يقوم عملاء AWS في مجال الرعاية الصحية والخدمات المالية والقطاع العام والصناعات الأخرى بتخزين مليارات المستندات في صورة صور أو ملفات PDF خدمة تخزين أمازون البسيطة (أمازون إس 3). ومع ذلك، لا يمكنهم الحصول على رؤى مثل استخدام المعلومات المقفلة في المستندات لنماذج اللغات الكبيرة (LLMs) أو البحث حتى يستخرجوا النص والنماذج والجداول والبيانات المنظمة الأخرى. مع معالجة AWS الذكية للمستندات (IDP) باستخدام خدمات الذكاء الاصطناعي مثل أمازون تيكستراك، يمكنك الاستفادة من تقنية التعلم الآلي (ML) الرائدة في الصناعة لمعالجة البيانات بسرعة ودقة من ملفات PDF أو صور المستندات (TIFF، JPEG، PNG). بعد استخراج النص من المستندات، يمكنك استخدامه لضبط نموذج الأساس، تلخيص البيانات باستخدام نموذج الأساسأو إرساله إلى قاعدة البيانات.
في هذا المنشور، نركز على معالجة مجموعة كبيرة من المستندات وتحويلها إلى ملفات نصية خام وتخزينها في Amazon S3. نحن نقدم لك حلين مختلفين لحالة الاستخدام هذه. الأول يسمح لك بتشغيل برنامج Python النصي من أي خادم أو مثيل بما في ذلك دفتر Jupyter؛ هذه هي أسرع طريقة للبدء. النهج الثاني هو النشر الجاهز لمكونات البنية التحتية المختلفة باستخدام مجموعة تطوير سحابة AWS (أوس سي دي كيه) يبني. يوفر تصميم AWS CDK إطارًا مرنًا ومرنًا لمعالجة مستنداتك وإنشاء مسار IDP شامل. من خلال استخدام AWS CDK، يمكنك توسيع وظائفه لتشمل التنقيح، قم بتخزين المخرجات في Amazon OpenSearchأو إضافة مخصص AWS لامدا تعمل مع منطق عملك الخاص.
يتيح لك كلا الحلين معالجة ملايين الصفحات بسرعة. قبل تشغيل أي من هذه الحلول على نطاق واسع، نوصي باختبار مجموعة فرعية من مستنداتك للتأكد من أن النتائج تلبي توقعاتك. في الأقسام التالية، سنصف أولاً حل البرنامج النصي، متبوعًا بحل إنشاء AWS CDK.
الحل 1: استخدم برنامج Python النصي
يقوم هذا الحل بمعالجة المستندات الخاصة بالنص الخام من خلال Amazon Textract بالسرعة التي تسمح بها الخدمة مع توقع أنه في حالة حدوث فشل في البرنامج النصي، ستستأنف العملية من حيث توقفت. يستخدم الحل ثلاث خدمات مختلفة: Amazon S3، الأمازون DynamoDBونص الأمازون.
ويوضح الرسم البياني التالي تسلسل الأحداث داخل البرنامج النصي. عندما ينتهي البرنامج النصي، ستتم إرجاع حالة الإكمال بالإضافة إلى الوقت المستغرق إلى وحدة تحكم استوديو SageMaker.

لقد قمنا بتعبئة هذا الحل في ملف البرنامج النصي .ipynb و نصي .py. يمكنك استخدام أي من الحلول القابلة للنشر وفقًا لمتطلباتك.
المتطلبات الأساسية المسبقة
لتشغيل هذا البرنامج النصي من دفتر ملاحظات Jupyter، يجب استخدام ملف إدارة الهوية والوصول AWS يجب أن يتمتع دور (IAM) المخصص للكمبيوتر الدفتري بأذونات تسمح له بالتفاعل مع DynamoDB وAmazon S3 وAmazon Textract. التوجيه العام هو توفير أذونات ذات امتيازات أقل لكل من هذه الخدمات إلى حسابك AmazonSageMaker-ExecutionRole دور. لمعرفة المزيد، راجع ابدأ باستخدام سياسات AWS المُدارة وانتقل نحو الأذونات ذات الامتيازات الأقل.
وبدلاً من ذلك، يمكنك تشغيل هذا البرنامج النصي من بيئات أخرى مثل الأمازون الحوسبة المرنة السحابية (Amazon EC2) أو الحاوية التي ستديرها، بشرط أن تكون Python وPip3 و AWS SDK لـ Python (Boto3) تم تثبيتها. مرة أخرى، يجب تطبيق نفس سياسات IAM التي تسمح للبرنامج النصي بالتفاعل مع الخدمات المُدارة المختلفة.
تجول
لتنفيذ هذا الحل، تحتاج أولاً إلى استنساخ المستودع GitHub جيثب:.
تحتاج إلى تعيين المتغيرات التالية في البرنامج النصي قبل أن تتمكن من تشغيله:
- Tracking_table – هذا هو اسم جدول DynamoDB الذي سيتم إنشاؤه.
- input_bucket – هذا هو موقع المصدر الخاص بك في Amazon S3 الذي يحتوي على المستندات التي تريد إرسالها إلى Amazon Textract للكشف عن النص. بالنسبة لهذا المتغير، قم بتوفير اسم المجموعة، مثل
mybucket. - input_bucket - هذا مخصص لتخزين الموقع الذي تريد أن يقوم Amazon Texttract بكتابة النتائج إليه. بالنسبة لهذا المتغير، قم بتوفير اسم المجموعة، مثل
myoutputbucket. - _input_prefix (اختياري) - إذا كنت تريد تحديد ملفات معينة من داخل مجلد في حاوية S3 الخاصة بك، فيمكنك تحديد اسم المجلد هذا كبادئة إدخال. بخلاف ذلك، اترك الإعداد الافتراضي فارغًا لتحديد الكل.
النص كالتالي:
يتم إنشاء مخطط جدول DynamoDB التالي عند تشغيل البرنامج النصي:
عند تشغيل البرنامج النصي لأول مرة، فإنه سيتحقق لمعرفة ما إذا كان جدول DynamoDB موجودًا وسيقوم بإنشائه تلقائيًا إذا لزم الأمر. بعد إنشاء الجدول، نحتاج إلى ملؤه بقائمة مراجع كائنات المستند من Amazon S3 التي نريد معالجتها. سيتم تعداد البرنامج النصي حسب التصميم على الكائنات الموجودة في المحدد input_bucket وملء جدولنا تلقائيًا بأسمائهم عند تشغيله. يستغرق الأمر حوالي 10 دقائق لتعداد أكثر من 100,000 مستند وملء تلك الأسماء في جدول DynamoDB من البرنامج النصي. إذا كان لديك ملايين الكائنات في إحدى الحاويات، فيمكنك بدلاً من ذلك استخدام ميزة المخزون في Amazon S3 التي تنشئ ملف CSV بالأسماء، ثم قم بملء جدول DynamoDB من هذه القائمة بالبرنامج النصي الخاص بك مسبقًا وعدم استخدام الوظيفة المسماة fetchAllObjectsInBucketandStoreName من خلال التعليق عليه. لمعرفة المزيد، راجع تكوين مخزون Amazon S3.
كما ذكرنا سابقًا، يوجد إصدار دفتر ملاحظات وإصدار نص Python. يعد دفتر الملاحظات الطريقة الأسهل للبدء؛ ما عليك سوى تشغيل كل خلية من البداية إلى النهاية.
إذا قررت تشغيل برنامج Python النصي من واجهة سطر الأوامر (CLI)، فمن المستحسن استخدام معدد الإرسال الطرفي مثل tmux. وذلك لمنع البرنامج النصي من التوقف في حالة انتهاء جلسة SSH الخاصة بك. على سبيل المثال: tmux new -d ‘python3 textractFeeder.py’.
ما يلي هو نقطة دخول البرنامج النصي; من هنا يمكنك التعليق على الطرق غير المطلوبة:
يتم تعيين الحقول التالية عندما يقوم البرنامج النصي بملء جدول DynamoDB:
- اسم الكائن – اسم المستند الموجود في Amazon S3 والذي سيتم إرساله إلى Amazon Textract
- الاسم – الحاوية التي يتم فيها تخزين كائن المستند
يجب ملء هذين الحقلين إذا قررت استخدام ملف CSV من تقرير مخزون S3 وتخطي التعبئة التلقائية التي تحدث داخل البرنامج النصي.
الآن بعد أن تم إنشاء الجدول وملؤه بمراجع كائنات المستند، أصبح البرنامج النصي جاهزًا لبدء استدعاء Amazon Textract StartDocumentTextDetection واجهة برمجة التطبيقات. يحتوي Amazon Texttract، على غرار الخدمات المُدارة الأخرى، على الحد الافتراضي على واجهات برمجة التطبيقات التي تسمى المعاملات في الثانية (TPS). إذا لزم الأمر، يمكنك طلب زيادة الحصة من وحدة تحكم Amazon Textract. تم تصميم التعليمات البرمجية لاستخدام سلاسل رسائل متعددة بشكل متزامن عند الاتصال بـ Amazon Textract لزيادة الإنتاجية إلى أقصى حد مع الخدمة. يمكنك تغيير هذا داخل الكود عن طريق تعديل threadCountforTextractAPICall عامل. افتراضيًا، يتم تعيين هذا على 20 موضوعًا. سيقرأ البرنامج النصي في البداية 200 صف من جدول DynamoDB ويخزنها في قائمة الذاكرة الداخلية المضمنة بفئة لسلامة سلسلة الرسائل. يتم بعد ذلك بدء تشغيل كل مؤشر ترابط للمتصل وتشغيله داخل مسار السباحة الخاص به. بشكل أساسي، سيقوم مؤشر ترابط المتصل الخاص بـ Amazon Textract باسترداد عنصر من قائمة الذاكرة الداخلية التي تحتوي على مرجع الكائن الخاص بنا. ثم سيتم استدعاء غير المتزامن start_document_text_detection API وانتظر الإقرار بمعرف الوظيفة. يتم بعد ذلك تحديث معرف المهمة مرة أخرى إلى صف DynamoDB لهذا الكائن، وسيتكرر الخيط عن طريق استرداد العنصر التالي من القائمة.
ما يلي هو رمز التزامن الرئيسي سيناريو:
ستستمر سلاسل رسائل المتصل في التكرار حتى لا يكون هناك أي عناصر داخل القائمة، وعند هذه النقطة ستتوقف كل سلاسل الرسائل. عندما تتوقف جميع سلاسل العمليات التي تعمل داخل ممرات السباحة الخاصة بها، يتم استرداد الصفوف الـ 200 التالية من DynamoDB وتبدأ مجموعة جديدة مكونة من 20 سلسلة سلاسل، وتتكرر العملية بأكملها حتى يتم استرداد كل صف لا يحتوي على معرف وظيفة من DynamoDB و محدث. في حالة تعطل البرنامج النصي بسبب مشكلة غير متوقعة، فيمكن تشغيل البرنامج النصي مرة أخرى من orchestrate() طريقة. يؤدي هذا إلى التأكد من أن مؤشرات الترابط ستستمر في معالجة الصفوف التي تحتوي على معرفات مهمة فارغة. لاحظ أنه عند إعادة تشغيل orchestrate() بعد توقف البرنامج النصي، هناك احتمال أن يتم إرسال بعض المستندات إلى Amazon Textract مرة أخرى. سيكون هذا الرقم مساويًا أو أقل من عدد سلاسل العمليات التي كانت قيد التشغيل في وقت التعطل.
عندما لا يكون هناك المزيد من الصفوف التي تحتوي على معرف مهمة فارغ في جدول DynamoDB، سيتوقف البرنامج النصي. سيتم العثور على جميع مخرجات JSON من Amazon Texttract لجميع الكائنات في الملف output_bucket بشكل افتراضي تحت textract_output مجلد. كل مجلد فرعي داخل textract_output سيتم تسميته بمعرف الوظيفة الذي يتوافق مع معرف الوظيفة الذي تم تخزينه في جدول DynamoDB لهذا الكائن. داخل مجلد معرف المهمة، ستجد JSON، والذي سيتم تسميته رقميًا بدءًا من 1 ومن المحتمل أن يشمل ملفات JSON الإضافية التي سيتم تصنيفها بـ 2 و3 وما إلى ذلك. يعد امتداد ملفات JSON نتيجة للمستندات الكثيفة أو المتعددة الصفحات، حيث يتجاوز مقدار المحتوى المستخرج حجم JSON الافتراضي في Amazon Textract وهو 1,000 كتلة. تشير إلى حظر لمزيد من المعلومات حول الكتل. ستحتوي ملفات JSON هذه على جميع البيانات التعريفية لـ Amazon Textract، بما في ذلك النص الذي تم استخراجه من داخل المستندات.
يمكنك العثور على إصدار دفتر ملاحظات Python والبرنامج النصي لهذا الحل في GitHub جيثب:.
تنظيف
عند اكتمال البرنامج النصي لـ Python، يمكنك توفير التكاليف عن طريق إيقاف تشغيل البرنامج النصي أو إيقافه أمازون ساجميكر ستوديو دفتر ملاحظات أو حاوية قمت بتدويرها.
ننتقل الآن إلى الحل الثاني للمستندات على نطاق واسع.
الحل 2: استخدم بنية AWS CDK بدون خادم
يستخدم هذا الحل وظائف خطوة AWS وتعمل Lambda على تنسيق مسار IDP. نحن نستخدم ال إنشاءات IDP AWS CDK، مما يجعل من السهل العمل مع Amazon Textract على نطاق واسع. بالإضافة إلى ذلك، نستخدم أ وظائف الخطوة الموزعة الخريطة للتكرار على جميع الملفات الموجودة في مجموعة S3 وبدء المعالجة. تحدد وظيفة Lambda الأولى عدد الصفحات الموجودة في مستنداتك. يتيح ذلك لخط الأنابيب استخدام واجهة برمجة التطبيقات المتزامنة (للمستندات ذات الصفحة الواحدة) أو غير المتزامنة (للمستندات متعددة الصفحات) تلقائيًا. عند استخدام واجهة برمجة التطبيقات غير المتزامنة، يتم استدعاء وظيفة Lambda إضافية لجميع ملفات JSON التي ستنتجها Amazon Textract لجميع صفحاتك في ملف JSON واحد لتسهيل تعامل التطبيقات النهائية مع المعلومات.
يحتوي هذا الحل أيضًا على وظيفتين إضافيتين من وظائف Lambda. تقوم الوظيفة الأولى بتحليل النص من JSON وحفظه كملف نصي في Amazon S3. تقوم الوظيفة الثانية بتحليل JSON وتخزينها للمقاييس الموجودة على عبء العمل.
يوضح الرسم البياني التالي سير عمل Step Functions.

المتطلبات الأساسية المسبقة
تستخدم قاعدة التعليمات البرمجية هذه AWS CDK وتتطلب Docker. يمكنك نشر هذا من سحابة AWS 9 مثيل، والذي تم إعداد AWS CDK وDocker فيه بالفعل.
تجول
لتنفيذ هذا الحل، تحتاج أولاً إلى استنساخ ملف مستودع.
بعد استنساخ المستودع، قم بتثبيت التبعيات:
ثم استخدم التعليمة البرمجية التالية لنشر مكدس AWS CDK:
يجب عليك توفير كل من مجموعة المصدر وبادئة المصدر (موقع الملفات التي تريد معالجتها) لهذا الحل.
عند اكتمال النشر، انتقل إلى وحدة تحكم Step Functions، حيث يجب أن ترى آلة الحالة ServerlessIDPArchivePipeline.
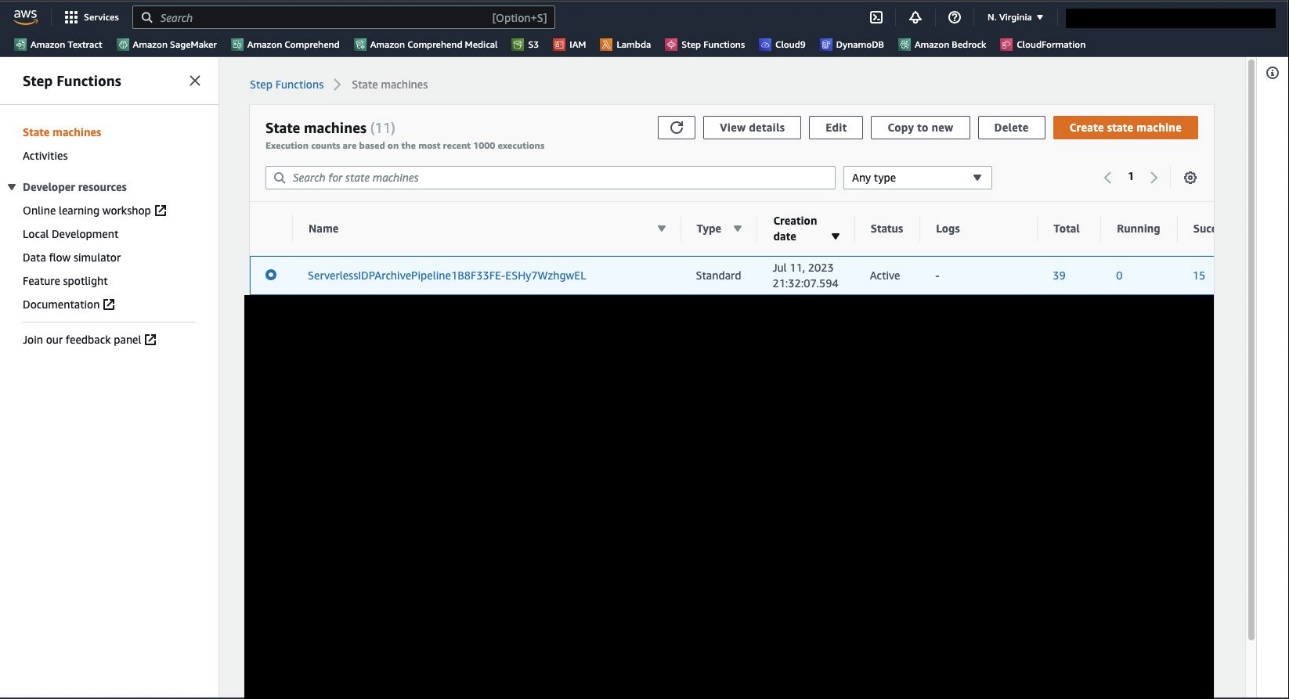
افتح صفحة تفاصيل جهاز الحالة وعلى المعاملات علامة التبويب، اختر ابدأ التنفيذ.
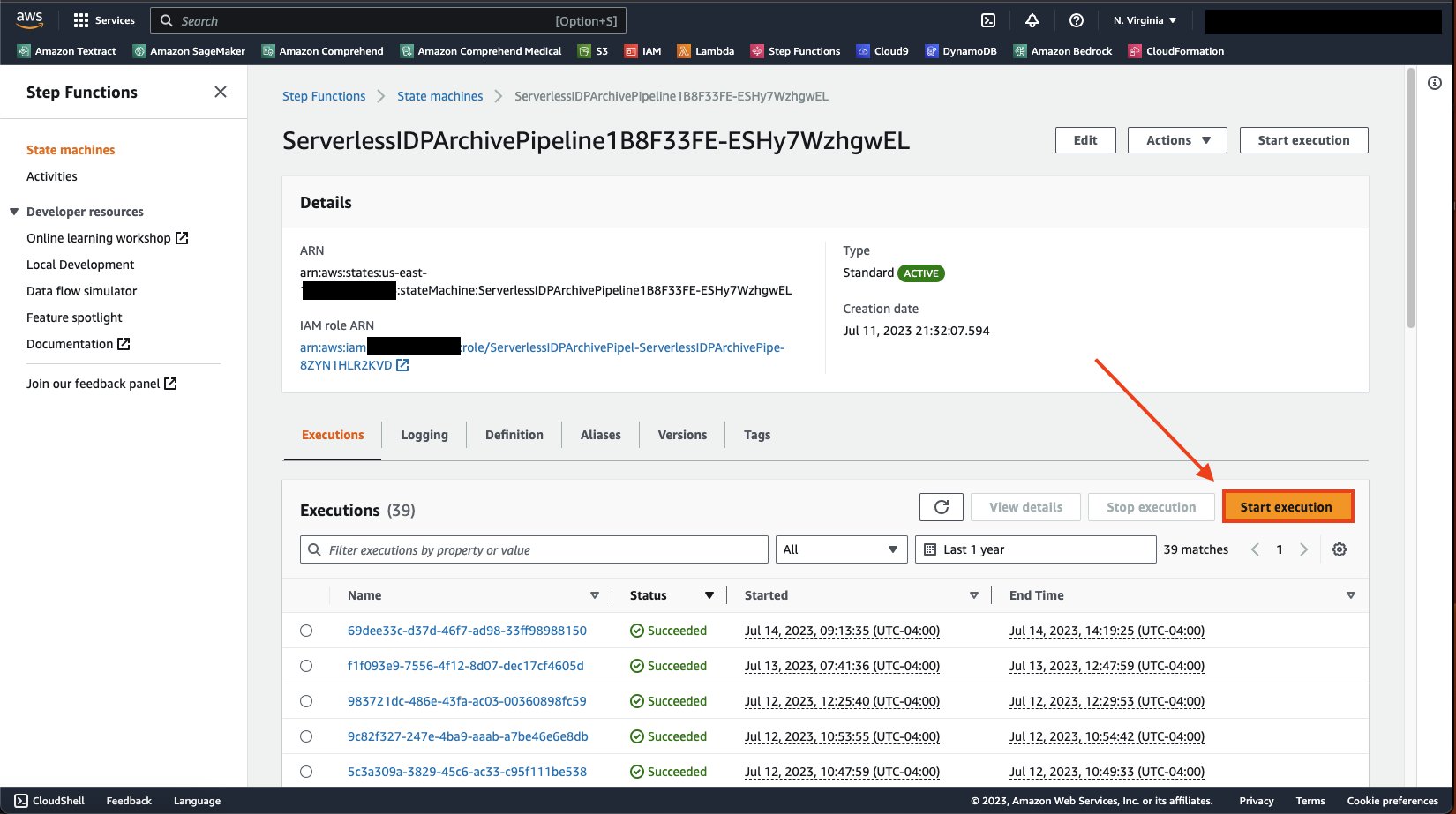
اختار ابدأ التنفيذ مرة أخرى لتشغيل آلة الدولة.
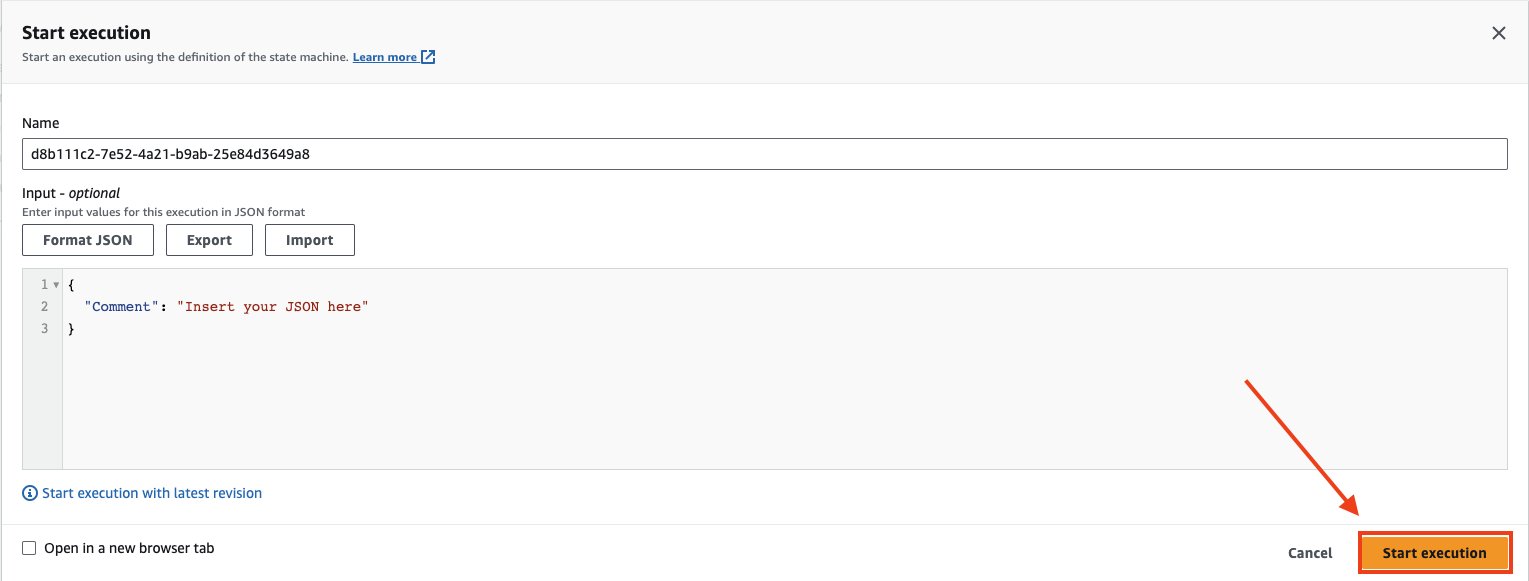
بعد بدء تشغيل جهاز الحالة، يمكنك مراقبة خط الأنابيب من خلال النظر إلى تشغيل الخريطة. سوف ترى حالة معالجة العنصر القسم مثل لقطة الشاشة التالية. كما ترون، تم تصميم هذا لتشغيل وتتبع ما نجح وما فشل. ستستمر هذه العملية حتى تتم قراءة كافة المستندات.

باستخدام هذا الحل، من المفترض أن تكون قادرًا على معالجة ملايين الملفات في حساب AWS الخاص بك دون القلق بشأن كيفية تحديد الملفات التي سيتم إرسالها إلى واجهة برمجة التطبيقات بشكل صحيح أو الملفات الفاسدة التي تفشل في مسار التدفق الخاص بك. من خلال وحدة التحكم Step Functions، ستتمكن من مشاهدة ملفاتك ومراقبتها في الوقت الفعلي.
تنظيف
بعد الانتهاء من تشغيل المسار، للتنظيف، يمكنك العودة إلى مشروعك وإدخال الأمر التالي:
سيؤدي هذا إلى حذف أية خدمات تم نشرها لهذا المشروع.
وفي الختام
في هذا المنشور، قدمنا حلاً يجعل من السهل تحويل صور المستندات وملفات PDF إلى ملفات نصية. يعد هذا شرطًا أساسيًا لاستخدام مستنداتك في الذكاء الاصطناعي والبحث. لمعرفة المزيد حول استخدام النص لتدريب نماذج الأساس الخاصة بك أو تحسينها، راجع قم بضبط Llama 2 لإنشاء النص على Amazon SageMaker JumpStart. للاستخدام مع البحث، راجع قم بتنفيذ فهرس البحث الذكي عن المستندات باستخدام Amazon Textract وAmazon OpenSearch. لمعرفة المزيد حول إمكانيات معالجة المستندات المتقدمة التي تقدمها خدمات AWS AI، راجع إرشادات لمعالجة المستندات الذكية على AWS.
حول المؤلف
 تيم كونديلو هو مهندس حلول متخصص في الذكاء الاصطناعي (AI) والتعلم الآلي (ML) في Amazon Web Services (AWS). ينصب تركيزه على معالجة اللغة الطبيعية ورؤية الكمبيوتر. يستمتع تيم بأخذ أفكار العملاء وتحويلها إلى حلول قابلة للتطوير.
تيم كونديلو هو مهندس حلول متخصص في الذكاء الاصطناعي (AI) والتعلم الآلي (ML) في Amazon Web Services (AWS). ينصب تركيزه على معالجة اللغة الطبيعية ورؤية الكمبيوتر. يستمتع تيم بأخذ أفكار العملاء وتحويلها إلى حلول قابلة للتطوير.
 ديفيد جيرلينج هو أحد كبار مهندسي حلول الذكاء الاصطناعي/تعلم الآلة ويتمتع بخبرة تزيد عن عشرين عامًا في تصميم وقيادة وتطوير أنظمة المؤسسات. يعد David جزءًا من فريق متخصص يركز على مساعدة العملاء على التعلم والابتكار واستخدام هذه الخدمات ذات القدرة العالية مع بياناتهم في حالات الاستخدام الخاصة بهم.
ديفيد جيرلينج هو أحد كبار مهندسي حلول الذكاء الاصطناعي/تعلم الآلة ويتمتع بخبرة تزيد عن عشرين عامًا في تصميم وقيادة وتطوير أنظمة المؤسسات. يعد David جزءًا من فريق متخصص يركز على مساعدة العملاء على التعلم والابتكار واستخدام هذه الخدمات ذات القدرة العالية مع بياناتهم في حالات الاستخدام الخاصة بهم.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/create-a-document-lake-using-large-scale-text-extraction-from-documents-with-amazon-textract/

