Einleitung
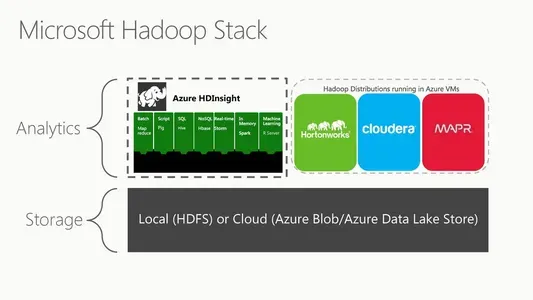
Microsoft Azure HDInsight (oder Microsoft HDFS) ist eine Cloud-basierte Hadoop Distributed File System-Version. Ein verteiltes Dateisystem läuft auf handelsüblicher Hardware und verwaltet riesige Datensammlungen. Es ist eine vollständig verwaltete Cloud-basierte Umgebung zur Analyse und Verarbeitung enormer Datenmengen. HDInsight arbeitet nahtlos mit dem Hadoop-Ökosystem zusammen, das Technologien wie MapReduce, Hive, Pig und Spark umfasst. Es ist auch mit den leistungsstarken Datenverarbeitungstechnologien von Microsoft wie Azure Data Lake Storage und Azure Blob Storage kompatibel.
Skalierbarkeit ist eines der wichtigsten Merkmale von HDInsight. Microsoft Azure HDInsight verfügt außerdem über Sicherheitsfunktionen auf Unternehmensebene, einschließlich rollenbasierter Zugriffskontrolle, Verschlüsselung und Netzwerkisolierung. HDInsight lässt sich problemlos in andere Cloud-Dienste von Microsoft integrieren, einschließlich Power BI, Azure Stream Analytics und Azure Data Factory. Schließlich handelt es sich um einen vollständig verwalteten Cloud-basierten Dienst, was bedeutet, dass Microsoft für die zugrunde liegende Infrastruktur, Wartung und Upgrades verantwortlich ist.
Lernziele
- Wir werden Microsoft HDFS und seine Funktionsweise in einem signifikanten Datenkontext überprüfen.
- Verstehen, wie man Azure HDInsight in der Cloud nutzt, um enorme Datenmengen zu verarbeiten und zu analysieren
- Wir werden Hadoop-Tools wie MapReduce, Hive und Spark und ihre Verwendung mit HDInsight untersuchen.
- Außerdem lernen Sie die Funktionen verschiedener Knoten in HDInsight kennen.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
HDInsight von Azure ist eine vollständig verwaltete Cloudlösung, auf der bedeutende Datenverarbeitungstechnologien wie Apache Hadoop und Apache Spark ausgeführt werden. Es ist eine Cloud-basierte Hadoop-Implementierung für massive Datenverarbeitung und -analyse in einem verteilten System. Hadoop ist ein frei verfügbares Software-Framework zum Teilen riesiger Datensätze zwischen Rechenknoten. Es spielt eine entscheidende Rolle in der gesamten Hadoop-Infrastruktur. Es handelt sich um ein verteiltes Dateisystem, das Anwendungsdaten auf kostengünstigen Standardservern an mehreren Standorten speichert und so mit hoher Geschwindigkeit zugänglich macht. Die Master/Slave-Architektur von HDFS stellt sicher, dass selbst die umfangreichsten Datensätze ohne Integritäts- oder Leistungsverlust gespeichert und verwaltet werden können.
Das verteilte Dateisystem von HDInsight ist HDFS. Wenn Benutzer Aufgaben an HDInsight senden, werden die Daten automatisch auf die Clusterknoten verteilt und in HDFS gespeichert. HDInsight enthält auch andere Hadoop-Ökosystemkomponenten wie MapReduce, Hive, Pig und Spark für die Verarbeitung und Analyse von Daten in HDFS. HDInsight ist eine Cloud-basierte Plattform, mit der Kunden die Funktionen von Hadoop und seinen Ökosystemprodukten nutzen können, ohne dass eine zugrunde liegende Infrastrukturverwaltung erforderlich ist. Es verwendet HDFS als Dateisystem, um die verteilte Datenspeicherung und -verarbeitung zu erleichtern.

Quelle: hkrtrainings.com
Q2. Wie funktioniert Microsoft Azure Data Lake Storage Gen2 mit HDFS?
Microsoft Azure Data Lake-Speicher Gen2 ist eine Cloud-basierte Speicherlösung mit einem hierarchischen Dateisystem zum Speichern und Analysieren riesiger Datenmengen. Es soll mit großen Datenverarbeitungsplattformen wie Hadoop und Spark interagieren und sich nahtlos mit HDFS verbinden. Azure Data Lake Storage Gen2 enthält eine Hadoop-kompatible Dateisystem (HCFS)-Schnittstelle, die es Hadoop und anderen Big-Data-Verarbeitungstools ermöglicht, auf Daten in Data Lake Storage Gen2 zuzugreifen, als wären sie in HDFS. Kunden können in Data Lake Storage Gen2 gespeicherte Daten mit ihren vorhandenen Hadoop-Tools und -Anwendungen verarbeiten und analysieren.
Wenn Hadoop-Aufträge auf HDInsight ausgeführt werden, werden die Daten automatisch auf die Knoten im Cluster verteilt und in HDFS gespeichert. Azure Data Lake Storage Gen2 kann Daten jedoch direkt im Speicherkonto speichern, ohne eine HDInsight-Sammlung zu erstellen. Auf diese Daten kann dann über die HCFS-Schnittstelle zugegriffen werden, die die gleiche Funktionalität wie HDFS bietet. Azure Data Lake Storage Gen2 bietet auch erweiterte Funktionen wie Azure Blob Storage-Integration, Azure Active Directory-Integration und Sicherheitsfunktionen auf Unternehmensebene wie rollenbasierte Zugriffssteuerung und Verschlüsselung. Insgesamt bietet Data Lake Storage Gen2 eine skalierbare und sichere Speicherlösung für die Verarbeitung und Analyse von Big Data und lässt sich nahtlos in Hadoop und HDFS integrieren.
Q3. Können Sie die Rolle von NameNode und DataNode in HDFS erklären?
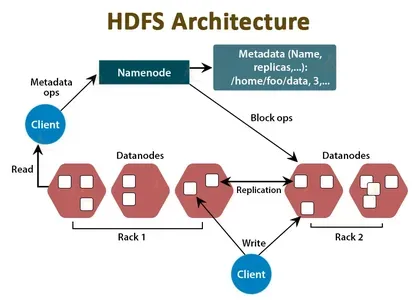
Die NameNode- und DataNode-Komponenten von HDFS schaffen eine verteilte Speicher- und Verarbeitungsumgebung für riesige Datensätze. So funktionieren sie:
- Namensknoten: Der NameNode dient als zentraler Koordinator und Metadatenspeicher des HDFS-Clusters. Es verwaltet Informationen zu Dateispeicherorten, Hierarchien sowie Datei- und Verzeichniseigenschaften. Der NameNode speichert diese Informationen im Arbeitsspeicher und auf der Festplatte und verwaltet den Zugriff auf HDFS-Daten. Wenn eine Clientanwendung Daten von HDFS lesen oder schreiben muss, kontaktiert sie zuerst den NameNode, um den Speicherort der Daten und andere Informationen abzurufen.
- Datenknoten: Der DataNode ist das Arbeitstier von HDFS. Es ist für die Speicherung der Datenblöcke verantwortlich, aus denen die Dateien in HDFS bestehen. Jeder DataNode verwaltet den Speicher für eine Teilmenge der Daten im HDFS-Cluster und dupliziert Daten auf andere DataNodes für Redundanz und Fehlertoleranz. Wenn eine Clientanwendung Daten lesen oder schreiben muss, kommuniziert sie direkt mit den Datenknoten, die die Datenblöcke enthalten.
Zusammenfassend arbeiten NameNode und DataNode zusammen, um ein verteiltes Dateisystem zu erstellen, das in der Lage ist, riesige Datensätze zu speichern und zu verarbeiten. Der NameNode behandelt die Dateiinformationen, während die DataNodes die eigentlichen Datenblöcke enthalten. Um Datenredundanz, Fehlertoleranz und schnellen Datenabruf bereitzustellen, interagieren NameNode und DataNodes miteinander.
Q4. Wie stellt HDFS Datenzuverlässigkeit und Fehlertoleranz sicher?
Es soll einen fehlertoleranten Speicher für riesige Datenmengen bieten. Dazu werden Daten über mehrere Cluster-Knoten dupliziert, Fehler erkannt und behoben und die Zuverlässigkeit und Genauigkeit der Datenspeicherung aufrechterhalten. HDFS gewährleistet Datenzuverlässigkeit und Fehlertoleranz auf folgende Weise:
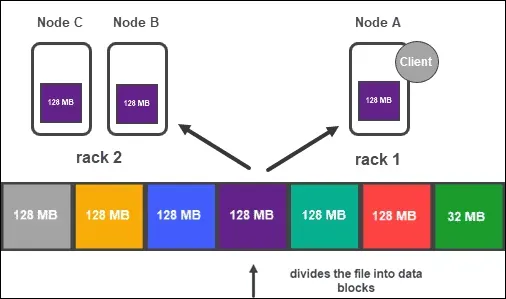
- Es speichert Daten in Blöcken, die über mehrere Datenknoten im Cluster dupliziert werden. Jeder Block wird standardmäßig dreimal repliziert, obwohl dies je nach den Anforderungen der Anwendung geändert werden kann. Die Datenreplikation über mehrere Knoten garantiert, dass Daten auf anderen Knoten verfügbar sind, selbst wenn einer oder mehrere ausfallen.
- Fehlererkennung und Wiederherstellung: HDFS überprüft kontinuierlich den Zustand der Datenknoten des Clusters. Immer wenn ein DataNode ausfällt oder nicht mehr reagiert, bemerkt der NameNode den Fehler und dupliziert die Daten des ausgefallenen Knotens auf andere Knoten im Cluster. Der NameNode aktualisiert dann die Metadaten, um die neuen Speicherorte der replizierten Datenblöcke widerzuspiegeln.
- Datenkonsistenz: Durch eine Write-Once-Read-Many (WORM)-Architektur stellt HDFS sicher, dass Daten zuverlässig und präzise gespeichert werden. Daten, die in HDFS geschrieben wurden, können nicht geändert werden. Dadurch wird die Datenkonsistenz auch dann gewährleistet, wenn mehrere Clients gleichzeitig auf dieselben Daten zugreifen.
- Blockplatzierung: Um zu gewährleisten, dass Datenblöcke auf unterschiedlichen Racks im Cluster platziert werden, verwendet HDFS eine Rack-bewusste Platzierungsstrategie. Dadurch wird sichergestellt, dass selbst bei Ausfall eines ganzen Frames die Daten in den anderen Racks des Clusters weiterhin verfügbar sind.
Insgesamt bietet HDFS durch das Duplizieren von Daten über mehrere Knoten, das Erkennen und Wiederherstellen nach Ausfällen, das Sicherstellen der Datenkonsistenz und den Einsatz einer Rack-bewussten Platzierungsrichtlinie zur Reduzierung von Datenverlusten aufgrund von Rack-Ausfällen eine zuverlässige und fehlertolerante Speicherlösung für riesige Datensätze.
Q5. Können Sie beschreiben, was die NameNode- und DataNode-Rollen in HDFS sind?
HDFS ist ein verteiltes Dateisystem, das riesige Datensätze auf handelsüblicher Hardware in einem Cluster speichert und verarbeitet. Wie in der vorherigen Frage erläutert, umfasst die HDFS-Architektur zwei Hauptkomponenten: den NameNode und den DataNode. Um Datenzuverlässigkeit und Fehlertoleranz bereitzustellen, interagieren NameNode und DataNodes. Wenn ein Client Daten von HDFS lesen oder schreiben muss, kommuniziert er mit dem NameNode, um die Datenblöcke zu finden. Der Client bespricht sich dann direkt mit den DataNodes, um Datenblöcke zu lesen oder zu schreiben.
MapReduce, ein verteiltes Datenverarbeitungs-Framework, wird häufig mit HDFS kombiniert. MapReduce soll große Datensätze handhaben, indem es sie in kleinere Teile aufteilt, die Verarbeitung dieser Blöcke auf einen Cluster von Prozessoren verteilt und die Ergebnisse aggregiert. So interagiert MapReduce mit HDFS:
- Die Eingabedaten werden in HDFS gespeichert. MapReduce empfängt Eingabedaten von HDFS und teilt sie in kleinere Blöcke auf, die als Eingabeaufteilungen bezeichnet werden.
- Die Input-Splits werden über den Cluster verteilt und mit MapReduce bestimmten Map-Jobs zugewiesen. Jeder Map-Job verarbeitet eine einzelne Eingabeaufteilung und erzeugt Zwischenschlüssel-Wert-Paare.
- Die zwischenzeitlichen Schlüssel-Wert-Paare werden dann sortiert und gemischt, bevor sie an die Reduce-Jobs gesendet werden. Jeder Reduce-Job sammelt Zwischeneingaben und generiert das Endergebnis.
- Das Endergebnis wird in HDFS gespeichert.
Insgesamt arbeiten HDFS und MapReduce zusammen, um eine skalierbare, fehlertolerante Architektur für die Verarbeitung massiver Datensätze zu schaffen. Es bietet zuverlässigen Speicher für Eingabe- und Ausgabedaten, während MapReduce die Datenverarbeitung über den gesamten Cluster verteilt.
Q6.Was unterscheidet HDFS von anderen Dateisystemen und welche Vorteile hat die Verwendung von HDFS in einer Umgebung mit riesigen Datenmengen?
HDFS unterscheidet sich von Standard-Dateisystemen in zahlreichen entscheidenden Bereichen, und diese Unterschiede bringen mehrere Vorteile bei der Arbeit mit großen Datenmengen. Dies sind einige wichtige Unterschiede und Vorteile der Verwendung von HDFS in einer Umgebung mit großen Datenmengen:
- Skalierbarkeit: Herkömmliche Dateisysteme sind nicht darauf ausgelegt, die riesigen Datenmengen zu verwalten, die in Big-Data-Situationen häufig vorkommen. Es ist so konzipiert, dass es horizontal wächst, was bedeutet, dass es Petabytes oder sogar Exabytes an Datenspeicherung und -verarbeitung aufnehmen kann, indem es die Daten über einen Cluster von handelsüblicher Hardware verteilt.
- Fehlertoleranz: Es ist fehlertolerant aufgebaut. Es kann den Ausfall einzelner Knoten im Cluster aushalten, indem es Daten über mehrere Knoten im Cluster dupliziert. Es verfügt auch über Techniken zur automatischen Erkennung und Wiederherstellung von Knotenausfällen.
- Es soll einen hohen Durchsatz sowohl beim Lesen als auch beim Schreiben von Daten haben. Bei der Arbeit mit riesigen Dateien kann HDFS schnelle Lese- und Schreibraten erreichen, da es auf massive Datenübertragungen spezialisiert ist.
- Datenlokalität: Es wurde entwickelt, um die Datenlokalität zu maximieren, was bedeutet, dass Daten wo immer möglich auf denselben Cluster-Knoten gespeichert und verarbeitet werden. Die Reduzierung des Datentransfers über das Netzwerk minimiert den Netzwerkverkehr und erhöht die Leistung.
- Kosteneffizienz: Da es für die Ausführung auf handelsüblicher Hardware konzipiert ist, kann es auf kostengünstigen Servern oder in der Cloud implementiert werden. Dadurch bietet es eine kostengünstige Möglichkeit, riesige Datenmengen zu speichern und zu verarbeiten.
Insgesamt sind die Vorteile des Einsatzes von HDFS in einem Big-Data-Kontext Skalierbarkeit, Fehlertoleranz, hoher Durchsatz, Datenlokalisierung und Kosteneffizienz. Durch die Nutzung dieser Funktionen können Unternehmen riesige Datensätze effizienter und kostengünstiger speichern, verwalten und analysieren als herkömmliche Dateisysteme.
Zusammenfassung
In diesem Artikel haben wir verschiedene Funktionen von Microsoft HDFS untersucht, darunter seine Einführung, Architektur, die Arbeit mit Azure Data Lake Storage Gen2 und seine Funktion in MapReduce. Wir sind auch allgemeine Interviewfragen sowohl in Amazon- als auch in Microsoft-Setups durchgegangen. Es ist wichtig für Big-Data-Anwendungen, da es skalierbaren und fehlertoleranten Speicher für riesige Datenmengen bietet. Das Verständnis von Design und Betrieb ist für Dateningenieure und Entwickler, die mit Big-Data-Lösungen arbeiten, von entscheidender Bedeutung.
Hier sind einige wichtige Punkte zum Mitnehmen:
- Es ist ein verteiltes Dateisystem, das riesige Datenmengen auf handelsüblicher Hardware in einem Cluster speichert und verarbeitet.
- Der NameNode und der DataNode sind die beiden grundlegenden Komponenten von HDFS. Der NameNode speichert die Informationen des Dateisystems, während der DataNode die eigentlichen Datenblöcke speichert, aus denen die Dateien bestehen.
- Es ist extrem fehlertolerant und bietet zuverlässigen Speicher für Big-Data-Anwendungen. Es kann Petabytes oder sogar Exabytes an Datenspeicherung und -verarbeitung aufnehmen, indem es die Daten über einen Cluster von handelsüblichen Computern verteilt.
- MapReduce, ein verteiltes Datenverarbeitungs-Framework, kann in Kombination mit HDFS verwendet werden. MapReduce unterteilt riesige Datensätze in kleinere Bits und verteilt deren Verarbeitung über einen Cluster von Prozessoren.
- Schließlich stellt Microsoft HDInsight bereit, eine Cloud-basierte Hadoop-Distribution, die HDFS, MapReduce und andere Komponenten enthält.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
Verbunden
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- Platoblockkette. Web3-Metaverse-Intelligenz. Wissen verstärkt. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2023/03/top-6-microsoft-hdfs-interview-questions/

