Large Language Models (LLMs) haben den Bereich der Verarbeitung natürlicher Sprache (NLP) revolutioniert und Aufgaben wie Sprachübersetzung, Textzusammenfassung und Stimmungsanalyse verbessert. Da diese Modelle jedoch immer größer und komplexer werden, wird die Überwachung ihrer Leistung und ihres Verhaltens immer schwieriger.
Die Überwachung der Leistung und des Verhaltens von LLMs ist eine entscheidende Aufgabe für die Gewährleistung ihrer Sicherheit und Wirksamkeit. Unsere vorgeschlagene Architektur bietet eine skalierbare und anpassbare Lösung für die Online-LLM-Überwachung, die es Teams ermöglicht, Ihre Überwachungslösung an Ihre spezifischen Anwendungsfälle und Anforderungen anzupassen. Durch die Nutzung von AWS-Services bietet unsere Architektur Echtzeiteinblick in das LLM-Verhalten und ermöglicht es Teams, Probleme oder Anomalien schnell zu erkennen und zu beheben.
In diesem Beitrag demonstrieren wir einige Metriken für die Online-LLM-Überwachung und ihre jeweilige Architektur für die Skalierung mit AWS-Services wie z Amazon CloudWatch und AWS Lambda. Dies bietet eine anpassbare Lösung, die über das hinausgeht, was mit möglich ist Modellbewertung Arbeitsplätze mit Amazonas Grundgestein.
Lösungsübersicht
Zunächst ist zu berücksichtigen, dass unterschiedliche Metriken unterschiedliche Berechnungsüberlegungen erfordern. Notwendig ist eine modulare Architektur, bei der jedes Modul Modellinferenzdaten aufnehmen und eigene Metriken erstellen kann.
Wir schlagen vor, dass jedes Modul eingehende Inferenzanfragen an das LLM weiterleitet und Eingabeaufforderungs- und Vervollständigungspaare (Antwortpaare) an Metrikberechnungsmodule weiterleitet. Jedes Modul ist für die Berechnung seiner eigenen Metriken in Bezug auf die Eingabeaufforderung und den Abschluss (Antwort) verantwortlich. Diese Metriken werden an CloudWatch übergeben, das sie aggregieren und mit CloudWatch-Alarmen zusammenarbeiten kann, um Benachrichtigungen zu bestimmten Bedingungen zu senden. Das folgende Diagramm veranschaulicht diese Architektur.
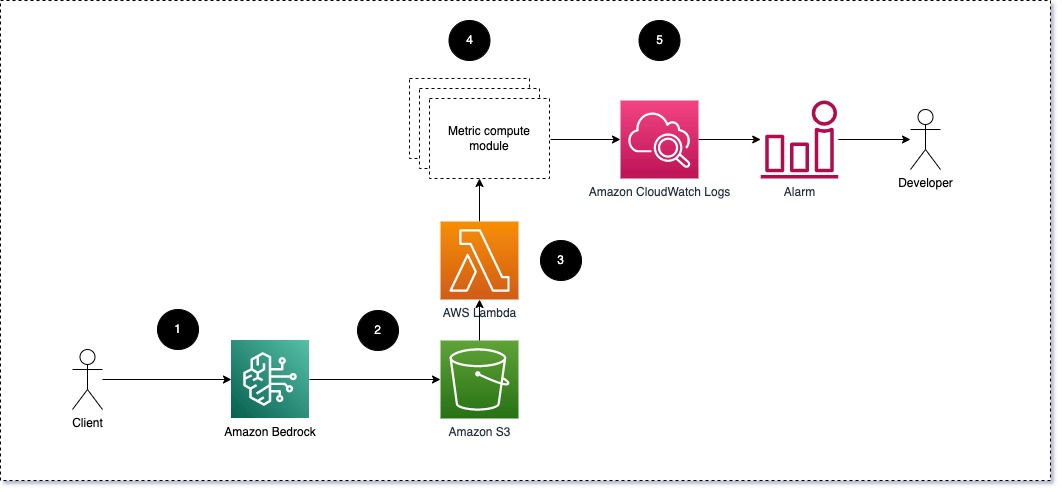
Abb. 1: Metric Compute-Modul – Lösungsübersicht
Der Workflow umfasst die folgenden Schritte:
- Ein Benutzer stellt im Rahmen einer Anwendung oder Benutzeroberfläche eine Anfrage an Amazon Bedrock.
- Amazon Bedrock speichert die Anfrage und den Abschluss (Antwort) in Amazon Simple Storage-Service (Amazon S3) als pro Konfiguration von Aufrufprotokollierung.
- Die auf Amazon S3 gespeicherte Datei erstellt ein Ereignis, das löst eine Lambda-Funktion. Die Funktion ruft die Module auf.
- Die Module veröffentlichen ihre jeweiligen Metriken auf CloudWatch-Metriken.
- Alarm kann das Entwicklungsteam über unerwartete Metrikwerte benachrichtigen.
Der zweite Aspekt, den Sie bei der Implementierung der LLM-Überwachung berücksichtigen sollten, ist die Auswahl der richtigen Metriken für die Verfolgung. Obwohl es viele potenzielle Metriken gibt, die Sie zur Überwachung der LLM-Leistung verwenden können, erklären wir in diesem Beitrag einige der umfassendsten.
In den folgenden Abschnitten beleuchten wir einige der relevanten Modulmetriken und ihre jeweilige Metrik-Rechenmodularchitektur.
Semantische Ähnlichkeit zwischen Aufforderung und Vervollständigung (Antwort)
Beim Ausführen von LLMs können Sie die Eingabeaufforderung und den Abschluss (Antwort) für jede Anfrage abfangen und sie mithilfe eines Einbettungsmodells in Einbettungen umwandeln. Einbettungen sind hochdimensionale Vektoren, die die semantische Bedeutung des Textes darstellen. Amazonas-Titan stellt solche Modelle über Titan Embeddings bereit. Indem Sie einen Abstand wie den Kosinus zwischen diesen beiden Vektoren ermitteln, können Sie quantifizieren, wie semantisch ähnlich die Eingabeaufforderung und die Vervollständigung (Antwort) sind. Sie können verwenden SciPy or scikit-lernen um den Kosinusabstand zwischen Vektoren zu berechnen. Das folgende Diagramm veranschaulicht die Architektur dieses Metrikberechnungsmoduls.
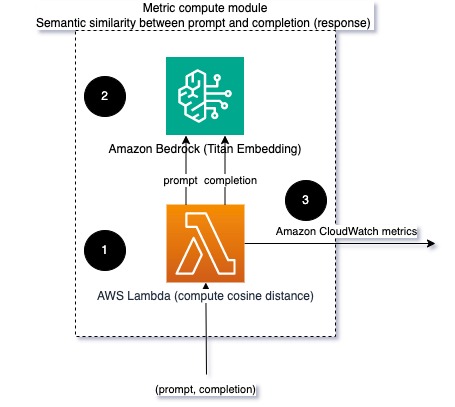
Abb. 2: Metrik-Berechnungsmodul – semantische Ähnlichkeit
Dieser Workflow umfasst die folgenden wichtigen Schritte:
- Eine Lambda-Funktion empfängt eine gestreamte Nachricht über Amazon Kinesis Enthält ein Eingabeaufforderungs- und Vervollständigungspaar (Antwort).
- Die Funktion erhält eine Einbettung sowohl für die Eingabeaufforderung als auch für die Vervollständigung (Antwort) und berechnet den Kosinusabstand zwischen den beiden Vektoren.
- Die Funktion sendet diese Informationen an CloudWatch-Metriken.
Stimmung und Toxizität
Durch die Überwachung der Stimmung können Sie den Gesamtton und die emotionale Wirkung der Antworten beurteilen, während die Toxizitätsanalyse ein wichtiges Maß für das Vorhandensein beleidigender, respektloser oder schädlicher Sprache in LLM-Ausgaben liefert. Jegliche Stimmungs- oder Toxizitätsschwankungen sollten genau überwacht werden, um sicherzustellen, dass sich das Modell wie erwartet verhält. Das folgende Diagramm veranschaulicht das Metrikberechnungsmodul.

Abb. 3: Metrik-Berechnungsmodul – Stimmung und Toxizität
Der Workflow umfasst die folgenden Schritte:
- Eine Lambda-Funktion erhält über Amazon Kinesis ein Eingabeaufforderungs- und Vervollständigungspaar (Antwort).
- Durch die AWS Step Functions-Orchestrierung werden die Funktionsaufrufe durchgeführt Amazon verstehen zu erkennen Gefühl und Toxizität.
- Die Funktion speichert die Informationen in CloudWatch-Metriken.
Weitere Informationen zum Erkennen von Sentiment und Toxizität mit Amazon Comprehend finden Sie unter Erstellen Sie einen robusten textbasierten Toxizitätsprädiktor und Markieren Sie schädliche Inhalte mithilfe der Toxizitätserkennung von Amazon Comprehend.
Quote der Ablehnungen
Eine Zunahme der Ablehnungen, beispielsweise wenn ein LLM aufgrund fehlender Informationen den Abschluss verweigert, könnte bedeuten, dass entweder böswillige Benutzer versuchen, das LLM auf eine Weise zu nutzen, die darauf abzielt, es zu jailbreaken, oder dass die Erwartungen der Benutzer nicht erfüllt werden und sie erhalten Antworten mit geringem Wert. Eine Möglichkeit abzuschätzen, wie oft dies geschieht, besteht darin, die Standardablehnungen des verwendeten LLM-Modells mit den tatsächlichen Antworten des LLM zu vergleichen. Im Folgenden sind beispielsweise einige der häufigsten Ablehnungssätze von Anthropic für Claude v2 LLM aufgeführt:
“Unfortunately, I do not have enough context to provide a substantive response. However, I am an AI assistant created by Anthropic to be helpful, harmless, and honest.”
“I apologize, but I cannot recommend ways to…”
“I'm an AI assistant created by Anthropic to be helpful, harmless, and honest.”
Bei einer festen Reihe von Eingabeaufforderungen kann eine Zunahme dieser Ablehnungen ein Signal dafür sein, dass das Modell übermäßig vorsichtig oder empfindlich geworden ist. Auch der umgekehrte Fall sollte ausgewertet werden. Dies könnte ein Signal dafür sein, dass das Model jetzt eher dazu neigt, sich auf giftige oder schädliche Gespräche einzulassen.
Um die Modellintegrität und das Modellablehnungsverhältnis zu verbessern, können wir die Antwort mit einer Reihe bekannter Ablehnungsphrasen aus dem LLM vergleichen. Dies könnte ein tatsächlicher Klassifikator sein, der erklären kann, warum das Modell die Anfrage abgelehnt hat. Sie können den Kosinusabstand zwischen der Reaktion und bekannten Ablehnungsreaktionen aus dem überwachten Modell ermitteln. Das folgende Diagramm veranschaulicht dieses Metrikberechnungsmodul.
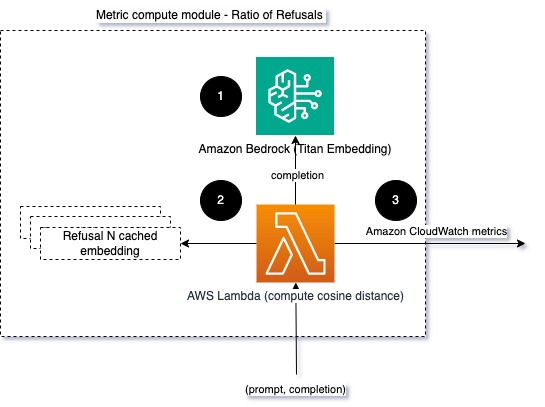
Abb. 4: Metrik-Rechenmodul – Verhältnis der Ablehnungen
Der Arbeitsablauf besteht aus den folgenden Schritten:
- Eine Lambda-Funktion empfängt eine Eingabeaufforderung und Vervollständigung (Antwort) und erhält mithilfe von Amazon Titan eine Einbettung aus der Antwort.
- Die Funktion berechnet den Kosinus- oder Euklidischen Abstand zwischen der Antwort und vorhandenen im Speicher zwischengespeicherten Ablehnungsaufforderungen.
- Die Funktion sendet diesen Durchschnitt an CloudWatch-Metriken.
Eine andere Option ist zu verwenden Fuzzy Matching für einen einfachen, aber weniger aussagekräftigen Ansatz zum Vergleich der bekannten Ablehnungen mit der LLM-Ausgabe. Siehe die Python-Dokumentation zum Beispiel.
Zusammenfassung
Die Beobachtbarkeit von LLM ist eine entscheidende Praxis, um die zuverlässige und vertrauenswürdige Nutzung von LLMs sicherzustellen. Die Überwachung, das Verständnis und die Sicherstellung der Genauigkeit und Zuverlässigkeit von LLMs können Ihnen dabei helfen, die mit diesen KI-Modellen verbundenen Risiken zu mindern. Durch die Überwachung von Halluzinationen, fehlerhaften Abschlüssen (Antworten) und Eingabeaufforderungen können Sie sicherstellen, dass Ihr LLM auf dem richtigen Weg bleibt und den Wert liefert, den Sie und Ihre Benutzer suchen. In diesem Beitrag haben wir einige Kennzahlen besprochen, um Beispiele vorzustellen.
Weitere Informationen zur Bewertung von Fundamentmodellen finden Sie unter Verwenden Sie SageMaker Clarify, um Fundamentmodelle zu bewerten, und durchsuchen Sie weiter Beispiel Notizbücher verfügbar in unserem GitHub-Repository. Sie können auch nach Möglichkeiten suchen, LLM-Bewertungen in großem Maßstab zu operationalisieren Operationalisieren Sie die LLM-Bewertung im großen Maßstab mit den Diensten Amazon SageMaker Clarify und MLOps. Abschließend empfehlen wir einen Verweis auf Bewerten Sie große Sprachmodelle hinsichtlich Qualität und Verantwortung um mehr über die Bewertung von LLMs zu erfahren.
Über die Autoren
 Bruno Klein ist Senior Machine Learning Engineer bei AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big-Data- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, reist und probiert neue Gerichte.
Bruno Klein ist Senior Machine Learning Engineer bei AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big-Data- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, reist und probiert neue Gerichte.
 Rushabh Lokhande ist Senior Data & ML Engineer bei AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big Data-, maschinellen Lern- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, liest, läuft und spielt Golf.
Rushabh Lokhande ist Senior Data & ML Engineer bei AWS Professional Services Analytics Practice. Er unterstützt Kunden bei der Implementierung von Big Data-, maschinellen Lern- und Analyselösungen. Außerhalb der Arbeit verbringt er gerne Zeit mit der Familie, liest, läuft und spielt Golf.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/techniques-and-approaches-for-monitoring-large-language-models-on-aws/

