Energie ist ein allgegenwärtiges Problem, und es ist unmöglich, den Energieverbrauch eines Systems zu optimieren, ohne das System als Ganzes zu betrachten. Bei der Optimierung einer Hardware-Implementierung wurden enorme Fortschritte erzielt, aber das reicht nicht mehr aus. Das Gesamtsystem muss optimiert werden.
Dies hat weitreichende Auswirkungen, von denen einige den Weg zum domänenspezifischen Computing vorantreiben. Die Verschiebung nach links spielt eine Rolle, aber was noch wichtiger ist: Sie bedeutet, dass alle Parteien, die am Gesamtenergieverbrauch für eine definierte Aufgabe beteiligt sind, zusammenarbeiten müssen, um dieses Ziel zu erreichen.
Energie wird immer mehr zu einem wichtigen Thema. „Da Energieeffizienz in allen Computerbereichen zu einem entscheidenden Anliegen wird, werden Architekten häufig aufgefordert, die Energiekosten von Algorithmen sowohl für das Hardware- als auch für das Softwaredesign zu berücksichtigen“, sagt Guillaume Boillet, Senior Director für Produktmanagement und strategisches Marketing bei Arterien. „Der Schwerpunkt verlagert sich von der reinen Optimierung hinsichtlich der Recheneffizienz (Geschwindigkeit, Durchsatz, Latenz) hin zur Optimierung auch hinsichtlich der Energieeffizienz (Joule pro Vorgang). Dazu müssen Faktoren wie die Anzahl der Speicherzugriffe, die Parallelisierbarkeit der Berechnung und der Einsatz spezieller Hardwarebeschleuniger berücksichtigt werden, die für bestimmte Aufgaben möglicherweise eine energieeffizientere Berechnung ermöglichen.“
Dadurch verlagert sich der Schwerpunkt von der Hardware-Implementierung hin zur Architekturanalyse sowohl der Hardware als auch der Software. „In den späteren Phasen des Designablaufs nehmen die Möglichkeiten zur Optimierung ab“, sagt William Ruby, Produktmanagementdirektor bei der EDA Group of Synopsys. „Möglicherweise haben Sie mehr Möglichkeiten zur automatischen Optimierung, sind aber auf eine geringere prozentuale Verbesserung beschränkt. Bei der Betrachtung der Kurve für potenzielle Einsparungen (siehe Abbildung 1) handelt es sich nicht um eine glatte Kurve von der Architektur bis zur Abnahme. Bei der Synthese gibt es einen Wendepunkt. Bevor der Entwurf einer Implementierung zugeordnet wird, hat man viel mehr Freiheitsgrade, aber nach diesem Wendepunkt brechen die Dinge drastisch ab.“
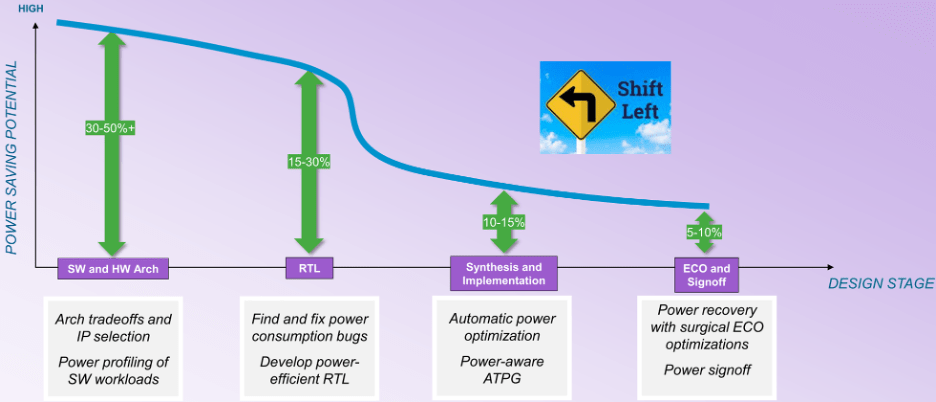
Abb.1: Möglichkeiten zur Energieeinsparung während der Entwurfsphase. Quelle: Synopsys
Das große Hindernis besteht darin, dass die Leistung vor dem Wendepunkt aktivitätsabhängig wird, was die automatische Optimierung erheblich erschwert. „Während der RTL-Entwicklung können dynamische vektorgesteuerte Prüfungen verwendet werden, um Verschwendung aufzudecken und logische Umstrukturierungen, Clock-Gating, Operator-Gating und andere Techniken durchzuführen, um diese zu reduzieren“, sagt Qazi Ahmed, Hauptproduktmanager bei Siemens EDA. „Es ist auch wichtig zu verstehen, dass die Leistung vom Anwendungsfall abhängig ist und anhand tatsächlicher softwaregesteuerter Arbeitslasten profiliert werden muss, um sicherzustellen, dass alle möglichen Szenarien abgedeckt sind. Dies gilt insbesondere im Kontext des vollständigen SoC, wo die Leistungshüllkurve völlig anders sein könnte als das, was eine synthetische vektorgesteuerte Analyse auf IP-Ebene zeigen könnte.“
„Es wird mehr Vorausplanung, Profilierung und Optimierung erforderlich sein“, sagt Tim Kogel, Chefingenieur für virtuelles Prototyping bei Synopsys.
Kogel wies auf verschiedene Ebenen hin, die angegangen werden müssen:
- Auf der Ebene der Makroarchitektur für die Analyse großer Kompromisse und die Auswahl dedizierter Verarbeitungselemente;
- Auf der Ebene der Mikroarchitektur zur Optimierung des Befehlssatzes und der Ausführungseinheiten für die Zielanwendung;
- Auf algorithmischer Ebene Auswahl und Optimierung von Algorithmen für Recheneffizienz und Speicherzugriffe und
- Auf Softwareebene: Bereitstellung von Feedback für Entwickler, wie sie ihre Software für Leistung und Energie optimieren können.
„Dies erfordert leistungs- und energiebewusste Werkzeuge für das virtuelle Prototyping und die Softwareentwicklung, um die Daten zu generieren, aus denen die Hardware- und Softwareimplementierung optimiert werden kann“, bemerkte er.
Software-Mapping
Die Entscheidung, was in der Software enthalten sein soll, ist eine frühe Aufgabe. „Möchte ich einen DSP-Kern haben, um die CPU zu entlasten?“ fragt Ruby von Synopsys. „Wie wirkt sich das auf meinen Stromverbrauch aus? Möchte ich einen Hardwarebeschleuniger implementieren oder möchte ich alle diese Funktionen in Software ausführen? Die Energiekosten der auf der CPU ausgeführten Software liegen nicht bei Null.“
Da Systeme zunehmend durch ihre Software definiert werden, müssen Überlegungen zum Thema Energie genau hier ansetzen. „Software ist ein Schlüsselelement, wenn es darum geht, Energie zu sparen und die Leistung zu verbessern“, sagt Vincent Risson, Senior Principal CPU Architect für Arm. „Rechenintensive Anwendungen profitieren oft erheblich von der Anwendungsoptimierung. Dies kann sowohl statisch im Sinne hoch abgestimmter Bibliotheken als auch dynamischer Frameworks sein, die es ermöglichen, die Berechnung auf die optimalste Verarbeitungs-Engine auszurichten. Mobile Geräte haben sich beispielsweise auf eine CPU-Systemarchitektur standardisiert, die Anwendungsprozessoren unterschiedliche Rechenleistung bietet und gleichzeitig einer gemeinsamen ISA und Konfiguration entspricht. Dadurch können Anwendungen dynamisch auf die Prozessoren migriert werden, die für die Effizienz optimal sind. Mechanismen für Selbstbeobachtung und Vielseitigkeit, bereitgestellt durch die Kombination von Software und heterogener Hardware, werden Möglichkeiten für eine verbesserte Effizienz in der Zukunft bieten.“
Es gibt oft mehr als eine Prozessorklasse, die von Software ausgeführt werden kann. „Wir können basierend auf den Arten von Arbeitslasten, die wir sehen, auswählen, wo eine bestimmte Anwendung ausgeführt werden soll“, sagt Jeff Wilcox, Fellow und CTO der Design Engineering Group für Client-SoC-Architekturen bei Intel. „Wenn es den Bedarf eines kleineren Kerns übersteigt, können größere Kerne hochgefahren werden. Es gibt Telemetrie und Workload-Charakterisierung, um herauszufinden, wo die Dinge am energieeffizientesten ausgeführt werden sollten. Viele der Arbeitsbelastungen, die wir derzeit erleben, sind unterschiedlich. Auch wenn symmetrische Agenten an derselben Arbeitslast arbeiten, bestehen Abhängigkeiten untereinander. Immer mehr Workloads erfordern asymmetrische Agenten, bei denen GPUs, NPUs und IPUs zur Verfügung stehen und diese Art von Workloads mit der CPU zusammenarbeiten. Das ist viel schwieriger zu optimieren. Wir sind an einem Punkt angelangt, an dem wir die Grundlagen haben, um die Leistungs- und Leistungsherausforderungen zu verstehen, aber wir entwickeln immer noch die Tools, um wirklich zu verstehen, wie wir sie vollständig verarbeiten und optimieren können.“
Die Schwierigkeit besteht darin, dass die Architektur der Arbeitslast von der Architektur der Hardware abhängen kann. „Es gibt viele Entwicklungen im Bereich der KI, und es ist nicht nur die Größe des Modells, die wichtig ist“, sagt Renxin Xia, Vizepräsident für Hardware bei Untether AI. „Ebenso wichtig ist, wie die Modelle aufgebaut sind und ob sie energieeffizient konstruiert sind. Das ist schwieriger zu beantworten, da es architekturabhängig ist. Die Energiekosten eines Algorithmus, der auf einer GPU ausgeführt wird, können sich stark von den Energiekosten dieses Algorithmus unterscheiden, der auf einem Speicher in einer Computerarchitektur ausgeführt wird.“
Konzentrieren Sie sich auf Software
Der allgemeine Konsens besteht darin, dass nichts davon ohne eine stärkere Zusammenarbeit zwischen Hardware und Software möglich ist. „Um diese Schrittfunktionsverbesserungen zu erreichen, ist eine gemeinsame Entwicklung von Hardware und Software erforderlich“, sagt Sailesh Kottapalli, Senior Fellow in der Rechenzentrumseinheit von Intel. „Allein der Versuch, dies transparent in Hardware umzusetzen, stößt an seine Grenzen. Schauen Sie sich an, was in der KI passiert. Wenn Hardware das einzige Element wäre, würden wir nicht den massiven Fortschritt sehen, den wir sehen. Vieles davon sind algorithmische Verbesserungen. Wenn Sie bei Softwarealgorithmen die Pfadlänge reduzieren, können Sie das gleiche Ergebnis mit weniger Anweisungen und geringerem Softwareaufwand erzielen. Wenn man sich darüber im Klaren ist, können wir manchmal herausfinden, dass es für diese Algorithmen einen neuen optimalen Befehlssatz und eine neue Mikroarchitektur gibt, und dann kann man das in der Hardware weiter optimieren.“
Es erfordert eine große Änderung in den Softwareentwicklungsabläufen. „In der Vergangenheit wurden Architekturen und Softwareabläufe auf Produktivität optimiert, das heißt, Allzweckprozessoren wurden mit Hochsprachen programmiert und nutzten die schnellsten und günstigsten Softwaretools“, sagt Kogel von Synopsys. „Die allgemeine Ausrichtung bestand darin, so viel Flexibilität und Produktivität wie möglich zu bieten und nur so viel wie unbedingt nötig zu optimieren. Dies muss dahingehend geändert werden, dass nur so viel Flexibilität wie erforderlich bereitgestellt wird und ansonsten dedizierte Implementierungen verwendet werden.“
Für viele Softwarefunktionen ist der Speicherzugriff der größte Stromverbraucher. „Eine Softwarefunktion kann auf unterschiedliche Weise implementiert werden, und das führt zu unterschiedlichen Befehlsströmen mit unterschiedlichen Leistungs- und Energieprofilen“, sagt Ruby von Synopsys. „Sie müssen die Speicherzugriffsanweisungen gewichten oder ihnen höhere Kosten zuweisen. Sie müssen vorsichtig sein, wie Sie Dinge modellieren. Auch wenn es nur um die CPU geht, müssen Sie die Energiekosten im Systemkontext modellieren.“
In Zukunft könnte auch die Ergebnisgenauigkeit ein Faktor sein, der bei der Optimierung hilfreich sein kann. „Erhebliche Energieeinsparungen können durch die Optimierung der Software erzielt werden, um die verfügbaren Hardwareressourcen besser zu nutzen“, sagt Boillet von Arteris. „Dazu gehören Compiler-Optimierungen, Code-Refactoring zur Reduzierung der Rechenkomplexität und Algorithmen, die speziell auf Energieeffizienz ausgelegt sind. Letzteres kann durch Näherungsberechnung für Anwendungen erreicht werden, die ein gewisses Maß an Ungenauigkeit tolerieren, wie etwa Multimedia-Verarbeitung, maschinelles Lernen und Sensordatenanalyse.“
Analyse
Alles beginnt mit der Analyse. „Wir können ein virtuelles Modell des Systems erstellen“, sagt Ruby. „Dann können wir Anwendungsfälle definieren, was in diesem Zusammenhang eigentlich eine Abfolge von Betriebsmodi des Designs ist. Das ist noch keine Software. Sie haben das System als eine Sammlung von Modellen beschrieben, sowohl Leistungsmodellen als auch Leistungsmodellen. Und Sie erhalten ein Leistungsprofil basierend auf diesen Modellen und dem von Ihnen definierten Anwendungsfall. Die nächste Alternative ist eine ähnliche Art der virtuellen Systembeschreibung. Nun führen Sie einen tatsächlichen Software-Workload dagegen aus. Wenn Sie noch tiefer gehen, wenn Sie mehr Sichtbarkeit und feinere Details wünschen, können Sie die RTL-Beschreibung des Designs verwenden. Vielleicht ist sie noch nicht endgültig, vielleicht ist sie noch früh, aber solange sie größtenteils wackelt, können Sie sie verwenden einen Emulator und führen Sie die eigentliche Arbeit aus. Sobald Sie dies tun, generiert der Emulator eine Aktivitätsdatenbank. Es gibt emulationsorientierte Leistungsanalysefunktionen, die große Datenmengen und Hunderte Millionen Taktzyklen an Arbeitslastdaten verarbeiten und ein Leistungsprofil erstellen können. Es gibt ein Spektrum an Dingen, die getan werden können.“
In manchen Fällen reicht die Zeitspanne möglicherweise nicht aus. „Der größte Teil unserer thermischen Analyse basiert auf einer Closed-Loop-Analyse, die auf Siliziumdaten basiert, und nicht auf einer Vor-Silizium-Simulation, da die Leiterbahnlängen erforderlich sind und die Analyse viel Zeit in Anspruch nimmt“, sagt Kottapalli von Intel. „Wir können nicht so lange simulieren, um ein realistisches thermisches Profil zu erstellen. Wir verwenden Profildaten von Silizium, verwenden verschiedene Arten von Workloads und Traces und analysieren dann, welche Lösungen wir entwickeln müssen.“
Es ist einfacher, wenn die Zeiträume kürzer sind. „Grundlegende Architekturentscheidungen müssen unter Berücksichtigung einer Art Power-Perspektive im Hinterkopf erwogen werden“, sagt Ruby. „Sie benötigen ein übergeordnetes, abstrakteres Modell aller Teile Ihres Systems, einschließlich aller Verarbeitungskerne und des Speichersubsystems, denn wie dieses organisiert ist, ist wirklich sehr, sehr wichtig. Wie viel Speicher wird wirklich benötigt? Dies sind grundlegende architektonische Entscheidungen. Sie müssen über einige Leistungsdaten verfügen, die diesen Komponenten zugeordnet sind. Wie viel Strom verbraucht die CPU unter dieser bestimmten Arbeitslast oder dieser bestimmten Arbeitslast? Was ist mit dem DSP-Kern, der Hardware, dem Speicher, dem Netzwerk auf dem Chip – wie viel verbraucht jeder von ihnen bei jedem Vorgang? Diese sind erforderlich, um grundlegende architektonische Entscheidungen zu treffen.“
Es sind viele neue Elektrowerkzeuge erforderlich. „Es gibt zwar EDA-Tools für den Umgang mit Hochgeschwindigkeits-Transienten mit hoher Leistungsdichte, es gibt aber noch viele andere Herausforderungen“, sagt Wilcox von Intel. „Einige der anderen Herausforderungen bestehen darin, die Dynamik längerer Zeitkonstanten zu betrachten oder Dinge im gesamten SoC zu verwalten. Ich habe im EDA-Bereich nicht so viel gesehen, was dabei hilft. Wir entwickeln weitere selbstentwickelte Tools, um diese Fähigkeiten aufzubauen.“
Während Tools für die Hardware-Seite dieser architektonischen Kompromisse entwickelt wurden, gibt es heute nur wenige Tools, die auf der Software-Seite helfen. „Wir brauchen unsere Softwareentwickler, um so schnell wie möglich den richtigen Code zu erstellen“, sagt Ruby. „Was meiner Meinung nach wirklich benötigt wird, ist eine Art Begleittechnologie für den Softwareentwickler. So wie wir über RTL-Leistungsanalysetools für die Hardware verfügen, benötigen Softwareentwicklungssysteme eine Art Leistungsprofiler, der ihnen sagt, wie viel Leistung und Energie dieser Code verbraucht. Da wir jetzt im Zeitalter der KI leben, wäre es cool, wenn KI-Technologie den Code analysieren würde. Sie erhalten eine Schätzung des Stromverbrauchs und einige KI-Technologien sagen möglicherweise, dass Sie auf diese Weise viel Strom sparen können, wenn Sie Ihren Code umstrukturieren.“
Zusammenfassung
Die Hardware-Welt stößt in Sachen Strom und Energie an Grenzen. In dieser Gemeinschaft nehmen die thermischen Grenzen und Bedenken zu. Ohne deren Berücksichtigung kann die Funktionalität der Hardware nicht wachsen. Diese haben jedoch noch nicht das Ausmaß erreicht, dass es sich um Probleme auf Systemebene handelt. Solange sich nicht alle Beteiligten, die zum Energieverbrauch beitragen, an einen Tisch setzen und das System energieeffizient gestalten, werden wir keine echten Lösungen für das Problem sehen.
Das hat auch eine zweite Seite. Alle Menschen, die die Werkzeuge herstellen, die diese Menschen verwenden, müssen ebenfalls an einem Strang ziehen und Abläufe entwickeln, die es allen ermöglichen, erfolgreich zu sein. Während es zwischen der EDA- und der Systemwelt einige Fortschritte bei der Lösung einiger thermischer Herausforderungen gab, gibt es auf architektonischer Ebene weniger Fortschritte und zwischen der Hardware- und Softwarewelt fast keine Fortschritte. Virtuelle Prototypen, die sich auf die Funktionalität konzentrieren, reichen nicht aus. Sie müssen auf Systemleistung und Energie ausgeweitet werden, und das geht nicht, ohne dass die Compiler-Entwickler eingreifen. Im domänenspezifischen Computing besteht eine Chance, da diese Leute aufgrund dieser Probleme eine neue Richtung in der Hardware einschlagen und es für sie möglicherweise wichtig genug ist, Fortschritte in den angrenzenden Bereichen zu erzielen. Aber es scheint alles noch eine lange Zeit in der Zukunft zu liegen.
Weiterführende Literatur
Der steigende Preis für Strom in Chips
Mehr Daten erfordern eine schnellere Verarbeitung, was zu einer ganzen Reihe von Problemen führt – von denen nicht alle offensichtlich oder sogar lösbar sind.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://semiengineering.com/optimizing-energy-at-the-system-level/

