Einleitung
Im Bereich der künstlichen Intelligenz haben Large Language Models (LLMs) und generative KI-Modelle wie GPT-4 von OpenAI, Claude 2 von Anthropic, Llama von Meta, Falcon, Palm von Google usw. die Art und Weise, wie wir Probleme lösen, revolutioniert. LLMs verwenden Deep-Learning-Techniken, um Aufgaben zur Verarbeitung natürlicher Sprache auszuführen. In diesem Artikel erfahren Sie, wie Sie LLM-Apps mithilfe einer Vektordatenbank erstellen. Möglicherweise haben Sie mit einem Chatbot wie dem Amazon-Kundendienst oder dem Flipkart Decision Assistant interagiert. Sie generieren menschenähnlichen Text und bieten ein interaktives Benutzererlebnis, das von echten Gesprächen kaum zu unterscheiden ist. Dennoch müssen diese LLMs optimiert werden, damit sie hochrelevante und spezifische Ergebnisse liefern, die für bestimmte Anwendungsfälle wirklich nützlich sind.

Wenn Sie beispielsweise fragen: „Wie ändere ich meine Sprache in der Android-App?“ Wenn Sie der Amazon-Kundendienst-App antworten, wurde diese möglicherweise nicht auf genau diesen Text geschult und kann daher möglicherweise nicht antworten. Hier kommt eine Vektordatenbank zum Einsatz. Eine Vektordatenbank speichert die Domänentexte (in diesem Fall Hilfedokumente) und frühere Anfragen aller Benutzer, einschließlich Bestellhistorie usw., als numerische Einbettungen und ermöglicht eine Suche nach ähnlichen Vektoren in Echtzeit. In diesem Fall kodiert es diese Abfrage in einen numerischen Vektor und verwendet ihn, um eine Ähnlichkeitssuche in seiner Vektordatenbank durchzuführen und seine nächsten Nachbarn zu finden. Mit dieser Hilfe kann der Chatbot den Benutzer korrekt zum Abschnitt „Ändern Sie Ihre Spracheinstellung“ in der Amazon-App führen.
Lernziele
- Wie funktionieren LLMs, welche Einschränkungen haben sie und warum benötigen sie Vektordatenbanken?
- Einführung in das Einbetten von Modellen und deren Codierung und Verwendung in Anwendungen.
- Erfahren Sie, was eine Vektordatenbank ist und wie sie Teil der LLM-Anwendungsarchitektur ist.
- Erfahren Sie, wie Sie LLM-/generative KI-Anwendungen mithilfe von Vektordatenbanken und Tensorflow programmieren.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was sind LLMs?
Large Language Models (LLMs) sind grundlegende Modelle für maschinelles Lernen, die Deep-Learning-Algorithmen verwenden, um natürliche Sprache zu verarbeiten und zu verstehen. Diese Modelle werden mit riesigen Mengen an Textdaten trainiert, um Muster und Entitätsbeziehungen in der Sprache zu lernen. LLMs können viele Arten von Sprachaufgaben ausführen, z. B. Sprachen übersetzen, Stimmungen analysieren, Chatbot-Gespräche und mehr. Sie können komplexe Textdaten verstehen, Entitäten und Beziehungen zwischen ihnen erkennen und neuen Text generieren, der kohärent und grammatikalisch korrekt ist.
Lesen Sie mehr über LLMs hier.
Wie funktionieren LLMs?
LLMs werden unter Verwendung einer großen Datenmenge, oft Terabytes oder sogar Petabytes, mit Milliarden oder Billionen von Parametern trainiert, sodass sie basierend auf den Eingabeaufforderungen oder Abfragen des Benutzers relevante Antworten vorhersagen und generieren können. Sie verarbeiten Eingabedaten durch Worteinbettungen, Selbstaufmerksamkeitsebenen und Feedforward-Netzwerke, um aussagekräftigen Text zu generieren. Erfahren Sie mehr über LLM-Architekturen hier.
Einschränkungen von LLMs
Während LLMs scheinbar sogar Antworten mit recht hoher Genauigkeit generieren better als Menschen in vielen standardisierten Tests, diese Modelle haben immer noch Einschränkungen. Erstens verlassen sie sich ausschließlich auf ihre Trainingsdaten, um ihre Argumentation aufzubauen, und daher fehlen möglicherweise spezifische oder aktuelle Informationen in den Daten. Dies führt dazu, dass das Modell falsche oder ungewöhnliche Reaktionen erzeugt, auch bekannt als „Halluzinationen“. Es gab eine laufende Anstrengung um dies abzumildern. Zweitens verhält oder reagiert das Modell möglicherweise nicht in einer Weise, die den Erwartungen des Benutzers entspricht.
Um diesem Problem zu begegnen, erweitern Vektordatenbanken und Einbettungsmodelle das Wissen über LLMs/generative KI, indem sie zusätzliche Suchvorgänge für ähnliche Modalitäten (Text, Bild, Video usw.) bereitstellen, für die der Benutzer Informationen sucht. Hier ist ein Beispiel, bei dem LLMs nicht über die vom Benutzer angeforderte Antwort verfügen und sich stattdessen auf eine Vektordatenbank verlassen, um diese Informationen zu finden.

LLMs und Vektordatenbanken
Large Language Models (LLMs) werden in vielen Bereichen der Industrie genutzt oder integriert, beispielsweise im E-Commerce, im Reisewesen, bei der Suche, bei der Inhaltserstellung und im Finanzwesen. Diese Modelle basieren auf einem relativ neueren Datenbanktyp, der sogenannten Vektordatenbank, die eine numerische Darstellung von Text, Bildern, Videos und anderen Daten in einer binären Darstellung namens Einbettungen speichert. Dieser Abschnitt beleuchtet die Grundlagen von Vektordatenbanken und Einbettungen und konzentriert sich vor allem auf deren Verwendung zur Integration in LLM-Anwendungen.
Eine Vektordatenbank ist eine Datenbank, die Einbettungen im hochdimensionalen Raum speichert und sucht. Diese Vektoren sind numerische Darstellungen der Merkmale oder Attribute von Daten. Mithilfe von Algorithmen, die den Abstand oder die Ähnlichkeit zwischen Vektoren in einem hochdimensionalen Raum berechnen, können Vektordatenbanken schnell und effizient ähnliche Daten abrufen. Im Gegensatz zu herkömmlichen skalarbasierten Datenbanken, die Daten in Zeilen oder Spalten speichern und exakt passende oder schlüsselwortbasierte Suchmethoden verwenden, funktionieren Vektordatenbanken anders. Sie verwenden Vektordatenbanken, um eine große Sammlung von Vektoren in sehr kurzer Zeit (in der Größenordnung von Millisekunden) zu durchsuchen und zu vergleichen, indem sie Techniken wie Approximate Nearest Neighbors (ANN) verwenden.
Ein kurzes Tutorial zu Einbettungen
KI-Modelle generieren Einbettungen, indem sie Rohdaten wie Text, Video und Bilder in eine Vektoreinbettungsbibliothek eingeben, z Wort2vec und Im Kontext von KI und maschinellem Lernen stellen diese Merkmale verschiedene Dimensionen der Daten dar, die für das Verständnis von Musterbeziehungen und zugrunde liegenden Strukturen wesentlich sind.
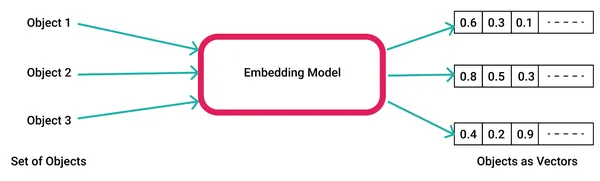
Hier ist ein Beispiel für die Generierung von Worteinbettungen mit word2vec.
1. Generieren Sie das Modell mithilfe Ihres benutzerdefinierten Datenkorpus oder verwenden Sie ein vorgefertigtes Beispielmodell von Google oder FastText. Wenn Sie Ihre eigene erstellen, können Sie diese als „word2vec.model“-Datei in Ihrem Dateisystem speichern.
import gensim # Create a word2vec model
model = gensim.models.Word2Vec(corpus) # Save the model file
model.save('word2vec.model')2. Laden Sie das Modell, generieren Sie eine Vektoreinbettung für ein Eingabewort und verwenden Sie diese, um ähnliche Wörter im Vektoreinbettungsraum abzurufen.
import gensim
import numpy as np # Load the word2vec model
model = gensim.models.Word2Vec.load('word2vec.model') # Get the vector for the word "king"
king_vector = model['king'] # Get the most similar vectors to the king vector
similar_vectors = model.similar_by_vector(king_vector, topn=5) # Print the most similar vectors
for vector in similar_vectors: print(vector[0], vector[1]) 3. Hier sind die Top-5-Wörter in der Nähe des Eingabeworts.
Output: man 0.85
prince 0.78
queen 0.75
lord 0.74
emperor 0.72LLM-Anwendungsarchitektur mit Vektordatenbanken
Auf hoher Ebene stützen sich Vektordatenbanken auf Einbettungsmodelle, um sowohl die Erstellung als auch die Abfrage von Einbettungen zu handhaben. Auf dem Aufnahmepfad wird der Korpusinhalt mithilfe des Einbettungsmodells in Vektoren codiert und in Vektordatenbanken wie Pinecone, ChromaDB, Weaviate usw. gespeichert. Auf dem Lesepfad führt die Anwendung eine Abfrage anhand von Sätzen oder Wörtern durch und diese wird erneut codiert durch das Einbettungsmodell in einen Vektor, der dann in die Vektordatenbank abgefragt wird, um die Ergebnisse abzurufen.
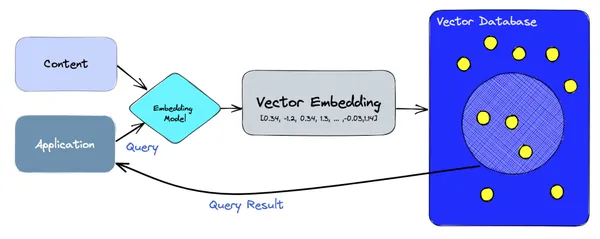
LLM-Anwendungen mit Vektordatenbanken
LLM hilft bei Sprachaufgaben und ist in eine breitere Klasse von Modellen eingebettet, wie z Generative KI das außer Text auch Bilder und Videos generieren kann. In diesem Abschnitt erfahren Sie, wie Sie mithilfe von Vektordatenbanken praktische LLM-/generative KI-Anwendungen erstellen. Ich habe Transformer und Torch-Bibliotheken für Sprachmodelle verwendet und Tannenzapfen als Vektordatenbank. Sie können ein beliebiges Sprachmodell für LLM/Einbettungen und eine beliebige Vektordatenbank für die Speicherung und Suche auswählen.
Chatbot-App
Um einen Chatbot mithilfe einer Vektordatenbank zu erstellen, können Sie die folgenden Schritte ausführen:
- Wählen Sie eine Vektordatenbank wie Pinecone, Chroma, Weaviate, AWS Kendra usw.
- Erstellen Sie einen Vektorindex für Ihren Chatbot.
- Trainieren Sie ein Sprachmodell mit einem großen Textkorpus Ihrer Wahl. Beispielsweise können Sie für einen Nachrichten-Chatbot Nachrichtendaten einspeisen.
- Integrieren Sie die Vektordatenbank und das Sprachmodell.
Hier ist ein einfaches Beispiel einer Chatbot-Anwendung, die eine Vektordatenbank und ein Sprachmodell verwendet:
import pinecone
import transformers # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the language model
model = transformers.AutoModelForCausalLM.from_pretrained("google/bigbird-roberta-base") # Define a function to generate text
def generate_text(prompt): inputs = model.prepare_inputs_for_generation(prompt, return_tensors="pt") outputs = model.generate(inputs, max_length=100) return outputs[0].decode("utf-8") # Define a function to retrieve the most similar vectors to the user's query vector
def retrieve_similar_vectors(query_vector): results = client.search("my_index", query_vector) return results # Define a function to generate a response to the user's query
def generate_response(query): # Retrieve the most similar vectors to the user's query vector similar_vectors = retrieve_similar_vectors(query) # Generate text based on the retrieved vectors response = generate_text(similar_vectors[0]) return response # Start the chatbot
while True: # Get the user's query query = input("What is your question? ") # Generate a response to the user's query response = generate_response(query) # Print the response print(response)Diese Chatbot-Anwendung ruft die Vektoren aus der Vektordatenbank ab, die dem Abfragevektor des Benutzers am ähnlichsten sind, und generiert dann mithilfe des Sprachmodells basierend auf den abgerufenen Vektoren Text.
ChatBot > What is your question?
User_A> How tall is the Eiffel Tower?
ChatBot>The height of the Eiffel Tower measures 324 meters (1,063 feet) from its base to the top of its antenna. Bildgenerator-App
Lassen Sie uns untersuchen, wie Sie eine Image Generator-App erstellen, die beides nutzt Generative KI und LLM-Bibliotheken.
- Erstellen Sie eine Vektordatenbank zum Speichern Ihrer Bildvektoren.
- Extrahieren Sie Bildvektoren aus Ihren Trainingsdaten.
- Fügen Sie die Bildvektoren in die Vektordatenbank ein.
- Trainieren Sie ein generatives gegnerisches Netzwerk (GAN). Lesen hier wenn Sie eine Einführung in GAN benötigen.
- Integrieren Sie die Vektordatenbank und das GAN.
Hier ist ein einfaches Beispiel für ein Programm, das eine Vektordatenbank und ein GAN zur Generierung von Bildern integriert:
import pinecone
import torch
from torchvision import transforms # Create an API client for the vector database
client = pinecone.Client(api_key="YOUR_API_KEY") # Load the GAN
generator = torch.load("generator.pt") # Define a function to generate an image from a vector
def generate_image(vector): # Convert the vector to a tensor tensor = torch.from_numpy(vector).float() # Generate the image image = generator(tensor) # Transform the image to a PIL image image = transforms.ToPILImage()(image) return image # Start the image generator
while True: # Get the user's query query = input("What kind of image would you like to generate? ") # Retrieve the most similar vector to the user's query vector similar_vectors = client.search("my_index", query) # Generate an image from the retrieved vector image = generate_image(similar_vectors[0]) # Display the image image.show()Dieses Programm ruft den Vektor aus der Vektordatenbank ab, der dem Abfragevektor des Benutzers am ähnlichsten ist, und generiert dann mithilfe des GAN basierend auf dem abgerufenen Vektor ein Bild.
ImageBot>What kind of image would you like to generate?
Me>An idyllic image of a mountain with a flowing river.
ImageBot> Wait a minute! Here you go...
Sie können dieses Programm an Ihre spezifischen Bedürfnisse anpassen. Sie können beispielsweise ein GAN trainieren, das auf die Generierung eines bestimmten Bildtyps spezialisiert ist, beispielsweise Porträts oder Landschaften.
Filmempfehlungs-App
Lassen Sie uns untersuchen, wie Sie aus einem Filmkorpus eine Filmempfehlungs-App erstellen. Mit einer ähnlichen Idee können Sie ein Empfehlungssystem für Produkte oder andere Einheiten aufbauen.
- Erstellen Sie eine Vektordatenbank zum Speichern Ihrer Filmvektoren.
- Extrahieren Sie Filmvektoren aus Ihren Filmmetadaten.
- Fügen Sie die Filmvektoren in die Vektordatenbank ein.
- Empfehlen Sie Benutzern Filme.
Hier ist ein Beispiel für die Verwendung der Pinecone-API, um Benutzern Filme zu empfehlen:
import pinecone # Create an API client
client = pinecone.Client(api_key="YOUR_API_KEY") # Get the user's vector
user_vector = client.get_vector("user_index", user_id) # Recommend movies to the user
results = client.search("movie_index", user_vector) # Print the results
for result in results: print(result["title"])Hier ist eine Beispielempfehlung für einen Benutzer
The Shawshank Redemption
The Dark Knight
Inception
The Godfather
Pulp FictionReale Anwendungsfälle von LLMs mit Vektorsuche/-datenbank
- Microsoft und TikTok nutzen Vektordatenbanken wie Pinecone für Langzeitgedächtnis und schnellere Suchvorgänge. Dies ist etwas, was LLMs ohne eine Vektordatenbank nicht alleine leisten können. Es hilft Benutzern, ihre früheren Fragen/Antworten zu speichern und ihre Sitzung fortzusetzen. Benutzer können beispielsweise fragen: „Erzählen Sie mir mehr über das Nudelrezept, das wir letzte Woche besprochen haben.“ Lesen hier.

- Der Entscheidungsassistent von Flipkart empfiehlt Benutzern Produkte, indem er zunächst die Abfrage als Vektoreinbettung codiert und eine Suche nach Vektoren durchführt, die relevante Produkte im hochdimensionalen Raum speichern. Wenn Sie beispielsweise nach „Wrangler-Lederjacke braun Herren mittel“ suchen, werden dem Benutzer mithilfe einer Vektorähnlichkeitssuche relevante Produkte empfohlen. Andernfalls hätte LLM keine Empfehlungen, da kein Produktkatalog solche Titel oder Produktdetails enthalten würde. Du kannst es lesen hier.
- Chipper Cash, ein Fintech in Afrika, nutzt eine Vektordatenbank, um betrügerische Benutzeranmeldungen um das Zehnfache zu reduzieren. Dazu werden alle Bilder früherer Benutzeranmeldungen als Vektoreinbettungen gespeichert. Wenn sich dann ein neuer Benutzer anmeldet, wird dieser als Vektor kodiert und mit den vorhandenen Benutzern verglichen, um Betrug zu erkennen. Du kannst es lesen hier.

- Facebook verwendet seine Vektorsuchbibliothek namens FAISS (Blog) in vielen Produkten intern, einschließlich Instagram Reels und Facebook Stories, um eine schnelle Suche nach Multimedia-Inhalten durchzuführen und ähnliche Kandidaten für bessere Vorschläge zu finden, die dem Benutzer angezeigt werden.
Zusammenfassung
Vektordatenbanken sind nützlich für die Erstellung verschiedener LLM-Anwendungen, wie z. B. Bildgenerierung, Film- oder Produktempfehlungen und Chatbots. Sie stellen LLMs zusätzliche oder ähnliche Informationen zur Verfügung, für die LLMs nicht geschult wurden. Sie speichern die Vektoreinbettungen effizient in einem hochdimensionalen Raum und verwenden die Suche nach nächsten Nachbarn, um ähnliche Einbettungen mit hoher Genauigkeit zu finden.
Key Take Away
Die wichtigsten Erkenntnisse aus diesem Artikel sind, dass sich Vektordatenbanken hervorragend für LLM-Apps eignen und die folgenden wichtigen Funktionen für die Integration durch Benutzer bieten:
- Leistung: Vektordatenbanken wurden speziell zum effizienten Speichern und Abrufen von Vektordaten entwickelt, was für die Entwicklung leistungsstarker LLM-Apps wichtig ist.
- Präzision: Vektordatenbanken können ähnliche Vektoren genau abgleichen, auch wenn sie geringfügige Abweichungen aufweisen. Sie verwenden Nearest-Neighbor-Algorithmen, um ähnliche Vektoren zu berechnen.
- Multimodal: Vektordatenbanken können verschiedene multimodale Daten aufnehmen, darunter Text, Bilder und Ton. Diese Vielseitigkeit macht sie zur idealen Wahl für LLM-/generative KI-Apps, die die Arbeit mit verschiedenen Datentypen erfordern.
- Entwicklerfreundlich: Vektordatenbanken sind relativ benutzerfreundlich, selbst für Entwickler, die möglicherweise nicht über umfassende Kenntnisse der Techniken des maschinellen Lernens verfügen.
Darüber hinaus möchte ich hervorheben, dass viele bestehende SQL/NoSQL-Lösungen bereits Vektoreinbettungsspeicher, Indizierung und schnellere Ähnlichkeitssuchfunktionen bieten, z. B. PostgreSQL und Redis. Dies ist ein sich schnell entwickelnder Bereich, sodass App-Entwicklern in naher Zukunft viele Möglichkeiten zur Entwicklung innovativer Apps zur Verfügung stehen werden.
Häufig gestellte Fragen
A. Large Language Models oder LLMs sind fortgeschrittene Programme der künstlichen Intelligenz (KI), die auf einem großen Korpus von Textdaten trainiert werden und neuronale Netze verwenden, um menschenähnliche Antworten mit Kontext nachzuahmen. Sie können Textdaten in dem Bereich, in dem sie geschult wurden, vorhersagen, beantworten und generieren.
A. Einbettungen sind numerische Darstellungen von Text, Bildern, Videos oder anderen Datenformaten. Sie erleichtern die gemeinsame Lokalisierung und das Auffinden semantisch ähnlicher Objekte in einem hochdimensionalen Raum.
A. Eine Datenbank speichert und fragt hochdimensionale Vektoreinbettungen ab, um ähnliche Vektoren mithilfe von Algorithmen für den nächsten Nachbarn wie ortssensitivem Hashing zu finden. LLMs/generative KI benötigen sie, um zusätzliche Suchvorgänge für ähnliche Vektoren bereitzustellen, anstatt das LLM selbst zu optimieren.
A. Vektordatenbanken sind Nischendatenbanken, die bei der Indexierung und Suche nach Vektoreinbettungen helfen. Sie erfreuen sich in der Open-Source-Community großer Beliebtheit und werden von vielen Organisationen/Apps integriert. Viele bestehende SQL/NoSQL-Datenbanken fügen jedoch ähnliche Funktionen hinzu, sodass der Entwicklergemeinschaft in naher Zukunft viele Optionen zur Verfügung stehen werden.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/10/how-to-build-llm-apps-using-vector-database/

