Einleitung
Es gab einen massiven Anstieg bei Anwendungen, die KI-Codierungsagenten verwenden. Mit zunehmender Qualität von LLMs und sinkenden Inferenzkosten wird es immer einfacher, leistungsfähige KI-Agenten zu entwickeln. Darüber hinaus entwickelt sich das Tooling-Ökosystem rasant weiter, wodurch es einfacher wird, komplexe KI-Codierungsagenten zu erstellen. Das Langchain-Framework war in dieser Hinsicht führend. Es verfügt über alle notwendigen Tools und Techniken, um produktionsreife KI-Anwendungen zu erstellen.
Doch eines fehlte bislang. Und das ist eine Multi-Agenten-Zusammenarbeit mit Zyklizität. Dies ist entscheidend für die Lösung komplexer Probleme, bei denen das Problem aufgeteilt und an spezialisierte Agenten delegiert werden kann. Hier kommt LangGraph ins Spiel, ein Teil des Langchain-Frameworks, das für die zustandsbehaftete Zusammenarbeit mehrerer Akteure zwischen KI-Coding-Agenten konzipiert ist. Darüber hinaus werden wir in diesem Artikel LangGraph und seine Grundbausteine besprechen, während wir damit einen Agenten erstellen.
Lernziele
- Verstehen Sie, was LangGraph ist.
- Entdecken Sie die Grundlagen von LangGraph zum Erstellen zustandsbehafteter Agenten.
- Entdecken Sie TogetherAI, um auf Open-Access-Modelle wie zuzugreifen DeepSeekCoder.
- Erstellen Sie mit LangGraph einen KI-Codierungsagenten, um Komponententests zu schreiben.

Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Was ist LangGraph?
LangGraph ist eine Erweiterung des LangChain-Ökosystems. Während LangChain die Erstellung von KI-Coding-Agenten ermöglicht, die mehrere Tools zum Ausführen von Aufgaben verwenden können, ist es nicht möglich, mehrere Ketten oder Akteure über die Schritte hinweg zu koordinieren. Dies ist ein entscheidendes Verhalten für die Erstellung von Agenten, die komplexe Aufgaben ausführen. LangGraph wurde unter Berücksichtigung dieser Aspekte konzipiert. Es behandelt die Agent-Workflows als eine zyklische Graph-Struktur, in der jeder Knoten eine Funktion oder ein ausführbares Langchain-Objekt darstellt und Kanten Verbindungen zwischen Knoten sind.
Zu den Hauptfunktionen von LangGraph gehören:
- Nodes: Jede Funktion oder jedes ausführbare Langchain-Objekt wie ein Werkzeug.
- Edges: Definiert die Richtung zwischen Knoten.
- Zustandsbehaftete Diagramme: Der primäre Diagrammtyp. Es dient zur Verwaltung und Aktualisierung von Zustandsobjekten, während es Daten über seine Knoten verarbeitet.
LangGraph nutzt dies, um eine zyklische LLM-Aufrufausführung mit Zustandspersistenz zu ermöglichen, die für das Agentenverhalten von entscheidender Bedeutung ist. Die Architektur ist inspiriert von Pregel und Apache-Strahl.
In diesem Artikel erstellen wir einen Agenten zum Schreiben von Pytest-Komponententests für eine Python-Klasse mit Methoden. Und das ist der Arbeitsablauf.
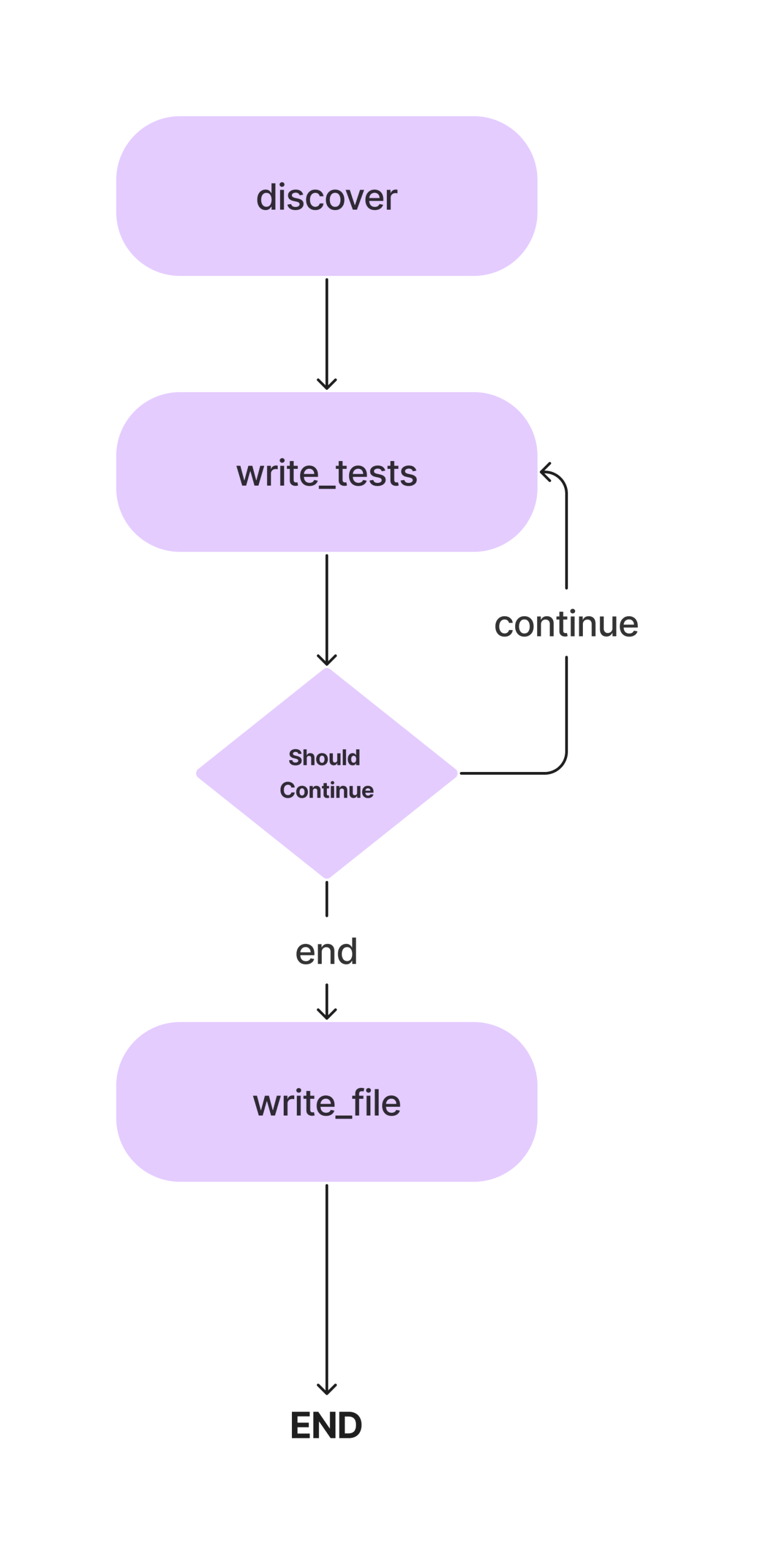
Wir werden die Konzepte im Detail besprechen, während wir unseren KI-Codierungsagenten zum Schreiben einfacher Komponententests erstellen. Kommen wir also zum Codierungsteil.
Aber vorher richten wir unsere Entwicklungsumgebung ein.
Abhängigkeiten installieren
Alles der Reihe nach. Erstellen Sie wie bei jedem Python-Projekt eine virtuelle Umgebung und aktivieren Sie sie.
python -m venv auto-unit-tests-writer
cd auto-unit-tests-writer
source bin/activateInstallieren Sie nun die Abhängigkeiten.
!pip install langgraph langchain langchain_openai coloramaImportieren Sie alle Bibliotheken und ihre Klassen.
from typing import TypedDict, List
import colorama
import os
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage
from langchain_core.messages import HumanMessage
from langchain_core.runnables import RunnableConfig
from langgraph.graph import StateGraph, END
from langgraph.pregel import GraphRecursionErrorWir möchten auch die Verzeichnisse und Dateien für Testfälle erstellen. Sie können Dateien manuell erstellen oder dafür Python verwenden.
# Define the paths.
search_path = os.path.join(os.getcwd(), "app")
code_file = os.path.join(search_path, "src/crud.py")
test_file = os.path.join(search_path, "test/test_crud.py")
# Create the folders and files if necessary.
if not os.path.exists(search_path):
os.mkdir(search_path)
os.mkdir(os.path.join(search_path, "src"))
os.mkdir(os.path.join(search_path, "test"))Aktualisieren Sie nun die Datei crud.py mit Code für eine In-Memory-CRUD-App. Wir werden diesen Code verwenden, um Unit-Tests zu schreiben. Sie können hierfür Ihr Python-Programm verwenden. Wir werden das folgende Programm zu unserer code.py-Datei hinzufügen.
#crud.py
code = """class Item:
def __init__(self, id, name, description=None):
self.id = id
self.name = name
self.description = description
def __repr__(self):
return f"Item(id={self.id}, name={self.name}, description={self.description})"
class CRUDApp:
def __init__(self):
self.items = []
def create_item(self, id, name, description=None):
item = Item(id, name, description)
self.items.append(item)
return item
def read_item(self, id):
for item in self.items:
if item.id == id:
return item
return None
def update_item(self, id, name=None, description=None):
for item in self.items:
if item.id == id:
if name:
item.name = name
if description:
item.description = description
return item
return None
def delete_item(self, id):
for index, item in enumerate(self.items):
if item.id == id:
return self.items.pop(index)
return None
def list_items(self):
return self.items"""
with open(code_file, 'w') as f:
f.write(code)LLM einrichten
Jetzt geben wir das LLM an, das wir in diesem Projekt verwenden werden. Welches Modell hier zum Einsatz kommt, hängt von den Aufgaben und der Verfügbarkeit der Ressourcen ab. Sie können proprietäre, leistungsstarke Modelle wie GPT-4, Gemini Ultra oder GPT-3.5 verwenden. Sie können auch Open-Access-Modelle wie Mixtral und Llama-2 verwenden. In diesem Fall können wir, da es sich um das Schreiben von Codes handelt, ein fein abgestimmtes Codierungsmodell wie DeepSeekCoder-33B oder Llama-2 Codierer verwenden. Mittlerweile gibt es mehrere Plattformen für LLM-Inferenzen, wie Anayscale, Abacus und Together. Wir werden Together AI verwenden, um DeepSeekCoder abzuleiten. Also besorgen Sie sich ein API-Schlüssel von Together, bevor Sie fortfahren.
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(base_url="https://api.together.xyz/v1",
api_key="your-key",
model="deepseek-ai/deepseek-coder-33b-instruct")Da die Together-API mit dem OpenAI SDK kompatibel ist, können wir das OpenAI SDK von Langchain verwenden, um mit auf Together gehosteten Modellen zu kommunizieren, indem wir den Parameter „base_url“ in ändern „https://api.together.xyz/v1“. Übergeben Sie in api_key Ihren Together-API-Schlüssel und anstelle von Modellen den Modellnamen verfügbar auf Together.
Definieren Sie den Agentenstatus
Dies ist einer der entscheidenden Teile von LangGraph. Hier definieren wir einen AgentState, der dafür verantwortlich ist, den Status der Agenten während der gesamten Ausführung zu verfolgen. Dabei handelt es sich in erster Linie um eine TypedDict-Klasse mit Entitäten, die den Status der Agents verwalten. Definieren wir unseren AgentState
class AgentState(TypedDict):
class_source: str
class_methods: List[str]
tests_source: strIn der obigen AgentState-Klasse speichert „class_source“ die ursprüngliche Python-Klasse, „class_methods“ zum Speichern von Methoden der Klasse und „tests_source“ für Unit-Test-Codes. Wir haben diese als AgentState definiert, um sie in allen Ausführungsschritten zu verwenden.
Definieren Sie nun den Graph mit dem AgentState.
# Create the graph.
workflow = StateGraph(AgentState)Wie bereits erwähnt, handelt es sich um einen zustandsbehafteten Graphen, und jetzt haben wir unser Zustandsobjekt hinzugefügt.
Knoten definieren
Nachdem wir nun den AgentState definiert haben, müssen wir Knoten hinzufügen. Was genau sind Knoten? In LangGraph sind Knoten Funktionen oder beliebige ausführbare Objekte, wie Langchain-Tools, die eine einzelne Aktion ausführen. In unserem Fall können wir mehrere Knoten definieren, z. B. eine Funktion zum Finden von Klassenmethoden, eine Funktion zum Ableiten und Aktualisieren von Komponententests für Zustandsobjekte und eine Funktion zum Schreiben in eine Testdatei.
Wir brauchen auch eine Möglichkeit, Codes aus einer LLM-Nachricht zu extrahieren. Hier ist wie.
def extract_code_from_message(message):
lines = message.split("n")
code = ""
in_code = False
for line in lines:
if "```" in line:
in_code = not in_code
elif in_code:
code += line + "n"
return codeDer Codeausschnitt hier geht davon aus, dass die Codes in dreifachen Anführungszeichen stehen.
Definieren wir nun unsere Knoten.
import_prompt_template = """Here is a path of a file with code: {code_file}.
Here is the path of a file with tests: {test_file}.
Write a proper import statement for the class in the file.
"""
# Discover the class and its methods.
def discover_function(state: AgentState):
assert os.path.exists(code_file)
with open(code_file, "r") as f:
source = f.read()
state["class_source"] = source
# Get the methods.
methods = []
for line in source.split("n"):
if "def " in line:
methods.append(line.split("def ")[1].split("(")[0])
state["class_methods"] = methods
# Generate the import statement and start the code.
import_prompt = import_prompt_template.format(
code_file=code_file,
test_file=test_file
)
message = llm.invoke([HumanMessage(content=import_prompt)]).content
code = extract_code_from_message(message)
state["tests_source"] = code + "nn"
return state
# Add a node to for discovery.
workflow.add_node(
"discover",
discover_function
)
Im obigen Codeausschnitt haben wir eine Funktion zum Erkennen von Codes definiert. Es extrahiert die Codes aus dem AgentState class_source Element, zerlegt die Klasse in einzelne Methoden und übergibt sie mit Eingabeaufforderungen an das LLM. Die Ausgabe wird im AgentState gespeichert test_source Element. Wir lassen es nur Importanweisungen für die Unit-Testfälle schreiben.
Wir haben auch den ersten Knoten zum StateGraph-Objekt hinzugefügt.
Nun zum nächsten Knoten.
Außerdem können wir hier einige Eingabeaufforderungsvorlagen einrichten, die wir benötigen. Dies sind Beispielvorlagen, die Sie je nach Bedarf ändern können.
# System message template.
system_message_template = """You are a smart developer. You can do this! You will write unit
tests that have a high quality. Use pytest.
Reply with the source code for the test only.
Do not include the class in your response. I will add the imports myself.
If there is no test to write, reply with "# No test to write" and
nothing more. Do not include the class in your response.
Example:
```
def test_function():
...
```
I will give you 200 EUR if you adhere to the instructions and write a high quality test.
Do not write test classes, only methods.
"""
# Write the tests template.
write_test_template = """Here is a class:
'''
{class_source}
'''
Implement a test for the method "{class_method}".
"""Definieren Sie nun den Knoten.
# This method will write a test.
def write_tests_function(state: AgentState):
# Get the next method to write a test for.
class_method = state["class_methods"].pop(0)
print(f"Writing test for {class_method}.")
# Get the source code.
class_source = state["class_source"]
# Create the prompt.
write_test_prompt = write_test_template.format(
class_source=class_source,
class_method=class_method
)
print(colorama.Fore.CYAN + write_test_prompt + colorama.Style.RESET_ALL)
# Get the test source code.
system_message = SystemMessage(system_message_template)
human_message = HumanMessage(write_test_prompt)
test_source = llm.invoke([system_message, human_message]).content
test_source = extract_code_from_message(test_source)
print(colorama.Fore.GREEN + test_source + colorama.Style.RESET_ALL)
state["tests_source"] += test_source + "nn"
return state
# Add the node.
workflow.add_node(
"write_tests",
write_tests_function
)Hier veranlassen wir den LLM, Testfälle für jede Methode zu schreiben, sie im Element „tests_source“ von AgentState zu aktualisieren und sie dem Workflow-StateGraph-Objekt hinzuzufügen.
Edges
Da wir nun zwei Knoten haben, definieren wir Kanten zwischen ihnen, um die Ausführungsrichtung zwischen ihnen festzulegen. Der LangGraph bietet hauptsächlich zwei Arten von Kanten.
- Bedingte Kante: Der Ausführungsfluss hängt von der Reaktion der Agenten ab. Dies ist entscheidend, um die Arbeitsabläufe zyklischer zu gestalten. Der Agent kann anhand bestimmter Bedingungen entscheiden, welche Knoten als nächstes verschoben werden sollen. Ob Sie zu einem vorherigen Knoten zurückkehren, den aktuellen wiederholen oder zum nächsten Knoten wechseln möchten.
- Normale Kante: Dies ist der Normalfall, bei dem ein Knoten immer nach dem Aufruf vorheriger Knoten aufgerufen wird.
Wir benötigen keine Bedingung, um discover und write_tests zu verbinden, daher verwenden wir eine normale Kante. Definieren Sie außerdem einen Einstiegspunkt, der angibt, wo die Ausführung beginnen soll.
# Define the entry point. This is where the flow will start.
workflow.set_entry_point("discover")
# Always go from discover to write_tests.
workflow.add_edge("discover", "write_tests")Die Ausführung beginnt mit der Entdeckung der Methoden und geht zur Funktion des Schreibens von Tests über. Wir benötigen einen weiteren Knoten, um die Unit-Test-Codes in die Testdatei zu schreiben.
# Write the file.
def write_file(state: AgentState):
with open(test_file, "w") as f:
f.write(state["tests_source"])
return state
# Add a node to write the file.
workflow.add_node(
"write_file",
write_file)Da dies unser letzter Knoten ist, definieren wir eine Kante zwischen write_tests und write_file. So können wir das machen.
# Find out if we are done.
def should_continue(state: AgentState):
if len(state["class_methods"]) == 0:
return "end"
else:
return "continue"
# Add the conditional edge.
workflow.add_conditional_edges(
"write_tests",
should_continue,
{
"continue": "write_tests",
"end": "write_file"
}
)Die Funktion „add_conditional_edge“ verwendet die Funktion „write_tests“, eine Funktion „should_continue“, die anhand von „class_methods“-Einträgen entscheidet, welcher Schritt ausgeführt werden soll, und eine Zuordnung mit Zeichenfolgen als Schlüsseln und anderen Funktionen als Werten.
Die Kante beginnt bei write_tests und führt basierend auf der Ausgabe von Should_continue eine der Optionen im Mapping aus. Wenn beispielsweise der Status [„class_methods“] nicht leer ist, haben wir nicht für alle Methoden Tests geschrieben. Wir wiederholen die Funktion write_tests und wenn wir mit dem Schreiben der Tests fertig sind, wird die Funktion write_file ausgeführt.
Wenn die Tests für alle Methoden abgeleitet wurden LLM, werden die Tests in die Testdatei geschrieben.
Fügen Sie nun die letzte Kante zum Workflow-Objekt für den Abschluss hinzu.
# Always go from write_file to end.
workflow.add_edge("write_file", END)Führen Sie den Workflow aus
Als letztes musste noch der Workflow kompiliert und ausgeführt werden.
# Create the app and run it
app = workflow.compile()
inputs = {}
config = RunnableConfig(recursion_limit=100)
try:
result = app.invoke(inputs, config)
print(result)
except GraphRecursionError:
print("Graph recursion limit reached.")Dadurch wird die App aufgerufen. Die Rekursionsgrenze gibt an, wie oft das LLM für einen bestimmten Workflow abgeleitet wird. Der Workflow stoppt, wenn das Limit überschritten wird.
Sie können die Protokolle auf dem Terminal oder im Notebook einsehen. Dies ist das Ausführungsprotokoll für eine einfache CRUD-App.
Ein Großteil der schweren Arbeit wird vom zugrunde liegenden Modell übernommen. Dies war eine Demoanwendung mit dem Deepseek-Codiermodell. Für eine bessere Leistung können Sie GPT-4 oder Claude Opus, Haiku usw. verwenden.
Sie können Langchain-Tools auch zum Surfen im Internet, zur Aktienkursanalyse usw. verwenden.
LangChain vs. LangGraph
Nun stellt sich die Frage, wann man LangChain vs LangGraph.
Wenn das Ziel darin besteht, ein Multi-Agenten-System mit Koordination zwischen diesen zu schaffen, ist LangGraph die richtige Wahl. Wenn Sie jedoch DAGs oder Ketten erstellen möchten, um Aufgaben zu erledigen, ist die LangChain Expression Language am besten geeignet.
Warum LangGraph verwenden?
LangGraph ist ein leistungsstarkes Framework, das viele bestehende Lösungen verbessern kann.
- RAG-Pipelines verbessern: LangGraph kann die RAG mit seiner zyklischen Graphenstruktur erweitern. Wir können eine Feedbackschleife einführen, um die Qualität des abgerufenen Objekts zu bewerten und bei Bedarf die Abfrage verbessern und den Vorgang wiederholen.
- Multi-Agent-Workflows: LangGraph ist für die Unterstützung von Multi-Agent-Workflows konzipiert. Dies ist entscheidend für die Lösung komplexer Aufgaben, die in kleinere Teilaufgaben unterteilt sind. Verschiedene Agenten mit einem gemeinsamen Status und unterschiedlichen LLMs und Tools können zusammenarbeiten, um eine einzelne Aufgabe zu lösen.
- Human-in-the-Loop: LangGraph verfügt über integrierte Unterstützung für den Human-in-the-Loop-Workflow. Dies bedeutet, dass ein Mensch die Zustände überprüfen kann, bevor er zum nächsten Knoten wechselt.
- Planungsagent: LangGraph eignet sich gut zum Erstellen von Planungsagenten, bei denen ein LLM-Planer eine Benutzeranfrage plant und zerlegt, ein Ausführender Tools und Funktionen aufruft und der LLM Antworten basierend auf vorherigen Ausgaben synthetisiert.
- Multimodale Agenten: LangGraph kann multimodale Agenten erstellen, z. B. visionsfähige Webnavigatoren.
Anwendungsfälle aus der Praxis
Es gibt zahlreiche Bereiche, in denen komplexe KI-Programmierungsagenten hilfreich sein können.
- Persönlicher Agents: Stellen Sie sich vor, Sie hätten Ihren eigenen Jarvis-ähnlichen Assistenten auf Ihren elektronischen Geräten, der bereit ist, Ihnen bei Aufgaben zu helfen, sei es per Text, Stimme oder sogar einer Geste. Das ist einer der aufregendsten Einsatzmöglichkeiten von KI-Agenten!
- KI-Lehrer: Chatbots sind großartig, aber sie haben ihre Grenzen. KI-Agenten, die mit den richtigen Tools ausgestattet sind, können über einfache Gespräche hinausgehen. Virtuelle KI-Lehrer, die ihre Lehrmethoden auf der Grundlage des Benutzerfeedbacks anpassen können, können bahnbrechend sein.
- Software-UX: Das Benutzererlebnis von Software kann mit KI-Agenten verbessert werden. Anstatt manuell durch Anwendungen zu navigieren, können Agenten Aufgaben mit Sprach- oder Gestenbefehlen erledigen.
- Räumliches Rechnen: Da die AR/VR-Technologie immer beliebter wird, wird auch die Nachfrage nach KI-Agenten steigen. Die Agenten können Umgebungsinformationen verarbeiten und Aufgaben bei Bedarf ausführen. Dies könnte in Kürze einer der besten Anwendungsfälle für KI-Agenten sein.
- LLM-Betriebssystem: AI-first-Betriebssysteme, bei denen Agenten erstklassige Bürger sind. Agenten sind für die Erledigung alltäglicher bis komplexer Aufgaben verantwortlich.
Zusammenfassung
LangGraph ist ein effizientes Framework zum Aufbau zyklischer zustandsbehafteter Multi-Akteur-Agentensysteme. Es füllt die Lücke im ursprünglichen LangChain-Framework. Da es sich um eine Erweiterung von LangChain handelt, können wir von allen Vorteilen des LangChain-Ökosystems profitieren. Mit zunehmender Qualität und Leistungsfähigkeit von LLMs wird es viel einfacher, Agentensysteme zur Automatisierung komplexer Arbeitsabläufe zu erstellen. Hier sind also die wichtigsten Erkenntnisse aus dem Artikel.
Key Take Away
- LangGraph ist eine Erweiterung von LangChain, die es uns ermöglicht, zyklische, zustandsbehaftete Agentensysteme mit mehreren Akteuren zu erstellen.
- Es implementiert eine Graphenstruktur mit Knoten und Kanten. Die Knoten sind Funktionen oder Werkzeuge und die Kanten sind die Verbindungen zwischen Knoten.
- Es gibt zwei Arten von Kanten: bedingt und normal. Bedingte Kanten unterliegen beim Übergang von einer Kante zur anderen Bedingungen, was für die Zyklizität des Arbeitsablaufs wichtig ist.
- LangGraph wird für die Erstellung zyklischer Multi-Akteur-Agenten bevorzugt, während LangChain sich besser für die Erstellung von Ketten oder gerichteten azyklischen Systemen eignet.
Häufig gestellte Fragen
Antwort. LangGraph ist eine Open-Source-Bibliothek zum Aufbau zustandsbehafteter zyklischer Agentensysteme mit mehreren Akteuren. Es basiert auf dem LangChain-Ökosystem.
Antwort. LangGraph wird für die Erstellung zyklischer Multi-Akteur-Agenten bevorzugt, während LangChain sich besser für die Erstellung von Ketten oder gerichteten azyklischen Systemen eignet.
Antwort. KI-Agenten sind Softwareprogramme, die mit ihrer Umgebung interagieren, Entscheidungen treffen und handeln, um ein Endziel zu erreichen.
Antwort. Dies hängt von Ihren Anwendungsfällen und Ihrem Budget ab. GPT 4 ist das leistungsfähigste, aber teuerste. Für die Codierung ist DeepSeekCoder-33b eine tolle, günstigere Option.
Antwort. Bei den Ketten handelt es sich um eine Abfolge fest codierter Aktionen, denen gefolgt werden muss, während die Agenten LLMs und andere Tools (auch Ketten) verwenden, um auf der Grundlage der Informationen Schlüsse zu ziehen und entsprechend zu handeln
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/build-an-ai-coding-agent-with-langgraph-by-langchain/

