Einleitung
In der heutigen schnelllebigen Welt der lokalen Lebensmittellieferungen ist die Gewährleistung der Kundenzufriedenheit für Unternehmen von entscheidender Bedeutung. Große Player wie Zomato und Swiggy dominieren diese Branche. Kunden erwarten frische Lebensmittel; Wenn sie verdorbene Artikel erhalten, freuen sie sich über eine Rückerstattung oder einen Rabattgutschein. Allerdings ist die manuelle Bestimmung der Lebensmittelfrische für Kunden und Mitarbeiter des Unternehmens umständlich. Eine Lösung besteht darin, diesen Prozess mithilfe von Deep-Learning-Modellen zu automatisieren. Diese Modelle können die Frische von Lebensmitteln vorhersagen, sodass nur gemeldete Beschwerden von den Mitarbeitern zur endgültigen Validierung überprüft werden können. Wenn das Modell die Frische der Lebensmittel bestätigt, kann es die Beschwerde automatisch abweisen. In diesem Artikel werden wir mithilfe von Deep Learning einen Lebensmittelqualitätsdetektor erstellen.
Deep Learning, eine Teilmenge der künstlichen Intelligenz, bietet in diesem Zusammenhang einen erheblichen Nutzen. Konkret können CNNs (Convolutional Neural Networks) eingesetzt werden, um Modelle anhand von Bildern von Lebensmitteln zu trainieren, um deren Frische zu erkennen. Die Genauigkeit unseres Modells hängt vollständig von der Qualität des Datensatzes ab. Im Idealfall würde die Integration echter Lebensmittelbilder aus den Chatbot-Beschwerden der Benutzer in hyperlokale Lebensmittelliefer-Apps die Genauigkeit erheblich verbessern. Da wir jedoch keinen Zugriff auf solche Daten haben, stützen wir uns auf einen weit verbreiteten Datensatz namens „Fresh and Rotten Classification Dataset“, der auf Kaggle zugänglich ist. Um den vollständigen Deep-Learning-Code zu erkunden, klicken Sie einfach auf die bereitgestellte Schaltfläche „Kopieren und Bearbeiten“. hier.
Lernziele
- Erfahren Sie, wie wichtig die Lebensmittelqualität für die Kundenzufriedenheit und das Geschäftswachstum ist.
- Entdecken Sie, wie Deep Learning beim Aufbau des Lebensmittelqualitätsdetektors hilft.
- Sammeln Sie praktische Erfahrungen durch die schrittweise Umsetzung dieses Modells.
- Verstehen Sie die Herausforderungen und Lösungen, die mit der Umsetzung verbunden sind.
Dieser Artikel wurde als Teil des veröffentlicht Data Science-Blogathon.
Inhaltsverzeichnis
Verstehen der Verwendung von Deep Learning im Lebensmittelqualitätsdetektor
Tiefes Lernen, eine Teilmenge von Artificial Intelligence, verwendet hauptsächlich räumliche Datensätze, um Modelle zu erstellen. Zum Trainieren dieser Modelle werden neuronale Netze im Rahmen von Deep Learning genutzt, die die Funktionalität des menschlichen Gehirns nachahmen.
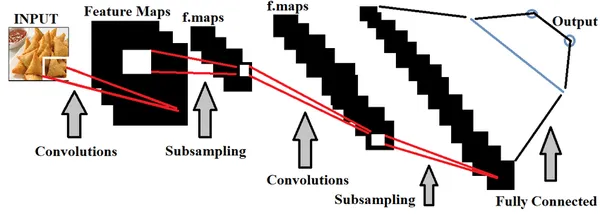
Im Zusammenhang mit der Erkennung der Lebensmittelqualität ist das Training von Deep-Learning-Modellen mit umfangreichen Sätzen von Lebensmittelbildern unerlässlich, um genau zwischen Lebensmitteln guter und schlechter Qualität unterscheiden zu können. Wir können es schaffen Hyperparameter-Tuning basierend auf den eingespeisten Daten, um das Modell genauer zu machen.
Bedeutung der Lebensmittelqualität bei der hyperlokalen Lieferung
Die Integration dieser Funktion in die hyperlokale Lebensmittellieferung bietet mehrere Vorteile. Das Modell vermeidet eine Voreingenommenheit gegenüber bestimmten Kunden und liefert genaue Vorhersagen, wodurch die Zeit für die Lösung von Beschwerden verkürzt wird. Darüber hinaus können wir diese Funktion während des Auftragsverpackungsprozesses nutzen, um die Qualität der Lebensmittel vor der Lieferung zu prüfen und sicherzustellen, dass die Kunden stets frische Lebensmittel erhalten.

Entwicklung eines Lebensmittelqualitätsdetektors
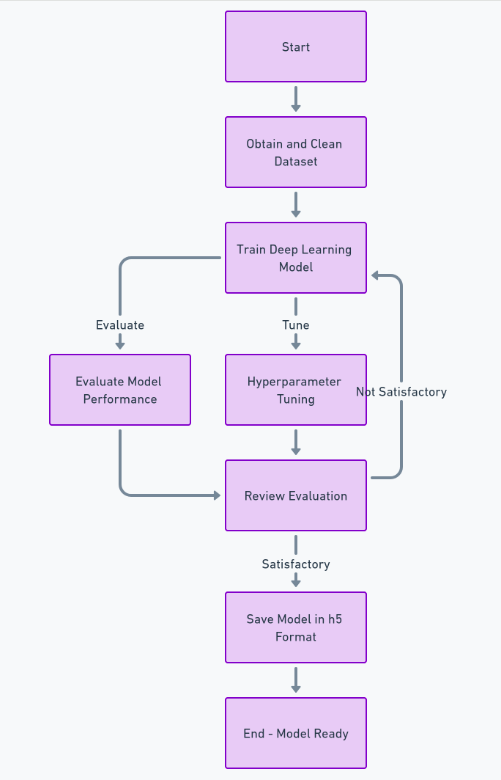
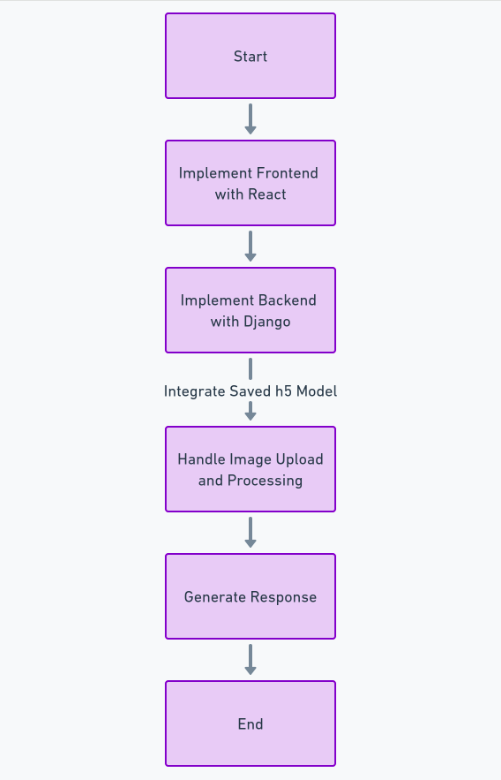
Um diese Funktion vollständig zu erstellen, müssen wir viele Schritte ausführen, z. B. den Datensatz abrufen und bereinigen, das Deep-Learning-Modell trainieren, die Leistung bewerten und Hyperparameter-Tuning durchführen und schließlich das Modell speichern h5 Format. Danach können wir das Frontend mit implementieren Reagierenund das Backend unter Verwendung des Python-Frameworks Django. Wir werden Django verwenden, um das Hochladen und Verarbeiten von Bildern zu übernehmen.
Über den Datensatz
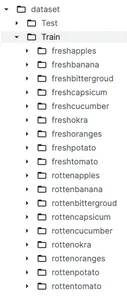
Bevor Sie sich eingehend mit der Datenvorverarbeitung und Modellbildung befassen, ist es wichtig, den Datensatz zu verstehen. Wie bereits erwähnt, verwenden wir einen Datensatz von Kaggle mit dem Namen Klassifizierung frischer und verdorbener Lebensmittel. Dieser Datensatz ist in zwei Hauptkategorien mit dem Namen unterteilt Training und Test welche werden zu Schulungs- bzw. Testzwecken genutzt. Unter dem Zugordner haben wir 9 Unterordner mit frischem Obst und frischem Gemüse und 9 Unterordner mit faulem Obst und faulem Gemüse.
Hauptmerkmale des Datensatzes
- Bildvielfalt: Dieser Datensatz enthält viele Lebensmittelbilder mit vielen Variationen in Bezug auf Winkel, Hintergrund und Lichtverhältnisse. Dies trägt dazu bei, dass das Modell nicht voreingenommen ist und genauer ist.
- Hochwertige Bilder: Dieser Datensatz enthält Bilder von sehr guter Qualität, die von verschiedenen professionellen Kameras aufgenommen wurden.
Laden und Vorbereiten von Daten
In diesem Abschnitt laden wir zunächst die Bilder mit „tensorflow.keras.preprocessing.image.Load_img'Funktion und Visualisierung der Bilder mithilfe der Matplotlib-Bibliothek. Die Vorverarbeitung dieser Bilder für das Modelltraining ist wirklich wichtig. Dabei werden die Bilder bereinigt und organisiert, damit sie für das Modell geeignet sind.
import os
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing.image import load_img
def visualize_sample_images(dataset_dir, categories):
n = len(categories)
fig, axs = plt.subplots(1, n, figsize=(20, 5))
for i, category in enumerate(categories):
folder = os.path.join(dataset_dir, category)
image_file = os.listdir(folder)[0]
img_path = os.path.join(folder, image_file)
img = load_img(img_path)
axs[i].imshow(img)
axs[i].set_title(category)
plt.tight_layout()
plt.show()
dataset_base_dir = '/kaggle/input/fresh-and-stale-classification/dataset'
train_dir = os.path.join(dataset_base_dir, 'Train')
categories = ['freshapples', 'rottenapples', 'freshbanana', 'rottenbanana']
visualize_sample_images(train_dir, categories)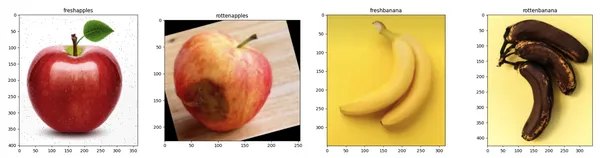
Laden wir nun die Trainings- und Testbilder in Variablen. Wir werden alle Bilder auf die gleiche Höhe und Breite von 180 skalieren.
from tensorflow.keras.preprocessing.image import ImageDataGenerator
batch_size = 32
img_height = 180
img_width = 180
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
validation_split=0.2)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='training')
validation_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(img_height, img_width),
batch_size=batch_size,
class_mode='binary',
subset='validation')
Modellierung
Lassen Sie uns nun das Deep-Learning-Modell mit dem Sequential-Algorithmus von „tensorflow.keras“ erstellen. Wir werden 3 Faltungsschichten und einen Adam-Optimierer hinzufügen. Bevor wir uns mit dem praktischen Teil befassen, wollen wir zunächst verstehen, was die Begriffe „Sequentielles Modell", „Adam Optimierer', und 'Faltungsschicht' bedeuten.
Sequentielles Modell
Das sequentielle Modell besteht aus einem Stapel von Schichten und bietet eine grundlegende Struktur in Keras. Es ist ideal für Szenarien, in denen Ihr neuronales Netzwerk über einen einzelnen Eingabetensor und einen einzelnen Ausgabetensor verfügt. Sie fügen Ebenen in der Reihenfolge ihrer Ausführung hinzu, sodass sie sich für die Konstruktion einfacher Modelle mit gestapelten Ebenen eignen. Diese Einfachheit macht das sequentielle Modell äußerst nützlich und einfacher zu implementieren.
Adam Optimierer
Die Abkürzung von Adam ist „Adaptive Moment Estimation“. Es dient als Optimierungsalgorithmus als Alternative zum stochastischen Gradientenabstieg und aktualisiert die Netzwerkgewichte iterativ. Adam Optimizer ist von Vorteil, da es für jede Netzwerkgewichtung eine Lernrate (LR) beibehält, was beim Umgang mit Rauschen in den Daten von Vorteil ist.
Faltungsschicht (Conv2D)
Es ist die Hauptkomponente der Convolutional Neural Networks (CNNs). Es wird hauptsächlich zur Verarbeitung räumlicher Datensätze wie Bilder verwendet. Diese Schicht wendet eine Faltungsfunktion oder -operation auf die Eingabe an und übergibt das Ergebnis dann an die nächste Schicht.
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(img_height, img_width, 3)),
MaxPooling2D(2, 2),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Conv2D(128, (3, 3), activation='relu'),
MaxPooling2D(2, 2),
Flatten(),
Dense(512, activation='relu'),
Dropout(0.5),
Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
epochs = 10
history = model.fit(
train_generator,
steps_per_epoch=train_generator.samples // batch_size,
epochs=epochs,
validation_data=validation_generator,
validation_steps=validation_generator.samples // batch_size)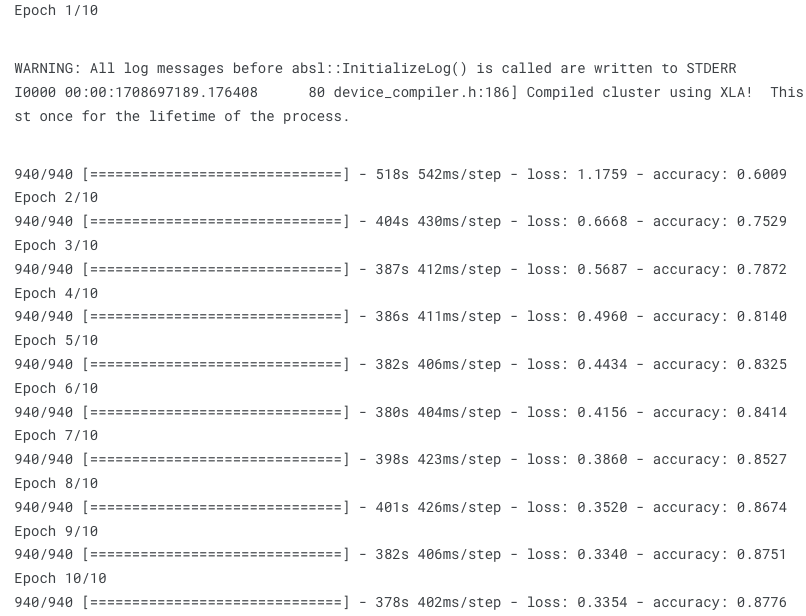
Testen des Lebensmittelqualitätsdetektors
Jetzt testen wir das Modell, indem wir ihm ein neues Lebensmittelbild geben und sehen, wie genau es frische und verdorbene Lebensmittel klassifizieren kann.
from tensorflow.keras.preprocessing import image
import numpy as np
def classify_image(image_path, model):
img = image.load_img(image_path, target_size=(img_height, img_width))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
predictions = model.predict(img_array)
if predictions[0] > 0.5:
print("Rotten")
else:
print("Fresh")
image_path = '/kaggle/input/fresh-and-stale-classification/dataset/Train/
rottenoranges/Screen Shot 2018-06-12 at 11.18.28 PM.png'
classify_image(image_path, model)
Wie wir sehen können, hat das Modell die richtigen Vorhersagen getroffen. Wie wir gegeben haben faulorange Bild als Eingabe, als die das Modell es korrekt vorhergesagt hat Morsch.
Für den Frontend- (React) und Backend-Code (Django) können Sie meinen vollständigen Code auf GitHub hier sehen: Link
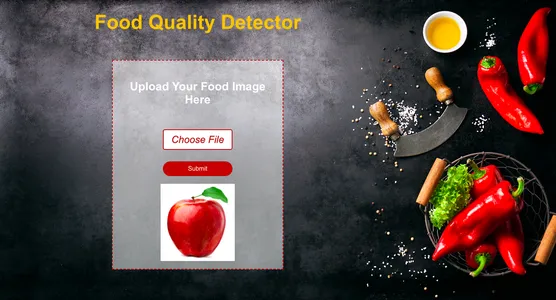
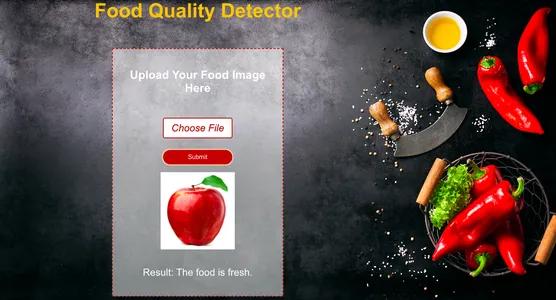
Zusammenfassung
Abschließend schlagen wir zur Automatisierung von Beschwerden über die Lebensmittelqualität in Hyperlocal Delivery-Apps den Aufbau eines Deep-Learning-Modells vor, das in eine Web-App integriert ist. Aufgrund der begrenzten Trainingsdaten erkennt das Modell jedoch möglicherweise nicht jedes Lebensmittelbild genau. Diese Implementierung dient als grundlegender Schritt hin zu einer größeren Lösung. Der Zugriff auf von Benutzern in Echtzeit hochgeladene Bilder innerhalb dieser Apps würde die Genauigkeit unseres Modells erheblich verbessern.
Key Take Away
- Die Lebensmittelqualität spielt eine entscheidende Rolle bei der Kundenzufriedenheit auf dem Markt für hyperlokale Lebensmittellieferungen.
- Sie können die Deep-Learning-Technologie nutzen, um einen genauen Prädiktor für die Lebensmittelqualität zu trainieren.
- Mit dieser Schritt-für-Schritt-Anleitung zur Erstellung der Web-App haben Sie praktische Erfahrungen gesammelt.
- Sie haben verstanden, wie wichtig die Qualität des Datensatzes für die Erstellung eines genauen Modells ist.
Die in diesem Artikel gezeigten Medien sind nicht Eigentum von Analytics Vidhya und werden nach Ermessen des Autors verwendet.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://www.analyticsvidhya.com/blog/2024/03/food-quality-detector/

