Als ich vor ein paar Jahren anfing, Datenanalyse zu lernen, lernte ich als Erstes SQL und Pandas. Als Datenanalyst ist es von entscheidender Bedeutung, über fundierte Kenntnisse in der Arbeit mit SQL und Pandas zu verfügen. Bei beiden handelt es sich um leistungsstarke Tools, die Datenanalysten dabei helfen, gespeicherte Daten in Datenbanken effizient zu analysieren und zu bearbeiten.
Überblick über SQL und Pandas
SQL (Structured Query Language) ist eine Programmiersprache zur Verwaltung und Bearbeitung relationaler Datenbanken. Andererseits ist Pandas eine Python-Bibliothek, die zur Datenmanipulation und -analyse verwendet wird.
Bei der Datenanalyse wird mit großen Datenmengen gearbeitet, und zur Speicherung dieser Daten werden häufig Datenbanken verwendet. SQL und Pandas bieten leistungsstarke Tools für die Arbeit mit Datenbanken, die es Datenanalysten ermöglichen, Daten effizient zu extrahieren, zu bearbeiten und zu analysieren. Durch den Einsatz dieser Tools können Datenanalysten wertvolle Erkenntnisse aus Daten gewinnen, die sonst schwer zu gewinnen wären.
In diesem Artikel erfahren Sie, wie Sie SQL und Pandas zum Lesen und Schreiben in eine Datenbank verwenden.
Anbindung an die DB
Installieren der Bibliotheken
Wir müssen zunächst die notwendigen Bibliotheken installieren, bevor wir mit Pandas eine Verbindung zur SQL-Datenbank herstellen können. Die beiden wichtigsten erforderlichen Bibliotheken sind Pandas und SQLAlchemy. Pandas ist eine beliebte Datenbearbeitungsbibliothek, die die Speicherung großer Datenstrukturen ermöglicht, wie in der Einleitung erwähnt. Im Gegensatz dazu bietet SQLAlchemy eine API für die Verbindung zur SQL-Datenbank und die Interaktion mit ihr.
Wir können beide Bibliotheken mit dem Python-Paketmanager pip installieren, indem wir die folgenden Befehle an der Eingabeaufforderung ausführen.
$ pip install pandas
$ pip install sqlalchemy
Herstellen der Verbindung
Nachdem die Bibliotheken installiert sind, können wir nun Pandas verwenden, um eine Verbindung zur SQL-Datenbank herzustellen.
Zunächst erstellen wir ein SQLAlchemy-Engine-Objekt mit create_engine()dem „Vermischten Geschmack“. Seine create_engine() Die Funktion verbindet den Python-Code mit der Datenbank. Als Argument wird eine Verbindungszeichenfolge verwendet, die den Datenbanktyp und die Verbindungsdetails angibt. In diesem Beispiel verwenden wir den SQLite-Datenbanktyp und den Pfad der Datenbankdatei.
Erstellen Sie anhand des folgenden Beispiels ein Engine-Objekt für eine SQLite-Datenbank:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
Wenn sich die SQLite-Datenbankdatei, in unserem Fall student.db, im selben Verzeichnis wie das Python-Skript befindet, können wir den Dateinamen direkt verwenden, wie unten gezeigt.
engine = create_engine('sqlite:///student.db')
Lesen von SQL-Dateien mit Pandas
Lesen wir nun die Daten, nachdem wir eine Verbindung hergestellt haben. In diesem Abschnitt werden wir uns mit dem befassen read_sql, read_sql_table und read_sql_query Funktionen und deren Verwendung für die Arbeit mit einer Datenbank.
Ausführen von SQL-Abfragen mit Panda read_sql() Funktion
Das read_sql() ist eine Pandas-Bibliotheksfunktion, die es uns ermöglicht, eine SQL-Abfrage auszuführen und die Ergebnisse in einen Pandas-Datenrahmen abzurufen. Der read_sql() Die Funktion verbindet SQL und Python und ermöglicht es uns, die Leistungsfähigkeit beider Sprachen zu nutzen. Die Funktion wird umgebrochen read_sql_table() und read_sql_query()dem „Vermischten Geschmack“. Seine read_sql() Die Funktion wird intern basierend auf der bereitgestellten Eingabe weitergeleitet. Das heißt, wenn die Eingabe eine SQL-Abfrage ausführen soll, wird sie weitergeleitet read_sql_query(), und wenn es sich um eine Datenbanktabelle handelt, wird sie weitergeleitet read_sql_table().
Das read_sql() Syntax ist wie folgt:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
SQL- und Con-Parameter sind erforderlich; der Rest ist optional. Wir können das Ergebnis jedoch mithilfe dieser optionalen Parameter manipulieren. Schauen wir uns jeden Parameter genauer an.
sql: SQL-Abfrage- oder Datenbanktabellennamecon: Verbindungsobjekt oder Verbindungs-URLindex_col: Mit diesem Parameter können wir eine oder mehrere Spalten aus dem SQL-Abfrageergebnis als Datenrahmenindex verwenden. Es kann entweder eine einzelne Spalte oder eine Liste von Spalten enthalten.coerce_float: Dieser Parameter gibt an, ob nicht numerische Werte in Gleitkommazahlen konvertiert oder als Zeichenfolgen belassen werden sollen. Standardmäßig ist es auf „true“ gesetzt. Wenn möglich, werden nicht-numerische Werte in Float-Typen konvertiert.params: Die Parameter bieten eine sichere Methode zur Übergabe dynamischer Werte an die SQL-Abfrage. Wir können den Parameter params verwenden, um ein Wörterbuch, ein Tupel oder eine Liste zu übergeben. Abhängig von der Datenbank variiert die Syntax der Parameter.parse_dates: Damit können wir angeben, welche Spalte im resultierenden Datenrahmen als Datum interpretiert wird. Es akzeptiert eine einzelne Spalte, eine Liste von Spalten oder ein Wörterbuch mit dem Schlüssel als Spaltennamen und dem Wert als Spaltenformat.columns: Dadurch können wir nur ausgewählte Spalten aus der Liste abrufen.chunksize: Bei der Arbeit mit einem großen Datensatz ist die Blockgröße wichtig. Es ruft das Abfrageergebnis in kleineren Blöcken ab und verbessert so die Leistung.
Hier ist ein Beispiel für die Verwendung read_sql():
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
Ausgang:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
Nachdem wir eine Verbindung zur Datenbank hergestellt haben, führen wir eine Abfrage aus, die alle Datensätze aus der zurückgibt Student Tabelle und speichert sie im DataFrame df. Die Spalte „Rollennummer“ wird mit in einen Index umgewandelt index_col Parameter und der Datentyp „dateOfBirth“ ist aufgrund von „datetime64[ns]“. parse_dates. Wir können benutzen read_sql() nicht nur zum Abrufen von Daten, sondern auch zum Ausführen anderer Vorgänge wie Einfügen, Löschen und Aktualisieren. read_sql() ist eine generische Funktion.
Laden bestimmter Tabellen oder Ansichten aus der Datenbank
Laden einer bestimmten Tabelle oder Ansicht mit Pandas read_sql_table() ist eine weitere Technik, um Daten aus der Datenbank in einen Pandas-Datenrahmen einzulesen.
Was ist read_sql_table?
Die Pandas-Bibliothek bietet die read_sql_table Funktion, die speziell dafür entwickelt wurde, eine gesamte SQL-Tabelle zu lesen, ohne Abfragen auszuführen, und das Ergebnis als Pandas-Datenrahmen zurückzugeben.
Die Syntax von read_sql_table() ist wie folgt:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
Außer für table_name und Schema, die Parameter werden auf die gleiche Weise erklärt wie read_sql().
table_name: Der Parametertable_nameist der Name der SQL-Tabelle in der Datenbank.schema: Dieser optionale Parameter ist der Name des Schemas, das den Tabellennamen enthält.
Nachdem wir eine Verbindung zur Datenbank hergestellt haben, verwenden wir die read_sql_table Funktion zum Laden der Student Tabelle in einen Pandas DataFrame.
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
Ausgang:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
Wir gehen davon aus, dass es sich um eine große Tabelle handelt, die speicherintensiv sein kann. Lassen Sie uns untersuchen, wie wir das nutzen können chunksize Parameter, um dieses Problem zu beheben.
Sehen Sie sich unseren praxisnahen, praktischen Leitfaden zum Erlernen von Git an, mit Best Practices, branchenweit akzeptierten Standards und einem mitgelieferten Spickzettel. Hören Sie auf, Git-Befehle zu googeln und tatsächlich in Verbindung, um es!
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
Ausgang:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
Bitte bedenken Sie, dass die chunksize Ich verwende hier 1, weil ich nur 3 Datensätze in meiner Tabelle habe.
Direktes Abfragen der Datenbank mit der SQL-Syntax von Pandas
Das Extrahieren von Erkenntnissen aus der Datenbank ist ein wichtiger Teil für Datenanalysten und Wissenschaftler. Dazu nutzen wir die read_sql_query() Funktion.
Was ist read_sql_query()?
Verwendung von Pandas read_sql_query() Mit dieser Funktion können wir SQL-Abfragen ausführen und die Ergebnisse direkt in einen DataFrame übertragen. Der read_sql_query() Die Funktion wurde speziell für erstellt SELECT Aussagen. Es kann nicht für andere Vorgänge verwendet werden, z DELETE or UPDATE.
Syntax:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
Alle Parameterbeschreibungen sind die gleichen wie die read_sql() Funktion. Hier ist ein Beispiel dafür read_sql_query():
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
Ausgang:
firstName lastName
0 Mark Simson
SQL-Dateien mit Pandas schreiben
Angenommen, wir haben bei der Datenanalyse festgestellt, dass einige Einträge geändert werden müssen oder dass eine neue Tabelle oder Ansicht mit den Daten erforderlich ist. Um einen neuen Datensatz zu aktualisieren oder einzufügen, gibt es eine Methode read_sql() und schreibe eine Anfrage. Allerdings kann diese Methode langwierig sein. Pandas bieten eine großartige Methode namens to_sql() für Situationen wie diese.
In diesem Abschnitt erstellen wir zunächst eine neue Tabelle in der Datenbank und bearbeiten dann eine vorhandene.
Erstellen einer neuen Tabelle in der SQL-Datenbank
Bevor wir eine neue Tabelle erstellen, besprechen wir zunächst to_sql() im Detail.
Was ist to_sql()?
Das to_sql() Mit der Funktion der Pandas-Bibliothek können wir die Datenbank schreiben oder aktualisieren. Der to_sql() Die Funktion kann DataFrame-Daten in einer SQL-Datenbank speichern.
Syntax für to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Nur name und con Parameter sind für die Ausführung zwingend erforderlich to_sql(); Andere Parameter bieten jedoch zusätzliche Flexibilität und Anpassungsmöglichkeiten. Lassen Sie uns jeden Parameter im Detail besprechen:
name: Der Name der SQL-Tabelle, die erstellt oder geändert werden soll.con: Das Verbindungsobjekt der Datenbank.schema: Das Schema der Tabelle (optional).if_exists: Der Standardwert dieses Parameters ist „fail“. Mit diesem Parameter können wir entscheiden, welche Aktion ausgeführt werden soll, wenn die Tabelle bereits vorhanden ist. Zu den Optionen gehören „fehlschlagen“, „ersetzen“ und „anhängen“.index: Der Indexparameter akzeptiert einen booleschen Wert. Standardmäßig ist es auf True gesetzt, was bedeutet, dass der Index des DataFrame in die SQL-Tabelle geschrieben wird.index_label: Mit diesem optionalen Parameter können wir eine Spaltenbezeichnung für die Indexspalten angeben. Standardmäßig wird der Index in die Tabelle geschrieben, mit diesem Parameter kann jedoch ein bestimmter Name vergeben werden.chunksize: Die Anzahl der Zeilen, die gleichzeitig in die SQL-Datenbank geschrieben werden sollen.dtype: Dieser Parameter akzeptiert ein Wörterbuch mit Schlüsseln als Spaltennamen und Werten als Datentypen.method: Der Methodenparameter ermöglicht die Angabe der Methode, die zum Einfügen von Daten in die SQL verwendet wird. Standardmäßig ist es auf „Keine“ eingestellt, was bedeutet, dass Pandas basierend auf der Datenbank den effizientesten Weg findet. Es gibt zwei Hauptoptionen für Methodenparameter:multi: Es ermöglicht das Einfügen mehrerer Zeilen in eine einzelne SQL-Abfrage. Allerdings unterstützen nicht alle Datenbanken das Einfügen mehrerer Zeilen.- Aufrufbare Funktion: Hier können wir eine benutzerdefinierte Funktion zum Einfügen schreiben und sie mithilfe von Methodenparametern aufrufen.
Hier ist ein Beispiel mit to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
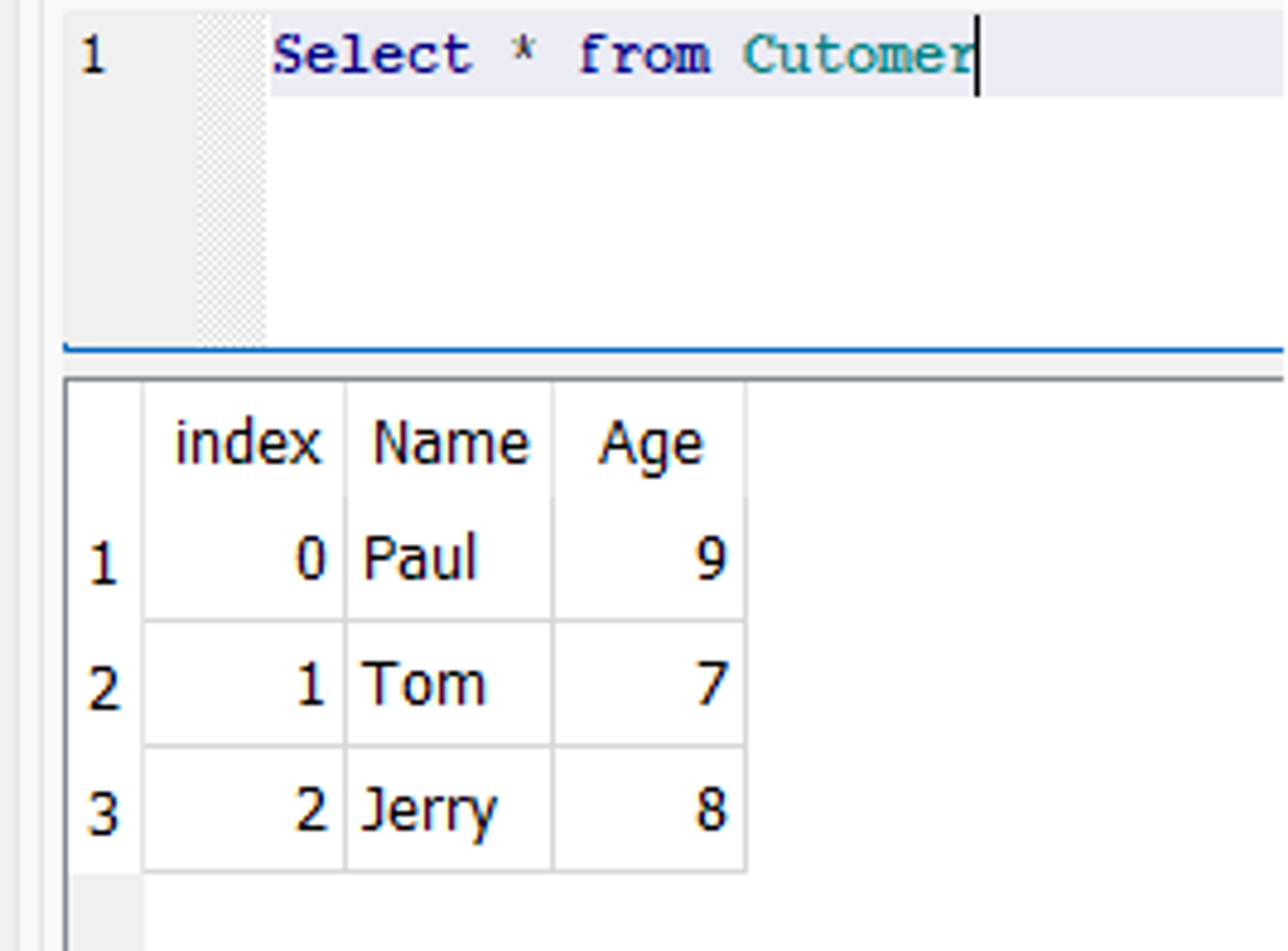
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
In der Datenbank wird eine neue Tabelle namens „Kunde“ mit zwei Feldern namens „Name“ und „Alter“ erstellt.
Datenbank-Snapshot:
Vorhandene Tabellen mit Pandas-Datenrahmen aktualisieren
Das Aktualisieren von Daten in einer Datenbank ist eine komplexe Aufgabe, insbesondere wenn es um große Datenmengen geht. Allerdings mit der to_sql() Die Funktion in Pandas kann diese Aufgabe erheblich erleichtern. Um die vorhandene Tabelle in der Datenbank zu aktualisieren, muss die to_sql() Funktion kann mit dem verwendet werden if_exists Parameter auf „ersetzen“ eingestellt. Dadurch wird die vorhandene Tabelle mit den neuen Daten überschrieben.
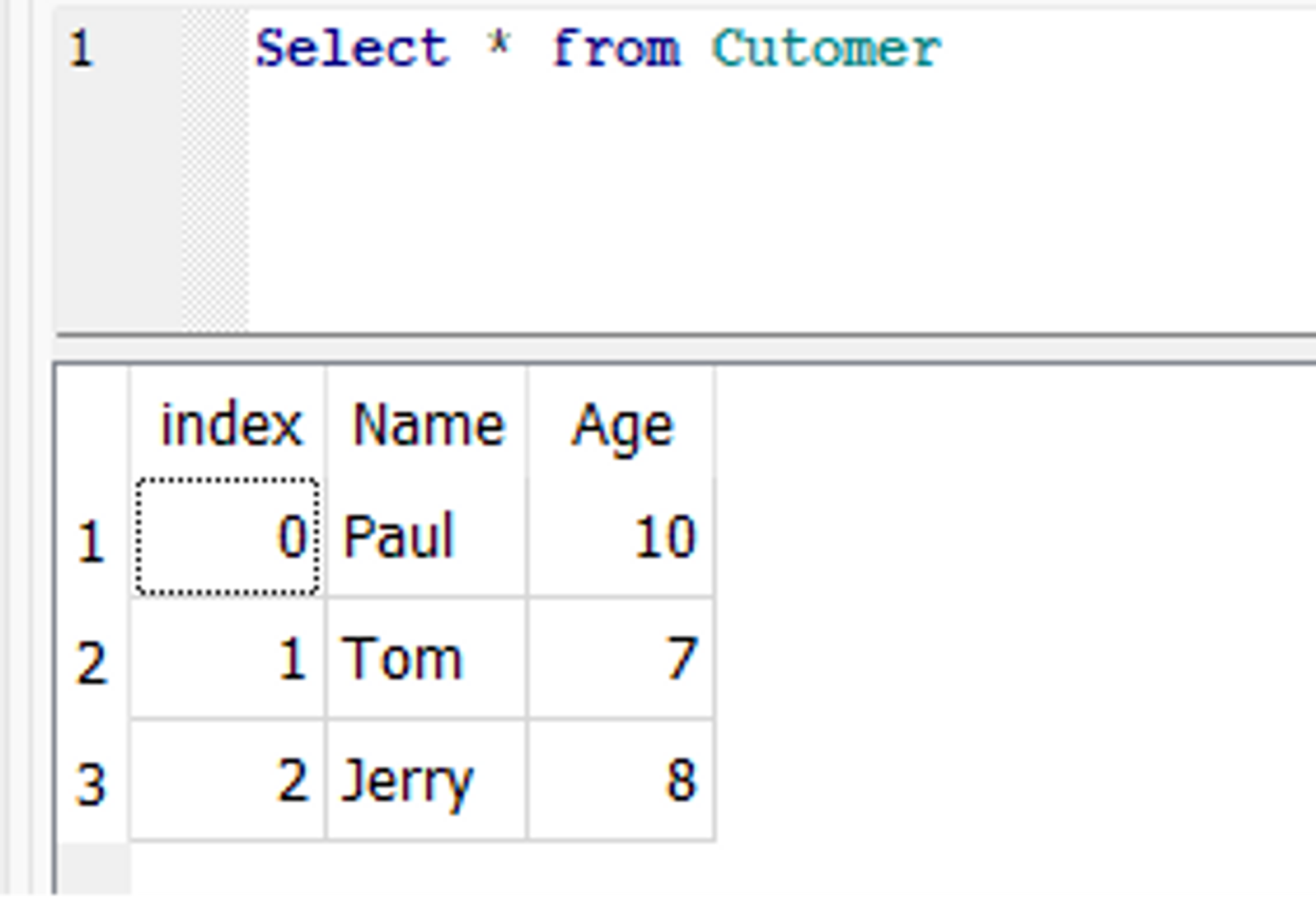
Hier ist ein Beispiel für to_sql() Dadurch wird das zuvor erstellte aktualisiert Customer Tisch. Angenommen, in der Customer In der Tabelle möchten wir das Alter eines Kunden namens Paul von 9 auf 10 aktualisieren. Dazu können wir zunächst die entsprechende Zeile im DataFrame ändern und dann die verwenden to_sql() Funktion zum Aktualisieren der Datenbank.
Code:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
In der Datenbank wird Pauls Alter aktualisiert:
Zusammenfassung
Zusammenfassend lässt sich sagen, dass sowohl Pandas als auch SQL leistungsstarke Tools für Datenanalyseaufgaben wie das Lesen und Schreiben von Daten in die SQL-Datenbank sind. Pandas bietet eine einfache Möglichkeit, eine Verbindung zur SQL-Datenbank herzustellen, Daten aus der Datenbank in einen Pandas-Datenrahmen zu lesen und Datenrahmendaten zurück in die Datenbank zu schreiben.
Die Pandas-Bibliothek erleichtert die Bearbeitung von Daten in einem Datenrahmen, während SQL eine leistungsstarke Sprache zum Abfragen von Daten in einer Datenbank bereitstellt. Die Verwendung von Pandas und SQL zum Lesen und Schreiben der Daten kann Zeit und Aufwand bei Datenanalyseaufgaben sparen, insbesondere wenn die Daten sehr groß sind. Insgesamt kann die gemeinsame Nutzung von SQL und Pandas Datenanalysten und Wissenschaftlern dabei helfen, ihren Arbeitsablauf zu optimieren.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoAiStream. Web3-Datenintelligenz. Wissen verstärkt. Hier zugreifen.
- Die Zukunft prägen mit Adryenn Ashley. Hier zugreifen.
- Kaufen und verkaufen Sie Anteile an PRE-IPO-Unternehmen mit PREIPO®. Hier zugreifen.
- Quelle: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

