المُقدّمة
في عالم الأعمال اليوم، تلعب خدمة رعاية العملاء دورًا مهمًا في ضمان الولاء ورضا العملاء. إن فهم وتحليل المشاعر التي يتم التعبير عنها أثناء التفاعلات يمكن أن يساعد في تحسين جودة خدمة العملاء. يعد تحليل المشاعر بشأن البيانات الصوتية لخدمة العملاء بمثابة أداة قوية لتحقيق هذا الهدف. في هذا الدليل الشامل، سوف نستكشف تعقيدات إجراء تحليل المشاعر على التسجيلات الصوتية لخدمة العملاء، مما يوفر خريطة طريق مفصلة للتنفيذ.

أهداف التعلم
- تعلم كيفية إنشاء تطبيق ويب Flask يستخدم AWS.
- تعلم إجراءات إجراء تحليل المشاعر.
- تعلم الحسابات المستخدمة في تحليل المشاعر.
- فهم كيفية استخراج البيانات المطلوبة والحصول على رؤى من هذا التحليل.
تم نشر هذه المقالة كجزء من مدونة علوم البيانات.
جدول المحتويات
إجراءات إجراء تحليل المشاعر
المرحلة 1: إعداد البيانات
فهم المهمة: لإجراء تحليل المشاعر على صوتيات خدمة العملاء المتاحة وتقديم رؤى من النتائج.
إنشاء تطبيق قارورة: يتم فهم إنشاء تطبيق ويب Flask الذي يستخدم Amazon Web Services (AWS) لإجراء التحليل. هذا التطبيق هو الأساس لمشروعنا.
تحميل التسجيلات الصوتية: يجب تخزين تسجيل المكالمات في قاعدة بيانات مثل حاوية AWS S3 لبدء التحليل.
تطوير واجهة المستخدم: يعد إنشاء واجهة سهلة الاستخدام أمرًا بالغ الأهمية. يتم تحقيق ذلك باستخدام CSS وHTML وJavaScript. تساعد هذه الواجهة المستخدمين على تحديد الأسماء والتواريخ والأوقات.
الحصول على المدخلات: يتم التقاط مدخلات المستخدم مثل الأسماء وتاريخ البدء والوقت وتاريخ الانتهاء والوقت لتخصيص عملية التحليل.
جلب التسجيلات: يتم تقديم إرشادات لجلب التسجيلات من مجموعة S3 خلال الفاصل الزمني المحدد.
النسخ الصوتي: قلب تحليل المشاعر يكمن في النص المكتوب. يستكشف هذا القسم كيفية قيام AWS Transcribe بتحويل الكلمات المنطوقة من التسجيلات المتاحة إلى نص
التحليل.
المرحلة الثانية: تحليل البيانات
إجراء تحليل المشاعر: يعد تحليل النص المكتوب أمرًا مهمًا لهذا الدليل. الخطوة الأولى في هذه المرحلة هي تقسيم كميات كبيرة من النص إلى أجزاء يمكن التحكم فيها. والخطوة التالية هي إجراء تحليل المشاعر على كل قطعة.
حساب مقاييس المشاعر: والخطوة التالية هي استخلاص رؤى ذات معنى. سنقوم بحساب متوسط جميع درجات المشاعر وحساب صافي نقاط الترويج (NPS). يعد NPS مقياسًا مهمًا يحدد ولاء العملاء أو الموظفين. صيغة NPS هي كما يلي:
NPS = ((إجمالي الإيجابيات / إجمالي
السجلات) – (إجمالي السلبيات / إجمالي السجلات)) * 100
إنشاء مخططات الاتجاه: وهذا يساعد على فهم الاتجاهات مع مرور الوقت. سنرشدك لإنشاء مخططات اتجاهات مرئية توضح التقدم المحرز في درجات المشاعر. ستغطي هذه الرسوم البيانية الإيجابية والسلبية،
القيم المختلطة والمحايدة وNPS.
صفحة النتيجة: في الخطوة الأخيرة من تحليلنا، سنقوم بإنشاء صفحة نتائج تعرض نتيجة تحليلنا. ستقدم هذه الصفحة تقريرًا عن مقاييس المشاعر ومخططات الاتجاه والرؤى القابلة للتنفيذ
مستمدة من تفاعلات رعاية العملاء.
الآن دعونا نبدأ تحليل المشاعر، باتباع الإجراء المذكور أعلاه.
استيراد المكتبات الضرورية
في هذا القسم، نقوم باستيراد مكتبات Python الأساسية التي تعتبر أساسية لبناء تطبيق Flask الخاص بنا، والتفاعل مع خدمات AWS، وتنفيذ مهام أخرى متنوعة.
from flask import Flask, render_template, request
import boto3
import json
import time
import urllib.request
import requests
import os
import pymysql
import re
import sys
import uuid
from datetime import datetime
import json
import csv
from io import StringIO
import urllibتحميل التسجيلات الصوتية
قبل البدء في تحليل تسجيل المكالمات، يجب أن يكون الوصول إلى التسجيلات سهلاً. يساعد تخزين التسجيلات في مواقع مثل حاوية AWS S3 في سهولة استرجاعها. في هذه الدراسة قمنا بتحميل
تسجيلات الموظفين والعملاء كتسجيلات منفصلة في مجلد واحد.
إنشاء واجهة المستخدم
باستخدام CSS وHTML وJavaScript، يتم إنشاء واجهة مستخدم جذابة بصريًا لهذا التطبيق. يساعد هذا المستخدم على تحديد المدخلات مثل الأسماء والتواريخ من الأدوات المتوفرة.

الحصول على المدخلات
نحن نستخدم تطبيق Flask الخاص بنا للحصول على معلومات من المستخدم. للقيام بذلك، نستخدم طريقة POST لجمع التفاصيل مثل أسماء الموظفين ونطاقات التاريخ. يمكننا بعد ذلك تحليل مشاعر كل من الموظف والعميل. في العرض التوضيحي الخاص بنا، نستخدم تسجيلات مكالمات الموظف للتحليل. يمكننا أيضًا استخدام تسجيلات مكالمات العملاء الذين يتفاعلون مع الموظف بدلاً من مكالمات الموظف.
يمكننا استخدام الكود التالي لهذا الغرض.
@app.route('/fetch_data', methods=['POST'])
def fetch_data(): name = request.form.get('name') begin_date = request.form.get('begin_date') begin_time = request.form.get('begin_time') begin_datetime_str = f"{begin_date}T{begin_time}.000Z" print('Begin time:',begin_datetime_str) end_date = request.form.get('end_date') end_time = request.form.get('end_time') end_datetime_str = f"{end_date}T{end_time}.000Z"جلب التسجيلات
لبدء تحليلنا، نحتاج إلى الحصول على التسجيلات الصوتية من موقعها المخزن. سواء كانت موجودة في مجموعة AWS S3 أو أي قاعدة بيانات أخرى، يتعين علينا اتباع خطوات معينة للحصول على هذه التسجيلات، خاصة لفترة زمنية محددة. يجب أن نتأكد من توفير المجلدات الصحيحة التي تحتوي على تسجيلات الموظفين أو العملاء.
يوضح هذا المثال كيفية الحصول على التسجيلات من حاوية S3.
# Initialize the S3 client
s3 = boto3.client('s3') # Specify the S3 bucket name and the prefix (directory) where your recordings are stored
bucket_name = 'your-s3-bucket-name'
prefix = 'recordings/' try: response = s3.list_objects_v2(Bucket=bucket_name, Prefix=prefix) # Iterate through the objects and fetch them for obj in response.get('Contents', []): # Get the key (object path) key = obj['Key'] # Download the object to a local file local_filename = key.split('/')[-1] s3.download_file(bucket_name, key, local_filename) print(f"Downloaded {key} to {local_filename}")
except Exception as e: print(f"An error occurred: {e}")النسخ الصوتي
يعد تحويل الكلمات المنطوقة من الصوت إلى نص أمرًا صعبًا. نحن نستخدم أداة سهلة الاستخدام تسمى Amazon Web Services (AWS) Transcribe للقيام بهذه المهمة تلقائيًا. ولكن قبل ذلك، نقوم بتنظيف البيانات الصوتية عن طريق إزالة الأجزاء التي لا يتحدث فيها أحد وتغيير المحادثات في اللغات الأخرى إلى الإنجليزية. أيضًا، إذا كان هناك عدة أشخاص يتحدثون في التسجيل، فنحن بحاجة إلى فصل أصواتهم والتركيز فقط على الصوت الذي نريد تحليله.
ومع ذلك، لكي يعمل جزء الترجمة، نحتاج إلى تسجيلاتنا الصوتية بتنسيق يمكن الوصول إليه من خلال رابط ويب. سيظهر الكود والشرح أدناه
لك كيف يعمل كل هذا.
رمز التنفيذ:
transcribe = boto3.client('transcribe', region_name=AWS_REGION_NAME)
def transcribe_audio(audio_uri): job_name_suffix = str(uuid.uuid4()) # Generate a unique job name using timestamp timestamp = str(int(time.time())) transcription_job_name = f'Transcription_{timestamp}_{job_name_suffix}' settings = { 'ShowSpeakerLabels': True, 'MaxSpeakerLabels': 2 } response = transcribe.start_transcription_job( TranscriptionJobName=transcription_job_name, LanguageCode='en-US', Media={'MediaFileUri': audio_uri}, Settings=settings ) transcription_job_name = response['TranscriptionJob']['TranscriptionJobName'] # Wait for the transcription job to complete while True: response = transcribe.get_transcription_job( TranscriptionJobName=transcription_job_name) status = response['TranscriptionJob']['TranscriptionJobStatus'] if status in ['COMPLETED', 'FAILED']: break print("Transcription in progress...") time.sleep(5) transcript_text = None if status == 'COMPLETED': transcript_uri = response['TranscriptionJob']['Transcript']['TranscriptFileUri'] with urllib.request.urlopen(transcript_uri) as url: transcript_json = json.loads(url.read().decode()) transcript_text = transcript_json['results']['transcripts'][0]['transcript'] print("Transcription completed successfully!") print('Transribed Text is:', transcript_text) else: print("Transcription job failed.") # Check if there are any transcripts (if empty, skip sentiment analysis) if not transcript_text: print("Transcript is empty. Skipping sentiment analysis.") return None return transcript_text
التفسير:
تهيئة الوظيفة: حدد اسمًا فريدًا ورمز لغة (في هذه الحالة، "en-US" للغة الإنجليزية) لبدء مهمة AWS Transcribe.
إعدادات النسخ: نحن نحدد إعدادات مهمة النسخ، بما في ذلك خيارات لإظهار تسميات السماعات وتحديد الحد الأقصى لعدد تسميات السماعات (مفيد للصوت متعدد السماعات).
بدء النسخ: ستبدأ المهمة باستخدام طريقة start_transcription_job. يقوم بنسخ الصوت المقدم بشكل غير متزامن.
مراقبة التقدم الوظيفي: نحن نتحقق بشكل دوري من حالة مهمة النسخ. يمكن أن تكون قيد التقدم، أو مكتملة، أو فاشلة. نتوقف وننتظر الانتهاء قبل المتابعة.
الوصول إلى نص النسخ: بمجرد اكتمال المهمة بنجاح، يمكننا الوصول إلى النص المكتوب من URI النصي المقدم. وهذا النص متاح بعد ذلك لتحليل المشاعر.
إجراء تحليل المشاعر
يعد تحليل المشاعر أمرًا مهمًا في عملنا التحليلي. الأمر كله يتعلق بفهم المشاعر والسياق في النص المكتوب الذي يأتي من تحويل الصوت إلى كلمات. للتعامل مع الكثير من النص، نقوم بتقسيمه إلى أجزاء أصغر. بعد ذلك، نستخدم أداة تسمى AWS Comprehend، وهي أداة رائعة في معرفة ما إذا كان النص يبدو إيجابيًا أم سلبيًا أم محايدًا، أو إذا كان مزيجًا من هذه المشاعر.
رمز التنفيذ:
def split_text(text, max_length): # Split the text into chunks of maximum length chunks = [] start = 0 while start < len(text): end = start + max_length chunks.append(text[start:end]) start = end return chunks def perform_sentiment_analysis(transcript): transcript = str(transcript) # Define the maximum length for each chunk max_chunk_length = 5000 # Split the long text into smaller chunks text_chunks = split_text(transcript, max_chunk_length) # Perform sentiment analysis using AWS Comprehend comprehend = boto3.client('comprehend', region_name=AWS_REGION_NAME) sentiment_results = [] confidence_scores = [] # Perform sentiment analysis on each chunk for chunk in text_chunks: response = comprehend.detect_sentiment(Text=chunk, LanguageCode='en') sentiment_results.append(response['Sentiment']) confidence_scores.append(response['SentimentScore']) sentiment_counts = { 'POSITIVE': 0, 'NEGATIVE': 0, 'NEUTRAL': 0, 'MIXED': 0 } # Iterate over sentiment results for each chunk for sentiment in sentiment_results: sentiment_counts[sentiment] += 1 # Determine the majority sentiment aws_sentiment = max(sentiment_counts, key=sentiment_counts.get) # Calculate average confidence scores average_neutral_confidence = round( sum(score['Neutral'] for score in confidence_scores) / len(confidence_scores), 4) average_mixed_confidence = round( sum(score['Mixed'] for score in confidence_scores) / len(confidence_scores), 4) average_positive_confidence = round( sum(score['Positive'] for score in confidence_scores) / len(confidence_scores), 4) average_negative_confidence = round( sum(score['Negative'] for score in confidence_scores) / len(confidence_scores), 4) return { 'aws_sentiment': aws_sentiment, 'average_positive_confidence': average_positive_confidence, 'average_negative_confidence': average_negative_confidence, 'average_neutral_confidence': average_neutral_confidence, 'average_mixed_confidence': average_mixed_confidence }التفسير:
تقسيم النص: للتعامل مع قدر كبير من النص بسهولة أكبر، قمنا بتقسيم النص إلى أجزاء أصغر يمكننا إدارتها بشكل أفضل. وسننظر بعد ذلك في هذه الأجزاء الأصغر واحدًا تلو الآخر.
فهم العواطف: نحن نستخدم AWS Comprehend لمعرفة المشاعر (مثل الإيجابية والسلبية والمحايدة والمختلطة) في كل جزء من هذه الأجزاء الصغيرة. ويخبرنا أيضًا مدى تأكدنا من هذه المشاعر.
الحفاظ على عدد العواطف: نسجل عدد المرات التي تظهر فيها كل عاطفة في كل هذه الأجزاء الصغيرة. وهذا يساعدنا على معرفة ما يشعر به معظم الناس بشكل عام.
إيجاد الثقة: نحن نحسب متوسط الدرجات لمدى تأكد AWS Comprehend من المشاعر التي يجدها. وهذا يساعدنا على معرفة مدى ثقة النظام في نتائجه.
حساب مقاييس المشاعر
بعد إجراء تحليل المشاعر على أجزاء فردية من النص، ننتقل إلى حساب مقاييس المشاعر ذات المعنى. توفر هذه المقاييس رؤى حول المشاعر العامة وتصورات العملاء أو الموظفين.
رمز التنفيذ:
result = perform_sentiment_analysis(transcript)
def sentiment_metrics(result): # Initialize variables to store cumulative scores total_sentiment_value = '' total_positive_score = 0 total_negative_score = 0 total_neutral_score = 0 total_mixed_score = 0 # Counters for each sentiment category count_positive = 0 count_negative = 0 count_neutral = 0 count_mixed = 0 # Process the fetched data and calculate metrics for record in result: sentiment_value = aws_sentiment positive_score = average_positive_confidence negative_score = average_negative_confidence neutral_score = average_neutral_confidence mixed_score = average_mixed_confidence # Count occurrences of each sentiment category if sentiment_value == 'POSITIVE': count_positive += 1 elif sentiment_value == 'NEGATIVE': count_negative += 1 elif sentiment_value == 'NEUTRAL': count_neutral += 1 elif sentiment_value == 'MIXED': count_mixed += 1 # Calculate cumulative scores total_sentiment_value = max(sentiment_value) total_positive_score += positive_score total_negative_score += negative_score total_neutral_score += neutral_score total_mixed_score += mixed_score # Calculate averages total_records = len(result) overall_sentiment = total_sentiment_value average_positive = total_positive_score / total_records if total_records > 0 else 0 average_negative = total_negative_score / total_records if total_records > 0 else 0 average_neutral = total_neutral_score / total_records if total_records > 0 else 0 average_mixed = total_mixed_score / total_records if total_records > 0 else 0 # Calculate NPS only if there are records if total_records > 0: NPS = ((count_positive/total_records) - (count_negative/total_records)) * 100 NPS_formatted = "{:.2f}%".format(NPS) else: NPS_formatted = "N/A" # Create a dictionary to store the calculated metrics metrics = { "total_records": total_records, "overall_sentiment": overall_sentiment, "average_positive": average_positive, "average_negative": average_negative, "average_neutral": average_neutral, "average_mixed": average_mixed, "count_positive": count_positive, "count_negative": count_negative, "count_neutral": count_neutral, "count_mixed": count_mixed, "NPS": NPS_formatted } return metrics
التفسير:
الدرجات التراكمية: نبدأ بإعداد بعض المتغيرات لتتبع إجمالي الدرجات للمشاعر الإيجابية والسلبية والمحايدة والمختلطة. سيتم إضافة هذه الدرجات أثناء مرورنا بجميع الأجزاء التي تم تحليلها.
عد المشاعر: نحن نستمر في حساب عدد المرات التي يظهر فيها كل نوع من المشاعر، تمامًا كما فعلنا عندما كنا نكتشف المشاعر مسبقًا.
إيجاد المتوسطات: نحن نحسب متوسط درجات المشاعر والمزاج العام بناءً على ما يشعر به معظم الناس. نقوم أيضًا بحساب ما يسمى صافي نقاط الترويج (NPS) باستخدام صيغة خاصة ذكرناها سابقًا.
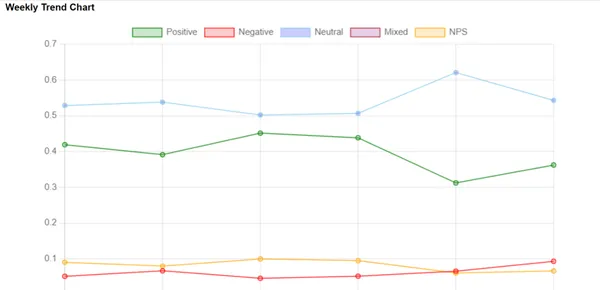
إنشاء مخططات الاتجاه
لنرى كيف تتغير العواطف مع مرور الوقت، نقوم بإنشاء مخططات الاتجاه. إنها مثل الصور التي تمثل بصريًا ما إذا كانت المشاعر تتزايد أم تتناقص. فهي تساعد الشركات على تحديد أي أنماط واستخدام هذه المعلومات لاتخاذ قرارات ذكية بناءً على البيانات.
إجراء:
تجميع البيانات: نقوم بحساب متوسط درجات المشاعر وقيم NPS لكل أسبوع. يتم حفظ هذه القيم بتنسيق القاموس وسيتم استخدامها لإنشاء مخططات الاتجاه.
حساب رقم الأسبوع: لكل تسجيل صوتي، نحدد الأسبوع الذي حدث فيه. وهذا أمر مهم لتنظيم البيانات في الاتجاهات الأسبوعية.
حساب المتوسطات: نقوم بحساب متوسط درجات المشاعر وقيم NPS لكل أسبوع. سيتم استخدام هذه القيم لإنشاء مخططات الاتجاه.
نتيجة تحليل المشاعر
بعد التحليل يمكننا إنشاء صفحة النتائج كما هو موضح أدناه. تقدم هذه الصفحة التقرير الشامل، مثل إجمالي عدد التسجيلات، وإجمالي مدة المكالمة، وما إلى ذلك. كما تعرض أيضًا مخططات تمثل متوسط الدرجات والاتجاهات. يمكننا أيضًا التقاط النتائج السلبية وتفاصيلها بشكل منفصل.
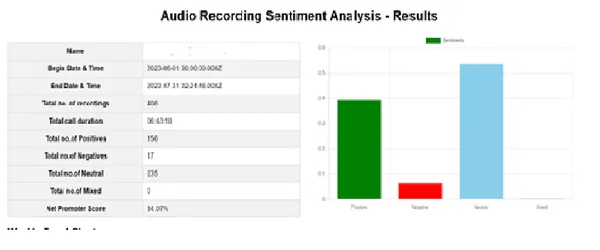
وفي الختام
في عالم الأعمال سريع الخطى اليوم، يعد فهم ما يشعر به العملاء أمرًا بالغ الأهمية. إنه مثل امتلاك أداة سرية لجعل العملاء أكثر سعادة. يساعد تحليل المشاعر لتسجيلات المكالمات الصوتية في الحصول على رؤى حول تفاعلات العملاء. توضح هذه المقالة خطوات إجراء تحليل المشاعر، بدءًا من تحويل الصوت إلى نص وحتى إنشاء مخططات الاتجاه.
أولاً، استخدمنا أدوات مثل AWS Transcribe لمساعدتنا في تحويل الكلمات المنطوقة من هذه النسخ الصوتية إلى نص قابل للقراءة. ثم قام تحليل المشاعر بتقييم العواطف والسياق وتصنيفها إلى مشاعر إيجابية أو سلبية أو محايدة أو مختلطة.
تضمنت مقاييس المشاعر تجميع النتائج وحساب صافي نقاط الترويج (NPS)، والتي يمكن بعد ذلك رسمها على الرسوم البيانية والرسوم البيانية لتحديد المشكلات ومراقبة التقدم وتحسين الولاء.
الوجبات السريعة الرئيسية
- يعد تحليل المشاعر أداة قوية للشركات لفهم التعليقات وإجراء التحسينات وتقديم تجارب العملاء.
- يمكن تصور تغيرات المشاعر بمرور الوقت من خلال مخططات الاتجاه، مما يساعد المؤسسات على اتخاذ قرارات تعتمد على البيانات.
الأسئلة المتكررة
الجواب. يحدد تحليل المشاعر النغمة العاطفية وسياق البيانات النصية باستخدام تقنية البرمجة اللغوية العصبية. في مجال رعاية العملاء، يساعد هذا النوع من التحليل المؤسسات على فهم ما يشعر به العملاء تجاه منتجاتهم أو خدماتهم. إنه أمر بالغ الأهمية لأنه يوفر رؤى قابلة للتنفيذ حول رضا العملاء ويمكّن الشركات من تحسين خدماتها بناءً على تعليقات العملاء. يساعد على معرفة كيفية تفاعل الموظفين مع العملاء.
الجواب. النسخ الصوتي هو عملية تحويل الكلمات المنطوقة في الصوت إلى نص مكتوب. في تحليل المشاعر، هذا هو أول شيء نقوم به. نحن نستخدم أدوات مثل AWS Transcribe لتغيير ما يقوله الأشخاص في المكالمة إلى كلمات يمكن للكمبيوتر فهمها. بعد ذلك، يمكننا أن ننظر إلى الكلمات لنرى كيف يشعر الناس.
الجواب. يتم تصنيف المشاعر عادة إلى أربع فئات رئيسية: الإيجابية والسلبية والمحايدة والمختلطة. تشير كلمة "إيجابي" إلى مشاعر إيجابية أو رضا. "السلبية" تعكس عدم الرضا أو المشاعر السلبية. "المحايد" يعني عدم وجود مشاعر إيجابية وسلبية، و"مختلط" يعني الخلط بين المشاعر الإيجابية والسلبية في النص.
الجواب. NPS هو رقم يخبرنا عن مدى إعجاب الأشخاص بشركة أو خدمة ما. نجده من خلال أخذ نسبة الأشخاص الذين يحبونه (إيجابي) وطرح نسبة الأشخاص الذين لا يحبونه (سلبي). تبدو الصيغة كما يلي: NPS = ((الأشخاص الإيجابيون / إجمالي الأشخاص) – (الأشخاص السلبيون / إجمالي الأشخاص)) * 100. ويعني ارتفاع NPS المزيد من العملاء السعداء.
الجواب. تشبه مخططات الاتجاه الصور التي توضح كيف تتغير مشاعر الأشخاص بمرور الوقت. إنها تساعد الشركات على معرفة ما إذا كان العملاء أصبحوا أكثر سعادة أم حزنًا. يمكن للشركات استخدام مخططات الاتجاه للعثور على الأنماط ومعرفة ما إذا كانت تحسيناتها ناجحة. تساعد مخططات الاتجاه الشركات على اتخاذ خيارات ذكية ويمكنها التحقق من تغييراتها لإسعاد العملاء.
الوسائط الموضحة في هذه المقالة ليست مملوكة لـ Analytics Vidhya ويتم استخدامها وفقًا لتقدير المؤلف.
مقالات ذات صلة
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://www.analyticsvidhya.com/blog/2023/09/decoding-customer-care-sentiments-comprehensive-audio-analysis-guide/

