لقد فتح الذكاء الاصطناعي التوليدي الكثير من الإمكانات في مجال الذكاء الاصطناعي. نحن نشهد العديد من الاستخدامات، بما في ذلك إنشاء النص، وإنشاء التعليمات البرمجية، والتلخيص، والترجمة، وروبوتات الدردشة، والمزيد. أحد هذه المجالات التي تتطور هو استخدام معالجة اللغة الطبيعية (NLP) لفتح فرص جديدة للوصول إلى البيانات من خلال استعلامات SQL البديهية. بدلاً من التعامل مع التعليمات البرمجية التقنية المعقدة، يمكن لمستخدمي الأعمال ومحللي البيانات طرح الأسئلة المتعلقة بالبيانات والرؤى بلغة واضحة. الهدف الأساسي هو إنشاء استعلامات SQL تلقائيًا من نص اللغة الطبيعية. للقيام بذلك، يتم تحويل إدخال النص إلى تمثيل منظم، ومن هذا التمثيل، يتم إنشاء استعلام SQL يمكن استخدامه للوصول إلى قاعدة البيانات.
في هذا المنشور، نقدم مقدمة للنص إلى SQL (Text2SQL) ونستكشف حالات الاستخدام والتحديات وأنماط التصميم وأفضل الممارسات. وعلى وجه التحديد، نناقش ما يلي:
- لماذا نحتاج إلى Text2SQL
- المكونات الرئيسية للنص إلى SQL
- اعتبارات هندسية سريعة للغة الطبيعية أو تحويل النص إلى SQL
- التحسينات وأفضل الممارسات
- أنماط العمارة
لماذا نحتاج إلى Text2SQL؟
اليوم، تتوفر كمية كبيرة من البيانات في تحليلات البيانات التقليدية، وتخزين البيانات، وقواعد البيانات، والتي قد لا يكون من السهل الاستعلام عنها أو فهمها بالنسبة لغالبية أعضاء المؤسسة. الهدف الأساسي من Text2SQL هو جعل قواعد بيانات الاستعلام أكثر سهولة للمستخدمين غير التقنيين، الذين يمكنهم تقديم استعلاماتهم باللغة الطبيعية.
يمكّن NLP SQL مستخدمي الأعمال من تحليل البيانات والحصول على إجابات عن طريق كتابة الأسئلة أو نطقها باللغة الطبيعية، مثل ما يلي:
- "إظهار إجمالي المبيعات لكل منتج في الشهر الماضي"
- "ما هي المنتجات التي حققت المزيد من الإيرادات؟"
- "ما هي نسبة العملاء من كل منطقة؟"
أمازون بيدروك هي خدمة مُدارة بالكامل توفر مجموعة مختارة من النماذج الأساسية عالية الأداء (FMs) عبر واجهة برمجة تطبيقات واحدة، مما يتيح إنشاء تطبيقات Gen AI وتوسيع نطاقها بسهولة. يمكن الاستفادة منه لإنشاء استعلامات SQL بناءً على أسئلة مشابهة لتلك المذكورة أعلاه والاستعلام عن البيانات التنظيمية المنظمة وإنشاء استجابات باللغة الطبيعية من بيانات استجابة الاستعلام.
المكونات الرئيسية للنص إلى SQL
تتضمن أنظمة تحويل النص إلى SQL عدة مراحل لتحويل استعلامات اللغة الطبيعية إلى SQL قابلة للتشغيل:
- معالجة اللغة الطبيعية:
- تحليل استعلام إدخال المستخدم
- استخراج العناصر الرئيسية والنية
- تحويل إلى تنسيق منظم
- جيل SQL:
- قم بتعيين التفاصيل المستخرجة في بناء جملة SQL
- قم بإنشاء استعلام SQL صالح
- استعلام قاعدة البيانات:
- قم بتشغيل استعلام SQL الذي تم إنشاؤه بواسطة الذكاء الاصطناعي في قاعدة البيانات
- استرجاع النتائج
- إرجاع النتائج للمستخدم
إحدى القدرات الرائعة لنماذج اللغات الكبيرة (LLMs) هي إنشاء التعليمات البرمجية، بما في ذلك لغة الاستعلام الهيكلية (SQL) لقواعد البيانات. يمكن الاستفادة من شهادات LLM هذه لفهم سؤال اللغة الطبيعية وإنشاء استعلام SQL مطابق كمخرجات. سوف تستفيد LLMs من خلال اعتماد التعلم في السياق وإعدادات الضبط مع توفير المزيد من البيانات.
يوضح الرسم البياني التالي تدفق Text2SQL الأساسي.

اعتبارات هندسية سريعة للغة الطبيعية إلى SQL
تعد المطالبة أمرًا بالغ الأهمية عند استخدام LLMs لترجمة اللغة الطبيعية إلى استعلامات SQL، وهناك العديد من الاعتبارات المهمة للهندسة السريعة.
الطُرق الفعّالة الهندسة السريعة هو المفتاح لتطوير اللغة الطبيعية لأنظمة SQL. توفر المطالبات الواضحة والمباشرة تعليمات أفضل لنموذج اللغة. إن توفير السياق الذي يطلبه المستخدم استعلام SQL مع تفاصيل مخطط قاعدة البيانات ذات الصلة يمكّن النموذج من ترجمة الهدف بدقة. يساعد تضمين بعض الأمثلة المشروحة لمطالبات اللغة الطبيعية واستعلامات SQL المقابلة في توجيه النموذج لإنتاج مخرجات متوافقة مع بناء الجملة. بالإضافة إلى ذلك، يؤدي دمج الجيل المعزز للاسترجاع (RAG)، حيث يسترد النموذج أمثلة مماثلة أثناء المعالجة، إلى تحسين دقة التعيين. تعد المطالبات المصممة جيدًا والتي توفر للنموذج ما يكفي من التعليمات والسياق والأمثلة وزيادة الاسترجاع أمرًا ضروريًا لترجمة اللغة الطبيعية بشكل موثوق إلى استعلامات SQL.
ما يلي هو مثال للمطالبة الأساسية مع تمثيل التعليمات البرمجية لقاعدة البيانات من المستند التقني تعزيز قدرات تحويل النص إلى SQL لعدد قليل من النماذج اللغوية الكبيرة: دراسة حول استراتيجيات التصميم الفوري.
كما هو موضح في هذا المثال، يوفر التعلم السريع المبني على عدد قليل من اللقطات للنموذج مجموعة من الأمثلة المشروحة في الموجه نفسه. يوضح هذا التعيين المستهدف بين اللغة الطبيعية وSQL للنموذج. عادةً، قد يحتوي الموجه على حوالي 2-3 أزواج تعرض استعلامًا باللغة الطبيعية وعبارة SQL المكافئة. ترشد هذه الأمثلة القليلة النموذج إلى إنشاء استعلامات SQL متوافقة مع بناء الجملة من اللغة الطبيعية دون الحاجة إلى بيانات تدريب مكثفة.
الضبط الدقيق مقابل الهندسة السريعة
عند بناء لغة طبيعية لأنظمة SQL، غالبًا ما ندخل في مناقشة ما إذا كان ضبط النموذج هو الأسلوب الصحيح أو ما إذا كانت الهندسة السريعة الفعالة هي الطريق الصحيح. يمكن النظر في كلا النهجين واختيارهما بناءً على مجموعة المتطلبات الصحيحة:
-
- الكون المثالى – يتم تدريب النموذج الأساسي مسبقًا على مجموعة نصية عامة كبيرة ومن ثم يمكن استخدامه الضبط الدقيق القائم على التعليمات، والذي يستخدم أمثلة مصنفة لتحسين أداء النموذج الأساسي الذي تم تدريبه مسبقًا على text-SQL. يؤدي هذا إلى تكييف النموذج مع المهمة المستهدفة. يقوم الضبط الدقيق بتدريب النموذج مباشرة على المهمة النهائية ولكنه يتطلب العديد من أمثلة نص SQL. يمكنك استخدام الضبط الدقيق الخاضع للإشراف استنادًا إلى LLM الخاص بك لتحسين فعالية تحويل النص إلى SQL. لهذا، يمكنك استخدام العديد من مجموعات البيانات مثل عنكبوت, ويكي إس كيو إل, مطاردة, بيرد-SQLالطرق أو CoSQL.
- الهندسة السريعة - يتم تدريب النموذج لإكمال المطالبات المصممة لمطالبة بناء جملة SQL الهدف. عند إنشاء SQL من لغة طبيعية باستخدام LLMs، يعد توفير تعليمات واضحة في الموجه أمرًا مهمًا للتحكم في مخرجات النموذج. في الموجه للتعليق على مكونات مختلفة مثل الإشارة إلى الأعمدة والمخطط ثم توجيه نوع SQL المراد إنشاؤه. تعمل هذه مثل التعليمات التي تخبر النموذج بكيفية تنسيق مخرجات SQL. يعرض الموجه التالي مثالاً حيث تقوم بتوجيه أعمدة الجدول وإرشادك لإنشاء استعلام MySQL:
تتمثل الطريقة الفعالة لنماذج تحويل النص إلى SQL في البدء أولاً بماجستير LLM أساسي دون أي ضبط دقيق لمهمة محددة. يمكن بعد ذلك استخدام المطالبات المصممة جيدًا لتكييف النموذج الأساسي وقيادته للتعامل مع تعيين النص إلى SQL. تسمح لك هذه الهندسة السريعة بتطوير القدرة دون الحاجة إلى إجراء الضبط الدقيق. إذا لم تحقق الهندسة السريعة في النموذج الأساسي الدقة الكافية، فيمكن بعد ذلك استكشاف الضبط الدقيق لمجموعة صغيرة من أمثلة SQL النصية بالإضافة إلى المزيد من الهندسة السريعة.
قد تكون هناك حاجة إلى الجمع بين الضبط الدقيق والهندسة السريعة إذا كانت الهندسة السريعة على النموذج الأولي المُدرب مسبقًا لا تلبي المتطلبات وحدها. ومع ذلك، فمن الأفضل محاولة إجراء هندسة سريعة في البداية دون إجراء ضبط دقيق، لأن هذا يسمح بالتكرار السريع دون جمع البيانات. إذا فشل هذا في توفير الأداء المناسب، فإن الضبط الدقيق جنبًا إلى جنب مع الهندسة السريعة يعد خطوة تالية قابلة للتطبيق. يعمل هذا النهج الشامل على زيادة الكفاءة إلى الحد الأقصى مع السماح بالتخصيص إذا كانت الأساليب المستندة إلى السرعة البحتة غير كافية.
التحسين وأفضل الممارسات
يعد التحسين وأفضل الممارسات أمرًا ضروريًا لتعزيز الفعالية وضمان استخدام الموارد على النحو الأمثل وتحقيق النتائج الصحيحة بأفضل طريقة ممكنة. تساعد التقنيات في تحسين الأداء والتحكم في التكاليف وتحقيق نتائج ذات جودة أفضل.
عند تطوير أنظمة تحويل النص إلى SQL باستخدام LLMs، يمكن لتقنيات التحسين تحسين الأداء والكفاءة. فيما يلي بعض المجالات الرئيسية التي يجب مراعاتها:
- Caching – لتحسين زمن الوصول والتحكم في التكلفة والتوحيد القياسي، يمكنك تخزين SQL الذي تم تحليله ومطالبات الاستعلام المعروفة من Text to-SQL LLM في ذاكرة التخزين المؤقت. وهذا يتجنب إعادة معالجة الاستعلامات المتكررة.
- مراقبة – يجب جمع السجلات والمقاييس حول تحليل الاستعلام والتعرف الفوري وإنشاء SQL ونتائج SQL لمراقبة نظام تحويل النص إلى SQL LLM. يوفر هذا رؤية لمثال التحسين الذي يقوم بتحديث المطالبة أو إعادة النظر في الضبط الدقيق باستخدام مجموعة بيانات محدثة.
- وجهات النظر المادية مقابل الجداول – يمكن لطرق العرض المادية تبسيط عملية إنشاء SQL وتحسين الأداء لاستعلامات تحويل النص إلى SQL الشائعة. قد يؤدي الاستعلام عن الجداول مباشرةً إلى SQL معقدة ويؤدي أيضًا إلى مشكلات في الأداء، بما في ذلك الإنشاء المستمر لتقنيات الأداء مثل الفهارس. بالإضافة إلى ذلك، يمكنك تجنب مشكلات الأداء عند استخدام نفس الجدول لمجالات أخرى من التطبيق في نفس الوقت.
- تحديث البيانات - يجب تحديث طرق العرض المادية وفقًا لجدول زمني للحفاظ على تحديث البيانات لاستعلامات تحويل النص إلى SQL. يمكنك استخدام أساليب التحديث الدفعي أو التزايدي لموازنة النفقات العامة.
- كتالوج البيانات المركزية - يوفر إنشاء كتالوج بيانات مركزي جزءًا واحدًا من الرؤية الزجاجية لمصادر بيانات المؤسسة وسيساعد LLMs على اختيار الجداول والمخططات المناسبة من أجل تقديم استجابات أكثر دقة. المتجه التضمين يمكن توفيرها من كتالوج البيانات المركزي إلى LLM مع المعلومات المطلوبة لإنشاء استجابات SQL دقيقة وذات صلة.
من خلال تطبيق أفضل ممارسات التحسين مثل التخزين المؤقت والمراقبة وطرق العرض المادية والتحديث المجدول والكتالوج المركزي، يمكنك تحسين أداء وكفاءة أنظمة تحويل النص إلى SQL بشكل كبير باستخدام LLMs.
أنماط العمارة
دعونا نلقي نظرة على بعض أنماط الهندسة المعمارية التي يمكن تنفيذها لنص في سير عمل SQL.
الهندسة السريعة
يوضح الرسم البياني التالي بنية إنشاء الاستعلامات باستخدام ماجستير إدارة الأعمال (LLM) باستخدام الهندسة السريعة.
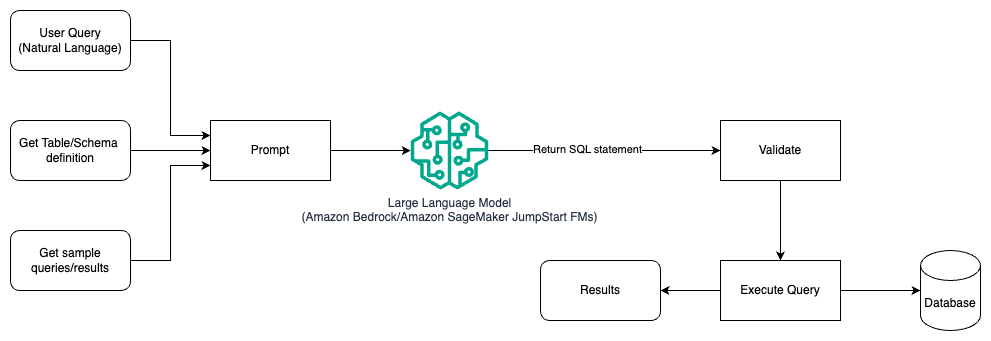
في هذا النمط، يقوم المستخدم بإنشاء تعليم سريع يعتمد على اللقطات القليلة والذي يزود النموذج بأمثلة توضيحية في الموجه نفسه، والذي يتضمن تفاصيل الجدول والمخطط وبعض نماذج الاستعلامات مع نتائجها. يستخدم LLM الموجه المقدم لإعادة SQL التي تم إنشاؤها بواسطة الذكاء الاصطناعي، والتي يتم التحقق من صحتها ثم تشغيلها على قاعدة البيانات للحصول على النتائج. هذا هو النمط الأكثر وضوحًا للبدء باستخدام الهندسة السريعة. لهذا يمكنك استخدام أمازون بيدروك or نماذج الأساس in أمازون سيج ميكر جومب ستارت.
في هذا النمط، يقوم المستخدم بإنشاء تعليم سريع يعتمد على الموجه والذي يزود النموذج بأمثلة توضيحية في الموجه نفسه، والذي يتضمن تفاصيل الجدول والمخطط وبعض نماذج الاستعلامات مع نتائجها. يستخدم LLM الموجه المقدم لإعادة SQL الذي تم إنشاؤه بواسطة الذكاء الاصطناعي والذي تم التحقق من صحته وتشغيله على قاعدة البيانات للحصول على النتائج. هذا هو النمط الأكثر وضوحًا للبدء باستخدام الهندسة السريعة. لهذا يمكنك استخدام أمازون بيدروك وهي خدمة مُدارة بالكامل توفر مجموعة مختارة من النماذج الأساسية عالية الأداء (FMs) من شركات الذكاء الاصطناعي الرائدة عبر واجهة برمجة تطبيقات واحدة، إلى جانب مجموعة واسعة من الإمكانات التي تحتاجها لإنشاء تطبيقات ذكاء اصطناعي مولدة تتمتع بالأمان والخصوصية والذكاء الاصطناعي المسؤول. أو نماذج مؤسسة JumpStart الذي يقدم نماذج أساسية حديثة لحالات الاستخدام مثل كتابة المحتوى، وإنشاء التعليمات البرمجية، والإجابة على الأسئلة، وكتابة النصوص، والتلخيص، والتصنيف، واسترجاع المعلومات، والمزيد
الهندسة السريعة والضبط الدقيق
يوضح الرسم البياني التالي بنية إنشاء الاستعلامات باستخدام LLM باستخدام الهندسة السريعة والضبط الدقيق.
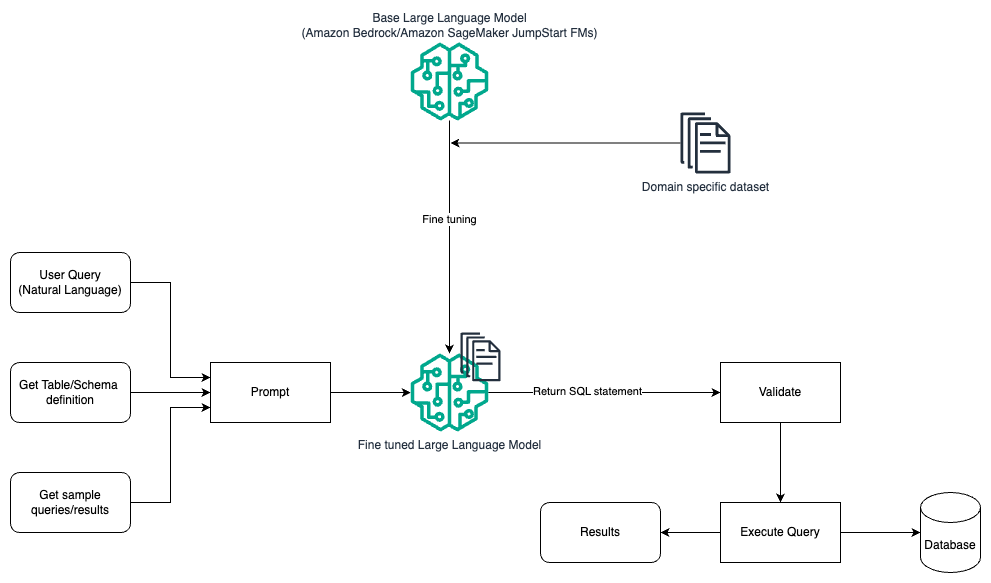
يشبه هذا التدفق النمط السابق، والذي يعتمد في الغالب على الهندسة السريعة، ولكن مع تدفق إضافي من الضبط الدقيق لمجموعة البيانات الخاصة بالمجال. يتم استخدام LLM المضبوط جيدًا لإنشاء استعلامات SQL بأقل قيمة في السياق للموجه. لهذا، يمكنك استخدام SageMaker JumpStart لضبط LLM على مجموعة بيانات خاصة بالمجال بنفس الطريقة التي تقوم بها بتدريب ونشر أي نموذج على الأمازون SageMaker.
الهندسة السريعة وRAG
يوضح الرسم البياني التالي بنية إنشاء الاستعلامات باستخدام LLM باستخدام الهندسة السريعة وRAG.
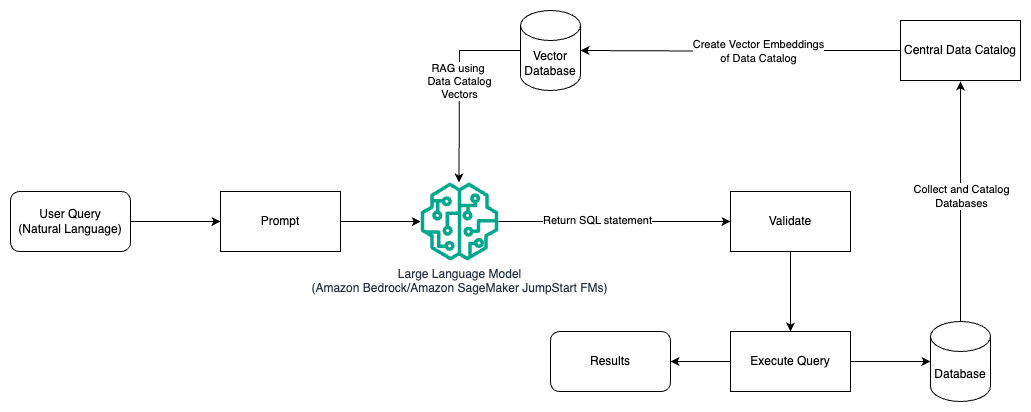
في هذا النمط نستخدم الجيل المعزز الاسترداد باستخدام مخازن التضمين ناقلات، مثل الأمازون تيتان التضمينات or تضمين كوهير، وفي أمازون بيدروك من كتالوج البيانات المركزية، مثل غراء AWS كتالوج البيانات، لقواعد البيانات داخل المنظمة. يتم تخزين تضمينات المتجهات في قواعد بيانات المتجهات مثل محرك المتجهات لـ Amazon OpenSearch Serverless, Amazon Relational Database Service (Amazon RDS) لـ PostgreSQL مع الالجائزة com.pgvector التمديد، أو أمازون كندرا. تستخدم LLM التضمينات المتجهة لتحديد قاعدة البيانات والجداول والأعمدة الصحيحة من الجداول بشكل أسرع عند إنشاء استعلامات SQL. يعد استخدام RAG مفيدًا عندما يتم تخزين البيانات والمعلومات ذات الصلة التي تحتاج إلى استردادها بواسطة LLMs في أنظمة قواعد بيانات منفصلة متعددة ويحتاج LLM إلى أن يكون قادرًا على البحث عن البيانات أو الاستعلام عنها من جميع هذه الأنظمة المختلفة. هذا هو المكان الذي يؤدي فيه توفير التضمين المتجه لكتالوج بيانات مركزي أو موحد إلى حاملي شهادات LLM إلى الحصول على معلومات أكثر دقة وشمولاً يتم إرجاعها بواسطة حاملي LLM.
وفي الختام
في هذا المنشور، ناقشنا كيف يمكننا توليد قيمة من بيانات المؤسسة باستخدام اللغة الطبيعية لإنشاء SQL. لقد بحثنا في المكونات الرئيسية والتحسين وأفضل الممارسات. لقد تعلمنا أيضًا أنماط الهندسة المعمارية بدءًا من الهندسة السريعة الأساسية وحتى الضبط الدقيق وRAG. لمعرفة المزيد، راجع أمازون بيدروك لبناء تطبيقات الذكاء الاصطناعي التوليدية وتوسيع نطاقها بسهولة باستخدام النماذج الأساسية
حول المؤلف
 راندي ديفو هو مهندس حلول رئيسي أول في AWS. وهو حاصل على MSEE من جامعة ميشيغان ، حيث عمل على الرؤية الحاسوبية للمركبات ذاتية القيادة. كما أنه حاصل على ماجستير إدارة الأعمال من جامعة ولاية كولورادو. شغل راندي العديد من المناصب في مجال التكنولوجيا ، بدءًا من هندسة البرمجيات إلى إدارة المنتجات. دخلت مساحة البيانات الضخمة في عام 2013 وتواصل استكشاف هذا المجال. يعمل بنشاط في مشاريع في مجال ML وقد قدم في العديد من المؤتمرات بما في ذلك ستراتا وغلوكون.
راندي ديفو هو مهندس حلول رئيسي أول في AWS. وهو حاصل على MSEE من جامعة ميشيغان ، حيث عمل على الرؤية الحاسوبية للمركبات ذاتية القيادة. كما أنه حاصل على ماجستير إدارة الأعمال من جامعة ولاية كولورادو. شغل راندي العديد من المناصب في مجال التكنولوجيا ، بدءًا من هندسة البرمجيات إلى إدارة المنتجات. دخلت مساحة البيانات الضخمة في عام 2013 وتواصل استكشاف هذا المجال. يعمل بنشاط في مشاريع في مجال ML وقد قدم في العديد من المؤتمرات بما في ذلك ستراتا وغلوكون.
 نيتين يوسابيوس هو مهندس حلول المؤسسات الأول في AWS، ويتمتع بخبرة في هندسة البرمجيات، وهندسة المؤسسات، والذكاء الاصطناعي/تعلم الآلة. إنه متحمس للغاية لاستكشاف إمكانيات الذكاء الاصطناعي التوليدي. وهو يتعاون مع العملاء لمساعدتهم في إنشاء تطبيقات جيدة التصميم على منصة AWS، كما أنه ملتزم بحل التحديات التقنية ومساعدتهم في رحلتهم السحابية.
نيتين يوسابيوس هو مهندس حلول المؤسسات الأول في AWS، ويتمتع بخبرة في هندسة البرمجيات، وهندسة المؤسسات، والذكاء الاصطناعي/تعلم الآلة. إنه متحمس للغاية لاستكشاف إمكانيات الذكاء الاصطناعي التوليدي. وهو يتعاون مع العملاء لمساعدتهم في إنشاء تطبيقات جيدة التصميم على منصة AWS، كما أنه ملتزم بحل التحديات التقنية ومساعدتهم في رحلتهم السحابية.
 ارغيا بانيرجي هو مهندس الحلول الأول في AWS في منطقة خليج سان فرانسيسكو ويركز على مساعدة العملاء على اعتماد واستخدام AWS Cloud. تركز "أرجيا" على البيانات الضخمة، وبحيرات البيانات، والبث المباشر، والتحليلات المجمعة، وخدمات وتقنيات الذكاء الاصطناعي/تعلم الآلة.
ارغيا بانيرجي هو مهندس الحلول الأول في AWS في منطقة خليج سان فرانسيسكو ويركز على مساعدة العملاء على اعتماد واستخدام AWS Cloud. تركز "أرجيا" على البيانات الضخمة، وبحيرات البيانات، والبث المباشر، والتحليلات المجمعة، وخدمات وتقنيات الذكاء الاصطناعي/تعلم الآلة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/generating-value-from-enterprise-data-best-practices-for-text2sql-and-generative-ai/

