اليوم، يسعدنا أن نعلن عن توفر دعم Llama 2 للاستدلال والضبط الدقيق تدريب AWS و استدلال AWS حالات في أمازون سيج ميكر جومب ستارت. يمكن أن يساعد استخدام المثيلات المستندة إلى AWS Trainium وInferentia، من خلال SageMaker، المستخدمين على خفض تكاليف الضبط الدقيق بنسبة تصل إلى 50%، وخفض تكاليف النشر بمقدار 4.7 مرات، مع تقليل زمن الاستجابة لكل رمز مميز. Llama 2 هو نموذج لغة نصية توليدية ذات انحدار تلقائي يستخدم بنية محولات محسنة. كنموذج متاح للجمهور، تم تصميم Llama 2 للعديد من مهام البرمجة اللغوية العصبية مثل تصنيف النص، وتحليل المشاعر، وترجمة اللغة، ونمذجة اللغة، وتوليد النص، وأنظمة الحوار. يمكن أن يصبح ضبط ونشر LLMs، مثل Llama 2، مكلفًا أو صعبًا لتلبية الأداء في الوقت الفعلي لتقديم تجربة جيدة للعملاء. Trainium وAWS Inferentia، تم تمكينهما بواسطة AWS نيورون توفر مجموعة أدوات تطوير البرامج (SDK) خيارًا عالي الأداء وفعالاً من حيث التكلفة للتدريب والاستدلال على نماذج Llama 2.
في هذا المنشور، نوضح كيفية نشر Llama 2 وضبطها على مثيلات Trainium وAWS Inferentia في SageMaker JumpStart.
حل نظرة عامة
في هذه المدونة، سنستعرض السيناريوهات التالية:
- انشر Llama 2 على مثيلات AWS Inferentia في كل من أمازون ساجميكر ستوديو واجهة مستخدم، مع تجربة نشر بنقرة واحدة، وSageMaker Python SDK.
- قم بضبط Llama 2 على مثيلات Trainium في كل من واجهة مستخدم SageMaker Studio وSageMaker Python SDK.
- قارن أداء نموذج Llama 2 المضبوط بدقة مع أداء النموذج المدرّب مسبقًا لإظهار فعالية الضبط الدقيق.
للحصول على الأيدي، راجع مثال على دفتر ملاحظات GitHub.
انشر Llama 2 على مثيلات AWS Inferentia باستخدام SageMaker Studio UI وPython SDK
في هذا القسم، نوضح كيفية نشر Llama 2 على مثيلات AWS Inferentia باستخدام واجهة مستخدم SageMaker Studio للنشر بنقرة واحدة وPython SDK.
اكتشف نموذج Llama 2 على واجهة مستخدم SageMaker Studio
يوفر SageMaker JumpStart إمكانية الوصول إلى كل من الوصول العام والمملوك نماذج الأساس. يتم إعداد النماذج الأساسية وصيانتها من موفري خدمات تابعين لجهات خارجية ومملوكين. وعلى هذا النحو، يتم إصدارها بموجب تراخيص مختلفة كما هو محدد بواسطة مصدر النموذج. تأكد من مراجعة الترخيص لأي نموذج أساسي تستخدمه. أنت مسؤول عن مراجعة أي شروط ترخيص معمول بها والامتثال لها والتأكد من أنها مقبولة لحالة الاستخدام الخاصة بك قبل تنزيل المحتوى أو استخدامه.
يمكنك الوصول إلى نماذج Llama 2 الأساسية من خلال SageMaker JumpStart في SageMaker Studio UI وSageMaker Python SDK. في هذا القسم، سنتعرف على كيفية اكتشاف النماذج في SageMaker Studio.
SageMaker Studio عبارة عن بيئة تطوير متكاملة (IDE) توفر واجهة مرئية واحدة قائمة على الويب حيث يمكنك الوصول إلى الأدوات المصممة خصيصًا لتنفيذ جميع خطوات تطوير التعلم الآلي (ML)، بدءًا من إعداد البيانات وحتى إنشاء تعلم الآلة الخاص بك وتدريبه ونشره. عارضات ازياء. لمزيد من التفاصيل حول كيفية البدء وإعداد SageMaker Studio، راجع ستوديو أمازون سيج ميكر.
بعد دخولك إلى SageMaker Studio، يمكنك الوصول إلى SageMaker JumpStart، الذي يحتوي على نماذج ودفاتر ملاحظات وحلول تم إنشاؤها مسبقًا، ضمن حلول آلية ومبنية مسبقًا. للحصول على معلومات أكثر تفصيلاً حول كيفية الوصول إلى النماذج الخاصة، راجع استخدم نماذج الأساس الخاصة من Amazon SageMaker JumpStart في Amazon SageMaker Studio.

من الصفحة المقصودة لـ SageMaker JumpStart، يمكنك استعراض الحلول والنماذج ودفاتر الملاحظات والموارد الأخرى.
إذا كنت لا ترى نماذج Llama 2، فقم بتحديث إصدار SageMaker Studio الخاص بك عن طريق إيقاف التشغيل وإعادة التشغيل. لمزيد من المعلومات حول تحديثات الإصدار، راجع قم بإيقاف تشغيل تطبيقات Studio Classic وتحديثها.
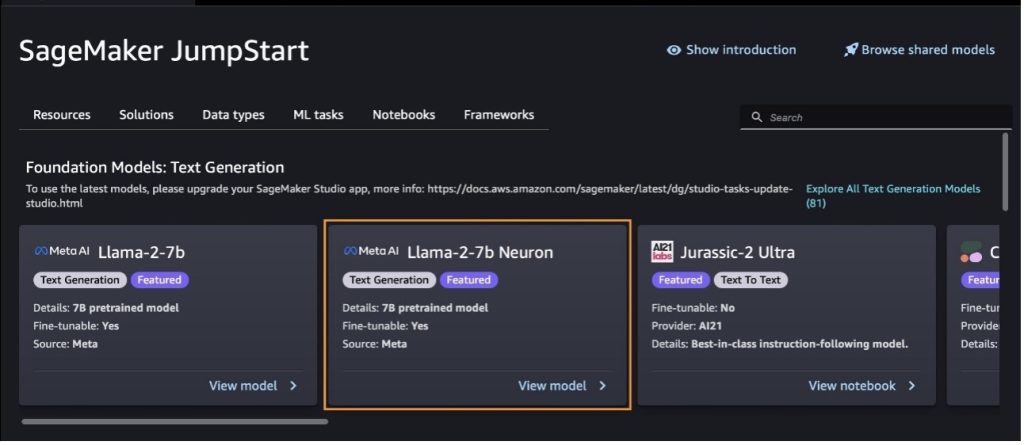
يمكنك أيضًا العثور على متغيرات الطراز الأخرى عن طريق الاختيار استكشف جميع نماذج إنشاء النص أو البحث عن llama or neuron في مربع البحث. ستتمكن من عرض نماذج Llama 2 Neuron على هذه الصفحة.

انشر نموذج Llama-2-13b باستخدام SageMaker Jumpstart
يمكنك اختيار بطاقة النموذج لعرض تفاصيل حول النموذج مثل الترخيص والبيانات المستخدمة للتدريب وكيفية استخدامه. يمكنك أيضًا العثور على زرين، نشر و افتح دفتر الملاحظات، والتي تساعدك على استخدام النموذج باستخدام هذا المثال بدون تعليمات برمجية.
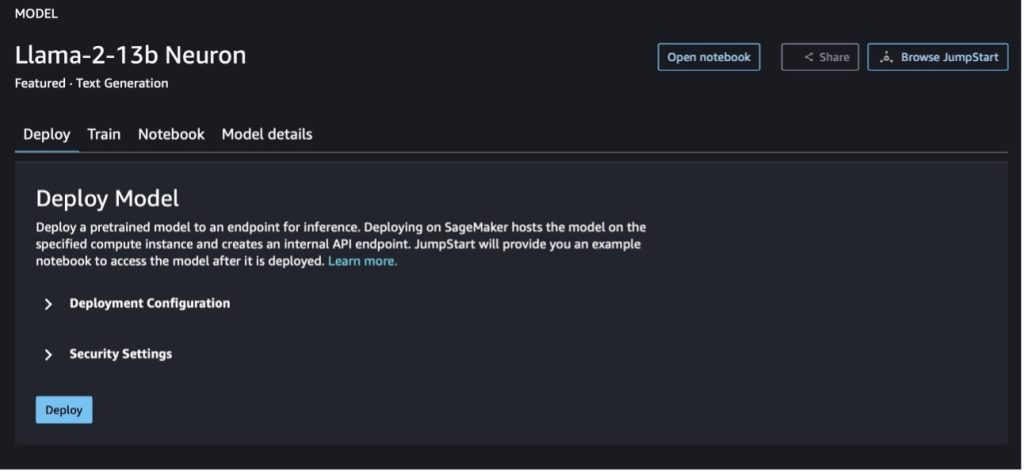
عند اختيار أي من الزرين، ستظهر لك نافذة منبثقة اتفاقية ترخيص المستخدم النهائي وسياسة الاستخدام المقبول (AUP) لتقر بها.
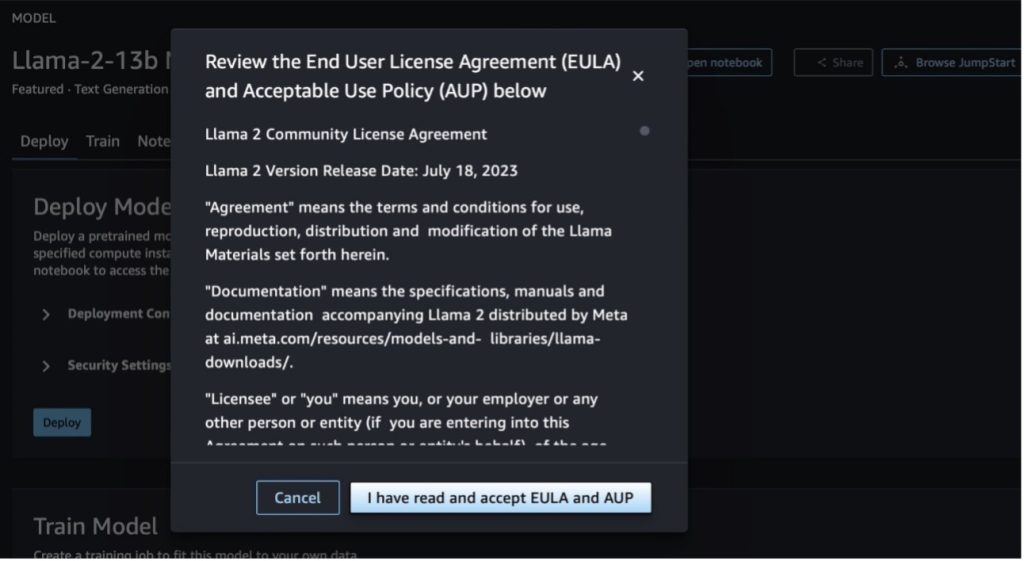
بعد إقرارك بالسياسات، يمكنك نشر نقطة نهاية النموذج واستخدامها عبر الخطوات الواردة في القسم التالي.
انشر نموذج Llama 2 Neuron عبر Python SDK
عندما تختار نشر والموافقة على الشروط، سيبدأ نشر النموذج. وبدلاً من ذلك، يمكنك النشر من خلال مثال دفتر الملاحظات عن طريق الاختيار افتح دفتر الملاحظات. يوفر نموذج دفتر الملاحظات إرشادات شاملة حول كيفية نشر النموذج لموارد الاستدلال والتنظيف.
لنشر نموذج أو تحسينه على مثيلات Trainium أو AWS Inferentia، يتعين عليك أولاً الاتصال بـ PyTorch Neuron (الشعلة العصبية) لتجميع النموذج في رسم بياني خاص بالخلايا العصبية، مما سيؤدي إلى تحسينه لـ NeuronCores الخاصة بـ Inferentia. يمكن للمستخدمين توجيه المترجم لتحسين زمن الاستجابة الأقل أو أعلى إنتاجية، اعتمادًا على أهداف التطبيق. في JumpStart، قمنا بتجميع الرسوم البيانية العصبية مسبقًا لمجموعة متنوعة من التكوينات، للسماح للمستخدمين باستكمال خطوات التجميع، مما يتيح ضبط النماذج ونشرها بشكل أسرع.
لاحظ أنه يتم إنشاء الرسم البياني المترجم مسبقًا لـ Neuron بناءً على إصدار محدد من إصدار Neuron Compiler.
هناك طريقتان لنشر LIama 2 على المثيلات المستندة إلى AWS Inferentia. تستخدم الطريقة الأولى التكوين المبني مسبقًا، وتسمح لك بنشر النموذج في سطرين فقط من التعليمات البرمجية. وفي الحالة الثانية، لديك سيطرة أكبر على التكوين. لنبدأ بالطريقة الأولى، بالتكوين المبني مسبقًا، ونستخدم نموذج Llama 2 13B Neuron المدرب مسبقًا، كمثال. يوضح الكود التالي كيفية نشر Llama 13B بسطرين فقط:
لإجراء الاستدلال على هذه النماذج، تحتاج إلى تحديد الوسيطة accept_eula أن تكون True كجزء من model.deploy() يتصل. تعيين هذه الوسيطة لتكون صحيحة، يعني أنك قرأت ووافقت على اتفاقية ترخيص المستخدم النهائي للنموذج. يمكن العثور على اتفاقية ترخيص المستخدم النهائي (EULA) في وصف بطاقة النموذج أو من موقع ميتا.
نوع المثيل الافتراضي لـ Llama 2 13B هو ml.inf2.8xlarge. يمكنك أيضًا تجربة معرفات النماذج المدعومة الأخرى:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(نموذج الدردشة)meta-textgenerationneuron-llama-2-13b-f(نموذج الدردشة)
وبدلاً من ذلك، إذا كنت تريد المزيد من التحكم في تكوينات النشر، مثل طول السياق ودرجة توازي الموتر والحد الأقصى لحجم الدفعة المتداول، فيمكنك تعديلها عبر المتغيرات البيئية، كما هو موضح في هذا القسم. حاوية التعلم العميق (DLC) الأساسية للنشر هي استدلال النموذج الكبير (LMI) NeuronX DLC. المتغيرات البيئية هي كما يلي:
- OPTION_N_POSITIONS - الحد الأقصى لعدد رموز الإدخال والإخراج. على سبيل المثال، إذا قمت بتجميع النموذج باستخدام
OPTION_N_POSITIONSمثل 512، يمكنك استخدام رمز إدخال يبلغ 128 (حجم موجه الإدخال) بحد أقصى لرمز الإخراج يبلغ 384 (يجب أن يكون إجمالي رموز الإدخال والإخراج 512). بالنسبة إلى الحد الأقصى لرمز الإخراج، فإن أي قيمة أقل من 384 تكون جيدة، ولكن لا يمكنك تجاوزها (على سبيل المثال، الإدخال 256 والإخراج 512). - OPTION_TENSOR_PARALLEL_DEGREE – عدد NeuronCores لتحميل النموذج في مثيلات AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – الحد الأقصى لحجم الدفعة للطلبات المتزامنة.
- OPTION_DTYPE – نوع التاريخ لتحميل النموذج.
يعتمد تجميع الرسم البياني للخلايا العصبية على طول السياق (OPTION_N_POSITIONS) ، درجة متوازية الموتر (OPTION_TENSOR_PARALLEL_DEGREE)، الحد الأقصى لحجم الدفعة (OPTION_MAX_ROLLING_BATCH_SIZE) ونوع البيانات (OPTION_DTYPE) لتحميل النموذج. يحتوي SageMaker JumpStart على رسوم بيانية عصبية مجمعة مسبقًا لمجموعة متنوعة من التكوينات للمعلمات السابقة لتجنب التجميع في وقت التشغيل. يتم سرد تكوينات الرسوم البيانية المترجمة مسبقًا في الجدول التالي. طالما أن المتغيرات البيئية تقع ضمن إحدى الفئات التالية، فسيتم تخطي تجميع الرسوم البيانية العصبية.
| LIama-2 7B وLIama-2 7B Chat | ||||
| نوع الطلب | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B وLIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
فيما يلي مثال لنشر Llama 2 13B وتعيين كافة التكوينات المتاحة.
الآن بعد أن قمنا بنشر نموذج Llama-2-13b، يمكننا تشغيل الاستدلال به عن طريق استدعاء نقطة النهاية. يوضح مقتطف التعليمات البرمجية التالي استخدام معلمات الاستدلال المدعومة للتحكم في إنشاء النص:
- الحد الاقصى للطول - يولد النموذج نصًا حتى يصل طول الإخراج (الذي يتضمن طول سياق الإدخال)
max_length. إذا تم تحديده ، يجب أن يكون عددًا صحيحًا موجبًا. - max_new_tokens - يقوم النموذج بإنشاء نص حتى يصل طول الإخراج (باستثناء طول سياق الإدخال).
max_new_tokens. إذا تم تحديده ، يجب أن يكون عددًا صحيحًا موجبًا. - عدد_الكتف – يشير هذا إلى عدد الحزم المستخدمة في البحث الجشع. إذا تم تحديده، فيجب أن يكون عددًا صحيحًا أكبر من أو يساوي
num_return_sequences. - no_repeat_ngram_size - يضمن النموذج تسلسل كلمات
no_repeat_ngram_sizeلا يتكرر في تسلسل الإخراج. إذا تم تحديده ، يجب أن يكون عددًا صحيحًا موجبًا أكبر من 1. - درجة الحرارة - هذا يتحكم في العشوائية في الإخراج. تؤدي درجة الحرارة المرتفعة إلى تسلسل إخراج بكلمات ذات احتمالية منخفضة؛ وينتج عن انخفاض درجة الحرارة تسلسل إخراج بكلمات ذات احتمالية عالية. لو
temperatureيساوي 0 ، ينتج عنه فك تشفير جشع. إذا تم تحديده ، يجب أن يكون عددًا عائمًا موجبًا. - في وقت مبكر - إذا
True، يتم الانتهاء من إنشاء النص عندما تصل جميع فرضيات الشعاع إلى نهاية الجملة المميزة. إذا تم تحديده، فيجب أن يكون منطقيًا. - do_sample - إذا
True، يقوم النموذج باختبار الكلمة التالية حسب الاحتمالية. إذا تم تحديده، فيجب أن يكون منطقيًا. - top_k - في كل خطوة من خطوات إنشاء النص، يتم أخذ عينات النموذج من الملف فقط
top_kعلى الأرجح الكلمات. إذا تم تحديده ، يجب أن يكون عددًا صحيحًا موجبًا. - top_p - في كل خطوة من خطوات إنشاء النص، يأخذ النموذج عينات من أصغر مجموعة ممكنة من الكلمات مع احتمال تراكمي قدره
top_p. إذا تم تحديده ، يجب أن يكون عددًا عشريًا بين 0-1. - توقف - إذا تم تحديدها، يجب أن تكون قائمة من السلاسل. يتوقف إنشاء النص في حالة إنشاء أي من السلاسل المحددة.
يظهر الكود التالي مثالا:
الناتج:
لمزيد من المعلومات حول المعلمات في الحمولة، راجع معايير مفصلة.
يمكنك أيضًا استكشاف تنفيذ المعلمات في ملف مفكرة لإضافة المزيد من المعلومات حول رابط الدفتر.
ضبط نماذج Llama 2 على مثيلات Trainium باستخدام SageMaker Studio UI وSageMaker Python SDK
أصبحت النماذج التأسيسية للذكاء الاصطناعي التوليدي محورًا أساسيًا في تعلم الآلة والذكاء الاصطناعي، ومع ذلك، فإن تعميمها الواسع يمكن أن يكون قصيرًا في مجالات محددة مثل الرعاية الصحية أو الخدمات المالية، حيث تتضمن مجموعات البيانات الفريدة. يسلط هذا القيد الضوء على الحاجة إلى ضبط نماذج الذكاء الاصطناعي التوليدية هذه باستخدام بيانات خاصة بالمجال لتعزيز أدائها في هذه المجالات المتخصصة.
الآن بعد أن قمنا بنشر الإصدار المُدرب مسبقًا من نموذج Llama 2، فلننظر إلى كيفية ضبط هذا ليتوافق مع البيانات الخاصة بالمجال لزيادة الدقة، وتحسين النموذج من حيث الإكمال الفوري، وتكييف النموذج ليناسب حالة استخدام عملك المحدد والبيانات. يمكنك ضبط النماذج باستخدام SageMaker Studio UI أو SageMaker Python SDK. نناقش كلتا الطريقتين في هذا القسم.
قم بضبط نموذج Llama-2-13b Neuron باستخدام SageMaker Studio
في SageMaker Studio، انتقل إلى نموذج Llama-2-13b Neuron. على ال نشر علامة التبويب، يمكنك الإشارة إلى خدمة تخزين أمازون البسيطة مجموعة (Amazon S3) تحتوي على مجموعات بيانات التدريب والتحقق من الصحة من أجل الضبط الدقيق. بالإضافة إلى ذلك، يمكنك تكوين تكوين النشر والمعلمات الفائقة وإعدادات الأمان للضبط الدقيق. ثم اختر قطار لبدء مهمة التدريب على مثيل SageMaker ML.
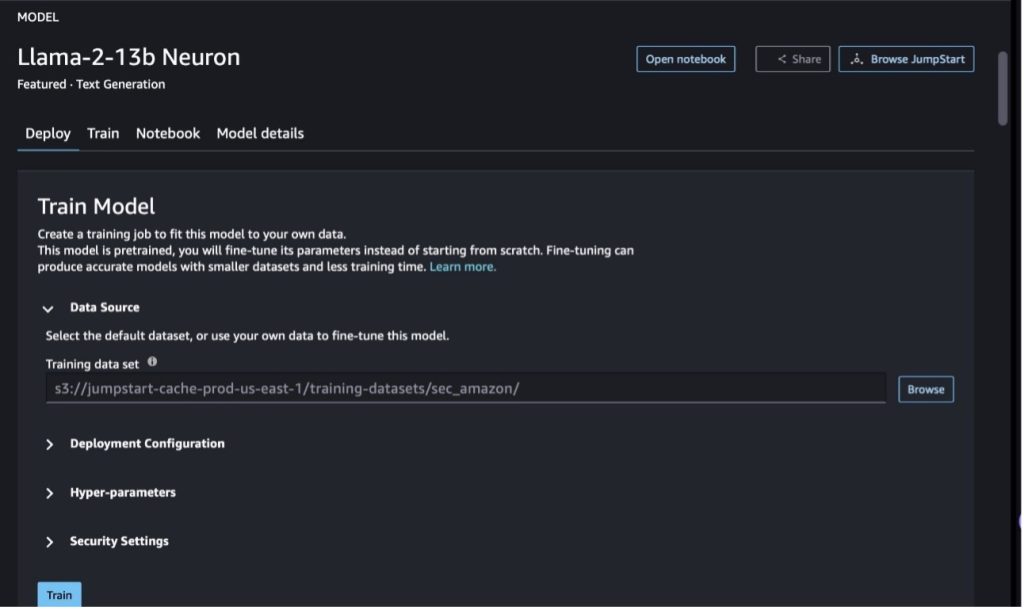
لاستخدام نماذج Llama 2، يتعين عليك قبول اتفاقية ترخيص المستخدم النهائي (EULA) وسياسة الاستخدام المقبول (AUP). وسوف تظهر عندما تختار قطار. أختر لقد قرأت وقبلت اتفاقية ترخيص المستخدم النهائي (EULA) وسياسة الاستخدام المقبول (AUP). لبدء مهمة الضبط الدقيق.
يمكنك عرض حالة مهمة التدريب الخاصة بك للنموذج الذي تم ضبطه بدقة ضمن وحدة تحكم SageMaker عن طريق الاختيار وظائف التدريب في جزء التنقل.
يمكنك إما ضبط نموذج Llama 2 Neuron الخاص بك باستخدام هذا المثال الذي لا يحتوي على تعليمات برمجية، أو الضبط الدقيق عبر Python SDK، كما هو موضح في القسم التالي.
قم بضبط نموذج Llama-2-13b Neuron عبر SageMaker Python SDK
يمكنك ضبط مجموعة البيانات باستخدام تنسيق تكييف المجال أو الضبط الدقيق القائم على التعليمات شكل. فيما يلي الإرشادات الخاصة بكيفية تنسيق بيانات التدريب قبل إرسالها للضبط الدقيق:
- إدخال - A
trainالدليل الذي يحتوي إما على ملف بتنسيق خطوط JSON (.jsonl) أو نص (.txt).- بالنسبة لملف خطوط JSON (.jsonl)، يكون كل سطر عبارة عن كائن JSON منفصل. يجب أن يتم تنظيم كل كائن JSON كزوج من القيمة الرئيسية، حيث يجب أن يكون المفتاح
textوالقيمة هي محتوى مثال تدريبي واحد. - يجب أن يساوي عدد الملفات الموجودة ضمن دليل القطار 1.
- بالنسبة لملف خطوط JSON (.jsonl)، يكون كل سطر عبارة عن كائن JSON منفصل. يجب أن يتم تنظيم كل كائن JSON كزوج من القيمة الرئيسية، حيث يجب أن يكون المفتاح
- الناتج – نموذج مدرب يمكن نشره للاستدلال.
في هذا المثال، نستخدم مجموعة فرعية من مجموعة بيانات دوللي في تنسيق ضبط التعليمات. تحتوي مجموعة بيانات Dolly على ما يقرب من 15,000 سجل لمتابعة التعليمات لفئات مختلفة، مثل الإجابة على الأسئلة والتلخيص واستخراج المعلومات. وهي متاحة بموجب ترخيص Apache 2.0. نحن نستخدم ال information_extraction أمثلة للضبط الدقيق.
- قم بتحميل مجموعة بيانات دوللي وتقسيمها إلى
train(للضبط الدقيق) وtest(للتقييم):
- استخدم قالبًا سريعًا للمعالجة المسبقة للبيانات بتنسيق تعليمات لمهمة التدريب:
- افحص المعلمات الفائقة واستبدلها بحالة الاستخدام الخاصة بك:
- قم بضبط النموذج وبدء مهمة تدريب SageMaker. تعتمد البرامج النصية للضبط الدقيق على نيورونكس-نيمو-ميجاترون repository، وهي إصدارات معدلة من الحزم نيمو و قمة التي تم تكييفها للاستخدام مع مثيلات Neuron وEC2 Trn1. ال نيورونكس-نيمو-ميجاترون يحتوي المستودع على توازي ثلاثي الأبعاد (البيانات والموتر وخطوط الأنابيب) للسماح لك بضبط LLMs على نطاق واسع. مثيلات Trainium المدعومة هي ml.trn3xlarge وml.trn1.32n.1xlarge.
- وأخيرًا، انشر النموذج المضبوط في نقطة نهاية SageMaker:
قارن الاستجابات بين نماذج Llama 2 Neuron المدربة مسبقًا والمضبوطة بدقة
الآن بعد أن قمنا بنشر الإصدار المدرب مسبقًا من نموذج Llama-2-13b وقمنا بضبطه بشكل دقيق، يمكننا عرض بعض مقارنات الأداء للإكمالات الفورية من كلا النموذجين، كما هو موضح في الجدول التالي. نقدم أيضًا مثالاً لضبط Llama 2 على مجموعة بيانات ملفات SEC بتنسيق .txt. للحصول على التفاصيل، راجع مثال على دفتر ملاحظات GitHub.
| العناصر | المدخلات | الحقيقة الأرضية | الاستجابة من نموذج غير دقيق | الاستجابة من النموذج الدقيق |
| 1 | يوجد أدناه تعليمات تصف مهمة، مقترنة بإدخال يوفر سياقًا إضافيًا. اكتب إجابة تكمل الطلب بشكل مناسب.nn### التعليمات:استخرج الجامعات التي درس فيها موريت وسنة تخرجه لكل منها، ثم ضعها في قائمة ذات تعداد نقطي.nn### الإدخال:n ولد موريت عام 1953 في فيفي بسويسرا وأكمل دراساته الجامعية في مدرسة البوليتكنيك الفيدرالية في لوزان (EPFL)، وتخرج منها عام 1975. وتابع دراساته العليا في جامعة تينيسي، وحصل على درجة الدكتوراه. في عام 1980. ثم انضم إلى هيئة التدريس في جامعة نيو مكسيكو، حيث بقي حتى عام 2006، عندما انتقل إلى EPFL. تقاعد من EPFL في ديسمبر 2016. اللجنة التوجيهية للمؤتمر. في عام 1996، تم انتخاب موريت كزميل في الجمعية الدولية للبيولوجيا الحاسوبية، لمساهماته البارزة في مجالات البيولوجيا الحاسوبية والمعلوماتية الحيوية.nn### Response:n | * المدرسة الفيدرالية للفنون التطبيقية في لوزان (EPFL) (تخرجت عام 1975)* جامعة تينيسي (تخرجت عام 1980) | درس موريه في كلية الفنون التطبيقية الفيدرالية في لوزان (EPFL) وجامعة تينيسي، وتخرج في عامي 1975 و1980، على التوالي.nn### تلميح:nn- استخدم وظيفة "تقسيم" لتقسيم المدخلات إلى قائمة من الجمل.n- استخدم وظيفة "التقسيم" لتقسيم كل جملة إلى قائمة من الكلمات. - استخدم وظيفة "التقسيم" للتقسيم | - مدرسة البوليتكنيك الفيدرالية في لوزان (EPFL)، 1975 ن - جامعة تينيسي، 1980 ن - جامعة نيو مكسيكو - مدرسة البوليتكنيك الفيدرالية في لوزان (EPFL)، 2006 ن فيما يلي تعليمات تصف مهمة، مقترنة بمدخل يوفر المزيد من السياق. اكتب ردًا يكمل الطلب بشكل مناسب |
| 2 | يوجد أدناه تعليمات تصف مهمة، مقترنة بإدخال يوفر سياقًا إضافيًا. اكتب إجابة تكمل الطلب بشكل مناسب.nn### التعليمات:من المقطع حدد سمات ديونيسوس. عرض النتائج بتنسيق مفصول بفاصلة.nn### الإدخال:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnإله الخمر، والإثمار، والحفلات، والمهرجانات، والجنون، والفوضى، والسكر، والنباتات، والنشوة، مسرح. وهو ابن زيوس وسيميلي الذي ولد مرتين، حيث انتزعه زيوس من بطن أمه وخياط ديونيسوس في فخذه وحمله حتى أصبح جاهزًا للولادة. في الفن، تم تصويره إما على أنه إله ملتحٍ أكبر سنًا (خاصة قبل 430 قبل الميلاد) أو شابًا مخنثًا طويل الشعر (خاصة بعد 430 قبل الميلاد). وتشمل صفاته الثيرسوس، وكأس الشرب، وكرمة العنب، وتاج اللبلاب. غالبًا ما يكون بصحبة ثياسوس، وهم مجموعة من الحاضرين بما في ذلك الساتير والميناد ومعلمه القديم سيلينوس. وكانت زوجة ديونيسوس أريادن. كان يُعتقد ذات مرة أن ديونيسيوس كان إضافة لاحقة إلى البانثيون اليوناني، لكن اكتشاف الألواح الخطية B يؤكد مكانته كإله منذ فترة مبكرة. وكان باخوس اسمًا آخر له باللغة اليونانية، وقد أصبح شائع الاستخدام بين الرومان. وتشمل حيواناته المقدسة الدلافين والثعابين والنمور والحمير.nn### Response:n | والعقص كأس الشرب والكرمة وإكليل اللبلاب | ديونيسوس (Διόνυσος، Diónusos) إله الخمر، والإثمار، والحفلات، والمهرجانات، والجنون، والفوضى، والسكر، والنباتات، والنشوة، والمسرح. وهو ابن زيوس وسيميلي الذي ولد مرتين، حيث انتزعه زيوس من بطن أمه وخياط ديونيسوس في فخذه. | thyrsus، كوب للشرب، كرمة العنب، تاج ivynn يوجد أدناه تعليمات تصف مهمة، مقترنة بإدخال يوفر سياقًا إضافيًا. اكتب ردًا يكمل الطلب بشكل مناسب.nn### التعليمات:ما الفرق بين الإمبراطورية البارثية والإمبراطورية الأرساسيدية؟nn### الإدخال:nكانت الإمبراطورية البارثية، المعروفة أيضًا باسم الإمبراطورية الأرساسيدية، |
| 3 | يوجد أدناه تعليمات تصف مهمة، مقترنة بإدخال يوفر سياقًا إضافيًا. اكتب إجابة تكمل الطلب بشكل مناسب.nn### التعليمات:لماذا تحتوي عاصمة أوزبكستان على أكبر جالية يونانية؟nn### الإدخال:nيبلغ عدد اليونانيين في أوزبكستان حوالي 9,000 نسمة. يتكون المجتمع من يونانيين من روسيا تم ترحيلهم بالقوة من ذلك البلد إلى أوزبكستان في الأربعينيات، ولاجئين سياسيين من اليونان. عاش حوالي 1940 يوناني في البلاد قبل الحرب العالمية الثانية، ووصل 30,000 آخرين بعد الحرب الأهلية اليونانية وهزيمة الجيش الديمقراطي اليوناني. وقد تضاءلت أعدادهم من 11,000 ألفاً في الستينيات. السبب الرئيسي هو الهجرة إلى اليونان بعد نهاية الحرب الباردة عندما سمحت القوانين بعودة جميع اليونانيين العرقيين الذين تم نفيهم لأسباب سياسية بعد الحرب الأهلية اليونانية. أكبر جالية يونانية في البلاد موجودة في العاصمة طشقند حيث تم نقل معظم اللاجئين السياسيين اليونانيين من قبل السلطات السوفيتية. في العصور القديمة، كان جنوب البلاد جزءًا من المملكة السلوقية الهلنستية، لكن المجتمعات اليونانية القليلة هناك اندمجت منذ ذلك الحين. أهم منظمة تمثل العرق اليوناني هي الجمعية الثقافية اليونانية في طشقند. تشمل أنشطة هذه المنظمة تعليم اللغة اليونانية (40,000 فصلاً بإجمالي 1960 طالبًا، فصول للكبار) وتعليم الرقصات والموسيقى اليونانية.nn### Response:n | تم نقل معظم اللاجئين السياسيين اليونانيين في أوزبكستان من قبل السلطات السوفيتية إلى العاصمة طشقند. | تضم عاصمة أوزبكستان أكبر جالية يونانية، إذ يبلغ عدد اليونانيين في أوزبكستان حوالي 9,000 نسمة. يتكون المجتمع من يونانيين من روسيا تم ترحيلهم بالقوة من ذلك البلد إلى أوزبكستان في الأربعينيات، ولاجئين سياسيين من اليونان. عاش حوالي 1940 يوناني في البلاد قبل الحرب العالمية الثانية و30,000 آخرين | تحتوي عاصمة أوزبكستان على أكبر جالية يونانية لأن هذا هو المكان الذي تم نقل معظم اللاجئين السياسيين اليونانيين من قبل السلطات السوفيتية بعد ترحيلهم من اليونان.nn فيما يلي تعليمات تصف مهمة، مقترنة بمدخلات توفر مزيد من السياق. اكتب ردًا يكمل الطلب بشكل مناسب.nn### التعليمات:nما الفرق بين الإمبراطورية البارثية والإمبراطورية الأرساسيدية؟nn### الإدخال:n |
يمكننا أن نرى أن الاستجابات الواردة من النموذج المضبوط بدقة تظهر تحسنًا كبيرًا في الدقة والملاءمة والوضوح مقارنة بتلك الواردة في النموذج المُدرب مسبقًا. في بعض الحالات، قد لا يكون استخدام النموذج المُدرب مسبقًا لحالة الاستخدام الخاصة بك كافيًا، لذا فإن ضبطه باستخدام هذه التقنية سيجعل الحل أكثر تخصيصًا لمجموعة البيانات الخاصة بك.
تنظيف
بعد الانتهاء من مهمة التدريب الخاصة بك وعدم الرغبة في استخدام الموارد الموجودة بعد الآن، قم بحذف الموارد باستخدام الكود التالي:
وفي الختام
يُظهر نشر نماذج Llama 2 Neuron وضبطها على SageMaker تقدمًا كبيرًا في إدارة نماذج الذكاء الاصطناعي التوليدية واسعة النطاق وتحسينها. تستخدم هذه النماذج، بما في ذلك المتغيرات مثل Llama-2-7b وLlama-2-13b، Neuron للتدريب والاستدلال الفعالين على المثيلات المستندة إلى AWS Inferentia وTrainium، مما يعزز أدائها وقابلية التوسع.
توفر القدرة على نشر هذه النماذج من خلال SageMaker JumpStart UI وPython SDK المرونة وسهولة الاستخدام. تتيح حزمة Neuron SDK، بدعمها لأطر تعلم الآلة الشائعة وقدرات الأداء العالي، التعامل بكفاءة مع هذه النماذج الكبيرة.
يعد ضبط هذه النماذج على البيانات الخاصة بالمجال أمرًا بالغ الأهمية لتعزيز أهميتها ودقتها في المجالات المتخصصة. تسمح العملية، التي يمكنك إجراؤها من خلال SageMaker Studio UI أو Python SDK، بالتخصيص حسب احتياجات محددة، مما يؤدي إلى تحسين أداء النموذج من حيث الإكمال الفوري وجودة الاستجابة.
وبالمقارنة، فإن الإصدارات المدربة مسبقًا من هذه النماذج، على الرغم من قوتها، قد توفر استجابات أكثر عمومية أو متكررة. يؤدي الضبط الدقيق إلى تخصيص النموذج ليناسب سياقات محددة، مما يؤدي إلى استجابات أكثر دقة وملاءمة وتنوعًا. ويتجلى هذا التخصيص بشكل خاص عند مقارنة الاستجابات من النماذج المدربة مسبقًا والمضبوطة بدقة، حيث يُظهر الأخير تحسنًا ملحوظًا في جودة وخصوصية المخرجات. في الختام، يمثل نشر نماذج Neuron Llama 2 وضبطها على SageMaker إطارًا قويًا لإدارة نماذج الذكاء الاصطناعي المتقدمة، مما يوفر تحسينات كبيرة في الأداء وقابلية التطبيق، خاصة عند تصميمها لمجالات أو مهام محددة.
ابدأ اليوم بالرجوع إلى نموذج SageMaker مفكرة.
لمزيد من المعلومات حول نشر وضبط نماذج Llama 2 المدربة مسبقًا على المثيلات المستندة إلى وحدة معالجة الرسومات، راجع قم بضبط Llama 2 لإنشاء النص على Amazon SageMaker JumpStart و نماذج Llama 2 الأساسية من Meta متاحة الآن في Amazon SageMaker JumpStart.
يود المؤلفون أن يعترفوا بالمساهمات الفنية لإيفان كرافيتز، وكريستوفر ويتن، وآدم كوزدرويتش، ومانان شاه، وجوناثان جينيجاني، ومايك جيمس.
حول المؤلف
 شين هوانغ هو عالم تطبيقي كبير في Amazon SageMaker JumpStart وخوارزميات Amazon SageMaker المدمجة. يركز على تطوير خوارزميات التعلم الآلي القابلة للتطوير. تتركز اهتماماته البحثية في مجال معالجة اللغة الطبيعية ، والتعلم العميق القابل للتفسير على البيانات المجدولة ، والتحليل القوي لتجميع الزمكان غير المعياري. وقد نشر العديد من الأوراق في مؤتمرات ACL و ICDM و KDD والجمعية الملكية للإحصاء: السلسلة أ.
شين هوانغ هو عالم تطبيقي كبير في Amazon SageMaker JumpStart وخوارزميات Amazon SageMaker المدمجة. يركز على تطوير خوارزميات التعلم الآلي القابلة للتطوير. تتركز اهتماماته البحثية في مجال معالجة اللغة الطبيعية ، والتعلم العميق القابل للتفسير على البيانات المجدولة ، والتحليل القوي لتجميع الزمكان غير المعياري. وقد نشر العديد من الأوراق في مؤتمرات ACL و ICDM و KDD والجمعية الملكية للإحصاء: السلسلة أ.
 نيتين يوسابيوس هو مهندس حلول المؤسسات الأول في AWS، ويتمتع بخبرة في هندسة البرمجيات، وهندسة المؤسسات، والذكاء الاصطناعي/تعلم الآلة. إنه متحمس للغاية لاستكشاف إمكانيات الذكاء الاصطناعي التوليدي. وهو يتعاون مع العملاء لمساعدتهم في إنشاء تطبيقات جيدة التصميم على منصة AWS، كما أنه ملتزم بحل التحديات التقنية ومساعدتهم في رحلتهم السحابية.
نيتين يوسابيوس هو مهندس حلول المؤسسات الأول في AWS، ويتمتع بخبرة في هندسة البرمجيات، وهندسة المؤسسات، والذكاء الاصطناعي/تعلم الآلة. إنه متحمس للغاية لاستكشاف إمكانيات الذكاء الاصطناعي التوليدي. وهو يتعاون مع العملاء لمساعدتهم في إنشاء تطبيقات جيدة التصميم على منصة AWS، كما أنه ملتزم بحل التحديات التقنية ومساعدتهم في رحلتهم السحابية.
 مادور براشانت يعمل في مجال الذكاء الاصطناعي التوليدي في AWS. إنه شغوف بالتقاطع بين التفكير البشري والذكاء الاصطناعي التوليدي. تكمن اهتماماته في الذكاء الاصطناعي التوليدي، وتحديدًا بناء الحلول المفيدة وغير الضارة، والأهم من ذلك كله أنها مثالية للعملاء. خارج العمل، يحب ممارسة اليوجا والمشي لمسافات طويلة وقضاء الوقت مع توأمه والعزف على الجيتار.
مادور براشانت يعمل في مجال الذكاء الاصطناعي التوليدي في AWS. إنه شغوف بالتقاطع بين التفكير البشري والذكاء الاصطناعي التوليدي. تكمن اهتماماته في الذكاء الاصطناعي التوليدي، وتحديدًا بناء الحلول المفيدة وغير الضارة، والأهم من ذلك كله أنها مثالية للعملاء. خارج العمل، يحب ممارسة اليوجا والمشي لمسافات طويلة وقضاء الوقت مع توأمه والعزف على الجيتار.
 ديوان شودري هو مهندس تطوير برمجيات مع Amazon Web Services. يعمل على خوارزميات Amazon SageMaker وعروض JumpStart. بصرف النظر عن بناء البنى التحتية للذكاء الاصطناعي / تعلم الآلة ، فهو متحمس أيضًا لبناء أنظمة موزعة قابلة للتطوير.
ديوان شودري هو مهندس تطوير برمجيات مع Amazon Web Services. يعمل على خوارزميات Amazon SageMaker وعروض JumpStart. بصرف النظر عن بناء البنى التحتية للذكاء الاصطناعي / تعلم الآلة ، فهو متحمس أيضًا لبناء أنظمة موزعة قابلة للتطوير.
 هاو تشو هو عالم أبحاث في Amazon SageMaker. وقبل ذلك، عمل على تطوير أساليب التعلم الآلي للكشف عن الاحتيال في Amazon Fraud Detector. إنه متحمس لتطبيق التعلم الآلي والتحسين وتقنيات الذكاء الاصطناعي التوليدية على العديد من مشكلات العالم الحقيقي. حصل على درجة الدكتوراه في الهندسة الكهربائية من جامعة نورث وسترن.
هاو تشو هو عالم أبحاث في Amazon SageMaker. وقبل ذلك، عمل على تطوير أساليب التعلم الآلي للكشف عن الاحتيال في Amazon Fraud Detector. إنه متحمس لتطبيق التعلم الآلي والتحسين وتقنيات الذكاء الاصطناعي التوليدية على العديد من مشكلات العالم الحقيقي. حصل على درجة الدكتوراه في الهندسة الكهربائية من جامعة نورث وسترن.
 تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
تشينغ لان هو مهندس تطوير برمجيات في AWS. لقد كان يعمل على العديد من المنتجات الصعبة في Amazon ، بما في ذلك حلول استدلال ML عالية الأداء ونظام تسجيل عالي الأداء. أطلق فريق Qing بنجاح أول نموذج مليار معلمة في إعلانات أمازون بزمن انتقال منخفض للغاية مطلوب. تتمتع Qing بمعرفة متعمقة حول تحسين البنية التحتية وتسريع التعلم العميق.
 د. أشيش خيتان هو عالم تطبيقي أقدم مع خوارزميات Amazon SageMaker المضمنة ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
د. أشيش خيتان هو عالم تطبيقي أقدم مع خوارزميات Amazon SageMaker المضمنة ويساعد في تطوير خوارزميات التعلم الآلي. حصل على الدكتوراه من جامعة إلينوي في أوربانا شامبين. وهو باحث نشط في التعلم الآلي والاستدلال الإحصائي ، وقد نشر العديد من الأوراق البحثية في مؤتمرات NeurIPS و ICML و ICLR و JMLR و ACL و EMNLP.
 الدكتور لي تشانغ هو مدير المنتج الرئيسي - الفني لخوارزميات Amazon SageMaker JumpStart وAmazon SageMaker المضمنة، وهي خدمة تساعد علماء البيانات وممارسي التعلم الآلي على البدء في التدريب ونشر نماذجهم، وتستخدم التعلم المعزز مع Amazon SageMaker. وقد فاز عمله السابق كعضو رئيسي في فريق البحث والمخترع الرئيسي في IBM Research بجائزة ورقة اختبار الزمن في IEEE INFOCOM.
الدكتور لي تشانغ هو مدير المنتج الرئيسي - الفني لخوارزميات Amazon SageMaker JumpStart وAmazon SageMaker المضمنة، وهي خدمة تساعد علماء البيانات وممارسي التعلم الآلي على البدء في التدريب ونشر نماذجهم، وتستخدم التعلم المعزز مع Amazon SageMaker. وقد فاز عمله السابق كعضو رئيسي في فريق البحث والمخترع الرئيسي في IBM Research بجائزة ورقة اختبار الزمن في IEEE INFOCOM.
 كامران خان، مدير تطوير الأعمال الفنية الأول لـ AWS Inferentina/Trianium في AWS. يتمتع بخبرة تزيد عن عشر سنوات في مساعدة العملاء على نشر وتحسين التدريب على التعلم العميق وأحمال العمل الاستدلالية باستخدام AWS Inferentia وAWS Trainium.
كامران خان، مدير تطوير الأعمال الفنية الأول لـ AWS Inferentina/Trianium في AWS. يتمتع بخبرة تزيد عن عشر سنوات في مساعدة العملاء على نشر وتحسين التدريب على التعلم العميق وأحمال العمل الاستدلالية باستخدام AWS Inferentia وAWS Trainium.
 جو سينيرشيا هو مدير منتج أول في AWS. يقوم بتحديد وبناء مثيلات Amazon EC2 للتعلم العميق والذكاء الاصطناعي وأحمال عمل الحوسبة عالية الأداء.
جو سينيرشيا هو مدير منتج أول في AWS. يقوم بتحديد وبناء مثيلات Amazon EC2 للتعلم العميق والذكاء الاصطناعي وأحمال عمل الحوسبة عالية الأداء.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/

