Bild vom Autor
Viele fortschrittliche Modelle für maschinelles Lernen wie Random Forests oder Gradientenverstärkungsalgorithmen wie XGBoost, CatBoost oder LightGBM (und sogar Autoencoder!) verlassen sich auf eine entscheidende gemeinsame Zutat: die Entscheidungsbaum!
Ohne Entscheidungsbäume zu verstehen, ist es unmöglich, auch nur einen der oben genannten fortschrittlichen Bagging- oder Gradienten-Verstärkungsalgorithmen zu verstehen, was eine Schande für jeden Datenwissenschaftler ist! Lassen Sie uns also das Innenleben eines Entscheidungsbaums entmystifizieren, indem wir einen in Python implementieren.
In diesem Artikel lernen Sie
- warum und wie ein Entscheidungsbaum Daten aufteilt,
- der Informationsgewinn und
- wie man Entscheidungsbäume in Python mit NumPy implementiert.
Den Code findest du auf mein Github.
Um Vorhersagen treffen zu können, stützen sich Entscheidungsbäume auf Spaltung den Datensatz rekursiv in kleinere Teile zerlegen.
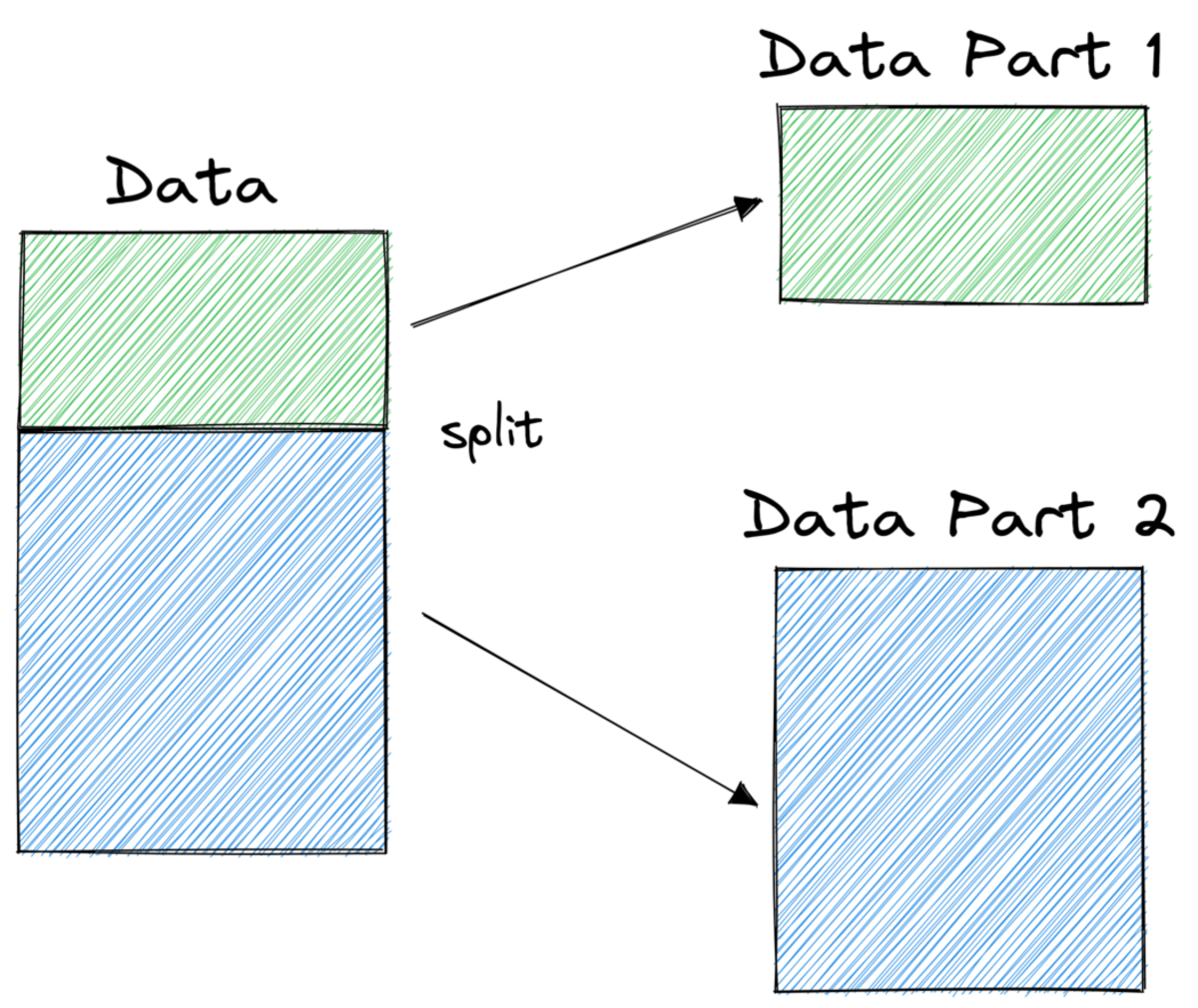
Bild vom Autor
Im Bild oben sehen Sie ein Beispiel für eine Teilung – der ursprüngliche Datensatz wird in zwei Teile geteilt. Im nächsten Schritt werden diese beiden Teile wieder geteilt und so weiter. Dies wird fortgesetzt, bis eine Art Abbruchkriterium erfüllt ist, z.
- wenn die Teilung dazu führt, dass ein Teil leer ist
- wenn eine bestimmte Rekursionstiefe erreicht wurde
- wenn (nach vorherigen Splits) der Datensatz nur noch aus wenigen Elementen besteht, wodurch weitere Splits unnötig werden.
Wie finden wir diese Spaltungen? Und warum interessiert es uns überhaupt? Lass es uns herausfinden.
Motivation
Nehmen wir an, wir wollen a lösen binär Klassifizierungsproblem die wir uns jetzt selbst erschaffen:
import numpy as np
np.random.seed(0) X = np.random.randn(100, 2) # features
y = ((X[:, 0] > 0) * (X[:, 1] < 0)) # labels (0 and 1)Die zweidimensionalen Daten sehen so aus:
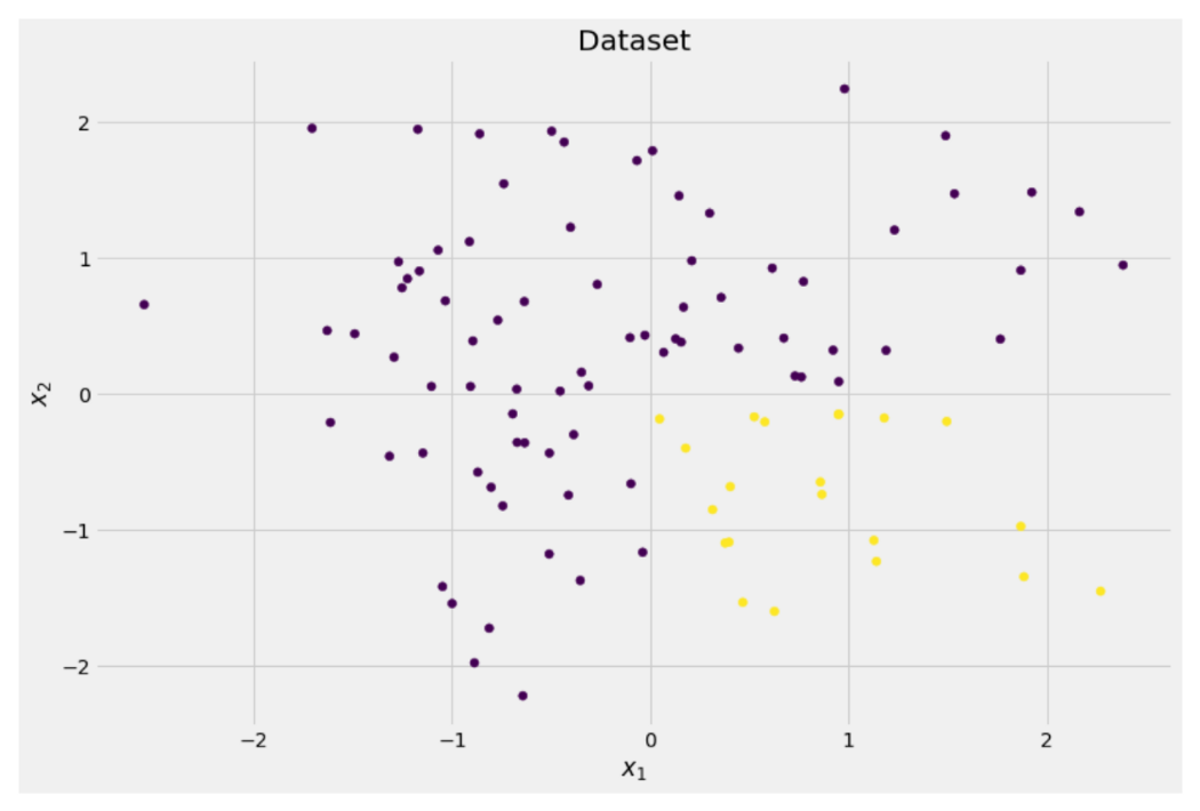
Bild vom Autor
Wir können sehen, dass es zwei verschiedene Klassen gibt – lila in etwa 75 % und gelb in etwa 25 % der Fälle. Wenn Sie diese Daten einem Entscheidungsbaum zuführen Klassifikator, dieser Baum hat zunächst folgende Gedanken:
„Es gibt zwei verschiedene Labels, was mir zu chaotisch ist. Ich möchte dieses Durcheinander beseitigen, indem ich die Daten in zwei Teile aufteile – diese Teile sollten sauberer sein als die gesamten Daten zuvor.“ — Baum, der Bewusstsein erlangte
Und das tut der Baum.
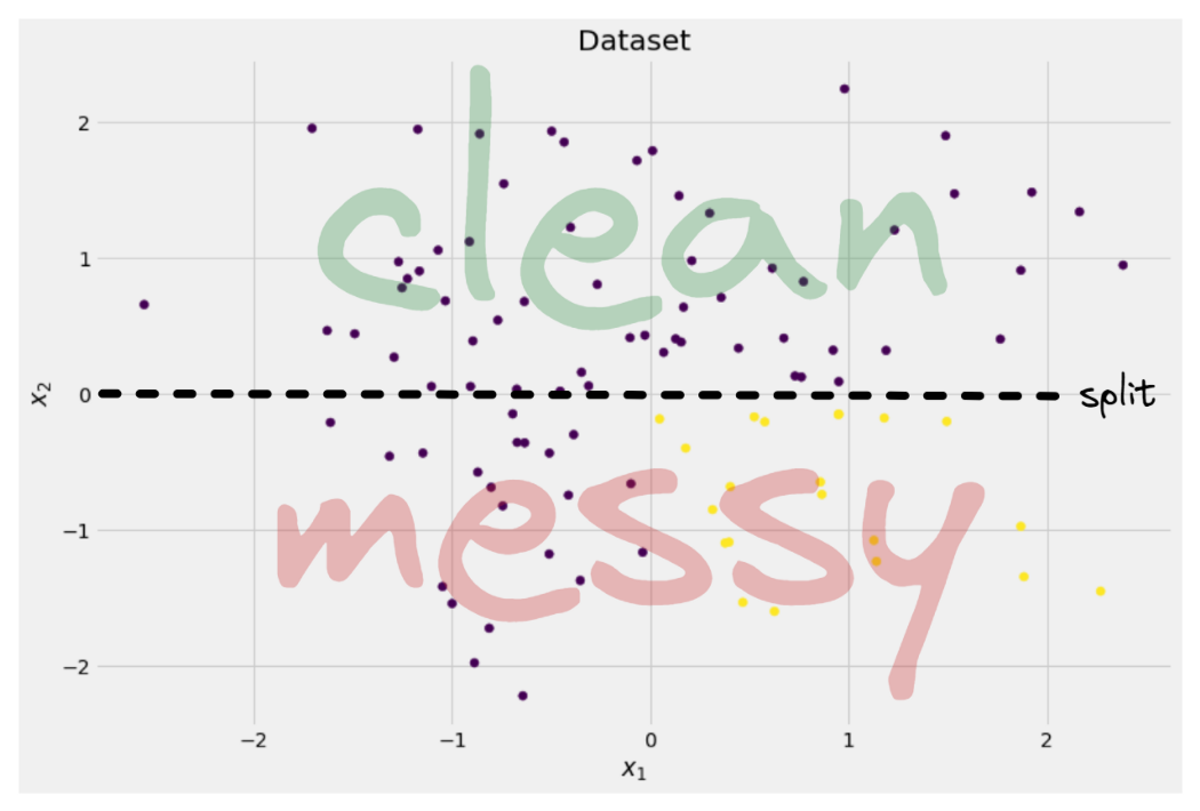
Bild vom Autor
Der Baum beschließt, ungefähr entlang der Spalte zu spalten x-Achse. Das hat zur Folge, dass der obere Teil der Daten nun perfekt ist reinigen, was bedeutet, dass Sie nur finden eine einzige klasse (in diesem Fall lila) dort.
Der untere Teil ist jedoch noch unordentlich, in gewissem Sinne noch chaotischer als zuvor. Früher lag das Klassenverhältnis im gesamten Datensatz bei etwa 75:25, aber in diesem kleineren Teil liegt es bei etwa 50:50, was ziemlich durcheinander ist
Hinweis: Hier spielt es keine Rolle, dass Lila und Gelb im Bild schön getrennt sind. Nur das Rohmenge verschiedener Labels in den zwei Teilen zählen.
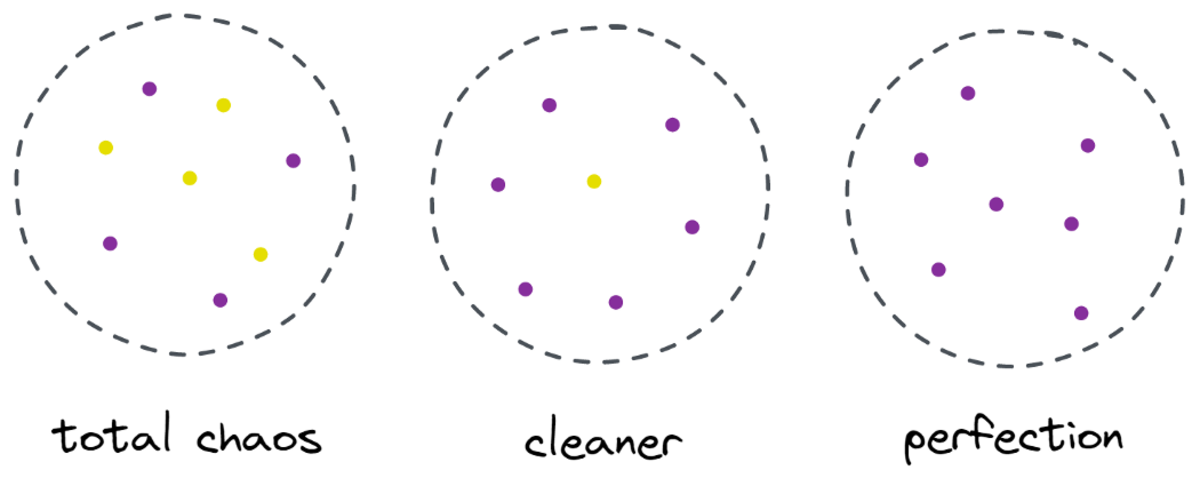
Bild vom Autor
Trotzdem ist dies als erster Schritt für den Baum gut genug, und so geht es weiter. Es würde zwar keine weitere Spaltung in der Spitze erzeugen, reinigen Teil mehr, kann es eine weitere Spalte im unteren Teil erstellen, um es zu bereinigen.
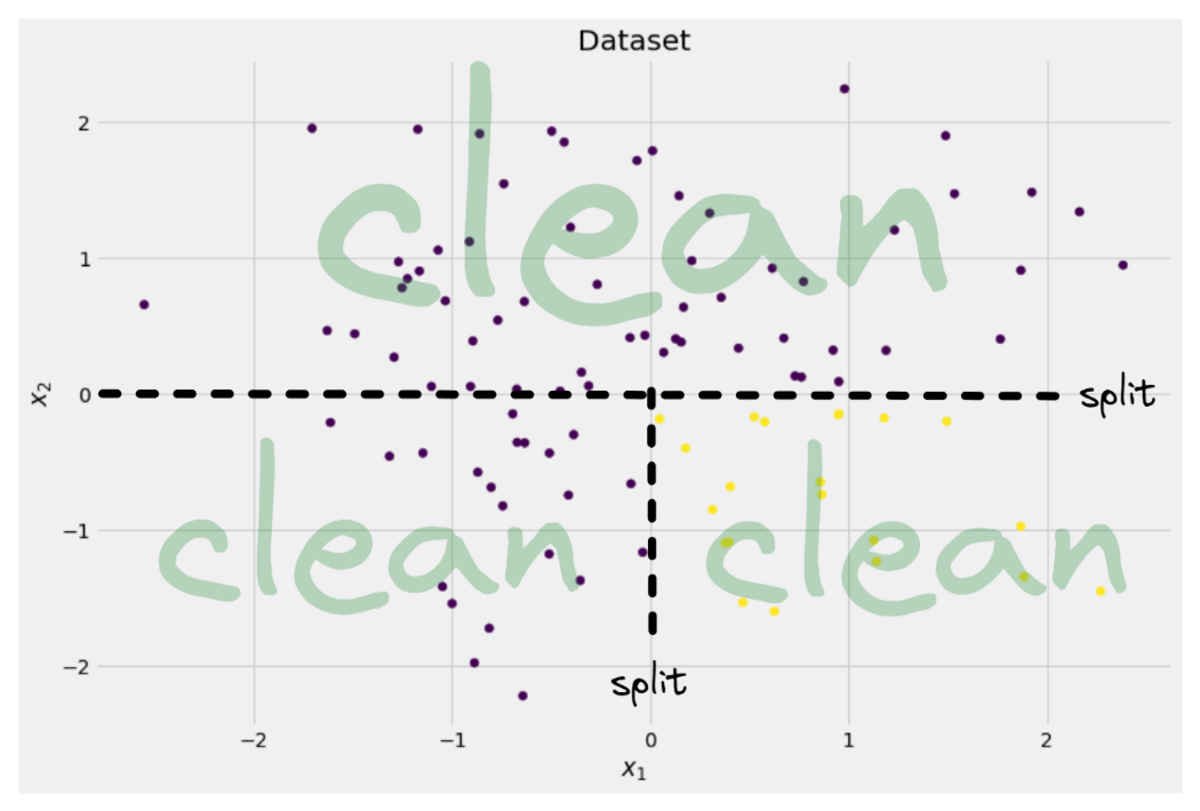
Bild vom Autor
Et voilà, jedes der drei separaten Teile ist komplett sauber, da wir nur eine einzige Farbe (Etikett) pro Teil finden.
Es ist jetzt ganz einfach, Vorhersagen zu treffen: Wenn ein neuer Datenpunkt hereinkommt, checken Sie einfach ein, welcher drei Teile es liegt und gib ihm die entsprechende Farbe. Das funktioniert jetzt so gut, weil jedes Teil ist reinigen. Einfach richtig?
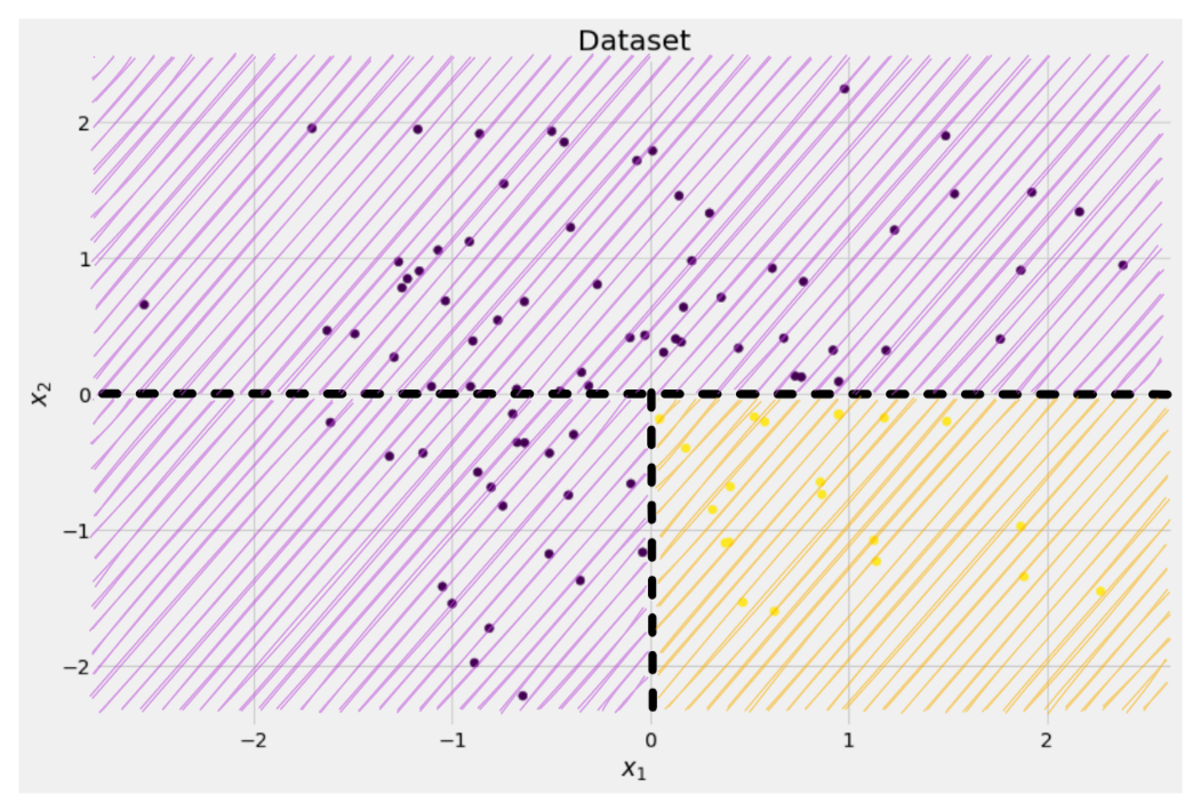
Bild vom Autor
Okay, wir haben darüber gesprochen reinigen und unordentlich Daten, aber bisher stellen diese Worte nur eine vage Idee dar. Um irgendetwas zu implementieren, müssen wir einen Weg finden, es zu definieren Sauberkeit.
Maßnahmen zur Sauberkeit
Nehmen wir zum Beispiel an, wir haben einige Labels
y_1 = [0, 0, 0, 0, 0, 0, 0, 0] y_2 = [1, 0, 0, 0, 0, 0, 1, 0]
y_3 = [1, 0, 1, 1, 0, 0, 1, 0]Intuitiv, y₁ ist der sauberste Satz von Etiketten, gefolgt von y₂ und dann y₃. So weit so gut, aber wie können wir dieses Verhalten beziffern? Am einfachsten fällt mir vielleicht folgendes ein:
Zählen Sie einfach die Anzahl der Nullen und die Anzahl der Einsen. Berechnen Sie ihre absolute Differenz. Um es schöner zu machen, normalisieren Sie es, indem Sie durch die Länge der Arrays dividieren.
Zum Beispiel, y₂ hat insgesamt 8 Einträge — 6 Nullen und 2 Einsen. Daher unsere benutzerdefinierten Sauberkeit Punktzahl wäre |6 – 2| / 8 = 0.5. Es ist leicht zu errechnen, dass die Sauberkeit punktet y₁ und y₃ sind 1.0 bzw. 0.0. Hier sehen wir die allgemeine Formel:
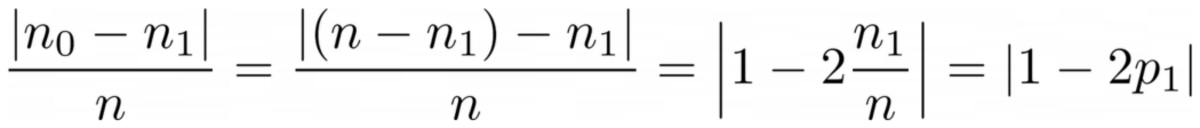
Bild vom Autor
Hier n₀ und n₁ sind die Anzahl der Nullen bzw. Einsen, n = n₀ + n₁ ist die Länge des Arrays und p₁ = n₁ / n ist der Anteil der 1 Labels.
Das Problem mit dieser Formel ist, dass es so ist speziell auf den Fall von zwei Klassen zugeschnitten, aber sehr oft sind wir an einer Mehrklassenklassifizierung interessiert. Eine Formel, die ganz gut funktioniert, ist die Gini-Verunreinigungsmaß:
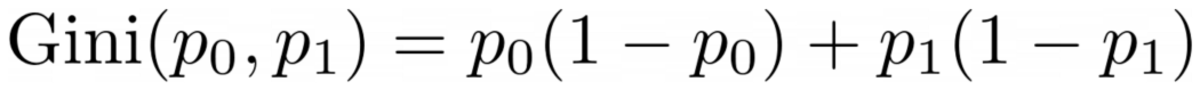
Bild vom Autor
oder der allgemeine Fall:
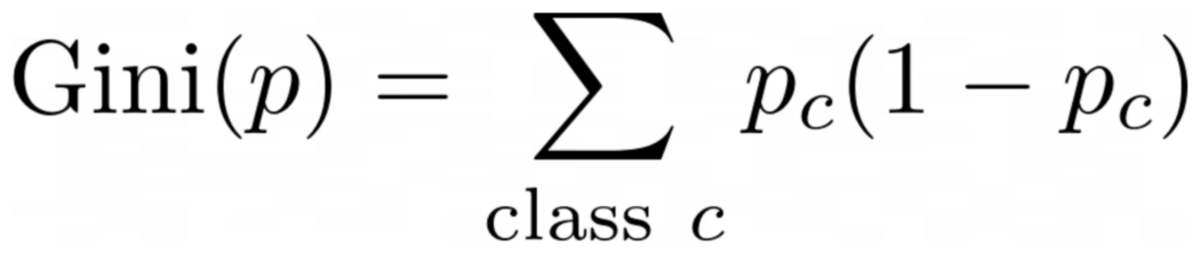
Bild vom Autor
Es funktioniert so gut, dass scikit-learn nahm es als Standardmaßnahme an für seinen DecisionTreeClassifier Klasse.
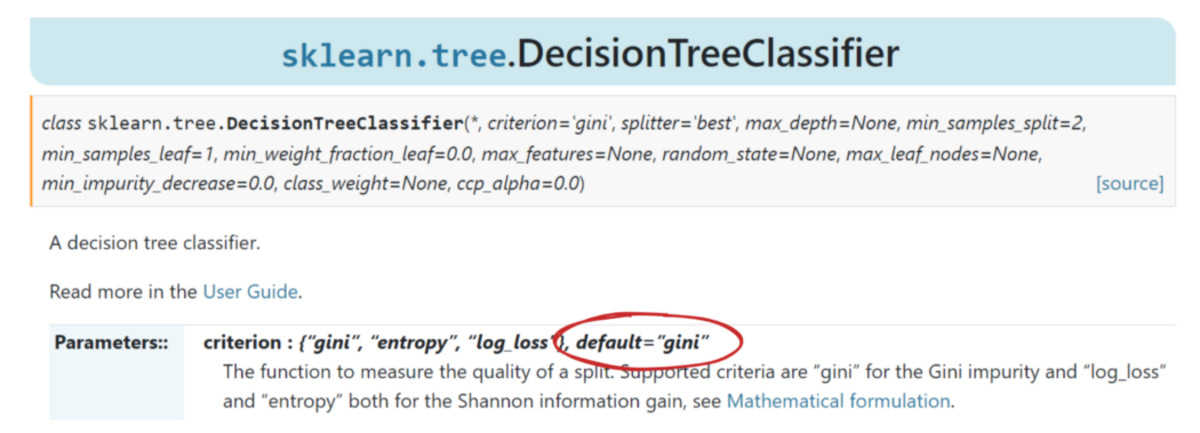
Bild vom Autor
Hinweis: Gini misst Unordnung statt Sauberkeit. Beispiel: Wenn eine Liste nur eine einzige Klasse enthält (=sehr saubere Daten!), dann sind alle Terme in der Summe Null, also ist die Summe Null. Der schlimmste Fall ist, wenn alle Klassen genau so oft vorkommen, in diesem Fall ist der Gini 1–1/C woher C ist die Anzahl der Klassen.
Nun, da wir ein Maß für Sauberkeit/Unordnung haben, wollen wir sehen, wie es verwendet werden kann, um gute Spaltungen zu finden.
Spaltungen finden
Es gibt viele Splits, aus denen wir wählen, aber welcher ist der beste? Lassen Sie uns wieder unseren anfänglichen Datensatz zusammen mit dem Gini-Verunreinigungsmaß verwenden.
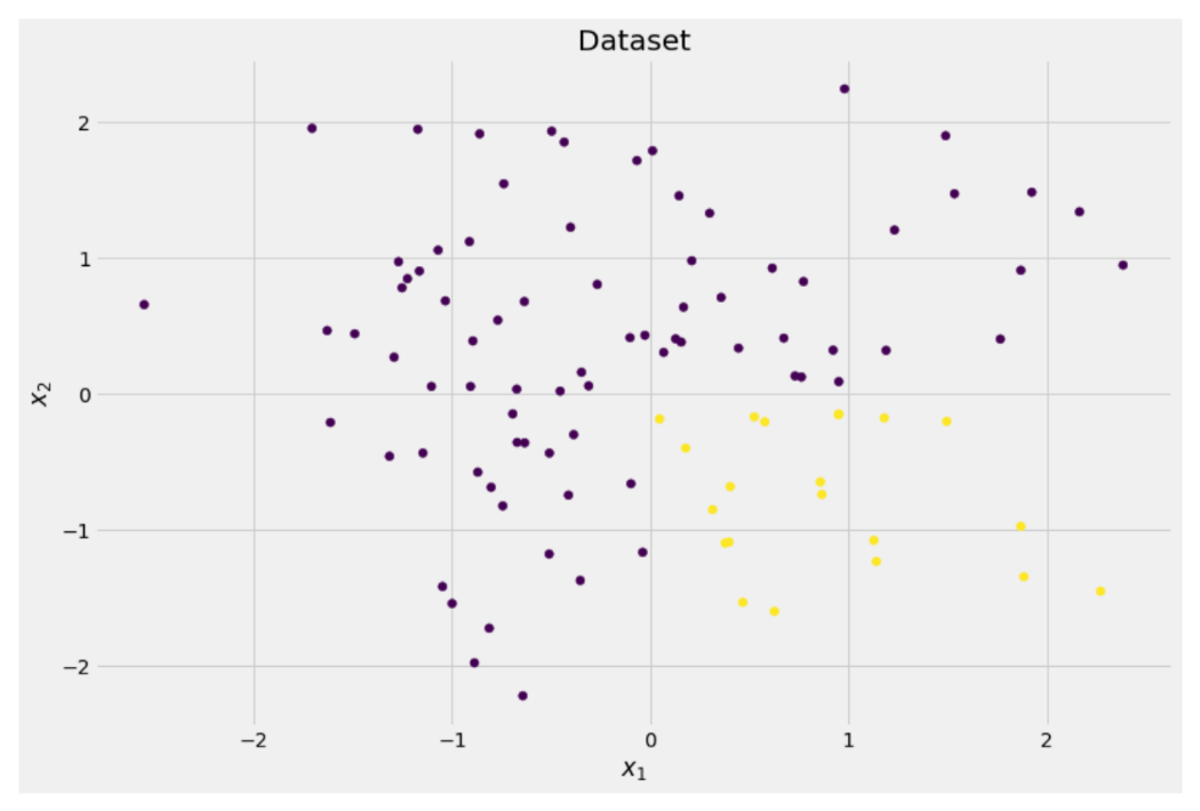
Bild vom Autor
Wir werden die Punkte jetzt nicht zählen, aber nehmen wir an, dass 75 % lila und 25 % gelb sind. Unter Verwendung der Definition von Gini ist die Verunreinigung des gesamten Datensatzes
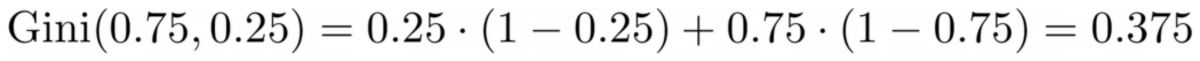
Bild vom Autor
Wenn wir den Datensatz entlang der x-Achse, wie zuvor:
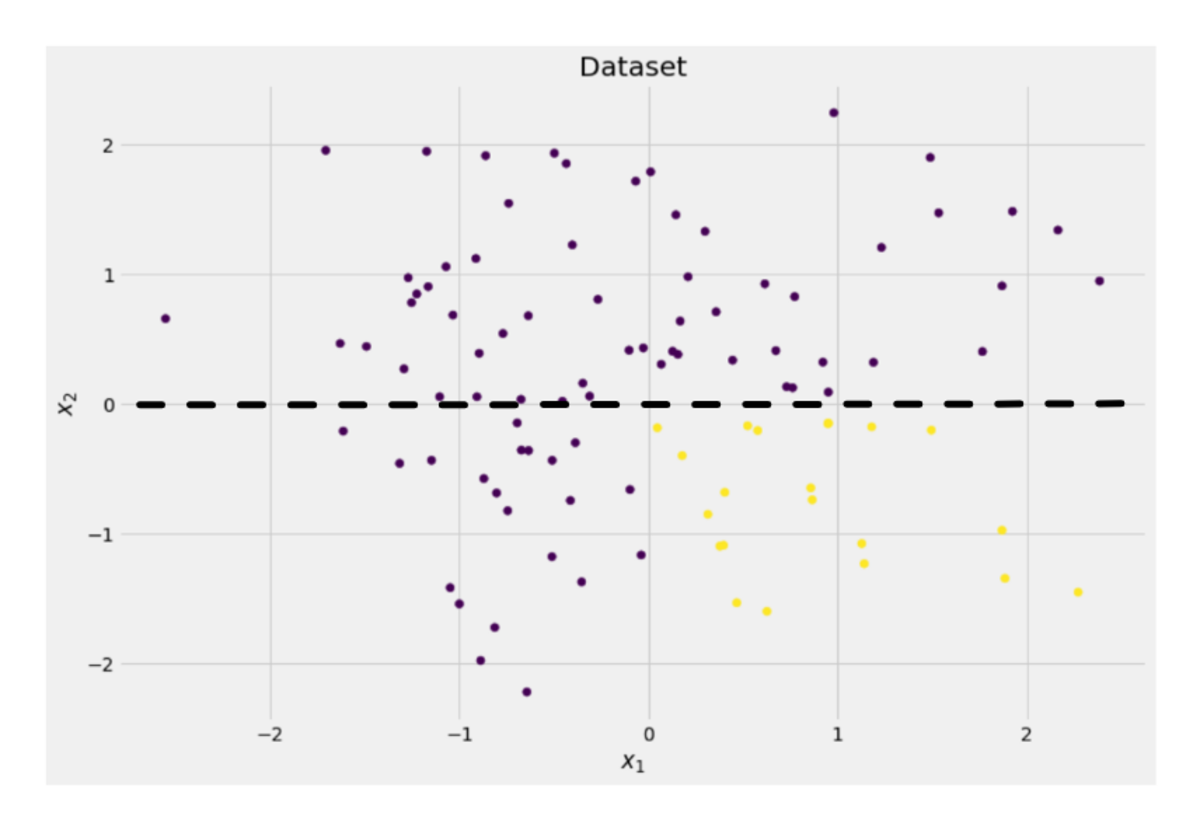
Bild vom Autor
Das Oberteil hat eine Gini-Verunreinigung von 0.0 und der untere Teil
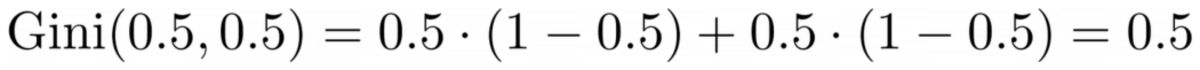
Bild vom Autor
Im Durchschnitt haben die beiden Teile eine Gini-Verunreinigung von (0.0 + 0.5) / 2 = 0.25, was besser ist als die 0.375 des gesamten Datensatzes von zuvor. Wir können es auch in Begriffen des sogenannten ausdrücken Informationsgewinn:
Der Informationsgewinn dieser Aufteilung beträgt 0.375 – 0.25 = 0.125.
Einfach so. Je höher der Informationsgewinn (dh je geringer die Gini-Verunreinigung), desto besser.
Hinweis: Eine andere ebenso gute anfängliche Teilung wäre entlang der y-Achse.
Eine wichtige Sache zu beachten ist, dass es nützlich ist wiegen Sie die Gini-Verunreinigungen der Teile nach der Größe der Teile. Nehmen wir zum Beispiel an, dass
- Teil 1 besteht aus 50 Datenpunkten und hat eine Gini-Verunreinigung von 0.0 und
- Teil 2 besteht aus 450 Datenpunkten und hat eine Gini-Verunreinigung von 0.5,
dann sollte die durchschnittliche Gini-Verunreinigung nicht (0.0 + 0.5) / 2 = 0.25 sein, sondern 50 / (50 + 450) * 0.0 + 450 / (50 + 450) * 0.5 = 0.45.
Okay, und wie finden wir die beste Aufteilung? Die einfache, aber ernüchternde Antwort lautet:
Probieren Sie einfach alle Splits aus und wählen Sie den mit dem höchsten Informationsgewinn aus. Es ist im Grunde ein Brute-Force-Ansatz.
Genauer gesagt werden Standard-Entscheidungsbäume verwendet teilt sich entlang der Koordinatenachsen auf, Ie xᵢ = c für irgendeine Funktion i und Schwelle c. Dies bedeutet, dass
- ein Teil der aufgeteilten Daten besteht aus allen Datenpunkten x mit x cund
- der andere Teil aller Punkte x mit xᵢ ≥ c.
Diese einfachen Aufteilungsregeln haben sich in der Praxis bewährt, aber Sie können diese Logik natürlich auch erweitern, um andere Aufteilungen (z. B. diagonale Linien wie z xᵢ + 2xⱼ = 3, beispielsweise).
Toll, das sind alle Zutaten, die wir brauchen, um jetzt loszulegen!
Wir werden den Entscheidungsbaum jetzt implementieren. Da es aus Knoten besteht, definieren wir a Node Klasse zuerst.
from dataclasses import dataclass @dataclass
class Node: feature: int = None # feature for the split value: float = None # split threshold OR final prediction left: np.array = None # store one part of the data right: np.array = None # store the other part of the dataEin Knoten kennt die Funktion, die er zum Aufteilen verwendet (feature) sowie der Aufteilungswert (value). value wird auch als Speicher für die endgültige Vorhersage des Entscheidungsbaums verwendet. Da wir einen binären Baum erstellen werden, muss jeder Knoten seine linken und rechten Kinder kennen, wie sie in gespeichert sind left und right .
Lassen Sie uns nun die eigentliche Implementierung des Entscheidungsbaums durchführen. Ich mache es scikit-learn-kompatibel, daher verwende ich einige Klassen von sklearn.base . Wenn Sie damit nicht vertraut sind, lesen Sie meinen Artikel darüber wie man scikit-learn-kompatible Modelle baut.
Lassen Sie uns implementieren!
import numpy as np
from sklearn.base import BaseEstimator, ClassifierMixin class DecisionTreeClassifier(BaseEstimator, ClassifierMixin): def __init__(self): self.root = Node() @staticmethod def _gini(y): """Gini impurity.""" counts = np.bincount(y) p = counts / counts.sum() return (p * (1 - p)).sum() def _split(self, X, y): """Bruteforce search over all features and splitting points.""" best_information_gain = float("-inf") best_feature = None best_split = None for feature in range(X.shape[1]): split_candidates = np.unique(X[:, feature]) for split in split_candidates: left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] information_gain = self._gini(y) - ( len(X_left) / len(X) * self._gini(y_left) + len(X_right) / len(X) * self._gini(y_right) ) if information_gain > best_information_gain: best_information_gain = information_gain best_feature = feature best_split = split return best_feature, best_split def _build_tree(self, X, y): """The heavy lifting.""" feature, split = self._split(X, y) left_mask = X[:, feature] split X_left, y_left = X[left_mask], y[left_mask] X_right, y_right = X[~left_mask], y[~left_mask] if len(X_left) == 0 or len(X_right) == 0: return Node(value=np.argmax(np.bincount(y))) else: return Node( feature, split, self._build_tree(X_left, y_left), self._build_tree(X_right, y_right), ) def _find_path(self, x, node): """Given a data point x, walk from the root to the corresponding leaf node. Output its value.""" if node.feature == None: return node.value else: if x[node.feature] node.value: return self._find_path(x, node.left) else: return self._find_path(x, node.right) def fit(self, X, y): self.root = self._build_tree(X, y) return self def predict(self, X): return np.array([self._find_path(x, self.root) for x in X])Und das ist es! Sie können jetzt all die Dinge tun, die Sie an scikit-learn lieben:
dt = DecisionTreeClassifier().fit(X, y)
print(dt.score(X, y)) # accuracy # Output
# 1.0Da der Baum ungeregelt ist, ist er stark überangepasst, daher die perfekte Zugbewertung. Die Genauigkeit wäre bei unsichtbaren Daten schlechter. Wir können auch überprüfen, wie der Baum aussieht via
print(dt.root) # Output (prettified manually):
# Node(
# feature=1,
# value=-0.14963454032767076,
# left=Node(
# feature=0,
# value=0.04575851730144607,
# left=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# ),
# right=Node(
# feature=None,
# value=1,
# left=None,
# right=None
# )
# ),
# right=Node(
# feature=None,
# value=0,
# left=None,
# right=None
# )
# )Als Bild wäre es das:
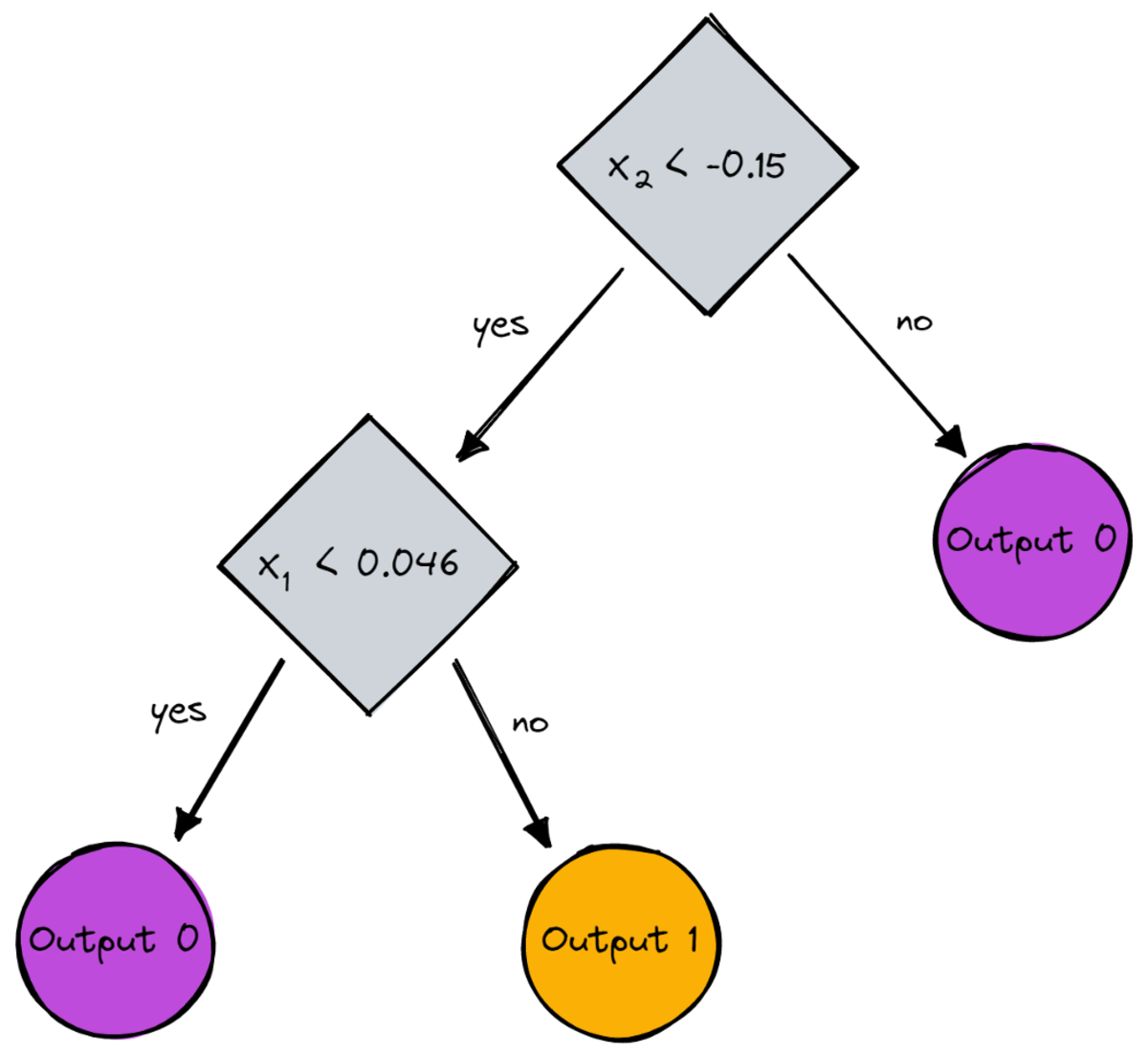
Bild vom Autor
In diesem Artikel haben wir gesehen, wie Entscheidungsbäume im Detail funktionieren. Wir begannen mit einigen vagen, aber intuitiven Ideen und setzten sie in Formeln und Algorithmen um. Am Ende konnten wir einen Entscheidungsbaum von Grund auf implementieren.
Ein Wort der Vorsicht: Unser Entscheidungsbaum kann noch nicht regularisiert werden. Normalerweise möchten wir Parameter wie angeben
- maximale Tiefe
- Blattgröße
- und minimalem Informationsgewinn
unter vielen anderen. Glücklicherweise sind diese Dinge nicht so schwer umzusetzen, was dies zu einer perfekten Hausaufgabe für Sie macht. Zum Beispiel, wenn Sie angeben leaf_size=10 als Parameter, dann sollten Knoten mit mehr als 10 Samples nicht mehr geteilt werden. Auch diese Implementierung ist nicht effizient. Normalerweise möchte man nicht Teile der Datensätze in Knoten speichern, sondern nur die Indizes. Ihr (möglicherweise großer) Datensatz befindet sich also nur einmal im Speicher.
Das Gute ist, dass Sie mit dieser Entscheidungsbaumvorlage jetzt verrückt werden können. Du kannst:
- implementieren diagonale Splits, dh xᵢ + 2xⱼ = 3 statt nur xᵢ = 3,
- Ändern Sie die Logik, die innerhalb der Blätter passiert, dh Sie können eine logistische Regression innerhalb jedes Blattes durchführen, anstatt nur eine Mehrheitsabstimmung durchzuführen, was Ihnen a gibt linearer Baum
- Ändern Sie das Aufteilungsverfahren, dh probieren Sie statt roher Gewalt einige zufällige Kombinationen aus und wählen Sie die beste aus, die Ihnen ein Ergebnis liefert Extra-Baum-Klassifikator
- und mehr.
Dr. Robert Kübler ist Data Scientist bei Publicis Media und Autor bei Towards Data Science.
Original. Mit Genehmigung erneut veröffentlicht.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/02/understanding-implementing-decision-tree.html?utm_source=rss&utm_medium=rss&utm_campaign=understanding-by-implementing-decision-tree

