
Image by Freepik
Natural Language Processing, or NLP, is a field within artificial intelligence for machines to have the ability to understand textual data. NLP research has existed for a long time, but only recently has it become more prominent with the introduction of big data and higher computational processing power.
With the NLP field becoming bigger, many researchers would try to improve the machine’s capability to understand the textual data better. Through much progress, many techniques are proposed and applied in the NLP field.
This article will compare various techniques for processing text data in the NLP field. This article will focus on discussing RNN, Transformers, and BERT because it’s the one that is often used in research. Let’s get into it.
Recurrent Neural Network or RNN was developed in 1980 but only recently gained attraction in the NLP field. RNN is a particular type within the neural network family used for sequential data or data that can’t be independent of each other. Sequential data examples are time series, audio, or text sentence data, basically any kind of data with meaningful order.
RNNs are different from regular feed-forward neural networks as they process information differently. In the normal feed-forward, the information is processed following the layers. However, RNN is using a loop cycle on the information input as consideration. To understand the differences, let’s see the image below.
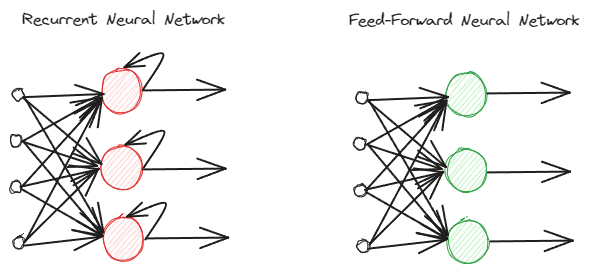
Image by Author
As you can see, the RNNs model implements a loop cycle during the information processing. RNNs would consider the current and previous data input when processing this information. That’s why the model is suitable for any type of sequential data.
If we take an example in the text data, imagine we have the sentence “I wake up at 7 AM”, and we have the word as input. In the feed-forward neural network, when we reach the word “up,” the model would already forget the words “I,” “wake,” and “up.” However, RNNs would use every output for each word and loop them back so the model would not forget.
In the NLP field, RNNs are often used in many textual applications, such as text classification and generation. It’s often used in word-level applications such as Part of Speech tagging, next-word generation, etc.
Looking at the RNNs more in-depth on the textual data, there are many types of RNNs. For example, the below image is the many-to-many types.
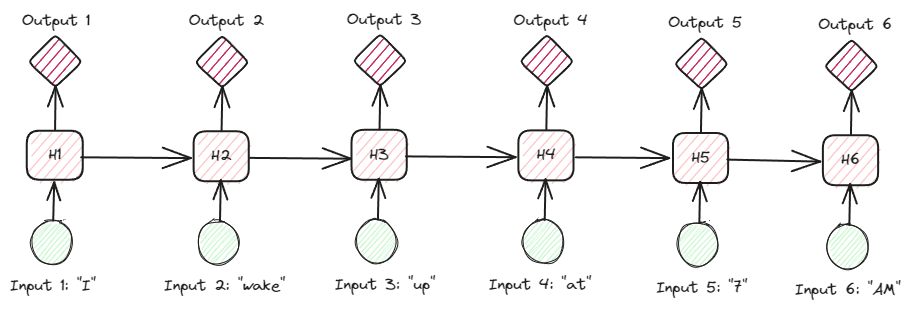
Image by Author
Looking at the image above, we can see that the output for each step (time-step in RNN) is processed one step at a time, and every iteration always considers the previous information.
Another RNN type used in many NLP applications is the encoder-decoder type (Sequence-to-Sequence). The structure is shown in the image below.
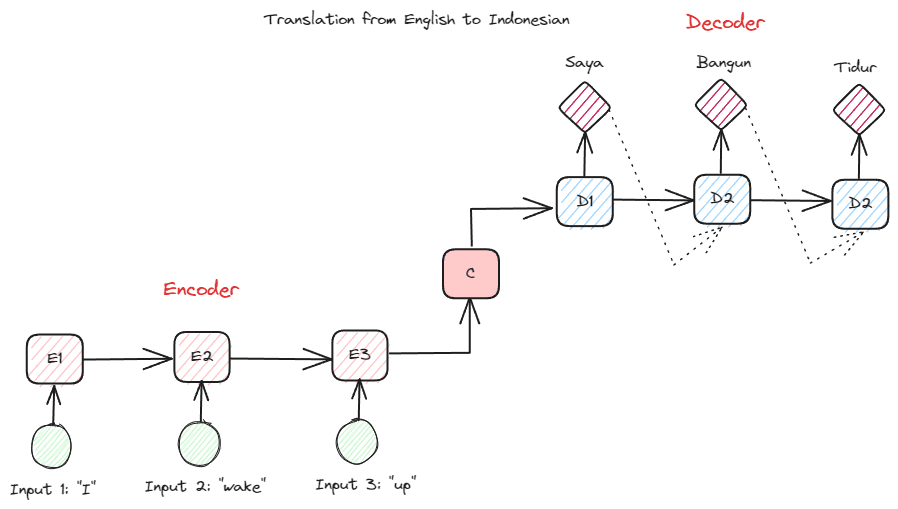
Image by Author
This structure introduces two parts that are used in the model. The first part is called Encoder, which is a part that receives data sequence and creates a new representation based on it. The representation would be used in the second part of the model, which is the decoder. With this structure, the input and output lengths don’t necessarily need to be equal. The example use case is a language translation, which often does not have the same length between the input and output.
There are various benefits of using RNNs to process natural language data, including:
- RNN can be used to process text input without length limitations.
- The model shares the same weights across all the time steps, which allows the neural network to use the same parameter in each step.
- Having the memory of past input makes RNN suitable for any sequential data.
But, there are several disadvantages as well:
- RNN is susceptible to both vanishing and exploding gradients. This is where the gradient result is the near-zero value (vanishing), causing network weight to only be updated for a tiny amount, or the gradient result is so significant (exploding) that it assigns an unrealistic enormous importance to the network.
- Long time of training because of the sequential nature of the model.
- Short-term memory means that the model starts to forget the longer the model is trained. There is an extension of RNN called LSTM to alleviate this problem.
Transformers is an NLP model architecture that tries to solve the sequence-to-sequence tasks previously encountered in the RNNs. As mentioned above, RNNs have problems with short-term memory. The longer the input, the more prominent the model was in forgetting the information. This is where the attention mechanism could help solve the problem.
The attention mechanism is introduced in the paper by Bahdanau et al. (2014) to solve the long input problem, especially with encoder-decoder type of RNNs. I would not explain the attention mechanism in detail. Basically, it is a layer that allows the model to focus on the critical part of the model input while having the output prediction. For example, the word input “Clock” would correlate highly with “Jam” in Indonesian if the task is for translation.
The transformers model is introduced by Vaswani et al. (2017). The architecture is inspired by the encoder-decoder RNN and built with the attention mechanism in mind and does not process data in sequential order. The overall transformers model is structured like the image below.
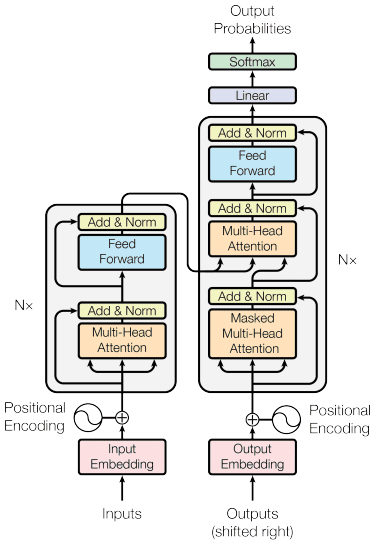
Transformers Architecture (Vaswani et al. 2017)
In the structure above, the transformers encode the data vector sequence into the word embedding with positional encoding in place while using the decoding to transform data into the original form. With the attention mechanism in place, the encoding can given importance according to the input.
Transformers provide few advantages compared to the other model, including:
- The parallelization process increases the training and inference speed.
- Capable of processing longer input, which offers a better understanding of the context
There are still some disadvantages to the transformers model:
- High computational processing and demand.
- The attention mechanism might require the text to be split because of the length limit it can handle.
- Context might be lost if the split were done wrong.
BERT
BERT, or Bidirectional Encoder Representations from Transformers, is a model developed by Devlin et al. (2019) that involves two steps (pre-training and fine-tuning) to create the model. If we compare, BERT is a stack of transformers encoder (BERT Base has 12 Layers while BERT Large has 24 layers).
BERT’s overall model development can be shown in the image below.
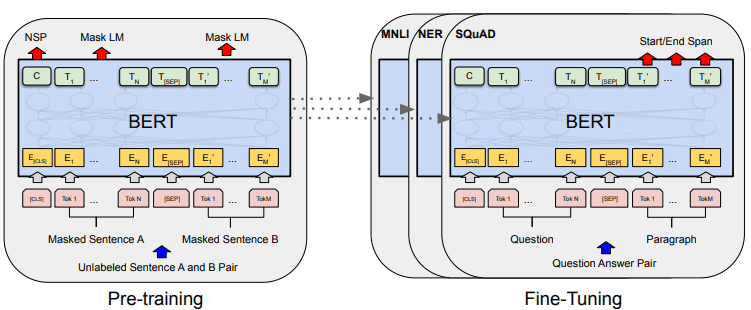
BERT overall procedures (Devlin et al. (2019)
Pre-training tasks initiate the model’s training at the same time, and once it is done, the model can be fine-tuned for various downstream tasks (question-answering, classification, etc.).
What makes BERT special is that it is the first unsupervised bidirectional language model that is pre-trained on text data. BERT was previously pre-trained on the entire Wikipedia and book corpus, consisting of over 3000 million words.
BERT is considered bidirectional because it didn’t read data input sequentially (from left to right or vice versa), but the transformer encoder read the whole sequence simultaneously.
Unlike directional models, which read the text input sequentially (left-to-right or right-to-left), the Transformer encoder reads the entire sequence of words simultaneously. That’s why the model is considered bidirectional and allows the model to understand the whole context of the input data.
To achieve bidirectional, BERT uses two techniques:
- Mask Language Model (MLM) — Word masking technique. The technique would mask 15% of the input words and try to predict this masked word based on the non-masked word.
- Next Sentence Prediction (NSP) — BERT tries to learn the relationship between sentences. The model has pairs of sentences as the data input and tries to predict if the subsequent sentence exists in the original document.
There are a few advantages to using BERT in the NLP field, including:
- BERT is easy to use for pre-trained various NLP downstream tasks.
- Bidirectional makes BERT understand the text context better.
- It’s a popular model that has much support from the community
Although, there are still a few disadvantages, including:
- Requires high computational power and long training time for some downstream task fine-tuning.
- The BERT model might result in a big model requiring much bigger storage.
- It’s better to use for complex tasks as the performance for simple tasks is not much different than using simpler models.
NLP has become more prominent recently, and much research has focused on improving the applications. In this article, we discuss three NLP techniques that are often used:
- RNN
- Transformers
- BERT
Each of the techniques has its advantages and disadvantages, but overall, we can see the model evolving in a better way.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
Cornellius Yudha Wijaya is a data science assistant manager and data writer. While working full-time at Allianz Indonesia, he loves to share Python and Data tips via social media and writing media.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://www.kdnuggets.com/comparing-natural-language-processing-techniques-rnns-transformers-bert?utm_source=rss&utm_medium=rss&utm_campaign=comparing-natural-language-processing-techniques-rnns-transformers-bert

