
Bild vom Herausgeber
Unternehmen auf der ganzen Welt erwarten zunehmend, dass ihre Entscheidungsprozesse von datengesteuerten Predictive-Analytics-Systemen gestützt werden, oder sollten es zumindest sein. Von rechtzeitigen Investitionen über Fulfillment-Logistik bis hin zur Betrugsprävention werden Daten in immer mehr Arbeitsabläufen genutzt, wobei immer mehr Augen darauf gerichtet sind. Mit anderen Worten, Informationsströme, die oft Data Scientists vorbehalten waren, werden jetzt von Leuten eingesehen – und manipuliert –, die in den dunklen Künsten der Daten weniger versiert sind.
Heutzutage sehen sich relative Datenlaien plötzlich in der Verantwortung, sowohl zu Datenpools beizutragen als auch ihre ML-Analyse zu interpretieren. Dies könnte zu Situationen führen, in denen Ihre Daten Sie anspucken und zischen, anstatt kooperativ zu schnurren. Um das Potenzial von Kratzern durch schlechte Datenhygiene durch Überanpassung oder Schlimmeres zu mindern, springt CatBoost auf den Küchentisch und präsentiert sich eindeutig als die beste Option für viele Branchen.
CatBoost ist ein gradientenverstärkendes ML-System, das sich von anderen GBDTs abhebt, indem es einzigartige Lösungen für die Interpretation von Datenquellen bietet, die sehr kategorisch sind oder fehlende Datenpunkte enthalten. In der Tat hat die API hier ihren Namen von Boosting Categories und nicht von einem katzenartigen Ursprung. Nebeneinander Vergleiche zeigen, dass CatBoost auch XGBoost und LightBGM übertrifft bedeutend in Bezug auf die Vorhersagebereitstellungszeit und Parameter-Tuning-Zeit, während sie in anderen Metriken vergleichbar bleiben.
Unter der Haube erreicht CatBoost dies, indem es die Split-by-Popularity-Methode verwendet, um symmetrische Entscheidungsbäume zu erstellen. Durch das Gruppieren von Merkmalen in einer einzigen Teilung mit nur einem linken und rechten untergeordneten Element werden die erforderliche Verarbeitungsleistung und -zeit im Vergleich zu Bäumen mit untergeordneten Elementen für jedes einzelne Merkmal in einem Satz erheblich reduziert. Diese Merkmale können kategorisch oder numerisch sein. Sie können dann auf verschiedenen Ebenen des Baums analysiert werden, bis die Zielvariable erfüllt ist. Dadurch werden die Daten effektiv reguliert und Datenpunkte davon abgehalten, explizite Korrelationen zu entwickeln, indem mehrere Sichtweisen auf dieselben Teilmengen angeboten werden. Dies verleiht den Vorhersagen von CatBoost mehr Widerstandsfähigkeit gegenüber Überanpassungs- und Generalisierungsfehlern im Trainingsprozess.
Während diese Punkte aus datenwissenschaftlicher und rechnerischer Sicht offensichtlich vorteilhaft sind, sind ihre Vorteile für eine gesamte Organisation möglicherweise weniger offensichtlich.
Es begrüßt Sie also nicht mit Ihren Hausschuhen, wenn Sie zu Hause ankommen, es erwidert die Sorgfalt und Aufmerksamkeit, die Sie ihm entgegenbringen, nicht auf liebevolle Weise. Wie genau verbessert CatBoost also Ihren Betrieb? Wie hilft die Recheneffizienz von CatBoost tatsächlich bei wesentlichen Geschäftsfunktionen und für wen? Es gibt bestimmte Elemente des CatBoost-Algorithmus, die im Vergleich zu ähnlichen ML-Systemen wie kleine Unterschiede erscheinen, sich aber für viele Unternehmen in enorme logistische Dividenden umwandeln.
Wir werden auf mehrere solcher Komponenten zoomen und dann wieder herauszoomen, um zu sehen, wie ihre realen Implementierungen dazu beitragen, Prozesse zu rationalisieren und letztendlich Geld zu sparen – Geld sparen ist eine Sprache, die jeder im Unternehmen spricht. Unternehmen erkennen möglicherweise, dass einige ihrer granularen Schmerzpunkte angegangen werden, während wir sie untersuchen, insbesondere wenn sie zerkratzt oder sogar vernarbt sind.
Für jede dieser Nuancen innerhalb der Open-Source-API gibt es praktische Vorteile, die für Data Scientists sofort offensichtlich sind. Für die zunehmende Zahl von Nicht-Tech-Teams, die gebeten werden, an der Datenanalysekette ihrer Unternehmen teilzunehmen, sowie für die Personen, deren Aufgabe es ist, ML-Workflows zu genehmigen, ist dies entschieden weniger offensichtlich.
1: Keine One-Hot-Codierung erforderlich
CatBoost verarbeitet kategoriale Merkmale im Klartext und vermeidet die Notwendigkeit einer umfangreichen Vorverarbeitung, wie bei anderen GBDTs, die auf numerischen Eingaben bestehen. Die gebräuchlichste Vorverarbeitungsmethode für kategoriale Daten ist die Kennzeichnung durch One-Hot-Codierung, die Daten in eine Binärdatei zerlegt, obwohl in einigen Fällen je nach Art die Verwendung einer Dummy-, Ordinal-, LOO- oder Bayes'schen Zielcodierungsmethode besser geeignet ist die Daten. Über One-Hot-Codierung vorverarbeitete kategoriale Merkmale können oft umfangreich sein und schnell übermäßig dimensional werden. Durch das eingebaute Ordinalcodierungssystem von CatBoost wird kategorialen Merkmalen ein numerischer Wert zugewiesen, aber die langen Verarbeitungszeiten und Überanpassungsmerkmale von hochdimensionalen Daten werden vermieden.
Obwohl diese Berechnungen möglicherweise in der Cloud durchgeführt werden, umfassen die Vorteile vor Ort:
- Da die API textbasierte kategoriale Daten nativ verarbeitet, sind weniger Berechnungen und weniger Transformationen der Daten erforderlich, was zu weniger Fehlern führt.
- Im Vergleich zur One-Hot-Codierung zerlegt CatBoost Daten in weniger Funktionen, was die Einfachheit und letztendlich die Interpretierbarkeit für Analystenteams erhöht.
- Textbasierte Daten, die in die Bibliothek eingespeist werden, werden mit demselben Textlabel zurückgegeben, wodurch auch die Interpetabilität optimiert wird.
- CatBoost erleichtert die Tiefenanalyse, indem es die Fokussierung auf den Beitrag eines einzelnen Merkmals zum Modell erleichtert, anstatt auf einen bestimmten Wert eines bestimmten Merkmals, wie es bei One-Hot-codierten Spalten der Fall ist. Mit der get_feature_importance()-Methode misst CatBoost die Merkmale anhand von SHAP-Werten, die auch zur Interpretation und Analyse einfach visualisiert werden können (siehe unten).
- Aus dem gleichen Grund ermöglicht diese Verwendung von kategorialen Daten Mitarbeitern aus allen Abteilungen die Möglichkeit, Daten viel einfacher einzugeben und zu interpretieren.
- Dieses Maß an Zugänglichkeit ermöglicht es Unternehmen, einheitliche Datenströme zu haben, sodass alle Bereiche des Unternehmens auf einen einzigen Informationspool verweisen. Unternehmen, die von gebissen wurden abteilungsübergreifende Verwirrung von mehreren Profilen einer einzelnen Entität wissen, wie viel Stress und Ressourcen dies sparen kann.
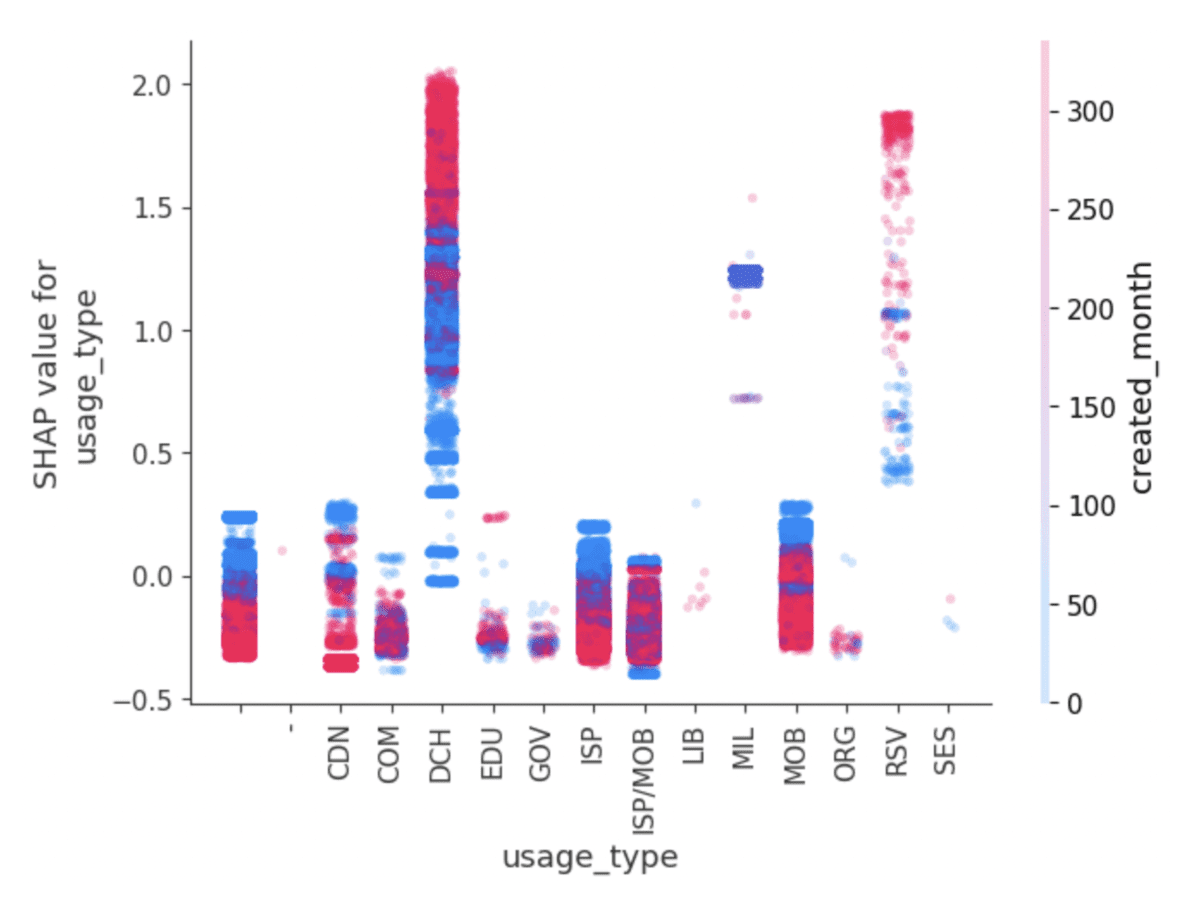
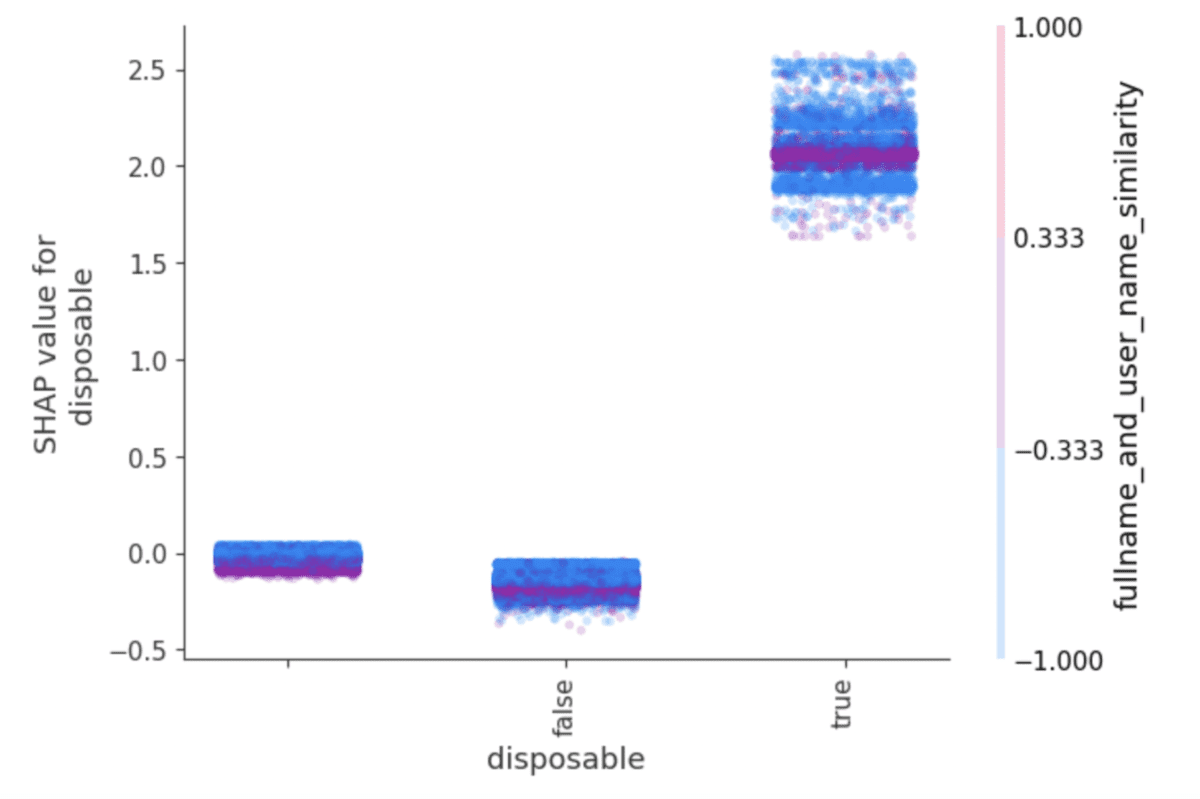
CatBoost hostet nativ die SHAP-Bibliothek und erleichtert Ausgabevisualisierungen wie diese, die anhand von Betrugspräventionsdaten trainiert wurden.
Dieser Aspekt der API von CatBoost ist ein offensichtlicher Vorteil für Branchen, die mit Daten arbeiten, die von Natur aus weniger numerisch sind als beispielsweise Finanzprognosen. Bereiche wie medizinische Diagnose, Betrugsprävention, Marktsegmentierung und Werbung sind alles Bereiche, die mit großen Mengen an kategorialen Daten zu tun haben und von den geschickten Klauen von CatBoost im Umgang damit profitieren würden.
2: Vergessene Bäume
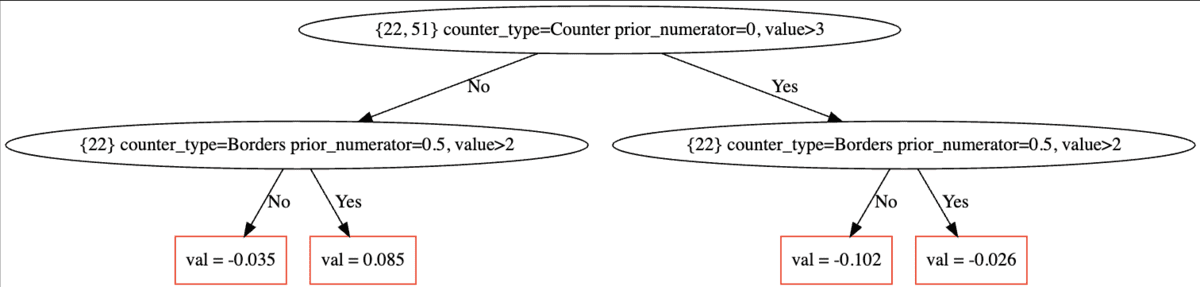
CatBoost nutzt vergessliche Entscheidungsbäume als Basislerner in seinem Gradienten-Boosting-Prozess. Das bedeutet, dass jeder Baum auf eine einzelne symmetrische Teilung beschränkt ist, wobei beide Seiten durch die integrierte Merkmalswichtigkeitsmessung des Algorithmus ausgeglichen werden.
Anstatt wie bei XGBoost Knoten für ein hochdimensionales Merkmal mehrfach aufzuteilen, erstellt CatBoost stattdessen mehrere Ebenen, um ein einzelnes Merkmal zu analysieren. Dies gibt ihm die Fähigkeit zu glänzen, wenn es um Folgendes geht:
- Optimierung von Verarbeitungszeit und Leistung. Hochdimensionale nicht-numerische Daten erfordern unweigerlich mehr Verarbeitungszeit und Leistung, wenn sie durch XGBoost im Vergleich zu CatBoost geschoben werden. Eine einzelne Aufteilung in jedem Knoten bedeutet eine deutlich schnellere Verarbeitungsgeschwindigkeit für jede Entscheidung, eine Reduzierung des Energieverbrauchs und eine Optimierung der Wartezeiten, intern oder extern.
- Regularisierung und Robustheit gegen Overfitting. Algorithmen, die Merkmale nehmen und Bäume in alle möglichen Ergebnisse dieses Merkmals aufteilen, werden häufig eine Überanpassung ihrer Daten bemerken. Durch die Begrenzung der Komplexität jeder Ebene des Baums wird im Wesentlichen eine starrere Regressionslinie durch Ihre Daten erstellt, eine Art De-facto-Regularisierung. Dies führt zu weniger falsch negativen und falsch positiven Ergebnissen, was sich darauf auswirken kann, wie Ihr Unternehmen seine Daten auf vielfältige Weise verwendet.
- Einfache Interpretierbarkeit. Auch hier kann es je nach Branche und automatisiertem Prozess einen guten Grund geben, erklären zu können, wie eine bestimmte ML-Bestimmung durchgeführt wurde. Dies kann der Zufriedenheit eines Kunden dienen, kann aber auch Teil der Einhaltung gesetzlicher Vorschriften sein, wenn es darum geht, transparent faire Praktiken zu haben oder eine Sicherheits-Due-Diligence durchzuführen.
Das vergessliche Baummodell von CatBoost verleiht ihm den größten Teil seiner Verarbeitungsleichtigkeit und macht es auch zu einer hochskalierbaren Option für große Datensätze. Beim Umgang mit kategorialen Daten ist CatBoost viel effizienter darin, schnell Schlussfolgerungen zu ziehen und gleichzeitig Datenrauschen zu ignorieren. In den Bereichen Marktsegmentierung, automatisierte Lieferkettenoptimierung, PPC-Werbung beispielsweise sind verrauschte Daten manchmal der Grund, warum eine scheinbar zufällige Werbung auf Ihr Gerät ausgerichtet wird oder eine Ladenkette zu viel oder zu wenig von etwas hat.
3: Daten „Nan-Handhabung“
Datensätze mit fehlenden Werten sind natürlich weniger nützlich für die Analyse im Allgemeinen. Wenn Sie sich numerischen Datensätzen nähern, ersetzt CatBoost die fehlenden Werte automatisch, anstatt dass diese fehlenden Werte die Stabilität des Modells beeinträchtigen. Abhängig von der Größe der Teilmenge wird der Wert entweder durch einfache Berechnungen oder durch maschinelles Lernen abgeleitete Beziehungen zwischen Merkmalen ersetzt. Diese Beziehungen sind vielleicht nur grenzwertig erklärbar, aber die erklärbaren Vorteile in tatsächlichen Arbeitsprozessen umfassen:
- Bessere Leistung in Bezug auf Genauigkeit und Fehlalarmraten, die überall dort, wo Daten von CatBoost analysiert werden, zu reibungsloseren Prozessen führen.
- Im Fall der Betrugsprävention können Nullwerte selbst als Indikatoren für potenzielle Risiken nützlich sein.
- Ermöglicht maßgeschneiderte Modelle für einzelne Kunden, da jeder unterschiedliche Prozesse und unterschiedliche Daten und Nan-Verhältnisse (Rate von Not-a-Number-Einträgen in Datensätzen) haben wird.
- Andere Branchen wie Gesundheitswesen, Bankwesen, Kundenanalyse und Lieferkettenmanagement nutzen die Nan-Handhabung gut – ziehen Sie in Betracht, wo immer jemand in der Dateneingabekette, von Neukunden bis hin zu Erfüllungsagenten, dazu neigen könnte nicht einen Teil eines Formulars ausfüllen. Manchmal könnte dies Faulheit sein, manchmal könnte es darauf hindeuten versuchter Bewerbungsbetrug.
Insbesondere verarbeitet CatBoost nur numerische Daten und verarbeitet sie nativ. Für kategoriale Daten sollte eine eigene Kategorie im Sinne von „leerer String“ oder „fehlender Wert“ gebildet werden, damit diese NaN-Werte im symmetrischen Split berücksichtigt werden.
Hier ist ein Beispiel für die einfache Handhabung der nan-Werte in kategorialen Daten:
for col in df.columns: if df[col].dtype.name in ("bool", "object", "category"): if (df[col].dtype.name == "category" and ("" not in df[col].cat.categories)): df[col] = df[col].cat.add_categories([""]) df[col] = df[col].fillna("")4: Parallelverarbeitung (Zoomies)
Wie oben erwähnt, ist die einzelne, symmetrische Teilung von CatBoost sehr vorteilhaft für die Verarbeitungsleistung und Vorhersagegeschwindigkeit.
Dafür gibt es zwei Hauptgründe. Die erste ist die Fähigkeit der symmetrischen Baumstruktur, eine Vorhersage zu erreichen Vektormultiplikation. Wo andere Bibliotheken zur Steigerung des Gradienten diese Berechnungen auf jeder Ebene des Baums durchführen würden, kann CatBoost sie auf den gesamten Baum anwenden und so die Vorhersagegenerierung drastisch beschleunigen.
Die zweite Erklärung für die Geschwindigkeit von CatBoost ist die Funktion zum Sortieren nach Beliebtheit, die dimensionale Daten nimmt und sie in zwei gleiche Zweige gruppiert, anstatt für jede Funktion einen möglichen Zweig zu erstellen. Natürlich benötigt ein einzelner Split weniger Energie zum Navigieren als 5, aber diese Art der Organisation bietet sich einfach an Parallelverarbeitung - Aufteilen von Daten in Teilmengen, um die Aufgabe auf mehrere Prozessoren aufzuteilen. Abhängig von den verfügbaren Hardware-Ressourcen kann CatBoost auch die optimale Methode der Parallelverarbeitung finden.
Abgesehen von den offensichtlichen Vorteilen eines geringeren Energieverbrauchs und schnellerer Gesamtprozesse sollten Sie einige Möglichkeiten berücksichtigen, wie Kunden- und Partnererlebnisse durch ineffiziente Datenverarbeitung beeinträchtigt werden können:
- Interne Arbeitsabläufe sind oft mit kleinen Wartezeiten behaftet, die sich zu größeren ausweiten können. Wir alle wissen das.
- Kleine Wartezeiten für Risikoanalysen, Betrugsprävention, Altersüberprüfung und andere Sicherheitsmaßnahmen können ein Online-Erlebnis beeinträchtigen oder beeinträchtigen. Die Abwanderung steigt offensichtlich mit den Wartezeiten mit hoher Reibung.
5: Niedlichkeitsfaktor
CatBoost ist im Vergleich zu ähnlichen ML-Algorithmen ziemlich liebenswert. Unabhängig vom Niveau des maschinellen Lernens oder der Datenexpertise ist die API mit ihrer klaren und verständlichen Dokumentation erlernbar. Betrachten Sie diese Funktionen zusammen:
- Erklärt Hypertuning-Parameter, um zu verstehen, welches spezifische Problem gelöst wird
- Verarbeitet automatisch kategoriale Daten, einschließlich der Vorverarbeitung
- Verfügt über ein robustes Modell, das im Allgemeinen sofort bereitgestellt werden kann
- Erweiterte Visualisierungen
from catboost import CatBoostRegressor
from sklearn.datasets import load_boston
boston_data = load_boston()
model = CatBoostRegressor( depth=2, verbose=False, iterations=1).fit( boston_data['data'], boston_data['target'])
Der obige Codeblock zeigt, wie sauber und einfach ein CatBoost-Modell auf einem Boston-Datensatz trainiert werden kann. Dies ist ein gutes Beispiel dafür, wie CatBoost eine zugänglichere Umgebung schafft als manche andere, insbesondere angesichts der großen und aktiven Community rund um das Produkt.
Die Vorteile dieser Herangehensweise sollten klar sein, insbesondere für Personen mit Erfahrung beim Einstieg in neue Teile fortschrittlicher Unternehmenssoftware. Im Allgemeinen ist es möglich, ein breiteres Spektrum an Teammitgliedern einzubeziehen Datenprozesse ohne sie abzuschrecken, ist wertvoll für die Verteilung von Verantwortlichkeiten und die Optimierung der Ressourcenverteilung.
Obwohl es mit Geschwindigkeit und Effizienz speziell für kategoriale Daten entwickelt wurde, verarbeitet CatBoost numerische Daten mit der gleichen Geschicklichkeit. Allerdings gibt es einige Bereiche, die mit XGBoost oder LightGBM sicherlich genauso gut geeignet sein könnten. Diese beiden Algorithmen wurden im Hinblick auf Geschwindigkeit und Skalierbarkeit entwickelt, einschließlich rein numerischer Daten, die hochdimensional sind und sich ständig ändern. Branchen, die sich mit sehr großen Datensätzen befassen, die von Natur aus vollständig und im Fluss sind, können mit einer dieser beiden APIs besser abschneiden, wie zum Beispiel:
- Finanzprognose
- Energieverteilung
- Leitung der Lieferkette
Insbesondere LightGBM gedeiht dort, wo die Verarbeitungsgeschwindigkeit entscheidend ist, wie z. B. bei der Verarbeitung natürlicher Sprache und der Bilderkennung.
Da Daten in den Geschäftsfunktionen eines zunehmend digitalisierten Unternehmensbereichs immer allgegenwärtiger werden, müssen Datenlösungen leichter zugänglich sein. Branchen wie Werbung, Marktanalyse, Kundensegmentierung, Betrugsprävention und medizinische Behandlung, CatBoost passt wahrscheinlich gut zusammen. Auch viele Arten von Finanzen. Obwohl es vielleicht nie so zugänglich ist wie eine echte Hauskatze, kann CatBoost in vielen Fällen freundlicher und sicherlich nützlicher sein.
Gellért Nacsa ist Data Science Lead bei SEON. Er studierte Angewandte Mathematik an der Universität und arbeitete als Datenanalyst, Algorithmus-Designer und Datenwissenschaftler. Er spielt gerne mit Daten, maschinellem Lernen und lernt ständig neue Dinge.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/2023/02/top-5-advantages-catboost-ml-brings-data-make-purr.html?utm_source=rss&utm_medium=rss&utm_campaign=top-5-advantages-that-catboost-ml-brings-to-your-data-to-make-it-purr

