تمت كتابة هذا المنشور بالاشتراك مع سانتوش وادي وناندا كيشور ثاتيكوندا من BigBasket.
BigBasket هو أكبر متجر للمواد الغذائية والبقالة عبر الإنترنت في الهند. إنهم يعملون في قنوات متعددة للتجارة الإلكترونية مثل التجارة السريعة والتسليم المحدد والاشتراكات اليومية. يمكنك أيضًا الشراء من متاجرهم الفعلية وآلات البيع. وهي تقدم تشكيلة كبيرة تضم أكثر من 50,000 منتج عبر 1,000 علامة تجارية، وتعمل في أكثر من 500 مدينة وبلدة. يخدم BigBasket أكثر من 10 مليون عميل.
في هذا المنشور، نناقش كيفية استخدام BigBasket الأمازون SageMaker لتدريب نموذج الرؤية الحاسوبية الخاص بهم لتحديد منتجات السلع الاستهلاكية سريعة الحركة (FMCG)، مما ساعدهم على تقليل وقت التدريب بنسبة 50% تقريبًا وتوفير التكاليف بنسبة 20%.
تحديات العملاء
اليوم، توفر معظم محلات السوبر ماركت والمتاجر الفعلية في الهند خدمة الدفع اليدوي عند طاولة الخروج. وهذا فيه مسألتان:
- ويتطلب الأمر قوة عاملة إضافية، وملصقات للوزن، وتدريبًا متكررًا لفريق التشغيل داخل المتجر أثناء التوسع.
- في معظم المتاجر، يختلف عداد الخروج عن عدادات الوزن، مما يزيد من الاحتكاك في رحلة الشراء الخاصة بالعميل. غالبًا ما يفقد العملاء ملصق الوزن ويتعين عليهم العودة إلى عدادات الوزن للحصول على ملصق الوزن مرة أخرى قبل متابعة عملية الدفع.
عملية الخروج الذاتي
قدمت BigBasket نظامًا للدفع مدعومًا بالذكاء الاصطناعي في متاجرها الفعلية والذي يستخدم الكاميرات لتمييز العناصر بشكل فريد. يقدم الشكل التالي نظرة عامة على عملية الخروج.
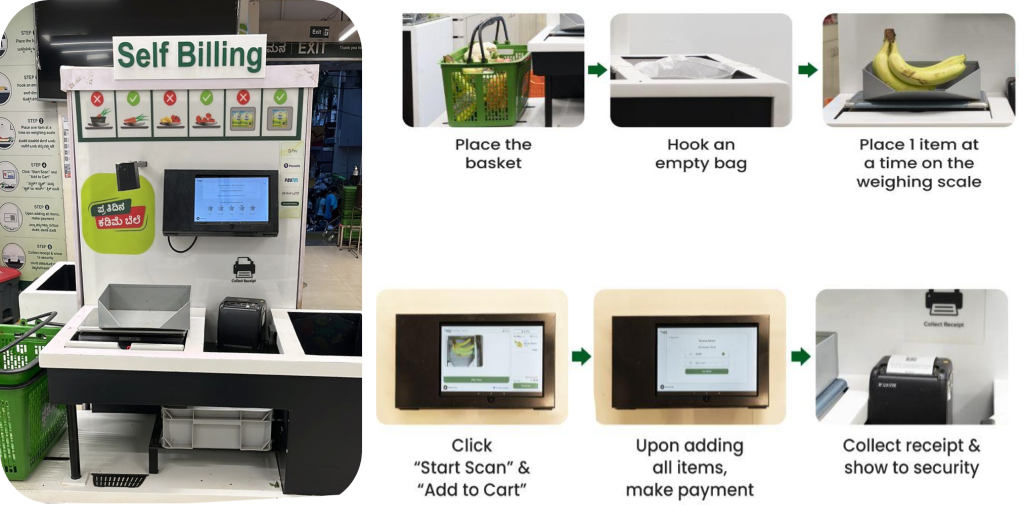
كان فريق BigBasket يقوم بتشغيل خوارزميات ML داخلية مفتوحة المصدر للتعرف على كائنات رؤية الكمبيوتر لتشغيل عملية الدفع المدعومة بالذكاء الاصطناعي في مقرهم. فريشو المتاجر (المادية). كنا نواجه التحديات التالية لتشغيل الإعداد الحالي:
- مع التقديم المستمر للمنتجات الجديدة، يحتاج نموذج الرؤية الحاسوبية إلى دمج معلومات المنتج الجديد بشكل مستمر. يحتاج النظام إلى التعامل مع كتالوج كبير يضم أكثر من 12,000 وحدة حفظ مخزون (SKU)، مع إضافة وحدات SKU جديدة باستمرار بمعدل يزيد عن 600 وحدة شهريًا.
- ولمواكبة المنتجات الجديدة، تم إنتاج نموذج جديد كل شهر باستخدام أحدث بيانات التدريب. لقد كان تدريب النماذج بشكل متكرر للتكيف مع المنتجات الجديدة أمرًا مكلفًا ويستغرق وقتًا طويلاً.
- أرادت BigBasket أيضًا تقليل وقت دورة التدريب لتحسين وقت التسويق. نظرًا للزيادات في وحدات SKU، كان الوقت الذي يستغرقه النموذج يتزايد خطيًا، مما أثر على وقت طرحه في السوق نظرًا لأن معدل تكرار التدريب كان مرتفعًا للغاية واستغرق وقتًا طويلاً.
- أدت زيادة البيانات للتدريب النموذجي والإدارة اليدوية لدورة التدريب الكاملة من البداية إلى النهاية إلى زيادة النفقات العامة بشكل كبير. كانت BigBasket تقوم بتشغيل هذا على منصة خارجية، مما تكبد تكاليف كبيرة.
حل نظرة عامة
نوصي بأن تقوم BigBasket بإعادة تصميم الحل الحالي الخاص بها للكشف عن منتجات سلع استهلاكية سريعة الحركة وتصنيفها باستخدام SageMaker لمواجهة هذه التحديات. قبل الانتقال إلى الإنتاج واسع النطاق، جربت BigBasket إصدارًا تجريبيًا على SageMaker لتقييم مقاييس الأداء والتكلفة والراحة.
كان هدفهم هو تحسين نموذج التعلم الآلي لرؤية الكمبيوتر (ML) الحالي لاكتشاف SKU. استخدمنا بنية الشبكة العصبية التلافيفية (CNN) مع ريسنت 152 لتصنيف الصور. تم تقدير مجموعة بيانات كبيرة تضم حوالي 300 صورة لكل SKU للتدريب النموذجي، مما أدى إلى أكثر من 4 ملايين صورة تدريبية إجمالية. بالنسبة لبعض وحدات SKU، قمنا بزيادة البيانات لتشمل نطاقًا أوسع من الظروف البيئية.
يوضح الرسم البياني التالي بنية الحل.

يمكن تلخيص العملية الكاملة في الخطوات عالية المستوى التالية:
- إجراء تنقية البيانات والتعليق التوضيحي والزيادة.
- تخزين البيانات في خدمة تخزين أمازون البسيطة دلو (أمازون S3).
- استخدم SageMaker و أمازون FSx لستر لزيادة كفاءة البيانات.
- تقسيم البيانات إلى مجموعات التدريب والتحقق من الصحة والاختبار. استخدمنا FSx لـ Luster و خدمة قاعدة بيانات الأمازون (Amazon RDS) للوصول السريع إلى البيانات المتوازية.
- استخدم العرف PyTorch حاوية Docker بما في ذلك المكتبات الأخرى مفتوحة المصدر.
- استعمل SageMaker توازي البيانات الموزعة (SMDDP) للتدريب الموزع المتسارع.
- مقاييس التدريب على نموذج السجل.
- انسخ النموذج النهائي إلى حاوية S3.
تم استخدام BigBasket دفاتر SageMaker لتدريب نماذج التعلم الآلي الخاصة بهم وتمكنوا بسهولة من نقل PyTorch الحالي مفتوح المصدر والتبعيات الأخرى مفتوحة المصدر إلى حاوية SageMaker PyTorch وتشغيل خط الأنابيب بسلاسة. كانت هذه أول فائدة يراها فريق BigBasket، لأنه لم يكن هناك أي تغييرات مطلوبة على التعليمات البرمجية لجعلها متوافقة للتشغيل على بيئة SageMaker.
تتكون شبكة النموذج من بنية ResNet 152 متبوعة بطبقات متصلة بالكامل. لقد قمنا بتجميد طبقات المعالم ذات المستوى المنخفض واحتفظنا بالأوزان المكتسبة من خلال نقل التعلم من نموذج ImageNet. بلغ إجمالي معلمات النموذج 66 مليونًا، وتتكون من 23 مليون معلمة قابلة للتدريب. وقد ساعدهم هذا النهج القائم على نقل التعلم على استخدام عدد أقل من الصور في وقت التدريب، كما أتاح لهم تقاربًا أسرع وخفض إجمالي وقت التدريب.
بناء وتدريب النموذج داخل أمازون ساجميكر ستوديو توفير بيئة تطوير متكاملة (IDE) تحتوي على كل ما يلزم لإعداد النماذج وبنائها وتدريبها وضبطها. ساعدت زيادة بيانات التدريب باستخدام تقنيات مثل اقتصاص الصور وتدويرها وقلبها على تحسين بيانات تدريب النموذج ودقة النموذج.
تم تسريع التدريب النموذجي بنسبة 50% من خلال استخدام مكتبة SMDDP، والتي تتضمن خوارزميات اتصال محسنة مصممة خصيصًا للبنية التحتية لـ AWS. لتحسين أداء قراءة/كتابة البيانات أثناء التدريب على النماذج وزيادة البيانات، استخدمنا FSx for Luster للحصول على إنتاجية عالية الأداء.
كان حجم بيانات التدريب الأولي أكثر من 1.5 تيرابايت. استخدمنا اثنين الأمازون الحوسبة المرنة السحابية (أمازون EC2) p4d.24 حالات كبيرة مع 8 GPU وذاكرة GPU 40 جيجابايت. بالنسبة للتدريب الموزع لـ SageMaker، يجب أن تكون المثيلات في نفس منطقة AWS ومنطقة توافر الخدمات. وأيضًا، يجب أن تكون بيانات التدريب المخزنة في حاوية S3 في نفس منطقة توافر الخدمات. تسمح هذه البنية أيضًا لـ BigBasket بالتغيير إلى أنواع المثيلات الأخرى أو إضافة المزيد من المثيلات إلى البنية الحالية لتلبية أي نمو كبير في البيانات أو تحقيق مزيد من التخفيض في وقت التدريب.
كيف ساعدت مكتبة SMDDP في تقليل وقت التدريب وتكلفته وتعقيده
في التدريب التقليدي على البيانات الموزعة، يقوم إطار التدريب بتعيين الرتب لوحدات معالجة الرسومات (العاملين) وإنشاء نسخة طبق الأصل من النموذج الخاص بك على كل وحدة معالجة رسومات. أثناء كل تكرار للتدريب، يتم تقسيم مجموعة البيانات العالمية إلى أجزاء (أجزاء الدفعة) ويتم توزيع قطعة على كل عامل. يتابع كل عامل بعد ذلك التمرير للأمام والخلف المحدد في برنامج التدريب الخاص بك على كل وحدة معالجة رسومات. أخيرًا، تتم مزامنة أوزان النماذج وتدرجاتها من النسخ المتماثلة المختلفة للنماذج في نهاية التكرار من خلال عملية اتصال جماعية تسمى AllReduce. بعد أن يكون لدى كل عامل ووحدة معالجة الرسومات نسخة طبق الأصل متزامنة من النموذج، تبدأ عملية التكرار التالية.
مكتبة SMDDP هي مكتبة اتصالات جماعية تعمل على تحسين أداء عملية التدريب المتوازية للبيانات الموزعة. تعمل مكتبة SMDDP على تقليل حمل الاتصالات لعمليات الاتصال الجماعي الرئيسية مثل AllReduce. تم تصميم تطبيق AllReduce للبنية التحتية لـ AWS ويمكنه تسريع التدريب من خلال تداخل عملية AllReduce مع التمريرة الخلفية. يحقق هذا الأسلوب كفاءة تحجيم شبه خطية وسرعة تدريب أسرع من خلال تحسين عمليات kernel بين وحدات المعالجة المركزية (CPU) ووحدات معالجة الرسومات.
لاحظ الحسابات التالية:
- حجم الدفعة العامة هو (عدد العقد في المجموعة) * (عدد وحدات معالجة الرسومات لكل عقدة) * (لكل جزء دفعة)
- جزء الدُفعة (دُفعة صغيرة) عبارة عن مجموعة فرعية من مجموعة البيانات المخصصة لكل وحدة معالجة رسومات (عامل) لكل تكرار
استخدمت BigBasket مكتبة SMDDP لتقليل الوقت الإجمالي للتدريب. باستخدام FSx for Lustre، قمنا بتقليل إنتاجية قراءة/كتابة البيانات أثناء التدريب النموذجي وزيادة البيانات. بفضل توازي البيانات، تمكنت BigBasket من تحقيق تدريب أسرع بنسبة 50% تقريبًا وأقل تكلفة بنسبة 20% مقارنة بالبدائل الأخرى، مما يوفر أفضل أداء على AWS. يقوم SageMaker تلقائيًا بإيقاف مسار التدريب بعد الانتهاء. اكتمل المشروع بنجاح مع توفير وقت تدريب أسرع بنسبة 50% في AWS (4.5 أيام في AWS مقابل 9 أيام على النظام الأساسي القديم الخاص بهم).
في وقت كتابة هذا المنشور، كانت BigBasket تقوم بتشغيل الحل الكامل في مرحلة الإنتاج لأكثر من 6 أشهر وتوسيع نطاق النظام من خلال تقديم الطعام للمدن الجديدة، ونحن نضيف متاجر جديدة كل شهر.
"لقد كانت شراكتنا مع AWS بشأن الانتقال إلى التدريب الموزع باستخدام عرض SMDDP الخاص بهم بمثابة فوز كبير. لم يقتصر الأمر على تقليل أوقات التدريب لدينا بنسبة 50% فحسب، بل كان أيضًا أرخص بنسبة 20%. في شراكتنا بأكملها، وضعت AWS معيارًا لهوس العملاء وتحقيق النتائج — من خلال العمل معنا طوال الطريق لتحقيق الفوائد الموعودة.
– كيشاف كومار، رئيس قسم الهندسة في BigBasket.
وفي الختام
في هذا المنشور، ناقشنا كيفية استخدام BigBasket لـ SageMaker لتدريب نموذج رؤية الكمبيوتر الخاص بهم لتحديد منتج السلع الاستهلاكية سريعة الحركة. يوفر تطبيق نظام الدفع الذاتي الآلي المدعوم بالذكاء الاصطناعي تجربة محسنة لعملاء التجزئة من خلال الابتكار، مع القضاء على الأخطاء البشرية في عملية الخروج. يؤدي تسريع إعداد المنتج الجديد باستخدام التدريب الموزع لـ SageMaker إلى تقليل وقت وتكلفة إعداد SKU. يتيح دمج FSx لـ Luster الوصول السريع إلى البيانات المتوازية لإعادة تدريب النموذج بكفاءة مع مئات من وحدات SKU الجديدة شهريًا. بشكل عام، يوفر حل الدفع الذاتي القائم على الذكاء الاصطناعي تجربة تسوق محسنة خالية من أخطاء الدفع في الواجهة الأمامية. لقد أحدثت الأتمتة والابتكار تحولًا كبيرًا في عمليات الدفع والتجهيز للبيع بالتجزئة.
يوفر SageMaker إمكانات شاملة لتطوير تعلم الآلة ونشره ومراقبته، مثل بيئة الكمبيوتر المحمول SageMaker Studio لكتابة التعليمات البرمجية والحصول على البيانات ووضع علامات على البيانات والتدريب على النماذج وضبط النماذج والنشر والمراقبة وغير ذلك الكثير. إذا كان عملك يواجه أيًا من التحديات الموضحة في هذا المنشور ويريد توفير الوقت للتسويق وتحسين التكلفة، فتواصل مع فريق حسابات AWS في منطقتك وابدأ مع SageMaker.
حول المؤلف
 سانتوش وادي هو مهندس رئيسي في BigBasket، ويتمتع بخبرة تزيد عن عقد من الزمن في حل تحديات الذكاء الاصطناعي. ويتمتع بخلفية قوية في رؤية الكمبيوتر وعلوم البيانات والتعلم العميق، وهو حاصل على درجة الدراسات العليا من IIT Bombay. قام سانتوش بتأليف منشورات IEEE بارزة، وباعتباره مؤلفًا متمرسًا لمدونة تقنية، فقد قدم أيضًا مساهمات كبيرة في تطوير حلول رؤية الكمبيوتر خلال فترة عمله في Samsung.
سانتوش وادي هو مهندس رئيسي في BigBasket، ويتمتع بخبرة تزيد عن عقد من الزمن في حل تحديات الذكاء الاصطناعي. ويتمتع بخلفية قوية في رؤية الكمبيوتر وعلوم البيانات والتعلم العميق، وهو حاصل على درجة الدراسات العليا من IIT Bombay. قام سانتوش بتأليف منشورات IEEE بارزة، وباعتباره مؤلفًا متمرسًا لمدونة تقنية، فقد قدم أيضًا مساهمات كبيرة في تطوير حلول رؤية الكمبيوتر خلال فترة عمله في Samsung.
 ناندا كيشور ثاتيكوندا هو مدير هندسي يقود هندسة البيانات والتحليلات في BigBasket. قامت ناندا ببناء تطبيقات متعددة للكشف عن الحالات الشاذة ولديها براءة اختراع مقدمة في مجال مماثل. لقد عمل على بناء تطبيقات على مستوى المؤسسات، وبناء منصات البيانات في العديد من المؤسسات ومنصات إعداد التقارير لتبسيط القرارات المدعومة بالبيانات. تتمتع ناندا بخبرة تزيد عن 18 عامًا في العمل في Java/J2EE وتقنيات Spring وأطر البيانات الضخمة باستخدام Hadoop وApache Spark.
ناندا كيشور ثاتيكوندا هو مدير هندسي يقود هندسة البيانات والتحليلات في BigBasket. قامت ناندا ببناء تطبيقات متعددة للكشف عن الحالات الشاذة ولديها براءة اختراع مقدمة في مجال مماثل. لقد عمل على بناء تطبيقات على مستوى المؤسسات، وبناء منصات البيانات في العديد من المؤسسات ومنصات إعداد التقارير لتبسيط القرارات المدعومة بالبيانات. تتمتع ناندا بخبرة تزيد عن 18 عامًا في العمل في Java/J2EE وتقنيات Spring وأطر البيانات الضخمة باستخدام Hadoop وApache Spark.
 سودهانشو الكراهية هو متخصص رئيسي في الذكاء الاصطناعي وتعلم الآلة في AWS ويعمل مع العملاء لتقديم المشورة لهم بشأن عمليات MLOs الخاصة بهم ورحلة الذكاء الاصطناعي التوليدية. في منصبه السابق، قام بوضع تصور وإنشاء وقيادة الفرق لبناء منصة متكاملة ومفتوحة المصدر للذكاء الاصطناعي والألعاب، ونجح في تسويقها مع أكثر من 100 عميل. يمتلك Sudhanshu عددًا من براءات الاختراع. كتب كتابين والعديد من الأوراق البحثية والمدونات؛ وقد عرض وجهة نظره في مختلف المحافل. لقد كان قائدًا فكريًا ومتحدثًا، ويعمل في هذه الصناعة منذ ما يقرب من 2 عامًا. لقد عمل مع عملاء Fortune 25 في جميع أنحاء العالم ويعمل مؤخرًا مع عملاء رقميين أصليين في الهند.
سودهانشو الكراهية هو متخصص رئيسي في الذكاء الاصطناعي وتعلم الآلة في AWS ويعمل مع العملاء لتقديم المشورة لهم بشأن عمليات MLOs الخاصة بهم ورحلة الذكاء الاصطناعي التوليدية. في منصبه السابق، قام بوضع تصور وإنشاء وقيادة الفرق لبناء منصة متكاملة ومفتوحة المصدر للذكاء الاصطناعي والألعاب، ونجح في تسويقها مع أكثر من 100 عميل. يمتلك Sudhanshu عددًا من براءات الاختراع. كتب كتابين والعديد من الأوراق البحثية والمدونات؛ وقد عرض وجهة نظره في مختلف المحافل. لقد كان قائدًا فكريًا ومتحدثًا، ويعمل في هذه الصناعة منذ ما يقرب من 2 عامًا. لقد عمل مع عملاء Fortune 25 في جميع أنحاء العالم ويعمل مؤخرًا مع عملاء رقميين أصليين في الهند.
 عيوش كومار هو مهندس الحلول في AWS. وهو يعمل مع مجموعة واسعة من عملاء AWS، لمساعدتهم على اعتماد أحدث التطبيقات الحديثة والابتكار بشكل أسرع باستخدام التقنيات السحابية الأصلية. ستجده يقوم بالتجربة في المطبخ في أوقات فراغه.
عيوش كومار هو مهندس الحلول في AWS. وهو يعمل مع مجموعة واسعة من عملاء AWS، لمساعدتهم على اعتماد أحدث التطبيقات الحديثة والابتكار بشكل أسرع باستخدام التقنيات السحابية الأصلية. ستجده يقوم بالتجربة في المطبخ في أوقات فراغه.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/how-bigbasket-improved-ai-enabled-checkout-at-their-physical-stores-using-amazon-sagemaker/

