Large Language Models (LLMs) sind die treibende Kraft hinter der KI-Revolution, aber das Spiel hat gerade eine große Wendung in der Handlung erfahren. Databricks DBRX, eine bahnbrechende Open-Source-Lösung LLM, ist hier, um den Status quo in Frage zu stellen. DBRX übertrifft etablierte Modelle und konkurriert mit Branchenführern und zeichnet sich durch überragende Leistung und Effizienz aus. Tauchen Sie tief in die Welt der LLMs ein und erfahren Sie, wie DBRX das Regelwerk neu schreibt und einen Einblick in die aufregende Zukunft von bietet Verarbeitung natürlicher Sprache.

Inhaltsverzeichnis
LLMs und Open-Source-LLMs verstehen
Large Language Models (LLMs) sind fortschrittliche Modelle zur Verarbeitung natürlicher Sprache, die menschenähnlichen Text verstehen und generieren können. Diese Modelle haben in verschiedenen Anwendungen wie Sprachverständnis, Programmierung und Mathematik zunehmend an Bedeutung gewonnen.
Open-Source-LLMs spielen eine entscheidende Rolle bei der Entwicklung und Weiterentwicklung der Technologie zur Verarbeitung natürlicher Sprache. Sie bieten der offenen Community und Unternehmen Zugang zu modernsten Sprachmodellen und ermöglichen es ihnen, ihre Modelle für bestimmte Anwendungen und Anwendungsfälle zu erstellen und anzupassen.
Was ist Databricks DBRX?
Databricks DBRX ist ein offenes, universelles Large Language Model (LLM), das von Databricks entwickelt wurde. Es hat einen neuen Stand der Technik für etablierte offene LLMs gesetzt, übertrifft GPT-3.5 und konkurriert mit Gemini 1.0 Pro. DBRX zeichnet sich in verschiedenen Benchmarks aus, darunter Sprachverständnis, Programmierung und Mathematik. Das Training erfolgt mithilfe der Next-Token-Vorhersage mit einer feinkörnigen Expertenmix-Architektur (MoE), was zu erheblichen Verbesserungen der Trainings- und Inferenzleistung führt.
Das Modell steht Databricks-Kunden über APIs zur Verfügung und kann vorab trainiert oder feinabgestimmt werden. Seine Effizienz wird durch die Trainings- und Inferenzleistung unterstrichen, die andere etablierte Modelle übertrifft und dabei etwa 40 % der Größe ähnlicher Modelle beträgt. DBRX ist eine zentrale Komponente der nächsten Generation von GenAI-Produkten von Databricks, die darauf ausgelegt sind, Unternehmen und die offene Community zu stärken.
Die MoE-Architektur von Databricks DBRX
DBRX von Databricks zeichnet sich als Open-Source-Allzweck-Large-Language-Model (LLM) mit einer einzigartigen Architektur für Effizienz aus. Hier ist eine Aufschlüsselung der wichtigsten Funktionen:
- Feinkörnige Expertenmischung (MoE): Diese innovative Architektur nutzt insgesamt 132 Milliarden Parameter, wobei pro Eingang nur 36 Milliarden aktiv sind. Dieser Fokus auf aktive Parameter verbessert die Effizienz im Vergleich zu anderen Modellen erheblich.
- Expertenkraft: DBRX beschäftigt 16 Experten und wählt 4 für jede Aufgabe aus, was erstaunliche 65-mal mehr mögliche Expertenkombinationen bietet, was zu einer überlegenen Modellqualität führt.
- Fortgeschrittene Techniken: Das Modell nutzt modernste Techniken wie Rotary Position Encodings (RoPE), Gated Linear Units (GLU) und Grouped Query Attention (GQA) und steigert so seine Leistung weiter.
- Effizienz-Champion: DBRX bietet bis zu doppelt so hohe Inferenzgeschwindigkeiten wie LLaMA2-70B. Darüber hinaus zeichnet es sich durch eine kompakte Größe aus, da es sowohl in der Gesamtzahl als auch in der Anzahl der aktiven Parameter etwa 40 % kleiner als Grok-1 ist.
- Leistung in der Praxis: Wenn DBRX auf dem Mosaik AI Model Serving gehostet wird, liefert es Textgenerierungsgeschwindigkeiten von bis zu 150 Token pro Sekunde und Benutzer.
- Leiter für Schulungseffizienz: Der Trainingsprozess für DBRX zeigt erhebliche Verbesserungen der Recheneffizienz. Es erfordert etwa die Hälfte der FLOPs (Fließkommaoperationen) im Vergleich zum Training dichter Modelle für die gleiche Endqualität.
Training DBRX
Das Training eines leistungsstarken LLM wie DBRX ist nicht ohne Hürden. Hier ist ein genauerer Blick auf den Trainingsprozess:
- Challenges: Die Entwicklung von Expertenmischungsmodellen wie DBRX stellte erhebliche wissenschaftliche und leistungsbezogene Hürden dar. Databricks musste diese Herausforderungen meistern, um eine robuste Pipeline zu schaffen, die in der Lage ist, Modelle der DBRX-Klasse effizient zu trainieren.
- Effizienzdurchbruch: Der Trainingsprozess für DBRX hat bemerkenswerte Verbesserungen der Recheneffizienz erzielt. Nehmen Sie DBRX MoE-B, ein kleineres Modell der DBRX-Familie, das im Vergleich zu anderen Modellen 1.7-mal weniger FLOPs (Floating-Point-Operationen) benötigte, um beim Databricks LLM Gauntlet eine Punktzahl von 45.5 % zu erreichen.
- Effizienzführer: Dieser Erfolg unterstreicht die Wirksamkeit des DBRX-Trainingsprozesses. Es positioniert DBRX als Spitzenreiter unter den Open-Source-Modellen und konkurriert bei RAG-Aufgaben sogar mit GPT-3.5 Turbo, und das alles bei gleichzeitig überlegener Effizienz.
DBRX im Vergleich zu anderen LLMs

Metriken und Ergebnisse
- DBRX wurde anhand etablierter Open-Source-Modelle für Sprachverständnisaufgaben gemessen.
- Es hat GPT-3.5 übertroffen und ist mit Gemini 1.0 Pro konkurrenzfähig.
- Das Modell hat seine Fähigkeiten in verschiedenen Benchmarks unter Beweis gestellt, darunter zusammengesetzte Benchmarks, Programmierung, Mathematik und MMLU.
- Bei Standard-Benchmarks hat es alle fein abgestimmten Chat- oder Anleitungsmodelle übertroffen und bei zusammengesetzten Benchmarks wie dem Hugging Face Open LLM Leaderboard und dem Databricks Model Gauntlet die höchste Punktzahl erzielt.
- Darüber hinaus hat DBRX Instruct eine überlegene Leistung bei Aufgaben mit langem Kontext und RAG gezeigt und GPT-3.5 Turbo bei allen Kontextlängen und allen Teilen der Sequenz übertroffen.
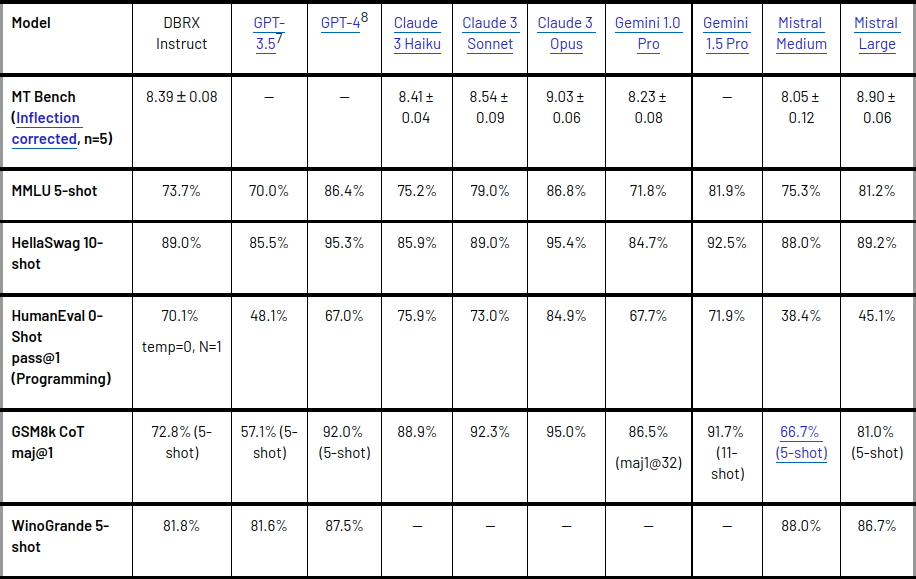
Stärken und Schwächen im Vergleich zu anderen Modellen
DBRX Instruct hat seine Stärken in den Bereichen Programmierung und Mathematik unter Beweis gestellt und bei Benchmarks wie HumanEval und GSM8k bessere Ergebnisse erzielt als andere offene Modelle. Es hat auch mit Gemini 1.0 Pro und Mistral Medium eine konkurrenzfähige Leistung gezeigt und Gemini 1.0 Pro in mehreren Benchmarks übertroffen. Es ist jedoch wichtig zu beachten, dass Modellqualität und Inferenzeffizienz typischerweise im Spannungsfeld stehen, und während DBRX in der Qualität herausragt, sind kleinere Modelle bei der Inferenz effizienter. Dennoch hat sich gezeigt, dass DBRX bessere Kompromisse zwischen Modellqualität und Inferenzeffizienz erzielt, als dies bei dichten Modellen normalerweise der Fall ist.
Wichtige Innovationen bei DBRX
DBRX, entwickelt von Databricks, führt mehrere wichtige Innovationen ein, die es von bestehenden Open-Source- und proprietären Modellen unterscheiden. Das Modell nutzt eine feinkörnige Expertenmix-Architektur (MoE) mit insgesamt 132 Milliarden Parametern, von denen 36 Milliarden bei jeder Eingabe aktiv sind.
Diese Architektur ermöglicht es DBRX, einen robusten und effizienten Trainingsprozess bereitzustellen, der GPT-3.5 Turbo übertrifft und GPT-4 Turbo in Anwendungen wie SQL herausfordert. Darüber hinaus beschäftigt DBRX 16 Experten und wählt 4 aus, was 65-mal mehr mögliche Kombinationen von Experten bietet, was zu einer verbesserten Modellqualität führt.
Das Modell umfasst außerdem rotierende Positionskodierungen (RoPE), Gated Linear Units (GLU) und Grouped Query Attention (GQA), was zu seiner außergewöhnlichen Leistung beiträgt.
Vorteile von DBRX gegenüber bestehenden Open-Source- und proprietären Modellen
DBRX bietet mehrere Vorteile gegenüber bestehenden Open-Source- und proprietären Modellen. Es übertrifft GPT-3.5 und ist mit Gemini 1.0 Pro konkurrenzfähig, wobei es seine Fähigkeiten in verschiedenen Benchmarks unter Beweis stellt, darunter zusammengesetzte Benchmarks, Programmierung, Mathematik und MMLU.
- Darüber hinaus übertrifft DBRX Instruct, eine Variante von DBRX, GPT-3.5 in Bezug auf Allgemeinwissen, vernünftiges Denken, Programmierung und mathematisches Denken.
- Es zeichnet sich auch bei Aufgaben mit langem Kontext aus und übertrifft GPT-3.5 Turbo bei allen Kontextlängen und allen Teilen der Sequenz.
- Darüber hinaus ist DBRX Instruct mit Gemini 1.0 Pro und Mistral Medium konkurrenzfähig und übertrifft Gemini 1.0 Pro in mehreren Benchmarks.
Die Effizienz des Modells wird durch seine Trainings- und Inferenzleistung unterstrichen, die andere etablierte Modelle übertrifft und dabei etwa 40 % der Größe ähnlicher Modelle beträgt. Die feinkörnige MoE-Architektur und der Trainingsprozess von DBRX haben erhebliche Verbesserungen der Recheneffizienz gezeigt und sind damit etwa doppelt so FLOP-effizienter als das Training dichter Modelle bei gleicher endgültiger Modellqualität.
Lesen Sie auch: Claude vs. GPT: Welches ist ein besseres LLM?
Zusammenfassung
Databricks DBRX stellt mit seiner innovativen Experten-Mix-Architektur GPT-3.5 in den Schatten und konkurriert im Sprachverständnis mit Gemini 1.0 Pro. Sein feinkörniges MoE, fortschrittliche Techniken und überlegene Recheneffizienz machen es zu einer überzeugenden Lösung für Unternehmen und die offene Community und versprechen bahnbrechende Fortschritte in der Verarbeitung natürlicher Sprache. Die Zukunft von LLMs ist rosiger, wenn DBRX den Weg weist.
Folge uns auf Google News um über die neuesten Innovationen in der Welt der KI, Datenwissenschaft & auf dem Laufenden zu bleiben GenAI.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/databricks-dbrx/

