عند نشر نموذج لغة كبير (LLM)، يهتم ممارسو التعلم الآلي (ML) عادةً بمقياسين لأداء خدمة النموذج: زمن الوصول، المحدد بالوقت الذي يستغرقه إنشاء رمز مميز واحد، والإنتاجية، المحدد بعدد الرموز المميزة التي تم إنشاؤها في الثانية. على الرغم من أن طلبًا واحدًا إلى نقطة النهاية المنشورة سيظهر إنتاجية مساوية تقريبًا لعكس زمن وصول النموذج، إلا أن هذا ليس هو الحال بالضرورة عندما يتم إرسال طلبات متزامنة متعددة في وقت واحد إلى نقطة النهاية. نظرًا لتقنيات تقديم النماذج، مثل التجميع المستمر للطلبات المتزامنة من جانب العميل، فإن زمن الوصول والإنتاجية لهما علاقة معقدة تختلف بشكل كبير بناءً على بنية النموذج وتكوينات الخدمة وأجهزة نوع المثيل وعدد الطلبات المتزامنة والاختلافات في حمولات الإدخال مثل كعدد من رموز الإدخال ورموز الإخراج.
يستكشف هذا المنشور هذه العلاقات من خلال قياس شامل لمجالات LLM المتوفرة في Amazon SageMaker JumpStart، بما في ذلك متغيرات Llama 2 وFalcon وMistral. باستخدام SageMaker JumpStart، يمكن لممارسي تعلم الآلة الاختيار من بين مجموعة واسعة من النماذج الأساسية المتاحة للعامة لنشرها على أجهزة مخصصة. الأمازون SageMaker مثيلات داخل بيئة معزولة بالشبكة. نحن نقدم مبادئ نظرية حول كيفية تأثير مواصفات المسرع على معايير LLM. نوضح أيضًا تأثير نشر مثيلات متعددة خلف نقطة نهاية واحدة. وأخيرًا، نقدم توصيات عملية لتخصيص عملية نشر SageMaker JumpStart لتتوافق مع متطلباتك المتعلقة بزمن الاستجابة والإنتاجية والتكلفة والقيود المفروضة على أنواع المثيلات المتاحة. وتستند جميع نتائج القياس وكذلك التوصيات على تنوعا مفكرة يمكنك التكيف مع حالة الاستخدام الخاصة بك.
تم نشر قياس نقطة النهاية
يوضح الشكل التالي قيم زمن الاستجابة الأدنى (يسار) وأعلى إنتاجية (يمين) لتكوينات النشر عبر مجموعة متنوعة من أنواع النماذج وأنواع المثيلات. والأهم من ذلك، أن كل عملية من عمليات نشر النماذج هذه تستخدم التكوينات الافتراضية كما هو منصوص عليه بواسطة SageMaker JumpStart مع إعطاء معرف النموذج المطلوب ونوع المثيل للنشر.
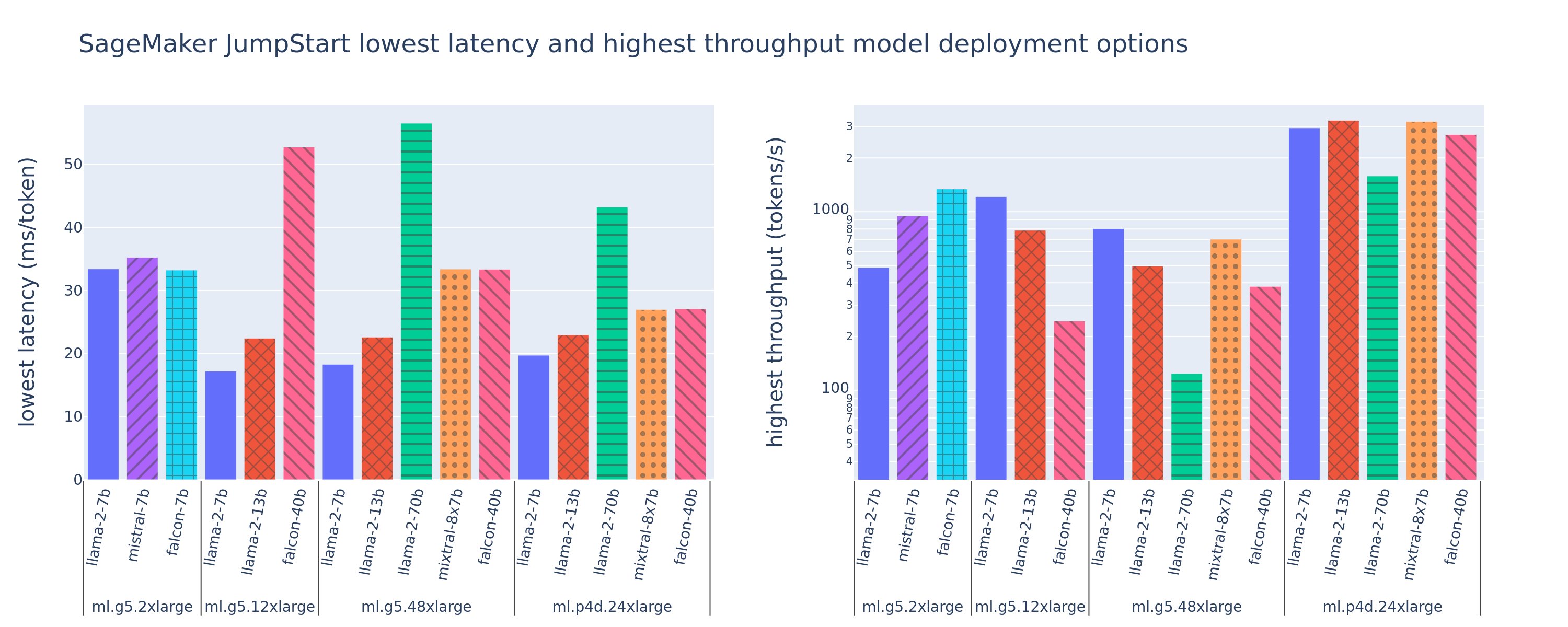
تتوافق قيم زمن الوصول والإنتاجية هذه مع الحمولات التي تحتوي على 256 رمزًا مميزًا للإدخال و256 رمزًا مميزًا للإخراج. يحد تكوين أقل زمن استجابة من النموذج الذي يخدم طلبًا متزامنًا واحدًا، بينما يعمل تكوين أعلى إنتاجية على زيادة العدد المحتمل للطلبات المتزامنة. كما يمكننا أن نرى في قياس الأداء لدينا، فإن زيادة الطلبات المتزامنة تؤدي بشكل رتيب إلى زيادة الإنتاجية مع تناقص التحسين للطلبات المتزامنة الكبيرة. بالإضافة إلى ذلك، يتم تقسيم النماذج بالكامل على المثيل المدعوم. على سبيل المثال، نظرًا لأن مثيل ml.g5.48xlarge يحتوي على 8 وحدات معالجة رسومات، فإن جميع نماذج SageMaker JumpStart التي تستخدم هذا المثيل يتم تقسيمها باستخدام توازي الموتر على جميع المسرعات الثمانية المتوفرة.
يمكننا أن نلاحظ بعض الوجبات السريعة من هذا الرقم. أولاً، لا يتم دعم كافة النماذج في كافة المثيلات؛ لا تدعم بعض النماذج الأصغر حجمًا، مثل Falcon 7B، تقسيم النموذج، بينما تتطلب النماذج الأكبر حجمًا متطلبات موارد حسابية أعلى. ثانيًا، مع زيادة التقسيم، يتحسن الأداء عادةً، ولكن قد لا يتحسن بالضرورة بالنسبة للنماذج الصغيرة. وذلك لأن النماذج الصغيرة مثل 7B و13B تتحمل حملًا كبيرًا للاتصالات عند تقسيمها عبر عدد كبير جدًا من المسرعات. نناقش هذا بمزيد من التعمق في وقت لاحق. أخيرًا، تميل مثيلات ml.p4d.24xlarge إلى الحصول على إنتاجية أفضل بشكل ملحوظ بسبب تحسينات عرض النطاق الترددي للذاكرة لـ A100 مقارنة بوحدات معالجة الرسومات A10G. كما سنناقش لاحقًا، يعتمد قرار استخدام نوع مثيل معين على متطلبات النشر الخاصة بك، بما في ذلك زمن الوصول والإنتاجية وقيود التكلفة.
كيف يمكنك الحصول على أقل زمن وصول وقيم تكوين الإنتاجية الأعلى؟ لنبدأ برسم زمن الاستجابة مقابل الإنتاجية لنقطة نهاية Llama 2 7B على مثيل ml.g5.12xlarge لحمولة تحتوي على 256 رمزًا مميزًا للإدخال و256 رمزًا مميزًا للإخراج، كما هو موضح في المنحنى التالي. يوجد منحنى مماثل لكل نقطة نهاية LLM منشورة.

مع زيادة التزامن، تزداد الإنتاجية وزمن الوصول أيضًا بشكل رتيب. ولذلك، فإن أقل نقطة استجابة تحدث عند قيمة طلب متزامنة تبلغ 1، ويمكنك زيادة إنتاجية النظام بطريقة فعالة من حيث التكلفة عن طريق زيادة الطلبات المتزامنة. توجد "ركبة" مميزة في هذا المنحنى، حيث من الواضح أن مكاسب الإنتاجية المرتبطة بالتزامن الإضافي لا تفوق الزيادة المرتبطة في زمن الوصول. الموقع الدقيق لهذه الركبة مخصص لحالة معينة؛ قد يحدد بعض الممارسين الركبة عند النقطة التي يتم فيها تجاوز متطلبات زمن الوصول المحددة مسبقًا (على سبيل المثال، 100 مللي ثانية/الرمز المميز)، في حين قد يستخدم آخرون معايير اختبار التحميل وأساليب نظرية الطابور مثل قاعدة نصف زمن الوصول، وقد يستخدم آخرون مواصفات المسرع النظري.
نلاحظ أيضًا أن الحد الأقصى لعدد الطلبات المتزامنة محدود. في الشكل السابق، ينتهي تتبع السطر بـ 192 طلبًا متزامنًا. مصدر هذا القيد هو حد مهلة استدعاء SageMaker، حيث يشير SageMaker إلى انتهاء مهلة استجابة الاستدعاء بعد 60 ثانية. هذا الإعداد خاص بالحساب وغير قابل للتكوين لنقطة نهاية فردية. بالنسبة لحاملي شهادة LLM، قد يستغرق إنشاء عدد كبير من رموز الإخراج ثوانٍ أو حتى دقائق. لذلك، يمكن أن تؤدي حمولات الإدخال أو الإخراج الكبيرة إلى فشل طلبات الاستدعاء. علاوة على ذلك، إذا كان عدد الطلبات المتزامنة كبيرًا جدًا، فستواجه العديد من الطلبات أوقات انتظار طويلة، مما يؤدي إلى حد المهلة الذي يبلغ 60 ثانية. ولأغراض هذه الدراسة، نستخدم حد المهلة لتحديد الحد الأقصى للإنتاجية الممكنة لنشر النموذج. الأهم من ذلك، على الرغم من أن نقطة نهاية SageMaker قد تتعامل مع عدد كبير من الطلبات المتزامنة دون ملاحظة مهلة استجابة الاستدعاء، فقد ترغب في تحديد الحد الأقصى للطلبات المتزامنة فيما يتعلق بالركبة في منحنى إنتاجية زمن الوصول. من المحتمل أن تكون هذه هي النقطة التي تبدأ عندها في النظر في القياس الأفقي، حيث توفر نقطة نهاية واحدة مثيلات متعددة مع نسخ متماثلة للنماذج وأرصدة تحميل الطلبات الواردة بين النسخ المتماثلة، لدعم المزيد من الطلبات المتزامنة.
ولأخذ هذه الخطوة إلى الأمام، يحتوي الجدول التالي على نتائج قياس الأداء لتكوينات مختلفة لنموذج Llama 2 7B، بما في ذلك عدد مختلف من رموز الإدخال والإخراج، وأنواع المثيلات، وعدد الطلبات المتزامنة. لاحظ أن الشكل السابق يرسم صفًا واحدًا فقط من هذا الجدول.
| . | الإنتاجية (الرموز / ثانية) | الكمون (ملي ثانية/الرمز المميز) | ||||||||||||||||||
| الطلبات المتزامنة | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| عدد الرموز الإجمالية: 512، عدد الرموز المميزة للإخراج: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| ml.g5.12xlarge | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| ml.g5.48xlarge | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| ml.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| عدد الرموز الإجمالية: 4096، عدد الرموز المميزة للإخراج: 256 | ||||||||||||||||||||
| ml.g5.2xlarge | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| ml.g5.12xlarge | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| ml.g5.48xlarge | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| ml.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
نلاحظ بعض الأنماط الإضافية في هذه البيانات. عند زيادة حجم السياق، يزيد زمن الوصول ويقل معدل النقل. على سبيل المثال، في ml.g5.2xlarge بتزامن 1، تبلغ الإنتاجية 30 رمزًا مميزًا في الثانية عندما يكون إجمالي عدد الرموز المميزة 512، مقابل 20 رمزًا مميزًا في الثانية إذا كان إجمالي عدد الرموز المميزة 4,096. وذلك لأن الأمر يستغرق وقتًا أطول لمعالجة المدخلات الأكبر. يمكننا أيضًا أن نرى أن زيادة قدرة وحدة معالجة الرسومات والتقسيم يؤثر على الحد الأقصى للإنتاجية والحد الأقصى للطلبات المتزامنة المدعومة. يوضح الجدول أن Llama 2 7B له قيم إنتاجية قصوى مختلفة بشكل ملحوظ لأنواع المثيلات المختلفة، وتحدث قيم الإنتاجية القصوى هذه عند قيم مختلفة للطلبات المتزامنة. قد تدفع هذه الخصائص ممارس تعلم الآلة إلى تبرير تكلفة مثيل واحد على الآخر. على سبيل المثال، نظرًا لمتطلبات زمن الوصول المنخفض، قد يحدد الممارس مثيل ml.g5.12xlarge (4 وحدات معالجة رسوميات A10G) عبر مثيل ml.g5.2xlarge (وحدة معالجة رسومات A1G واحدة). إذا تم توفير متطلبات إنتاجية عالية، فإن استخدام مثيل ml.p10d.4xlarge (24 وحدات معالجة رسومات A8) مع التقسيم الكامل سيكون مبررًا فقط في ظل التزامن العالي. ومع ذلك، لاحظ أنه غالبًا ما يكون من المفيد بدلاً من ذلك تحميل مكونات الاستدلال المتعددة لنموذج 100B على مثيل ml.p7d.4xlarge واحد؛ ستتم مناقشة هذا الدعم متعدد النماذج لاحقًا في هذا المنشور.
تم إجراء الملاحظات السابقة لنموذج Llama 2 7B. ومع ذلك، تظل الأنماط المماثلة صحيحة بالنسبة للنماذج الأخرى أيضًا. الفكرة الأساسية هي أن أرقام أداء زمن الاستجابة والإنتاجية تعتمد على الحمولة ونوع المثيل وعدد الطلبات المتزامنة، لذلك ستحتاج إلى العثور على التكوين المثالي لتطبيقك المحدد. لإنشاء الأرقام السابقة لحالة الاستخدام الخاصة بك، يمكنك تشغيل الملف المرتبط مفكرة، حيث يمكنك تكوين تحليل اختبار الحمل هذا لنموذجك ونوع المثيل والحمولة.
فهم مواصفات المسرع
يعتمد اختيار الأجهزة المناسبة لاستدلال LLM بشكل كبير على حالات استخدام محددة وأهداف تجربة المستخدم وLLM المختار. يحاول هذا القسم إنشاء فهم للركبة في منحنى إنتاجية الكمون فيما يتعلق بالمبادئ عالية المستوى بناءً على مواصفات المسرع. هذه المبادئ وحدها لا تكفي لاتخاذ القرار: فالمقاييس الحقيقية ضرورية. على المدى جهاز يتم استخدامه هنا ليشمل جميع مسرعات أجهزة ML. نحن نؤكد أن الركبة في منحنى إنتاجية الكمون مدفوعة بأحد عاملين:
- لقد استنفد المسرع الذاكرة للتخزين المؤقت لمصفوفات KV، لذلك يتم وضع الطلبات اللاحقة في قائمة الانتظار
- لا يزال لدى المسرع ذاكرة احتياطية لذاكرة التخزين المؤقت KV، ولكنه يستخدم حجم دفعة كبير بما يكفي بحيث يتم تحديد وقت المعالجة بواسطة حساب زمن الوصول للعملية بدلاً من عرض النطاق الترددي للذاكرة
نحن نفضل عادة أن نكون مقيدين بالعامل الثاني لأن هذا يعني أن موارد المسرع مشبعة. في الأساس، أنت تقوم بتعظيم الموارد التي دفعت مقابلها. دعونا نستكشف هذا التأكيد بمزيد من التفصيل.
التخزين المؤقت KV وذاكرة الجهاز
تقوم آليات انتباه المحولات القياسية بحساب الانتباه لكل رمز مميز جديد مقابل جميع الرموز المميزة السابقة. تقوم معظم خوادم ML الحديثة بتخزين مفاتيح الانتباه والقيم في ذاكرة الجهاز (DRAM) لتجنب إعادة الحساب في كل خطوة. وهذا ما يسمى هذا مخبأ كيلو فولت، وينمو مع حجم الدفعة وطول التسلسل. وهو يحدد عدد طلبات المستخدم التي يمكن تقديمها بالتوازي، وسيحدد الركبة في منحنى إنتاجية زمن الوصول إذا لم يتم استيفاء النظام المرتبط بالحساب في السيناريو الثاني المذكور سابقًا، نظرًا لذاكرة الوصول العشوائي الديناميكية (DRAM) المتاحة. الصيغة التالية عبارة عن تقدير تقريبي للحد الأقصى لحجم ذاكرة التخزين المؤقت KV.

في هذه الصيغة، B هو حجم الدفعة وN هو عدد المسرعات. على سبيل المثال، يستهلك نموذج Llama 2 7B في FP16 (2 بايت/معلمة) الذي يتم تقديمه على وحدة معالجة الرسومات A10G (ذاكرة DRAM سعة 24 جيجابايت) حوالي 14 جيجابايت، ويترك 10 جيجابايت لذاكرة التخزين المؤقت KV. من خلال توصيل طول السياق الكامل للنموذج (N = 4096) والمعلمات المتبقية (n_layers=32، وn_kv_attention_heads=32، وd_attention_head=128)، يوضح هذا التعبير أننا مقيدون بخدمة حجم دفعة من أربعة مستخدمين بالتوازي بسبب قيود DRAM . إذا لاحظت المعايير المقابلة في الجدول السابق، فهذا يعد تقريبًا جيدًا للركبة المرصودة في منحنى إنتاجية زمن الوصول هذا. طرق مثل الاهتمام بالاستعلام المجمع (GQA) يمكنه تقليل حجم ذاكرة التخزين المؤقت لـ KV، وفي حالة GQA بنفس العامل فإنه يقلل من عدد رؤوس KV.
الكثافة الحسابية وعرض النطاق الترددي لذاكرة الجهاز
لقد تجاوز النمو في القوة الحسابية لمسرعات تعلم الآلة عرض النطاق الترددي للذاكرة، مما يعني أنه يمكنهم إجراء العديد من العمليات الحسابية على كل بايت من البيانات في مقدار الوقت المستغرق للوصول إلى تلك البايت.
• شدة الحساب، أو نسبة عمليات الحساب إلى الوصول إلى الذاكرة، حيث تحدد العملية ما إذا كانت محدودة بعرض النطاق الترددي للذاكرة أو سعة الحساب على الجهاز المحدد. على سبيل المثال، يمكن لوحدة معالجة الرسومات A10G (عائلة نوع مثيل g5) مع 70 TFLOPS FP16 وعرض النطاق الترددي 600 جيجابايت/ثانية حساب 116 عملية/بايت تقريبًا. يمكن لوحدة معالجة الرسومات A100 (عائلة نوع مثيل p4d) حساب 208 عملية/بايت تقريبًا. إذا كانت الكثافة الحسابية لنموذج المحول أقل من تلك القيمة، فهو مرتبط بالذاكرة؛ إذا كان أعلاه، فهو مرتبط بالحساب. تتطلب آلية الانتباه الخاصة بـ Llama 2 7B 62 ops/byte لحجم الدفعة 1 (للحصول على شرح، راجع دليل لاستدلال LLM والأداء) مما يعني أنها مرتبطة بالذاكرة. عندما تكون آلية الانتباه مرتبطة بالذاكرة، يتم ترك عمليات التقلب الباهظة الثمن دون استخدام.
هناك طريقتان للاستفادة بشكل أفضل من المسرع وزيادة الكثافة الحسابية: تقليل الوصول إلى الذاكرة المطلوبة للعملية (وهذا ما تنبيه فلاش يركز على) أو زيادة حجم الدفعة. ومع ذلك، قد لا نكون قادرين على زيادة حجم الدفعة لدينا بما يكفي للوصول إلى نظام مرتبط بالحوسبة إذا كانت ذاكرة الوصول العشوائي الديناميكية (DRAM) لدينا صغيرة جدًا بحيث لا يمكنها الاحتفاظ بذاكرة التخزين المؤقت KV المقابلة. يتم وصف التقريب الخام لحجم الدفعة الحرجة B* الذي يفصل بين الأنظمة المرتبطة بالحساب والأنظمة المرتبطة بالذاكرة لاستدلال وحدة فك ترميز GPT القياسية من خلال التعبير التالي، حيث A_mb هو عرض النطاق الترددي لذاكرة التسريع، وA_f هو FLOPS المسرع، وN هو الرقم من المسرعات. يمكن استخلاص حجم الدُفعة الحرج هذا من خلال إيجاد الوقت الذي يساوي فيه وقت الوصول إلى الذاكرة وقت الحساب. تشير إلى هذا بلوق وظيفة لفهم المعادلة 2 وافتراضاتها بمزيد من التفصيل.
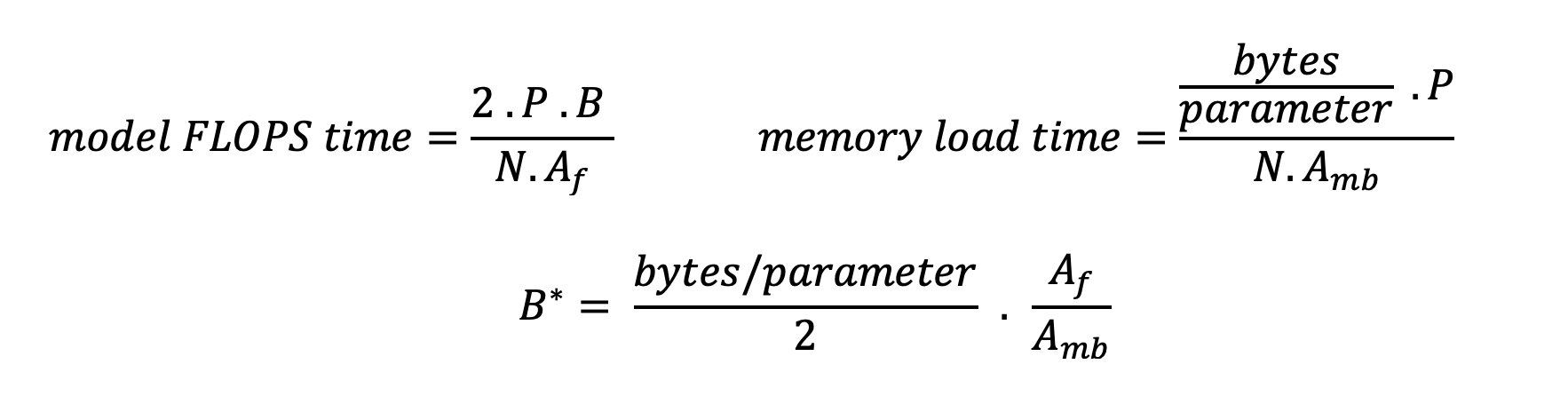
هذه هي نفس نسبة العمليات/البايت التي حسبناها سابقًا لـ A10G، وبالتالي فإن حجم الدفعة الحرجة على وحدة معالجة الرسومات هذه هو 116. إحدى الطرق للتعامل مع حجم الدفعة النظري الحرج هذا هي زيادة تقسيم النموذج وتقسيم ذاكرة التخزين المؤقت عبر المزيد من مسرعات N. يؤدي هذا إلى زيادة سعة ذاكرة التخزين المؤقت KV بشكل فعال بالإضافة إلى حجم الدفعة المرتبطة بالذاكرة.
هناك فائدة أخرى لتقسيم النموذج وهي تقسيم معلمات النموذج وعمل تحميل البيانات عبر مسرعات N. هذا النوع من التجزئة هو نوع من التوازي النموذجي يشار إليه أيضًا باسم التوازي الموتر. بسذاجة، هناك N أضعاف عرض النطاق الترددي للذاكرة وقوة الحوسبة بشكل إجمالي. بافتراض عدم وجود أي حمل من أي نوع (الاتصالات والبرامج وما إلى ذلك)، فإن هذا من شأنه أن يقلل زمن وصول فك التشفير لكل رمز مميز بمقدار N إذا كنا مرتبطين بالذاكرة، لأن زمن وصول فك تشفير الرمز المميز في هذا النظام مرتبط بالوقت الذي يستغرقه تحميل النموذج الأوزان وذاكرة التخزين المؤقت. ومع ذلك، في الحياة الواقعية، تؤدي زيادة درجة التقسيم إلى زيادة الاتصال بين الأجهزة لمشاركة عمليات التنشيط الوسيطة في كل طبقة نموذج. تقتصر سرعة الاتصال هذه على النطاق الترددي للاتصال البيني للجهاز. ومن الصعب تقدير تأثيره بدقة (لمزيد من التفاصيل، انظر التوازي النموذجي)، ولكن هذا يمكن أن يتوقف في النهاية عن تحقيق الفوائد أو تدهور الأداء - وهذا ينطبق بشكل خاص على النماذج الأصغر حجمًا، لأن عمليات نقل البيانات الأصغر تؤدي إلى انخفاض معدلات النقل.
لمقارنة مسرعات ML بناءً على مواصفاتها، نوصي بما يلي. أولاً، احسب حجم الدفعة الحرجة التقريبي لكل نوع مسرع وفقًا للمعادلة الثانية وحجم ذاكرة التخزين المؤقت KV لحجم الدفعة الحرجة وفقًا للمعادلة الأولى. يمكنك بعد ذلك استخدام ذاكرة الوصول العشوائي الديناميكية المتوفرة على المسرع لحساب الحد الأدنى لعدد المسرعات المطلوبة لملاءمة ذاكرة التخزين المؤقت KV ومعلمات النموذج. في حالة الاختيار بين عدة مسرعات، قم بإعطاء الأولوية للمسرعات بالترتيب الأقل تكلفة لكل جيجابايت/ثانية من عرض النطاق الترددي للذاكرة. أخيرًا، قم بقياس هذه التكوينات وتحقق من أفضل تكلفة/رمز مميز للحد الأعلى لوقت الاستجابة المطلوب.
حدد تكوين نشر نقطة النهاية
تستخدم العديد من شهادات LLM الموزعة بواسطة SageMaker JumpStart امتداد استنتاج توليد النص (تي جي آي) حاوية سيج ميكر لخدمة النموذج. يناقش الجدول التالي كيفية ضبط مجموعة متنوعة من معلمات عرض النماذج إما للتأثير على خدمة النموذج التي تؤثر على منحنى إنتاجية زمن الوصول أو حماية نقطة النهاية من الطلبات التي قد تؤدي إلى زيادة التحميل على نقطة النهاية. هذه هي المعلمات الأساسية التي يمكنك استخدامها لتكوين نشر نقطة النهاية الخاصة بك لحالة الاستخدام الخاصة بك. ما لم ينص على خلاف ذلك، فإننا نستخدم الافتراضي معلمات حمولة إنشاء النص و متغيرات بيئة TGI.
| متغيرات البيئة | الوصف | القيمة الافتراضية لـ SageMaker JumpStart |
| تكوينات الخدمة النموذجية | . | . |
MAX_BATCH_PREFILL_TOKENS |
يحد من عدد الرموز المميزة في عملية التعبئة المسبقة. تقوم هذه العملية بإنشاء ذاكرة التخزين المؤقت KV لتسلسل موجه الإدخال الجديد. وهي كثيفة الاستخدام للذاكرة ومقيدة بالحوسبة، لذا فإن هذه القيمة تحدد عدد الرموز المميزة المسموح بها في عملية تعبئة مسبقة واحدة. تتوقف خطوات فك التشفير للاستعلامات الأخرى مؤقتًا أثناء حدوث التعبئة المسبقة. | 4096 (TGI الافتراضي) أو الحد الأقصى لطول السياق المدعوم الخاص بالنموذج (يتوفر SageMaker JumpStart)، أيهما أكبر. |
MAX_BATCH_TOTAL_TOKENS |
يتحكم في الحد الأقصى لعدد الرموز المميزة التي سيتم تضمينها ضمن دفعة أثناء فك التشفير، أو تمرير أمامي واحد عبر النموذج. ومن الناحية المثالية، تم تعيين هذا لتعظيم استخدام جميع الأجهزة المتاحة. | غير محدد (TGI الافتراضي). سيقوم TGI بتعيين هذه القيمة فيما يتعلق بذاكرة CUDA المتبقية أثناء عملية إحماء النموذج. |
SM_NUM_GPUS |
عدد القطع التي سيتم استخدامها. أي عدد وحدات معالجة الرسومات المستخدمة لتشغيل النموذج باستخدام توازي الموتر. | يعتمد على المثيل (يتوفر SageMaker JumpStart). بالنسبة لكل مثيل مدعوم لنموذج معين، يوفر SageMaker JumpStart أفضل إعداد لتوازي الموتر. |
| تكوينات لحماية نقطة النهاية الخاصة بك (اضبطها لحالة الاستخدام الخاصة بك) | . | . |
MAX_TOTAL_TOKENS |
وهذا يحد من ميزانية الذاكرة لطلب عميل واحد عن طريق الحد من عدد الرموز المميزة في تسلسل الإدخال بالإضافة إلى عدد الرموز المميزة في تسلسل الإخراج ( max_new_tokens معلمة الحمولة). |
الحد الأقصى لطول السياق المدعوم الخاص بالنموذج. على سبيل المثال، 4096 للاما 2. |
MAX_INPUT_LENGTH |
يحدد الحد الأقصى المسموح به لعدد الرموز المميزة في تسلسل الإدخال لطلب عميل واحد. تتضمن الأشياء التي يجب مراعاتها عند زيادة هذه القيمة ما يلي: تتطلب تسلسلات الإدخال الأطول مزيدًا من الذاكرة، مما يؤثر على التجميع المستمر، كما أن العديد من النماذج لها طول سياق مدعوم لا ينبغي تجاوزه. | الحد الأقصى لطول السياق المدعوم الخاص بالنموذج. على سبيل المثال، 4095 للاما 2. |
MAX_CONCURRENT_REQUESTS |
الحد الأقصى لعدد الطلبات المتزامنة التي تسمح بها نقطة النهاية المنشورة. ستؤدي الطلبات الجديدة التي تتجاوز هذا الحد على الفور إلى ظهور خطأ محمّل بشكل زائد للنموذج لمنع زمن الوصول الضعيف لطلبات المعالجة الحالية. | 128 (TGI الافتراضي). يتيح لك هذا الإعداد الحصول على إنتاجية عالية لمجموعة متنوعة من حالات الاستخدام، ولكن يجب عليك التثبيت بالشكل المناسب للتخفيف من أخطاء مهلة استدعاء SageMaker. |
يستخدم خادم TGI الدفع المستمر، والذي يقوم بشكل ديناميكي بتجميع الطلبات المتزامنة معًا لمشاركة تمرير أمامي لاستنتاج نموذج واحد. هناك نوعان من التمريرات الأمامية: التعبئة المسبقة وفك التشفير. يجب أن يقوم كل طلب جديد بتشغيل تمريرة أمامية واحدة للتعبئة المسبقة لملء ذاكرة التخزين المؤقت KV لرموز تسلسل الإدخال. بعد ملء ذاكرة التخزين المؤقت KV، ينفذ تمرير فك التشفير الأمامي توقعًا واحدًا للرمز المميز التالي لجميع الطلبات المجمعة، والذي يتم تكراره بشكل متكرر لإنتاج تسلسل الإخراج. عند إرسال الطلبات الجديدة إلى الخادم، يجب أن تنتظر خطوة فك التشفير التالية حتى يمكن تشغيل خطوة التعبئة المسبقة للطلبات الجديدة. يجب أن يحدث هذا قبل أن يتم تضمين هذه الطلبات الجديدة في خطوات فك التشفير اللاحقة المجمعة بشكل مستمر. نظرًا لقيود الأجهزة، قد لا تتضمن الدفعات المستمرة المستخدمة لفك التشفير جميع الطلبات. عند هذه النقطة، تدخل الطلبات في قائمة انتظار المعالجة ويبدأ زمن استجابة الاستدلال في الزيادة بشكل ملحوظ مع زيادة طفيفة في الإنتاجية.
من الممكن فصل تحليلات قياس زمن استجابة LLM إلى زمن استجابة التعبئة المسبقة، وزمن وصول فك التشفير، وزمن وصول قائمة الانتظار. يختلف الوقت الذي يستهلكه كل مكون من هذه المكونات بشكل أساسي في طبيعته: فالملء المسبق عبارة عن حساب لمرة واحدة، ويحدث فك التشفير مرة واحدة لكل رمز مميز في تسلسل الإخراج، ويتضمن الانتظار عمليات تجميع الخادم. عندما تتم معالجة طلبات متزامنة متعددة، يصبح من الصعب فصل أزمنة الاستجابة عن كل مكون من هذه المكونات لأن زمن الاستجابة الذي يواجهه أي طلب عميل معين يتضمن أزمنة استجابة في قائمة الانتظار مدفوعة بالحاجة إلى التعبئة المسبقة للطلبات المتزامنة الجديدة بالإضافة إلى أزمنة الاستجابة في قائمة الانتظار المدفوعة بالتضمين للطلب في عمليات فك التشفير دفعة واحدة. لهذا السبب، يركز هذا المنشور على زمن الوصول للمعالجة الشاملة. تحدث الركبة في منحنى إنتاجية زمن الوصول عند نقطة التشبع حيث تبدأ أزمنة انتظار قائمة الانتظار في الزيادة بشكل ملحوظ. تحدث هذه الظاهرة لأي خادم استدلال نموذجي وتكون مدفوعة بمواصفات التسريع.
تتضمن المتطلبات الشائعة أثناء النشر تلبية الحد الأدنى من الإنتاجية المطلوبة والحد الأقصى المسموح به لوقت الاستجابة والحد الأقصى للتكلفة في الساعة والحد الأقصى للتكلفة لإنشاء مليون رمز مميز. يجب عليك اشتراط هذه المتطلبات على الحمولات التي تمثل طلبات المستخدم النهائي. يجب أن يأخذ التصميم الذي يلبي هذه المتطلبات في الاعتبار العديد من العوامل، بما في ذلك بنية النموذج المحددة وحجم النموذج وأنواع المثيلات وعدد المثيلات (القياس الأفقي). في الأقسام التالية، نركز على نشر نقاط النهاية لتقليل زمن الوصول وزيادة الإنتاجية وتقليل التكلفة. يأخذ هذا التحليل في الاعتبار 1 رمزًا مميزًا و512 رمزًا مميزًا للإخراج.
تقليل الكمون
يعد زمن الوصول متطلبًا مهمًا في العديد من حالات الاستخدام في الوقت الفعلي. في الجدول التالي، نلقي نظرة على الحد الأدنى لوقت الاستجابة لكل نموذج وكل نوع مثيل. يمكنك تحقيق الحد الأدنى من الكمون عن طريق الإعداد MAX_CONCURRENT_REQUESTS = 1.
| الحد الأدنى لزمن الوصول (ملي ثانية/الرمز المميز) | |||||
| معرف النموذج | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| اللاما 2 7 ب | 33 | 17 | 18 | 20 | - |
| اللاما 2 7B الدردشة | 33 | 17 | 18 | 20 | - |
| اللاما 2 13 ب | - | 22 | 23 | 23 | - |
| اللاما 2 13B الدردشة | - | 23 | 23 | 23 | - |
| اللاما 2 70 ب | - | - | 57 | 43 | - |
| اللاما 2 70B الدردشة | - | - | 57 | 45 | - |
| ميسترال 7 ب | 35 | - | - | - | - |
| تعليمات ميسترال 7B | 35 | - | - | - | - |
| ميكسترال 8x7B | - | - | 33 | 27 | - |
| الصقر 7B | 33 | - | - | - | - |
| تعليمات الصقر 7B | 33 | - | - | - | - |
| الصقر 40B | - | 53 | 33 | 27 | - |
| تعليمات الصقر 40B | - | 53 | 33 | 28 | - |
| الصقر 180B | - | - | - | - | 42 |
| دردشة فالكون 180 بي | - | - | - | - | 42 |
لتحقيق الحد الأدنى من زمن الاستجابة للنموذج، يمكنك استخدام التعليمات البرمجية التالية أثناء استبدال معرف النموذج ونوع المثيل المطلوبين:
لاحظ أن أرقام زمن الوصول تتغير بناءً على عدد رموز الإدخال والإخراج. ومع ذلك، تظل عملية النشر كما هي باستثناء متغيرات البيئة MAX_INPUT_TOKENS و MAX_TOTAL_TOKENS. هنا، يتم تعيين متغيرات البيئة هذه للمساعدة في ضمان متطلبات زمن الوصول لنقطة النهاية لأن تسلسلات الإدخال الأكبر قد تنتهك متطلبات زمن الاستجابة. لاحظ أن SageMaker JumpStart يوفر بالفعل متغيرات البيئة المثالية الأخرى عند تحديد نوع المثيل؛ على سبيل المثال، سيتم تعيين استخدام ml.g5.12xlarge SM_NUM_GPUS إلى 4 في البيئة النموذجية.
تعظيم الإنتاجية
في هذا القسم، نقوم بزيادة عدد الرموز المميزة التي تم إنشاؤها في الثانية. يتم تحقيق ذلك عادةً عند الحد الأقصى من الطلبات المتزامنة الصالحة للنموذج ونوع المثيل. في الجدول التالي، نقوم بالإبلاغ عن الإنتاجية التي تم تحقيقها عند أكبر قيمة طلب متزامن تم تحقيقها قبل مواجهة مهلة استدعاء SageMaker لأي طلب.
| الحد الأقصى للإنتاجية (الرموز المميزة/ثانية)، الطلبات المتزامنة | |||||
| معرف النموذج | ml.g5.2xlarge | ml.g5.12xlarge | ml.g5.48xlarge | ml.p4d.24xlarge | ml.p4de.24xlarge |
| اللاما 2 7 ب | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| اللاما 2 7B الدردشة | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| اللاما 2 13 ب | - | 787 (128) | 496 (64) | 3245 (512) | - |
| اللاما 2 13B الدردشة | - | 782 (128) | 505 (64) | 3310 (512) | - |
| اللاما 2 70 ب | - | - | 124 (16) | 1585 (256) | - |
| اللاما 2 70B الدردشة | - | - | 114 (16) | 1546 (256) | - |
| ميسترال 7 ب | 947 (64) | - | - | - | - |
| تعليمات ميسترال 7B | 986 (128) | - | - | - | - |
| ميكسترال 8x7B | - | - | 701 (128) | 3196 (512) | - |
| الصقر 7B | 1340 (128) | - | - | - | - |
| تعليمات الصقر 7B | 1313 (128) | - | - | - | - |
| الصقر 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| تعليمات الصقر 40B | - | 245 (32) | 415 (64) | 2675 (512) | - |
| الصقر 180B | - | - | - | - | 1100 (128) |
| دردشة فالكون 180 بي | - | - | - | - | 1081 (128) |
لتحقيق أقصى إنتاجية لنموذج، يمكنك استخدام الكود التالي:
لاحظ أن الحد الأقصى لعدد الطلبات المتزامنة يعتمد على نوع النموذج ونوع المثيل والحد الأقصى لعدد رموز الإدخال والحد الأقصى لعدد رموز الإخراج. ولذلك، يجب عليك تعيين هذه المعلمات قبل الإعداد MAX_CONCURRENT_REQUESTS.
لاحظ أيضًا أن المستخدم المهتم بتقليل زمن الاستجابة غالبًا ما يكون على خلاف مع مستخدم مهتم بزيادة الإنتاجية إلى الحد الأقصى. يهتم الأول بالاستجابات في الوقت الفعلي، في حين يهتم الأخير بالمعالجة المجمعة بحيث تكون قائمة انتظار نقطة النهاية مشبعة دائمًا، وبالتالي تقليل وقت توقف المعالجة. غالبًا ما يهتم المستخدمون الذين يرغبون في تحقيق أقصى قدر من الإنتاجية المشروطة بمتطلبات زمن الوصول بالعمل على الركبة في منحنى إنتاجية زمن الوصول.
تقليل التكلفة
يتضمن الخيار الأول لتقليل التكلفة تقليل التكلفة لكل ساعة. باستخدام هذا، يمكنك نشر نموذج محدد على مثيل SageMaker بأقل تكلفة في الساعة. لمعرفة التسعير في الوقت الفعلي لمثيلات SageMaker، راجع تسعير Amazon SageMaker. بشكل عام، يعد نوع المثيل الافتراضي لـ SageMaker JumpStart LLMs هو خيار النشر الأقل تكلفة.
يتضمن الخيار الثاني لتقليل التكلفة تقليل التكلفة لإنشاء مليون رمز مميز. هذا تحويل بسيط للجدول الذي ناقشناه سابقًا لزيادة الإنتاجية إلى أقصى حد، حيث يمكنك أولاً حساب الوقت المستغرق بالساعات لإنشاء مليون رمز مميز (1e1 / الإنتاجية / 1). يمكنك بعد ذلك مضاعفة هذه المرة لإنشاء مليون رمز مميز بسعر الساعة لمثيل SageMaker المحدد.
لاحظ أن المثيلات ذات التكلفة الأقل لكل ساعة ليست هي نفسها المثيلات ذات التكلفة الأقل لإنشاء مليون رمز مميز. على سبيل المثال، إذا كانت طلبات الاستدعاء متفرقة، فقد يكون المثيل ذو التكلفة الأقل لكل ساعة هو الأمثل، بينما في سيناريوهات التقييد، قد تكون أقل تكلفة لإنشاء مليون رمز مميز أكثر ملاءمة.
الموتر الموازي مقابل المقايضة متعددة النماذج
في جميع التحليلات السابقة، فكرنا في نشر نسخة طبق الأصل من نموذج واحد بدرجة توازي موتر تساوي عدد وحدات معالجة الرسومات في نوع مثيل النشر. هذا هو سلوك SageMaker JumpStart الافتراضي. ومع ذلك، كما ذكرنا سابقًا، يمكن أن تؤدي مشاركة النموذج إلى تحسين زمن وصول النموذج وإنتاجيته فقط إلى حد معين، والذي تهيمن بعده متطلبات الاتصال بين الأجهزة على وقت الحساب. وهذا يعني أنه من المفيد في كثير من الأحيان نشر نماذج متعددة ذات درجة متوازية أقل في مثيل واحد بدلاً من نموذج واحد بدرجة متوازية أعلى.
هنا، ننشر نقطتي النهاية Llama 2 7B و13B على مثيلات ml.p4d.24xlarge بدرجات متوازي الموتر (TP) 1 و2 و4 و8. للحصول على الوضوح في سلوك النموذج، تقوم كل نقطة من نقاط النهاية هذه بتحميل نموذج واحد فقط.
| . | الإنتاجية (الرموز / ثانية) | الكمون (ملي ثانية/الرمز المميز) | ||||||||||||||||||
| الطلبات المتزامنة | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| درجة TP | اللاما 2 13 ب | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | اللاما 2 7 ب | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
أظهرت تحليلاتنا السابقة بالفعل مزايا كبيرة في الإنتاجية على مثيلات ml.p4d.24xlarge، والتي غالبًا ما تُترجم إلى أداء أفضل من حيث التكلفة لإنشاء مليون رمز مميز عبر عائلة مثيلات g1 في ظل ظروف تحميل الطلب المتزامن العالية. يوضح هذا التحليل بوضوح أنه يجب عليك مراعاة المفاضلة بين تقسيم النموذج وتكرار النموذج في مثيل واحد؛ وهذا يعني أن النموذج المجزأ بالكامل لا يمثل عادةً أفضل استخدام لموارد الحوسبة ml.p5d.4xlarge لعائلات النماذج 24B و7B. في الواقع، بالنسبة لعائلة الطراز 13B، يمكنك الحصول على أفضل إنتاجية لنسخة طبق الأصل من نموذج واحد بدرجة توازي موتر تبلغ 7 بدلاً من 4.
من هنا، يمكنك استنتاج أن أعلى تكوين إنتاجي للنموذج 7B يتضمن درجة متوازية موتر تبلغ 1 مع ثمانية نسخ متماثلة للنماذج، ومن المحتمل أن يكون تكوين أعلى إنتاجية للنموذج 13B هو درجة موازية موتر تبلغ 2 مع أربع نسخ متماثلة للنماذج. لمعرفة المزيد حول كيفية تحقيق ذلك، راجع يمكنك تقليل تكاليف نشر النموذج بنسبة 50% في المتوسط باستخدام أحدث ميزات Amazon SageMaker، والذي يوضح استخدام نقاط النهاية المستندة إلى مكونات الاستدلال. نظرًا لتقنيات موازنة التحميل، وتوجيه الخادم، ومشاركة موارد وحدة المعالجة المركزية (CPU)، قد لا تتمكن من تحقيق تحسينات كاملة في الإنتاجية تساوي تمامًا عدد النسخ المتماثلة مضروبًا في الإنتاجية لنسخة متماثلة واحدة.
التحجيم الأفقي
كما لوحظ سابقًا، فإن كل عملية نشر لنقطة النهاية لها قيود على عدد الطلبات المتزامنة اعتمادًا على عدد الرموز المميزة للإدخال والإخراج بالإضافة إلى نوع المثيل. إذا كان هذا لا يلبي متطلبات الإنتاجية أو الطلب المتزامن، فيمكنك التوسيع للاستفادة من أكثر من مثيل واحد خلف نقطة النهاية المنشورة. يقوم SageMaker تلقائيًا بإجراء موازنة تحميل الاستعلامات بين المثيلات. على سبيل المثال، تنشر التعليمة البرمجية التالية نقطة نهاية مدعومة بثلاث حالات:
يوضح الجدول التالي كسب الإنتاجية كعامل لعدد المثيلات لنموذج Llama 2 7B.
| . | . | الإنتاجية (الرموز / ثانية) | الكمون (ملي ثانية/الرمز المميز) | ||||||||||||||
| . | الطلبات المتزامنة | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| عدد المثيلات | نوع الطلب | عدد الرموز الإجمالية: 512، عدد الرموز المميزة للإخراج: 256 | |||||||||||||||
| 1 | ml.g5.2xlarge | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | ml.g5.2xlarge | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | ml.g5.2xlarge | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
ومن الجدير بالذكر أن الركبة في منحنى إنتاجية زمن الوصول تنتقل إلى اليمين لأن أعداد المثيلات الأعلى يمكنها التعامل مع أعداد أكبر من الطلبات المتزامنة داخل نقطة النهاية متعددة المثيلات. بالنسبة لهذا الجدول، تكون قيمة الطلب المتزامن لنقطة النهاية بأكملها، وليس لعدد الطلبات المتزامنة التي يتلقاها كل مثيل على حدة.
يمكنك أيضًا استخدام ميزة القياس التلقائي، وهي ميزة لمراقبة أعباء العمل لديك وضبط السعة ديناميكيًا للحفاظ على أداء ثابت ويمكن التنبؤ به بأقل تكلفة ممكنة. وهذا خارج نطاق هذا المنصب. لمعرفة المزيد حول القياس التلقائي، راجع تكوين نقاط نهاية الاستدلال التلقائي في Amazon SageMaker.
استدعاء نقطة النهاية مع الطلبات المتزامنة
لنفترض أن لديك مجموعة كبيرة من الاستعلامات التي ترغب في استخدامها لإنشاء استجابات من نموذج منشور في ظل ظروف إنتاجية عالية. على سبيل المثال، في مقطع التعليمات البرمجية التالي، نقوم بتجميع قائمة تضم 1,000 حمولة، حيث تطلب كل حمولة إنشاء 100 رمز مميز. إجمالاً، نطلب إنشاء 100,000 رمز.
عند إرسال عدد كبير من الطلبات إلى واجهة برمجة تطبيقات وقت تشغيل SageMaker، قد تواجه أخطاء في التقييد. وللتخفيف من ذلك، يمكنك إنشاء عميل وقت تشغيل SageMaker مخصص يزيد من عدد محاولات إعادة المحاولة. يمكنك توفير كائن جلسة SageMaker الناتج إلى ملف JumpStartModel منشئ أو sagemaker.predictor.retrieve_default إذا كنت ترغب في إرفاق متنبئ جديد بنقطة نهاية تم نشرها بالفعل. في التعليمة البرمجية التالية، نستخدم كائن الجلسة هذا عند نشر نموذج Llama 2 مع تكوينات SageMaker JumpStart الافتراضية:
نقطة النهاية المنشورة هذه لديها MAX_CONCURRENT_REQUESTS = 128 بشكل افتراضي. في الكتلة التالية، نستخدم مكتبة العقود الآجلة المتزامنة للتكرار على استدعاء نقطة النهاية لجميع الحمولات مع 128 مؤشر ترابط عامل. على الأكثر، ستعالج نقطة النهاية 128 طلبًا متزامنًا، وكلما أعاد الطلب استجابة، سيرسل المنفذ على الفور طلبًا جديدًا إلى نقطة النهاية.
يؤدي هذا إلى إنشاء 100,000 رمز مميز بإجمالي إنتاجية تبلغ 1255 رمزًا مميزًا/ثانية على مثيل ml.g5.2xlarge واحد. يستغرق هذا حوالي 80 ثانية للمعالجة.
لاحظ أن قيمة الإنتاجية هذه تختلف بشكل ملحوظ عن الحد الأقصى للإنتاجية لـ Llama 2 7B على ml.g5.2xlarge في الجداول السابقة لهذا المنشور (486 رمزًا مميزًا/ثانية عند 64 طلبًا متزامنًا). وذلك لأن حمولة الإدخال تستخدم 8 رموز مميزة بدلاً من 256، وعدد الرموز المميزة للإخراج هو 100 بدلاً من 256، وتسمح أعداد الرموز المميزة الأصغر بـ 128 طلبًا متزامنًا. هذا تذكير أخير بأن جميع أرقام زمن الوصول والإنتاجية تعتمد على الحمولة! سيؤثر تغيير أعداد الرموز المميزة للحمولة النافعة على عمليات التجميع أثناء تقديم النموذج، مما سيؤثر بدوره على أوقات التعبئة المسبقة وفك التشفير وقائمة الانتظار الناشئة لتطبيقك.
وفي الختام
في هذا المنشور، قدمنا معايير قياس مستوى SageMaker JumpStart LLMs، بما في ذلك Llama 2 وMistral وFalcon. لقد قدمنا أيضًا دليلاً لتحسين زمن الاستجابة والإنتاجية والتكلفة لتكوين نشر نقطة النهاية لديك. يمكنك البدء بتشغيل دفتر الملاحظات المرتبط لقياس حالة الاستخدام الخاصة بك.
حول المؤلف
 دكتور كايل أولريش هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. تشمل اهتماماته البحثية خوارزميات التعلم الآلي القابلة للتطوير ، والرؤية الحاسوبية ، والسلاسل الزمنية ، والمعاملات البايزية غير البارامترية ، والعمليات الغاوسية. حصل على درجة الدكتوراه من جامعة ديوك وقد نشر أبحاثًا في NeurIPS و Cell و Neuron.
دكتور كايل أولريش هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. تشمل اهتماماته البحثية خوارزميات التعلم الآلي القابلة للتطوير ، والرؤية الحاسوبية ، والسلاسل الزمنية ، والمعاملات البايزية غير البارامترية ، والعمليات الغاوسية. حصل على درجة الدكتوراه من جامعة ديوك وقد نشر أبحاثًا في NeurIPS و Cell و Neuron.
 Dr. فيفيك مادان هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. حصل على الدكتوراه من جامعة إلينوي في Urbana-Champaign وكان باحثًا بعد الدكتوراه في Georgia Tech. وهو باحث نشط في التعلم الآلي وتصميم الخوارزمية وقد نشر أوراقًا علمية في مؤتمرات EMNLP و ICLR و COLT و FOCS و SODA.
Dr. فيفيك مادان هو عالم تطبيقي مع فريق Amazon SageMaker JumpStart. حصل على الدكتوراه من جامعة إلينوي في Urbana-Champaign وكان باحثًا بعد الدكتوراه في Georgia Tech. وهو باحث نشط في التعلم الآلي وتصميم الخوارزمية وقد نشر أوراقًا علمية في مؤتمرات EMNLP و ICLR و COLT و FOCS و SODA.
 د. أشيش خيتان هو عالم تطبيقي أقدم في Amazon SageMaker JumpStart ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
د. أشيش خيتان هو عالم تطبيقي أقدم في Amazon SageMaker JumpStart ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
 جواو مورا هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة في AWS. يساعد João عملاء AWS - من الشركات الناشئة الصغيرة إلى المؤسسات الكبيرة - على تدريب النماذج الكبيرة ونشرها بكفاءة، وبناء منصات تعلم الآلة على AWS على نطاق أوسع.
جواو مورا هو أحد كبار مهندسي الحلول المتخصصة في الذكاء الاصطناعي/تعلم الآلة في AWS. يساعد João عملاء AWS - من الشركات الناشئة الصغيرة إلى المؤسسات الكبيرة - على تدريب النماذج الكبيرة ونشرها بكفاءة، وبناء منصات تعلم الآلة على AWS على نطاق أوسع.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/

