
Bild vom Autor
Mistral AI, eines der weltweit führenden KI-Forschungsunternehmen, hat kürzlich das Basismodell für veröffentlicht Mistral 7B v0.2.
Dieses Open-Source-Sprachmodell wurde während der Hackathon-Veranstaltung des Unternehmens am 23. März 2024 vorgestellt.
Die Mistral 7B-Modelle verfügen über 7.3 Milliarden Parameter und sind damit äußerst leistungsstark. Sie übertreffen Llama 2 13B und Llama 1 34B in fast allen Benchmarks. Das neueste V0.2-Modell führt neben anderen Verbesserungen ein 32-KB-Kontextfenster ein und verbessert so seine Fähigkeit, Text zu verarbeiten und zu generieren.
Darüber hinaus handelt es sich bei der kürzlich angekündigten Version um das Basismodell der befehlsoptimierten Variante „Mistral-7B-Instruct-V0.2“, die Anfang letzten Jahres veröffentlicht wurde.
In diesem Tutorial zeige ich Ihnen, wie Sie auf dieses Sprachmodell in Hugging Face zugreifen und es verfeinern können.
Wir werden das Basismodell Mistral 7B-v0.2 mithilfe der AutoTrain-Funktionalität von Hugging Face verfeinern.
Gesicht umarmen ist dafür bekannt, den Zugang zu Modellen des maschinellen Lernens zu demokratisieren und es alltäglichen Benutzern zu ermöglichen, fortschrittliche KI-Lösungen zu entwickeln.
AutoTrain, eine Funktion von Hugging Face, automatisiert den Prozess des Modelltrainings und macht ihn zugänglich und effizient.
Es hilft Benutzern bei der Auswahl der besten Parameter und Trainingstechniken bei der Feinabstimmung von Modellen, eine Aufgabe, die ansonsten entmutigend und zeitaufwändig sein kann.
Hier sind 5 Schritte zur Feinabstimmung Ihres Mistral-7B-Modells:
1. Einrichten der Umgebung
Sie müssen zunächst ein Konto bei Hugging Face erstellen und dann ein Modell-Repository erstellen.
Um dies zu erreichen, befolgen Sie einfach die hier aufgeführten Schritte Link und kehren Sie zu diesem Tutorial zurück.
Wir werden das Modell in Python trainieren. Wenn es um die Auswahl einer Notebook-Umgebung für Schulungen geht, können Sie Folgendes verwenden Kaggle-Notizbücher or Google Colab, die beide kostenlosen Zugriff auf GPUs ermöglichen.
Wenn der Schulungsprozess zu lange dauert, möchten Sie möglicherweise zu einer Cloud-Plattform wie AWS Sagemaker oder Azure ML wechseln.
Führen Sie abschließend die folgenden Pip-Installationen durch, bevor Sie mit dem Codieren für dieses Tutorial beginnen:
!pip install -U autotrain-advanced
!pip install datasets transformers2. Vorbereiten Ihres Datensatzes
In diesem Tutorial verwenden wir die Alpaka-Datensatz auf Hugging Face, das so aussieht:
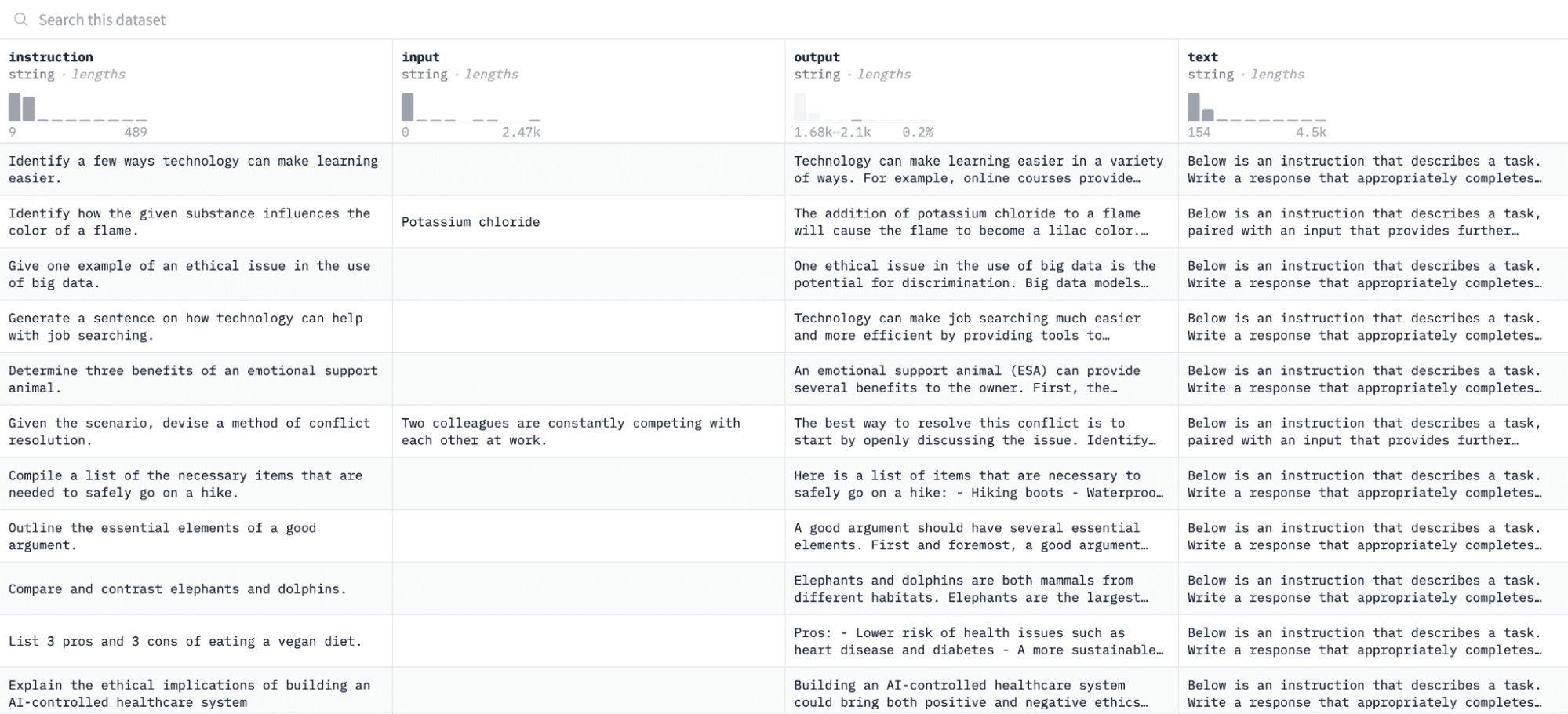
Wir werden das Modell anhand von Paaren von Anweisungen und Ausgaben verfeinern und seine Fähigkeit bewerten, auf die gegebenen Anweisungen im Bewertungsprozess zu reagieren.
Um auf diesen Datensatz zuzugreifen und ihn vorzubereiten, führen Sie die folgenden Codezeilen aus:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")Die erste Funktion lädt den Alpaca-Datensatz mithilfe der „Datasets“-Bibliothek und bereinigt ihn, um sicherzustellen, dass keine leeren Anweisungen eingefügt werden. Die zweite Funktion strukturiert Ihre Daten in einem Format, das AutoTrain verstehen kann.
Nach der Ausführung des obigen Codes wird der Datensatz geladen, formatiert und im angegebenen Pfad gespeichert. Wenn Sie Ihren formatierten Datensatz öffnen, sollten Sie eine einzelne Spalte mit der Bezeichnung „formatted_text“ sehen.
3. Einrichten Ihrer Trainingsumgebung
Nachdem Sie den Datensatz nun erfolgreich vorbereitet haben, können wir mit der Einrichtung Ihrer Modelltrainingsumgebung fortfahren.
Dazu müssen Sie folgende Parameter definieren:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'Hier ist eine Aufschlüsselung der oben genannten Spezifikationen:
- Sie können eine beliebige angeben Projektname. Hier werden alle Ihre Projekt- und Schulungsdateien gespeichert.
- Das Modellname Parameter ist das Modell, das Sie optimieren möchten. In diesem Fall habe ich einen Pfad zum angegeben Basismodell Mistral-7B v0.2 auf Hugging Face.
- Das hf_token Die Variable muss auf Ihren Hugging Face-Token eingestellt sein, den Sie durch Navigieren zu erhalten können diesen Link.
- Ihr repo_id muss auf das Hugging Face-Modellrepository eingestellt sein, das Sie im ersten Schritt dieses Tutorials erstellt haben. Meine Repository-ID lautet beispielsweise NatasshaS/Model2.
4. Modellparameter konfigurieren
Bevor wir unser Modell verfeinern, müssen wir die Trainingsparameter definieren, die Aspekte des Modellverhaltens wie Trainingsdauer und Regularisierung steuern.
Diese Parameter beeinflussen wichtige Aspekte wie die Trainingsdauer des Modells, wie es aus den Daten lernt und wie es eine Überanpassung vermeidet.
Sie können die folgenden Parameter für Ihr Modell festlegen:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. Umgebungsvariablen festlegen
Bereiten wir nun unsere Trainingsumgebung vor, indem wir einige Umgebungsvariablen festlegen.
Dieser Schritt stellt sicher, dass die AutoTrain-Funktion die gewünschten Einstellungen zur Feinabstimmung des Modells verwendet, z. B. unseren Projektnamen und unsere Trainingseinstellungen:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. Starten Sie das Modelltraining
Beginnen wir abschließend mit dem Training des Modells mithilfe von Autozug Befehl. In diesem Schritt müssen Sie Ihr Modell, Ihren Datensatz und Ihre Trainingskonfigurationen angeben, wie unten dargestellt:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )Stellen Sie sicher, dass Sie die ändern Datenweg dorthin, wo sich Ihr Trainingsdatensatz befindet.
7. Bewertung des Modells
Sobald Ihr Modell das Training abgeschlossen hat, sollte in Ihrem Verzeichnis ein Ordner mit demselben Titel wie Ihr Projektname angezeigt werden.
In meinem Fall trägt dieser Ordner den Titel „Mistralai“, wie im Bild unten zu sehen:
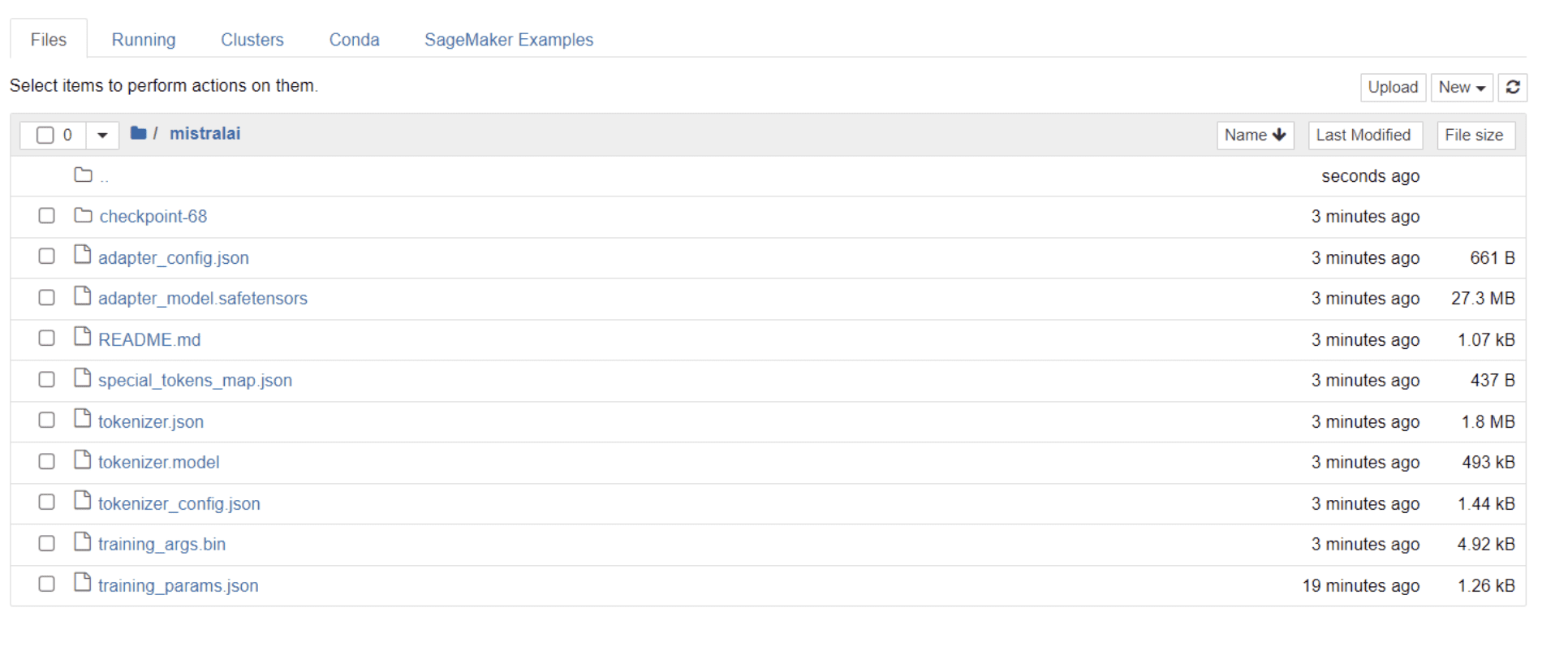
In diesem Ordner finden Sie Dateien, die Ihre Modellgewichte, Hyperparameter und Architekturdetails umfassen.
Lassen Sie uns nun prüfen, ob dieses fein abgestimmte Modell in der Lage ist, eine Frage in unserem Datensatz genau zu beantworten. Um dies zu erreichen, müssen wir zunächst die folgenden Codezeilen ausführen, um 5 Beispieleingaben und -ausgaben aus unserem Datensatz zu generieren:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")Sie sollten eine Antwort sehen, die wie folgt aussieht und fünf Beispieldatenpunkte enthält:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.Wir werden eine der oben genannten Anweisungen in das Modell eingeben und prüfen, ob sie eine genaue Ausgabe generiert. Hier ist eine Funktion, um dem Modell eine Anweisung zu geben und eine Antwort von ihm zu erhalten:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerGeben Sie abschließend eine Frage in diese Funktion ein, wie unten dargestellt:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)Ihr Modell sollte eine Antwort generieren, die mit der entsprechenden Ausgabe im Trainingsdatensatz identisch ist, wie unten dargestellt:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andBitte beachten Sie, dass die Antwort aufgrund der von uns angegebenen Anzahl an Token möglicherweise unvollständig oder abgeschnitten erscheint. Sie können den Wert „max_length“ jederzeit anpassen, um eine längere Antwort zu ermöglichen.
Wenn Sie so weit gekommen sind, herzlichen Glückwunsch!
Sie haben erfolgreich ein hochmodernes Sprachmodell verfeinert und dabei die Leistungsfähigkeit von Mistral 7B v-0.2 zusammen mit den Fähigkeiten von Hugging Face genutzt.
Aber die Reise endet hier nicht.
Als nächsten Schritt empfehle ich, mit verschiedenen Datensätzen zu experimentieren oder bestimmte Trainingsparameter zu optimieren, um die Modellleistung zu optimieren. Die Feinabstimmung von Modellen in größerem Maßstab erhöht ihren Nutzen. Versuchen Sie daher, mit größeren Datensätzen oder unterschiedlichen Formaten wie PDFs und Textdateien zu experimentieren.
Solche Erfahrungen sind von unschätzbarem Wert, wenn in Organisationen mit realen Daten gearbeitet wird, die oft chaotisch und unstrukturiert sind.
Natascha Selvaraj ist ein autodidaktischer Datenwissenschaftler mit einer Leidenschaft für das Schreiben. Natassha schreibt über alles, was mit Datenwissenschaft zu tun hat, eine wahre Meisterin aller Datenthemen. Sie können sich mit ihr verbinden LinkedIn oder schau sie dir an YouTube-Kanal.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

