Bild vom Autor
Die Verwendung von Scikit-Learn-Pipelines kann Ihre Vorverarbeitungs- und Modellierungsschritte vereinfachen, die Codekomplexität reduzieren, die Konsistenz bei der Datenvorverarbeitung sicherstellen, bei der Optimierung von Hyperparametern helfen und Ihren Workflow organisierter und einfacher zu warten machen. Durch die Integration mehrerer Transformationen und des endgültigen Modells in eine einzige Einheit verbessern Pipelines die Reproduzierbarkeit und machen alles effizienter.
In diesem Tutorial werden wir mit dem arbeiten Bankabwanderung Datensatz von Kaggle, um einen Random Forest Classifier zu trainieren. Wir vergleichen den herkömmlichen Ansatz der Datenvorverarbeitung und des Modelltrainings mit einer effizienteren Methode unter Verwendung von Scikit-Learn-Pipelines und ColumnTransformers.
In der Datenverarbeitungspipeline lernen wir, wie man sowohl kategoriale als auch numerische Spalten einzeln transformiert. Wir beginnen mit einem traditionellen Codestil und zeigen dann eine bessere Möglichkeit, eine ähnliche Verarbeitung durchzuführen.
Laden Sie nach dem Extrahieren der Daten aus der ZIP-Datei die Datei „train.csv“ mit „id“ als Indexspalte. Löschen Sie unnötige Spalten und mischen Sie den Datensatz.
import pandas as pd
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
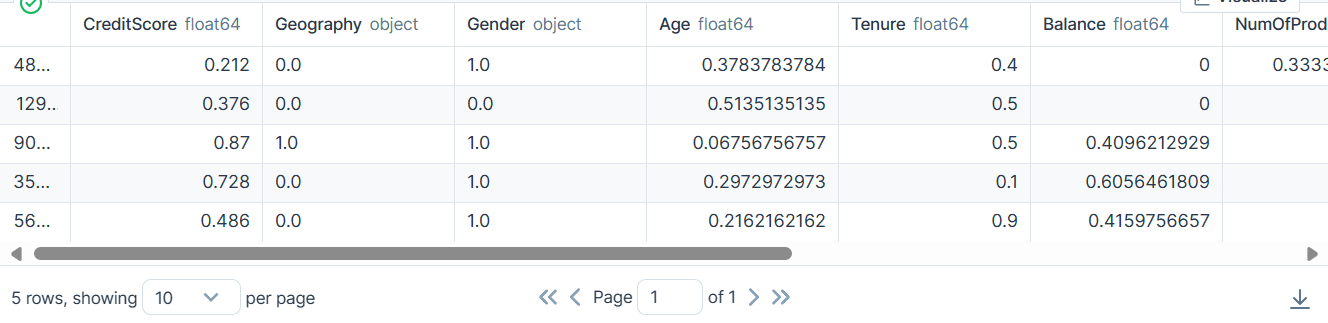
bank_df.head()
Wir haben kategorische, ganzzahlige und Gleitkomma-Spalten. Der Datensatz sieht ziemlich sauber aus.

Einfacher Scikit-Learn-Code
Als Datenwissenschaftler habe ich diesen Code mehrmals geschrieben. Unser Ziel ist es, die fehlenden Werte sowohl für kategoriale als auch für numerische Merkmale zu ergänzen. Um dies zu erreichen, verwenden wir einen „SimpleImputer“ mit unterschiedlichen Strategien für jeden Feature-Typ.
Nachdem die fehlenden Werte ausgefüllt sind, konvertieren wir kategoriale Merkmale in Ganzzahlen und wenden die Min-Max-Skalierung auf numerische Merkmale an.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Filling missing categorical values
cat_impute = SimpleImputer(strategy="most_frequent")
bank_df.iloc[:,cat_col] = cat_impute.fit_transform(bank_df.iloc[:,cat_col])
# Filling missing numerical values
num_impute = SimpleImputer(strategy="median")
bank_df.iloc[:,num_col] = num_impute.fit_transform(bank_df.iloc[:,num_col])
# Encode categorical features as an integer array.
cat_encode = OrdinalEncoder()
bank_df.iloc[:,cat_col] = cat_encode.fit_transform(bank_df.iloc[:,cat_col])
# Scaling numerical values.
scaler = MinMaxScaler()
bank_df.iloc[:,num_col] = scaler.fit_transform(bank_df.iloc[:,num_col])
bank_df.head()
Als Ergebnis haben wir einen Datensatz erhalten, der sauber und transformiert ist und nur Ganzzahl- oder Gleitkommawerte enthält.
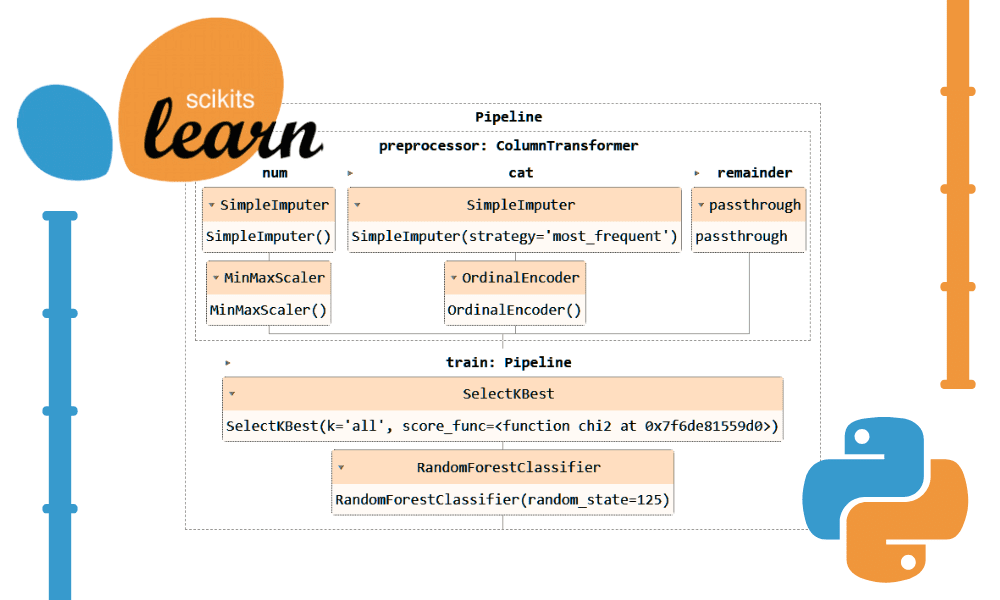
Scikit-learn Pipelines-Code
Lassen Sie uns den obigen Code mit „Pipeline“ und „ColumnTransformer“ konvertieren. Anstatt die Vorverarbeitungstechnik anzuwenden, erstellen wir zwei Pipelines. Eine ist für numerische Spalten und eine für kategoriale Spalten.
- In der numerischen Pipeline haben wir eine einfache Imputation mit einer „Mittelwert“-Strategie verwendet und einen Min-Max-Skalierer zur Normalisierung angewendet.
- In der kategorialen Pipeline haben wir den einfachen Imputer mit der Strategie „most_frequent“ und den ursprünglichen Encoder verwendet, um die Kategorien in numerische Werte umzuwandeln.
Wir haben die beiden Pipelines mithilfe des ColumnTransformer kombiniert und jede mit dem Spaltenindex versehen. Es wird Ihnen helfen, diese Pipelines auf bestimmte Spalten anzuwenden. Beispielsweise wird eine kategoriale Transformatorpipeline nur auf die Spalten 1 und 2 angewendet.
Hinweis: Der Rest = „Passthrough“ bedeutet, dass die nicht verarbeiteten Spalten am Ende hinzugefügt werden. In unserem Fall ist es die Zielspalte.
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine transformers into a ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Apply the preprocessing pipeline
bank_df = preproc_pipe.fit_transform(bank_df)
bank_df[0]
Nach der Transformation enthält das resultierende Array einen numerischen Transformationswert am Anfang und einen kategorialen Transformationswert am Ende, basierend auf der Reihenfolge der Pipelines im Spaltentransformator.
array([0.712 , 0.24324324, 0.6 , 0. , 0.33333333,
1. , 1. , 0.76443485, 2. , 0. ,
0. ])
Sie können das Pipeline-Objekt im Jupyter Notebook ausführen, um die Pipeline zu visualisieren. Stellen Sie sicher, dass Sie über die neueste Version von Scikit-learn verfügen.
preproc_pipe

Um unser Modell zu trainieren und zu bewerten, müssen wir unseren Datensatz in zwei Teilmengen aufteilen: Training und Testen.
Dazu erstellen wir zunächst abhängige und unabhängige Variablen und konvertieren sie in NumPy-Arrays. Anschließend verwenden wir die Funktion „train_test_split“, um den Datensatz in zwei Teilmengen aufzuteilen.
from sklearn.model_selection import train_test_split
X = bank_df.drop("Exited", axis=1).values
y = bank_df.Exited.values
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)Einfacher Scikit-Learn-Code
Die herkömmliche Art, Trainingscode zu schreiben, besteht darin, zunächst eine Funktionsauswahl mit „SelectKBest“ durchzuführen und dann die neue Funktion unserem Random Forest Classifier-Modell bereitzustellen.
Wir trainieren zunächst das Modell mithilfe des Trainingssatzes und werten die Ergebnisse mithilfe des Testdatensatzes aus.
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
KBest = SelectKBest(chi2, k="all")
X_train = KBest.fit_transform(X_train, y_train)
X_test = KBest.transform(X_test)
model = RandomForestClassifier(n_estimators=100, random_state=125)
model.fit(X_train,y_train)
model.score(X_test, y_test)
Wir haben eine einigermaßen gute Genauigkeitsbewertung erreicht.
0.8613035487063481Scikit-learn Pipelines-Code
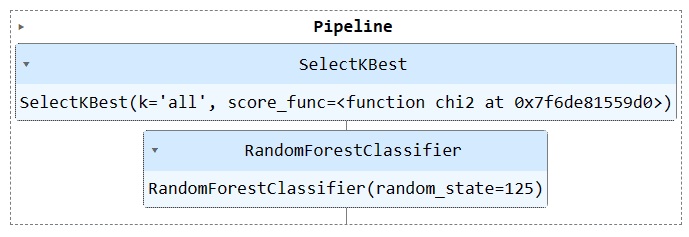
Nutzen wir die Funktion „Pipeline“, um beide Trainingsschritte in einer Pipeline zusammenzufassen. Anschließend können wir das Modell an den Trainingssatz anpassen und es anhand des Testsatzes bewerten.
KBest = SelectKBest(chi2, k="all")
model = RandomForestClassifier(n_estimators=100, random_state=125)
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
train_pipe.fit(X_train,y_train)
train_pipe.score(X_test, y_test)
Wir haben ähnliche Ergebnisse erzielt, aber der Code scheint effizienter und einfacher zu sein. Es ist ganz einfach, neue Schritte zur Trainingspipeline hinzuzufügen oder daraus zu entfernen.
0.8613035487063481
Führen Sie das Pipeline-Objekt aus, um die Pipeline zu visualisieren.
train_pipe
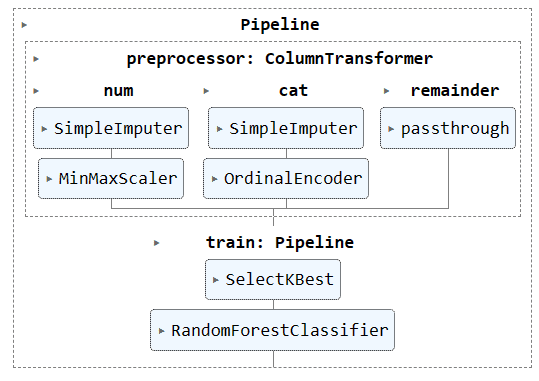
Jetzt kombinieren wir sowohl die Vorverarbeitungs- als auch die Trainingspipeline, indem wir eine weitere Pipeline erstellen und beide Pipelines hinzufügen.
Hier ist der vollständige Code:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OrdinalEncoder, MinMaxScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.ensemble import RandomForestClassifier
#loading the data
bank_df = pd.read_csv("train.csv", index_col="id")
bank_df = bank_df.drop(['CustomerId', 'Surname'], axis=1)
bank_df = bank_df.sample(frac=1)
# Splitting data into training and testing sets
X = bank_df.drop(["Exited"],axis=1)
y = bank_df.Exited
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=125
)
# Identify numerical and categorical columns
cat_col = [1,2]
num_col = [0,3,4,5,6,7,8,9]
# Transformers for numerical data
numerical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='mean')),
('scaler', MinMaxScaler())
])
# Transformers for categorical data
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='most_frequent')),
('encoder', OrdinalEncoder())
])
# Combine pipelines using ColumnTransformer
preproc_pipe = ColumnTransformer(
transformers=[
('num', numerical_transformer, num_col),
('cat', categorical_transformer, cat_col)
],
remainder="passthrough"
)
# Selecting the best features
KBest = SelectKBest(chi2, k="all")
# Random Forest Classifier
model = RandomForestClassifier(n_estimators=100, random_state=125)
# KBest and model pipeline
train_pipe = Pipeline(
steps=[
("KBest", KBest),
("RFmodel", model),
]
)
# Combining the preprocessing and training pipelines
complete_pipe = Pipeline(
steps=[
("preprocessor", preproc_pipe),
("train", train_pipe),
]
)
# running the complete pipeline
complete_pipe.fit(X_train,y_train)
# model accuracy
complete_pipe.score(X_test, y_test)
Ausgang:
0.8592837955201874
Visualisierung der kompletten Pipeline.
complete_pipe

Einer der Hauptvorteile der Verwendung von Pipelines besteht darin, dass Sie die Pipeline mit dem Modell speichern können. Während der Inferenz müssen Sie nur das Pipeline-Objekt laden, das bereit ist, die Rohdaten zu verarbeiten und Ihnen genaue Vorhersagen zu liefern. Sie müssen die Verarbeitungs- und Transformationsfunktionen in der App-Datei nicht neu schreiben, da sie sofort funktionieren. Dies macht den Machine-Learning-Workflow effizienter und spart Zeit.
Speichern wir zunächst die Pipeline mit skops-dev/skops Bibliothek.
import skops.io as sio
sio.dump(complete_pipe, "bank_pipeline.skops")
Laden Sie dann die gespeicherte Pipeline und zeigen Sie die Pipeline an.
new_pipe = sio.load("bank_pipeline.skops", trusted=True)
new_pipe
Wie wir sehen, haben wir die Pipeline erfolgreich geladen.
Um unsere ausgelastete Pipeline zu bewerten, treffen wir Vorhersagen zum Testsatz und berechnen dann die Genauigkeit und F1-Ergebnisse.
from sklearn.metrics import accuracy_score, f1_score
predictions = new_pipe.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
f1 = f1_score(y_test, predictions, average="macro")
print("Accuracy:", str(round(accuracy, 2) * 100) + "%", "F1:", round(f1, 2))
Es stellt sich heraus, dass wir uns auf Minderheitenklassen konzentrieren müssen, um unseren F1-Score zu verbessern.
Accuracy: 86.0% F1: 0.76
Die Projektdateien und der Code sind unter verfügbar Deepnote-Arbeitsbereich. Der Arbeitsbereich verfügt über zwei Notebooks: eines mit der Scikit-learn-Pipeline und eines ohne sie.
In diesem Tutorial haben wir erfahren, wie Scikit-Learn-Pipelines dazu beitragen können, Arbeitsabläufe für maschinelles Lernen zu optimieren, indem sie Sequenzen von Datentransformationen und Modellen verketten. Durch die Kombination von Vorverarbeitung und Modelltraining in einem einzigen Pipeline-Objekt können wir Code vereinfachen, konsistente Datentransformationen sicherstellen und unsere Arbeitsabläufe organisierter und reproduzierbarer gestalten.
Abid Ali Awan (@1abidaliawan) ist ein zertifizierter Datenwissenschaftler, der es liebt, Modelle für maschinelles Lernen zu erstellen. Derzeit konzentriert er sich auf die Erstellung von Inhalten und schreibt technische Blogs zu maschinellem Lernen und Data-Science-Technologien. Abid hat einen Master-Abschluss in Technologiemanagement und einen Bachelor-Abschluss in Telekommunikationstechnik. Seine Vision ist es, ein KI-Produkt mit einem grafisch-neuronalen Netzwerk für Schüler zu entwickeln, die mit psychischen Erkrankungen zu kämpfen haben.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/streamline-your-machine-learning-workflow-with-scikit-learn-pipelines?utm_source=rss&utm_medium=rss&utm_campaign=streamline-your-machine-learning-workflow-with-scikit-learn-pipelines

