Im Bereich des verteilten Deep Learning für große Sprachmodelle (LLMs) wurden enorme Fortschritte erzielt, insbesondere nach der Veröffentlichung von ChatGPT im Dezember 2022. LLMs wachsen mit Milliarden oder sogar Billionen von Parametern weiter an Größe, und das wird oft nicht der Fall sein passen aufgrund von Speicherbeschränkungen in ein einzelnes Beschleunigergerät wie eine GPU oder sogar in einen einzelnen Knoten wie ml.p5.32xlarge. Kunden, die LLMs schulen, müssen ihre Arbeitslast oft auf Hunderte oder sogar Tausende von GPUs verteilen. Die Ermöglichung von Schulungen in einem solchen Umfang bleibt bei verteilter Schulung eine Herausforderung, und eine effiziente Schulung in einem so großen System ist ein weiteres ebenso wichtiges Problem. In den letzten Jahren hat die verteilte Trainingsgemeinschaft 3D-Parallelität (Datenparallelität, Pipeline-Parallelität und Tensor-Parallelität) und andere Techniken (wie Sequenzparallelität und Expertenparallelität) eingeführt, um solchen Herausforderungen zu begegnen.
Im Dezember 2023 kündigte Amazon die Veröffentlichung des an SageMaker-Modell-Parallelbibliothek 2.0 (SMP), das zusammen mit dem eine hochmoderne Effizienz beim Training großer Modelle erreicht SageMaker-Bibliothek für verteilte Datenparallelität (SMDDP). Diese Version ist ein bedeutendes Update von 1.x: SMP ist jetzt in Open Source PyTorch integriert Vollständig geteilte Datenparallelität (FSDP) APIs, die Ihnen die Verwendung einer vertrauten Schnittstelle beim Training großer Modelle ermöglichen und kompatibel sind mit Transformatormotor (TE), wodurch erstmals Tensor-Parallelitätstechniken neben FSDP freigeschaltet werden. Weitere Informationen zur Veröffentlichung finden Sie unter Die Parallelbibliothek des Amazon SageMaker-Modells beschleunigt jetzt PyTorch FSDP-Workloads um bis zu 20 %.
In diesem Beitrag untersuchen wir die Leistungsvorteile von Amazon Sage Maker (einschließlich SMP und SMDDP) und wie Sie die Bibliothek nutzen können, um große Modelle effizient auf SageMaker zu trainieren. Wir demonstrieren die Leistung von SageMaker mit Benchmarks auf ml.p4d.24xlarge-Clustern mit bis zu 128 Instanzen und gemischter FSDP-Präzision mit bfloat16 für das Llama 2-Modell. Wir beginnen mit einer Demonstration nahezu linearer Skalierungseffizienzen für SageMaker, gefolgt von der Analyse der Beiträge jedes Features für optimalen Durchsatz und enden mit einem effizienten Training mit verschiedenen Sequenzlängen bis zu 32,768 durch Tensorparallelität.
Nahezu lineare Skalierung mit SageMaker
Um die Gesamttrainingszeit für LLM-Modelle zu reduzieren, ist die Aufrechterhaltung eines hohen Durchsatzes bei der Skalierung auf große Cluster (Tausende von GPUs) angesichts des Kommunikationsaufwands zwischen den Knoten von entscheidender Bedeutung. In diesem Beitrag demonstrieren wir robuste und nahezu lineare Skalierungseffizienzen (durch Variation der Anzahl der GPUs für eine feste Gesamtproblemgröße) auf p4d-Instanzen, die sowohl SMP als auch SMDDP aufrufen.
In diesem Abschnitt demonstrieren wir die nahezu lineare Skalierungsleistung von SMP. Hier trainieren wir Llama 2-Modelle verschiedener Größen (7B-, 13B- und 70B-Parameter) mit einer festen Sequenzlänge von 4,096, dem SMDDP-Backend für kollektive Kommunikation, TE-fähig, einer globalen Batch-Größe von 4 Millionen, mit 16 bis 128 p4d-Knoten . Die folgende Tabelle fasst unsere optimale Konfiguration und Trainingsleistung (Modell-TFLOPs pro Sekunde) zusammen.
| Modellgröße | Anzahl der Knoten | TFLOPs* | sdp* | tp* | ausladen* | Skalierungseffizienz |
| 7B | 16 | 136.76 | 32 | 1 | N | 100.0% |
| 32 | 132.65 | 64 | 1 | N | 97.0% | |
| 64 | 125.31 | 64 | 1 | N | 91.6% | |
| 128 | 115.01 | 64 | 1 | N | 84.1% | |
| 13 Mrd | 16 | 141.43 | 32 | 1 | Y | 100.0% |
| 32 | 139.46 | 256 | 1 | N | 98.6% | |
| 64 | 132.17 | 128 | 1 | N | 93.5% | |
| 128 | 120.75 | 128 | 1 | N | 85.4% | |
| 70 Mrd | 32 | 154.33 | 256 | 1 | Y | 100.0% |
| 64 | 149.60 | 256 | 1 | N | 96.9% | |
| 128 | 136.52 | 64 | 2 | N | 88.5% |
*Bei der gegebenen Modellgröße, Sequenzlänge und Anzahl der Knoten zeigen wir den global optimalen Durchsatz und die Konfigurationen nach Untersuchung verschiedener SDP-, TP- und Aktivierungs-Offloading-Kombinationen.
Die vorstehende Tabelle fasst die optimalen Durchsatzzahlen zusammen, abhängig vom Grad der Sharded Data Parallelität (SDP) (typischerweise unter Verwendung von FSDP-Hybrid-Sharding anstelle von Voll-Sharding, weitere Details im nächsten Abschnitt), dem Grad der Tensor-Parallelität (Tp) und den Änderungen des Aktivierungs-Offloading-Werts. Demonstration einer nahezu linearen Skalierung für SMP zusammen mit SMDDP. Wenn beispielsweise die Llama 2-Modellgröße 7B und die Sequenzlänge 4,096 gegeben sind, werden insgesamt Skalierungseffizienzen von 97.0 %, 91.6 % und 84.1 % (relativ zu 16 Knoten) bei 32, 64 bzw. 128 Knoten erreicht. Die Skalierungseffizienzen sind über verschiedene Modellgrößen hinweg stabil und nehmen mit zunehmender Modellgröße leicht zu.
SMP und SMDDP zeigen auch ähnliche Skalierungseffizienzen für andere Sequenzlängen wie 2,048 und 8,192.
Leistung der SageMaker-Modell-Parallelbibliothek 2.0: Llama 2 70B
Die Modellgrößen sind in den letzten Jahren weiter gewachsen, zusammen mit häufigen Leistungsaktualisierungen auf dem neuesten Stand der Technik in der LLM-Community. In diesem Abschnitt veranschaulichen wir die Leistung in SageMaker für das Llama 2-Modell unter Verwendung einer festen Modellgröße 70B, einer Sequenzlänge von 4,096 und einer globalen Stapelgröße von 4 Millionen. Zum Vergleich mit der global optimalen Konfiguration und dem optimalen Durchsatz der vorherigen Tabelle (mit SMDDP-Backend, typischerweise FSDP-Hybrid-Sharding und TE) erweitert die folgende Tabelle andere optimale Durchsätze (möglicherweise mit Tensorparallelität) mit zusätzlichen Spezifikationen für das verteilte Backend (NCCL und SMDDP). , FSDP-Sharding-Strategien (vollständiges Sharding und Hybrid-Sharding) und die Aktivierung von TE oder nicht (Standard).
| Modellgröße | Anzahl der Knoten | TFLOPS | TFLOPs #3-Konfiguration | TFLOPs-Verbesserung gegenüber dem Ausgangswert | ||||||||
| . | . | NCCL vollständiges Sharding: #0 | Vollständiges SMDDP-Sharding: Nr. 1 | SMDDP-Hybrid-Sharding: #2 | SMDDP-Hybrid-Sharding mit TE: #3 | sdp* | tp* | ausladen* | #0 → #1 | #1 → #2 | #2 → #3 | #0 → #3 |
| 70 Mrd | 32 | 150.82 | 149.90 | 150.05 | 154.33 | 256 | 1 | Y | -0.6% | 0.1% | 2.9% | 2.3% |
| 64 | 144.38 | 144.38 | 145.42 | 149.60 | 256 | 1 | N | 0.0% | 0.7% | 2.9% | 3.6% | |
| 128 | 68.53 | 103.06 | 130.66 | 136.52 | 64 | 2 | N | 50.4% | 26.8% | 4.5% | 99.2% | |
*Bei der gegebenen Modellgröße, Sequenzlänge und Anzahl der Knoten zeigen wir den global optimalen Durchsatz und die optimale Konfiguration, nachdem wir verschiedene SDP-, TP- und Aktivierungs-Offloading-Kombinationen untersucht haben.
Die neueste Version von SMP und SMDDP unterstützt mehrere Funktionen, darunter natives PyTorch FSDP, erweitertes und flexibleres Hybrid-Sharding, Transformer-Engine-Integration, Tensor-Parallelität und optimierten All-Gather-Kollektivbetrieb. Um besser zu verstehen, wie SageMaker ein effizientes verteiltes Training für LLMs erreicht, untersuchen wir inkrementelle Beiträge von SMDDP und dem folgenden SMP Kernfunktionen:
- SMDDP-Verbesserung gegenüber NCCL mit vollständigem FSDP-Sharding
- Ersetzen des vollständigen FSDP-Shardings durch Hybrid-Sharding, wodurch die Kommunikationskosten gesenkt und der Durchsatz verbessert werden
- Eine weitere Steigerung des Durchsatzes mit TE, selbst wenn die Tensor-Parallelität deaktiviert ist
- Bei niedrigeren Ressourceneinstellungen kann das Aktivierungs-Offloading möglicherweise ein Training ermöglichen, das ansonsten aufgrund der hohen Speicherauslastung nicht durchführbar oder sehr langsam wäre
FSDP Full Sharding: SMDDP-Verbesserung gegenüber NCCL
Wie in der vorherigen Tabelle gezeigt, gibt es bei vollständiger Shardierung der Modelle mit FSDP zwar einen vergleichbaren Durchsatz von NCCL (TFLOPs #0) und SMDDP (TFLOPs #1) bei 32 oder 64 Knoten, aber eine enorme Verbesserung von 50.4 % von NCCL zu SMDDP bei 128 Knoten.
Bei kleineren Modellgrößen beobachten wir konsistente und signifikante Verbesserungen mit SMDDP gegenüber NCCL, beginnend bei kleineren Clustergrößen, da SMDDP den Kommunikationsengpass effektiv abmildern kann.
FSDP-Hybrid-Sharding zur Reduzierung der Kommunikationskosten
In SMP 1.0 haben wir gestartet Sharded-Daten-Parallelität, eine verteilte Trainingstechnik, die von Amazon selbst entwickelt wird MiCS Technologie. In SMP 2.0 führen wir SMP-Hybrid-Sharding ein, eine erweiterbare und flexiblere Hybrid-Sharding-Technik, die es ermöglicht, Modelle auf eine Teilmenge von GPUs aufzuteilen, anstatt auf alle Trainings-GPUs, was beim vollständigen FSDP-Sharding der Fall ist. Dies ist nützlich für mittelgroße Modelle, die nicht über den gesamten Cluster verteilt werden müssen, um die Speicherbeschränkungen pro GPU zu erfüllen. Dies führt dazu, dass Cluster über mehr als ein Modellreplikat verfügen und jede GPU zur Laufzeit mit weniger Peers kommuniziert.
Das Hybrid-Sharding von SMP ermöglicht effizientes Modell-Sharding über einen größeren Bereich, vom kleinsten Shard-Grad ohne Speicherprobleme bis hin zur gesamten Clustergröße (was einem vollständigen Sharding entspricht).
Die folgende Abbildung veranschaulicht der Einfachheit halber die Durchsatzabhängigkeit von SDP bei tp = 1. Obwohl es nicht unbedingt mit dem optimalen tp-Wert für NCCL- oder SMDDP-Full-Sharding in der vorherigen Tabelle übereinstimmt, liegen die Zahlen recht nahe beieinander. Es bestätigt eindeutig den Wert des Wechsels von vollständigem Sharding zu Hybrid-Sharding bei einer großen Clustergröße von 128 Knoten, was sowohl für NCCL als auch für SMDDP gilt. Bei kleineren Modellgrößen beginnen erhebliche Verbesserungen durch Hybrid-Sharding bei kleineren Clustergrößen, und der Unterschied nimmt mit der Clustergröße immer weiter zu.
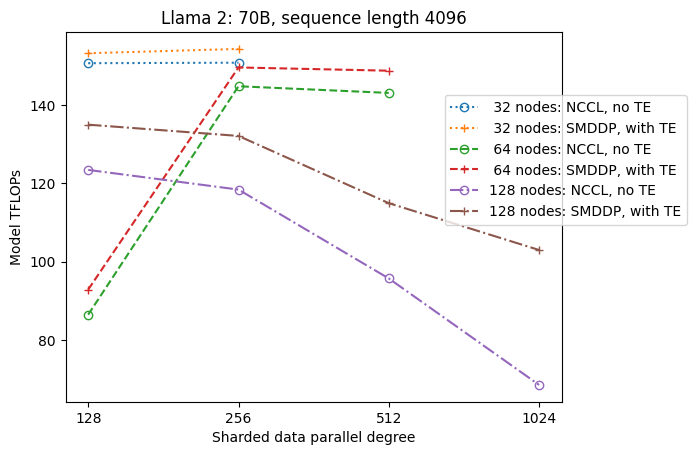
Verbesserungen mit TE
TE wurde entwickelt, um das LLM-Training auf NVIDIA-GPUs zu beschleunigen. Obwohl FP8 nicht verwendet wird, da es auf p4d-Instanzen nicht unterstützt wird, sehen wir mit TE auf p4d immer noch eine deutliche Beschleunigung.
Zusätzlich zu MiCS, das mit dem SMDDP-Backend trainiert wurde, führt TE eine konsistente Steigerung des Durchsatzes über alle Clustergrößen hinweg ein (die einzige Ausnahme ist das vollständige Sharding bei 128 Knoten), selbst wenn die Tensor-Parallelität deaktiviert ist (Tensor-Parallelitätsgrad ist 1).
Bei kleineren Modellgrößen oder verschiedenen Sequenzlängen ist der TE-Boost stabil und nicht trivial und liegt im Bereich von etwa 3–7.6 %.
Aktivierungs-Offloading bei niedrigen Ressourceneinstellungen
Bei niedrigen Ressourceneinstellungen (bei einer kleinen Anzahl von Knoten) kann es bei FSDP zu einem hohen Speicherdruck (oder im schlimmsten Fall sogar zu wenig Speicher) kommen, wenn die Aktivierungsprüfpunktfunktion aktiviert ist. In solchen Szenarios, in denen es zu Speicherengpässen kommt, ist die Aktivierung der Aktivierungsauslagerung möglicherweise eine Option zur Verbesserung der Leistung.
Wie wir beispielsweise zuvor gesehen haben, kann Llama 2 bei Modellgröße 13B und Sequenzlänge 4,096 zwar mit mindestens 32 Knoten mit Aktivierungs-Checkpointing und ohne Aktivierungs-Offloading optimal trainieren, erreicht jedoch den besten Durchsatz mit Aktivierungs-Offloading, wenn es auf 16 begrenzt ist Knoten.
Ermöglichen Sie das Training mit langen Sequenzen: SMP-Tensor-Parallelität
Längere Sequenzlängen sind für lange Gespräche und Kontexte erwünscht und erhalten in der LLM-Community mehr Aufmerksamkeit. Daher berichten wir in der folgenden Tabelle über verschiedene Durchsätze bei langen Sequenzen. Die Tabelle zeigt optimale Durchsätze für das Llama 2-Training auf SageMaker mit verschiedenen Sequenzlängen von 2,048 bis 32,768. Bei einer Sequenzlänge von 32,768 ist ein natives FSDP-Training mit 32 Knoten bei einer globalen Batch-Größe von 4 Millionen nicht durchführbar.
| . | . | . | TFLOPS | ||
| Modellgröße | Sequenzlänge | Anzahl der Knoten | Natives FSDP und NCCL | SMP und SMDDP | SMP-Verbesserung |
| 7B | 2048 | 32 | 129.25 | 138.17 | 6.9% |
| 4096 | 32 | 124.38 | 132.65 | 6.6% | |
| 8192 | 32 | 115.25 | 123.11 | 6.8% | |
| 16384 | 32 | 100.73 | 109.11 | 8.3% | |
| 32768 | 32 | NA | 82.87 | . | |
| 13 Mrd | 2048 | 32 | 137.75 | 144.28 | 4.7% |
| 4096 | 32 | 133.30 | 139.46 | 4.6% | |
| 8192 | 32 | 125.04 | 130.08 | 4.0% | |
| 16384 | 32 | 111.58 | 117.01 | 4.9% | |
| 32768 | 32 | NA | 92.38 | . | |
| *: max | . | . | . | . | 8.3% |
| *: Median | . | . | . | . | 5.8% |
Wenn die Clustergröße groß ist und eine feste globale Batchgröße gegeben ist, ist das Training einiger Modelle möglicherweise mit nativem PyTorch FSDP nicht durchführbar, da keine integrierte Pipeline oder Unterstützung für Tensorparallelität fehlt. In der obigen Tabelle beträgt die effektive Stapelgröße pro GPU bei einer globalen Stapelgröße von 4 Millionen, 32 Knoten und einer Sequenzlänge von 32,768 0.5 (z. B. tp = 2 mit Stapelgröße 1), was andernfalls ohne Einführung nicht realisierbar wäre Tensorparallelität.
Zusammenfassung
In diesem Beitrag haben wir effizientes LLM-Training mit SMP und SMDDP auf p4d-Instanzen demonstriert und dabei Beiträge auf mehrere Schlüsselfunktionen zurückgeführt, wie z. B. SMDDP-Verbesserung gegenüber NCCL, flexibles FSDP-Hybrid-Sharding anstelle von vollständigem Sharding, TE-Integration und die Aktivierung von Tensor-Parallelität zugunsten von lange Sequenzlängen. Nachdem es in einer Vielzahl von Umgebungen mit verschiedenen Modellen, Modellgrößen und Sequenzlängen getestet wurde, weist es robuste, nahezu lineare Skalierungseffizienzen auf, bis zu 128 p4d-Instanzen auf SageMaker. Zusammenfassend lässt sich sagen, dass SageMaker weiterhin ein leistungsstarkes Werkzeug für LLM-Forscher und -Praktiker ist.
Weitere Informationen finden Sie unter SageMaker-Modellparallelitätsbibliothek v2, oder kontaktieren Sie das SMP-Team unter sm-model-parallel-feedback@amazon.com.
Danksagung
Wir möchten Robert Van Dusen, Ben Snyder, Gautam Kumar und Luis Quintela für ihr konstruktives Feedback und ihre Diskussionen danken.
Über die Autoren

Xinle Sheila Liu ist eine SDE in Amazon SageMaker. In ihrer Freizeit liest sie gerne und treibt gerne Outdoor-Sport.
 Suhit Kodgule ist Softwareentwicklungsingenieur bei der AWS Artificial Intelligence-Gruppe und arbeitet an Deep-Learning-Frameworks. In seiner Freizeit wandert, reist und kocht er gerne.
Suhit Kodgule ist Softwareentwicklungsingenieur bei der AWS Artificial Intelligence-Gruppe und arbeitet an Deep-Learning-Frameworks. In seiner Freizeit wandert, reist und kocht er gerne.
 Victor Zhu ist Softwareentwickler für verteiltes Deep Learning bei Amazon Web Services. Er genießt Wanderungen und Brettspiele in der SF Bay Area.
Victor Zhu ist Softwareentwickler für verteiltes Deep Learning bei Amazon Web Services. Er genießt Wanderungen und Brettspiele in der SF Bay Area.
 Derya Cavdar arbeitet als Softwareentwickler bei AWS. Zu ihren Interessen zählen Deep Learning und verteilte Trainingsoptimierung.
Derya Cavdar arbeitet als Softwareentwickler bei AWS. Zu ihren Interessen zählen Deep Learning und verteilte Trainingsoptimierung.
 Teng Xu ist Software Development Engineer in der Distributed Training-Gruppe in AWS AI. Er liest gerne.
Teng Xu ist Software Development Engineer in der Distributed Training-Gruppe in AWS AI. Er liest gerne.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/distributed-training-and-efficient-scaling-with-the-amazon-sagemaker-model-parallel-and-data-parallel-libraries/

