في هذا المنشور، نوضح كيفية استخدام التقليم الهيكلي القائم على البحث في الهندسة العصبية (NAS) لضغط نموذج BERT المضبوط بدقة لتحسين أداء النموذج وتقليل أوقات الاستدلال. تشهد نماذج اللغات المدربة مسبقًا (PLMs) اعتمادًا تجاريًا ومؤسسيًا سريعًا في مجالات أدوات الإنتاجية وخدمة العملاء والبحث والتوصيات وأتمتة عمليات الأعمال وإنشاء المحتوى. عادةً ما يرتبط نشر نقاط نهاية استنتاج PLM بزمن انتقال أعلى وتكاليف بنية تحتية أعلى بسبب متطلبات الحوسبة وانخفاض الكفاءة الحسابية بسبب العدد الكبير من المعلمات. يؤدي تقليم PLM إلى تقليل حجم النموذج وتعقيده مع الاحتفاظ بقدراته التنبؤية. تحقق أجهزة PLM المُقلَّمة مساحة أصغر للذاكرة وزمن وصول أقل. لقد أثبتنا أنه من خلال تقليم PLM واستبدال عدد المعلمات وخطأ التحقق من الصحة لمهمة مستهدفة محددة، نكون قادرين على تحقيق أوقات استجابة أسرع عند مقارنتها بنموذج PLM الأساسي.
يعد التحسين متعدد الأهداف أحد مجالات اتخاذ القرار الذي يعمل على تحسين أكثر من وظيفة موضوعية واحدة، مثل استهلاك الذاكرة ووقت التدريب وموارد الحوسبة، ليتم تحسينها في وقت واحد. التقليم الهيكلي هو أسلوب لتقليل الحجم والمتطلبات الحسابية لـ PLM عن طريق تقليم الطبقات أو الخلايا العصبية/العقد أثناء محاولة الحفاظ على دقة النموذج. من خلال إزالة الطبقات، يحقق التقليم الهيكلي معدلات ضغط أعلى، مما يؤدي إلى تناثر منظم صديق للأجهزة مما يقلل من أوقات التشغيل وأوقات الاستجابة. يؤدي تطبيق تقنية تقليم هيكلية على نموذج إدارة دورة حياة المنتج (PLM) إلى نموذج أخف وزنًا مع مساحة ذاكرة أقل، والتي عند استضافتها كنقطة نهاية استدلالية في SageMaker، توفر كفاءة محسنة للموارد وتكلفة أقل عند مقارنتها بوحدة إدارة دورة الحياة (PLM) الأصلية المضبوطة بدقة.
يمكن تطبيق المفاهيم الموضحة في هذا المنشور على التطبيقات التي تستخدم ميزات PLM، مثل أنظمة التوصية وتحليل المشاعر ومحركات البحث. على وجه التحديد، يمكنك استخدام هذا الأسلوب إذا كان لديك فرق مخصصة للتعلم الآلي (ML) وعلوم البيانات تعمل على ضبط نماذج PLM الخاصة بها باستخدام مجموعات البيانات الخاصة بالمجال ونشر عدد كبير من نقاط النهاية الاستدلالية باستخدام الأمازون SageMaker. أحد الأمثلة على ذلك هو بائع تجزئة عبر الإنترنت ينشر عددًا كبيرًا من نقاط النهاية الاستدلالية لتلخيص النص وتصنيف كتالوج المنتج وتصنيف مشاعر التعليقات على المنتج. قد يكون مثال آخر هو مقدم الرعاية الصحية الذي يستخدم نقاط النهاية لاستنتاج PLM لتصنيف المستندات السريرية، والتعرف على الكيانات المسماة من التقارير الطبية، وروبوتات الدردشة الطبية، والتقسيم الطبقي لمخاطر المرضى.
حل نظرة عامة
في هذا القسم، نقدم سير العمل العام ونشرح النهج. أولا، نستخدم أمازون ساجميكر ستوديو مفكرة لضبط نموذج BERT المدرب مسبقًا على مهمة مستهدفة باستخدام مجموعة بيانات خاصة بالمجال. بيرت (تمثيلات التشفير ثنائية الاتجاه من المحولات) هي نموذج لغة مدرب مسبقًا يعتمد على هندسة المحولات تستخدم لمهام معالجة اللغة الطبيعية (NLP). البحث عن الهندسة العصبية (NAS) هو أسلوب لأتمتة تصميم الشبكات العصبية الاصطناعية ويرتبط ارتباطًا وثيقًا بتحسين المعلمات الفائقة، وهو نهج يستخدم على نطاق واسع في مجال التعلم الآلي. الهدف من NAS هو العثور على البنية المثالية لمشكلة معينة من خلال البحث في مجموعة كبيرة من البنى المرشحة باستخدام تقنيات مثل التحسين الخالي من التدرج أو عن طريق تحسين المقاييس المطلوبة. عادةً ما يتم قياس أداء البنية باستخدام مقاييس مثل فقدان التحقق من الصحة. الضبط التلقائي لنموذج SageMaker (AMT) يقوم بأتمتة العملية الشاقة والمعقدة للعثور على المجموعات المثالية من المعلمات الفائقة لنموذج ML التي تحقق أفضل أداء للنموذج. تستخدم AMT خوارزميات بحث ذكية وتقييمات متكررة باستخدام مجموعة من المعلمات الفائقة التي تحددها. فهو يختار قيم المعلمات الفائقة التي تنشئ نموذجًا يقدم أفضل أداء، كما يتم قياسه بواسطة مقاييس الأداء مثل الدقة ودرجة F-1.
يعد نهج الضبط الدقيق الموضح في هذا المنشور عامًا ويمكن تطبيقه على أي مجموعة بيانات مستندة إلى النص. يمكن أن تكون المهمة المخصصة لـ BERT PLM مهمة نصية مثل تحليل المشاعر أو تصنيف النص أو الأسئلة والأجوبة. في هذا العرض التوضيحي، المهمة المستهدفة هي مشكلة تصنيف ثنائية حيث يتم استخدام BERT لتحديد ما إذا كان يمكن استنتاج معنى جزء نصي واحد من الجزء الآخر، من مجموعة بيانات تتكون من مجموعة من أزواج أجزاء النص. نحن نستخدم ال التعرف على مجموعة البيانات النصية من مجموعة قياس الأداء GLUE. نقوم بإجراء بحث متعدد الأهداف باستخدام SageMaker AMT لتحديد الشبكات الفرعية التي تقدم مفاضلات مثالية بين عدد المعلمات ودقة التنبؤ للمهمة المستهدفة. عند إجراء بحث متعدد الأهداف، نبدأ بتحديد الدقة وعدد المعلمات باعتبارها الأهداف التي نهدف إلى تحسينها.
ضمن شبكة BERT PLM، يمكن أن تكون هناك شبكات فرعية معيارية مستقلة تسمح للنموذج بالحصول على قدرات متخصصة مثل فهم اللغة وتمثيل المعرفة. يستخدم BERT PLM شبكة فرعية متعددة الرؤوس للانتباه الذاتي وشبكة فرعية للتغذية الأمامية. تسمح طبقة الاهتمام الذاتي متعددة الرؤوس لـ BERT بربط مواضع مختلفة لتسلسل واحد من أجل حساب تمثيل التسلسل من خلال السماح لرؤوس متعددة بحضور إشارات سياق متعددة. يتم تقسيم المدخلات إلى مساحات فرعية متعددة ويتم تطبيق الاهتمام الذاتي على كل من المساحات الفرعية بشكل منفصل. تسمح الرؤوس المتعددة في محول PLM للنموذج بالحضور بشكل مشترك إلى المعلومات من مساحات فرعية تمثيلية مختلفة. شبكة التغذية الأمامية الفرعية هي شبكة عصبية بسيطة تأخذ المخرجات من الشبكة الفرعية متعددة الرؤوس للانتباه الذاتي، وتعالج البيانات، وترجع تمثيلات التشفير النهائية.
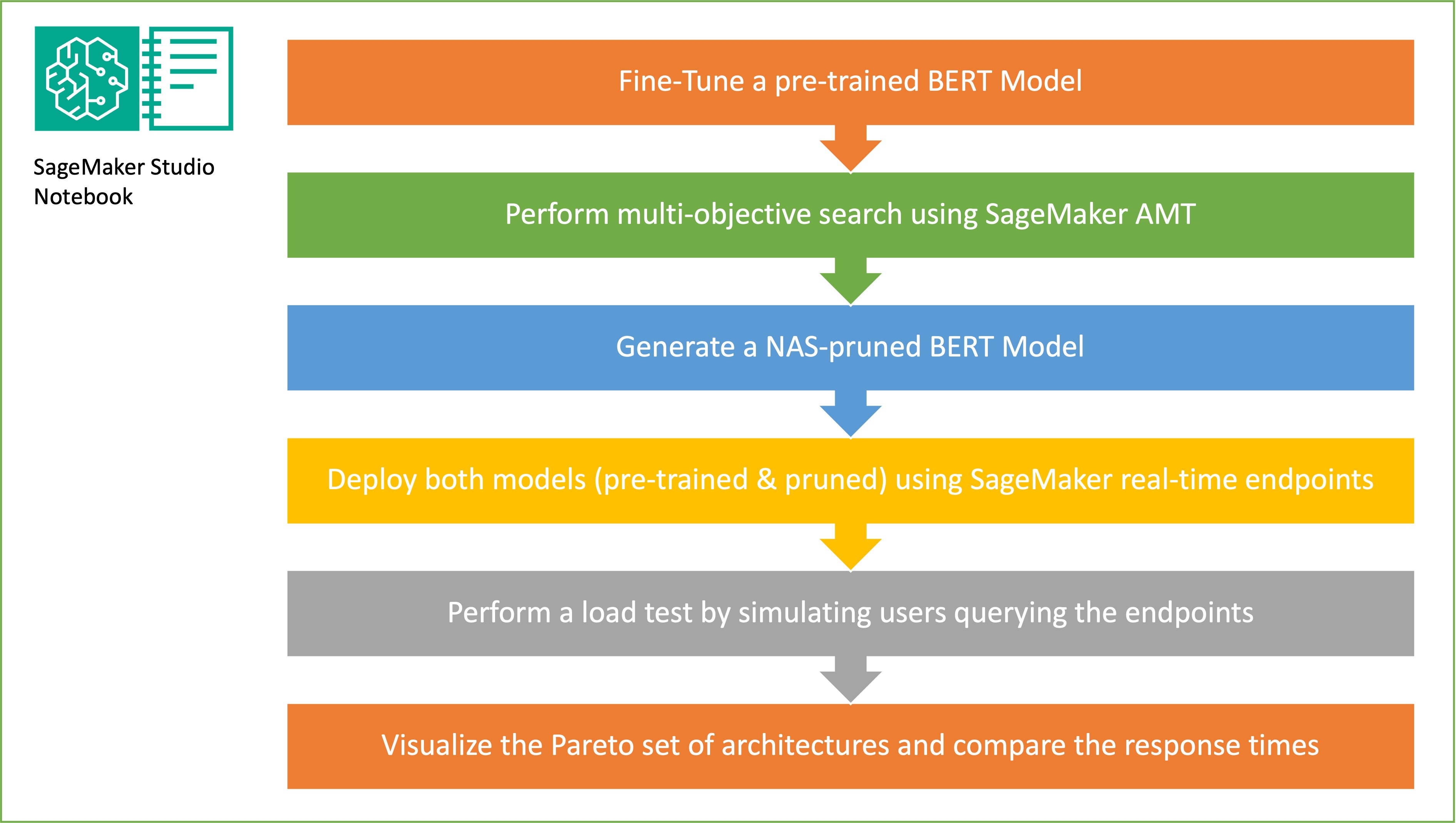
الهدف من أخذ العينات العشوائية للشبكة الفرعية هو تدريب نماذج BERT الأصغر التي يمكنها الأداء بشكل جيد بما فيه الكفاية في المهام المستهدفة. قمنا بأخذ عينات من 100 شبكة فرعية عشوائية من نموذج BERT الأساسي المضبوط بدقة وقمنا بتقييم 10 شبكات في وقت واحد. يتم تقييم الشبكات الفرعية المدربة للمقاييس الموضوعية ويتم اختيار النموذج النهائي بناءً على المفاضلات الموجودة بين المقاييس الموضوعية. نحن نتصور جبهة باريتو للشبكات الفرعية التي تم أخذ عينات منها، والتي تحتوي على النموذج المقطوع الذي يوفر المفاضلة المثلى بين دقة النموذج وحجم النموذج. نختار الشبكة الفرعية المرشحة (نموذج BERT المُشذب من NAS) استنادًا إلى حجم النموذج ودقة النموذج الذي نرغب في مقايضته. بعد ذلك، نستضيف نقاط النهاية، والنموذج الأساسي BERT المُدرب مسبقًا، ونموذج BERT المجهز بواسطة NAS باستخدام SageMaker. لإجراء اختبار الحمل، نستخدم جراد، أداة اختبار تحميل مفتوحة المصدر يمكنك تنفيذها باستخدام Python. نقوم بإجراء اختبار التحميل على كلا نقطتي النهاية باستخدام Locust ونتصور النتائج باستخدام واجهة Pareto لتوضيح المفاضلة بين أوقات الاستجابة والدقة لكلا النموذجين. يوفر الرسم البياني التالي نظرة عامة على سير العمل الموضح في هذا المنشور.
المتطلبات الأساسية المسبقة
يشترط لهذه الوظيفة توفر المتطلبات التالية:
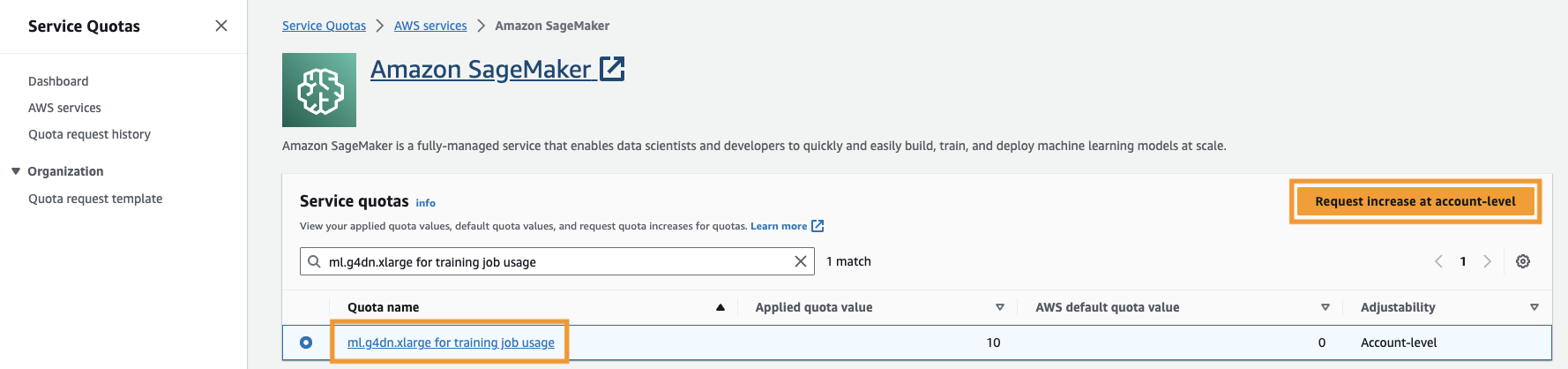
تحتاج أيضًا إلى زيادة حصة الخدمة للوصول إلى ثلاث مثيلات على الأقل من مثيلات ml.g4dn.xlarge في SageMaker. نوع المثيل ml.g4dn.xlarge هو مثيل GPU الفعال من حيث التكلفة والذي يسمح لك بتشغيل PyTorch محليًا. لزيادة حصة الخدمة، أكمل الخطوات التالية:
- على وحدة التحكم، انتقل إلى Service Quotas.
- في حالة إدارة الحصص، اختر الأمازون SageMaker، ثم اختر عرض الحصص.

- ابحث عن "ml-g4dn.xlarge لاستخدام مهمة التدريب" وحدد عنصر الحصة النسبية.
- اختار طلب الزيادة على مستوى الحساب.
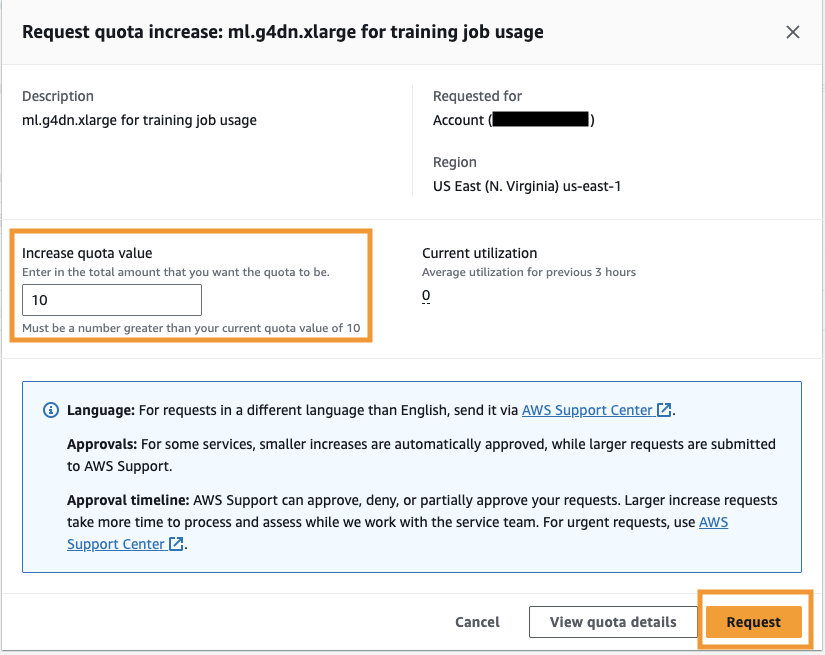
- في حالة زيادة قيمة الحصة، أدخل قيمة 5 أو أعلى.
- اختار أطلب.
قد تستغرق الموافقة على الحصة النسبية المطلوبة بعض الوقت حتى تكتمل اعتمادًا على أذونات الحساب.
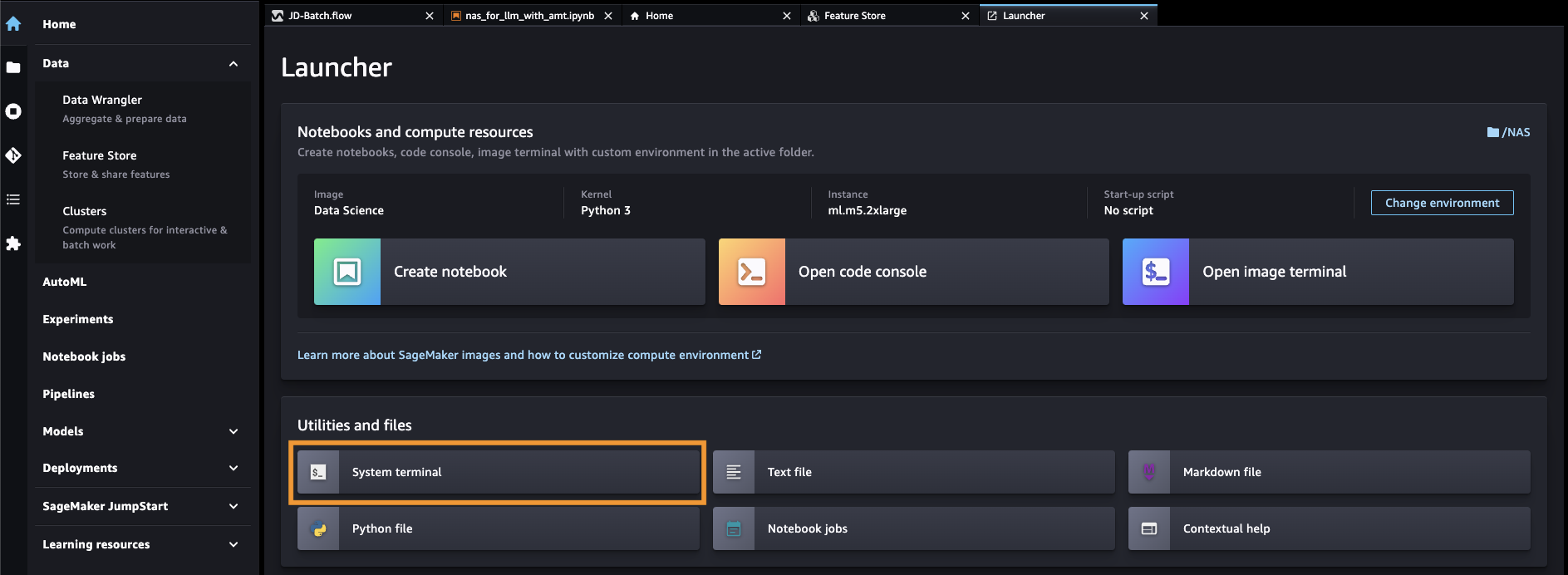
- افتح SageMaker Studio من وحدة تحكم SageMaker.

- اختار محطة النظام مع المرافق والملفات.
- قم بتشغيل الأمر التالي لاستنساخ جيثب ريبو إلى مثيل SageMaker Studio:
- انتقل إلى
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - فتح الملف
nas_for_llm_with_amt.ipynb. - قم بإعداد البيئة باستخدام
ml.g4dn.xlargeسبيل المثال واختيار أختار.
قم بإعداد نموذج BERT المدرب مسبقًا
في هذا القسم، نقوم باستيراد مجموعة بيانات التعرف على النصوص النصية من مكتبة مجموعة البيانات وتقسيم مجموعة البيانات إلى مجموعات تدريب ومجموعات التحقق من الصحة. تتكون مجموعة البيانات هذه من أزواج من الجمل. تتمثل مهمة BERT PLM في التعرف، في ضوء جزأين من النص، على ما إذا كان يمكن استنتاج معنى جزء نصي واحد من الجزء الآخر. وفي المثال التالي يمكننا أن نستنتج معنى العبارة الأولى من العبارة الثانية:
نقوم بتحميل مجموعة بيانات التعرف على النصوص من ملف GLUE مجموعة قياس الأداء عبر مكتبة مجموعة البيانات من عناق الوجه ضمن نص التدريب الخاص بنا (./training.py). قمنا بتقسيم مجموعة بيانات التدريب الأصلية من GLUE إلى مجموعة تدريب وتحقق من الصحة. في نهجنا، نقوم بضبط نموذج BERT الأساسي باستخدام مجموعة بيانات التدريب، ثم نقوم بإجراء بحث متعدد الأهداف لتحديد مجموعة الشبكات الفرعية التي تحقق التوازن الأمثل بين المقاييس الموضوعية. نحن نستخدم مجموعة بيانات التدريب حصريًا لضبط نموذج BERT. ومع ذلك، فإننا نستخدم بيانات التحقق من الصحة للبحث متعدد الأهداف عن طريق قياس الدقة في مجموعة بيانات التحقق من صحة الرفض.
ضبط BERT PLM باستخدام مجموعة بيانات خاصة بالمجال
تتضمن حالات الاستخدام النموذجية لنموذج BERT الخام توقع الجملة التالية أو نمذجة اللغة المقنعة. لاستخدام نموذج BERT الأساسي للمهام النهائية مثل التعرف على النص، يتعين علينا تحسين النموذج باستخدام مجموعة بيانات خاصة بالمجال. يمكنك استخدام نموذج BERT المضبوط جيدًا لمهام مثل تصنيف التسلسل والإجابة على الأسئلة وتصنيف الرمز المميز. ومع ذلك، لأغراض هذا العرض التوضيحي، نستخدم النموذج الدقيق للتصنيف الثنائي. قمنا بضبط نموذج BERT المُدرب مسبقًا باستخدام مجموعة بيانات التدريب التي أعددناها مسبقًا، باستخدام المعلمات الفائقة التالية:
نحفظ نقطة التفتيش الخاصة بالتدريب النموذجي في ملف خدمة تخزين أمازون البسيطة (Amazon S3)، بحيث يمكن تحميل النموذج أثناء البحث متعدد الأهداف القائم على NAS. قبل أن نقوم بتدريب النموذج، نحدد المقاييس مثل العصر وخسارة التدريب وعدد المعلمات وخطأ التحقق من الصحة:
بعد بدء عملية الضبط الدقيق، تستغرق مهمة التدريب حوالي 15 دقيقة حتى تكتمل.
قم بإجراء بحث متعدد الأهداف لتحديد الشبكات الفرعية وتصور النتائج
في الخطوة التالية، نقوم بإجراء بحث متعدد الأهداف على نموذج BERT الأساسي المضبوط بدقة عن طريق أخذ عينات من الشبكات الفرعية العشوائية باستخدام SageMaker AMT. للوصول إلى شبكة فرعية داخل الشبكة الفائقة (نموذج BERT المضبوط)، نقوم بإخفاء جميع مكونات PLM التي لا تشكل جزءًا من الشبكة الفرعية. إن إخفاء شبكة فائقة للعثور على شبكات فرعية في PLM هو أسلوب يستخدم لعزل وتحديد أنماط سلوك النموذج. لاحظ أن محولات Hugging Face تحتاج إلى أن يكون الحجم المخفي مضاعفًا لعدد الرؤوس. يتحكم الحجم المخفي في محول PLM في حجم مساحة متجه الحالة المخفية، مما يؤثر على قدرة النموذج على تعلم التمثيلات والأنماط المعقدة في البيانات. في BERT PLM، يكون متجه الحالة المخفية ذو حجم ثابت (768). لا يمكننا تغيير الحجم المخفي، وبالتالي يجب أن يكون عدد الرؤوس في [1، 3، 6، 12].
على النقيض من التحسين أحادي الهدف، في بيئة الأهداف المتعددة، لا يكون لدينا عادة حل واحد يعمل على تحسين جميع الأهداف في نفس الوقت. بدلاً من ذلك، نهدف إلى جمع مجموعة من الحلول التي تهيمن على جميع الحلول الأخرى في هدف واحد على الأقل (مثل خطأ التحقق من الصحة). يمكننا الآن بدء البحث متعدد الأهداف من خلال AMT من خلال تحديد المقاييس التي نريد تقليلها (خطأ التحقق من الصحة وعدد المعلمات). يتم تعريف الشبكات الفرعية العشوائية بواسطة المعلمة max_jobs ويتم تحديد عدد الوظائف المتزامنة بواسطة المعلمة max_parallel_jobs. يتوفر رمز تحميل نقطة تفتيش النموذج وتقييم الشبكة الفرعية في ملف evaluate_subnetwork.py النصي.
تستغرق مهمة ضبط AMT حوالي ساعتين و2 دقيقة للتشغيل. بعد تشغيل مهمة ضبط AMT بنجاح، نقوم بتحليل سجل المهمة وجمع تكوينات الشبكة الفرعية، مثل عدد الرؤوس وعدد الطبقات وعدد الوحدات والمقاييس المقابلة مثل خطأ التحقق من الصحة وعدد المعلمات. تعرض لقطة الشاشة التالية ملخصًا لمهمة موالف AMT الناجحة.
بعد ذلك، نقوم بتصور النتائج باستخدام مجموعة باريتو (المعروفة أيضًا باسم باريتو فرونتير أو مجموعة باريتو المثالية)، والتي تساعدنا على تحديد المجموعات المثالية من الشبكات الفرعية التي تهيمن على جميع الشبكات الفرعية الأخرى في المقياس الموضوعي (خطأ في التحقق من الصحة):
أولاً، نقوم بجمع البيانات من مهمة ضبط AMT. ثم نقوم برسم مجموعة باريتو باستخدام matplotlob.pyplot مع عدد المعلمات في المحور س وخطأ التحقق من الصحة في المحور ص. وهذا يعني أنه عندما ننتقل من شبكة فرعية لمجموعة باريتو إلى أخرى، يجب علينا إما التضحية بالأداء أو حجم النموذج ولكن تحسين الآخر. في النهاية، توفر لنا مجموعة باريتو المرونة لاختيار الشبكة الفرعية التي تناسب تفضيلاتنا. يمكننا أن نقرر مقدار ما نريد تقليل حجم شبكتنا ومقدار الأداء الذي نرغب في التضحية به.

انشر نموذج BERT المضبوط ونموذج الشبكة الفرعية المحسّن لـ NAS باستخدام SageMaker
بعد ذلك، قمنا بنشر أكبر نموذج في مجموعة باريتو الخاصة بنا والذي يؤدي إلى أقل قدر من انحطاط الأداء إلى أ نقطة نهاية SageMaker. أفضل نموذج هو الذي يوفر المفاضلة المثلى بين خطأ التحقق من الصحة وعدد المعلمات لحالة الاستخدام الخاصة بنا.
مقارنة النموذج
لقد استخدمنا نموذج BERT الأساسي المُدرب مسبقًا، وقمنا بضبطه بدقة باستخدام مجموعة بيانات خاصة بالمجال، وقمنا بإجراء بحث NAS لتحديد الشبكات الفرعية المهيمنة بناءً على المقاييس الموضوعية، ونشرنا النموذج المُنقَّص على نقطة نهاية SageMaker. بالإضافة إلى ذلك، أخذنا نموذج BERT الأساسي المُدرب مسبقًا وقمنا بنشر النموذج الأساسي على نقطة نهاية SageMaker ثانية. بعد ذلك، هربنا اختبار الحمل باستخدام Locust على كلا نقطتي النهاية الاستدلالية وتقييم الأداء من حيث وقت الاستجابة.
أولاً، نقوم باستيراد مكتبات Locust وBoto3 الضرورية. ثم نقوم بإنشاء بيانات وصفية للطلب ونسجل وقت البدء لاستخدامه في اختبار التحميل. ثم يتم تمرير الحمولة إلى نقطة نهاية SageMaker لاستدعاء واجهة برمجة التطبيقات (API) عبر BotoClient لمحاكاة طلبات المستخدم الحقيقية. نحن نستخدم Locust لإنشاء العديد من المستخدمين الظاهريين لإرسال الطلبات بالتوازي وقياس أداء نقطة النهاية تحت الحمل. يتم إجراء الاختبارات عن طريق زيادة عدد المستخدمين لكل من نقطتي النهاية، على التوالي. بعد اكتمال الاختبارات، يقوم Locust بإخراج ملف CSV لإحصائيات الطلب لكل نموذج من النماذج المنشورة.
بعد ذلك، نقوم بإنشاء مخططات وقت الاستجابة من ملفات CSV التي تم تنزيلها بعد إجراء الاختبارات باستخدام Locust. الغرض من رسم وقت الاستجابة مقابل عدد المستخدمين هو تحليل نتائج اختبار الحمل من خلال تصور تأثير وقت الاستجابة لنقاط نهاية النموذج. في الرسم البياني التالي، يمكننا أن نرى أن نقطة نهاية نموذج NAS-Pruned تحقق وقت استجابة أقل مقارنة بنقطة نهاية نموذج BERT الأساسية.
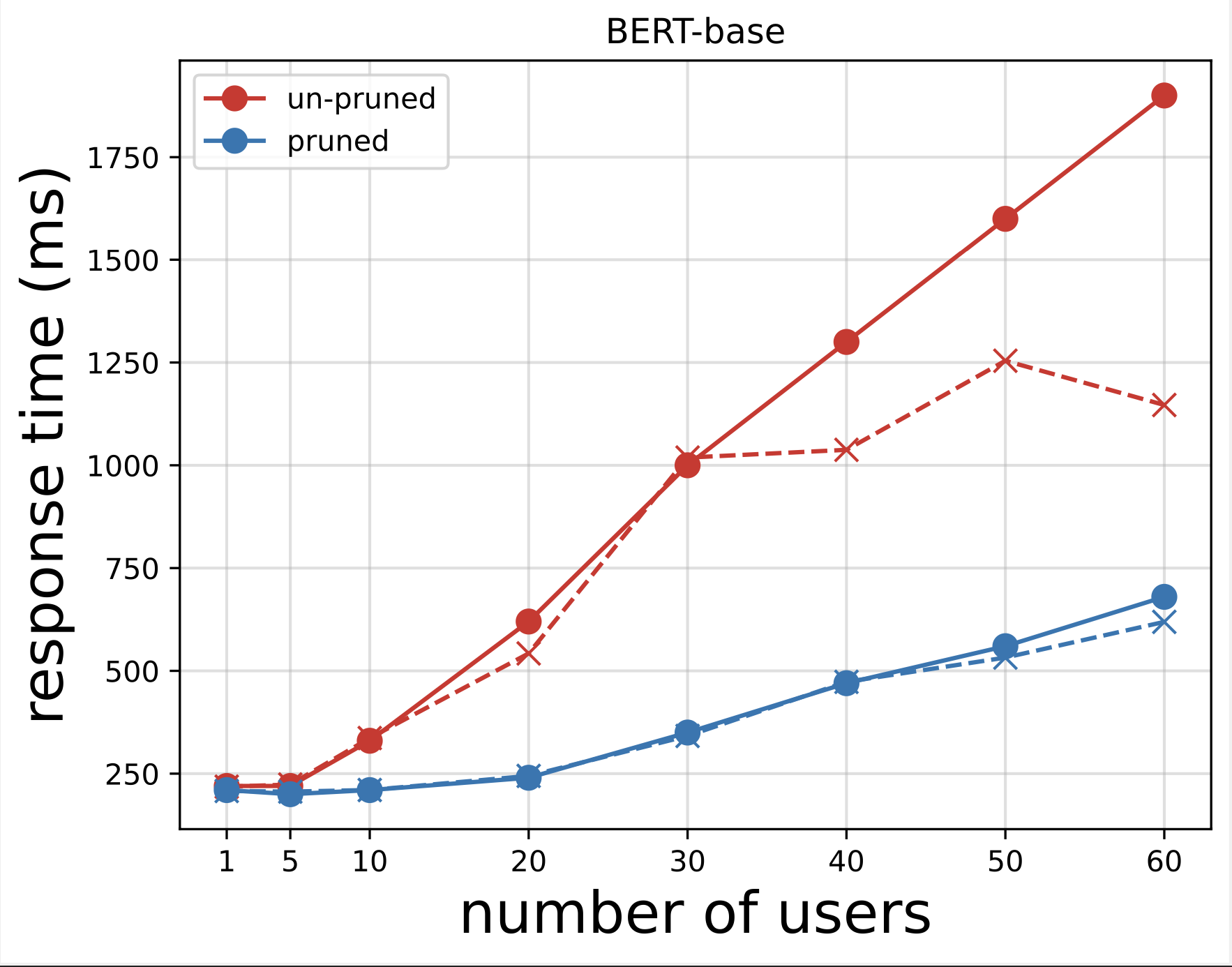
في المخطط الثاني، وهو امتداد للمخطط الأول، نلاحظ أنه بعد حوالي 70 مستخدمًا، يبدأ SageMaker في خنق نقطة النهاية الأساسية لنموذج BERT ويطرح استثناءً. ومع ذلك، بالنسبة لنقطة نهاية نموذج NAS، يحدث الاختناق بين 90-100 مستخدم وبوقت استجابة أقل.

من المخططين، نلاحظ أن النموذج المُنقَّع يتمتع بوقت استجابة أسرع ومقياس أفضل عند مقارنته بالنموذج غير المُنقَّع. نظرًا لأننا نقوم بتوسيع عدد نقاط نهاية الاستدلال، كما هو الحال مع المستخدمين الذين ينشرون عددًا كبيرًا من نقاط نهاية الاستدلال لتطبيقات PLM الخاصة بهم، فإن فوائد التكلفة وتحسين الأداء تبدأ في أن تصبح كبيرة جدًا.
تنظيف
لحذف نقاط نهاية SageMaker لنموذج BERT الأساسي المضبوط جيدًا ونموذج NAS، أكمل الخطوات التالية:
- في وحدة تحكم SageMaker ، اختر الإستنباط و النهاية في جزء التنقل.
- حدد نقطة النهاية واحذفها.
وبدلاً من ذلك، من دفتر ملاحظات SageMaker Studio، قم بتشغيل الأوامر التالية عن طريق توفير أسماء نقاط النهاية:
وفي الختام
في هذا المنشور، ناقشنا كيفية استخدام NAS لتهذيب نموذج BERT المضبوط بدقة. لقد قمنا أولاً بتدريب نموذج BERT الأساسي باستخدام البيانات الخاصة بالمجال وقمنا بنشره على نقطة نهاية SageMaker. لقد أجرينا بحثًا متعدد الأهداف على نموذج BERT الأساسي المضبوط بدقة باستخدام SageMaker AMT لمهمة مستهدفة. لقد تصورنا واجهة Pareto واخترنا نموذج BERT الأمثل لـ NAS من Pareto وقمنا بنشر النموذج إلى نقطة نهاية SageMaker ثانية. أجرينا اختبار التحميل باستخدام Locust لمحاكاة المستخدمين الذين يستعلمون عن نقطتي النهاية، وقمنا بقياس وتسجيل أوقات الاستجابة في ملف CSV. لقد رسمنا وقت الاستجابة مقابل عدد المستخدمين لكلا النموذجين.
لاحظنا أن أداء نموذج BERT المشذّب كان أفضل بكثير في كل من وقت الاستجابة وعتبة اختناق المثيل. لقد خلصنا إلى أن نموذج NAS-Pruned كان أكثر مرونة في مواجهة الحمل المتزايد على نقطة النهاية، مع الحفاظ على وقت استجابة أقل حتى مع زيادة عدد المستخدمين الذين شددوا على النظام مقارنة بنموذج BERT الأساسي. يمكنك تطبيق تقنية NAS الموضحة في هذا المنشور على أي نموذج لغة كبير للعثور على نموذج مُنقَّص يمكنه أداء المهمة المستهدفة بوقت استجابة أقل بكثير. يمكنك تحسين النهج بشكل أكبر باستخدام زمن الوصول كمعلمة بالإضافة إلى فقدان التحقق من الصحة.
على الرغم من أننا نستخدم NAS في هذا المنشور، إلا أن التكميم هو أسلوب شائع آخر يستخدم لتحسين نماذج PLM وضغطها. يقلل التكميم من دقة الأوزان وعمليات التنشيط في شبكة مدربة من نقطة عائمة 32 بت إلى عروض بت أقل مثل الأعداد الصحيحة 8 بت أو 16 بت، مما يؤدي إلى نموذج مضغوط يولد استنتاجًا أسرع. لا يقلل التكميم من عدد المعلمات؛ وبدلاً من ذلك فإنه يقلل من دقة المعلمات الموجودة للحصول على نموذج مضغوط. يؤدي تقليم NAS إلى إزالة الشبكات الزائدة في PLM، مما يؤدي إلى إنشاء نموذج متناثر بمعلمات أقل. عادةً، يتم استخدام تقليم NAS وتكميمه معًا لضغط PLMs الكبيرة للحفاظ على دقة النموذج، وتقليل خسائر التحقق من الصحة مع تحسين الأداء، وتقليل حجم النموذج. تشمل التقنيات الأخرى الشائعة الاستخدام لتقليل حجم PLMs تقطير المعرفة, عامل المصفوفةو شلالات التقطير.
يعد النهج المقترح في منشور المدونة مناسبًا للفرق التي تستخدم SageMaker لتدريب النماذج وضبطها باستخدام البيانات الخاصة بالمجال ونشر نقاط النهاية لتوليد الاستدلال. إذا كنت تبحث عن خدمة مُدارة بالكامل توفر مجموعة مختارة من النماذج الأساسية عالية الأداء اللازمة لإنشاء تطبيقات ذكاء اصطناعي مولدة، ففكر في استخدام أمازون بيدروك. إذا كنت تبحث عن نماذج مفتوحة المصدر مدربة مسبقًا لمجموعة واسعة من حالات استخدام الأعمال وترغب في الوصول إلى قوالب الحلول وأمثلة دفاتر الملاحظات، ففكر في استخدام أمازون سيج ميكر جومب ستارت. يتوفر أيضًا إصدار مدرب مسبقًا من نموذج الغلاف الأساسي Hugging Face BERT الذي استخدمناه في هذا المنشور من SageMaker JumpStart.
حول المؤلف
 أبراجيثان فيدياناثان هو مهندس حلول المؤسسات الرئيسي في AWS. وهو مهندس سحابي يتمتع بخبرة تزيد عن 24 عامًا في تصميم وتطوير أنظمة البرامج واسعة النطاق والموزعة. وهو متخصص في الذكاء الاصطناعي التوليدي وهندسة بيانات التعلم الآلي. إنه عداء ماراثون طموح وتشمل هواياته المشي لمسافات طويلة وركوب الدراجة وقضاء الوقت مع زوجته وولديه.
أبراجيثان فيدياناثان هو مهندس حلول المؤسسات الرئيسي في AWS. وهو مهندس سحابي يتمتع بخبرة تزيد عن 24 عامًا في تصميم وتطوير أنظمة البرامج واسعة النطاق والموزعة. وهو متخصص في الذكاء الاصطناعي التوليدي وهندسة بيانات التعلم الآلي. إنه عداء ماراثون طموح وتشمل هواياته المشي لمسافات طويلة وركوب الدراجة وقضاء الوقت مع زوجته وولديه.
 آرون كلاين هو عالم تطبيقي كبير في AWS ويعمل على أساليب التعلم الآلي الآلي للشبكات العصبية العميقة.
آرون كلاين هو عالم تطبيقي كبير في AWS ويعمل على أساليب التعلم الآلي الآلي للشبكات العصبية العميقة.
 جاسيك جوليبيوسكي هو عالم تطبيقي كبير في AWS.
جاسيك جوليبيوسكي هو عالم تطبيقي كبير في AWS.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/

