
Photo by Google DeepMind
Im unermüdlichen Streben nach Innovation und der Sicherung eines Wettbewerbsvorteils nutzen Unternehmen zunehmend die Leistungsfähigkeit der künstlichen Intelligenz (KI) als transformatives Werkzeug. Das Versprechen der KI, Abläufe zu rationalisieren, Entscheidungsprozesse zu verbessern und verborgene Muster in Daten aufzudecken, hat ihre schnelle Integration in allen Branchen vorangetrieben, insbesondere im Einzelhandel, in der Fertigung und im Vertrieb.
Doch trotz der überzeugenden Möglichkeiten hängt die Erzielung des maximalen Nutzens von KI von einer soliden Grundlage der Datenreife ab. Leider stehen zahlreiche Unternehmen aufgrund verschiedener Faktoren vor der Herausforderung, diesen Reifegrad zu erreichen. Zu diesen Herausforderungen gehören häufig:
- Fragmentierte Datensilos
- Schlechte Datenqualität
- Eingeschränkte Transparenz über Datenbestände und Fähigkeiten
- Organisatorische Trägheit bei der Wiederherstellung eines Gleichgewichts zwischen Technologie als Wegbereiter und Anbieter von Geschäftsdatenanforderungen
In diesem Artikel werde ich präskriptive Strategien zur Bewältigung dieser Herausforderungen hervorheben und eine robuste Datengrundlage für die Skalierung differenzierter KI-Funktionen schaffen.
Führungskräfte aus den Bereichen Einzelhandel, Fertigung und Vertrieb nutzen die Leistungsfähigkeit von KI, um bemerkenswerte Ergebnisse zu erzielen, von der Optimierung von Lieferketten bis hin zur Vorhersage des Kundenverhaltens. Generative KI gewinnt im Mainstream an Bedeutung. Eine kürzlich von Fortune/Deloitte durchgeführte CEO-Umfrage ergab, dass CEOs ein weit verbreitetes Interesse am Potenzial generativer KI haben. In einer aktuellen Umfrage 79 % der Vorstandsvorsitzenden zeigten sich optimistisch hinsichtlich des Potenzials der Technologie zur Steigerung der betrieblichen Effizienz, wobei mehr als die Hälfte mit der Entstehung neuer Wachstumsmöglichkeiten rechnet. Ein erheblicher Teil offenbarte die laufenden Bemühungen, generative KI zu evaluieren und damit zu experimentieren, was einen proaktiven Ansatz zur Nutzung modernster Fortschritte in der Geschäftslandschaft unterstreicht.
Branchenführer mit dem höchsten KI-Reifegrad haben differenzierte Fähigkeiten zur Steigerung des Umsatzes und zur Optimierung des Betriebs unter Beweis gestellt. Beispielsweise hat die KI-gestützte Empfehlungsmaschine von Amazon, die Produkte basierend auf den vergangenen Käufen und dem Browserverlauf eines Kunden vorschlägt, maßgeblich zur Umsatzsteigerung beigetragen. In ähnlicher Weise hat Walmart erfolgreich KI-Algorithmen für die Bestandsverwaltung und Nachfrageprognose eingesetzt, was bedeutet, dass der Einzelhandelsriese KI einsetzt, um sicherzustellen, dass Produkte verfügbar sind, wann und wo seine Kunden sie benötigen.
Doch laut dem AI Maturity Model von Gartner 52 % der mittleren bis großen US-Unternehmen experimentieren immer noch mit KI.
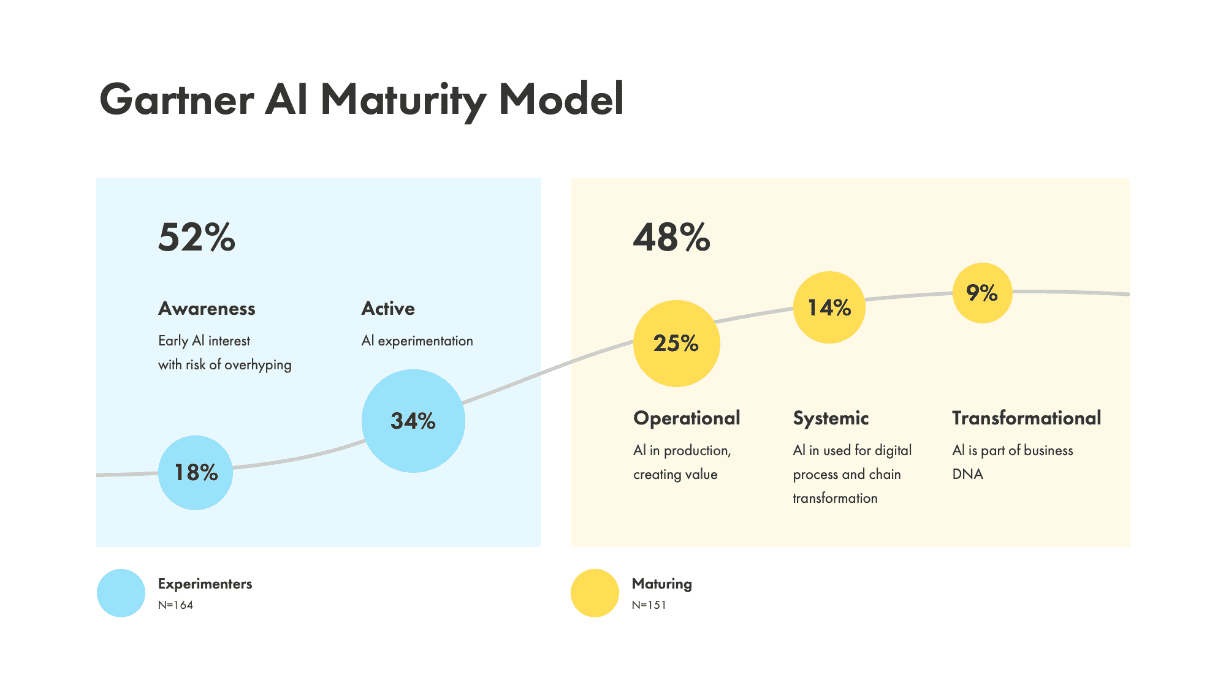
Laut einer aktuellen AWS-Umfrage unter über 300 CDOs sehen Chief Data Officers, die eine wesentliche Rolle bei der Einführung von KI und der Unterstützung der digitalen Transformation spielen und für die Datenstrategie und Governance innerhalb von Organisationen verantwortlich sind, die Datenqualität als eines der größten Hindernisse für die vollständige Nutzung von KI-Funktionen an .
Schauen wir uns die Herausforderungen bei der Datenreife an, die sich auf die Einführung von KI auswirken, und wie man sie bewältigen kann.
Trotz des unbestreitbaren Potenzials von KI benötigen viele Unternehmen aufgrund datenbezogener Hürden Hilfe bei der Skalierung KI-gestützter Anwendungsfälle. Wenn Unternehmen ehrgeizige KI-Initiativen in Angriff nehmen, stoßen sie oft auf erhebliche Hindernisse, die eine rechtzeitige Umsetzung und breite Akzeptanz behindern. Um diese Herausforderungen zu meistern und das Potenzial der KI voll auszuschöpfen, müssen Unternehmen der Datenreife Priorität einräumen.
Unter Datenreife versteht man die Fähigkeit einer Organisation, ihre Datenbestände effektiv zu verwalten, zu steuern und zu nutzen. Es umfasst Datenqualität, Governance, Integration und Analysefunktionen. Ein Mangel an Datenreife kann zu mehreren Herausforderungen führen, die die Einführung und Skalierbarkeit von KI behindern, wie zum Beispiel:
- Datensilos und Fragmentierung: Über unterschiedliche Systeme und Formate verstreute Daten schaffen Datensilos, die eine ganzheitliche unternehmensweite Nutzung verhindern können.
- Probleme mit der Datenqualität: Ungenaue, unvollständige oder inkonsistente Daten können zu fehlerhaften KI-Modellen und unzuverlässigen Erkenntnissen führen.
- Lücken in der Datenverwaltung: Ohne angemessene Data-Governance-Praktiken können Unternehmen mit Problemen im Zusammenhang mit Datensicherheit, Datenschutz und Compliance konfrontiert werden.
- Begrenzte Datenanalysefunktionen: Die Unfähigkeit, aus Daten aussagekräftige Erkenntnisse zu gewinnen, kann die Entwicklung und Anwendung von KI behindern.
Diese Herausforderungen unterstreichen die entscheidende Rolle der Datenreife bei der Ermöglichung der KI-Skalierbarkeit. Um diese Hürden zu überwinden, müssen Unternehmen einen umfassenden Datenmanagement- und Governance-Ansatz verfolgen.
DataArt bietet Unternehmen umfassende Strategien und Lösungen zur Steigerung der Datenreife. Wir bringen unsere Partner zu einem Software-Ökosystem, in dem Daten demokratisiert, agil und zweckorientiert sind und Hindernisse überwinden, die der Einführung von KI im Wege stehen. Durch die Förderung einer Kultur des Dateneigentums, der Befähigung und der Innovation sind Unternehmen besser in der Lage, das transformative Potenzial der KI zu nutzen und skalierbare, KI-gestützte Anwendungsfälle voranzutreiben und sich so an die Spitze einer Zukunft zu setzen, die von datengesteuerter Exzellenz und nachhaltigem Wachstum geprägt ist .
Das Aufkommen der Data Mesh- und Data Product-Strategien kündigt einen transformativen Paradigmenwechsel in der Weltwirtschaft an. Data Mesh, ein neuartiger Architekturansatz, befürwortet die Dezentralisierung des Dateneigentums und der Datenverwaltung und fördert so eine domänengesteuerte Datenarchitektur in einem einzigen Unternehmen. Diese Strategie zielt darauf ab, die Engpässe zentralisierter Data Lakes oder Warehouses zu lindern, indem das Dateneigentum auf domänenspezifische Teams verteilt wird. Durch diese Arbeit der Datenverteilung versetzt Data Mesh Teams in die Lage, ihre Datenprodukte zu kuratieren, zu besitzen und weiterzuentwickeln und so Agilität und Skalierbarkeit zu fördern und gleichzeitig die Datenverwaltung und -qualität aufrechtzuerhalten.
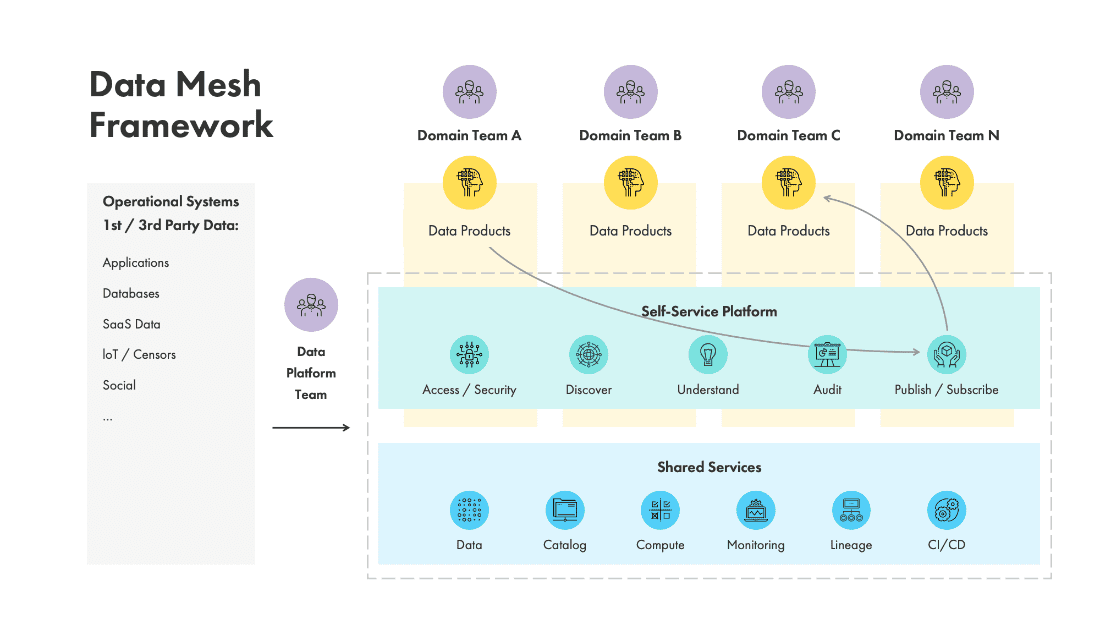
Abbildung 1: Data Mesh-Framework zur Ermöglichung einer schnellen Wertschöpfung durch geschäftsdomänengesteuerte Datenprodukte.
Gleichzeitig festigt die Datenproduktstrategie die Grundlage für die Skalierbarkeit von KI weiter. Es setzt sich für die Konzeptualisierung, Erstellung und Verwaltung von Daten als Produkte ein, die auf spezifische Benutzerbedürfnisse innerhalb einer Organisation zugeschnitten sind. Jedes Datenprodukt umfasst wertvolle Erkenntnisse, vorbereitete Datensätze oder Analysetools, die auf die Nutzung durch verschiedene Interessengruppen zugeschnitten sind. Dieser Ansatz fördert eine Kultur des Dateneigentums und ermöglicht es Teams, Innovationen zu entwickeln, zusammenzuarbeiten und aus kuratierten Datenprodukten umsetzbare Erkenntnisse abzuleiten, wodurch die Einführung von KI beschleunigt wird.
Beispielsweise kann ein analytisches Datenprodukt zur Kundensegmentierung weiter verwendet werden, um Abwanderungsdatenprodukte zu erstellen, und beide können für Marketingzwecke verwendet werden, um hyperpersonalisierte Inhalte für Kunden zu generieren. Ohne ein Datenprodukt oder einen Datenprodukt-Marktplatz müssten Teams viel Zeit damit verbringen, diese Analysefunktionen von Grund auf aufzubauen. Stattdessen können bei jedem neuen Anwendungsfall vorhandene Datenprodukte wiederverwendet und einem neuen Verwendungszweck zugeführt werden, was die Entwicklungszeit verkürzt und konsistentere Ergebnisse erzeugt.
Da Unternehmen aller Branchen nach effektiveren Möglichkeiten zur Verwaltung ihrer Daten suchen, müssen mehrere Faktoren sorgfältig berücksichtigt werden. Bei der Datendemokratisierung geht es darum, Daten für Stakeholder wie Datenwissenschaftler, Geschäftsanalysten, Fachexperten, Management und Führungskräfte zugänglich und verständlich zu machen. Darüber hinaus müssen Unternehmen sicherstellen, dass ihre Daten leicht verfügbar, lesbar, aber auch sicher und konform sind, und zwar mit transparenten Standards und Kontrollen. Durch die Implementierung der richtigen Sicherheits- und Compliance-Maßnahmen können Unternehmen die Datenintegrität, den Datenschutz und die Einhaltung gesetzlicher Vorschriften gewährleisten.
Diese Entwicklung stellt einen grundlegenden Wandel in der Art und Weise dar, wie Unternehmen Daten nutzen. In der Vergangenheit waren IT-Abteilungen für den Aufbau der datenbezogenen Module ihres Unternehmens verantwortlich, wie z. B. Lager und analytische Datenprodukte. Durch die Implementierung eines KI-gestützten Ansatzes zur Datendemokratisierung kann es zu einem Technologievermittler werden, anstatt nur den Datenzugriff und die Datenbereitstellung zu kontrollieren. Mit einem bereitgestellten KI-gestützten System kann die IT ihre Ressourcen darauf konzentrieren, Benutzern die Möglichkeit zu geben, unabhängig in den Daten ihres Unternehmens zu navigieren und daraus Erkenntnisse abzuleiten. Um diesen Übergang zu ermöglichen, ist eine grundlegende Veränderung der Rolle der IT erforderlich, die sich von Gatekeepern zu Partnern bei der Förderung von Zusammenarbeit und Innovation entwickelt.
Die Datenkuratierung spielt eine entscheidende Rolle bei der Sicherstellung der Qualität, Relevanz und Nutzbarkeit von Datenbeständen innerhalb einer Organisation. Aufgrund der schieren Menge und Vielfalt der Datenquellen, der Funktionssilos und des manuellen Aufwands ist die Wartung jedoch oft eine Herausforderung. Dies ist einer der Bereiche, die mit KI verbessert werden können. KI-gesteuerte Tools und Algorithmen können Datenverarbeitungsaufgaben automatisieren, was eine schnellere Kuratierung, Datenbereinigung und Normalisierung ermöglicht und den manuellen Aufwand reduziert. KI-Algorithmen können Muster in Daten erkennen und Informationen kontextualisieren, was eine genauere Kuratierung und Kategorisierung ermöglicht.
Durch die Übernahme und Umsetzung dieser Strategien können Unternehmen eine solide Datenreifebasis schaffen, die es ihnen ermöglicht, die Leistungsfähigkeit der KI effektiv zu nutzen und KI-gestützte Anwendungsfälle unternehmensweit zu skalieren. Darüber hinaus kann DataArt Unternehmen dabei helfen, grundlegende Kernkompetenzen zu etablieren oder zu verbessern, die Technologie, Menschen und Prozesse verbinden, wie zum Beispiel:
- Datensilos aufbrechen: Integration von Daten aus unterschiedlichen Quellen in ein zentrales Repository, um Datenkonsistenz und -zugänglichkeit sicherzustellen.
- Daten-Governance etablieren: Implementierung eines Frameworks, das Dateneigentum, Zugriffskontrollen, Datenqualitätsstandards und Datennutzungsrichtlinien definiert.
- Verbesserung der Datenqualität: Implementierung von Datenqualitätsprüfungen, Bereinigungsprozessen und Anreicherungstechniken zur Verbesserung der Datengenauigkeit und -vollständigkeit.
- Förderung der Datenkompetenz: Schulung der Mitarbeiter zu Datenmanagementprinzipien, Datenanalysetechniken und datengesteuerter Entscheidungsfindung, um die Datennutzung im Unternehmen zu verbessern.
- Investition in die Dateninfrastruktur: Modernisierung der Dateninfrastruktur zur Bewältigung des wachsenden Datenvolumens, der Geschwindigkeit und Vielfalt der Daten und Gewährleistung einer effizienten Datenspeicherung, -verarbeitung und -analyse.
- DataOps nutzen: Implementierung von DataOps-Praktiken zur Automatisierung von Datenverwaltungsprozessen, um eine schnelle Datenbereitstellung und kontinuierliche Verbesserung zu ermöglichen.
- Nutzung cloudbasierter Datenlösungen: Nutzung cloudbasierter Datenplattformen zur Steigerung der Skalierbarkeit, Flexibilität und Kosteneffizienz bei der Datenverwaltung.
- Kontinuierliche Überwachung und Verbesserung: Überwachung der Datenqualität, Governance-Compliance und Nutzungsmuster, um aufkommende Herausforderungen zu erkennen und anzugehen.
Datenreife ist nicht nur eine technische Anforderung; Es ist eine strategische Notwendigkeit für Unternehmen, die das transformative Potenzial der KI erschließen möchten. Durch die Bewältigung der kritischen Herausforderungen im Zusammenhang mit der Datenreife können Unternehmen den Weg für eine Zukunft ebnen, die von datengesteuerten Erkenntnissen und KI-gestützten Innovationen geprägt ist.
Oleg Royz ist Vizepräsident für Einzelhandel und Vertrieb bei DataArt.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/data-maturity-the-cornerstone-of-ai-enabled-innovation?utm_source=rss&utm_medium=rss&utm_campaign=data-maturity-the-cornerstone-of-ai-enabled-innovation

