Images of elephants roaming the African plains are imprinted on all of our minds and something easily recognized as a symbol of Africa. But the future of elephants today is uncertain. An elephant is currently being killed by poachers every 15 minutes, and humans, who love watching them so much, have declared war on their species. Most people are not poachers, ivory collectors or intentionally harming wildlife, but silence or indifference to the battle at hand is as deadly.
You can choose to read this article, feel bad for a moment and then move on to your next email and start your day.
Or, perhaps you will pause and think: Our opportunities to help save wildlife, especially elephants, are right in front of us and grow every day. And some of these opportunities are rooted in machine learning (ML) and the magical outcome we fondly call AI.

Image Credits: Jes Lefcourt (opens in a new window)
Open-source developers are giving elephants a neural edge
Six months ago, amid a COVID-infused world, Hackster.io, a large open-source community owned by Avnet, and Smart Parks, a Dutch-based organization focused on wildlife conservation, reached out to tech industry leaders, including Microsoft, u-blox and Taoglas, Nordic Semiconductors, Western Digital and Edge Impulse with an idea to fund the R&D, manufacturing and shipping of 10 of the most advanced elephant tracking collars ever built.
These modern tracking collars are designed to deploy advanced machine-learning (ML) algorithms with the most extended battery life ever delivered for similar devices and a networking range more expansive than ever seen before. To make this vision even more audacious, they called to fully open-source and freely share the outcome of this effort via OpenCollar.io, a conservation organization championing open-source tracking collar hardware and software for environmental and wildlife monitoring projects.
Our opportunities to help save wildlife — especially elephants — are right in front of us and grow every day.
The tracker, ElephantEdge, would be built by specialist engineering firm Irnas, with the Hackster community coming together to make fully deployable ML models by Edge Impulse and telemetry dashboards by Avnet that will run the newly built hardware. Such an ambitious project was never attempted before, and many doubted that such a collaborative and innovative project could be pulled off.
Creating the world’s best elephant-tracking device
Only they pulled it off. Brilliantly. The new ElephantEdge tracker is considered the most advanced of its kind, with eight years of battery life and hundreds of miles worth of LoRaWAN networking repeaters range, running TinyML models that will provide park rangers with a better understanding of elephant acoustics, motion, location, environmental anomalies and more. The tracker can communicate with an array of sensors, connected by LoRaWAN technology to park rangers’ phones and laptops.
This gives rangers a more accurate image and location to track than earlier systems that captured and reported on pictures of all wildlife, which ran down the trackers’ battery life. The advanced ML software that runs on these trackers is built explicitly for elephants and developed by the Hackster.io community in a public design challenge.
“Elephants are the gardeners of the ecosystems as their roaming in itself creates space for other species to thrive. Our ElephantEdge project brings in people from all over the world to create the best technology vital for the survival of these gentle giants. Every day they are threatened by habitat destruction and poaching. This innovation and partnerships allow us to gain more insight into their behavior so we can improve protection,” said Smart Parks co-founder Tim van Dam.

Image Credits: Jes Lefcourt (opens in a new window)
Open-source, community-powered, conservation-AI at work
With hardware built by Irnas and Smart Parks, the community was busy building the algorithms to make it sing. Software developer and data scientist Swapnil Verma and Mausam Jain in the U.K. and Japan created Elephant AI. Using Edge Impulse, the team developed two ML models that will tap the tracker’s onboard sensors and provide critical information for park rangers.
The first community-led project, called Human Presence Detection, will alert park rangers of poaching risk using audio sampling to detect human presence in areas where humans are not supposed to be. This algorithm uses audio sensors to record sound and sight while sending it over the LoRaWAN network directly to a ranger’s phone to create an immediate alert.
The second model they named “Elephant Activity Monitoring.” It detects general elephant activity, taking time-series input from the tracker’s accelerometer to spot and make sense of running, sleeping and grazing to provide conservation specialists with the critical information they need to protect the elephants.
Another brilliant community development came from the other side of the world. Sara Olsson, a Swedish software engineer who has a passion for the national world, created a TinyML and IoT monitoring dashboard to help park rangers with conservation efforts.
With little resources and support, Sara built a full telemetry dashboard combined with ML algorithms to monitor camera traps and watering holes, while reducing network traffic by processing data on the collar and considerably saving battery life. To validate her hypothesis, she used 1,155 data models and 311 tests!
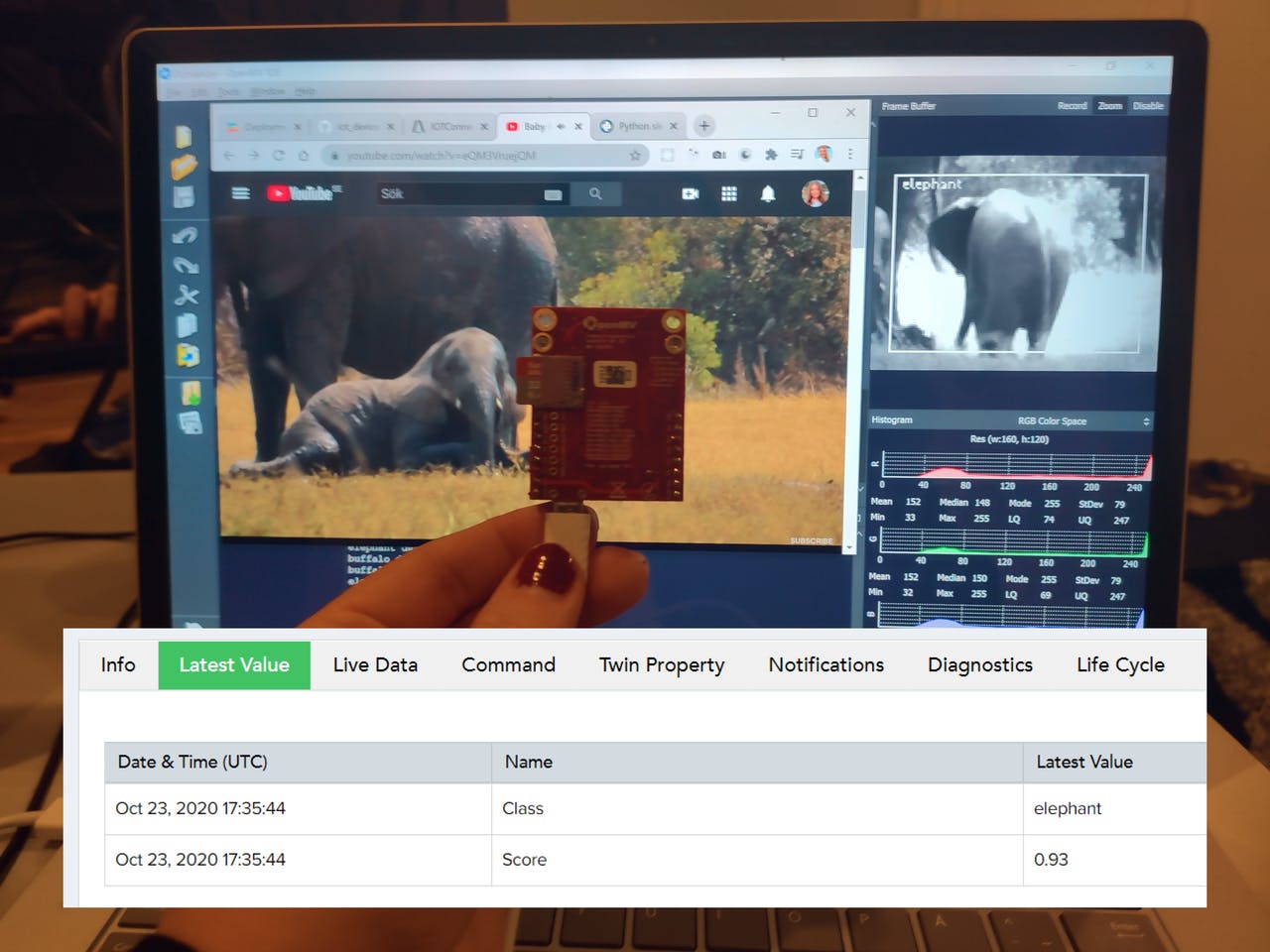
Sara Olsson’s TinyML and IoT monitoring dashboard. Image Credits: Sara Olsson
She completed her work in the Edge Impulse studio, creating the models and testing them with camera traps streams from Africam using an OpenMV camera from her home’s comfort.

Image Credits: Sara Olsson (opens in a new window)
Technology for good works, but human behavior must change
Project ElephantEdge is an example of how commercial and public interest can converge and result in a collaborative sustainability effort to advance wildlife conservation efforts. The new collar can generate critical data and equip park rangers with better data to make urgent life-saving decisions about protecting their territories. By the end of 2021, at least ten elephants will be sporting the new collars in selected parks across Africa, in partnership with the World Wildlife Fund and Vulcan’s EarthRanger, unleashing a new wave of conservation, learning and defending.
Naturally, this is great, the technology works, and it’s helping elephants like never before. But in reality, the root cause of the problem runs much more profound. Humans must change their relationship to the natural world for proper elephant habitat and population revival to occur.
“The threat to elephants is greater than it’s ever been,” said Richard Leakey, a leading palaeoanthropologist and conservationist scholar. The main argument for allowing trophy or ivory hunting is that it raises money for conservation and local communities. However, a recent report revealed that only 3% of Africa’s hunting revenue trickles down to communities in hunting areas. Animals don’t need to die to make money for the communities you live around.
With great technology, collaboration and a commitment to address the underlying cultural conditions and the ivory trade that leads to most elephant deaths, there’s a real chance to save these singular creatures.
Source: https://techcrunch.com/2020/11/20/can-artificial-intelligence-give-elephants-a-winning-edge/

