
Bild erstellt mit dem Segmind SSD-1B-Modell
Sind Sie gespannt darauf, mit der Datenanalyse mit SQL zu beginnen? Nun, vielleicht müssen Sie noch ein wenig warten. Aber warum?
Daten in Datenbanktabellen können oft unübersichtlich sein. Ihre Daten können fehlende Werte, doppelte Datensätze, Ausreißer, inkonsistente Dateneinträge und mehr enthalten. Daher ist es äußerst wichtig, die Daten zu bereinigen, bevor Sie sie mit SQL analysieren können.
Wenn Sie SQL lernen, können Sie nach Belieben Datenbanktabellen erstellen, ändern sowie Datensätze aktualisieren und löschen. In der Praxis ist dies jedoch fast nie der Fall. Möglicherweise verfügen Sie nicht über die Berechtigung, Tabellen zu ändern, Datensätze zu aktualisieren und zu löschen. Sie haben jedoch Lesezugriff auf die Datenbank und können eine Reihe von SELECT-Abfragen ausführen.
In diesem Tutorial erstellen wir eine Datenbanktabelle, füllen sie mit Datensätzen und sehen, wie wir die Daten mit SQL bereinigen können. Beginnen wir mit dem Codieren!
Für dieses Tutorial erstellen wir eine employees Tabelle wie folgt:
-- Create the employees table
CREATE TABLE employees (
employee_id INT PRIMARY KEY,
employee_name VARCHAR(50),
salary DECIMAL(10, 2),
hire_date VARCHAR(20),
department VARCHAR(50)
);
Als nächstes fügen wir einige fiktive Beispieldatensätze in die Tabelle ein:
-- Insert 20 sample records
INSERT INTO employees (employee_id, employee_name, salary, hire_date, department) VALUES
(1, 'Amy West', 60000.00, '2021-01-15', 'HR'),
(2, 'Ivy Lee', 75000.50, '2020-05-22', 'Sales'),
(3, 'joe smith', 80000.75, '2019-08-10', 'Marketing'),
(4, 'John White', 90000.00, '2020-11-05', 'Finance'),
(5, 'Jane Hill', 55000.25, '2022-02-28', 'IT'),
(6, 'Dave West', 72000.00, '2020-03-12', 'Marketing'),
(7, 'Fanny Lee', 85000.50, '2018-06-25', 'Sales'),
(8, 'Amy Smith', 95000.25, '2019-11-30', 'Finance'),
(9, 'Ivy Hill', 62000.75, '2021-07-18', 'IT'),
(10, 'Joe White', 78000.00, '2022-04-05', 'Marketing'),
(11, 'John Lee', 68000.50, '2018-12-10', 'HR'),
(12, 'Jane West', 89000.25, '2017-09-15', 'Sales'),
(13, 'Dave Smith', 60000.75, '2022-01-08', NULL),
(14, 'Fanny White', 72000.00, '2019-04-22', 'IT'),
(15, 'Amy Hill', 84000.50, '2020-08-17', 'Marketing'),
(16, 'Ivy West', 92000.25, '2021-02-03', 'Finance'),
(17, 'Joe Lee', 58000.75, '2018-05-28', 'IT'),
(18, 'John Smith', 77000.00, '2019-10-10', 'HR'),
(19, 'Jane Hill', 81000.50, '2022-03-15', 'Sales'),
(20, 'Dave White', 70000.25, '2017-12-20', 'Marketing');
Wie Sie sehen, habe ich einen kleinen Satz von Vor- und Nachnamen verwendet, um das Namensfeld für die Datensätze zu sampeln und zu erstellen. Bei den Aufzeichnungen können Sie jedoch kreativer sein.
Note: Alle Abfragen in diesem Tutorial beziehen sich auf MySQL. Es steht Ihnen jedoch frei, das RDBMS Ihrer Wahl zu verwenden.
Fehlende Werte in Datensätzen sind immer ein Problem. Man muss also entsprechend damit umgehen.
Ein naiver Ansatz besteht darin, alle Datensätze zu löschen, die fehlende Werte für ein oder mehrere Felder enthalten. Sie sollten dies jedoch nicht tun, es sei denn, Sie sind sicher, dass es keine andere bessere Möglichkeit gibt, mit fehlenden Werten umzugehen.
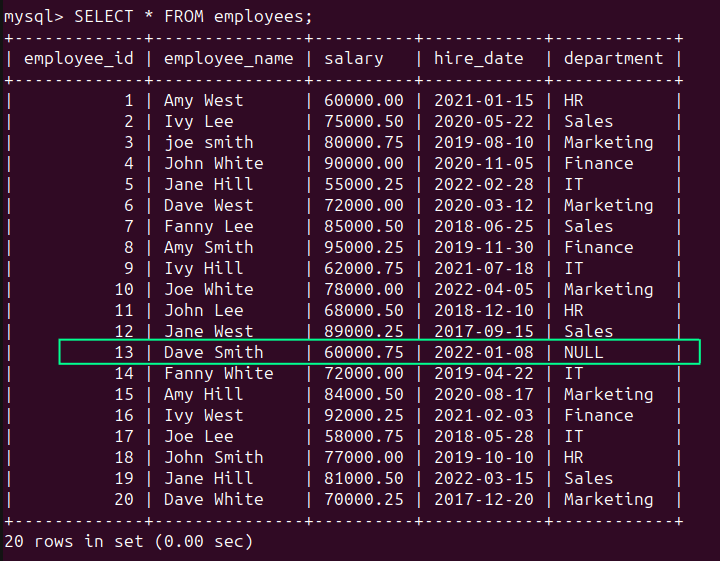
Im employees In der Tabelle sehen wir, dass in der Spalte „Abteilung“ (siehe Zeile von „employee_id“ 13) ein NULL-Wert vorhanden ist, der darauf hinweist, dass das Feld fehlt:
SELECT * FROM employees;
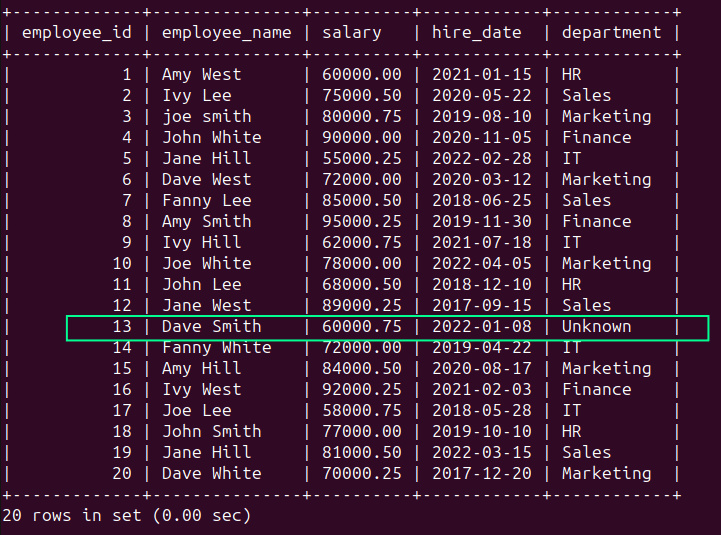
Sie können die Verwendung COALESCE()-Funktion So verwenden Sie die Zeichenfolge „Unbekannt“ für den NULL-Wert:
SELECT
employee_id,
employee_name,
salary,
hire_date,
COALESCE(department, 'Unknown') AS department
FROM employees;
Das Ausführen der obigen Abfrage sollte zu folgendem Ergebnis führen:
Doppelte Datensätze in einer Datenbanktabelle können die Analyseergebnisse verfälschen. Wir haben die Employee_ID als Primärschlüssel in unserer Datenbanktabelle ausgewählt. Wir werden also keine sich wiederholenden Mitarbeiterdatensätze im haben employee_data Tabelle.
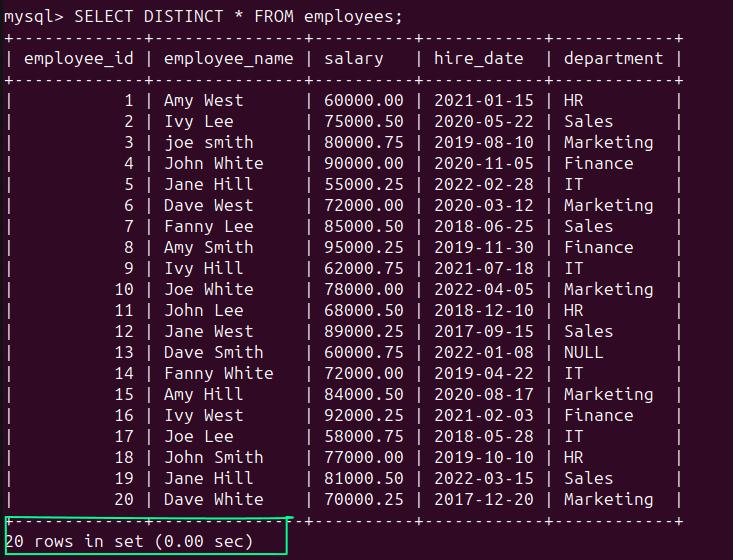
Sie können weiterhin die SELECT DISTINCT-Anweisung verwenden:
SELECT DISTINCT * FROM employees;
Wie erwartet enthält die Ergebnismenge alle 20 Datensätze:
Wie Sie bemerken, ist die Spalte „hire_date“ derzeit VARCHAR und kein Datumstyp. Um die Arbeit mit Datumsangaben zu vereinfachen, ist es hilfreich, das zu verwenden STR_TO_DATE() Funktion so:
SELECT
employee_id,
employee_name,
salary,
STR_TO_DATE(hire_date, '%Y-%m-%d') AS hire_date,
department
FROM employees;
Hier haben wir unter anderem nur die Spalte „hire_date“ ausgewählt und keine Operationen an den Datumswerten durchgeführt. Daher sollte die Abfrageausgabe mit der der vorherigen Abfrage identisch sein.
Wenn Sie jedoch Vorgänge wie das Hinzufügen eines Offset-Datums zu den Werten durchführen möchten, kann diese Funktion hilfreich sein.
Ausreißer in einem oder mehreren numerischen Feldern können die Analyse verzerren. Daher sollten wir nach Ausreißern suchen und diese entfernen, um die Daten herauszufiltern, die nicht relevant sind.
Für die Entscheidung, welche Werte Ausreißer darstellen, sind jedoch Domänenkenntnisse und Daten erforderlich, bei denen sowohl Kenntnisse über die Domäne als auch über historische Daten zum Einsatz kommen.
Nehmen wir in unserem Beispiel an, wir kennt dass die Spalte „Gehalt“ eine Obergrenze von 100000 hat. Daher kann jeder Eintrag in der Spalte „Gehalt“ höchstens 100000 betragen. Und Einträge, die diesen Wert überschreiten, sind Ausreißer.
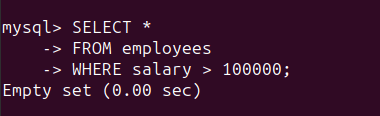
Wir können nach solchen Datensätzen suchen, indem wir die folgende Abfrage ausführen:
SELECT *
FROM employees
WHERE salary > 100000;
Wie ersichtlich, sind alle Einträge in der Spalte „Gehalt“ gültig. Die Ergebnismenge ist also leer:
Inkonsistente Dateneingaben und Formatierungen kommen häufig vor, insbesondere in Datums- und Zeichenfolgenspalten.
Im employees In der Tabelle sehen wir, dass der Datensatz, der dem Mitarbeiter „Bob Johnson“ entspricht, nicht in der Groß-/Kleinschreibung des Titels enthalten ist.
Aus Gründen der Konsistenz wählen wir jedoch alle Namen aus, die im Titelformat formatiert sind. Sie müssen das verwenden CONCAT() Funktion in Verbindung mit OBERER, HÖHER() und UNTERSTRING() so:
SELECT
employee_id,
CONCAT(
UPPER(SUBSTRING(employee_name, 1, 1)), -- Capitalize the first letter of the first name
LOWER(SUBSTRING(employee_name, 2, LOCATE(' ', employee_name) - 2)), -- Make the rest of the first name lowercase
' ',
UPPER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 1, 1)), -- Capitalize the first letter of the last name
LOWER(SUBSTRING(employee_name, LOCATE(' ', employee_name) + 2)) -- Make the rest of the last name lowercase
) AS employee_name_title_case,
salary,
hire_date,
department
FROM employees;
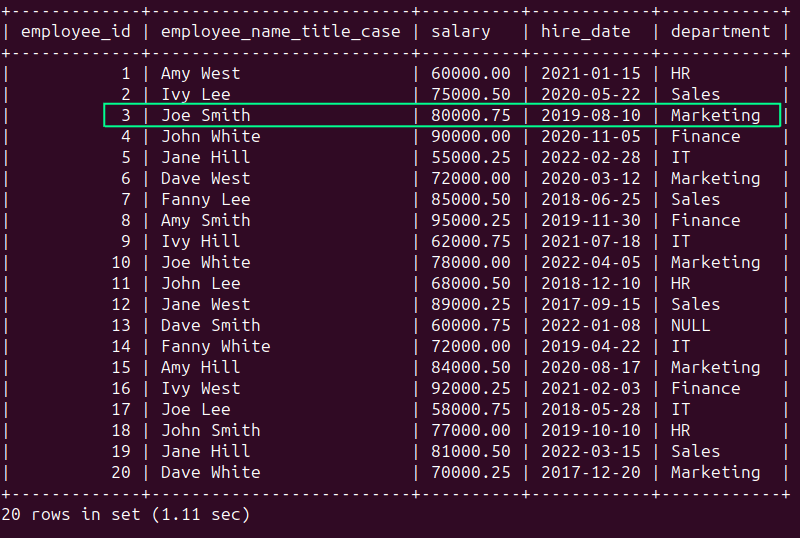
Als wir über Ausreißer sprachen, erwähnten wir, dass die Obergrenze in der Spalte „Gehalt“ 100000 betragen sollte, und betrachteten jeden Gehaltseintrag über 100000 als Ausreißer.
Richtig ist aber auch, dass Sie in der Spalte „Gehalt“ keine negativen Werte haben möchten. Sie können also die folgende Abfrage ausführen, um zu überprüfen, ob alle Mitarbeiterdatensätze Werte zwischen 0 und 100000 enthalten:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department
FROM employees
WHERE salary 0 OR salary > 100000;
Wie man sieht, ist die Ergebnismenge leer:

Das Ableiten neuer Spalten ist nicht unbedingt ein Datenbereinigungsschritt. In der Praxis müssen Sie jedoch möglicherweise vorhandene Spalten verwenden, um neue Spalten abzuleiten, die für die Analyse hilfreicher sind.
So befasst sich beispielsweise die employees Die Tabelle enthält eine Spalte „hire_date“. Ein hilfreicheres Feld ist vielleicht die Spalte „years_of_service“, die angibt, wie lange ein Mitarbeiter schon im Unternehmen ist.
Die folgende Abfrage findet die Differenz zwischen dem aktuellen Jahr und dem Jahreswert in „hire_date“, um die „years_of_service“ zu berechnen:
SELECT
employee_id,
employee_name,
salary,
hire_date,
department,
YEAR(CURDATE()) - YEAR(hire_date) AS years_of_service
FROM employees;
Sie sollten die folgende Ausgabe sehen:

Wie bei anderen Abfragen, die wir ausgeführt haben, wird die ursprüngliche Tabelle dadurch nicht verändert. Um neue Spalten zur Originaltabelle hinzuzufügen, benötigen Sie Berechtigungen zum ÄNDERN der Datenbanktabelle.
Ich hoffe, Sie verstehen, wie relevante Datenbereinigungsaufgaben die Datenqualität verbessern und relevantere Analysen ermöglichen können. Sie haben gelernt, wie Sie nach fehlenden Werten, doppelten Datensätzen, inkonsistenter Formatierung, Ausreißern und mehr suchen.
Versuchen Sie, Ihre eigene relationale Datenbanktabelle zu erstellen und einige Abfragen auszuführen, um häufige Datenbereinigungsaufgaben durchzuführen. Als nächstes erfahren Sie mehr darüber SQL zur Datenvisualisierung.
Bala Priya C ist ein Entwickler und technischer Redakteur aus Indien. Sie arbeitet gerne an der Schnittstelle von Mathematik, Programmierung, Datenwissenschaft und Inhaltserstellung. Zu ihren Interessen- und Fachgebieten gehören DevOps, Datenwissenschaft und Verarbeitung natürlicher Sprache. Sie liebt es zu lesen, zu schreiben, zu programmieren und Kaffee zu trinken! Derzeit arbeitet sie daran, zu lernen und ihr Wissen mit der Entwickler-Community zu teilen, indem sie Tutorials, Anleitungen, Meinungsbeiträge und mehr verfasst.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.kdnuggets.com/data-cleaning-in-sql-how-to-prepare-messy-data-for-analysis?utm_source=rss&utm_medium=rss&utm_campaign=data-cleaning-in-sql-how-to-prepare-messy-data-for-analysis

