
„Eine Unze Vorbeugung ist mehr wert als ein Pfund Heilung“, sagt ein altes Sprichwort und erinnert uns daran, dass es einfacher ist, etwas von vornherein zu verhindern, als den Schaden zu reparieren, nachdem er eingetreten ist.
Im Zeitalter der künstlichen Intelligenz (KI) unterstreicht dieses Sprichwort, wie wichtig es ist, potenzielle Fallstricke wie Überanpassung durch Techniken wie Regularisierung zu vermeiden.
In diesem Artikel werden wir die Regularisierung entdecken, indem wir mit ihren Grundprinzipien beginnen, bis hin zu ihrer Anwendung mithilfe von Sci-kit Learn (maschinelles Lernen) und Tensorflow (Deep Learning) und ihre transformative Kraft anhand realer Datensätze durch den Vergleich dieser Ergebnisse erleben. Lasst uns beginnen!
Regularisierung ist ein entscheidendes Konzept beim maschinellen Lernen und Deep Learning, das darauf abzielt, eine Überanpassung von Modellen zu verhindern.
Überanpassung tritt auf, wenn ein Modell die Trainingsdaten zu gut lernt. Die Situation zeigt, dass Ihr Modell zu schön ist, um wahr zu sein.
Mal sehen, wie eine Überanpassung aussieht.
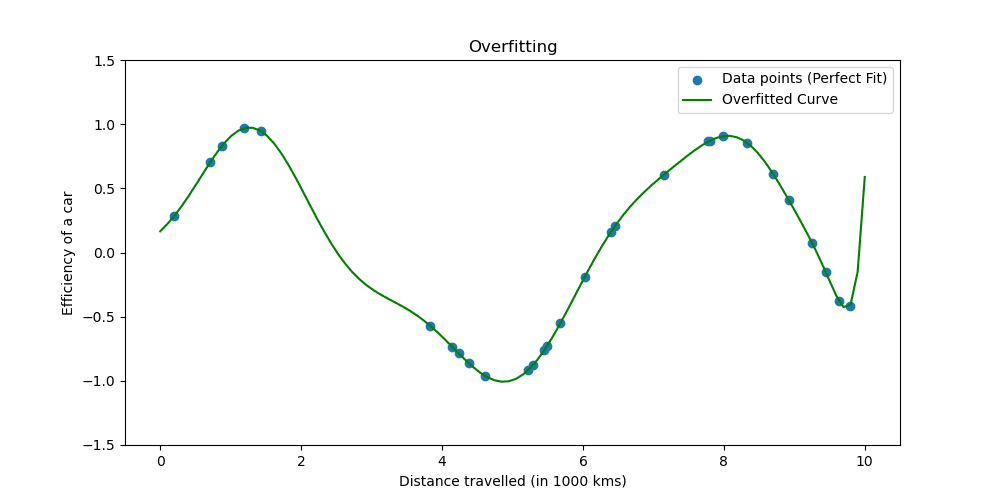
Regularisierungstechniken passen den Lernprozess an, um das Modell zu vereinfachen und sicherzustellen, dass es bei Trainingsdaten gut funktioniert und sich gut auf neue Daten verallgemeinern lässt. Wir werden zwei bekannte Möglichkeiten untersuchen, dies zu tun.
Beim maschinellen Lernen wird die Regularisierung häufig auf lineare Modelle angewendet, beispielsweise auf die lineare und logistische Regression. In diesem Zusammenhang sind die häufigsten Formen der Regularisierung:
- L1-Regularisierung (Lasso-Regression)
- L2-Regularisierung (Ridge-Regression)
Lasso-Regularisierung regt das Modell dazu an, nur die wesentlichsten Merkmale zu verwenden, indem es zulässt, dass einige Koeffizientenwerte genau Null sind, was besonders nützlich für die Merkmalsauswahl sein kann.


Auf der anderen Seite, Ridge Regularisierung entmutigt signifikante Koeffizienten, indem das Quadrat ihrer Werte bestraft wird.

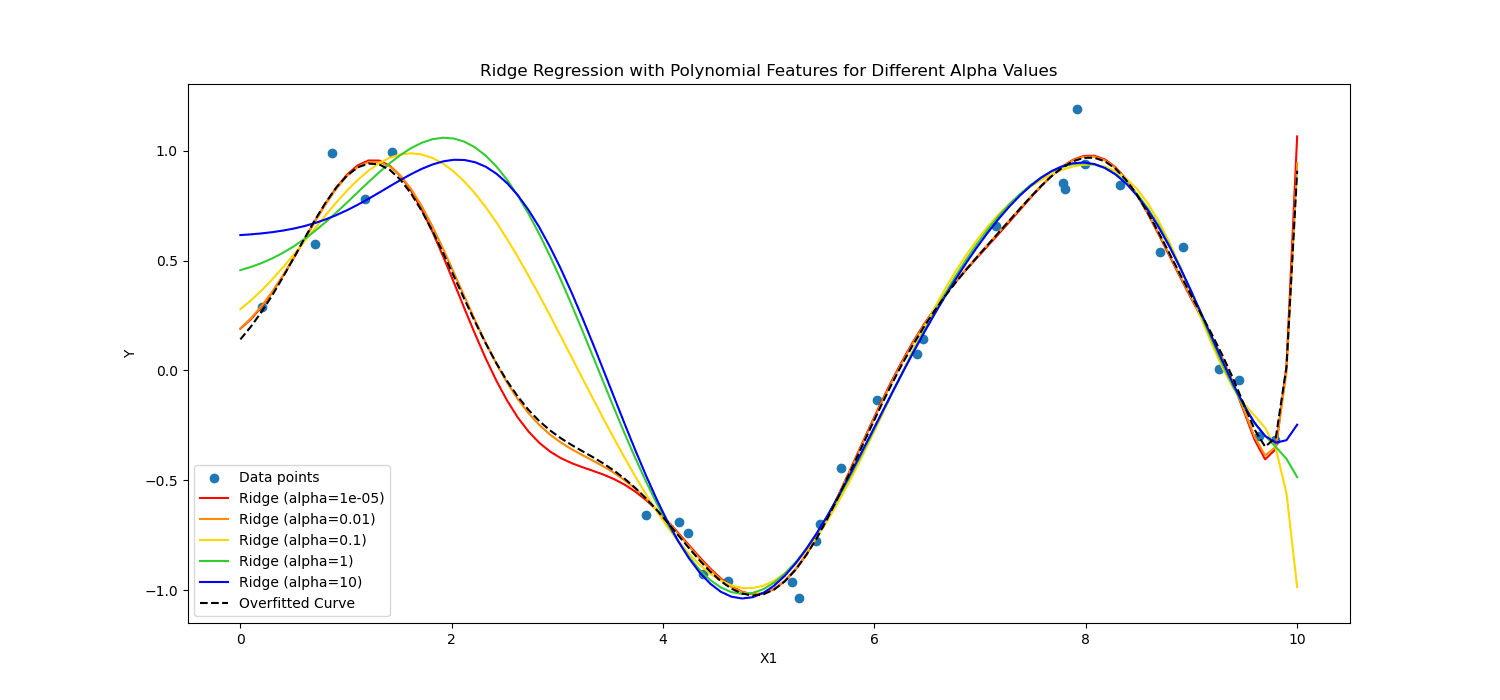
Kurz gesagt, sie haben anders gerechnet.
Wenden wir diese auf die Herzpatientendaten an, um die Leistungsfähigkeit von Deep Learning und maschinellem Lernen zu sehen.
Jetzt werden wir die Regularisierung anwenden, um Daten von Herzpatienten zu analysieren und die Wirksamkeit der Regularisierung zu ermitteln. Sie können den Datensatz unter erreichen hier.
Um maschinelles Lernen anzuwenden, verwenden wir Scikit-learn; Um Deep Learning anzuwenden, verwenden wir TensorFlow. Lasst uns beginnen!
Regularisierung im maschinellen Lernen
Scikit-learn ist eines der beliebtesten Python-Bibliotheken für maschinelles Lernen, das einfache und effiziente Datenanalyse- und Modellierungstools bietet.
Es umfasst Implementierungen verschiedener Regularisierungstechniken, insbesondere für lineare Modelle.
Hier untersuchen wir, wie man die Regularisierung L1 (Lasso) und L2 (Ridge) anwendet.
Im folgenden Code trainieren wir die logistische Regression mithilfe der Techniken Ridge (L2) und Lasso-Regularisierung (L1). Am Ende sehen wir den ausführlichen Bericht. Schauen wir uns den Code an.
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
# Assuming heart_data is already loaded
X = heart_data.drop('target', axis=1)
y = heart_data['target']
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Standardize the features
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Define regularization values to explore
regularization_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over regularization values for L1 and L2
for C_value in regularization_values:
# Train and evaluate L1 model
log_reg_l1 = LogisticRegression(penalty='l1', C=C_value, solver='liblinear')
log_reg_l1.fit(X_train_scaled, y_train)
y_pred_l1 = log_reg_l1.predict(X_test_scaled)
accuracy_l1 = accuracy_score(y_test, y_pred_l1)
report_l1 = classification_report(y_test, y_pred_l1)
performance_metrics.append(('L1', C_value, accuracy_l1))
# Train and evaluate L2 model
log_reg_l2 = LogisticRegression(penalty='l2', C=C_value, solver='liblinear')
log_reg_l2.fit(X_train_scaled, y_train)
y_pred_l2 = log_reg_l2.predict(X_test_scaled)
accuracy_l2 = accuracy_score(y_test, y_pred_l2)
report_l2 = classification_report(y_test, y_pred_l2)
performance_metrics.append(('L2', C_value, accuracy_l2))
# Print the performance metrics for all models
print("Model Performance Evaluation:")
print("--------------------------------")
for metric in performance_metrics:
reg_type, C_value, accuracy = metric
print(f"Regularization: {reg_type}, C: {C_value}, Accuracy: {accuracy:.2f}")
Hier ist die Ausgabe.
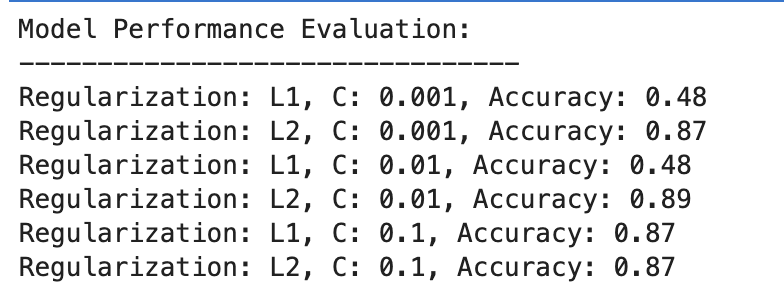
Bewerten wir das Ergebnis.
L1 Regularisierung
- Bei C=0.001 ist die Genauigkeit besonders niedrig (48 %). Dies zeigt, dass das Modell nicht ausreichend angepasst ist. Es zeigt zu viel Regularisierung.
- Wenn C auf 0.01 ansteigt, bleibt die Genauigkeit für L1 unverändert, was darauf hindeutet, dass das Modell immer noch unter einer Unteranpassung leidet oder die Regularisierung zu stark ist.
- Bei C=0.1 verbessert sich die Genauigkeit deutlich auf 87 %, was zeigt, dass die Reduzierung der Regularisierungsstärke es dem Modell ermöglicht, besser aus den Daten zu lernen.
L2 Regularisierung
Die L2-Regularisierung schneidet im Großen und Ganzen konstant gut ab, mit einer Genauigkeit von 87 % für C=0.001 und einer etwas höheren Genauigkeit von 89 % für C=0.01, die sich dann bei 87 % für C=0.1 stabilisiert.
Dies deutet darauf hin, dass die L2-Regularisierung für diesen Datensatz in logistischen Regressionsmodellen im Allgemeinen fehlerverzeihender und effektiver ist, möglicherweise aufgrund ihrer Natur.
Regularisierung im Deep Learning
Beim Deep Learning werden mehrere Regularisierungstechniken verwendet, darunter L1- (Lasso) und L2- (Ridge) Regularisierung, Dropout und frühes Stoppen.
Um zu wiederholen, was wir zuvor im Beispiel für maschinelles Lernen getan haben, wenden wir in diesem Fall die L1- und L2-Regularisierung an. Lassen Sie uns dieses Mal eine Liste von L1- und L2-Regularisierungswerten definieren.
Anschließend werden wir für alle diese Werte unser Deep-Learning-Modell trainieren und evaluieren und am Ende die Ergebnisse bewerten.
Mal sehen, den Code.
from tensorflow.keras.regularizers import l1_l2
import numpy as np
# Define a list/grid of L1 and L2 regularization values
l1_values = [0.001, 0.01, 0.1]
l2_values = [0.001, 0.01, 0.1]
# Placeholder for storing performance metrics
performance_metrics = []
# Iterate over all combinations of L1 and L2 values
for l1_val in l1_values:
for l2_val in l2_values:
# Define model with the current combination of L1 and L2
model = Sequential([
Dense(128, activation='relu', input_shape=(X_train_scaled.shape[1],), kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(64, activation='relu', kernel_regularizer=l1_l2(l1=l1_val, l2=l2_val)),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
history = model.fit(X_train_scaled, y_train, validation_split=0.2, epochs=100, batch_size=10, verbose=0)
# Evaluate the model
loss, accuracy = model.evaluate(X_test_scaled, y_test, verbose=0)
# Store the performance along with the regularization values
performance_metrics.append((l1_val, l2_val, accuracy))
# Find the best performing model
best_performance = max(performance_metrics, key=lambda x: x[2])
best_l1, best_l2, best_accuracy = best_performance
# After the loop, to print all performance metrics
print("All Model Performances:")
print("L1 Value | L2 Value | Accuracy")
for metrics in performance_metrics:
print(f"{metrics[0]:8} | {metrics[1]:8} | {metrics[2]:.3f}")
# After finding the best performance, to print the best model details
print("nBest Model Performance:")
print("----------------------------")
print(f"Best L1 value: {best_l1}")
print(f"Best L2 value: {best_l2}")
print(f"Best accuracy: {best_accuracy:.3f}")
Hier ist die Ausgabe.
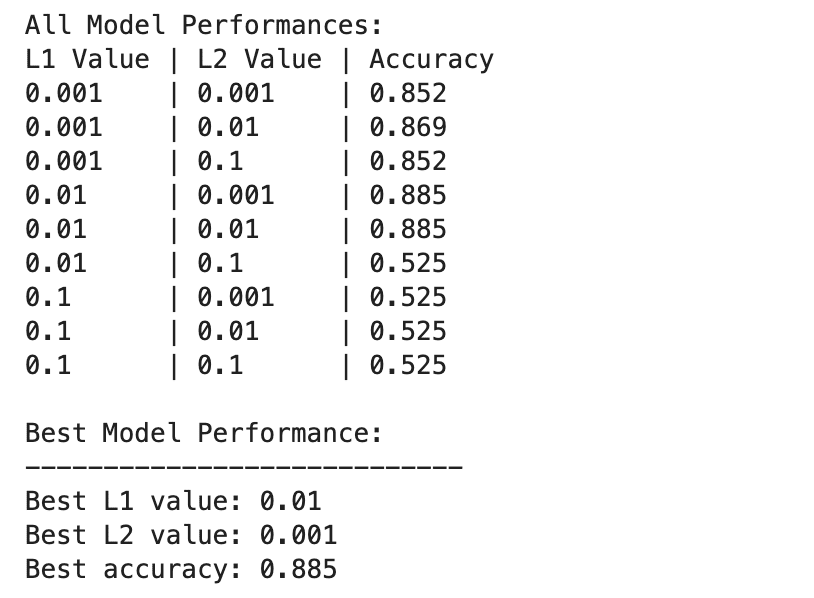
Die Leistung des Deep-Learning-Modells variiert stärker bei verschiedenen Kombinationen von L1- und L2-Regularisierungswerten.
Die beste Leistung wird bei L1=0.01 und L2=0.001 mit einer Genauigkeit von 88.5 % beobachtet, was auf eine ausgewogene Regularisierung hinweist, die eine Überanpassung verhindert und es dem Modell gleichzeitig ermöglicht, die zugrunde liegenden Muster in den Daten zu erfassen.
Höhere Regularisierungswerte, insbesondere bei L1=0.1 oder L2=0.1, reduzieren die Modellgenauigkeit drastisch auf 52.5 %, was darauf hindeutet, dass zu viel Regularisierung die Lernkapazität des Modells stark einschränkt.
Maschinelles Lernen und Deep Learning in der Regularisierung
Vergleichen wir die Ergebnisse zwischen maschinellem Lernen und tiefem Lernen.
Wirksamkeit der Regularisierung: Sowohl im maschinellen Lernen als auch im Deep-Learning-Kontext trägt eine angemessene Regularisierung dazu bei, eine Überanpassung zu mildern, eine übermäßige Regularisierung führt jedoch zu einer Unteranpassung. Die optimale Regularisierungsstärke variiert, wobei Deep-Learning-Modelle aufgrund ihrer höheren Komplexität möglicherweise eine differenziertere Balance erfordern.
Eigenschaften: Das leistungsstärkste Modell für maschinelles Lernen (L2 mit C=0.01, 89 % Genauigkeit) und das leistungsstärkste Deep-Learning-Modell (L1=0.01, L2=0.001, 88.5 % Genauigkeit) erzielen vergleichbare Genauigkeiten, was zeigt, dass beide Ansätze effektiv sein können reguliert, um eine hohe Leistung für diesen Datensatz zu erzielen.
Regularisierungsstrategie: Die L2-Regularisierung scheint effektiver zu sein und weniger empfindlich auf die Wahl von C in logistischen Regressionsmodellen zu reagieren, während eine Kombination aus L1- und L2-Regularisierung das beste Ergebnis beim Deep Learning liefert und ein Gleichgewicht zwischen Merkmalsauswahl und Gewichtsbenachteiligung bietet.
Die Wahl und Stärke der Regularisierung sollte sorgfältig abgestimmt werden, um die Lernkomplexität mit dem Risiko einer Über- oder Unteranpassung in Einklang zu bringen.
Im Rahmen dieser Untersuchung haben wir die Regularisierung entmystifiziert und ihre Rolle bei der Verhinderung einer Überanpassung und der Sicherstellung einer guten Verallgemeinerung unserer Modelle auf unsichtbare Daten aufgezeigt.
Durch die Anwendung von Regularisierungstechniken kommen Sie Ihren Kenntnissen im maschinellen Lernen und Deep Learning näher und festigen Ihr Data-Scientist-Toolset.
Gehen Sie in die Datenprojekte und versuchen Sie, Ihre Daten in verschiedenen Szenarien zu regulieren, z Vorhersage der Lieferdauer. In diesem Datenprojekt haben wir sowohl Modelle für maschinelles Lernen als auch für Deep Learning verwendet. Am Ende haben wir jedoch auch erwähnt, dass es Raum für Verbesserungen geben könnte. Warum versuchen Sie es dort nicht mit der Regularisierung und sehen, ob es hilft?
Nate Rosidi ist Data Scientist und in der Produktstrategie. Er ist auch außerplanmäßiger Professor für Analytik und Gründer von StrataScratch, eine Plattform, die Datenwissenschaftlern hilft, sich mit echten Interviewfragen von Top-Unternehmen auf ihre Interviews vorzubereiten. Verbinde dich mit ihm auf Twitter: StrataScratch or LinkedIn.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/wtf-is-regularization-and-what-is-it-for?utm_source=rss&utm_medium=rss&utm_campaign=wtf-is-regularization-and-what-is-it-for

