اليوم، يسعدنا أن نعلن عن القدرة على ضبط نماذج Code Llama باستخدام Meta أمازون سيج ميكر جومب ستارت. تعد عائلة Code Llama من نماذج اللغات الكبيرة (LLMs) عبارة عن مجموعة من نماذج إنشاء التعليمات البرمجية المدربة مسبقًا والمضبوطة بدقة والتي يتراوح حجمها من 7 مليار إلى 70 مليار معلمة. توفر نماذج Code Llama المضبوطة دقة أفضل وقابلية للتفسير مقارنة بنماذج Code Llama الأساسية، كما هو واضح في اختبارها ضد HumanEval ومجموعات بيانات MBPP. يمكنك ضبط نماذج Code Llama ونشرها باستخدام SageMaker JumpStart باستخدام أمازون ساجميكر ستوديو واجهة المستخدم ببضع نقرات أو باستخدام SageMaker Python SDK. يعتمد الضبط الدقيق لنماذج اللاما على البرامج النصية المتوفرة في ملف اللاما وصفات جيثب الريبو من Meta باستخدام تقنيات التكميم PyTorch FSDP وPEFT/LoRA وInt8.
في هذا المنشور، سنتعرف على كيفية ضبط النماذج المدربة مسبقًا على Code Llama عبر SageMaker JumpStart من خلال تجربة واجهة مستخدم وSDK بنقرة واحدة متاحة في ما يلي مستودع جيثب.
ما هو برنامج SageMaker JumpStart
باستخدام SageMaker JumpStart، يمكن لممارسي التعلم الآلي (ML) الاختيار من بين مجموعة واسعة من النماذج الأساسية المتاحة للعامة. يمكن لممارسي ML نشر النماذج الأساسية لـ مخصصة الأمازون SageMaker مثيلات من بيئة شبكة معزولة وتخصيص النماذج باستخدام SageMaker للتدريب على النموذج ونشره.
ما هو كود اللاما
Code Llama هو إصدار متخصص في التعليمات البرمجية من اللاما 2 تم إنشاؤه من خلال مواصلة تدريب Llama 2 على مجموعات البيانات الخاصة بالرمز وأخذ عينات أكثر من مجموعة البيانات نفسها لفترة أطول. يتميز Code Llama بقدرات ترميز محسنة. يمكنه إنشاء تعليمات برمجية ولغة طبيعية حول التعليمات البرمجية، من كل من مطالبات التعليمات البرمجية واللغة الطبيعية (على سبيل المثال، "اكتب لي دالة تُخرج تسلسل فيبوناتشي"). يمكنك أيضًا استخدامه لإكمال التعليمات البرمجية وتصحيح الأخطاء. وهو يدعم العديد من لغات البرمجة الأكثر شيوعًا المستخدمة اليوم، بما في ذلك Python وC++ وJava وPHP وTypescript (JavaScript) وC# وBash والمزيد.
لماذا نقوم بضبط نماذج Code Llama؟
نشرت Meta معايير أداء Code Llama في HumanEval وMBPP للغات الترميز الشائعة مثل Python وJava وJavaScript. أظهر أداء نماذج Code Llama Python على HumanEval أداءً متفاوتًا عبر لغات البرمجة والمهام المختلفة، حيث تراوح الأداء من 38% في نموذج 7B Python إلى 57% في نماذج 70B Python. بالإضافة إلى ذلك، أظهرت نماذج Code Llama المضبوطة بدقة على لغة برمجة SQL نتائج أفضل، كما هو واضح في معايير تقييم SQL. تسلط هذه المعايير المنشورة الضوء على الفوائد المحتملة للضبط الدقيق لنماذج Code Llama، مما يتيح أداءً أفضل وتخصيصًا وتكيفًا مع مجالات ومهام ترميز محددة.
الضبط الدقيق بدون تعليمات برمجية عبر واجهة مستخدم SageMaker Studio
لبدء ضبط نماذج Llama الخاصة بك باستخدام SageMaker Studio، أكمل الخطوات التالية:
- في وحدة تحكم SageMaker Studio ، اختر بداية القفز في جزء التنقل.
ستجد قوائم تضم أكثر من 350 نموذجًا تتراوح بين النماذج مفتوحة المصدر والنماذج الخاصة.
- ابحث عن نماذج Code Llama.

إذا كنت لا ترى نماذج Code Llama، فيمكنك تحديث إصدار SageMaker Studio الخاص بك عن طريق إيقاف التشغيل وإعادة التشغيل. لمزيد من المعلومات حول تحديثات الإصدار، راجع قم بإيقاف تشغيل وتحديث تطبيقات الاستوديو. يمكنك أيضًا العثور على متغيرات الطراز الأخرى عن طريق الاختيار استكشف جميع نماذج إنشاء التعليمات البرمجية أو ابحث عن Code Llama في مربع البحث.
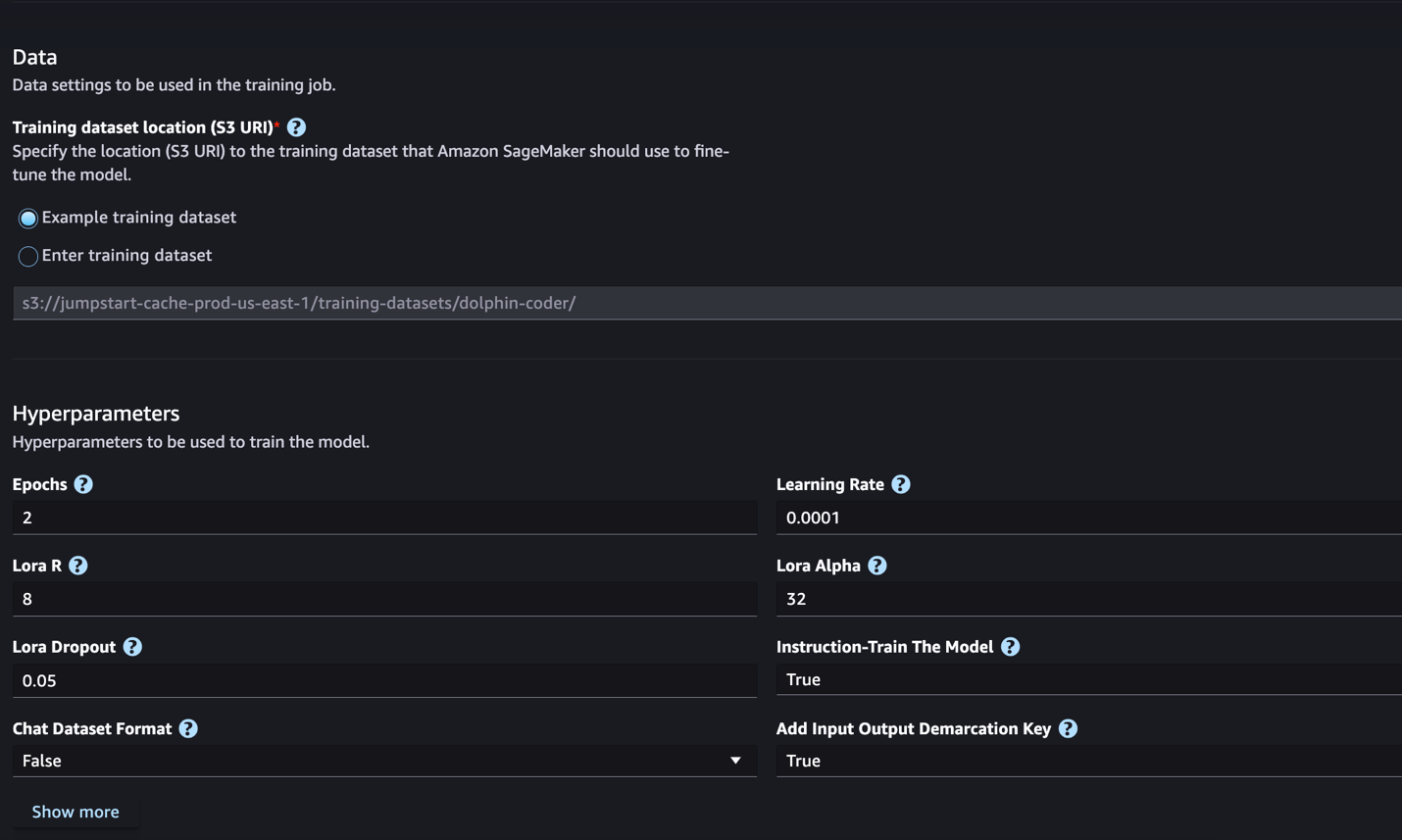
يدعم SageMaker JumpStart حاليًا الضبط الدقيق للتعليمات لنماذج Code Llama. تعرض لقطة الشاشة التالية صفحة الضبط الدقيق لنموذج Code Llama 2 70B.
- في حالة موقع مجموعة بيانات التدريب، يمكنك الإشارة إلى خدمة تخزين أمازون البسيطة مجموعة (Amazon S3) تحتوي على مجموعات بيانات التدريب والتحقق من الصحة من أجل الضبط الدقيق.
- قم بتعيين تكوين النشر والمعلمات الفائقة وإعدادات الأمان للضبط الدقيق.
- اختار قطار لبدء مهمة الضبط الدقيق على مثيل SageMaker ML.
نناقش تنسيق مجموعة البيانات الذي تحتاجه للتحضير لضبط التعليمات في القسم التالي.
- بعد ضبط النموذج بشكل دقيق، يمكنك نشره باستخدام صفحة النموذج على SageMaker JumpStart.
سيظهر خيار نشر النموذج المضبوط بدقة عند الانتهاء من الضبط الدقيق، كما هو موضح في لقطة الشاشة التالية.

الضبط الدقيق عبر SageMaker Python SDK
في هذا القسم، نوضح كيفية ضبط نماذج Code LIama باستخدام SageMaker Python SDK على مجموعة بيانات بتنسيق التعليمات. على وجه التحديد، تم ضبط النموذج بشكل دقيق لمجموعة من مهام معالجة اللغة الطبيعية (NLP) الموضحة باستخدام التعليمات. يساعد هذا في تحسين أداء النموذج للمهام غير المرئية من خلال المطالبات الصفرية.
أكمل الخطوات التالية لإكمال مهمة الضبط الدقيق. يمكنك الحصول على كود الضبط الدقيق بالكامل من مستودع جيثب.
أولاً، دعونا نلقي نظرة على تنسيق مجموعة البيانات المطلوبة لضبط التعليمات. يجب تنسيق بيانات التدريب بتنسيق خطوط JSON (.jsonl)، حيث يكون كل سطر عبارة عن قاموس يمثل عينة بيانات. يجب أن تكون جميع بيانات التدريب في مجلد واحد. ومع ذلك، يمكن حفظه في ملفات .jsonl متعددة. فيما يلي نموذج بتنسيق خطوط JSON:
يمكن أن يحتوي مجلد التدريب على ملف template.json ملف يصف تنسيقات الإدخال والإخراج. وفيما يلي نموذج القالب:
لمطابقة القالب، يجب أن تتضمن كل عينة في ملفات خطوط JSON system_prompt, questionو response مجالات. في هذه التظاهرة نستخدم مجموعة بيانات دولفين المبرمج من عناق الوجه.
بعد إعداد مجموعة البيانات وتحميلها إلى حاوية S3، يمكنك البدء في الضبط الدقيق باستخدام الكود التالي:
يمكنك نشر النموذج المضبوط مباشرة من المقدر، كما هو موضح في التعليمة البرمجية التالية. لمزيد من التفاصيل، راجع دفتر الملاحظات في مستودع جيثب.
تقنيات الضبط الدقيق
يبلغ حجم نماذج اللغة مثل Llama أكثر من 10 جيجابايت أو حتى 100 جيجابايت. يتطلب الضبط الدقيق لهذه النماذج الكبيرة مثيلات ذات ذاكرة CUDA عالية بشكل ملحوظ. علاوة على ذلك، قد يكون تدريب هذه النماذج بطيئًا جدًا نظرًا لحجم النموذج. لذلك، من أجل الضبط الدقيق الفعال، نستخدم التحسينات التالية:
- التكيف ذو الرتبة المنخفضة (LoRA) - هذا نوع من الضبط الدقيق الفعال للمعلمات (PEFT) من أجل الضبط الدقيق الفعال للنماذج الكبيرة. باستخدام هذه الطريقة، يمكنك تجميد النموذج بأكمله وإضافة مجموعة صغيرة فقط من المعلمات أو الطبقات القابلة للتعديل إلى النموذج. على سبيل المثال، بدلاً من تدريب جميع المعلمات البالغ عددها 7 مليار لـ Llama 2 7B، يمكنك ضبط أقل من 1% من المعلمات. يساعد هذا في تقليل متطلبات الذاكرة بشكل كبير لأنك تحتاج فقط إلى تخزين التدرجات وحالات المحسن والمعلومات الأخرى المتعلقة بالتدريب لـ 1% فقط من المعلمات. علاوة على ذلك، يساعد ذلك في تقليل وقت التدريب وكذلك التكلفة. لمزيد من التفاصيل حول هذه الطريقة، راجع LoRA: التكيف منخفض الرتبة لنماذج اللغة الكبيرة.
- Int8 التكميم - حتى مع التحسينات مثل LoRA، لا تزال نماذج مثل Llama 70B أكبر من أن يتم تدريبها. لتقليل أثر الذاكرة أثناء التدريب، يمكنك استخدام تكميم Int8 أثناء التدريب. عادةً ما يقلل التكميم من دقة أنواع بيانات النقطة العائمة. على الرغم من أن هذا يقلل من الذاكرة المطلوبة لتخزين أوزان النماذج، إلا أنه يؤدي إلى انخفاض الأداء بسبب فقدان المعلومات. يستخدم تكميم Int8 ربع الدقة فقط ولكنه لا يؤدي إلى تدهور الأداء لأنه لا يسقط البتات ببساطة. يقوم بتقريب البيانات من نوع إلى آخر. للتعرف على تكميم Int8، راجع LLM.int8(): مضاعفة مصفوفة 8 بت للمحولات على نطاق واسع.
- البيانات المتوازية بالكامل (FSDP) - هذا نوع من خوارزمية التدريب المتوازية للبيانات التي تقوم بتقسيم معلمات النموذج عبر العاملين المتوازيين للبيانات ويمكن اختياريًا إلغاء تحميل جزء من حساب التدريب إلى وحدات المعالجة المركزية (CPU). على الرغم من أن المعلمات مقسمة عبر وحدات معالجة الرسومات المختلفة، إلا أن حساب كل دفعة صغيرة يكون محليًا لعامل وحدة معالجة الرسومات. إنه يقسم المعلمات بشكل أكثر اتساقًا ويحقق الأداء الأمثل من خلال تداخل الاتصالات والحساب أثناء التدريب.
يلخص الجدول التالي تفاصيل كل طراز بإعدادات مختلفة.
| الموديل | الإعدادات الإفتراضية | لورا + FSDP | لورا + لا FSDP | Int8 التكميم + LORA + لا FSDP |
| رمز اللاما 2 7B | لورا + FSDP | نعم | نعم | نعم |
| رمز اللاما 2 13B | لورا + FSDP | نعم | نعم | نعم |
| رمز اللاما 2 34B | INT8 + لورا + لا FSDP | لا | لا | نعم |
| رمز اللاما 2 70B | INT8 + لورا + لا FSDP | لا | لا | نعم |
يعتمد الضبط الدقيق لنماذج اللاما على البرامج النصية المقدمة من خلال ما يلي جيثب ريبو.
المعلمات الفائقة المدعومة للتدريب
يدعم الضبط الدقيق لـ Code Llama 2 عددًا من المعلمات الفائقة، يمكن لكل منها التأثير على متطلبات الذاكرة وسرعة التدريب وأداء النموذج المضبوط بدقة:
- عصر - عدد التمريرات التي تجريها خوارزمية الضبط الدقيق عبر مجموعة بيانات التدريب. يجب أن يكون عددًا صحيحًا أكبر من 1. الإعداد الافتراضي هو 5.
- معدل التعليم – معدل تحديث أوزان النموذج بعد العمل على كل دفعة من الأمثلة التدريبية. يجب أن يكون تعويمًا موجبًا أكبر من 0. القيمة الافتراضية هي 1e-4.
- التعليمات_ضبطها – هل سيتم تعليم النموذج أم لا. لا بد وأن
TrueorFalse. الافتراضي هوFalse. - per_device_train_batch_size – حجم الدفعة لكل وحدة معالجة الرسومات الأساسية/وحدة المعالجة المركزية للتدريب. يجب ان يكون تصحيحا اجابيا. الافتراضي هو 4.
- per_device_eval_batch_size - حجم الدفعة لكل وحدة معالجة الرسومات الأساسية/وحدة المعالجة المركزية للتقييم. يجب ان يكون تصحيحا اجابيا. الافتراضي هو 1.
- max_train_samples – لأغراض تصحيح الأخطاء أو التدريب بشكل أسرع، قم باقتطاع عدد أمثلة التدريب لهذه القيمة. القيمة -1 تعني استخدام كافة عينات التدريب. يجب أن يكون عددًا صحيحًا موجبًا أو -1. الافتراضي هو -1.
- max_val_samples – لأغراض تصحيح الأخطاء أو التدريب بشكل أسرع، قم باقتطاع عدد أمثلة التحقق من الصحة لهذه القيمة. القيمة -1 تعني استخدام كافة عينات التحقق من الصحة. يجب أن يكون عددًا صحيحًا موجبًا أو -1. الافتراضي هو -1.
- max_input_length - الحد الأقصى لطول تسلسل الإدخال الإجمالي بعد الترميز. سيتم اقتطاع تسلسلات أطول من هذا. إذا -1،
max_input_lengthتم ضبطه على الحد الأدنى وهو 1024 والحد الأقصى لطول النموذج الذي يحدده برنامج الرمز المميز. إذا تم تعيينها على قيمة إيجابية،max_input_lengthتم ضبطه على الحد الأدنى من القيمة المقدمة وmodel_max_lengthتم تعريفه بواسطة الرمز المميز. يجب أن يكون عددًا صحيحًا موجبًا أو -1. الافتراضي هو -1. - validation_split_ratio - إذا كانت قناة التحقق من الصحة
none، يجب أن تكون نسبة فصل التحقق من صحة القطار من بيانات القطار بين 0-1. الافتراضي هو 0.2. - Train_data_split_seed - في حالة عدم وجود بيانات التحقق من الصحة، يؤدي ذلك إلى إصلاح التقسيم العشوائي لبيانات التدريب المدخلة إلى بيانات التدريب والتحقق التي تستخدمها الخوارزمية. يجب أن يكون صحيحا. الافتراضي هو 0.
- المعالجة المسبقة_num_workers – عدد العمليات المستخدمة للمعالجة المسبقة. لو
None، يتم استخدام العملية الرئيسية للمعالجة المسبقة. الافتراضي هوNone. - lora_r – لورا ر. يجب أن يكون عدداً صحيحاً موجباً. الافتراضي هو 8.
- lora_alpha - لورا ألفا. يجب ان يكون تصحيحا اجابيا. الافتراضي هو 32
- lora_dropout - لورا التسرب. يجب أن يكون تعويمًا موجبًا بين 0 و1. القيمة الافتراضية هي 0.05.
- int8_quantization - إذا
True، يتم تحميل النموذج بدقة 8 بت للتدريب. الافتراضي لـ 7B و13B هوFalse. الافتراضي لـ 70B هوTrue. - تمكين_fsdp – إذا كان صحيحا، يستخدم التدريب FSDP. الافتراضي لـ 7B و13B هو صحيح. الافتراضي لـ 70B هو خطأ. لاحظ أن
int8_quantizationغير مدعوم مع FSDP.
عند اختيار المعلمات الفائقة، ضع في اعتبارك ما يلي:
- الضبط
int8_quantization=Trueيقلل من متطلبات الذاكرة ويؤدي إلى تدريب أسرع. - تقليل
per_device_train_batch_sizeوmax_input_lengthيقلل من متطلبات الذاكرة وبالتالي يمكن تشغيله على مثيلات أصغر. ومع ذلك، فإن تحديد قيم منخفضة جدًا قد يؤدي إلى زيادة وقت التدريب. - إذا كنت لا تستخدم تكميم Int8 (
int8_quantization=False)، استخدم FSDP (enable_fsdp=True) لتدريب أسرع وأكثر كفاءة.
أنواع المثيلات المدعومة للتدريب
يلخص الجدول التالي أنواع المثيلات المدعومة لتدريب النماذج المختلفة.
| الموديل | نوع المثيل الافتراضي | أنواع المثيلات المدعومة |
| رمز اللاما 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge، ml.g5.24xlarge، ml.g5.48xlarge، ml.p3dn.24xlarge، ml.g4dn.12xlarge |
| رمز اللاما 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge، ml.g5.48xlarge، ml.p3dn.24xlarge، ml.g4dn.12xlarge |
| رمز اللاما 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
عند اختيار نوع المثيل، ضع في اعتبارك ما يلي:
- توفر مثيلات G5 التدريب الأكثر كفاءة بين أنواع المثيلات المدعومة. لذلك، إذا كانت لديك مثيلات G5 متاحة، فيجب عليك استخدامها.
- يعتمد وقت التدريب إلى حد كبير على مقدار عدد وحدات معالجة الرسومات وذاكرة CUDA المتوفرة. ولذلك، فإن التدريب على المثيلات التي لها نفس العدد من وحدات معالجة الرسومات (على سبيل المثال، ml.g5.2xlarge وml.g5.4xlarge) هو نفسه تقريبًا. لذلك، يمكنك استخدام المثيل الأرخص للتدريب (ml.g5.2xlarge).
- عند استخدام مثيلات p3، سيتم إجراء التدريب بدقة 32 بت لأن bfloat16 غير مدعوم في هذه المثيلات. لذلك، ستستهلك مهمة التدريب ضعف كمية ذاكرة CUDA عند التدريب على مثيلات p3 مقارنة بمثيلات g5.
للتعرف على تكلفة التدريب لكل مثيل، راجع مثيلات Amazon EC2 G5.
التقييم
يعد التقييم خطوة مهمة لتقييم أداء النماذج المضبوطة بدقة. نقدم تقييمات نوعية وكمية لإظهار تحسن النماذج المضبوطة بدقة مقارنة بالنماذج غير المضبوطة بدقة. في التقييم النوعي، نعرض استجابة نموذجية من النماذج المضبوطة وغير المضبوطة. وفي التقييم الكمي نستخدم HumanEval، مجموعة اختبار تم تطويرها بواسطة OpenAI لإنشاء كود Python لاختبار القدرة على إنتاج نتائج صحيحة ودقيقة. يقع مستودع HumanEval تحت ترخيص MIT. لقد قمنا بضبط متغيرات Python لجميع نماذج Code LIama بأحجام مختلفة (Code LIama Python 7B و13B و34B و70B على مجموعة بيانات دولفين المبرمج)، وعرض نتائج التقييم في الأقسام التالية.
التقييم النوعي
مع نشر النموذج الذي تم ضبطه بدقة، يمكنك البدء في استخدام نقطة النهاية لإنشاء التعليمات البرمجية. في المثال التالي، نقدم استجابات من متغيرات Code LIama 34B Python الأساسية والمضبوطة بدقة على عينة اختبار في مجموعة بيانات دولفين المبرمج:
يقوم نموذج Code Llama المضبوط بدقة، بالإضافة إلى توفير الكود للاستعلام السابق، بإنشاء شرح تفصيلي للنهج وكود زائف.
الاستجابة غير الدقيقة لرمز Llama 34b Python:
استجابة Code Llama 34B Python الدقيقة
الحقيقة الأرضية
ومن المثير للاهتمام أن نسختنا المحسّنة من Code Llama 34B Python توفر حلاً ديناميكيًا قائمًا على البرمجة لأطول سلسلة فرعية متناوبة، والذي يختلف عن الحل المقدم في الحقيقة الأساسية من مثال الاختبار المحدد. نموذجنا المضبوط يفسر ويشرح الحل الديناميكي القائم على البرمجة بالتفصيل. من ناحية أخرى، فإن النموذج غير المضبوط يهلوس النواتج المحتملة مباشرة بعد print بيان (كما هو موضح في الخلية اليسرى) لأن الإخراج axyzzyx ليس أطول متناظر في السلسلة المحددة. من حيث التعقيد الزمني، فإن حل البرمجة الديناميكية أفضل بشكل عام من النهج الأولي. يحتوي حل البرمجة الديناميكية على تعقيد زمني قدره O(n^2)، حيث n هو طول سلسلة الإدخال. يعد هذا أكثر كفاءة من الحل الأولي من النموذج غير المضبوط بدقة، والذي كان له أيضًا تعقيد زمني تربيعي قدره O(n^2) ولكن بنهج أقل تحسينًا.
هذا يبدو واعدا! تذكر أننا قمنا فقط بضبط متغير Code LIama Python بنسبة 10% من مجموعة بيانات دولفين المبرمج. هناك الكثير لاستكشافه!
على الرغم من التعليمات الشاملة الواردة في الرد، ما زلنا بحاجة إلى فحص صحة كود بايثون المقدم في الحل. بعد ذلك، نستخدم إطار تقييم يسمى تقييم الإنسان لإجراء اختبارات التكامل على الاستجابة الناتجة من Code LIama لفحص جودتها بشكل منهجي.
التقييم الكمي مع HumanEval
HumanEval عبارة عن أداة تقييمية لتقييم قدرات LLM على حل مشكلات البرمجة المستندة إلى Python، كما هو موضح في الورقة تقييم نماذج اللغات الكبيرة المدربة على التعليمات البرمجية. على وجه التحديد، يتكون من 164 مشكلة برمجة أصلية تعتمد على لغة Python والتي تعمل على تقييم قدرة نموذج اللغة على إنشاء تعليمات برمجية بناءً على المعلومات المقدمة مثل توقيع الوظيفة، وسلسلة المستندات، والنص، واختبارات الوحدة.
بالنسبة لكل سؤال برمجة قائم على Python، نرسله إلى نموذج Code LIama الذي تم نشره على نقطة نهاية SageMaker للحصول على استجابات k. بعد ذلك، نقوم بتشغيل كل من إجابات k في اختبارات التكامل في مستودع HumanEval. إذا اجتازت أي استجابة من استجابات k اختبارات التكامل، فإننا نحسب أن حالة الاختبار هذه ناجحة؛ خلاف ذلك، فشل. ثم نكرر العملية لحساب نسبة الحالات الناجحة حسب درجة التقييم النهائية pass@k. باتباع الممارسة القياسية، قمنا بتعيين k كـ 1 في تقييمنا، لإنشاء إجابة واحدة فقط لكل سؤال واختبار ما إذا كان يجتاز اختبار التكامل.
ما يلي هو نموذج التعليمات البرمجية لاستخدام مستودع HumanEval. يمكنك الوصول إلى مجموعة البيانات وإنشاء استجابة واحدة باستخدام نقطة نهاية SageMaker. لمزيد من التفاصيل، راجع دفتر الملاحظات في مستودع جيثب.
يوضح الجدول التالي التحسينات التي تم إدخالها على نماذج Code LIama Python المضبوطة بدقة على النماذج غير المضبوطة عبر أحجام النماذج المختلفة. لضمان الصحة، نقوم أيضًا بنشر نماذج Code LIama غير المضبوطة بدقة في نقاط نهاية SageMaker وتشغيلها من خلال تقييمات Human Eval. ال تمرير @ 1 الأرقام (الصف الأول في الجدول التالي) تتطابق مع الأرقام المذكورة في ورقة بحثية عن كود اللاما. يتم تعيين معلمات الاستدلال باستمرار على النحو التالي "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
كما يمكننا أن نرى من النتائج، فإن جميع متغيرات Code LIama Python المضبوطة بدقة تظهر تحسنًا كبيرًا مقارنة بالنماذج غير المضبوطة بدقة. على وجه الخصوص، يتفوق Code LIama Python 70B على النموذج غير المضبوط بنسبة 12% تقريبًا.
| . | 7 ب بايثون | 13 ب بايثون | 34B | 34 ب بايثون | 70 ب بايثون |
| أداء النموذج الذي تم تدريبه مسبقًا (تمرير @ 1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| أداء نموذجي مضبوط (تمرير @ 1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
يمكنك الآن تجربة ضبط نماذج Code LIama على مجموعة البيانات الخاصة بك.
تنظيف
إذا قررت أنك لم تعد ترغب في استمرار تشغيل نقطة نهاية SageMaker، فيمكنك حذفها باستخدام AWS SDK لـ Python (Boto3), واجهة سطر الأوامر AWS (AWS CLI)، أو وحدة تحكم SageMaker. لمزيد من المعلومات، راجع حذف نقاط النهاية والموارد. بالإضافة إلى ذلك ، يمكنك ذلك قم بإيقاف تشغيل موارد SageMaker Studio التي لم تعد مطلوبة.
وفي الختام
في هذا المنشور، ناقشنا الضبط الدقيق لنماذج Meta's Code Llama 2 باستخدام SageMaker JumpStart. لقد أظهرنا أنه يمكنك استخدام وحدة التحكم SageMaker JumpStart في SageMaker Studio أو SageMaker Python SDK لضبط هذه النماذج ونشرها. ناقشنا أيضًا تقنية الضبط الدقيق وأنواع المثيلات والمعلمات الفائقة المدعومة. بالإضافة إلى ذلك، قمنا بتحديد توصيات للتدريب الأمثل بناءً على الاختبارات المختلفة التي أجريناها. كما يمكننا أن نرى من نتائج الضبط الدقيق لثلاثة نماذج عبر مجموعتي بيانات، فإن الضبط الدقيق يحسن التلخيص مقارنة بالنماذج غير المضبوطة بدقة. كخطوة تالية، يمكنك محاولة ضبط هذه النماذج على مجموعة البيانات الخاصة بك باستخدام الكود المتوفر في مستودع GitHub لاختبار النتائج وقياسها لحالات الاستخدام الخاصة بك.
حول المؤلف
 الدكتور شين هوانغ هو عالم تطبيقي كبير في Amazon SageMaker JumpStart وخوارزميات Amazon SageMaker المدمجة. يركز على تطوير خوارزميات التعلم الآلي القابلة للتطوير. تتركز اهتماماته البحثية في مجال معالجة اللغة الطبيعية ، والتعلم العميق القابل للتفسير على البيانات المجدولة ، والتحليل القوي لتجميع الزمكان غير المعياري. وقد نشر العديد من الأوراق في مؤتمرات ACL و ICDM و KDD والجمعية الملكية للإحصاء: السلسلة أ.
الدكتور شين هوانغ هو عالم تطبيقي كبير في Amazon SageMaker JumpStart وخوارزميات Amazon SageMaker المدمجة. يركز على تطوير خوارزميات التعلم الآلي القابلة للتطوير. تتركز اهتماماته البحثية في مجال معالجة اللغة الطبيعية ، والتعلم العميق القابل للتفسير على البيانات المجدولة ، والتحليل القوي لتجميع الزمكان غير المعياري. وقد نشر العديد من الأوراق في مؤتمرات ACL و ICDM و KDD والجمعية الملكية للإحصاء: السلسلة أ.
 فيشال يالامانجالي هو مهندس حلول الشركات الناشئة الذي يعمل مع شركات الذكاء الاصطناعي والروبوتات والمركبات ذاتية القيادة في المراحل المبكرة. يعمل Vishaal مع عملائه لتقديم حلول ML المتطورة وهو مهتم شخصيًا بالتعلم المعزز وتقييم LLM وإنشاء الأكواد. قبل انضمامه إلى AWS، كان Vishaal طالبًا جامعيًا في UCI، وكان يركز على المعلوماتية الحيوية والأنظمة الذكية.
فيشال يالامانجالي هو مهندس حلول الشركات الناشئة الذي يعمل مع شركات الذكاء الاصطناعي والروبوتات والمركبات ذاتية القيادة في المراحل المبكرة. يعمل Vishaal مع عملائه لتقديم حلول ML المتطورة وهو مهتم شخصيًا بالتعلم المعزز وتقييم LLM وإنشاء الأكواد. قبل انضمامه إلى AWS، كان Vishaal طالبًا جامعيًا في UCI، وكان يركز على المعلوماتية الحيوية والأنظمة الذكية.
 ميناكشيسوندارام ثاندافارايان يعمل لدى AWS كمتخصص في الذكاء الاصطناعي/ تعلم الآلة. لديه شغف لتصميم وإنشاء وتعزيز تجارب البيانات والتحليلات التي تركز على الإنسان. تركز Meena على تطوير أنظمة مستدامة توفر مزايا تنافسية قابلة للقياس للعملاء الاستراتيجيين لشركة AWS. مينا هي موصلة ومفكرة تصميمية، وتسعى جاهدة لدفع الشركات إلى طرق جديدة للعمل من خلال الابتكار والحضانة وإرساء الديمقراطية.
ميناكشيسوندارام ثاندافارايان يعمل لدى AWS كمتخصص في الذكاء الاصطناعي/ تعلم الآلة. لديه شغف لتصميم وإنشاء وتعزيز تجارب البيانات والتحليلات التي تركز على الإنسان. تركز Meena على تطوير أنظمة مستدامة توفر مزايا تنافسية قابلة للقياس للعملاء الاستراتيجيين لشركة AWS. مينا هي موصلة ومفكرة تصميمية، وتسعى جاهدة لدفع الشركات إلى طرق جديدة للعمل من خلال الابتكار والحضانة وإرساء الديمقراطية.
 د. أشيش خيتان هو عالم تطبيقي أقدم مع خوارزميات Amazon SageMaker المضمنة ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
د. أشيش خيتان هو عالم تطبيقي أقدم مع خوارزميات Amazon SageMaker المضمنة ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

