Einleitung
In der Vergangenheit hat die generative KI den Markt erobert, und als Ergebnis verfügen wir heute über verschiedene Modelle mit unterschiedlichen Anwendungen. Die Evaluierung von Gen AI begann mit der Transformer-Architektur, und diese Strategie wurde seitdem auch in anderen Bereichen übernommen. Nehmen wir ein Beispiel. Wie wir wissen, verwenden wir derzeit das VIT-Modell im Bereich der stabilen Diffusion. Wenn Sie das Modell genauer untersuchen, werden Sie feststellen, dass zwei Arten von Diensten verfügbar sind: kostenpflichtige Dienste und Open-Source-Modelle, deren Nutzung kostenlos ist. Der Benutzer, der auf die zusätzlichen Dienste zugreifen möchte, kann kostenpflichtige Dienste wie OpenAI nutzen, und für das Open-Source-Modell haben wir ein Hugging Face.
Sie können auf das Modell zugreifen und entsprechend Ihrer Aufgabenstellung das jeweilige Modell aus den Diensten herunterladen. Beachten Sie außerdem, dass für Token-Modelle entsprechend dem jeweiligen Dienst in der kostenpflichtigen Version Gebühren anfallen können. Ebenso stellt AWS auch Dienste wie AWS Bedrock bereit, die den Zugriff auf LLM-Modelle über die API ermöglichen. Lassen Sie uns gegen Ende dieses Blogbeitrags die Preise für Dienstleistungen besprechen.
Lernziele
- Generative KI mit Stable Diffusion, LLaMA 2 und Claude-Modellen verstehen.
- Erkundung der Funktionen und Fähigkeiten der Stable Diffusion-, LLaMA 2- und Claude-Modelle von AWS Bedrock.
- Entdecken Sie AWS Bedrock und seine Preise.
- Erfahren Sie, wie Sie diese Modelle für verschiedene Aufgaben wie Bildgenerierung, Textsynthese und Codegenerierung nutzen können.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist generative KI?
Generative KI ist eine Teilmenge der künstlichen Intelligenz (KI), die entwickelt wird, um basierend auf Benutzeranfragen neue Inhalte wie Bilder, Text oder Code zu erstellen. Diese Modelle sind stark auf große Datenmengen trainiert, wodurch die Erstellung von Inhalten oder die Reaktion auf Benutzeranfragen wesentlich genauer und zeitlich weniger komplex wird. Generative KI hat viele Anwendungen in verschiedenen Bereichen, wie z. B. kreative Künste, Inhaltsgenerierung, Datenerweiterung und Problemlösung.
Sie können auf einige meiner Blogs verweisen, die mit LLM-Modellen erstellt wurden, z Chatbot (Gemini Pro) und Automatisierte Feinabstimmung von LLaMA 2-Modellen in der Gradient AI Cloud. Ich habe auch das Hugging Face erstellt BLOOM Modell von Meta zur Entwicklung des Chatbots.
Hauptmerkmale von GenAI
- Inhaltserstellung: LLM-Modelle können neue Inhalte generieren, indem sie die vom Benutzer als Eingabe bereitgestellten Abfragen verwenden, um Text, Bilder oder Code zu generieren.
- Feintuning: Wir können leicht eine Feinabstimmung vornehmen, was bedeutet, dass wir das Modell anhand verschiedener Parameter trainieren können, um die Leistung von LLM-Modellen zu steigern und ihre Leistung zu verbessern.
- Datengesteuertes Lernen: Generative KI-Modelle werden auf großen Datensätzen mit unterschiedlichen Parametern trainiert, sodass sie Muster aus Daten und Trends in den Daten lernen können, um genaue und aussagekräftige Ergebnisse zu generieren.
- Effizienz: Generative KI-Modelle liefern genaue Ergebnisse; Dadurch sparen sie im Vergleich zu manuellen Erstellungsmethoden Zeit und Ressourcen.
- Vielseitigkeit: Diese Modelle sind in allen Bereichen nützlich. Generative KI bietet Anwendungen in verschiedenen Bereichen, darunter kreative Künste, Inhaltsgenerierung, Datenerweiterung und Problemlösung.
Was ist AWS Bedrock?
AWS Bedrock ist eine Plattform von Amazon Web Services (AWS). AWS bietet eine Vielzahl von Diensten und hat daher kürzlich den generativen KI-Dienst Bedrock hinzugefügt, der eine Vielzahl großer Sprachmodelle (LLMs) hinzufügt. Diese Modelle werden für spezifische Aufgaben in verschiedenen Bereichen erstellt. Wir verfügen über verschiedene Modelle wie das Textgenerierungsmodell und das Bildmodell, die von Datenwissenschaftlern nahtlos in Software wie VSCode integriert werden können. Wir können LLMs verwenden, um verschiedene NLP-Aufgaben wie Textgenerierung, Zusammenfassung, Übersetzung und mehr zu trainieren und einzusetzen.
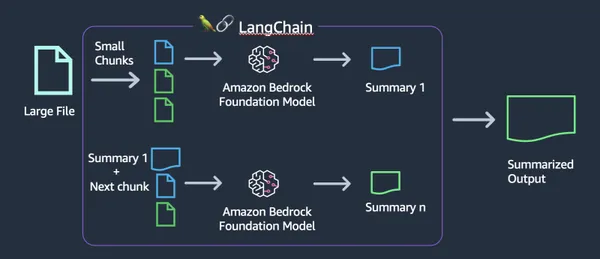
Hauptmerkmale von AWS Bedrock
- Zugriff auf vorab trainierte Modelle: AWS Bedrock bietet viele vorab trainierte LLM-Modelle, die Benutzer problemlos nutzen können, ohne Modelle von Grund auf erstellen oder trainieren zu müssen.
- Feintuning: Benutzer können vorab trainierte Modelle mithilfe ihrer eigenen Datensätze verfeinern, um sie an bestimmte Anwendungsfälle und Domänen anzupassen.
- Skalierbarkeit: AWS Bedrock basiert auf der AWS-Infrastruktur und bietet Skalierbarkeit für die Verarbeitung großer Datenmengen und rechenintensiver KI-Arbeitslasten.
- Umfassende API: Bedrock bietet eine umfassende API, über die wir problemlos mit dem Modell kommunizieren können.
Wie baut man ein AWS-Grundgerüst auf?
Das Einrichten von AWS Bedrock ist einfach und dennoch leistungsstark. Dieses auf Amazon Web Services (AWS) basierende Framework bietet eine zuverlässige Grundlage für Ihre Anwendungen. Lassen Sie uns die einfachen Schritte durchgehen, um loszulegen.
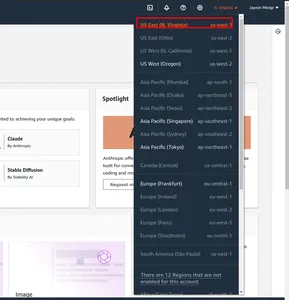
Schritt 1: Navigieren Sie zunächst zur AWS Management Console. Und die Region verändern. Ich habe im roten Kästchen us-east-1 markiert.
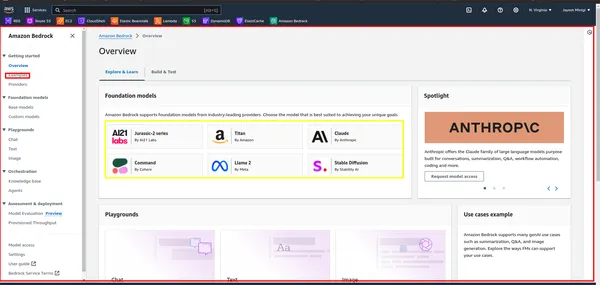
Schritt 2: Suchen Sie anschließend in der AWS Management Console nach „Bedrock“ und klicken Sie darauf. Klicken Sie dann auf die Schaltfläche „Erste Schritte“. Dadurch gelangen Sie zum Bedrock-Dashboard, wo Sie auf die Benutzeroberfläche zugreifen können.
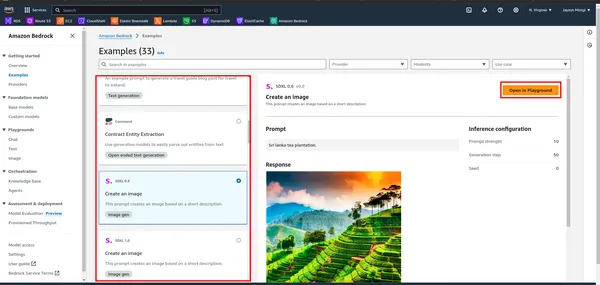
Schritt 3: Im Dashboard sehen Sie ein gelbes Rechteck mit verschiedenen Fundamentmodellen wie LLaMA 2, Claude usw. Klicken Sie auf das rote Rechteck, um Beispiele und Demonstrationen dieser Modelle anzuzeigen.
Schritt 4: Wenn Sie auf das Beispiel klicken, werden Sie zu einer Seite weitergeleitet, auf der Sie ein rotes Rechteck finden. Klicken Sie für Spielplatzzwecke auf eine dieser Optionen.
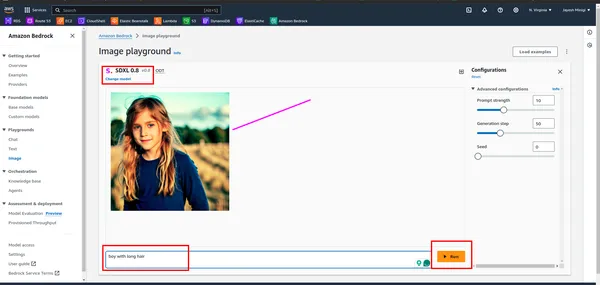
Was ist stabile Diffusion?
Stable Diffusion ist ein GenAI-Modell, das Bilder basierend auf Benutzereingaben (Text) generiert. Benutzer geben Textaufforderungen ein und Stable Diffusion erzeugt entsprechende Bilder, wie im praktischen Teil gezeigt. Es wurde 2022 eingeführt und nutzt Diffusionstechnologie und latenten Raum, um qualitativ hochwertige Bilder zu erstellen.
Nach der Einführung der Transformatorarchitektur in der Verarbeitung natürlicher Sprache (NLP) wurden erhebliche Fortschritte erzielt. In der Computer Vision setzten sich Modelle wie der Vision Transformer (ViT) durch. Während traditionelle Architekturen wie das Encoder-Decoder-Modell üblich waren, übernimmt Stable Diffusion eine Encoder-Decoder-Architektur unter Verwendung von U-Net. Diese architektonische Wahl trägt zu seiner Effektivität bei der Erzeugung hochwertiger Bilder bei.
Bei der stabilen Diffusion wird einem Bild nach und nach Gaußsches Rauschen hinzugefügt, bis nur noch zufälliges Rauschen übrig bleibt – ein Vorgang, der als Vorwärtsdiffusion bezeichnet wird. Anschließend wird dieses Rauschen mithilfe eines Rauschprädiktors umgekehrt, um das Originalbild wiederherzustellen.
Insgesamt stellt Stable Diffusion einen bemerkenswerten Fortschritt in der generativen KI dar und bietet effiziente und qualitativ hochwertige Bilderzeugungsfunktionen.
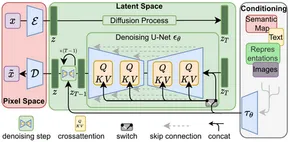
Hauptmerkmale einer stabilen Diffusion
- Bilderzeugung: Stable Diffusion verwendet das VIT-Modell, um Bilder vom Benutzer (Text) als Eingaben zu erstellen.
- Vielseitigkeit: Dieses Modell ist vielseitig, sodass wir es in ihren jeweiligen Bereichen verwenden können. Wir können Bilder, GiF, Videos und Animationen erstellen.
- Effizienz: Stabile Diffusionsmodelle nutzen latenten Raum und erfordern im Vergleich zu anderen Bilderzeugungsmodellen weniger Rechenleistung.
- Feinabstimmungsmöglichkeiten: Benutzer können die stabile Diffusion genau an ihre spezifischen Bedürfnisse anpassen. Durch Anpassen von Parametern wie Rauschunterdrückungsschritten und Geräuschpegeln können Benutzer die Ausgabe entsprechend ihren Vorlieben anpassen.
Einige der Bilder, die mithilfe des stabilen Diffusionsmodells erstellt wurden


Wie baut man eine stabile Diffusion auf?
Um Stable Diffusion zu erstellen, müssen Sie mehrere Schritte ausführen, darunter das Einrichten Ihrer Entwicklungsumgebung, den Zugriff auf das Modell und den Aufruf mit den entsprechenden Parametern.
Schritt 1. Umgebungsvorbereitung
- Erstellung einer virtuellen Umgebung: Erstellen Sie eine virtuelle Umgebung mit venv
conda create -p ./venv python=3.10 -y
- Aktivierung der virtuellen Umgebung: Aktivieren Sie die virtuelle Umgebung
conda activate ./venvSchritt 2. Anforderungspakete installieren
!pip install boto3
!pip install awscliSchritt 3: Einrichten der AWS CLI
- Zunächst müssen Sie einen Benutzer in IAM erstellen und ihm die erforderlichen Berechtigungen, beispielsweise Administratorzugriff, erteilen.
- Befolgen Sie anschließend die folgenden Befehle, um die AWS CLI einzurichten, damit Sie problemlos auf das Modell zugreifen können.
- Konfigurieren Sie AWS-Anmeldeinformationen: Nach der Installation müssen Sie Ihre AWS-Anmeldeinformationen konfigurieren. Öffnen Sie ein Terminal oder eine Eingabeaufforderung und führen Sie den folgenden Befehl aus:
aws configure- Nachdem Sie den obigen Befehl ausgeführt haben, wird eine ähnliche Benutzeroberfläche angezeigt.
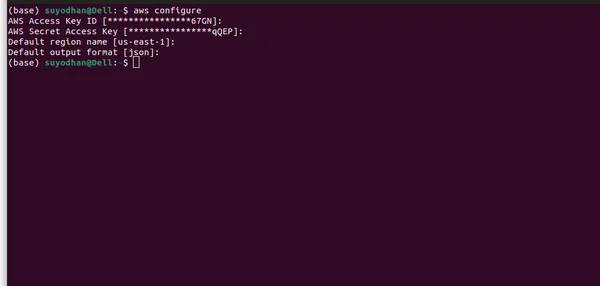
- Bitte stellen Sie sicher, dass Sie alle erforderlichen Informationen angeben und die richtige Region auswählen, da das LLM-Modell möglicherweise nicht in allen Regionen verfügbar ist. Darüber hinaus habe ich die Region angegeben, in der das LLM-Modell auf AWS Bedrock verfügbar ist.
Schritt 4: Importieren der erforderlichen Bibliotheken
- Importieren Sie die erforderlichen Pakete.
import boto3
import json
import base64
import os
- Boto3 ist eine Python-Bibliothek, die eine benutzerfreundliche Schnittstelle für die programmgesteuerte Interaktion mit Amazon Web Services (AWS)-Ressourcen bietet.
Schritt 5: Erstellen Sie einen AWS Bedrock-Client
bedrock = boto3.client(service_name="bedrock-runtime")
Schritt 6: Nutzlastparameter definieren
- Beobachten Sie zunächst die API in AWS Bedrock.
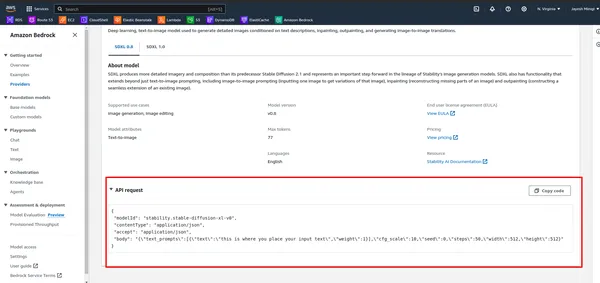
- Führen Sie die folgende Zelle aus.
# DEFINE THE USER QUERY
USER_QUERY="provide me an 4k hd image of a beach, also use a blue sky rainy season and
cinematic display"
payload_params = {
"text_prompts": [{"text": USER_QUERY, "weight": 1}],
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
Schritt 7: Definieren Sie das Payload-Objekt
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body= json.dumps(payload_params),
modelId=model_id,
accept="application/json",
contentType="application/json",
)
Schritt 8: Senden Sie eine Anfrage an die AWS Bedrock API und rufen Sie den Antworttext ab
response_body = json.loads(response.get("body").read())

Schritt 9: Bilddaten aus der Antwort extrahieren
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
Schritt 10: Speichern Sie das Bild in einer Datei
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)

Schritt 11: Erstellen Sie eine Streamlit-App
- Installieren Sie zuerst den Streamlit. Öffnen Sie dazu das Terminal und gehen Sie daran vorbei.
pip install streamlit
- Erstellen Sie ein Python-Skript für die Streamlit-App
import streamlit as st
import boto3
import json
import base64
import os
def generate_image(prompt_text):
prompt_template = [{"text": prompt_text, "weight": 1}]
bedrock = boto3.client(service_name="bedrock-runtime")
payload = {
"text_prompts": prompt_template,
"cfg_scale": 10,
"seed": 0,
"steps": 50,
"width": 512,
"height": 512
}
body = json.dumps(payload)
model_id = "stability.stable-diffusion-xl-v0"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json",
)
response_body = json.loads(response.get("body").read())
artifact = response_body.get("artifacts")[0]
image_encoded = artifact.get("base64").encode("utf-8")
image_bytes = base64.b64decode(image_encoded)
# Save image to a file in the output directory.
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_name = f"{output_dir}/generated-img.png"
with open(file_name, "wb") as f:
f.write(image_bytes)
return file_name
def main():
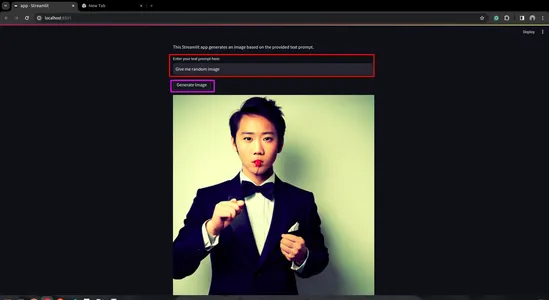
st.title("Generated Image")
st.write("This Streamlit app generates an image based on the provided text prompt.")
# Text input field for user prompt
prompt_text = st.text_input("Enter your text prompt here:")
if st.button("Generate Image") and prompt_text:
image_file = generate_image(prompt_text)
st.image(image_file, caption="Generated Image", use_column_width=True)
elif st.button("Generate Image") and not prompt_text:
st.error("Please enter a text prompt.")
if __name__ == "__main__":
main()
- Führen Sie die Streamlit-App aus
streamlit run app.py
Was ist LLaMA 2?
LLaMA 2, oder das Large Language Model of Many Applications, gehört zur Kategorie der Large Language Models (LLM). Facebook (Meta) hat dieses Modell entwickelt, um ein breites Spektrum von Anwendungen zur Verarbeitung natürlicher Sprache (NLP) zu untersuchen. In der früheren Serie war das „LAMA“-Modell der Ausgangspunkt der Entwicklung, es nutzte jedoch veraltete Methoden.
Hauptmerkmale von LLaMA 2
- Vielseitigkeit: LLaMA 2 ist ein leistungsstarkes Modell, das vielfältige Aufgaben mit hoher Genauigkeit und Effizienz bewältigen kann
- Kontextverständnis: Beim Sequenz-zu-Sequenz-Lernen erforschen wir Phoneme, Morpheme, Lexeme, Syntax und Kontext. LLaMA 2 ermöglicht ein besseres Verständnis kontextueller Nuancen.
- Lernen übertragen: LLaMA 2 ist ein robustes Modell, das von umfangreichem Training an einem großen Datensatz profitiert. Transferlernen erleichtert die schnelle Anpassung an spezifische Aufgaben.
- Open-Source: In Data Science ist die Community ein zentraler Aspekt. Open-Source-Modelle ermöglichen es Forschern, Entwicklern und Communities, sie zu erkunden, anzupassen und in ihre Projekte zu integrieren.
Anwendungsbeispiele
- LLaMA 2 kann dabei helfen Erstellen von Textgenerierungen Aufgaben, wie z Geschichten schreiben, Inhalte erstellen, usw.
- Wir wissen, wie wichtig Zero-Shot-Lernen ist. Wir können also LLaMA 2 verwenden zur Beantwortung von Fragen Aufgaben, ähnlich wie ChatGPT. Es liefert relevante und genaue Antworten.
- Für die Sprachübersetzung verfügen wir auf dem Markt über APIs, die wir jedoch abonnieren müssen. Aber LLaMA 2 bietet kostenlose Sprachübersetzungen, wodurch es einfach zu verwenden ist.
- LLaMA 2 ist einfach zu bedienen und eine ausgezeichnete Wahl für die Entwicklung Chatbots.
So erstellen Sie LLaMA 2
Um LLaMA 2 zu erstellen, müssen Sie mehrere Schritte ausführen, darunter das Einrichten Ihrer Entwicklungsumgebung, den Zugriff auf das Modell und den Aufruf mit den entsprechenden Parametern.
Schritt 1: Bibliotheken importieren
- Importieren Sie in der ersten Zelle des Notizbuchs die erforderlichen Bibliotheken:
import boto3
import json
Schritt 2: Definieren Sie Prompt und AWS Bedrock Client
- Definieren Sie in der nächsten Zelle die Eingabeaufforderung zum Generieren des Gedichts und erstellen Sie einen Client für den Zugriff auf die AWS Bedrock-API:
prompt_data = """
Act as a Shakespeare and write a poem on Generative AI
"""
bedrock = boto3.client(service_name="bedrock-runtime")
Schritt 3: Nutzlast definieren und Modell aufrufen
- Beobachten Sie zunächst die API in AWS Bedrock.
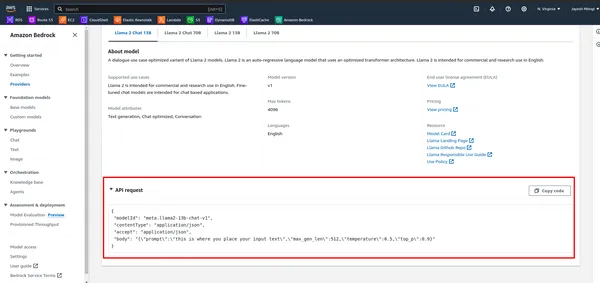
- Definieren Sie die Nutzlast mit der Eingabeaufforderung und anderen Parametern und rufen Sie dann das Modell mit dem AWS Bedrock-Client auf:
payload = {
"prompt": "[INST]" + prompt_data + "[/INST]",
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
response_text = response_body['generation']
print(response_text)
Schritt 4: Führen Sie das Notebook aus
- Führen Sie die Zellen im Notizbuch nacheinander aus, indem Sie Umschalt + Eingabetaste drücken. Die Ausgabe der letzten Zelle zeigt das generierte Gedicht an.
Schritt 5: Erstellen Sie eine Streamlit-App
- Erstellen Sie ein Python-Skript: Erstellen Sie ein neues Python-Skript (z. B. llama2_app.py) und öffnen Sie es in Ihrem bevorzugten Code-Editor
import streamlit as st
import boto3
import json
# Define AWS Bedrock client
bedrock = boto3.client(service_name="bedrock-runtime")
# Streamlit app layout
st.title('LLama2 Model App')
# Text input for user prompt
user_prompt = st.text_area('Enter your text prompt here:', '')
# Button to trigger model invocation
if st.button('Generate Output'):
payload = {
"prompt": user_prompt,
"max_gen_len": 512,
"temperature": 0.5,
"top_p": 0.9
}
body = json.dumps(payload)
model_id = "meta.llama2-70b-chat-v1"
response = bedrock.invoke_model(
body=body,
modelId=model_id,
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response.get("body").read())
generation = response_body['generation']
st.text('Generated Output:')
st.write(generation)
- Führen Sie die Streamlit-App aus:
- Speichern Sie Ihr Python-Skript und führen Sie es mit dem Streamlit-Befehl in Ihrem Terminal aus:
streamlit run llama2_app.py
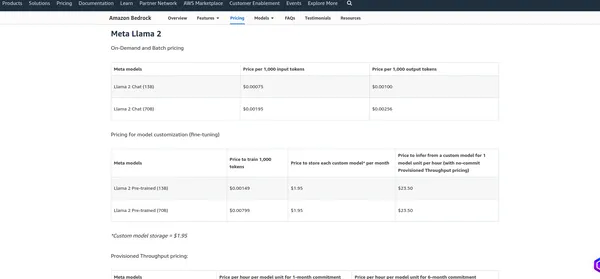
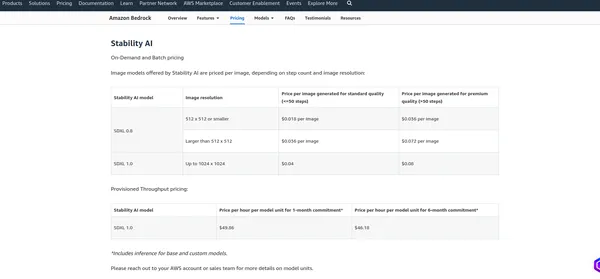
Preise für AWS Bedrock
Das Preise von AWS Bedrock hängt von verschiedenen Faktoren und den von Ihnen genutzten Diensten ab, z. B. Modellhosting, Inferenzanfragen, Datenspeicherung und Datenübertragung. AWS berechnet in der Regel nutzungsabhängig, d. h. Sie zahlen nur für das, was Sie nutzen. Ich empfehle einen Blick auf die offizielle Preisseite, da AWS möglicherweise seine Preisstruktur ändert. Ich kann Ihnen die aktuellen Gebühren mitteilen, aber es ist am besten, die Informationen auf der zu überprüfen offizielle Seite für die genauesten Details.
Meta LaMA 2
Stabilität KI
Zusammenfassung
Dieser Blog befasste sich intensiv mit dem Bereich der generativen KI und konzentrierte sich insbesondere auf zwei leistungsstarke LLM-Modelle: Stable Diffusion und LLamV2. Wir haben AWS Bedrock auch als Plattform für die Erstellung von LLM-Modell-APIs untersucht. Mithilfe dieser APIs haben wir gezeigt, wie man Code schreibt, um mit den Modellen zu interagieren. Darüber hinaus nutzten wir den AWS Bedrock-Spielplatz, um die Fähigkeiten der Modelle zu üben und zu bewerten.
Zu Beginn haben wir darauf hingewiesen, wie wichtig es ist, die richtige Region innerhalb von AWS Bedrock auszuwählen, da diese Modelle möglicherweise nicht in allen Regionen verfügbar sind. Im weiteren Verlauf haben wir jedes LLM-Modell praktisch untersucht, angefangen bei der Erstellung von Jupyter-Notebooks bis hin zur Entwicklung von Streamlit-Anwendungen.
Abschließend haben wir die Preisstruktur von AWS Bedrock besprochen, wobei wir die Notwendigkeit hervorgehoben haben, die damit verbundenen Kosten zu verstehen und genaue Informationen auf der offiziellen Preisseite zu finden.
Key Take Away
- Stable Diffusion und LLAMV2 auf AWS Bedrock bieten einfachen Zugriff auf leistungsstarke generative KI-Funktionen.
- AWS Bedrock bietet eine einfache Schnittstelle und umfassende Dokumentation für eine nahtlose Integration.
- Diese Modelle verfügen über unterschiedliche Schlüsselfunktionen und Anwendungsfälle in verschiedenen Domänen.
- Denken Sie daran, die richtige Region für den Zugriff auf die gewünschten Modelle auf AWS Bedrock auszuwählen.
- Die praktische Implementierung generativer KI-Modelle wie Stable Diffusion und LLAMv2 bietet Effizienz auf AWS Bedrock.
Häufig gestellte Fragen
A. Generative KI ist eine Teilmenge der künstlichen Intelligenz, die sich auf die Erstellung neuer Inhalte wie Bilder, Texte oder Code konzentriert und nicht nur auf die Analyse vorhandener Daten.
A. Stable Diffusion ist ein generatives KI-Modell, das mithilfe von Diffusionstechnologie und latentem Raum fotorealistische Bilder aus Text- und Bildaufforderungen erzeugt.
A. AWS Bedrock bietet APIs zum Verwalten, Trainieren und Bereitstellen von Modellen und ermöglicht Benutzern den Zugriff auf große Sprachmodelle wie LLAMv2 für verschiedene Anwendungen.
A. Sie können über die bereitgestellten APIs auf LLM-Modelle in AWS Bedrock zugreifen, indem Sie beispielsweise das Modell mit bestimmten Parametern aufrufen und die generierte Ausgabe empfangen.
A. Stable Diffusion kann aus Textaufforderungen qualitativ hochwertige Bilder generieren, nutzt den latenten Raum effizient und ist für ein breites Spektrum von Benutzern zugänglich.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/02/building-end-to-end-generative-ai-models-with-aws-bedrock/

