
Die Microservices-Architektur fördert die Erstellung flexibler, unabhängiger Dienste mit klar definierten Grenzen. Dieser skalierbare Ansatz ermöglicht es Entwicklern, Dienste individuell zu warten und weiterzuentwickeln, ohne die gesamte Anwendung zu beeinträchtigen. Um jedoch das volle Potenzial der Microservices-Architektur, insbesondere für KI-gestützte Chat-Anwendungen, auszuschöpfen, ist eine robuste Integration mit den neuesten Large Language Models (LLMs) wie Meta Llama V2 und OpenAIs ChatGPT und anderen fein abgestimmten Modellen erforderlich, die auf den jeweiligen Anwendungsfall abgestimmt sind Bereitstellung eines Multi-Modell-Ansatzes für eine diversifizierte Lösung.
LLMs sind groß angelegte Modelle, die auf der Grundlage ihres Trainings auf verschiedenen Daten menschenähnliche Texte generieren. Durch das Lernen aus Milliarden von Wörtern im Internet verstehen LLMs den Kontext und generieren abgestimmte Inhalte in verschiedenen Bereichen. Die Integration verschiedener LLMs in eine einzige Anwendung stellt jedoch häufig Herausforderungen dar, da für jedes Modell eindeutige Schnittstellen, Zugriffsendpunkte und spezifische Nutzlasten erforderlich sind. Ein einziger Integrationsdienst, der eine Vielzahl von Modellen verarbeiten kann, verbessert also das Architekturdesign und ermöglicht die Skalierung unabhängiger Dienste.
Dieses Tutorial führt Sie in die IntelliNode-Integrationen für ChatGPT und LLaMA V2 in einer Microservice-Architektur mit Node.js und Express ein.
Hier sind einige von IntelliNode bereitgestellte Chat-Integrationsoptionen:
- LLaMA V2: Sie können das LLaMA V2-Modell entweder über die API von Replicate für einen unkomplizierten Prozess oder über Ihren AWS SageMaker-Host für eine zusätzliche Kontrolle integrieren.
LLaMA V2 ist ein leistungsstarkes Open-Source-Large-Language-Modell (LLM), das vorab trainiert und mit bis zu 70 Milliarden Parametern feinabgestimmt wurde. Es eignet sich hervorragend für komplexe Denkaufgaben in verschiedenen Bereichen, einschließlich Spezialgebieten wie Programmierung und kreativem Schreiben. Die Trainingsmethodik umfasst selbstüberwachte Daten und die Ausrichtung auf menschliche Vorlieben durch Reinforcement Learning with Human Feedback (RLHF). LLaMA V2 übertrifft bestehende Open-Source-Modelle und ist hinsichtlich Benutzerfreundlichkeit und Sicherheit mit Closed-Source-Modellen wie ChatGPT und BARD vergleichbar.
- ChatGPT: Durch die einfache Bereitstellung Ihres OpenAI-API-Schlüssels ermöglicht das IntelliNode-Modul die Integration mit dem Modell in einer einfachen Chat-Schnittstelle. Sie können über die Modelle GPT 3.5 oder GPT 4 auf ChatGPT zugreifen. Diese Modelle wurden anhand großer Datenmengen trainiert und fein abgestimmt, um äußerst kontextbezogene und genaue Antworten zu liefern.
Beginnen wir mit der Initialisierung eines neuen Node.js-Projekts. Öffnen Sie Ihr Terminal, navigieren Sie zum Verzeichnis Ihres Projekts und führen Sie den folgenden Befehl aus:
npm init -y
Dieser Befehl erstellt eine neue „package.json“-Datei für Ihre Anwendung.
Als nächstes installieren Sie Express.js, das zur Verarbeitung von HTTP-Anfragen und -Antworten sowie zur Intellinode-Verbindung für LLM-Modelle verwendet wird:
npm install express npm install intellinode
Erstellen Sie nach Abschluss der Installation eine neue Datei mit dem Namen „app.js.` im Stammverzeichnis Ihres Projekts. Fügen Sie dann den Express-Initialisierungscode in „app.js“ hinzu.
Code nach Autor
Replicate bietet einen schnellen Integrationspfad mit Llama V2 über den API-Schlüssel, und IntelliNode stellt die Chatbot-Schnittstelle bereit, um Ihre Geschäftslogik vom Replicate-Backend zu entkoppeln, sodass Sie zwischen verschiedenen Chat-Modellen wechseln können.
Beginnen wir mit der Integration mit Llama, das im Backend von Replica gehostet wird:
Code nach Autor
Holen Sie sich Ihren Testschlüssel von replizieren.com um die Integration zu aktivieren.
Lassen Sie uns nun die Llama V2-Integration über AWS SageMaker behandeln, die Datenschutz und zusätzliche Kontrollebene bietet.
Die Integration erfordert die Generierung eines API-Endpunkts aus Ihrem AWS-Konto. Zuerst richten wir den Integrationscode in unserer Microservice-App ein:
Code nach Autor
Die folgenden Schritte dienen zum Erstellen eines Llama-Endpunkts in Ihrem Konto. Sobald Sie das API-Gateway eingerichtet haben, kopieren Sie die URL, die zum Ausführen des „/lama/aws' Service.
So richten Sie einen Llama V2-Endpunkt in Ihrem AWS-Konto ein:
1- SageMaker-Service: Wählen Sie den SageMaker-Dienst in Ihrem AWS-Konto aus und klicken Sie auf Domänen.

AWS-Konto – Wählen Sie Sagemaker aus
2- Erstellen Sie eine SageMaker-Domäne: Beginnen Sie mit der Erstellung einer neuen Domäne auf Ihrem AWS SageMaker. Dieser Schritt richtet einen kontrollierten Bereich für Ihre SageMaker-Vorgänge ein.
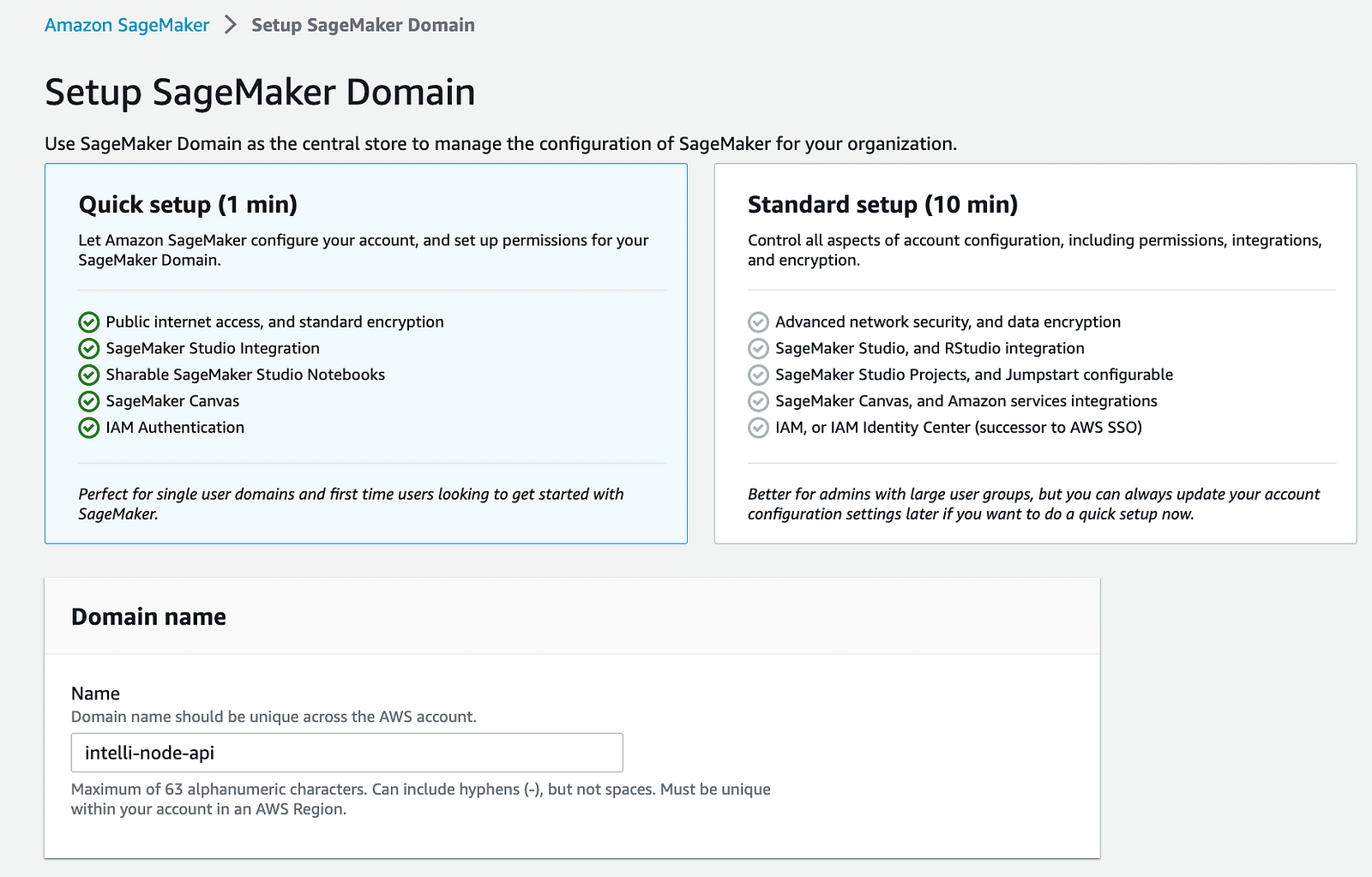
aws-Konto-Sagemaker-Domäne
3- Stellen Sie das Lama-Modell bereit: Nutzen Sie SageMaker JumpStart, um das Llama-Modell bereitzustellen, das Sie integrieren möchten. Aufgrund der höheren monatlichen Kosten für den Betrieb des 2B-Modells wird empfohlen, mit dem 70B-Modell zu beginnen.

Starthilfe für AWS Account-Sagemaker
4- Kopieren Sie den Endpunktnamen: Sobald Sie ein Modell bereitgestellt haben, notieren Sie sich unbedingt den Endpunktnamen, der für zukünftige Schritte von entscheidender Bedeutung ist.
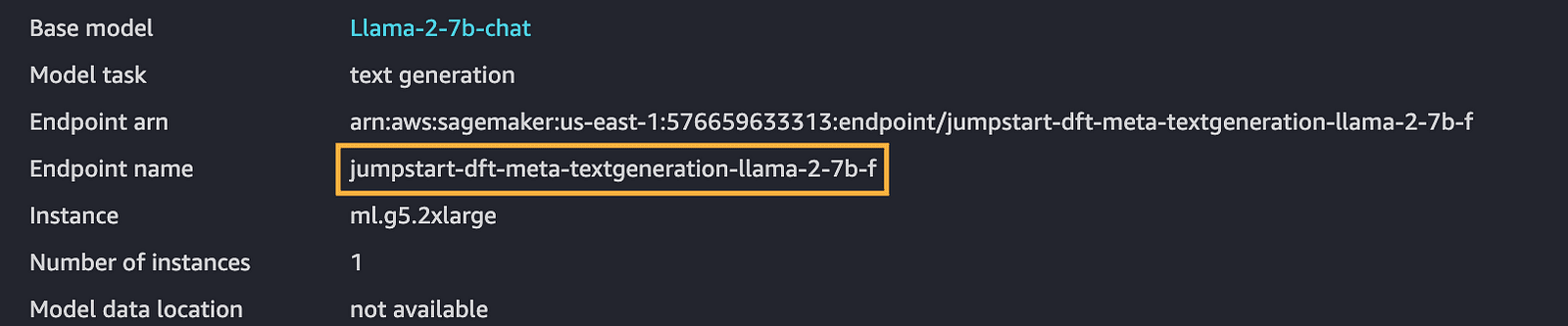
aws-Konto-Sagemaker-Endpunkt
5- Erstellen Sie eine Lambda-Funktion: AWS Lambda ermöglicht die Ausführung des Back-End-Codes ohne Serververwaltung. Erstellen Sie eine Node.js-Lambda-Funktion zur Integration des bereitgestellten Modells.
6- Umgebungsvariable einrichten: Erstellen Sie in Ihrem Lambda eine Umgebungsvariable namens llama_endpoint mit dem Wert des SageMaker-Endpunkts.
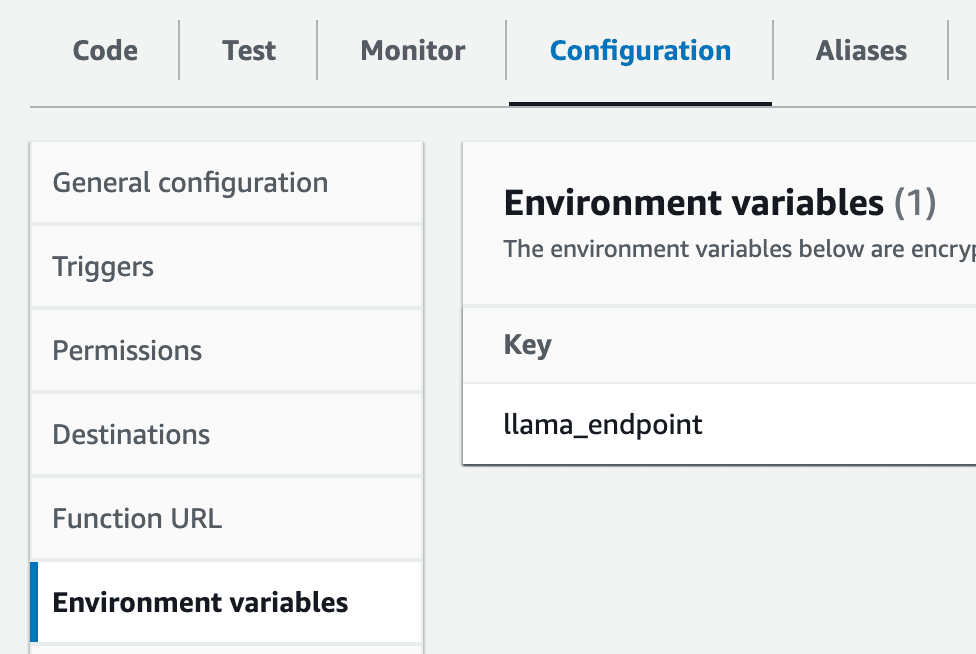
aws-Konto-lmabda-Einstellungen
7- Intellinode Lambda-Import: Sie müssen die vorbereitete Lambda-Zip-Datei importieren, die eine Verbindung zu Ihrer SageMaker Llama-Bereitstellung herstellt. Dieser Export ist eine ZIP-Datei und kann im gefunden werden lambda_llama_sagemaker Verzeichnis.

AWS-Konto-Lambda-Upload aus der ZIP-Datei
8- API-Gateway-Konfiguration: Klicken Sie auf der Lambda-Funktionsseite auf die Option „Trigger hinzufügen“ und wählen Sie „API Gateway“ aus der Liste der verfügbaren Trigger aus.
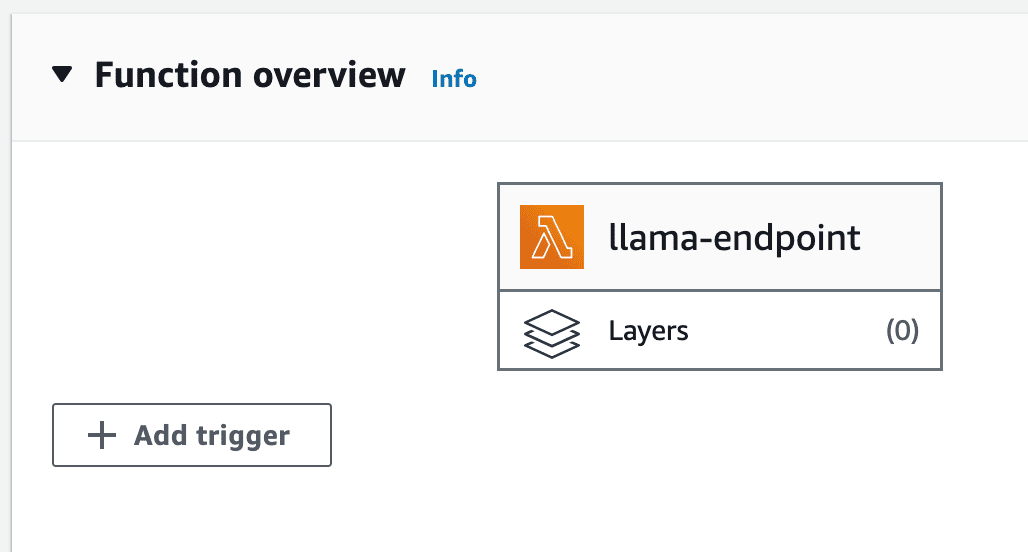
AWS-Konto-Lambda-Trigger
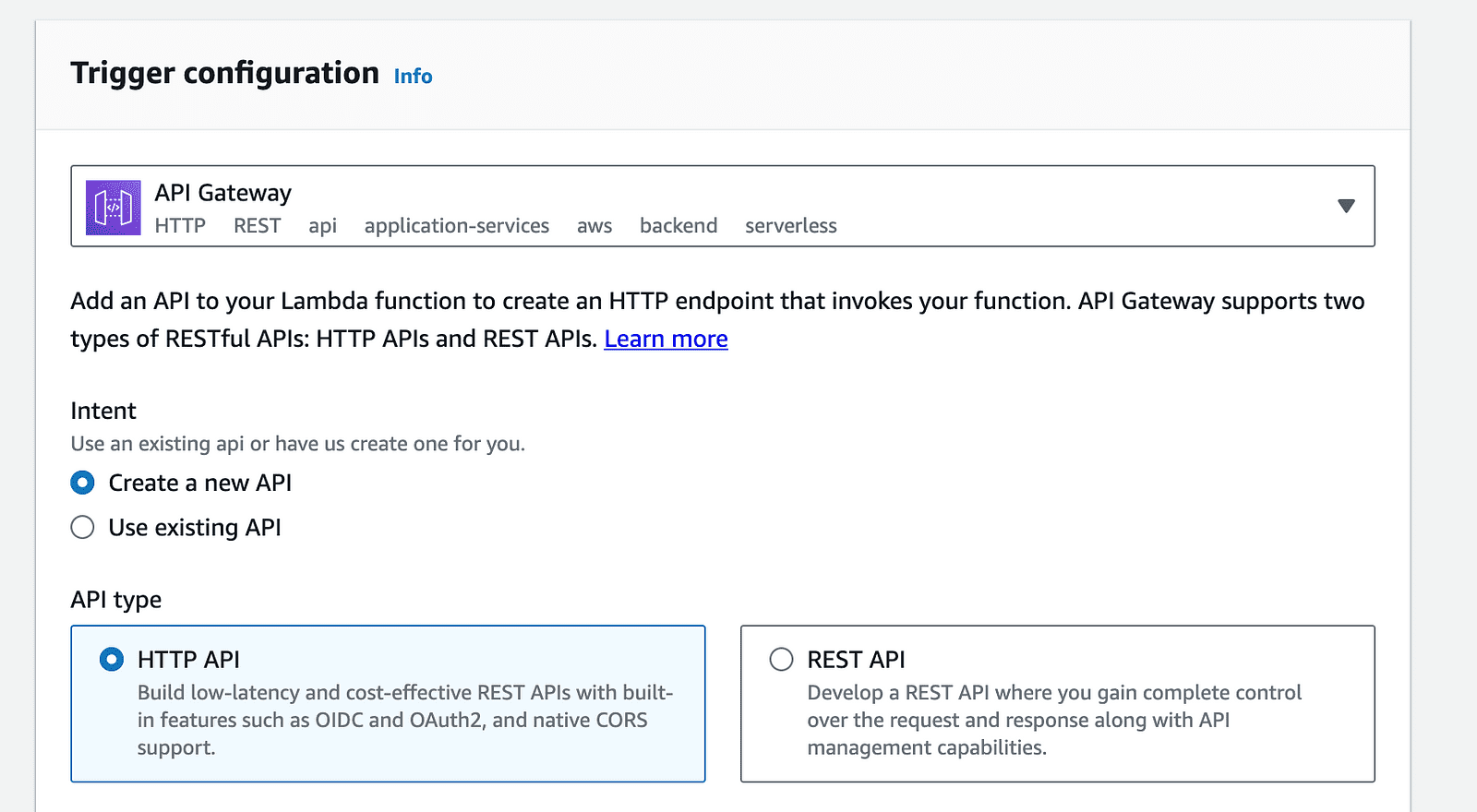
AWS-Konto-API-Gateway-Trigger
9- Lambda-Funktionseinstellungen: Aktualisieren Sie die Lambda-Rolle, um die erforderlichen Berechtigungen für den Zugriff auf SageMaker-Endpunkte zu erteilen. Darüber hinaus sollte der Timeout-Zeitraum der Funktion verlängert werden, um der Verarbeitungszeit Rechnung zu tragen. Nehmen Sie diese Anpassungen im Reiter „Konfiguration“ Ihrer Lambda-Funktion vor.
Klicken Sie auf den Rollennamen, um die Berechtigungen zu aktualisieren und die Berechtigung für den Zugriff auf Sagemaker bereitzustellen:
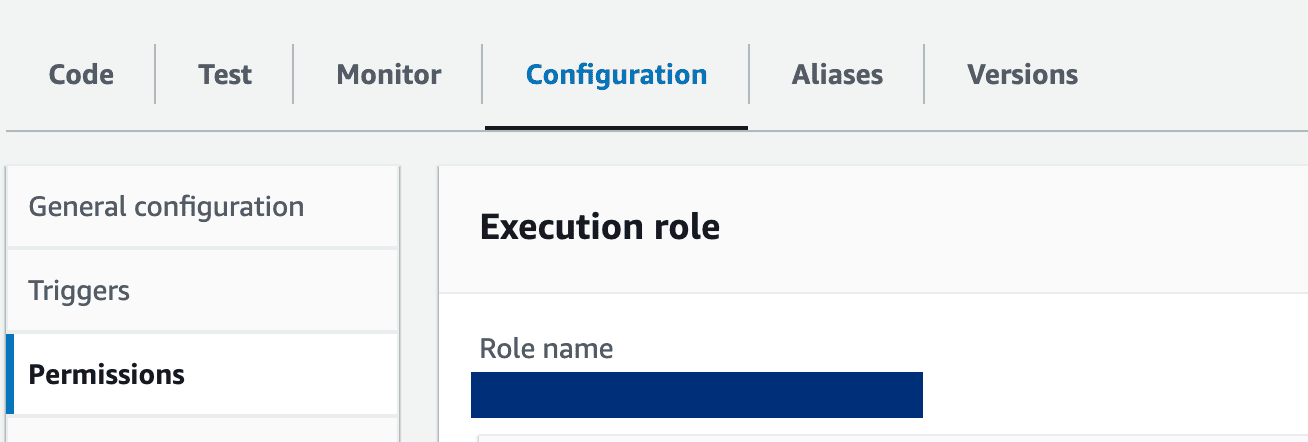
AWS-Konto-Lambda-Rolle
Abschließend veranschaulichen wir die Schritte zur Integration von Openai ChatGPT als weitere Option in die Microservice-Architektur:
Code nach Autor
Holen Sie sich Ihren Testschlüssel von Plattform.openai.com.
Exportieren Sie zunächst den API-Schlüssel wie folgt in Ihr Terminal:
Code nach Autor
Führen Sie dann die Node-App aus:
node app.js
Geben Sie die folgende URL in den Browser ein, um den ChatGPT-Dienst zu testen:
http://localhost:3000/chatgpt?message=hello
Wir haben einen Microservice entwickelt, der auf den Fähigkeiten großer Sprachmodelle wie Llama V2 und ChatGPT von OpenAI basiert. Diese Integration öffnet die Tür für die Nutzung endloser Geschäftsszenarien, die auf fortschrittlicher KI basieren.
Durch die Übersetzung Ihrer Anforderungen an maschinelles Lernen in entkoppelte Microservices kann Ihre Anwendung von den Vorteilen der Flexibilität und Skalierbarkeit profitieren. Anstatt Ihre Abläufe so zu konfigurieren, dass sie den Einschränkungen eines monolithischen Modells entsprechen, können die Sprachmodellfunktionen jetzt individuell verwaltet und entwickelt werden. Dies verspricht eine bessere Effizienz sowie eine einfachere Fehlerbehebung und Upgrade-Verwaltung.
Bibliographie
- ChatGPT-API: Link.
- Replikat-API: Link.
- SageMaker Lama-Starthilfe: Link
- IntelliNode Erste Schritte: Link
- Vollständiger GitHub-Code-Repo: Link
Ahmad Albarqawi ist Ingenieur und Data Science Master an der Illinois Urbana-Champaign.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Automobil / Elektrofahrzeuge, Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- ChartPrime. Verbessern Sie Ihr Handelsspiel mit ChartPrime. Hier zugreifen.
- BlockOffsets. Modernisierung des Eigentums an Umweltkompensationen. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/building-microservice-for-multichat-backends-using-llama-and-chatgpt?utm_source=rss&utm_medium=rss&utm_campaign=building-microservice-for-multi-chat-backends-using-llama-and-chatgpt

