Einleitung
Daten sind Treibstoff für die IT-Branche und die Data Science-Projekt in der heutigen Online-Welt. Die IT-Branche ist stark auf Echtzeit-Erkenntnisse angewiesen Streaming-Daten Quellen. Die Handhabung und Verarbeitung der Streaming-Daten ist die härteste Arbeit Datenanalyse. Wir wissen, dass es sich bei Streaming-Daten um Daten handelt, die in großer Menge in einer kontinuierlichen Verarbeitung ausgegeben werden, was bedeutet, dass sich die Daten jede Sekunde ändern. Zur Verarbeitung dieser Daten verwenden wir Confluent-Plattform – Eine selbstverwaltete, unternehmenstaugliche Distribution von Apache Kafka.
Kafka ist ein verteilter, von der Architektur bewältigbarer Fehler, der als beliebte Wahl für die Verwaltung von Datenströmen mit hohem Durchsatz dient. Die Daten von Kafka werden dann im gesammelt MongoDB in Form von Sammlungen. In diesem Artikel erstellen wir die End-to-End-Pipeline, in der Daten mit Hilfe der API in der Pipeline abgerufen und dann in Kafka in Form von Themen gesammelt und dann in MongoDB gespeichert werden, von wo aus wir sie verwenden können im Projekt oder führen Sie das Feature-Engineering durch.
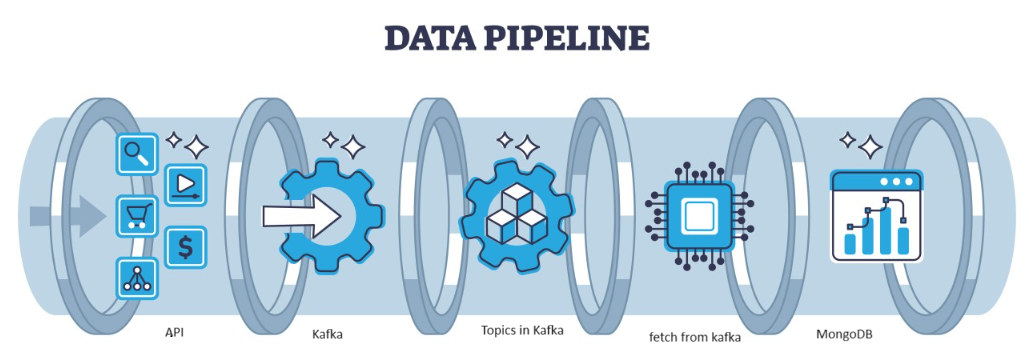
Lernziele
- Erfahren Sie, was Streaming-Daten sind und wie Sie mithilfe von Kafka mit Streaming-Daten umgehen.
- Verstehen Sie die Confluent-Plattform – eine selbstverwaltete, unternehmenstaugliche Distribution von Apache Kafka.
- Speichern Sie die von Kafka gesammelten Daten in der MongoDB, einer NoSQL-Datenbank, die die unstrukturierten Daten speichert.
- Erstellen Sie eine vollständige End-to-End-Pipeline zum Abrufen und Speichern der Daten in der Datenbank.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Identifizieren Sie das Problem
Um die vom Sensor kommenden Streaming-Daten zu verarbeiten, werden pro Sekunde Fahrzeuge erzeugt, die Sensordaten enthalten, und es ist schwierig, die Daten zu verarbeiten und vorzuverarbeiten, um sie zu verwenden Data Science-Projekt. Um dieses Problem anzugehen, erstellen wir die End-to-End-Pipeline, die die Daten verarbeitet und speichert.
Was sind Streaming-Daten?
Daten streamen sind Daten, die kontinuierlich von verschiedenen Quellen generiert werden und bei denen es sich um unstrukturierte Daten handelt. Es bezieht sich auf einen kontinuierlichen Datenfluss, der aus verschiedenen Quellen in Echtzeit oder nahezu in Echtzeit generiert wird. Bei der herkömmlichen Stapelverarbeitung werden Daten erfasst und diese Streaming-Daten bei ihrer Generierung verarbeitet. Bei Streaming-Daten kann es sich um IOT-Daten wie Temperatursensoren und GPS-Tracker oder um Maschinendaten handeln. Diese Daten werden von Maschinen und Industrieanlagen generiert, etwa Telemetriedaten von Fahrzeugen und Fertigungsmaschinen. Es gibt Streaming-Datenverarbeitungsplattformen wie Apache-Kafka.
Was ist Kafka?
Apache Kafka ist eine Plattform zum Aufbau von Echtzeit-Datenpipelines und Streaming-Anwendungen. Die Kafka Streams API ist eine leistungsstarke Bibliothek, die eine spontane Verarbeitung ermöglicht, sodass Sie Fensterparameter sammeln und erstellen, Daten innerhalb eines Streams verknüpfen und vieles mehr können. Apache Kafka besteht aus einer Speicherschicht und einer Rechenschicht, die effiziente Datenaufnahme in Echtzeit, Streaming-Datenpipelines und systemübergreifende Speicherung kombiniert.
Wie wird der Ansatz aussehen?
Hierbei handelt es sich um eine Pipeline für maschinelles Lernen, die uns dabei hilft, die Daten im JSON-Format in und aus Kafka Confluent zu veröffentlichen und zu verarbeiten. Es gibt zwei Teile der Kafka-Datenverarbeitung: Verbraucher und Produzent. Um die Streaming-Daten von den verschiedenen Produzenten zu speichern und sie in Confluent zu speichern, wird dann eine Deserialisierung der Daten durchgeführt und diese Daten werden in der Datenbank gespeichert.
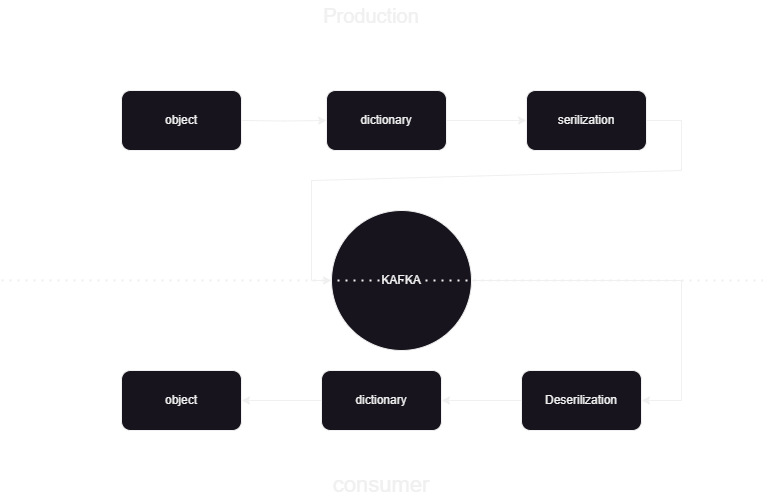
Überblick über die Systemarchitektur
Wir verarbeiten die Streaming-Daten mit Hilfe von Confluent Kafka und das Kafka ist in zwei Teile unterteilt:
- Kafka-Produzent: Der Kafka-Produzent ist für die Produktion und den Versand von Daten an Kafka-Themen verantwortlich.
- Kafka Consumer: Kafka Consumer soll Daten aus den Kafka-Themen lesen und verarbeiten.
Start
│
├─ Kafka Consumer (Read from Kafka Topic)
│ ├─ Process Message
│ └─ Store Data in MongoDB
│
├─ Kafka Producer (Generate Sensor Data)
│ ├─ Send Data to Kafka Topic
│ └─ Repeat
│
End
Was sind Komponenten?
- Themen: Themen sind logische Kanäle oder Kategorien, die von Produzenten veröffentlicht werden. Jedes Thema ist in eine oder mehrere Partitionen unterteilt und jedes Thema wird aus Gründen der Fehlertoleranz über mehrere Broker repliziert. Produzenten veröffentlichen Daten zu bestimmten Themen und Verbraucher abonnieren Themen, um Daten zu nutzen.
- Hersteller: Ein Apache Kafka Producer ist eine Clientanwendung, die Ereignisse in einem Kafka-Cluster veröffentlicht (schreibt). Anwendungen, die Daten an Themen senden, werden als Kafka-Produzenten bezeichnet. Dieser Abschnitt gibt einen Überblick über den Kafka-Produzenten.
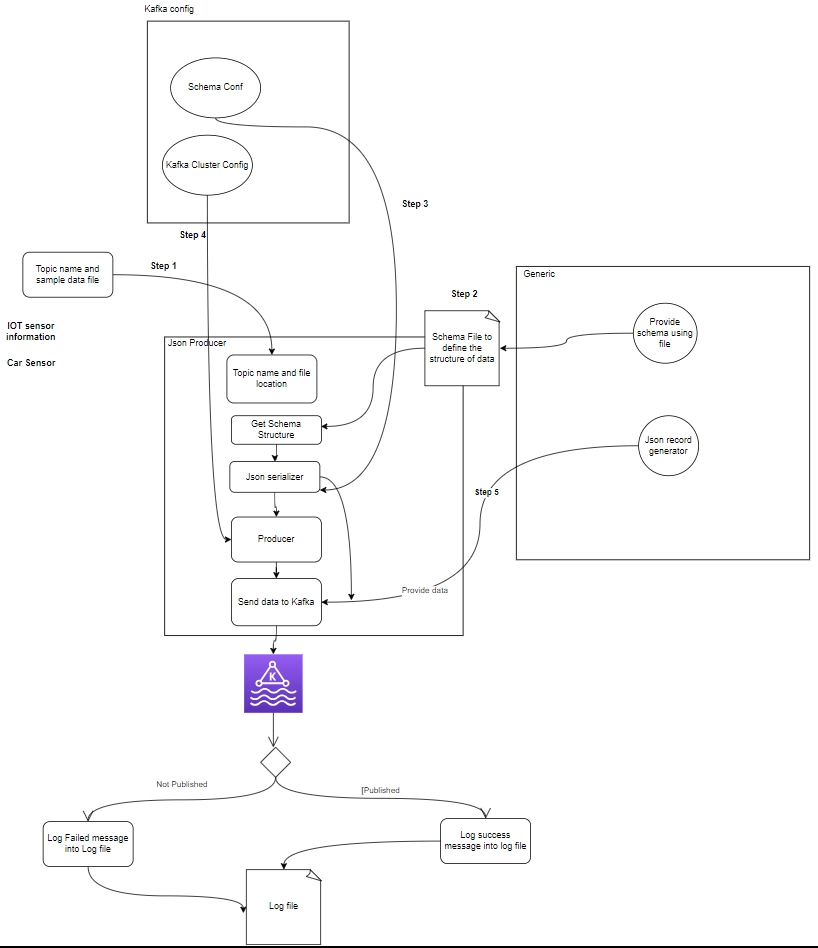
- Verbraucher: Kafka-Konsumenten sind dafür verantwortlich, Daten aus Kafka-Themen zu lesen, zu verarbeiten und zu verarbeiten. Verbraucher können Teil jeder Anwendung sein, die Daten von Kafka verwenden und darauf reagieren muss. Sie abonnieren ein oder mehrere Themen und Daten von Kafka-Brokern. Verbraucher können in Verbrauchergruppen organisiert werden, wobei jede Verbrauchergruppe einen oder mehrere Verbraucher hat und jedes Thema eines Themas nur von einem Verbraucher innerhalb der Gruppe konsumiert wird. Dies ermöglicht eine parallele Verarbeitung und einen Lastausgleich des Datenverbrauchs.
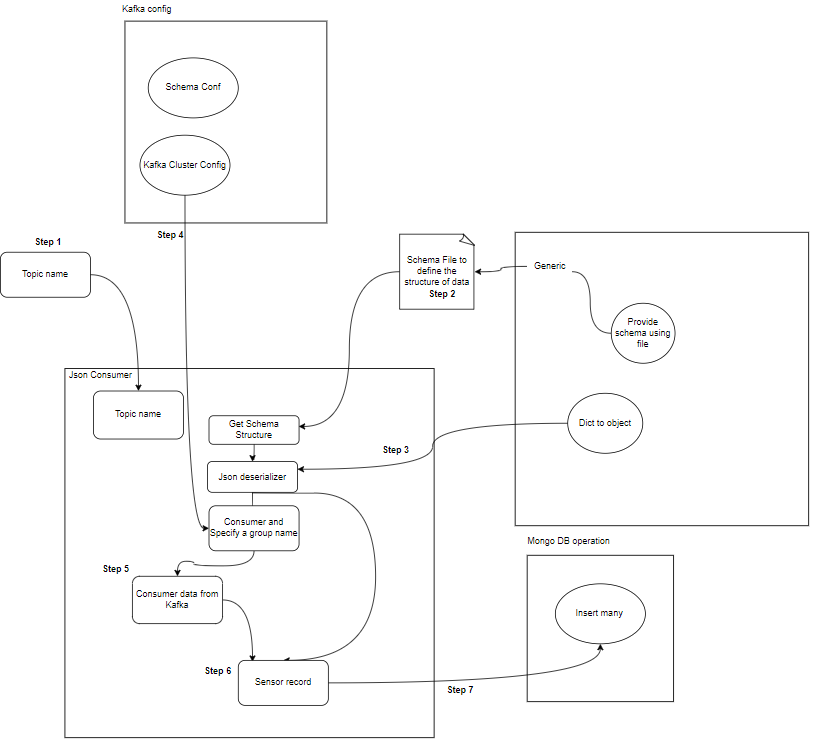
Was ist die Projektstruktur?
Dies zeigt das Flussdiagramm des Projekts, wie der Ordner und die Dateien im Projekt aufgeteilt sind:
flowchart/
│
├── consumer.drawio.svg
├── flow of kafka.drawio
└── producer.drawio.svg
sample_data/
│
└── aps_failure_training_set1.csv
env/
sensor_data-pipeline_kafka
/
│
├── src/
│ ├── database/
│ │ ├── mongodb.py
│ │
│ ├── kafka_config/
│ │ └──__init__.py/
│ │
│ │
│ ├── constant/
│ │ ├── __init__.py
│ │
│ │
│ ├── data_access/
│ │ ├── user_data.py
│ │ └── user_embedding_data.py
│ │
│ ├── entity/
│ │ ├── __init__.py
│ │ └── generic.py
│ │
│ ├── exception/
│ │ └── (exception handling)
│ │
│ ├── kafka_logger/
│ │ └── (logging configuration)
│ │
│ ├── kafka_consumer/
│ │ └── util.py
│ │
│ └── __init__.py
│
└── logs/
└── (log files)
.dockerignore
.gitignore
Dockerfile
schema.json
consumer_main.py
producer_main.py
requirments.txt
setup.py- Kafka-Produzent: Der Produzent ist der Hauptteil, der Sensordaten generiert (z. B. aus CSV-Dateien in sample_data/) und sie in einem Kafka-Topic veröffentlicht. Fehlerbedingungen, die während der Datengenerierung oder -veröffentlichung auftreten können.
- Kafka-Broker: Kafka-Broker speichern und replizieren Daten im gesamten Kafka-Cluster, übernehmen die Datenpartitionierung und stellen Fehlertoleranz und hohe Verfügbarkeit sicher.
- Kafka-Verbraucher: Verbraucher lesen Daten aus Kafka-Themen, verarbeiten sie (z. B. Transformationen, Aggregationen) und speichern sie in MongoDB. Sie überwachen auch Fehlerzustände, die bei der Datenverarbeitung auftreten können.
- MongoDB: MongoDB speichert die von Kafka-Konsumenten empfangenen Sensordaten. Es bietet eine Abfrage zum Datenabruf und gewährleistet die Datenhaltbarkeit durch Replikations- und Fehlertoleranzmechanismen.
Start
│
├── Kafka Producer ──────────────────┐
│ ├── Generate Sensor Data │
│ └── Publish Data to Kafka Topic │
│ │
│ └── Error Handling
│ │
├── Kafka Broker(s) ─────────────────┤
│ ├── Store and Replicate Data │
│ └── Handle Data Partitioning │
│ │
├── Kafka Consumer(s) ───────────────┤
│ ├── Read Data from Kafka Topic │
│ ├── Process Data │
│ └── Store Data in MongoDB │
│ │
│ └── Error Handling
│ │
├── MongoDB ────────────────────────┤
│ ├── Store Sensor Data │
│ ├── Provide Query Interface │
│ └── Ensure Data Durability │
│ │
└── End │
Voraussetzungen für die Datenspeicherung
Konfluenter Kafka
- Konto erstellen: Um Kafka zu verstehen, benötigen Sie Confluent. Sie lieben Apache Kafka®, verwalten es aber nicht. Der Cloud-native, umfassende und vollständig verwaltete Service geht weit über Kafka hinaus, sodass sich Ihre besten Mitarbeiter auf die Wertschöpfung für Ihr Unternehmen konzentrieren können.
- Themen erstellen:
- Gehen Sie zur Startseite und zur Seitenleiste
- Gehen Sie zu Umgebung und klicken Sie dann auf Standard
- Gehen Sie zu den Themen

- Wählen Sie „Neues Thema“ und geben Sie den Namen des Themas ein

MongoDB
Erstellen Sie eine Registrierung, melden Sie sich dann beim MongoDB-Atlas an und speichern Sie den Verbindungslink des Mongodb-Atlas zur weiteren Verwendung.
Schritt-für-Schritt-Anleitung für die Projekteinrichtung
- Python-Installation: Stellen Sie sicher, dass Python auf Ihrem Computer installiert ist. Sie können es herunterladen und installieren Python von der offiziellen Website.
- Conda-Version: Überprüfen Sie die Conda-Version im Terminal.
- Erstellung einer virtuellen Umgebung: Erstellen Sie eine virtuelle Umgebung mit venv.
conda create -p venv python==3.10 -y- Aktivierung der virtuellen Umgebung: Aktivieren Sie die virtuelle Umgebung:
conda activate venv/- Erforderliche Pakete installieren: Verwenden Sie pip, um die erforderlichen Abhängigkeiten zu installieren, die in der Datei „requirements.txt“ aufgeführt sind:
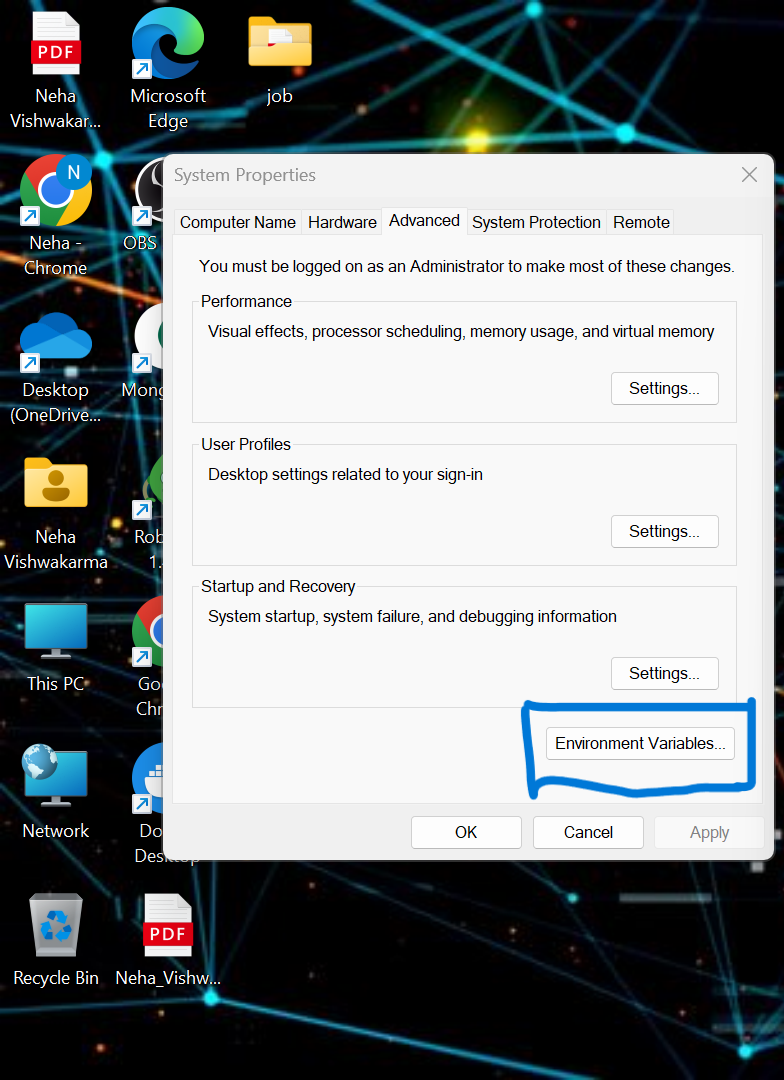
pip install -r requirements.txt- Wir müssen einige der Umgebungsvariablen im lokalen System festlegen. Dies ist die konfluente Cloud-Cluster-Umgebungsvariable
API_KEY
API_SECRET_KEY
BOOTSTRAP_SERVER
SCHEMA_REGISTRY_API_KEY
SCHEMA_REGISTRY_API_SECRET
ENDPOINT_SCHEMA_URL
Aktualisieren Sie die Anmeldeinformationen in der .env-Datei und führen Sie den folgenden Befehl aus, um Ihre Anwendung im Docker auszuführen.
- Erstellen Sie eine .env-Datei im Stammverzeichnis Ihres Projekts, falls diese nicht verfügbar ist, fügen Sie den folgenden Inhalt ein und aktualisieren Sie die Anmeldeinformationen
API_KEY=asgdakhlsa
API_SECRET_KEY=dsdfsdf
BOOTSTRAP_SERVER=sdfasd
SCHEMA_REGISTRY_API_KEY=sdfsaf
SCHEMA_REGISTRY_API_SECRET=sdfasdf
ENDPOINT_SCHEMA_URL=sdafasf
MONGO_DB_URL=sdfasdfas
- Ausführen der Producer- und Consumer-Datei:
python producer_main.py
python consumer_main.pyWie implementiert man Code?
- src/: Dieses Verzeichnis ist der Hauptordner für alle Quellcodedateien. Innerhalb dieses Verzeichnisses haben wir die folgenden Unterverzeichnisse:
Consumer/: Dieses Verzeichnis enthält den Code für den Kafka_consumer, der für das Lesen von Daten aus Kafka-Themen und deren Verarbeitung verantwortlich ist.
Produzent/: Dieses Verzeichnis enthält den Code für den Kafka_producer, der für die Generierung und das Senden von Sensordaten an Kafka-Themen verantwortlich ist. - README.md: Diese Markdown-Datei enthält Dokumentation und Anweisungen für das Projekt, einschließlich einer Übersicht über seinen Zweck, der Anweisungen, Nutzungsrichtlinien und jeglicher Informationen.
- Anforderungen.txt: In dieser Datei ist die für das Projekt erforderliche Python-Bibliothek aufgeführt. Jede Abhängigkeit wird zusammen mit ihrer Versionsnummer aufgelistet. Tools wie pip können diese Datei verwenden, um die erforderlichen Abhängigkeiten automatisch zu installieren.
sensor_data-pipeline_kafka/
│
├── src/
│ ├── consumer/
│ │ ├── __init__.py
│ │ └── kafka_consumer.py
│ │
│ ├── producer/
│ │ ├── __init__.py
│ │ └── kafka_producer.py
│ │
│ └── __init__.py
│
├── README.md
└── requirements.txt
mongodb.py: Um die MongoDB Altas über den Link zu verbinden, schreiben wir das Python-Skript
import pymongo
import os
import certifi
ca = certifi.where()
db_link ="mongodb+srv://Neha:<password>@cluster0.jsogkox.mongodb.net/"
class MongodbOperation:
def __init__(self) -> None:
#self.client = pymongo.MongoClient(os.getenv('MONGO_DB_URL'),tlsCAFile=ca)
self.client = pymongo.MongoClient(db_link,tlsCAFile=ca)
self.db_name="NehaDB"
def insert_many(self,collection_name,records:list):
self.client[self.db_name][collection_name].insert_many(records)
def insert(self,collection_name,record):
self.client[self.db_name][collection_name].insert_one(record)
Geben Sie Ihre URL ein, die eine Kopie aus MongoDb Altas ist
Ausgang:
from src.kafka_producer.json_producer import product_data_using_file
from src.constant import SAMPLE_DIR
import os
if __name__ == '__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
product_data_using_file(topic=topic,file_path=sample_file_path)
Diese Datei wird ausgeführt, dann rufen wir die auf Python-Produzent_main.py und dies wird die folgende Datei aufrufen:
import argparse
from uuid import uuid4
from src.kafka_config import sasl_conf, schema_config
from six.moves import input
from src.kafka_logger import logging
from confluent_kafka import Producer
from confluent_kafka.serialization import StringSerializer, SerializationContext, MessageField
from confluent_kafka.schema_registry import SchemaRegistryClient
from confluent_kafka.schema_registry.json_schema import JSONSerializer
import pandas as pd
from typing import List
from src.entity.generic import Generic, instance_to_dict
FILE_PATH = "C:/Users/RAJIV/Downloads/ml-data-pipeline-main/sample_data/kafka-sensor-topic.csv"
def delivery_report(err, msg):
"""
Reports the success or failure of a message delivery.
Args:
err (KafkaError): The error that occurred on None on success.
msg (Message): The message that was produced or failed.
"""
if err is not None:
logging.info("Delivery failed for User record {}: {}".format(msg.key(), err))
return
logging.info('User record {} successfully produced to {} [{}] at offset {}'
.format(
msg.key(), msg.topic(), msg.partition(), msg.offset()))
def product_data_using_file(topic,file_path):
logging.info(f"Topic: {topic} file_path:{file_path}")
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
schema_registry_conf = schema_config()
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
string_serializer = StringSerializer('utf_8')
json_serializer = JSONSerializer(schema_str, schema_registry_client,
instance_to_dict)
producer = Producer(sasl_conf())
print("Producing user records to topic {}. ^C to exit.".format(topic))
# while True:
# Serve on_delivery callbacks from previous calls to produce()
producer.poll(0.0)
try:
for instance in Generic.get_object(file_path=file_path):
print(instance)
logging.info(f"Topic: {topic} file_path:{instance.to_dict()}")
producer.produce(topic=topic,
key=string_serializer(str(uuid4()), instance.to_dict()),
value=json_serializer(instance,
SerializationContext(topic, MessageField.VALUE)),
on_delivery=delivery_report)
print("nFlushing records...")
producer.flush()
except KeyboardInterrupt:
pass
except ValueError:
print("Invalid input, discarding record...")
pass
Ausgang:

from src.kafka_consumer.json_consumer import consumer_using_sample_file
from src.constant import SAMPLE_DIR
import os
if __name__=='__main__':
topics = os.listdir(SAMPLE_DIR)
print(f'topics: [{topics}]')
for topic in topics:
sample_topic_data_dir = os.path.join(SAMPLE_DIR,topic)
sample_file_path = os.path.join(sample_topic_data_dir,os.listdir(sample_topic_data_dir)[0])
consumer_using_sample_file(topic="kafka-sensor-topic",file_path = sample_file_path)
Diese Datei wird ausgeführt, dann rufen wir die auf python Consumer_main.py und dies wird die folgende Datei aufrufen:
import argparse
from confluent_kafka import Consumer
from confluent_kafka.serialization import SerializationContext, MessageField
from confluent_kafka.schema_registry.json_schema import JSONDeserializer
from src.entity.generic import Generic
from src.kafka_config import sasl_conf
from src.database.mongodb import MongodbOperation
def consumer_using_sample_file(topic,file_path):
schema_str = Generic.get_schema_to_produce_consume_data(file_path=file_path)
json_deserializer = JSONDeserializer(schema_str,
from_dict=Generic.dict_to_object)
consumer_conf = sasl_conf()
consumer_conf.update({
'group.id': 'group7',
'auto.offset.reset': "earliest"})
consumer = Consumer(consumer_conf)
consumer.subscribe([topic])
mongodb = MongodbOperation()
records = []
x = 0
while True:
try:
# SIGINT can't be handled when polling, limit timeout to 1 second.
msg = consumer.poll(1.0)
if msg is None:
continue
record: Generic = json_deserializer(msg.value(),
SerializationContext(msg.topic(), MessageField.VALUE))
# mongodb.insert(collection_name="car",record=car.record)
if record is not None:
records.append(record.to_dict())
if x % 5000 == 0:
mongodb.insert_many(collection_name="sensor", records=records)
records = []
x = x + 1
except KeyboardInterrupt:
break
consumer.close()Ausgang:

Wenn wir sowohl den Verbraucher als auch den Produzenten ausführen, läuft das System auf dem Kafka und die Informationen/Daten werden schneller erfasst

Ausgang:
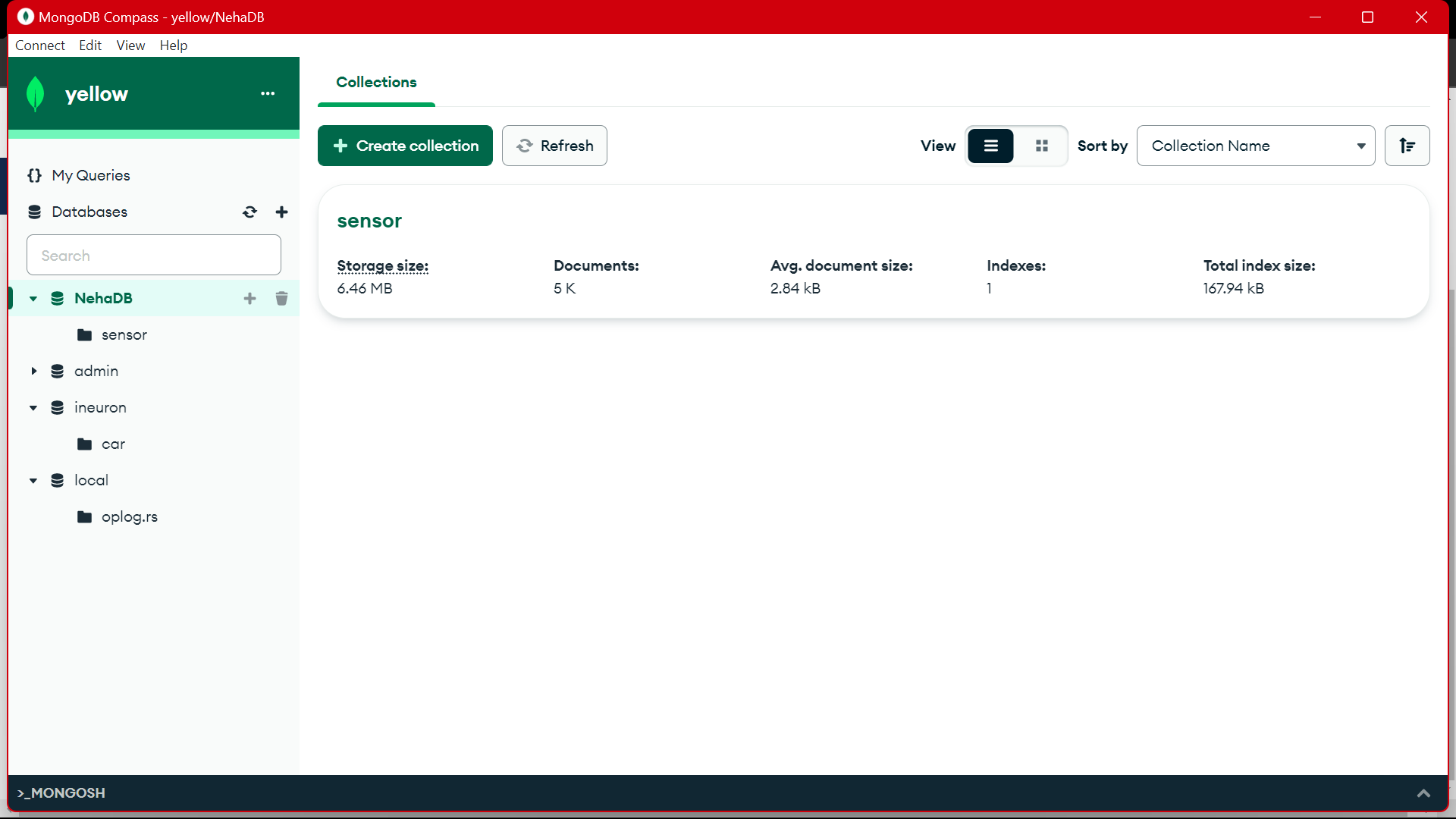
Von MongoDB aus verwenden wir diese Daten für die Vorverarbeitung in EDA. An diesen Daten werden Feature-Engineering- und Datenanalysearbeiten durchgeführt.
[Eingebetteten Inhalt]
Zusammenfassung
In diesem Artikel verstehen wir, wie wir die Streaming-Daten vom Sensor zum Kafka in Form des JSON-Formats speichern und verarbeiten und dann die Daten in MongoDB speichern. Wir wissen, dass es sich bei Streaming-Daten um Daten handelt, die in großer Menge in einer kontinuierlichen Verarbeitung ausgegeben werden, was bedeutet, dass sich die Daten jede Sekunde ändern. Wir haben die End-to-End-Pipeline erstellt, in der Daten mithilfe der API in der Pipeline abgerufen und dann in Kafka in Form von Themen gesammelt und dann in MongoDB gespeichert werden. Von dort aus können wir sie im Projekt verwenden oder ausführen Feature-Engineering.
Key Take Away
- Erfahren Sie, was Streaming-Daten sind und wie Sie mithilfe von Kafka mit Streaming-Daten umgehen.
- Verstehen Sie die Confluent-Plattform – eine selbstverwaltete, unternehmenstaugliche Distribution von Apache Kafka.
- Speichern Sie die von Kafka gesammelten Daten in der MongoDB, einer NoSQL-Datenbank, die die unstrukturierten Daten speichert.
- Erstellen Sie eine vollständige End-to-End-Pipeline zum Abrufen und Speichern der Daten in der Datenbank.
- Verstehen Sie die Funktionalität jeder Komponente des Projekts, implementieren Sie sie im Docker und implementieren Sie sie in einer Cloud, um sie jederzeit verwenden zu können.
Downloads
Häufig gestellte Fragen
A. MongoDB speichert die Daten in unstrukturierten Daten. Streaming-Daten sind unstrukturierte Datenformen zur Speichernutzung. Als Datenbank verwenden wir MongoDB.
A. Der Zweck besteht darin, eine Echtzeit-Datenverarbeitungspipeline zu erstellen, in der in Kafka-Themen aufgenommene Daten zur weiteren Analyse, Berichterstellung oder Anwendungsnutzung genutzt, verarbeitet und in MongoDB gespeichert werden können.
A. Zu den Anwendungsfällen gehören Echtzeitanalysen, IoT-Datenverarbeitung, Protokollaggregation, Social-Media-Überwachung und Empfehlungssysteme, bei denen Streaming-Daten zur weiteren Analyse oder Anwendungsnutzung verarbeitet und gespeichert werden müssen.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/02/kafka-to-mongodb-building-a-streamlined-data-pipeline/

