Bild vom Herausgeber | Übertragen Sie den Lernfluss von Skyengine.ai
Wenn es um die Maschinelles LernenDort, wo der Appetit auf Daten unstillbar ist, hat nicht jeder den Luxus, jederzeit auf riesige Datensätze zuzugreifen und daraus zu lernen – genau dort Transferlernen kommt zur Rettung, insbesondere wenn Sie nur über begrenzte Daten verfügen oder die Kosten für die Beschaffung weiterer Daten einfach zu hoch sind.
In diesem Artikel werfen wir einen genaueren Blick auf die Magie des Transferlernens und zeigen, wie es Modelle, die bereits aus riesigen Datensätzen gelernt haben, geschickt nutzt, um Ihren eigenen maschinellen Lernprojekten einen deutlichen Schub zu verleihen, selbst wenn Ihre Daten eher dünn sind.
Ich werde die Hürden angehen, die mit der Arbeit in datenarmen Umgebungen einhergehen, einen Blick auf die Zukunft werfen und die Vielseitigkeit und Effektivität des Transferlernens in allen möglichen Bereichen feiern.
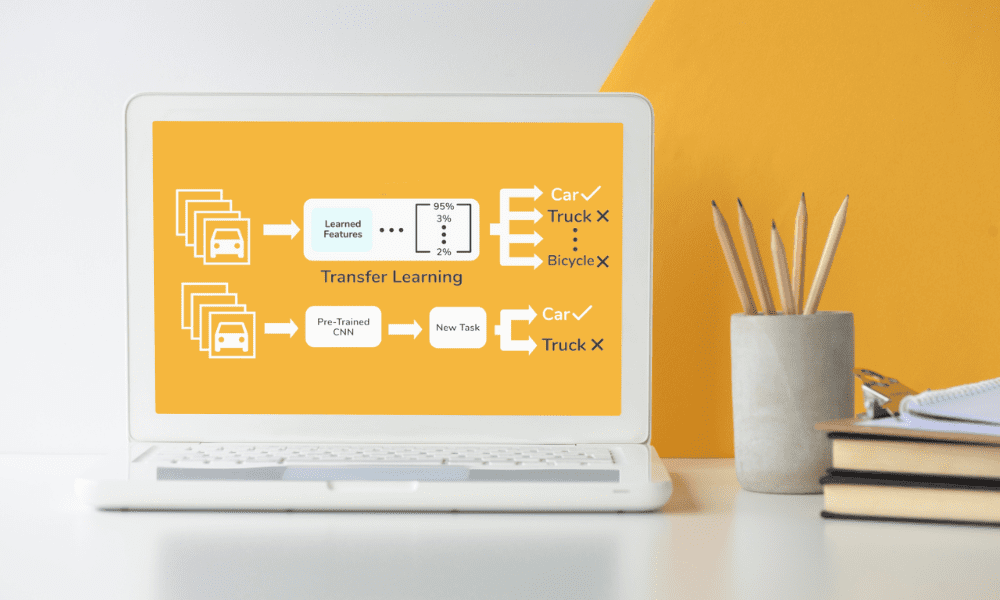
Transferlernen ist ein Technik, die beim maschinellen Lernen verwendet wird Dabei wird ein für eine Aufgabe entwickeltes Modell für eine zweite, verwandte Aufgabe verwendet und weiterentwickelt.
Im Kern basiert dieser Ansatz auf der Idee, dass das beim Erlernen eines Problems gewonnene Wissen bei der Lösung eines anderen, einigermaßen ähnlichen Problems hilfreich sein kann.
Zum Beispiel ein Modell, das darauf trainiert ist, Objekte in Bildern zu erkennen kann angepasst werden, um bestimmte Tierarten auf Fotos zu erkennenDabei nutzt es sein bereits vorhandenes Wissen über Formen, Texturen und Muster.
Es beschleunigt aktiv den Trainingsprozess und reduziert gleichzeitig die benötigte Datenmenge deutlich. In kleinen Datenszenarien ist dies besonders vorteilhaft, da es den herkömmlichen Bedarf an großen Datensätzen umgeht, um eine hohe Modellgenauigkeit zu erreichen.
Durch die Verwendung vorab trainierter Modelle können Praktiker viele dieser Probleme umgehen anfängliche Hürden, die häufig mit der Modellentwicklung verbunden sindB. Funktionsauswahl und Modellarchitekturdesign.
Vorab trainierte Modelle dienen als eigentliche Grundlage für Transferlernen. Diese Modelle, die häufig von Forschungseinrichtungen oder Technologiegiganten anhand umfangreicher Datensätze entwickelt und trainiert werden, werden der Öffentlichkeit zur Verfügung gestellt.
Die Vielseitigkeit von vorgefertigte Modelle ist bemerkenswert, mit Anwendungen, die von der Bild- und Spracherkennung bis zur Verarbeitung natürlicher Sprache reichen. Die Übernahme dieser Modelle für neue Aufgaben kann die Entwicklungszeit und die benötigten Ressourcen drastisch verkürzen.
Zum Beispiel, Modelle, die auf der ImageNet-Datenbank trainiert wurden, das Millionen von beschrifteten Bildern in Tausenden von Kategorien enthält, bietet einen umfangreichen Funktionsumfang für eine Vielzahl von Bilderkennungsaufgaben.
Die Anpassungsfähigkeit dieser Modelle an neue, kleinere Datensätze unterstreicht ihren Wert und ermöglicht die Extraktion komplexer Merkmale, ohne dass umfangreiche Rechenressourcen erforderlich sind.
Die Arbeit mit begrenzten Daten stellt einzigartige Herausforderungen dar –Das Hauptanliegen ist die Überanpassung, bei dem ein Modell die Trainingsdaten, einschließlich ihres Rauschens und ihrer Ausreißer, zu gut lernt, was zu einer schlechten Leistung bei unsichtbaren Daten führt.
Transferlernen mindert dieses Risiko, indem es Modelle verwendet, die vorab auf verschiedenen Datensätzen trainiert wurden, und so die Generalisierung verbessert.
Die Wirksamkeit des Transferlernens hängt jedoch von der Relevanz des vorab trainierten Modells für die neue Aufgabe ab. Wenn die Aufgaben zu unterschiedlich sind, kommen die Vorteile des Transferlernens möglicherweise nicht vollständig zum Tragen.
Außerdem, Feinabstimmung eines vorab trainierten Modells mit einem kleinen Datensatz erfordert eine sorgfältige Anpassung der Parameter, um zu vermeiden, dass das wertvolle Wissen, das das Modell bereits erworben hat, verloren geht.
Zusätzlich zu diesen Hürden gibt es ein weiteres Szenario, in dem Daten gefährdet werden können, nämlich während des Komprimierungsprozesses. Dies gilt sogar für ganz einfache Aktionen, etwa wenn Sie es möchten PDF-Dateien komprimieren, aber zum Glück können solche Vorkommnisse durch sorgfältige Änderungen verhindert werden.
Im Kontext des maschinellen Lernens Sicherstellung der Vollständigkeit und Qualität der Daten Selbst wenn eine Komprimierung zur Speicherung oder Übertragung durchgeführt wird, ist dies für die Entwicklung eines zuverlässigen Modells von entscheidender Bedeutung.
Transferlernen, das auf vorab trainierten Modellen basiert, unterstreicht die Notwendigkeit einer sorgfältigen Umsetzung Verwaltung von Datenressourcen um Informationsverluste zu verhindern und sicherzustellen, dass jedes Datenelement in der Schulungs- und Bewerbungsphase optimal genutzt wird.
Die Beibehaltung erlernter Funktionen mit der Anpassung an neue Aufgaben in Einklang zu bringen, ist ein heikler Prozess, der ein tiefes Verständnis sowohl des Modells als auch der vorliegenden Daten erfordert.
Das Der Horizont des Transferlernens erweitert sich ständig, wobei die Forschung die Grenzen des Möglichen verschiebt.
Ein spannender Weg hier ist die Entwicklung von universellere Modelle die mit minimalem Anpassungsaufwand auf ein breiteres Aufgabenspektrum angewendet werden kann.
Ein weiterer Forschungsbereich ist die Verbesserung von Algorithmen für den Wissenstransfer zwischen sehr unterschiedlichen Bereichen, wodurch die Flexibilität des Transferlernens erhöht wird.
Es besteht auch ein wachsendes Interesse daran, den Prozess der Auswahl und Feinabstimmung vorab trainierter Modelle für bestimmte Aufgaben zu automatisieren, was die Eintrittsbarriere für den Einsatz fortschrittlicher Techniken des maschinellen Lernens weiter senken könnte.
Diese Fortschritte versprechen, das Transferlernen noch zugänglicher und effektiver zu machen und neue Möglichkeiten für seine Anwendung in Bereichen zu eröffnen, in denen Daten knapp oder schwer zu sammeln sind.
Das Schöne am Transferlernen liegt in seiner Anpassungsfähigkeit, die sich über alle möglichen Bereiche hinweg anwenden lässt.
Aus dem Gesundheitswesen, wo es möglich ist helfen bei der Diagnose von Krankheiten B. mit begrenzten Patientendaten, bis hin zur Robotik, wo sie das Erlernen neuer Aufgaben ohne umfangreiche Schulung beschleunigt, sind die potenziellen Anwendungen enorm.
Im Bereich der Verarbeitung natürlicher SpracheDas Transferlernen hat erhebliche Fortschritte bei Sprachmodellen mit vergleichsweise kleinen Datensätzen ermöglicht.
Diese Anpassungsfähigkeit zeigt nicht nur die Effizienz des Transferlernens, sondern unterstreicht auch sein Potenzial, den Zugang zu fortschrittlichen Techniken des maschinellen Lernens zu demokratisieren, um kleineren Organisationen und Forschern die Durchführung von Projekten zu ermöglichen, die zuvor aufgrund von Datenbeschränkungen für sie unerreichbar waren.
Auch wenn es ein Django-Plattformkönnen Sie Transferlernen nutzen, um die Fähigkeiten Ihrer Anwendung zu verbessern ohne bei Null anzufangen alle immer wieder.
Transferlernen überschreitet die Grenzen bestimmter Programmiersprachen oder Frameworks und ermöglicht die Anwendung fortschrittlicher Modelle des maschinellen Lernens auf Projekte, die in unterschiedlichen Umgebungen entwickelt werden.
Transferlernen ist nicht nur über die Überwindung der Datenknappheit; Es ist auch ein Beweis für Effizienz und Ressourcenoptimierung beim maschinellen Lernen.
Indem Forscher und Entwickler auf dem Wissen aus vorab trainierten Modellen aufbauen, können sie mit weniger Rechenleistung und weniger Zeit signifikante Ergebnisse erzielen.
Diese Effizienz ist besonders wichtig in Szenarien, in denen die Ressourcen begrenzt sind, sei es in Bezug auf Daten, Rechenkapazitäten oder beides.
Da 43% aller Websites Wenn Sie WordPress als CMS verwenden, ist dies ein großartiges Testgelände für ML-Modelle, die sich beispielsweise auf Folgendes spezialisiert haben: Bahnkratzen oder Vergleich verschiedener Arten von Inhalten auf kontextuelle und sprachliche Unterschiede.
Dies unterstreicht die praktische Vorteile des Transferlernens in realen Szenarien, wo der Zugriff auf umfangreiche, domänenspezifische Daten möglicherweise eingeschränkt ist. Transferlernen fördert auch die Wiederverwendung bestehender Modelle und orientiert sich an nachhaltigen Praktiken, indem der Bedarf an energieintensiven Schulungen von Grund auf reduziert wird.
Der Ansatz veranschaulicht, wie die strategische Ressourcennutzung zu erheblichen Fortschritten beim maschinellen Lernen führen und anspruchsvolle Modelle zugänglicher und umweltfreundlicher machen kann.
Am Ende unserer Untersuchung des Transferlernens wird deutlich, dass diese Technik das maschinelle Lernen, wie wir es kennen, erheblich verändert, insbesondere für Projekte, die mit begrenzten Datenressourcen zu kämpfen haben.
Transferlernen ermöglicht die effektive Nutzung vorab trainierter Modelle, sodass sowohl kleine als auch große Projekte bemerkenswerte Ergebnisse erzielen können ohne dass umfangreiche Datensätze erforderlich sind oder Rechenressourcen.
Mit Blick auf die Zukunft ist das Potenzial für Transferlernen enorm und vielfältig, und die Aussicht, maschinelle Lernprojekte praktikabler und weniger ressourcenintensiv zu machen, ist nicht nur vielversprechend; es wird bereits Realität.
Dieser Wandel hin zu zugänglicheren und effizienteren Methoden des maschinellen Lernens birgt das Potenzial, Innovationen in zahlreichen Bereichen voranzutreiben, vom Gesundheitswesen bis zum Umweltschutz.
Transferlernen demokratisiert maschinelles Lernen und macht fortschrittliche Techniken einem weitaus breiteren Publikum zugänglich als je zuvor.
Nahla Davis ist Softwareentwickler und Tech Writer. Bevor sie ihre Arbeit ganz der technischen Redaktion widmete, schaffte sie es – neben anderen faszinierenden Dingen – als leitende Programmiererin bei einer erfahrungsorientierten Branding-Organisation von Inc. 5,000 zu arbeiten, zu deren Kunden Samsung, Time Warner, Netflix und Sony zählen.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/exploring-the-potential-of-transfer-learning-in-small-data-scenarios?utm_source=rss&utm_medium=rss&utm_campaign=exploring-the-potential-of-transfer-learning-in-small-data-scenarios

