
Entscheidungsbäume sind einer der einfachsten nichtlinearen überwachten Algorithmen in der Welt des maschinellen Lernens. Wie der Name schon sagt, werden sie verwendet, um Entscheidungen in ML-Begriffen zu treffen, wir nennen es Klassifizierung (obwohl sie auch für die Regression verwendet werden können).
Die Entscheidungsbäume haben eine unidirektionale Baumstruktur, dh an jedem Knoten trifft der Algorithmus eine Entscheidung zur Aufteilung in Kindknoten basierend auf bestimmten Stoppkriterien. Am häufigsten verwenden DTs Entropie, Informationsgewinn, Gini-Index usw.
Es gibt einige bekannte Algorithmen in DTs wie ID3, C4.5, CART, C5.0, CHAID, QUEST, CRUISE. In diesem Artikel würden wir die einfachste und älteste diskutieren: ID3.
ID3, oder Iternative Dichotomizer, war die erste von drei Entscheidungsbaumimplementierungen, die von Ross Quinlan entwickelt wurden.
Der Algorithmus baut einen Baum von oben nach unten auf, ausgehend von einer Reihe von Zeilen/Objekten und einer Spezifikation von Merkmalen. An jedem Knoten des Baums wird ein Merkmal basierend auf der Minimierung der Entropie oder der Maximierung des Informationsgewinns getestet, um den Objektsatz aufzuteilen. Dieser Prozess wird fortgesetzt, bis die Menge in einem gegebenen Knoten homogen ist (dh der Knoten enthält Objekte derselben Kategorie). Der Algorithmus verwendet eine gierige Suche. Es wählt einen Test unter Verwendung des Informationsgewinnkriteriums aus und untersucht dann nie die Möglichkeit alternativer Wahlmöglichkeiten.
Nachteile:
- Das Modell ist möglicherweise überangepasst.
- Funktioniert nur bei kategorialen Merkmalen
- Verarbeitet keine fehlenden Werte
- Langsame Geschwindigkeit
- Beschneidung wird nicht unterstützt
- Unterstützt kein Boosten
So viele Nachteile eines Algorithmus, warum diskutieren wir überhaupt darüber?
Antwort: Es ist einfach und großartig, die Intuition für Baumalgorithmen zu entwickeln.
Eines der beliebtesten Kinderlieder, bei dem der Regen entscheidet, ob Johny/Arthur draußen spielen würden, ist unser heutiges Beispiel. Die einzige Änderung ist, dass nicht nur Regen, sondern jedes schlechte Wetter das Spiel des Kindes beeinträchtigt und wir einen DT verwenden würden, um seine Anwesenheit draußen vorherzusagen.

Quelle: Wikipedia
Die Daten sehen so aus:
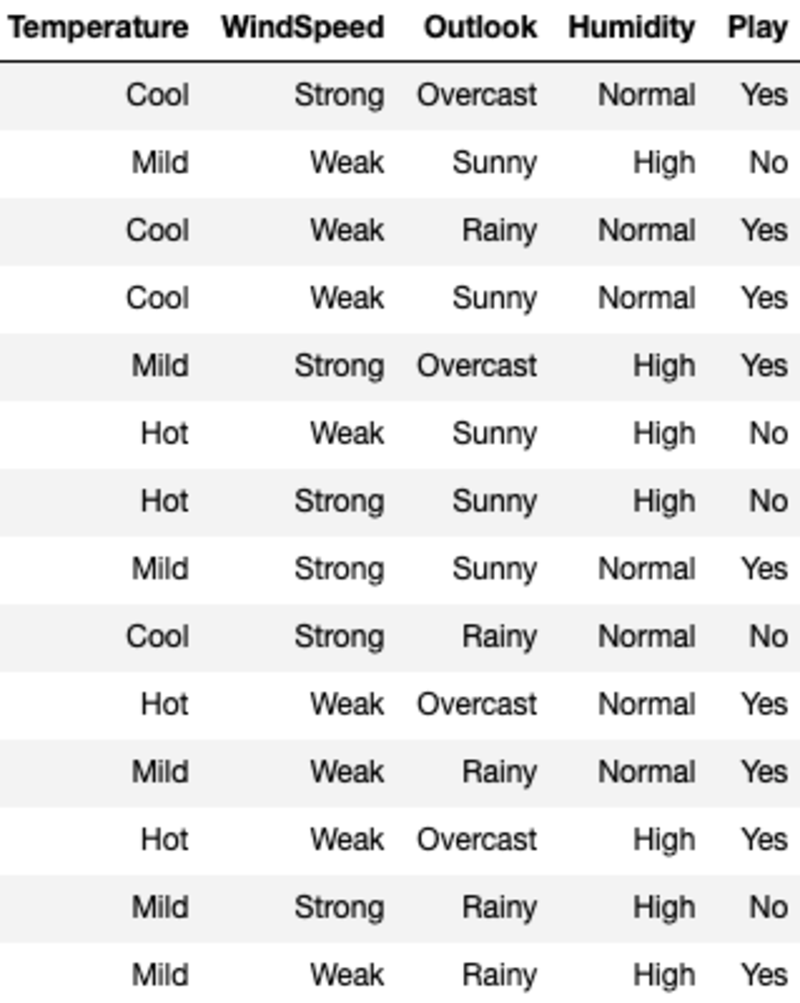
'Temperature', 'WindSpeed', 'Outlook' und 'Humidity' sind die Features und 'Play' ist die Zielvariable. Nur kategoriale Daten und keine fehlenden Werte bedeuten, dass wir ID3 verwenden können.
Lassen Sie uns die Aufteilungskriterien durchgehen, bevor wir uns dem Algorithmus selbst zuwenden. Der Einfachheit halber werden wir jedes Kriterium nur für den Fall der binären Klassifikation diskutieren.
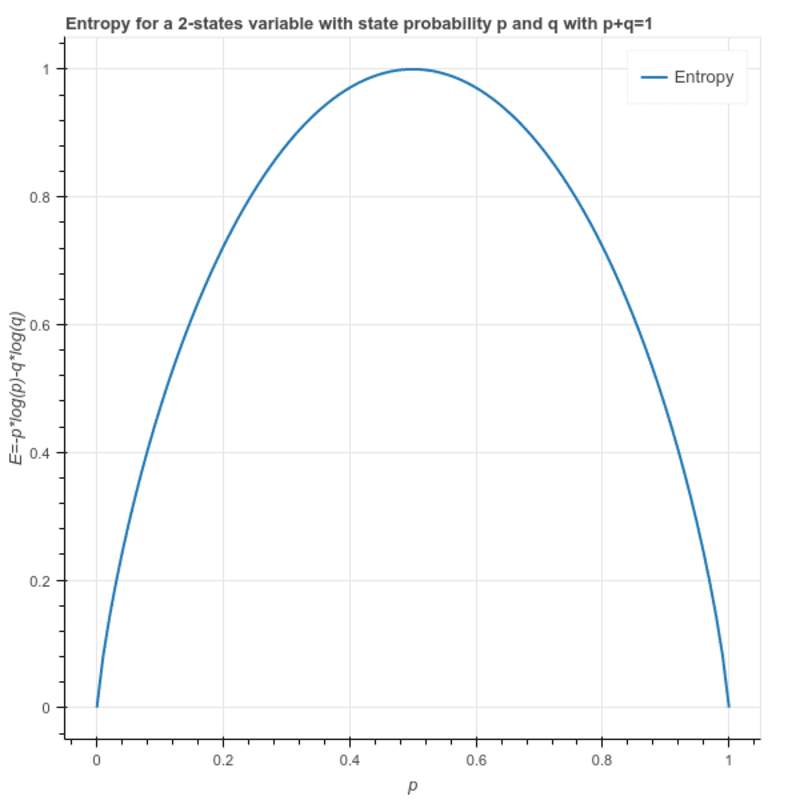
Entropie: Daraus wird die Heterogenität einer Stichprobe berechnet und ihr Wert liegt zwischen 0 und 1. Ist die Stichprobe homogen, so ist die Entropie 0 und hat die Stichprobe den gleichen Anteil an allen Klassen, hat sie eine Entropie von 1.
S = -(p * log₂p + q * log₂q)
Wo p und q sind jeweilige Anteile der 2 Klassen in der Stichprobe.
Dies kann auch geschrieben werden als: S = -(p * log₂p + (1-p)* log₂(1-p))
Informationsgewinn: Es ist die Differenz der Entropie eines Knotens und der durchschnittlichen Entropie für alle Werte eines untergeordneten Knotens. Für die Teilung wird das Merkmal gewählt, das den maximalen Informationsgewinn ergibt.
Die Entropie des Wurzelknotens: (9 – Ja und 5 – Nein)
S = -(9/14)*log(9/14) — (5/14) * log(5/14) = 0.94
Es gibt 4 Möglichkeiten, den Wurzelknoten aufzuteilen. ('Temperatur', 'Windgeschwindigkeit', 'Aussicht' und 'Luftfeuchtigkeit'). Daher berechnen wir die gewichtete durchschnittliche Entropie des untergeordneten Knotens, wenn wir eine der oben genannten auswählen:
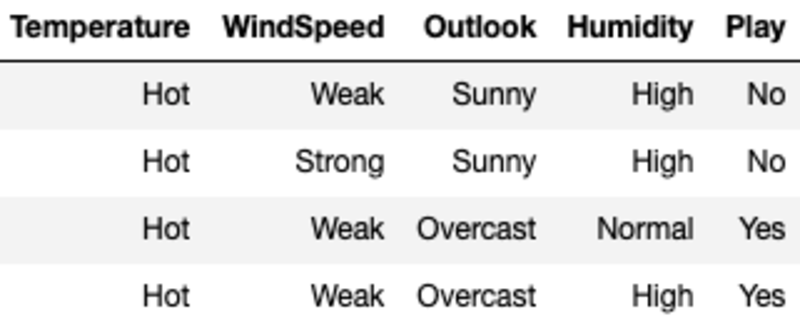
I(Temperature) = Hot*E(Temperature=Hot) + Mild*E(Temperature=Mild) + Cool*E(Temperature=Cool)
Wobei Hot, Mild und Cool den Anteil der 3 Werte in den Daten darstellen.
I(Temperature) = (4/14)*1 + (6/14)*0.918 + (4/14)*0.811 = 0.911
Hier wird die Entropie für jeden Wert berechnet, indem die Stichprobe anhand des Werts des Merkmals gefiltert und dann die Formel für die Entropie verwendet wird. Beispielsweise wird E(Temperature=Hot) berechnet, indem die ursprüngliche Stichprobe gefiltert wird, bei der die Temperatur Hot ist (in diesem Fall haben wir eine gleiche Anzahl von Ja und Nein, was bedeutet, dass die Entropie gleich 1 ist).
Wir berechnen den Informationsgewinn der Aufspaltung nach Temperatur, indem wir die durchschnittliche Entropie für die Temperatur von der Wurzelknoten-Entropie subtrahieren.
G(Temperature) = S — I(Temperature) = 0.94–0.911 = 0.029
Ebenso berechnen wir die Verstärkung aus allen vier Merkmalen und wählen die 1 mit der maximalen Verstärkung aus.
G(WindSpeed) = S — I(WindSpeed) = 0.94–0.892 =0.048
G(Outlook) = S — I(Outlook) = 0.94–0.693 =0.247
G(Humidity) = S — I(Humidity) = 0.94–0.788 =0.152
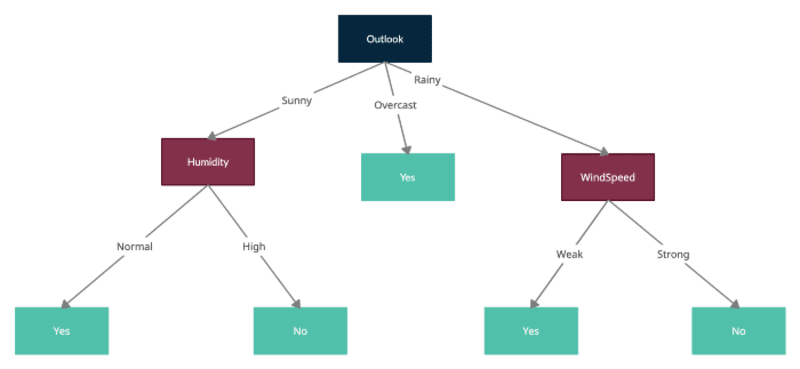
Outlook hat den maximalen Informationsgewinn, daher würden wir den Root-Knoten in Outlook aufteilen und jeder für die untergeordneten Knoten stellt die Probe dar, die durch einen der Werte von Outlook gefiltert wird, dh sonnig, bewölkt und regnerisch.
Jetzt würden wir denselben Vorgang wiederholen, indem wir die neuen Knoten, die als Wurzelknoten gebildet wurden, mit gefilterten Stichproben behandeln und die Entropien für jeden berechnen und die Aufteilungen testen, indem wir die durchschnittliche Entropie für jede weitere Aufteilung berechnen und diese von der aktuellen Knotenentropie subtrahieren, um den Informationsgewinn zu erhalten. Bitte beachten Sie, dass ID3 die Verwendung bereits verwendeter Funktionen zum Teilen von untergeordneten Knoten nicht zulässt. Somit kann jedes Merkmal nur einmal in einem Baum für die Aufteilung verwendet werden.
Hier ist der letzte Baum, der durch alle Teilungen gebildet wird:
Eine einfache Implementierung mit Python-Code ist zu finden hier
Zusammenfassung
Ich habe mein Bestes versucht, die Funktionsweise von ID3 zu erklären, aber ich weiß, dass Sie vielleicht Fragen haben. Bitte lassen Sie es mich in den Kommentaren wissen und ich würde mich freuen, sie alle zu nehmen.
Danke fürs Lesen!
Ankit Malik baut skalierbare KI/ML-Lösungen für mehrere Bereiche wie Marketing, Lieferkette, Einzelhandel, Werbung und Prozessautomatisierung. Er hat an beiden Enden des Spektrums gearbeitet, von führenden Data-Science-Projekten in Fortune-500-Unternehmen bis hin zum Gründungsmitglied eines Data-Science-Inkubators in mehreren Start-ups. Er hat verschiedene innovative Produkte und Dienstleistungen entwickelt und glaubt an dienende Führung.
Original. Mit Genehmigung erneut veröffentlicht.

