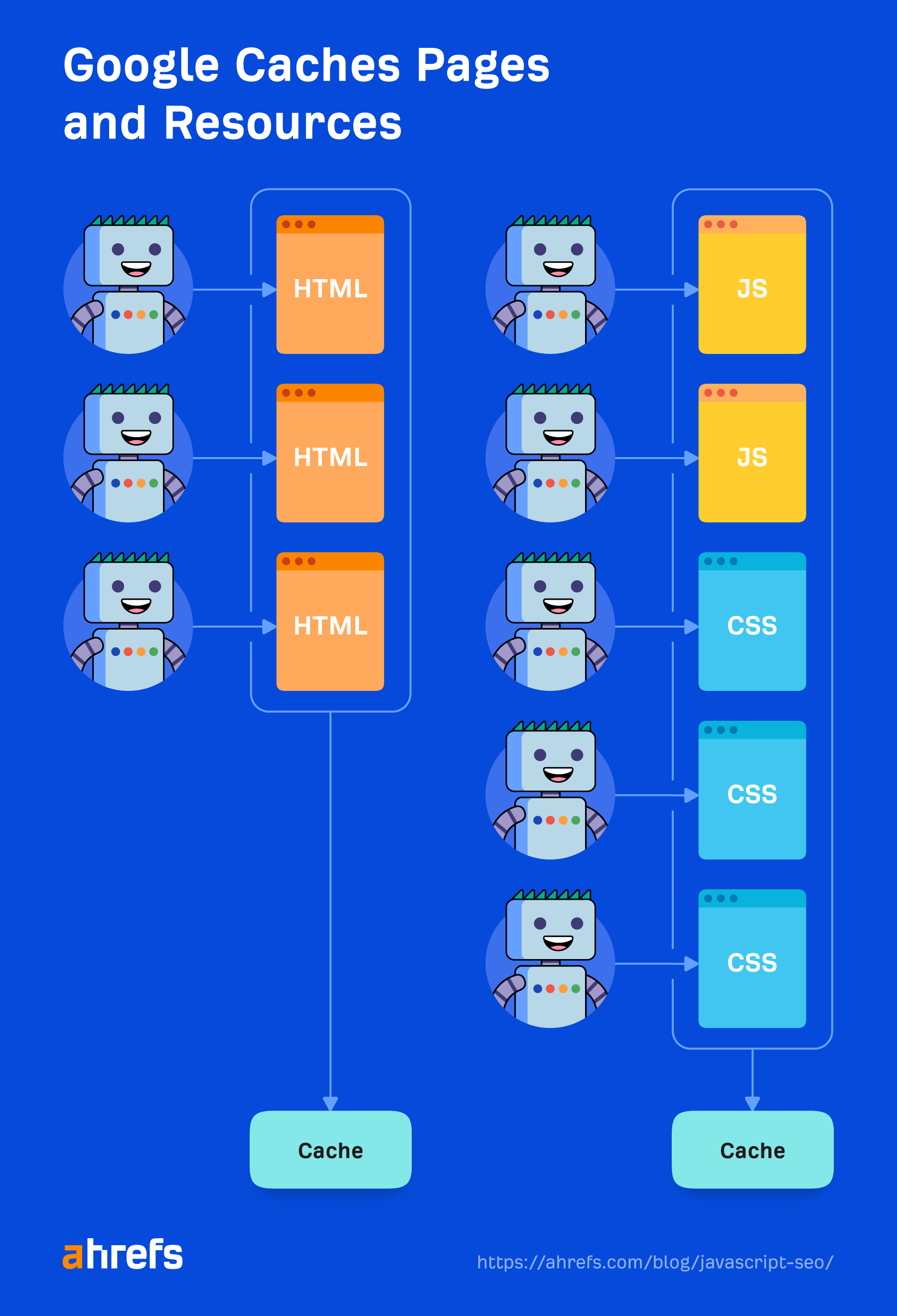
Caching
Jede Datei, die Google herunterlädt, einschließlich HTML-Seiten, JavaScript-Dateien, CSS-Dateien usw., wird aggressiv zwischengespeichert. Google ignoriert Ihre Cache-Timings und ruft bei Bedarf eine neue Kopie ab. Ich werde im Abschnitt „Renderer“ etwas mehr darüber sprechen und warum es wichtig ist.
Eliminierung von Duplikaten
Doppelte Inhalte können aus dem heruntergeladenen HTML-Code entfernt oder herabgestuft werden, bevor er an das Rendering gesendet wird. Darüber habe ich bereits oben im Abschnitt „Doppelter Inhalt“ gesprochen.
Die restriktivsten Richtlinien
Wie ich bereits erwähnt habe, wird Google die restriktivste Variante wählen Aussagen zwischen HTML und der gerenderten Version einer Seite. Wenn JavaScript eine Anweisung ändert und dies mit der Anweisung aus HTML in Konflikt steht, befolgt Google einfach die restriktivste Anweisung. Noindex überschreibt den Index und noindex in HTML überspringt das Rendern insgesamt.
3. Render-Warteschlange
Eine der größten Bedenken vieler SEOs mit JavaScript und zweistufiger Indexierung (HTML, dann gerenderte Seite) ist, dass Seiten möglicherweise tagelang oder sogar wochenlang nicht gerendert werden. Als Google dies untersuchte, wurde es gefunden Seiten gingen im Durchschnitt nach fünf Sekunden an den Rendererund das 90. Perzentil betrug Minuten. Daher sollte die Zeitspanne zwischen dem Erhalten des HTML-Codes und dem Rendern der Seiten in den meisten Fällen kein Problem darstellen.
Allerdings rendert Google nicht alle Seiten. Wie ich bereits erwähnt habe, wird eine Seite mit einem Robots-Meta-Tag oder einem Header, der ein Noindex-Tag enthält, nicht an den Renderer gesendet. Es verschwendet keine Ressourcen beim Rendern einer Seite, die ohnehin nicht indiziert werden kann.
Dabei werden auch Qualitätskontrollen durchgeführt. Wenn es sich den HTML-Code ansieht oder anhand anderer Signale oder Muster vernünftigerweise feststellen kann, dass die Qualität einer Seite für die Indexierung nicht ausreicht, macht es sich nicht die Mühe, dies an den Renderer zu senden.
Es gibt auch eine Besonderheit bei Nachrichtenseiten. Google möchte Seiten auf Nachrichtenseiten schnell indizieren, damit es die Seiten zuerst basierend auf dem HTML-Inhalt indizieren kann – und später zurückkehren kann, um diese Seiten zu rendern.
4. Renderer
Im Renderer rendert Google eine Seite, um zu sehen, was ein Nutzer sieht. Hier werden das JavaScript und alle von JavaScript vorgenommenen Änderungen verarbeitet DOM.
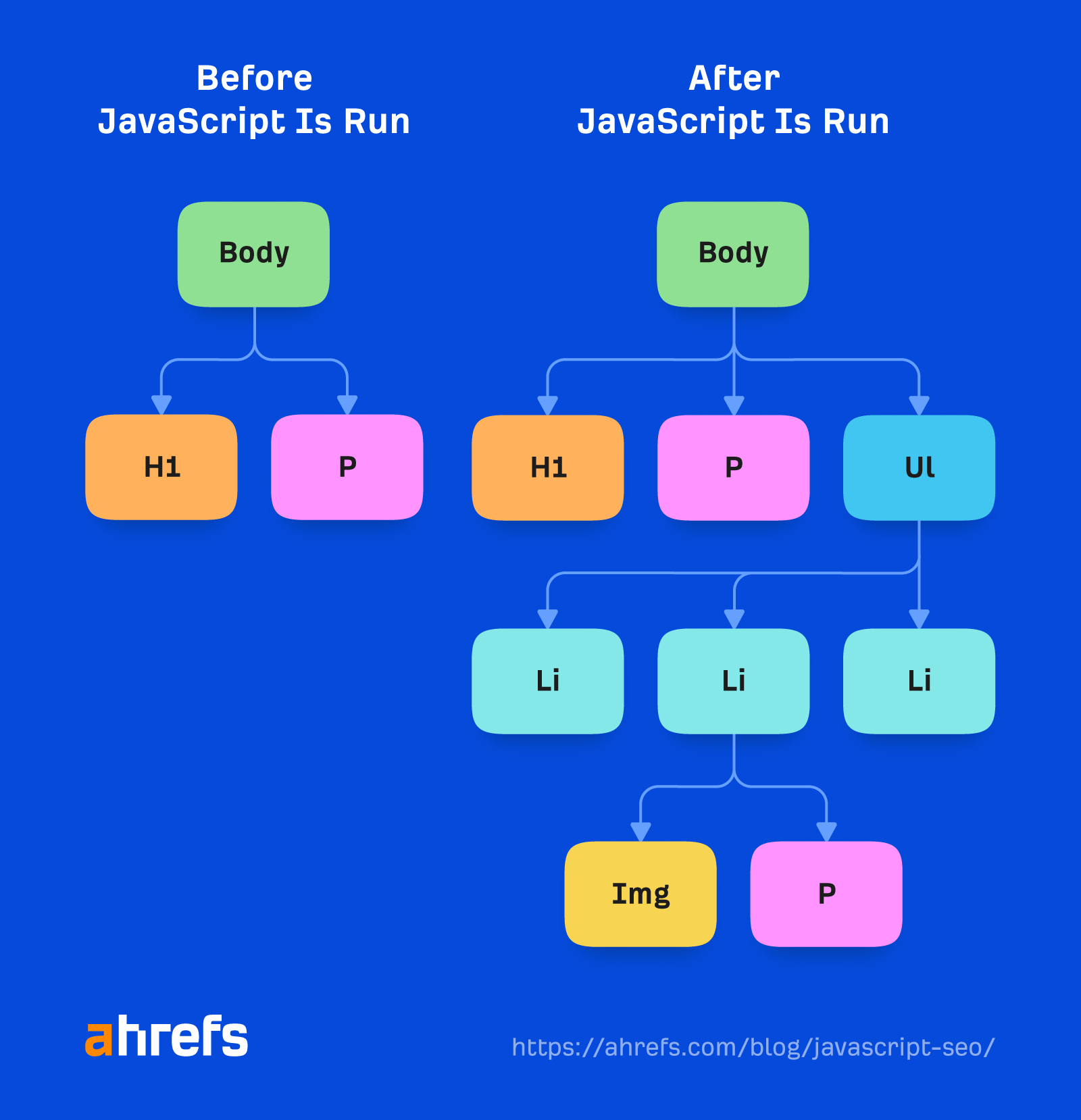
Dafür nutzt Google einen Headless-Chrome-Browser, der mittlerweile „Evergreen“ ist, das heißt, er sollte die neueste Chrome-Version verwenden und die neuesten Funktionen unterstützen. Vor Jahren hat Google mit Chrome 41 gerendert und viele Funktionen wurden damals nicht unterstützt.
Google hat mehr Infos zum WRS, zu dem Dinge wie das Verweigern von Berechtigungen, Zustandslosigkeit, das Reduzieren von Light-DOM und Shadow-DOM und mehr gehören, die es wert sind, gelesen zu werden.
Das Rendern im Webmaßstab könnte das achte Weltwunder sein. Es ist ein ernstes Unterfangen und erfordert enorme Ressourcen. Aufgrund der Größe geht Google beim Rendering-Prozess viele Abkürzungen, um die Dinge zu beschleunigen.
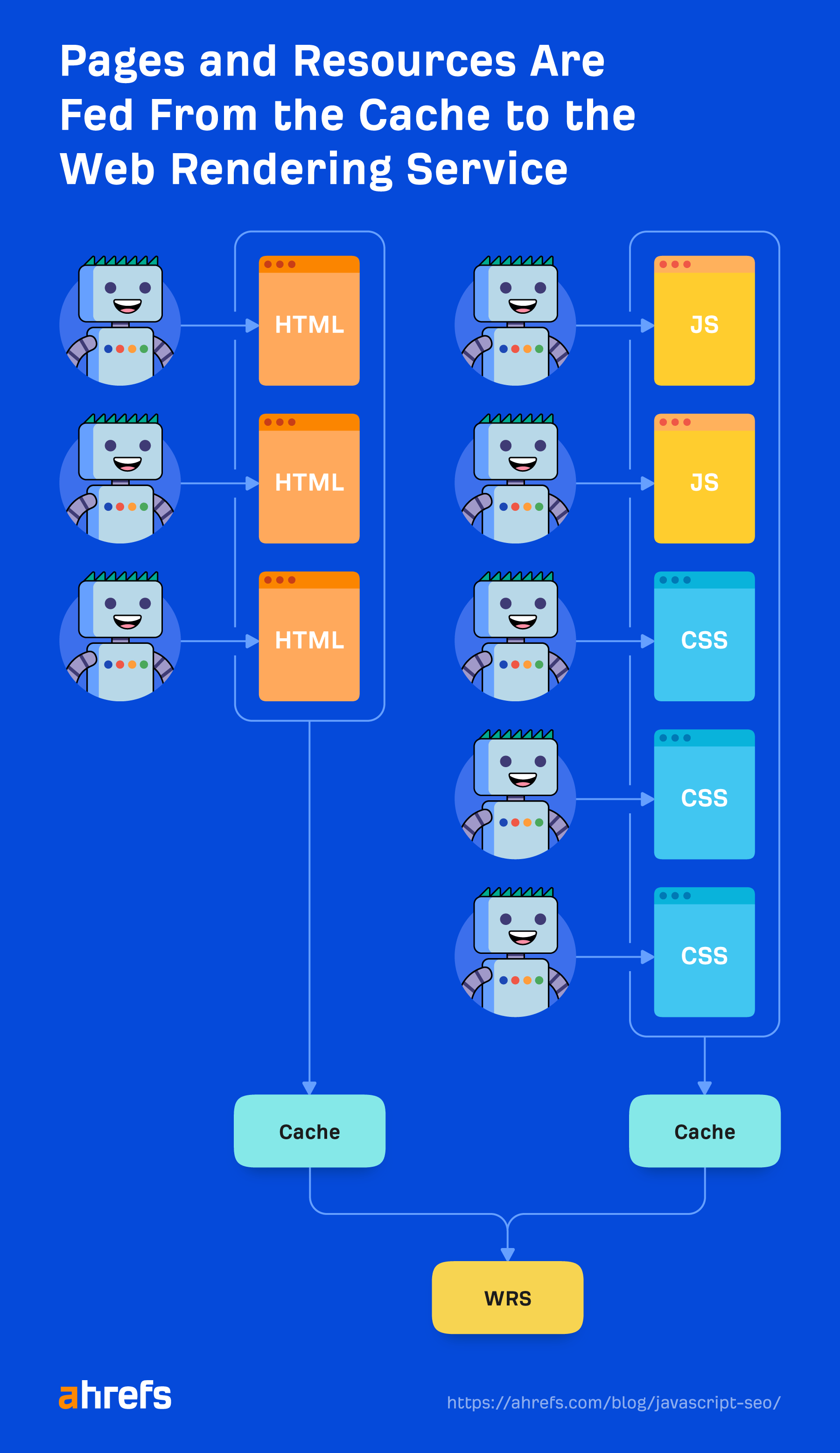
Zwischengespeicherte Ressourcen
Google verlässt sich stark auf Caching-Ressourcen. Seiten werden zwischengespeichert. Dateien werden zwischengespeichert. Fast alles wird zwischengespeichert, bevor es an den Renderer gesendet wird. Es geht nicht darum, bei jedem Seitenaufruf jede Ressource herunterzuladen, denn das wäre sowohl für das Unternehmen als auch für die Websitebesitzer teuer. Stattdessen werden diese zwischengespeicherten Ressourcen genutzt, um die Effizienz zu steigern.
Eine Ausnahme bilden XHR-Anfragen, die der Renderer in Echtzeit ausführt.
Es gibt kein Timeout von fünf Sekunden
Ein verbreiteter SEO-Mythos besagt, dass Google nur fünf Sekunden wartet, um Ihre Seite zu laden. Obwohl es immer eine gute Idee ist, Ihre Website schneller zu machen, ergibt dieser Mythos angesichts der oben erwähnten Art und Weise, wie Google Dateien zwischenspeichert, keinen Sinn. Es lädt bereits eine Seite mit allem, was in seinen Systemen zwischengespeichert ist, und fordert keine neuen Ressourcen an.
Wenn es nur fünf Sekunden warten würde, würde es viele Inhalte verpassen.
Der Mythos stammt wahrscheinlich von Testtools wie dem URL-Inspektionstool, bei denen Ressourcen live abgerufen und nicht zwischengespeichert werden und den Benutzern innerhalb einer angemessenen Zeitspanne ein Ergebnis zurückgeben müssen. Es könnte auch daran liegen, dass Seiten keine Priorität für das Crawlen haben, was den Eindruck erweckt, dass die Leute lange auf das Rendern und Indexieren warten müssen.
Für den Renderer gibt es kein festes Timeout. Es läuft mit einem beschleunigten Timer, um zu sehen, ob zu einem späteren Zeitpunkt etwas hinzugefügt wird. Außerdem wird die Ereignisschleife im Browser überprüft, um zu sehen, wann alle Aktionen ausgeführt wurden. Es ist wirklich geduldig und Sie sollten sich keine Sorgen um ein bestimmtes Zeitlimit machen.
Es ist geduldig, verfügt aber auch über Sicherheitsvorkehrungen für den Fall, dass etwas hängen bleibt oder jemand versucht, auf seinen Seiten Bitcoin zu schürfen. Ja, das ist eine Sache. Wir mussten auch Schutzmaßnahmen für das Bitcoin-Mining hinzufügen, und zwar sogar eine Studie veröffentlicht, darüber.
Was Googlebot sieht
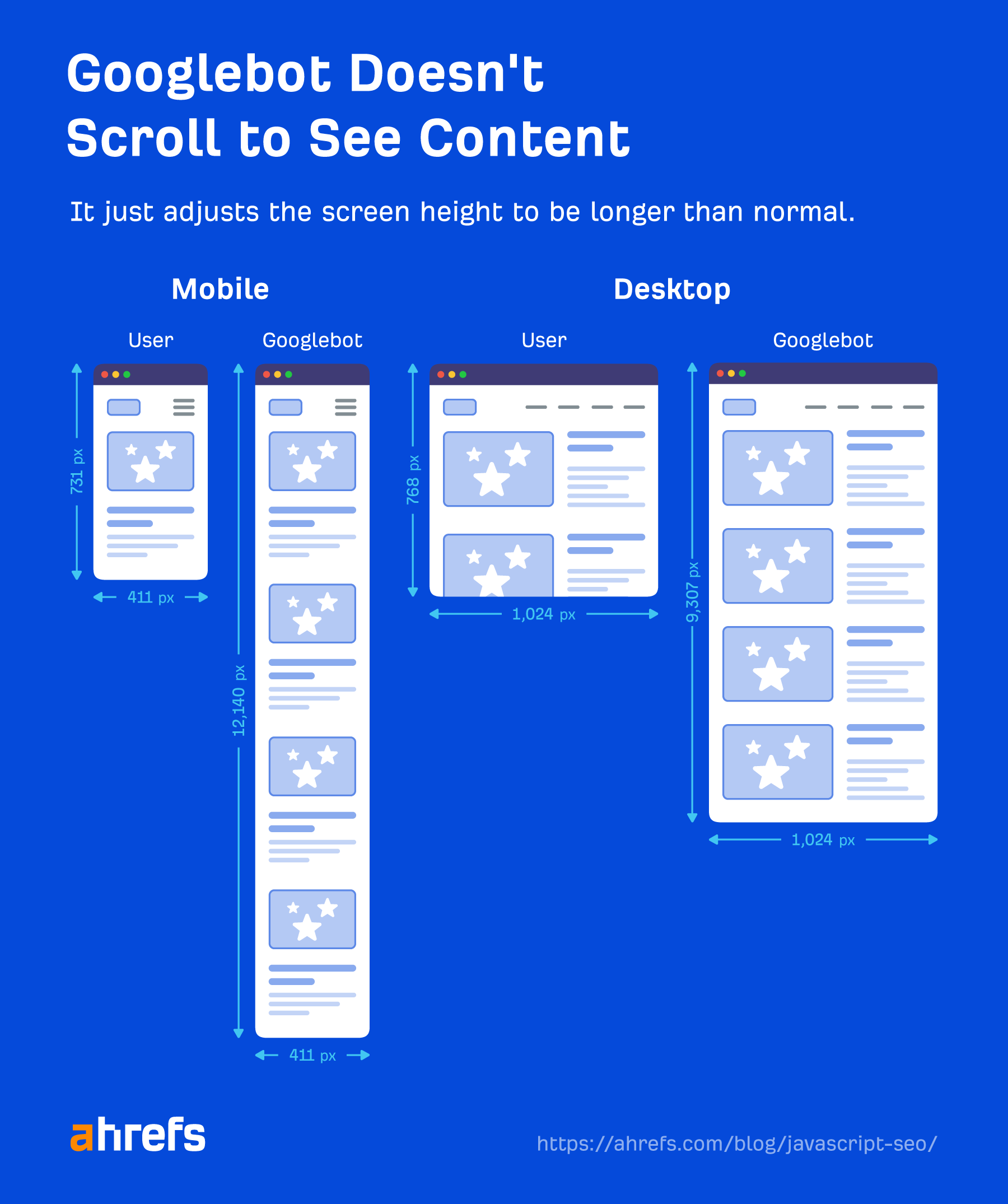
Der Googlebot ergreift keine Maßnahmen auf Webseiten. Es wird nicht auf Dinge geklickt oder gescrollt, aber das bedeutet nicht, dass es keine Problemumgehungen gibt. Solange Inhalte ohne eine erforderliche Aktion in das DOM geladen werden, wird Google sie sehen. Wenn es erst nach einem Klick in das DOM geladen wird, wird der Inhalt nicht gefunden.
Google muss auch nicht scrollen, um Ihre Inhalte anzuzeigen, da es eine clevere Problemumgehung bietet, um die Inhalte anzuzeigen. Für Mobilgeräte lädt es die Seite mit einer Bildschirmgröße von 411×731 Pixeln und Ändert die Länge auf 12,140 Pixel.
Im Wesentlichen wird es zu einem wirklich langen Telefon mit einer Bildschirmgröße von 411 x 12140 Pixeln. Für den Desktop gilt das Gleiche und die Auflösung steigt von 1024 x 768 Pixel auf 1024 x 9307 Pixel. Ich habe keine aktuellen Tests für diese Zahlen gesehen und sie können sich je nach Länge der Seiten ändern.
Eine weitere interessante Abkürzung besteht darin, dass Google die Pixel während des Rendervorgangs nicht malt. Es braucht Zeit und zusätzliche Ressourcen, um den Ladevorgang einer Seite abzuschließen, und es ist nicht unbedingt erforderlich, den Endzustand mit den gezeichneten Pixeln zu sehen. Außerdem sind Grafikkarten zwischen Gaming, Krypto-Mining und KI teuer.
Google muss lediglich die Struktur und das Layout kennen und erhält diese, ohne dass die Pixel tatsächlich gezeichnet werden müssen. Als Martin bringt es auf den Punkt:
Bei der Google-Suche sind uns die Pixel eigentlich egal, weil wir sie eigentlich niemandem zeigen wollen. Wir wollen die Informationen und die semantischen Informationen verarbeiten, also brauchen wir etwas im Zwischenzustand. Wir müssen die Pixel nicht wirklich malen.
Ein Bild kann helfen, etwas besser zu erklären, was ausgeschnitten ist. Wenn Sie in Chrome Dev Tools einen Test auf der Registerkarte „Leistung“ ausführen, erhalten Sie ein Ladediagramm. Der durchgezogene grüne Teil stellt hier die Malphase dar. Beim Googlebot passiert das nie, was Ressourcen spart.

Gray = Herunterladen
Blau = HTML
Gelb = JavaScript
Lila = Layout
Grün = Malerei
5. Crawl-Warteschlange
Google verfügt über eine Ressource, die sich ein wenig mit dem Crawling-Budget befasst. Sie sollten jedoch wissen, dass jede Website über ein eigenes Crawling-Budget verfügt und jede Anfrage priorisiert werden muss. Google muss auch das Crawling Ihrer Seiten im Vergleich zum Crawlen jeder anderen Seite im Internet ausbalancieren.
Neuere Websites im Allgemeinen oder Websites mit vielen dynamischen Seiten werden wahrscheinlich langsamer gecrawlt. Einige Seiten werden seltener aktualisiert als andere, und einige Ressourcen werden möglicherweise auch seltener angefordert.
Beim Rendern von JavaScript gibt es viele Möglichkeiten. Google hat ein solides Diagramm, das ich gerade zeigen werde. Für Suchmaschinen ist jede Art von SSR-, statischem Rendering- und Prerendering-Setup in Ordnung. Gatsby, Next, Nuxt usw. sind alle großartig.

Am problematischsten wird das vollständige clientseitige Rendering sein, bei dem das gesamte Rendering im Browser erfolgt. Während Google wahrscheinlich mit dem clientseitigen Rendering einverstanden sein wird, ist es am besten, eine andere Rendering-Option zu wählen, um andere zu unterstützen Suchmaschinen.
Bing hat es auch Unterstützung für JavaScript-Rendering, aber der Maßstab ist unbekannt. Yandex und Baidu werden, soweit ich gesehen habe, nur begrenzt unterstützt, und viele andere Suchmaschinen unterstützen JavaScript kaum oder gar nicht. Unsere eigene Suchmaschine, Ja, wird unterstützt und wir rendern etwa 200 Millionen Seiten pro Tag. Aber wir rendern nicht jede Seite, die wir crawlen.
Es gibt auch die Möglichkeit von dynamisches Rendern, das für bestimmte Benutzeragenten gerendert wird. Dies ist ein Workaround, und ehrlich gesagt habe ich es nie empfohlen und bin froh, dass Google jetzt auch davon abrät.
Gelegentlich möchten Sie es möglicherweise zum Rendern für bestimmte Bots wie Suchmaschinen oder sogar Social-Media-Bots verwenden. Social-Media-Bots führen kein JavaScript aus, also Dinge wie OG-Tags werden nicht gesehen, es sei denn, Sie rendern den Inhalt, bevor Sie ihn ihnen bereitstellen.
In der Praxis werden Setups dadurch komplexer und für SEOs schwieriger zu beheben. Es ist auf jeden Fall Cloaking, obwohl Google sagt, dass dies nicht der Fall ist und dass es damit einverstanden ist.
Note
Wenn Sie das alte verwendet haben AJAX-Crawling-Schema mit Hashbangs (#!), wissen Sie, dass dies veraltet ist und nicht mehr unterstützt wird.
Abschließende Gedanken
JavaScript ist für SEOs kein Grund zur Angst. Hoffentlich hat Ihnen dieser Artikel dabei geholfen, besser zu verstehen, wie Sie damit arbeiten können.
Scheuen Sie sich nicht, sich an Ihre Entwickler zu wenden, mit ihnen zusammenzuarbeiten und ihnen Fragen zu stellen. Sie werden Ihre größten Verbündeten sein, wenn es darum geht, Ihre JavaScript-Site für Suchmaschinen zu verbessern.
Habe Fragen? Lass es mich wissen auf Twitter.
Weiterführende Literatur
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://ahrefs.com/blog/javascript-seo/

