CCC unterstützte drei wissenschaftliche Sitzungen auf der diesjährigen AAAS-Jahreskonferenz. Falls Sie nicht persönlich teilnehmen konnten, werden wir jede Sitzung noch einmal zusammenfassen. Diese Woche werden wir die Höhepunkte der Sitzung zusammenfassen: „Generative KI in der Wissenschaft: Versprechen und Fallstricke.“ Im dritten Teil fassen wir die Präsentation von Dr. Duncan Watson-Parris, Assistenzprofessor am Scripps Institution of Oceanography und am Halıcıoğlu Data Science Institute an der UC San Diego, zusammen.
Im Anschluss an den Vortrag von Dr. Markus Buehler über generative KI in der Mechanobiologie richtete Dr. Watson-Parris die Aufmerksamkeit des Publikums auf generative KI-Anwendungen in den Klimawissenschaften. Er begann damit, den Unterschied zwischen Klima und Wetter zu skizzieren. Wetter bezieht sich auf kurzfristige atmosphärische Bedingungen, während Klima langfristige atmosphärische Bedingungen beschreibt. Kurz gesagt: Das Klima ist das, was Sie erwarten, das Wetter ist das, was Sie bekommen. „Eines der größten Probleme bei der Klimamodellierung“, sagt Watson-Parris, „ist, dass wir nur über aktuelle Daten aus der Zeit verfügen, als wir mit der Durchführung von Klimamessungen begannen.“ Es ist besonders schwierig, genaue Modelle zu erstellen, die zukünftige Klimamuster und Wetterereignisse vorhersagen, da wir die Ergebnisse in der realen Welt erst überprüfen können, wenn diese Ereignisse eintreten. Für kurzfristigere Vorhersagen, beispielsweise Wettervorhersagen für die nächsten drei Tage, können wir die Genauigkeit dieser Modelle jedoch leicht überprüfen.
Branchenspezifische Wettermodelle sind bereits sehr genau. Diese Modelle sind genauso genau wie die nationalen Wettervorhersagemodelle für kurzfristige Schätzungen (~3-7-Tage-Vorhersagen). Eines der größten Probleme bei der Wettervorhersage ist jedoch die Erfassung der anfänglichen Wetterbedingungen. Wie Dr. Willett in ihrem Vortrag betonte, können bereits geringfügig unterschiedliche Ausgangsbedingungen zu sehr unterschiedlichen Ergebnissen führen. Dies trifft auf Wettersimulationen zu, sagt Dr. Watson-Parris, die wichtige Auswirkungen auf die reale Welt haben können. Das unten gezeigte Wettermuster führte 2017 in der Region Kalifornien und Oregon zu einem atmosphärischen Fluss, der so viel Regen erzeugte, dass der Oroville-Staudamm platzte und Schäden in Millionenhöhe verursachte. Dieses Ereignis war schwer vorherzusagen, da es sich um ein Extremereignis, einen Ausreißer, handelte. Mithilfe maschineller Lernvorhersagen können wir viel größere Mengen an Stichproben durchführen, um extremere Wetterereignisse vorherzusagen und uns so besser auf sie vorzubereiten.
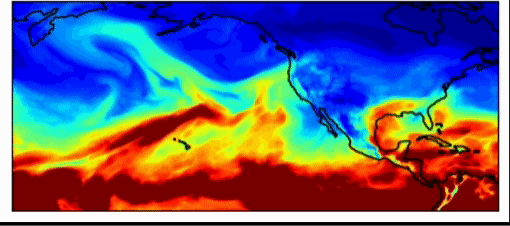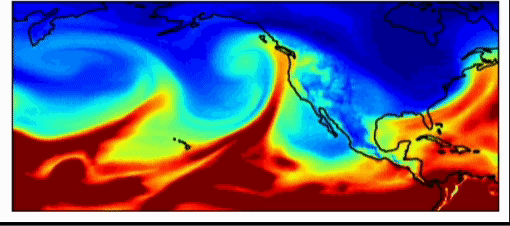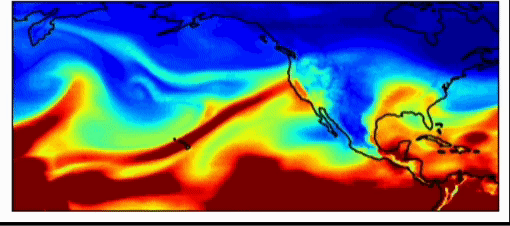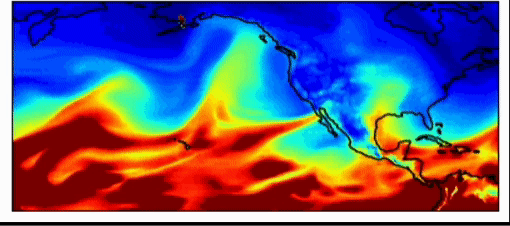
Wenn Forscher über das Klimasystem nachdenken, erklärt Dr. Watson-Parris, und wenn sie größere Maßstäbe und längere Zeiträume betrachten, sehen sie schließlich, wie durchschnittliche Wolken über die Jahreszeiten aussehen, und sie können sich Statistiken von Systemen ansehen. Diese Statistiken werden durch die Randbedingungen des Erdsystems bestimmt – die Menge der ein- und ausgehenden Energie. Wenn das Problem auf diese Weise formuliert wird, können wir im Durchschnitt vorhersagen, wo sich die Wolken während der Jahreszeiten befinden werden, und es gibt Möglichkeiten, maschinelles Lernen zu nutzen, um diese verschiedenen Vorhersagen zu verbessern und zu untersuchen. Eine der Aufgaben von Klimamodellen besteht darin, Prognosen zu erstellen – also zu verstehen, wie sich das Klima in Zukunft unter verschiedenen menschlichen Einflüssen verändern wird. Diese sollen mögliche Zukunftsaussichten erforschen. Um dies zu erreichen, generieren Forscher plausiblere sozioökonomische Pfade für das zukünftige Verhalten der Gesellschaft.
Unten ist ein von Dr. Watson-Parris gezeigtes Bild zu sehen, das einige mögliche zukünftige Entwicklungen in der Gesellschaft darstellt, die in diesen Klimamodellen berücksichtigt werden müssen. Auf der linken Seite befindet sich ein Nachhaltigkeitsmodell, das bis zum Ende des Jahrhunderts den Klimafaktor – also die Erwärmung, die der Mensch dem System zufügt – auf einem niedrigeren Niveau hält. Andererseits ist das Szenario der Entwicklung fossiler Brennstoffe auf der rechten Seite eine Art Worst-Case-Szenario. Dies ist eine sehr spärliche Auswahl an Möglichkeiten, wie die Menschheit das Jahr 2100 erreichen könnte.

In der Praxis trainieren Forscher bei der Entscheidung über das Klimaszenario und bei der Kommunikation mit politischen Entscheidungsträgern, die die Auswirkungen ihrer Entscheidungen verstehen möchten, einfache Klimamodell-Emulatoren. Diese Emulatoren berücksichtigen Prognosen für verschiedene Emissionen wie CO2 und Methan sowie kurzlebige Klimakräfte wie Ruß und Sulfat, und Forscher können die Reaktion dieser Klimamodelle auf der Grundlage von Trainingsdaten emulieren. „Wir können mehr oder weniger komplexe Modelle der globalen Reaktion der globalen Durchschnittstemperatur auf diese Emissionen erstellen“, sagt Watson-Parris. „Diese Modelle funktionieren einigermaßen gut, weil Wissenschaftler ein gutes Verständnis der zugrunde liegenden Physik haben. Aber niemand lebt in der globalen Durchschnittstemperatur, und wir werden alle diese Veränderungen unterschiedlich spüren. Um regionale Veränderungen zu verstehen, nehmen Wissenschaftler daher den globalen Mittelwert und skalieren die Musteränderung auf regionale Situationen. Diese Modelle funktionieren gut, aber sie verlieren die Auswirkungen, die diese Emissionen vor Ort haben könnten. Beispielsweise wird insbesondere Ruß größtenteils in Südasien emittiert, und die Auswirkungen davon werden vor allem in Südasien zu spüren sein.“
Wenn dieses Problem in einer Regressionsumgebung dargestellt wird, sehen wir, dass es möglicherweise Möglichkeiten für maschinelles Lernen gibt. "Im Rahmen des Klimabank In unserem Papier, das wir vor einem Jahr geschrieben haben, sagte Dr. Watson-Parris, sagten wir, wir könnten die Emissionen und Konzentrationen von Treibhausgasen sowie Karten der Emissionen von Sulfat und Ruß nehmen und diese direkt auf die Klimamodelle zurückführen, um Vorhersagen zu erhalten. Wir müssen uns auch nicht auf die Temperatur beschränken, sondern können Niederschlag und andere Variablen berücksichtigen. Auf diese Weise können wir Emulatoren der Klimamodelle erstellen, die vorhersagen, was das Klimamodell bei einer bestimmten Menge an emittiertem CO2 produzieren wird, und es uns ermöglichen, diese Modelle auf einem Laptop statt auf einem Supercomputer auszuführen.“
Dr. Watson-Parris zeigte dann ein Bild von drei verschiedenen Erkenntnissen der globalen Temperaturreaktion in einem zurückhaltenden, mittelmäßigen Szenario der Klimapolitik. Die ersten beiden Spalten sind Emulatoren für maschinelles Lernen und die dritte ist eine Klimamodellsimulation voller Komplexität, die auf einem Supercomputer eine Woche dauerte. „Die Ergebnisse jedes dieser Modelle sind kaum zu unterscheiden“, sagt Watson-Parris. Diese Klimamodelle können dieses Erwärmungsmuster sehr gut genau vorhersagen. Sie leisten sogar gute Arbeit bei der Vorhersage von Niederschlagsmustern. Diese Modelle verbessern die Zugänglichkeit und Beteiligung und ermöglichen es kleineren Organisationen und politischen Entscheidungsträgern, sich an der Klimavorhersage und -erkundung zu beteiligen, ohne dass dafür große Mittel oder Infrastruktur erforderlich sind.

Bei diesen Modellen handelt es sich nicht um generative KI, sondern um reine Regressionsmodelle, und eine bestimmte Eingabe liefert immer das gleiche Ergebnis. Allerdings werden heute Möglichkeiten untersucht, generative und Diffusionsmodelle zu nutzen, um die probabilistischen Verteilungen des Wetters zur Generierung von Wetterzuständen zu nutzen. Forscher verwenden diese Modelle, um das Klima und die Wettermuster der Zukunft unter Berücksichtigung verschiedener Klimaszenarien vorherzusagen. „Schwierigkeiten bleiben bestehen“, sagt Dr. Watson-Parris, „weil es immer noch keine ‚Grundwahrheit‘ zur Überprüfung von Vorhersagen gibt und wir noch herausfinden müssen, wie wir statistische Modelle kalibrieren können, aber das ist die Zukunft der Klimavorhersage, und ich.“ Ich bin optimistisch, dass diese Tools die Zugänglichkeit, Beteiligung und das Verständnis für die Zukunft der Klimawissenschaft verbessern werden.“
Vielen Dank fürs Lesen. Bleiben Sie morgen dran für den letzten Beitrag dieser Blogserie, der den Fragen-und-Antwort-Teil dieses Panels zusammenfasst.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://feeds.feedblitz.com/~/874057523/0/cccblog~CCC-AAAS-Generative-AI-in-Science-Promises-and-Pitfalls-Recap-%e2%80%93-Part-Three/

